
Jun 11
Knowledge Graphs as the Missing Data Layer for LLM-Based Industrial Asset Operations
How much does the data model behind the tools matter?
Industrial asset management generates vast quantities of structured data: sensor telemetry, work orders, failure mode analyses, equipment hierarchies, and maintenance schedules. The rise of Large Language Models (LLMs) has prompted efforts to build autonomous agents that can reason over this data—answering operational questions, predicting failures, and recommending maintenance actions.
LLM-based agents for industrial asset operations show limited accuracy when reasoning over flat document stores. AssetOpsBench provides the first systematic evaluation of such agents, benchmarking seven contemporary LLMs across 141 expert-curated maintenance scenarios. It establishes that GPT-4 agents achieve 65% on 139 industrial maintenance scenarios, and compares LLM orchestration paradigms (Agent-As-Tool vs. Plan-Execute) on a fixed data layer.
This approach from Samyama transforms the AssetOpsBench data sources into a typed knowledge graph using an 8-step ETL pipeline and treats a typed knowledge graph as a grounding substrate, routing each question by how it is best answered:
(i) LLM-generated Cypher for structured retrieval, which lifts the same GPT-4 model from 65% to 82-83%;
(ii) native graph and optimization primitives, with no LLM, reaching 99% on graph-answerable scenarios; and
(iii) generation-augmented knowledge (GAK) for answers absent from the data -- the engine's agent materializes the missing facts as provenance-tagged graph nodes, then answers.
A recurring theme is inverted LLM usage: constraining the LLM to query generation or one-shot enrichment from a typed schema and letting the graph execute deterministically.
On the 88 real AssetOpsBench failure-mode scenarios the benchmark itself flags non-deterministic -- ten equipment types absent from the graph -- GAK lifts answerability from zero to 100% of equipment types and answers 81.8% of scenarios, every materialized fact tagged source:LLM-derived for auditability. This work also contributes 40 graph-native scenarios.
For structured operational domains the data layer -- not the LLM orchestration -- is the primary lever, and a typed knowledge graph serves as a grounding substrate between raw industrial data and LLM reasoning.
By Madhulatha Mandarapu, Sandeep Kunkunuru
arxiv.org/abs/2605.26874
#LLM #EmergingTech #AssetManagement #Research #Innovation #DataEngineering #KnowledgeEngineering
--
💬 ‘A great newsletter’ - Claudia Remlinger, former Sr. Marketing Director, Neo4j.
Join readers from Amazon, Capgemini, Michelin, Neo4j & more
Subscribe to the Year of the Graph newsletter for quarterly updates and insights on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech 👇
yearofthegraph.xyz/newslette…

1
8
293

May 26
Ontologist / Knowledge Engineer / Knowledge Graph Engineer - Via Ex-Amazonians
What does it actually mean to work as an Ontologist or Knowledge Engineer? A detailed job description - built with input from practitioners who've done the work at Amazon - breaks it down clearly.
The role sits at the intersection of data, semantics, AI, and business understanding. It combines ontology development, knowledge graph design, semantic modeling, data integration, and stakeholder communication. In practice it can range from highly conceptual ontology architecture to hands-on pipelines, graph queries, and system design.
The title varies. You might see: Ontologist, Knowledge Engineer, Knowledge Graph Engineer, Semantic Layer Specialist, or simply Data Engineer. Many organizations use overlapping or imperfect titles, especially when ontology work is embedded inside larger data or AI teams.
Core responsibilities include:
Defining concepts, entities, relationships, and semantic structures
Building and maintaining knowledge graphs
Connecting datasets with inconsistent schemas or terminology
Supporting AI, search, recommendation, and question-answering systems
Translating business concepts into machine-readable models
Facilitating conversations between departments with conflicting terminology
Key skills span three areas:
Knowledge Engineering: identifying reliable data sources, writing mappings between data sources and ontologies, developing consistency and reasoning engines, writing graph queries (SPARQL, Cypher, TKQL), handling linguistic ambiguities, regression and progression testing, creating data visualization templates.
Ontology Work: scoping use cases and competency questions, gathering SME input, modeling and extending ontologies, writing inference rules and reasoning logic, improving guidelines and naming conventions, internationalizing ontologies.
Data Engineering: ETL pipeline development, knowledge graph performance metrics, data integration across formats and schemas.
A typical day might include meeting with stakeholders to clarify terminology, designing ontology structures, mapping incoming datasets into a graph model, writing design documents, and educating internal teams about semantic layers.
Key personal traits: highly organized, comfortable with ambiguity, patient communicator, able to balance idealism with practicality.
By Ashleigh Faith, Beth Homes and Christelle Maignan (Ex-Amazonians)
youtube.com/watch?v=Sdh3wFbo…
#KnowledgeEngineering #Ontology #SemanticModeling #DataEngineering #EnterpriseAI
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

1
7
344
May 13
Do You Need An Upper Ontology?
Picture a reasonably sharp engineer. They've been told to build an ontology. They've installed Protégé, loaded BFO, and are now staring at Continuant and Occurrent, wondering what any of this has to do with their product catalogue or supply chain graph.
This is not a failure of intelligence. It is a failure of framing.
Kurt Cagle makes a pointed case: for most projects, you do not need an upper ontology. Choosing one without understanding what you are actually buying into may make your problem significantly worse.
Why? Because an upper ontology is not a neutral foundation. It is a methodology in disguise -- encoding specific philosophical commitments about what kinds of things exist, how change is modelled, and how relationships are typed.
The argument cuts deep in several directions:
Every extension is a fork. The moment you create a new class or property specific to your domain, you have amended the contract. And you will always fork it.
Most organisations that claim to use OWL do not, in any meaningful sense, use the reasoner. What they actually have is a knowledge graph with some rdf:type declarations -- a UML diagram that happens to serialise to Turtle. SHACL handles everything most teams are actually doing, with explicit operational semantics.
The bootstrapping argument is now broken. It is now possible to generate a robust domain ontology -- including SHACL shapes, property definitions, and class hierarchies -- in hours, not months. The "free partial model" an upper ontology provides is no longer saving you time. It may be costing you fit.
And for AI systems specifically: most upper ontologies were not built with reification as a first-class concern. RDF-Star changes the epistemic unit from a triple to a contextualised, provenance-bearing claim. Named graphs dissolve the open/closed world binary by making world assumptions local to a graph context. Frameworks designed before these primitives were serious may actively obstruct the modelling patterns that AI systems require.
The actual question is not which upper ontology to choose. It is: what problem are you solving, and at what scope?
Upper ontologies are not wrong. They are answers to a specific question. Most organisations, most of the time, are not asking that question -- they have simply been told that they should be.
ontologist.substack.com/p/do…
#Ontology #KnowledgeEngineering #SemanticWeb #RDF #SHACL
--
Connected Data London 2026 has been announced! 11-12 November, Leonardo Royal Hotel London Tower Bridge
📝 connected-data.london/post/c…
Join us for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
🎟 Ticket sales are open. Benefit from early bird prices with discounts up to 30%. 2026.connected-data.london
📺 Sponsorship opportunities are available. Maximize your exposure with early onboarding. Contact us at info@connected-data.london for more.

4
152
May 12
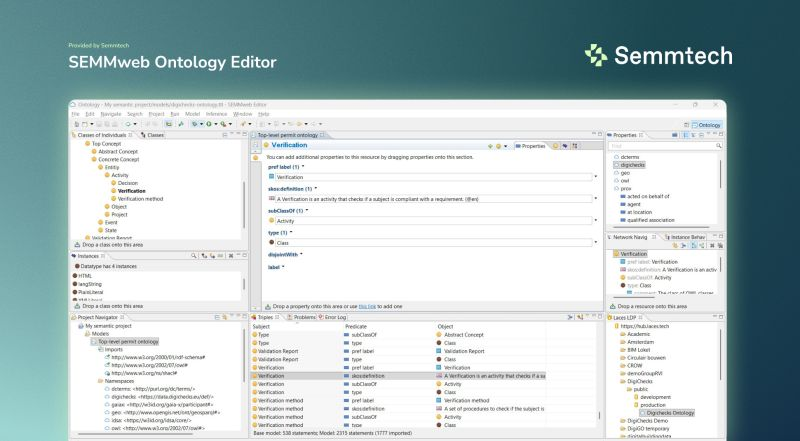
SEMMweb: A new open source Ontology Editor
Ten years ago, Semmtech built a tool for their own daily work. As early practitioners in Linked Data, they needed a way to work directly with ontologies - precise, structured, and aligned with standards like RDFS and OWL.
That is how the SEMMweb Ontology Editor came to be.
Now they're sharing it with the public. The goal: make Linked Data, Knowledge Graphs and Ontologies easier to work with.
The SEMMweb Ontology Editor is a Windows desktop application that allows users to create, view, edit, import, and publish ontologies according to Linked Data principles.
Multiple windows assist the user in understanding the contents of an ontology (or indeed of imported ontologies) and to add new data in the form of statements (or triples).
This tool has been designed with data professionals in mind (e.g., ontologists, Linked Data engineers, Semantic Web specialists, researchers and academic users), although other users may well find it a valuable tool too.
The various views available are designed to present the data in as understandable a manner possible for any given ontology. Addtionally, drag-and-drop functionality between the various windows simplifies the process of making additions. Supported file formats for ontologies are .ttl, .owl, .rdf, .nt, .n3.
Whether you are a seasoned Knowledge Graph architect or a data analyst just starting out, this tool offers a solid foundation to:
📌 Learn Linked Data concepts through practical experience
📌 Explore the use of semantic technologies
📌 Keep Linked Data vocabularies and ontologies at your fingertips
And for those who need to lower the technical barrier for domain experts, they also developed user-friendly applications that hide this complexity - such as the Laces Ontology Manager.
Show&Tell: How to Use the Semmweb Ontology Editor. May 19 Webinar: watch.getcontrast.io/registe…
Github: github.com/semmtech/semmweb-…
#LinkedData #Ontology #SemanticWeb #OWL #KnowledgeEngineering #OpenSource
--
🤝 Put your graph tech brand in front of the people who matter
Your graph technology deserves to be seen by buyers, analysts, and builders who are actively shaping the space.
The Year of the Graph is the independent hub that this community trusts.
Slots for the upcoming Summer 2026 Issue are filling fast. Reach out and book yours now 👇
yearofthegraph.xyz/contact/
1
5
12
780
What is an Ontologist or Knowledge Engineer, and how do you become one?
Some job titles still make people pause. Ontologist. Knowledge Engineer. Semantic Data Engineer. What do these roles actually involve?
At the core, this is about operating at the intersection of data, meaning, and systems -- designing, implementing, and operationalizing semantic models and knowledge graphs that power search, analytics, and AI-driven applications.
Think of it as bridging the gap between data engineering, information architecture, and domain expertise. The goal: organizational knowledge that is machine-readable, consistent, and aligned across teams.
Key responsibilities span a wide range:
* Designing and maintaining ontologies and semantic data models
* Facilitating knowledge extraction from domain experts and translating it into shared definitions
* Building and maintaining knowledge graphs from structured and unstructured data
* Integrating graph data with APIs, search systems, and downstream applications
* Supporting semantic search, entity resolution, recommendation systems, and AI/ML use cases
* Educating and guiding teams transitioning from relational to graph-based thinking
On the technical side, the role typically calls for experience with RDF, OWL, SKOS or property graphs, query languages like SPARQL or Cypher, and programming in Python. Backgrounds in Information Science, Linguistics, Computer Science, or Philosophy are all viable paths in.
The role itself comes in variants.
An Ontologist leans into conceptual modeling and knowledge representation.
A Knowledge Engineer balances modeling with implementation.
A Semantic Data Engineer focuses on pipelines, infrastructure, and deployment.
In practice, strong candidates often span all three.
What does success look like?
Clear and consistent definitions across teams, knowledge graphs that serve real-world use cases, improved data quality and discoverability, and genuine collaboration between technical and non-technical stakeholders.
By Asheigh Faith, Katariina Kari and Veronika Heimsbakk.
youtu.be/227m9jGICps?utm_sou…
#Ontology #KnowledgeEngineering #SemanticWeb #KnowledgeGraphs #DataEngineering
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

5
185
The Semantic Web Never Shipped. Its Core Idea Just Did.
When you enter the world of the semantic web, you're quickly seduced by the promise: formal ontologies, reasoners able to automatically infer meaning, data interoperable across any system, a representation of reality that machines can truly understand.
After 5 years applying the Semantic Web stack to heavy industry, Karim Ounnoughi has some honest field notes: some core concepts are basically unusable at scale, while "secondary" features turned out to be the real life-savers.
The key reframe: OWL was never meant to be a runtime. It's a compiler. Its value isn't querying millions of triples at speed -- it's defining consistent logic aligned with domain knowledge, ensuring concepts don't contradict each other across different data schemas.
As Nicolas Figay puts it, drawing on 30 years of experience: "SQL or SPARQL stands at the implementation side, during the runtime, while OWL stands at the conceptual phase first." Skipping that conceptual layer "is the open door to miscommunication and errors."
So where did the original "Semantic" goal actually land? Karim's argument: LLMs won that bet. They made natural language machine-accessible in ways the Semantic Web never achieved in practice.
But Figay draws a sharp line here. LLMs reconcile people with natural language. They don't reconcile with machines and formal automata -- and in any domain requiring verification, validation, and accountability, that gap matters enormously. "This is not supported by LLMs, so we have to be very cautious."
The more optimistic synthesis: LLMs as an on-ramp to formal models, not a replacement for them. Computer-aided learning of modeling and ontology languages. Augmentation, not substitution.
This article is an honest synthesis of that journey. It's addressed to semantic web practitioners who know the technologies (RDF, OWL, SHACL, SPARQL) but who are asking the same questions: why are we doing all this, and what is actually worth the effort?
Covering everything from the OWL reasoning performance wall, to the rdfs:domain trap, to what actually still stands after years in production.
By Karim Ounnoughi.
The Semantic Web Never Shipped. Its Core Idea Just Did. medium.com/@ounnoughikarim/t…
#SemanticWeb #OWL #Ontology #KnowledgeEngineering #EnterpriseData
--
Connected Data London 2026 | 11–12 November | Leonardo Royal Hotel London Tower Bridge
🎤 Share your work with the world's most passionate data community. The Call for Submissions is open. connected-data.london/2026-c…
🎟 Tickets on sale now. Early bird discounts up to 30%. 2026.connected-data.london?u…
📺 Sponsorship opportunities available. Contact info@connected-data.london for details.
#KnowledgeGraph #GraphRAG #Ontology #Graph #AI #DataScience #GraphDB #SemTech

3
153

Apr 23
The AI gold rush is in full swing — more GPUs, bigger reasoning models, more “agentic” hype. But there’s a silent crisis no one wants to talk about: the Meaning Gap.
x.com/EmekaOkoye/status/2047…
#ai #KnowledgeGraphs #AgenticAI #SemanticLayer #ContextEngineering #Ontology #DataStrategy #AIReadiness #KnowledgeEngineering #InstitutionalMemory #SemanticWeb

2
147
Semantica v0.4.0: Temporal intelligence and Agentic AI
Semantica is a framework for building context graphs and decision intelligence systems with explainability and provenance.
It transforms AI agents from black boxes into trustworthy, auditable systems by providing structured knowledge representation, complete decision tracking, and end-to-end lineage. Perfect for high-stakes domains where every answer must be traceable: healthcare, finance, legal, cybersecurity, and government.
🕐 Temporal Intelligence Bi-temporal model baked into the core — valid time transaction time on everything. Query your graph at any point in history. Full Allen interval algebra — deterministic, zero LLM calls. Extract temporal metadata from text with calibrated confidence scores.
🤖 Agentic AI with Agno Graph-backed persistent agent memory. Multi-hop GraphRAG for agent knowledge retrieval. Decision-intelligence & KG pipeline toolkits agents can call natively. Shared memory across entire agent teams, role-scoped.
🧠 Datalog-Style Reasoning Recursive Horn clause rules — ancestor(X,Y) :- parent(X,Z), ancestor(Z,Y). Handles transitivity & self-joins that loop forward/backward engines indefinitely. O(1) delta-index — re-evaluates only what changed.
🔌 Novita AI Provider create_provider("novita") — OpenAI-compatible, plug-and-play. Default: deepseek/deepseek-v3.2, configure via NOVITA_API_KEY.
🔍 Knowledge Explorer API 20 REST endpoints — graph traversal, analytics, decisions, SPARQL export. SKOS vocabulary browsing RDF/OWL import. WebSocket real-time progress · launch with one command.
✅ Ontology & Validation SHACL shape generation — zero hand-authoring, three quality tiers. Cross-ontology alignment structured diff with breaking-change classification.
🗂️ Named Graph Support Correct FROM / FROM NAMED clause handling in query execution. Graph URI percent-encoding, default_graph_uri alias.
⚡ Under the Hood O(N) → O(limit) pagination — no more 502s on large graphs. Full RLock thread safety across all graph paths. 6 CodeQL security findings resolved. 886 tests passing. 0 failures.
By Mohd Kaif
Semantica v0.4.0 — Release Notes github.com/Hawksight-AI/sema…
#SemanticWeb #TemporalReasoning #MultiAgentSystems #KnowledgeEngineering #OpenSource
--
📩 The Year of the Graph Spring 2026 newsletter issue is out!
Beyond Context Graphs: How Ontology, Semantics, and Knowledge Graphs Define Context 👇
yearofthegraph.xyz/newslette…
All things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech.
Subscribe and follow to be in the know. Reach out if you'd like to be featured

1
11
48
2,003
Mar 25
An introduction to Knowledge Engineering
How does human expertise become something an AI system can actually reason with?
That question sits at the heart of knowledge management, and it has never been more timely. As AI adoption accelerates, the gap between what experts know and what systems can reliably do is where projects succeed or fail.
Knowledge engineering is the discipline that bridges that gap. It is older than the current AI wave -- Feigenbaum and McCorduck were writing about it in the 1980s -- but it is more relevant than ever. Turning policies, documentation, and expert judgment into structured, auditable, explainable reasoning is not a solved problem. It is daily work.
This is not new territory. The Semantic Web pioneers understood it. Enterprise knowledge management has wrestled with it for decades. What is new is the context: as more organizations deploy AI in high-consequence domains -- tax, law, healthcare, financial services -- the question of whether a system reasons correctly, and whether you can explain why, is more urgent today.
Knowledge graphs give AI systems the structured, semantically rich foundation they need to reason beyond pattern matching. Ontologies define the concepts, relationships, and constraints that make that reasoning coherent and domain-faithful. Data modeling determines whether expert knowledge survives the translation into something a machine can use.
@RainbirdAI co-founder and CTO Ben Taylor is hosting a free five-part live webinar series alongside Rainbird's Knowledge Engineering team to open up exactly this conversation -- from first principles through to live build.
Over five sessions starting 25 March, the series covers:
-- What knowledge engineering is and how it connects to knowledge graphs and ontology design
-- Knowledge elicitation: surfacing the tacit expertise that never makes it into documentation
-- Building knowledge graphs that are scalable, testable, and maintainable
-- What the work actually looks like in practice
-- A live demonstration: eliciting from source documents, building a knowledge graph, running tests
No programming background required. Curiosity is the only prerequisite.
rainbird.ai/rainbird-communi…
#KnowledgeEngineering #Ontology #DataModeling #ExplainableAI
--
📩 The Year of the Graph Spring 2026 newsletter issue is out!
Beyond Context Graphs: How Ontology, Semantics, and Knowledge Graphs Define Context 👇
yearofthegraph.xyz/newslette…
All things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech.
Subscribe and follow to be in the know. Reach out if you'd like to be featured

3
26
779
Jan 26
SPARQL for SQL Developers: A Translation Guide
Getting started with SPARQL for knowledge engineering
There are plenty of roles in action in any AI project. And their focus areas and toolbox are changing and expanding.
Veronika Heimsbakk shares a practical approach on how data engineers can work as knowledge engineers with little or no knowledge of knowledge graphs in a series of articles.
In this article she focuses on explaining SPARQL to people who are familiar with SQL.
Many of the concepts in SQL translate directly to SPARQL. Both languages share fundamentals as filters, sorting, grouping, and joining data from multiple sources.
The key difference lies in how we think about data. While SQL operates on tables with predefined schemas, SPARQL navigates through a graph of interconnected resources.
Instead of explicitly declaring joins between tables, we describe patterns of relationships, and SPARQL finds the matches.
From Data Engineering to Knowledge Engineering in the blink of an eye veronahe.substack.com/p/from…
Data Engineering Ontologies veronahe.substack.com/p/data…
A few elementary pieces on logic veronahe.substack.com/p/a-fe…
SPARQL for SQL Developers: A Translation Guide veronahe.substack.com/p/spar…
Mastering maplib - a groundbreaking RDF framework for Python 2025.connected-data.london/t…
#DataEngineering #Tutorial #SQL #KnowledgeEngineering #SPARQL
--
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: lnkd.in/dbGCHruY
📩 Join the community: lnkd.in/d_BxVbhZ
Join community legends and new voices in #CDL25 for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology

1
4
141
Jan 21
Semantica: An Open Source Semantic Layer & Knowledge Engineering Framework
Semantica bridges the gap between raw data chaos and AI-ready knowledge. It's a semantic intelligence platform that transforms unstructured data into structured, queryable knowledge graphs powering GraphRAG, AI agents, and multi-agent systems.
Semantica claims to understand semantic relationships across all content, provide automated ontology generation, and build a unified semantic layer with production-grade QA.
github.com/Hawksight-AI/sema…
v0.2.3 was just released, moving Semantica closer to a true end-to-end document → graph → insight workflow:
⚡ High-performance vector ingestion with parallel embeddings
🕸️ AWS Neptune integration with a complete dev setup and notebooks
🧠 More reliable LLM-based entity & relation extraction for production knowledge graphs
📓 Jupyter-friendly pipelines for long-running and large document analysis with Docling Parser
📘 Also features a new end-to-end notebook (Google Colab ready)
A full Earnings Call Analysis pipeline using Docling Semantica AWS Neptune:
* Parse complex financial documents (tables, layouts, transcripts) with Docling
* Normalize, extract, deduplicate, and validate entities & relationships with Semantica
* Persist and query the knowledge graph in Amazon Neptune
* Use GraphRAG for hybrid retrieval and grounded strategic Q&A
colab.research.google.com/dr…
#OpenSource #GraphRAG #LLMs #GenerativeAI #AIEngineering #DataEngineering #KnowledgeEngineering #EmergingTech
--
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: 2025.connected-data.london/
📩 Join the community: connected-data.london
Join community legends and new voices in #CDL25 for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
2
1
8
1,099


29 Dec 2025
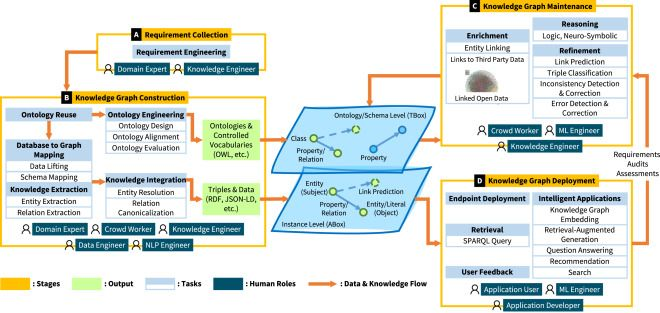
Knowledge prompting: How knowledge engineers use generative AI
Knowledge engineering is all about building and maintaining knowledge-based systems, often through knowledge graphs, and LLMs are opening up new possibilities for making this process faster and smarter.
KE has used NLP demonstrating notable advantages in knowledge-intensive tasks, but the most effective use of generative AI to support knowledge engineers across the KE activities is still in its infancy.
To explore how generative AI may enhance KE and change existing KE practices, a multi-method study was conducted during a KE hackathon.
The hackathon served as a way to bring the community together, share ideas and make progress quickly.
Observations from the event were combined with interviews afterwards to understand what works, what doesn’t, and what people really need.
Researchers investigated participants’ views on the use of generative AI, the challenges they face, the skills they may need to integrate generative AI into their practices, and how they use generative AI responsibly.
They found participants felt LLMs could indeed contribute to improving efficiency when engineering KGs, but presented increased challenges around the already complex issues of evaluating KE task success.
Prompting was assessed as a useful but undervalued skill for knowledge engineers working with LLMs; NLP skills may become more relevant across more roles in KE workflows.
Integrating generative AI into KE tasks needs to be done with awareness of potential risks and harms. Given the limited ethical training most knowledge engineers receive, solutions such as the proposed ‘KG Cards’ based on Data Cards could be a useful guide for KG construction.
Findings can support designers of KE AI copilots, KE researchers, and practitioners using advanced AI to develop trustworthy applications, propose new methodologies for KE and operate new technologies responsibly.
LLMs are great for things like knowledge acquisition and quick quality checks, but when it comes to complex scenarios, things get tricky.
New skills like prompt engineering and better ways to document the KG lifecycle and evaluate outputs are needed.
Copilot approaches, where humans and AI work side by side could be the way forward.
sciencedirect.com/science/ar…
#Research #KnowledgeEngineering #LLMs #GenAI
--
Connected Data London 2025 brought together leaders and innovators. Were you there?
🎥 Watch the sessions: 2025.connected-data.london/
📩 Join the community: connected-data.london
4
222
30 Oct 2025
Semantic Modeling Guidelines for Knowledge Engineers
Semantic modeling provides a structured way to represent knowledge, enabling systems to understand and process data with meaningful connections. Whether you're organizing business concepts, structuring domain knowledge, or preparing data for AI applications, a well-designed semantic model ensures clarity, consistency and interoperability.
These semantic modeling guidelines are designed for beginners as well as advanced modelers, offering a step-by-step introduction to semantic modeling concepts, key elements and practical techniques.
They start by explaining what semantic modeling is and how it helps, then explore the foundational building blocks: classes, attributes and relationships. As they progress, they show how to connect these elements into a meaningful ontology and refine it with hierarchical structures.
Finally, they outline essential methodology and design principles to help first-time modelers make informed decisions. The goal is that by the end of the first section, readers should have the foundational knowledge to start building their own semantic models with confidence.
As semantic models grow in complexity and scale, structuring them effectively requires careful planning, adherence to best practices, and an awareness of existing methodologies. While foundational knowledge of semantic modeling provides a strong start, building high-quality, maintainable ontologies demands a more strategic approach.
The advanced section in the semantic modeling guidelines is designed for practitioners who already understand the basics but seek to refine their skills, adopt industry standards, and make informed modeling decisions.
This section covers essential methodology and design principles and walks through the key stages of advanced ontology development: from clearly specifying scope and use cases, to implementing and refining the model, to documenting, publishing, and managing its evolution and versions over time.
Whether you're an experienced knowledge graph engineer or an early practitioner looking to elevate your modeling expertise, this guide is designed to help you build more effective, interoperable and scalable ontologies.
bit.ly/47uVMIC
By metaphacts - come meet them at Connected Data London 2025!
#Tutorial #DataModeling #KnowledgeEngineering #Guidelines
--
Connected Data London 2025 is coming! 20-21 November, Leonardo Royal Hotel London Tower Bridge
Join community legends and new voices in #CDL25 for all things #KnowledgeGraph #Graph #analytics #datascience #AI #graphDB #SemTech #Ontology
👉 Discover more about the event and secure your place today: 2025.connected-data.london/
🤝 Want to partner with us on this year's event? Contact us at info@connected-data.london to discuss sponsorship opportunities
📩 Signup for our newsletter and be the first to know about news, special offers and important dates connected-data.london
2
137

11 Aug 2025
5/10
Expert Systems mimic human decision-making using rule-based logic. They’re used in diagnostics, legal analysis, and financial advising to provide consistent, knowledge-driven recommendations.
#ExpertSystems #AI #DecisionSupport #KnowledgeEngineering #SmartSolutions #Automation

2
56
73
294

The internet is chaos. Inflectiv is infrastructure.
Stop drowning in screenshots, forgotten threads, and scattered notes.
We’re building the layer where your context becomes structured, queryable fuel for AI.
This isn’t just organization—it’s ownership.
→ Join the Alpha: app.inflectiv.ai
#KnowledgeEngineering #StructuredAI #InflectivAlpha
28 Jul 2025

The internet is full of notes. Inflectiv turns them into systems.

5
14
116

2 Jun 2025
Join the conversation on how we can rigorously assess the capabilities of LMs in semantic technologies and structured knowledge generation. 📊🤖
#ELMKE2025 #LanguageModels #KnowledgeEngineering #Evaluation #SemanticWeb #AI #KnowledgeGraphs #LLMs #ESWC2025 #ResponsibleAI


3
160

20 Mar 2025
🌐 Can you revolutionize Knowledge Graphs? We’re seeking innovative approaches to automate construction of ontologies. Help transform how data is organized and used. Submit your solution today on bit.ly/43VAC67 💡
#KnowledgeGraphs #Ontology #AI #KnowledgeEngineering

2
126

20 Mar 2025
Can Prolog build a list from facts, or is it more likely to form a band and plan a world tour?" 🎸🎶
Source: devhubby.com/thread/how-to-c…
#ProgrammingLanguages #AI #KnowledgeEngineering #DataStructures #facts #prolog

1
5
27
