
🏅 Congratulations to the winners of the #ISWC2025 SemTab Challenge!
🎓 “ADFr: Knowledge Graph Entity Linking via Interactive Reasoning and Exploration with GRASP” by Sebastian Walter and Hannah Bast.
👏 A big round of applause to the authors!
#EntityLinking #SPARQL



1
5
401

7 Nov 2025
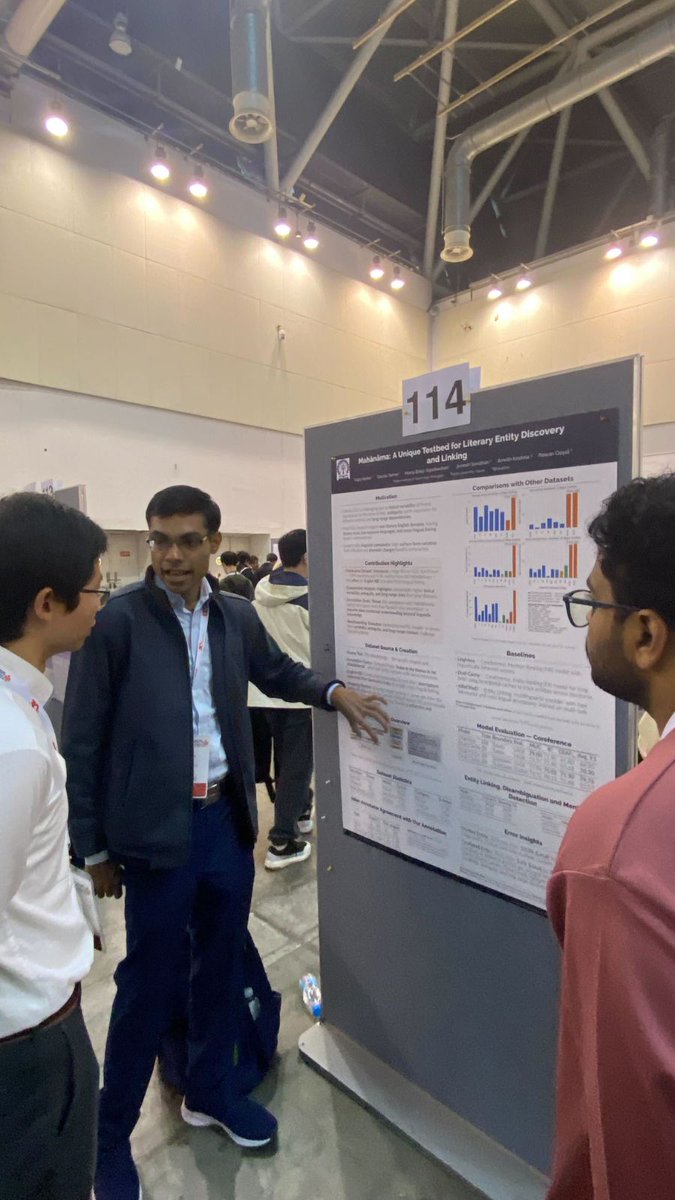
Our poster Mahānāma is starting to attract some buzz at #EMNLP2025! 🎉
Exciting to see growing interest in literary & cultural NLP 🪔📚
#EMNLP #NLP #EntityLinking #DigitalHumanities
#Research
7 Nov 2025

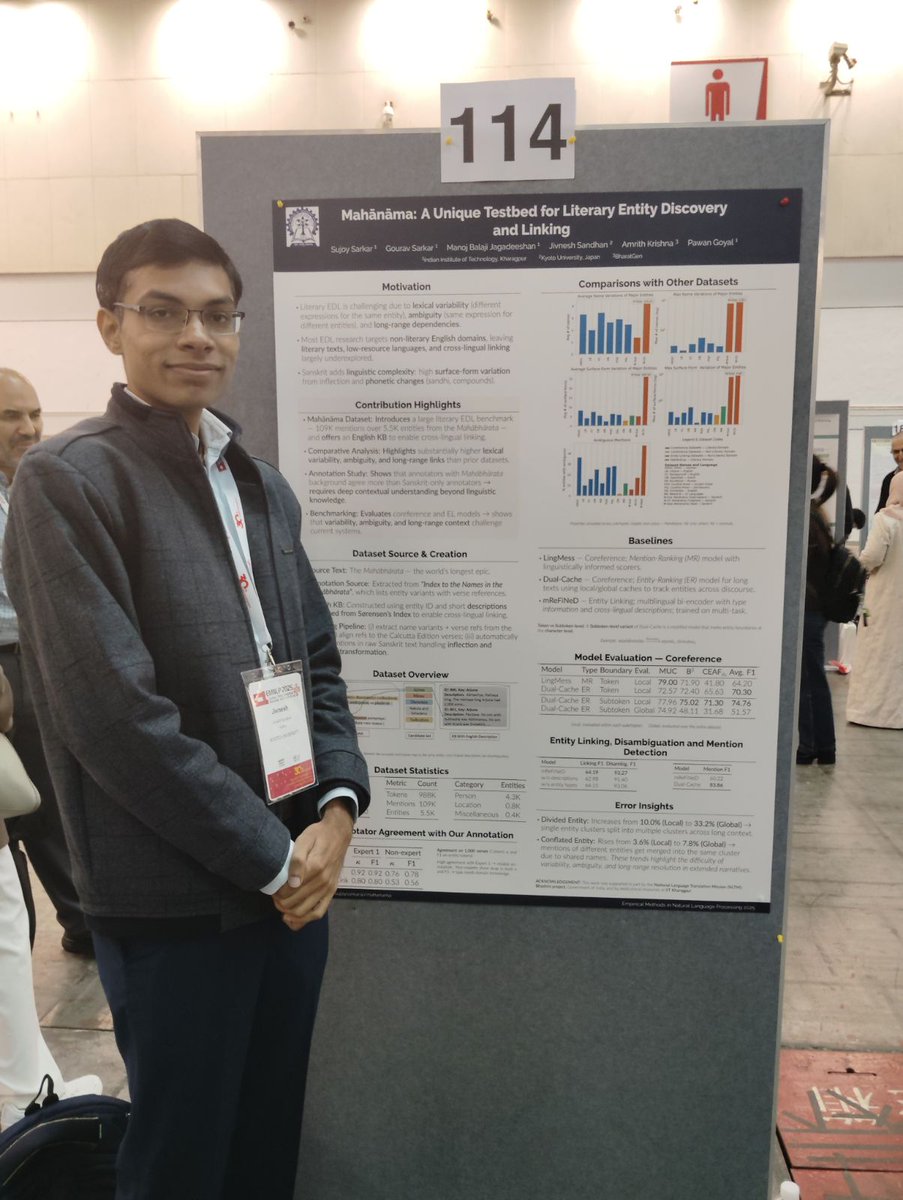
Poster up! 🎉 Mahānāma: A Unique Testbed for Literary Entity Discovery and Linking — presented in person by my good friend and co-author Jivnesh Sandhan at EMNLP 2025. Come say hi if you’re around!
#EMNLP2025 #PosterSession #EMNLP
1
6
641

📢 Kicking off the day at the BioNLP Workshop with the opening talk!
🧬 Accelerating Cross-Encoders in Biomedical Entity Linking
With: @JavierSanzCruza & @jakelever0
📍 Room 2.15
🕗 08:50–09:10
Drop by if you’re around — would love to chat!
#BioNLP #ACL2025NLP #EntityLinking

5
12
569

10 Sep 2024
Introducing our latest work, OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs 🚀. OneGen enables LLMs to perform retrieval during generation, utilizing less training data while achieving impressive performance and efficiency. #NLP #LLMs #RAG #Generation #Retrieval #Efficient #EntityLinking
📖 Paper: huggingface.co/papers/2409.0…
⌨️ Code: github.com/zjunlp/OneGen
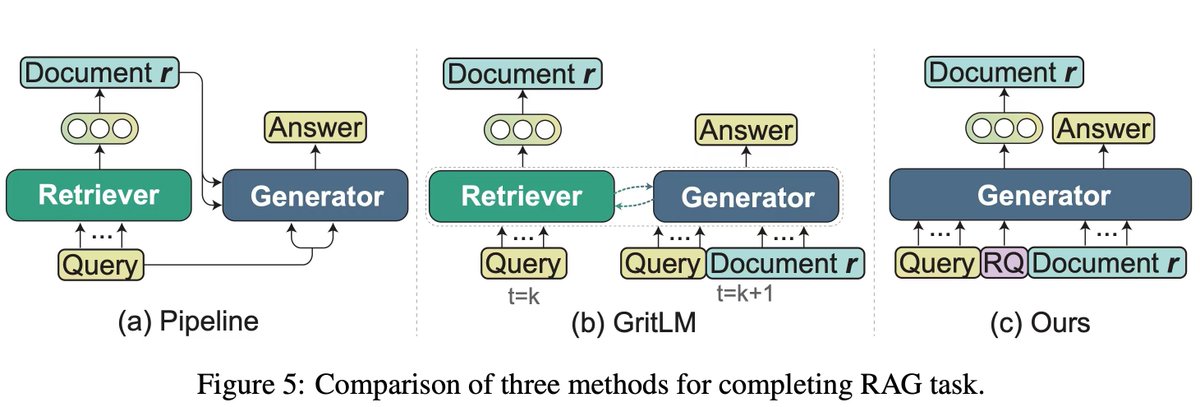
🧩 Why OneGen: Many current tasks rely on both the retrieval and generative capabilities of models.
Traditional approaches typically employ a separate retrieval model and a generation model to accomplish such composite tasks. Since the representation spaces of generative and retrieval models do not overlap, their mode of interaction is through text.
In RAG tasks, a query undergoes a forward pass in the generative model and another in the retrieval model, necessitating two forward computations in total.
Furthermore, this current pipeline approach is susceptible to the accumulation of errors. Besides, in multi-turn dialogues, reformulation of the query is often essential.
Our work, however, circumvents the need for the query to undergo two forward computations and also eliminates the requirement for query reformulation, while adopting an end-to-end training methodology.
🔥 Contribution:
1️⃣ We propose a training-efficiency, inference-efficiency, and pluggable framework OneGen that is particularly suitable for tasks interleaved with generation and retrieval.
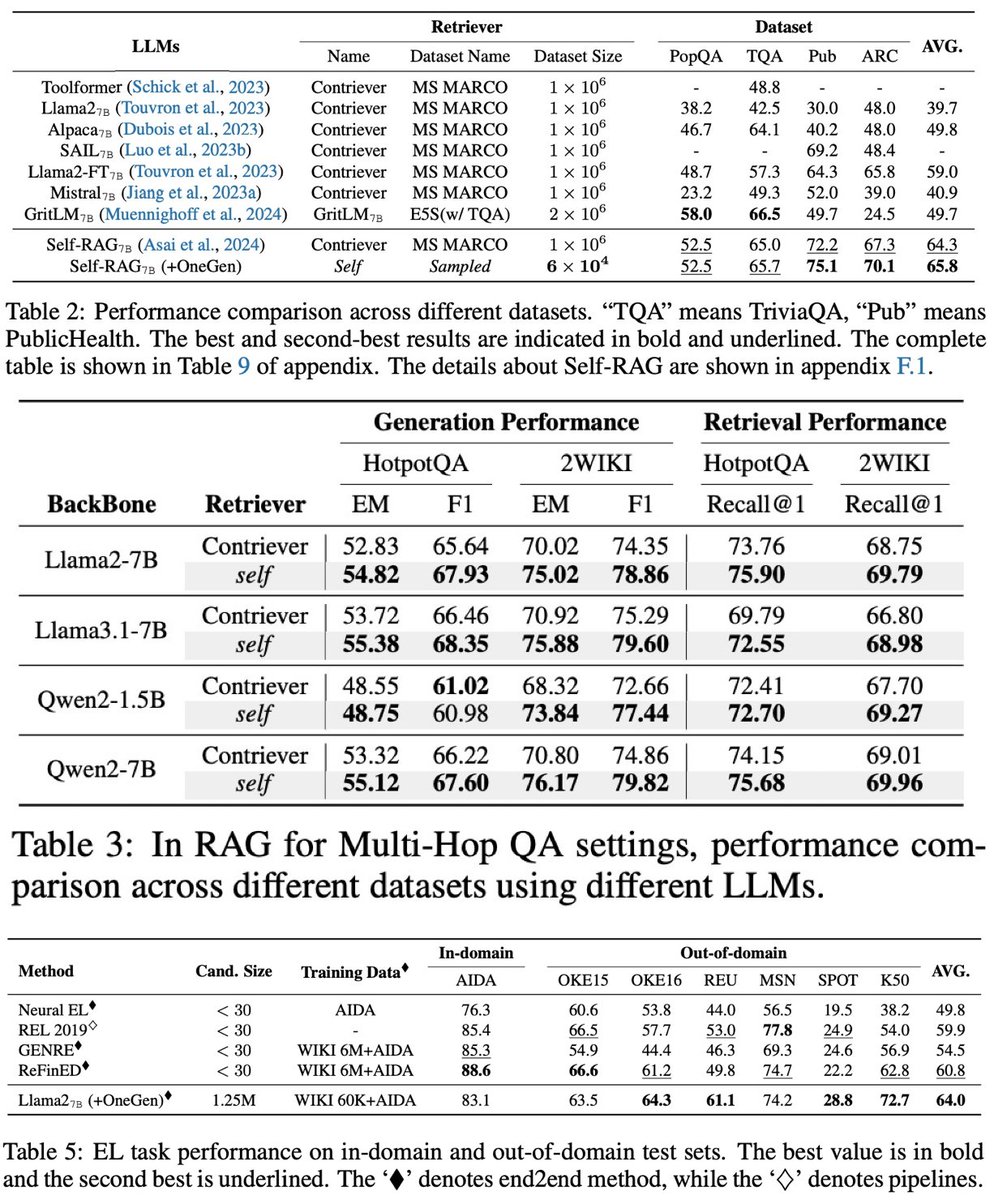
2️⃣ Our model, fine-tuned on less training data, demonstrates better performance on six RAG datasets and six entity linking datasets on average.
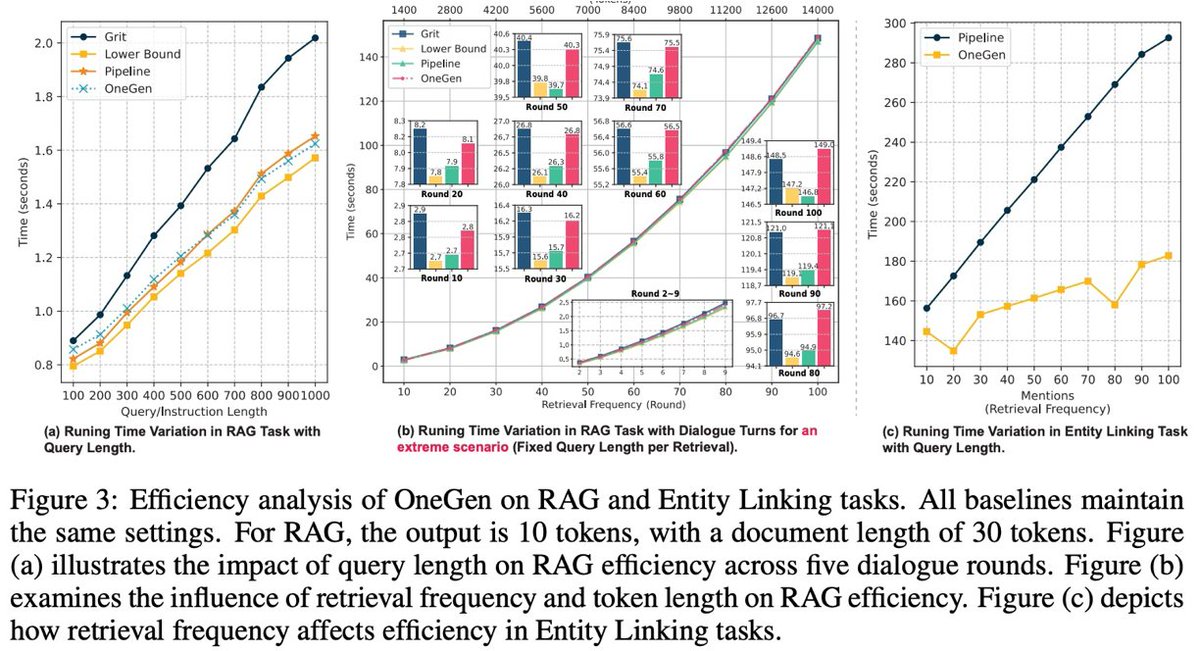
3️⃣ We demonstrate the efficiency of OneGen at inference, highlighting a speed improvement as the length of query increases or retrieval frequency increases, compared to other LLM alternatives.
💡Solution Overview: Our core idea is to integrate generation and retrieval to the same context by allocating the retrieval task to retrieval tokens generated in an autoregressive manner, thus enabling LLM to perform both tasks in a single forward pass.
🔬Results: We evaluate the effectiveness of our method on two main tasks that require both generation and retrieval: RAG (including single-hop QA which needs single-retrieval and multi-hop QA which needs multi-retrieval) and Entity Linking (EL).
Empirical results show OneGen outperforms the previous pipeline solutions. Moreover, further analysis demonstrates OneGen can enhance retrieval capability when jointly trained, with no sacrifice in generation capability. In addition, we demonstrate superior inference speed and memory consumption of OneGen compared with other LLM alternatives, particularly as retrieval frequency increases.
We're excited to hear your thoughts and feedback ! 🎙️

20
93
21,913

☝️ #Entitylinking is a foundational task in #textanalysis.
⚙️ Here's how @OntotextGraphDB’s standards-based entity linking makes it easier to add new, related data that provides context to other entities stored in the original data model. hubs.la/Q02MlQzT0
2
2
197
Ontotext ranked among the top 10 research teams in one of the toughest #entitylinking challenges focused on medical entities extraction & normalization to #SNOMED CT. We are committed to pushing the boundaries of applying #AI in healthcare 💪 hubs.la/Q02yNj470
1
94
🎉 Excited to share that our paper about SNOMED #entitylinking was awarded Best Paper award at the #BioInformed Conference (hubs.la/Q02G91Wl0). Stay tuned for the upcoming full text & post conference proceedings in Springer.


A joint team b/n Ontotext & @universitysofia ranked #7/500 at the toughest #entitylinking competition! This is a great recognition of our #AI skills & expertise w/n the #Healthcare & #LifeSciences domains. hubs.la/Q02yNB200
1
2
179
A joint team b/n Ontotext & @universitysofia ranked #7/500 at the toughest #entitylinking competition! This is a great recognition of our #AI skills & expertise w/n the #Healthcare & #LifeSciences domains. hubs.la/Q02yNB200
1
2
295
We compare how the different #GraphRAG patterns can address the problem of lacking background knowledge that the naive “chunky” #RAG hits, including the use of #NLQ and external context derived from #Wikidata via #EntityLinking: hubs.la/Q02v7zqx0
2
6
569
Our webinar tomorrow will focus on a #knowledgegraph demonstrator we put a lot of effort to create, which leverages #LLMs to boost information extraction tasks, such as named entities recognition, #entitylinking, & event & relationship extraction. Join us! hubs.la/Q02t4fSN0

2
6
235
On Apr 17 our team will demonstrate how LLMs & #entitylinking enable users to define, detect, & customize model schema in real-time, supporting decision-making in investment, risk management, & strategic planning. Join them! ⤵
hubs.la/Q02rQQqf0 #knowledgegraphs #semantics
1
4
210

17 Feb 2024
2. #EntityLinking that beats some of the big software companies ontotext.com/blog/common-eng… . Cc @enrichmydata
2
2
80

7 Feb 2024
@Babelscape's R&D for #agroinformatics with @UF is a clear use case for #WSD and #EntityLinking and how they can perform well together in a vertical like #farming! #NLProc #NLP #LLMs
7 Feb 2024

Our #Word #Sense #Disambiguation and #Entity #Linking system to boost agroinformatics and corpora research at the University of Florida. More here: multilingual.com/babelscapes…
1
4
289
24 Dec 2023
If you are in #Tokyo tomorrow you might be interested in this talk I will give @chokkanorg #OkazakiLab on a #UnifiedVision of #WSD, #EntityLinking and #RelationExtraction! #NLProc nlp.c.titech.ac.jp/news/2023…
2
7
22
3,433

4 Oct 2023
Stay tuned for the integration of #multilingual #semantics and #LLMs! #disambiguation #entitylinking #NLProc #NLP
2
6
532

22 Sep 2023
Next up on: #KalicubeTuesdays with @me__emi__ & @moccandsayegh
Let us learn how #EntityLinking bridges the gap between the web’s treasure trove of information & your brand’s identity
Tickets here!
eventbrite.com/e/kalicube-tu…
#GoogleSearch #EntitySEO #ContentCreation #Wordlift

3
66
20 Sep 2023
Next up on: #KalicubeTuesdays with @me__emi__ & @moccandsayegh
Enter the fascinating world of #EntityLinking & #EntitySEO for #branddevelopment = two game-changing concepts that are reshaping the online search ecosystem.
Tickets here!
eventbrite.com/e/kalicube-tu…

2
4
1,092
31 Aug 2023
Learn how to connect #entities by aggregating the world’s information & making your #content relevant to search.
Check out this @wordliftit article ‘#Entity-Oriented #SEO: How #EntityLinking Can Boost Your Performance’ written by @me__emi__.
Read now!
wordlift.io/blog/en/entity-b…

7
217

28 Jun 2023
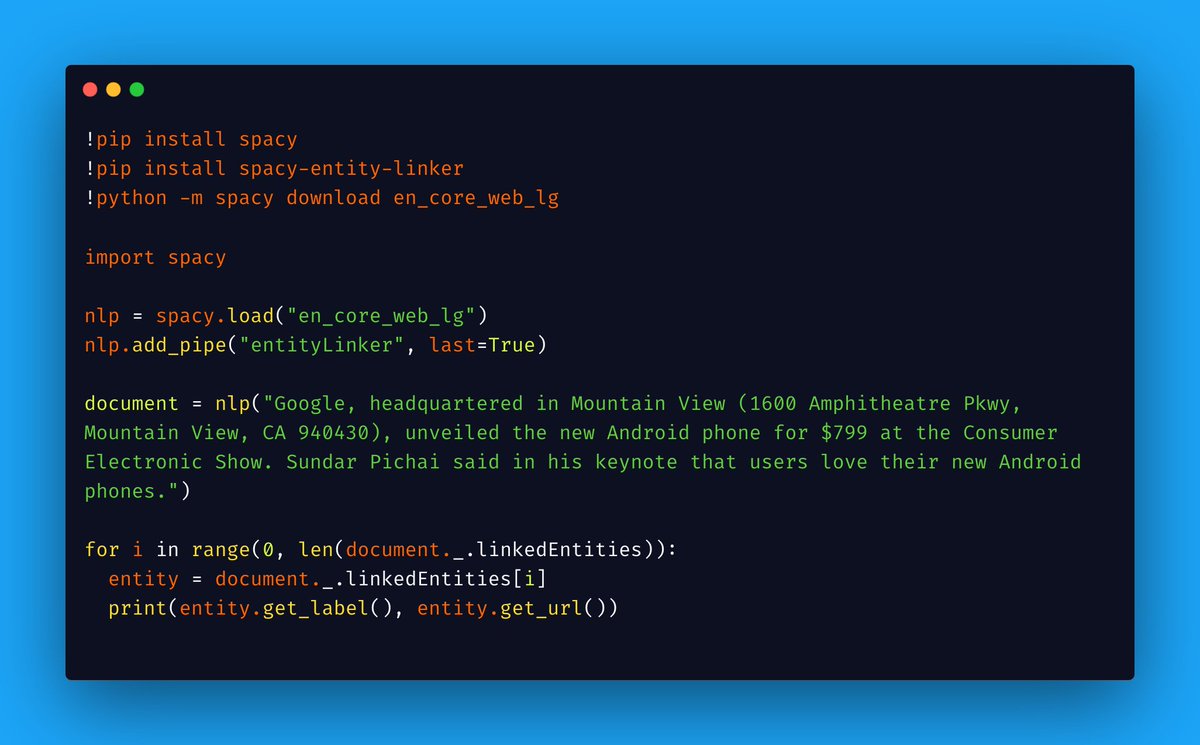
Create #SEO WebPage JSON-LD with mentions for FREE by using #GoogleColab, #spaCy & #ChatGPT through #entityLinking (wikification)!
Step 1: You run the following snippet in Colab (everything's setup, you just need to post the code)
Step 2: Copy the output & then...
1
2
9
885

30 May 2023
@n_heist from @dwsunima presenting our work on #NIL aware #entitylinking with NASTyLinker at #eswc2023

3
141