
🚨 Catch issues before they impact your customers.
Explore → hubs.li/Q04jYfZt0
#NetSuite #ERP #Ecommerce #BusinessAnalytics #CustomerExperience #DigitalTransformation #ConnectedData

6

Jun 12
The Early Bird clock is ticking. ⏱️
In just 3 days, ticket prices for #CDL26 will increase across all pass types - including All-Access, Day Passes, and Remote. This is your final window to join us at the Leonardo Royal Hotel London Tower Bridge while saving 30%.
What’s on the table:
✅ Technical deep-dives into Knowledge Graphs and LLMs.
✅ Hands-on Masterclasses.
✅ Networking with the world’s top data architects.
Don’t wait for the deadline. Save 30% and book your pass today.
👉 2026.connected-data.london/c…
#CDL26 #ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech #EnterpriseData #DataStrategy #AIArchitecture

1
109
Jun 10
Programme Update: New Speakers from Gartner, Scania and Google 🎤
The Connected Data London 2026 programme continues to expand. We are pleased to introduce our latest speaker additions for our 10th anniversary event in London:
Vinay Balasubramaniam (Google): Director of Product Management for BigQuery, our Gold Sponsor. He will discuss the BigQuery Core SQL Engine, price performance and advanced analytics covering vector search, graph analytics and AI co processing, drawing on his extensive background leading enterprise platform strategy.
Afraz Jaffri (Gartner): A VP Analyst delivering strategic market insights on the intersection of AI, context and knowledge graphs. He will break down how to implement graph based solutions for reliable agentic systems, drawing on a decade of experience advising enterprise leaders on data platform strategy.
Bei Li (Google): A founder of Spanner Graph and BigQuery Graph from our Gold Sponsor team. He will share the technical vision and engineering development behind both graph systems since their inception, alongside insights from building foundational data infrastructure for Google Search and Ads.
Nikos Trokanas (Scania Group): An Ontology Architect specialising in knowledge graphs, ontology engineering and generative AI integration. He will share practical insights from his 15 years of experience delivering semantic infrastructure across the automotive, finance and biomedical sectors.
Read more about our speakers and their upcoming sessions:
👉 2026.connected-data.london/?…
#CDL26 #ConnectedData #KnowledgeGraphs #DataArchitecture #Gartner #Scania #Google #BigQuery #AI
Ps. Early Bird pricing ends Monday 15 June. Book your ticket now for the lowest rate:
👉 2026.connected-data.london/

1
123

Context in Finance Isn’t Metadata — It’s a Binding Contract linkedin.com/pulse/context-f… cc @kidehen @asemota @quentinkasseh @bayoadekanmbi @AlanMorrison
#ai #finance #ConnectedData #KnowledgeGraph #ontology #Semantics
2
65
May 25
Wanted: Masterclass Instructors for #CDL26. 🛠️
At Connected Data London, we don’t just talk about the future - we build it. Our 2-hour Masterclasses are designed to give attendees practical, hands-on skills they can use in their daily work immediately.
We are looking for experts to lead deep-dive tutorials on:
Graph Engineering: Persistence strategies, triple stores vs LPGs, and scaling.
AI Implementation: Building GraphRAG pipelines, fine-tuning LLMs with KGs, or agentic workflows.
Data Modelling: Advanced ontology design, SHACL validation, and semantic layers.
Why lead a Masterclass?
Beyond the prestige of the CDL stage, you’ll have the opportunity to engage deeply with a technical audience hungry for real-world skills.
📝 Submit your Masterclass proposal: connected-data.london/2026-c…
#CDL26 #ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Masterclass #GraphDatabase #DataEngineering #AIWorkshops

3
205
May 18
How does an AI agent remember its reasoning? 🧠
At Connected Data London 2026, we are putting a spotlight on Context Graphs—the structures that capture the temporal lineage and decision traces behind autonomous behaviour.
If you are working on the architectures that give AI a "memory" beyond simple vector retrieval, we want to see your work on our stage. We are looking for talks on:
Decision-aware graphs and lineage.
Bridging the gap between theory and real-world production.
Capturing the precedents that govern agentic systems.
Join the community shaping the future of AI memory and trust.
🗓️ Deadline: 31 August
🔗 Guidelines & Submissions: connected-data.london/2026-c…
#CDL26 #ConnectedData #KnowledgeGraphs #ResponsibleAI #AIGovernance #ContextGraphs

1
5
408
May 13
AI and Knowledge Graphs: A Mutually Beneficial Relationship. 🤝
While LLMs excel at reasoning and natural language, they often struggle with factual consistency and domain-specific truth. This is where Knowledge Graphs step in—acting as the essential "truth layer" for GenAI.
For #CDL26, we want to see how you are building the next generation of AI systems. We are looking for submissions on:
Graph RAG: Real-world lessons, variants, and Knowledge Augmented Generation (KAG).
Graphs and Agents: Powering agent workflows and providing agentic memory.
Neuro-symbolic AI: Combining rule-based reasoning with machine learning.
Graph Learning: Use cases for GNNs and Graph Foundation models.
If you are bridging the gap between symbolic logic and neural networks, we want you on our stage in London.
📝 Submit your proposal: connected-data.london/2026-c…
#ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech #GenAI #AgenticAI #GraphRAG #NLP #CDL26

3
113

AIoT: From Connected Data to Intelligent Automation Across Industries
iotbusinessnews.com/2026/04/… #AIoT #ConnectedData
1
2
3
88
Are we seeing a surge in "vibe ontologies" or a new era of rigorous Knowledge Engineering?
At Connected Data London 2026, we’re diving deep into the resurgence of Ontologies. From acting as the truth layer for Agentic AI to enabling process harmonisation across the enterprise, the "Foundations and Applications of Ontologies" track is one of our most anticipated.
We are calling for speakers to share their insights on:
Ontology design patterns for the LLM era.
Moving from raw data to knowledge engineering.
The role of visual editors and automated quality checks.
Don't just follow the debate - lead it.
🗓️ Deadline: 31 August
🔗 Guidelines and Submissions: connected-data.london/2026-c…
#ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech #DataArchitect #CDL26

1
3
229
Apr 29
🚀 The wait is over! The Call for Submissions for #CDL26 is NOW OPEN.
Be a part of the celebration: 10 Years Connecting Data, People and Ideas
The leading global technology conference for those using Relationships, Meaning, and Context in Data to achieve great things.
Join us in the heart of London as we celebrate a decade of innovation in Knowledge Graphs, Graph Analytics, Data Science, AI, Graph Databases, Semantic Tech and Ontology this November.
Share your use cases and breakthroughs. Submissions are open across 2 areas:
Presentations:
Real world use cases and innovative approaches across 3 tracks: Nodes, focus on use cases, Edges, focus on innovation, Educational, focus on applications.
Masterclasses:
Hands-on tutorials in which instructors teach attendees skills they can use in their daily work.
Why Speak at CDL26?
Global Platform: Join 350 luminaries who have graced our stage and reach our ever-growing global audience of thousands.
Adoption and Innovation: From the resurgence of Ontologies to the cutting edge of Agentic AI and Context Graphs.
Speaker Benefits: Free event pass, speaker guidance, and exclusive network discounts.
📅 Deadline: Aug 31
✅ Notification of Acceptance - September 14, 2026
Topics of interest and submission guidelines here:
🔗 connected-data.london/2026-c…
#ConnectedData #KnowledgeGraphs #DataScience #AI #GraphDB #Analytics #SemTech #EmergingTech

2
423
Apr 20
Semantic Partners joins Connected Data London 2026 as a Silver Sponsor 🥈
A specialist in liberating data meaning from isolated silos, they build knowledge graphs using RDF and semantic technology. Their expertise spans three core pillars: graph systems implementation, semantic engineering and knowledge graph training.
👉 Meet the team at CDL26 to discuss how they implement custom semantic solutions for your business:
2026.connected-data.london/s…
#CDL26 #ConnectedData #KnowledgeGraphs #RDF #SemanticTech #Ontology

2
113
Mar 18
Save the Date: Connected Data London 2026 🚀
We are celebrating 10 years of Connected Data London! Join us on 11–12 November 2026 at the Leonardo Hotel Tower Bridge as we bring together the world’s leading pioneers in Knowledge Graphs, AI, and Linked Data for our milestone anniversary edition.
To kick off the countdown, we are proud to announce our first four speakers:
🎤 Keynote: William Tunstall-Pedoe Founder of Unlikely AI and the pioneer behind the technology that powers Amazon Alexa.
Joined by:
🔹 Malcolm Hawker – Thought leader and CDO at Profisee.
🔹 Juan Sequeda – Principal Fundamental Researcher at ServiceNow.
🔹 Jessica Talisman – Semantic Architect and Founder of The Ontology Pipeline.
From technical masterclasses to world-class keynotes, CDL 2026 will be our most ambitious event yet.
Get your Super Earlybird pass here 👉 2026.connected-data.london/?…
Find out more on our blog post: connected-data.london/post/c…
#CDL2026 #ConnectedData #10thAnniversary #KnowledgeGraphs #AI #DataStrategy #LondonTech

1
3
630

Feb 20
How and Why Netflix Built a Real-Time Distributed Graph
Ingesting and Processing Data Streams at Internet Scale, Building a Scalable Storage Layer
The Netflix product experience historically consisted of a single core offering: streaming video on demand. But the evolution of its business has created a new class of problems where member interactions with the app have to be analyzed across different business verticals.
In a traditional data warehouse, these events would land in at least two different tables and may be processed at different cadences. But in a graph system, they become connected almost instantly. Ultimately, analyzing member interactions in the app across domains empowers Netflix to create more personalized and engaging experiences.
The data engineering team recognized a solution to process and store swathes of interconnected data while enabling fast querying to discover insights is needed.
Although they could have structured the data in various ways, they ultimately settled on a graph representation.
Graph offers key advantages, specifically:
* Relationship-Centric Queries
* Flexibility as Relationships Grow
* Pattern and Anomaly Detection
This is why they set out to build a Real-Time Distributed Graph, or “RDG” for short.
Three main layers in the system power the RDG:
* Ingestion and Processing — receive events from disparate upstream data sources and use them to generate graph nodes and edges.
* Storage — write nodes and edges to persistent data stores.
* Serving — expose ways for internal clients to query graph nodes and edges.
The team built the ingestion and processing pipeline using Apache Flink to transform streaming events into graph primitives.
But the critical question is - once billions of nodes and edges are created from member interactions, how do you actually store them?
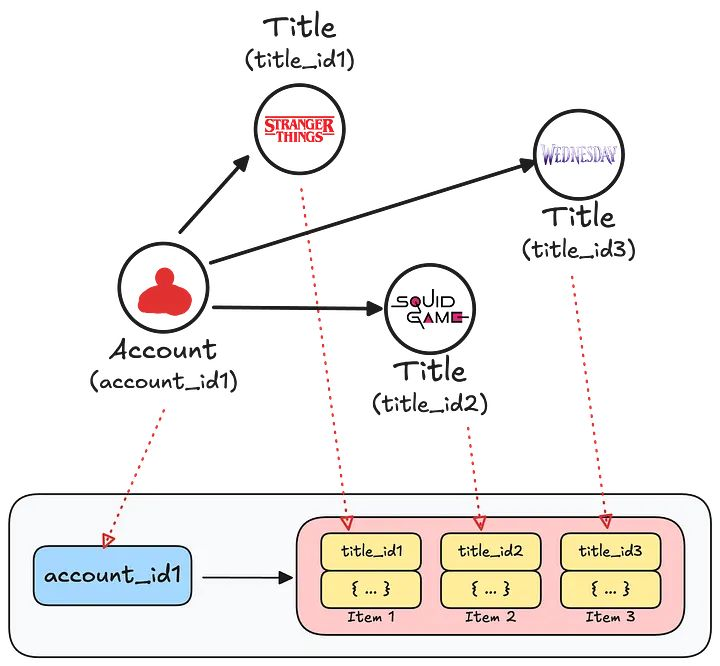
The RDG is a property graph consisting of:
* Nodes: Entities including member accounts, titles (such as shows/movies), devices, and games. Each node has a unique identifier and a set of properties containing additional metadata.
* Edges: Relationships between nodes, such as “started watching,” “logged in from,” or “plays.” Edges also have unique identifiers and properties, such as timestamps.
In evaluating different storage options, Netflix explored traditional graph datastores. While they do provide feature-rich capabilities around things like native-graph query support and data models to represent different types of graphs, they also pose a mix of scalability, workload, and ecosystem challenges.
They ultimately decided that the options evaluated wouldn’t meet requirements at Netflix’s scale. So they turned instead to an internal platform specifically designed for this type of challenge: the Data Gateway Platform. More specifically, its Key-Value Data Abstraction Layer (KVDAL).
For the RDG, Netflix provisions a separate namespace for every node type and edge type in the graph. This also makes it straightforward to extend the RDG with new types of nodes and edges.
By Adrian Taruc, James Dalton, Luis Medina, Ajit Koti
How and Why Netflix Built a Real-Time Distributed Graph: Part 1 — Ingesting and Processing Data Streams at Internet Scale
netflixtechblog.com/how-and-…
How and Why Netflix Built a Real-Time Distributed Graph: Part 2 — Building a Scalable Storage Layer
netflixtechblog.medium.com/h…
#EmergingTech #DataEngineering #ConnectedData #RealTimeProcessing
--
📩 The Year of the Graph Winter 2025-2026 newsletter issue is out!
The Ontology issue: From knowledge to graphs and back again 👇
yearofthegraph.xyz/newslette…
All things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech.
Subscribe and follow to be in the know. Reach out if you'd like to be featured
1
9
49
2,486

Feb 18
🗺️ The Graph Analytics market is heading toward $9.5B by 2032 - but can you navigate it?
Graph technology has evolved from a niche curiosity to a multi-billion dollar market, and it's accelerating fast with AI.
But for engineers, data scientists, architects, and technology leaders, the tooling landscape can feel overwhelming and fragmented.
That's exactly why we built The State of Graph: a comprehensive, structured repository, visualization, and analysis of the entire graph technology space.
Today, we're sharing the first of 7 categories: 🔍 Graph Analytics
Graph analytics uncovers patterns in connected data powering use cases like:
→ Fraud detection & network security
→ Risk propagation & anomaly detection
→ Community analysis & influence mapping
→ BI, retail, and social networks
📊 The numbers speak for themselves: $2.41B in 2025 → $9.49B by 2032 (21.61% CAGR)
This catalog is built for those who are choosing, building, or evaluating graph analytics tools.
Not just listing everything, but mapping how frameworks, libraries, and platforms align with real-world constraints. We limit inclusion to tools where graph algorithms are core functionality, not afterthoughts.
This project started as a hallway conversation at Connected Data London 2024, and has been a labor of love throughout 2025 with Maya Natarajan and Anisha Mane. We debuted it live at @Connected_Data London 2025, and now it's yours to explore.
👉 Check out the Graph Analytics Catalog v.1: stateofthegraph.com/2026/02/…
Do you have questions, feedback, or want help navigating it? Reach out - we'd love to hear from you.
#GraphAnalytics #GraphTechnology #DataScience #ConnectedData #NetworkAnalysis #FraudDetection #AIInfrastructure #DataEngineering #TechTrends #EmergingTech #Analytics #Algorithms
2
99

Employees shouldn’t juggle systems for simple answers.
Connected data drives faster, smarter decisions.
At Cymetrix, we build a strong Data 360 foundation for seamless data flow.
Learn more: cymetrixsoft.com/services/sa…
.
.
#DigitalTransformation #ConnectedData #Cymetrix #Wondrlab

2
12

Jan 21
Business intelligence only works when it’s connected to the source of truth. Accounting systems and analytics shouldn’t live in separate worlds.
bit.ly/4qYRoJN
#ConnectedData #Gravity #AccountingTechnology
1
6
411
18 Dec 2025
🎄 Keep the Connected Data insights flowing this festive season!
Secure your 2025 All Access Pass today and gain immediate access to all 2025 recordings plus complimentary access to Connected Data 2024.
Attendees described Connected Data London 2025 as uniquely different from every other event they have attended, with real value in every single session.
It is the perfect way to catch up on key insights, panels and masterclasses you missed and explore two years of Connected Data content at your own pace.
This offer is available for a limited time only, so do not miss out.
Sign up for the 2025 recordings here ➡️ sbee.link/p3u8x94ryt
Once your pass is confirmed, your access code to the 2024 recordings will be shared with you.
#ConnectedData #CDL25 #CDL24 #DataCommunity #AI #Analytics #FestiveOffer

2
101

2 Dec 2025
We loved this recap from Robin Osagie at #ConnectedData London.
Across industries, the challenge is the same: fragmented data siloed processes.
Bringing meaning to data unlocks real engineering AI impact
👉 bit.ly/487S7R4
NumoData Partner | #CDL25 @ConnectedData
11
13
562

26 Nov 2025
TechMode loved being on the ground with NumoData at #ConnectedData London, where Xanthos Angelides broke down the Semantic Digital Twin with real clarity - from data silos to end-to-end network meaning.
Learn more👉 bit.ly/487S7R4
NumoData Partner #CDL25 @ConnectedData
8
13
479
21 Nov 2025
Knowledge graphs and semantics? We know all about those thanks to the sessions hosted by Torsten Jedicke (Digital Transformation Manager, @VodafoneUK ), Robin Osagie (Business Development Manager, NumoData), Kevin Phillips (Senior Neptune Specialist Solutions Architect @awscloud ), Charles Ivie (Senior Graph Architect, @awscloud), Alex Heald (AI Engineer, Tomoro) and Douglas Adams (AI Engineer, Tomoro) 📱💻📈
Here, these experts discussed knowledge graphs, semantics and how these can be applied through real-world examples👏👏
#CDL25 #AI #ConnectedData



2
117