
11h

1

Compute and reasoning are all about GPUs and HBMs.
Jun 15

Chamath said a gigawatt data center used to cost ~$5B when he started his project but now runs closer to ~$100B fully loaded.
The jump is all about silicon density with $NVDA Rubin-class racks approaching 600kW and every gigawatt carrying far more GPU and HBM content.
32

Jun 14
Also important to note that with larger HBMs and ASICs you can no longer continue with this!! You need a bigger size which ll create warpage
2
235

What is the ultimate high value added mfg product from the Tungsten supply chain?
It seems to be latest 3D NAND & HBMs, which are in a super cycle. That feeds AI industry.
So holding back W export to Japan is a true natsec move since it allows China to move up value chain.
1
3
31
1,813

Jun 13
Wow...demand for HBMs "structurally" more predictable now

$MU, SK hynix, Samsung, $TSM
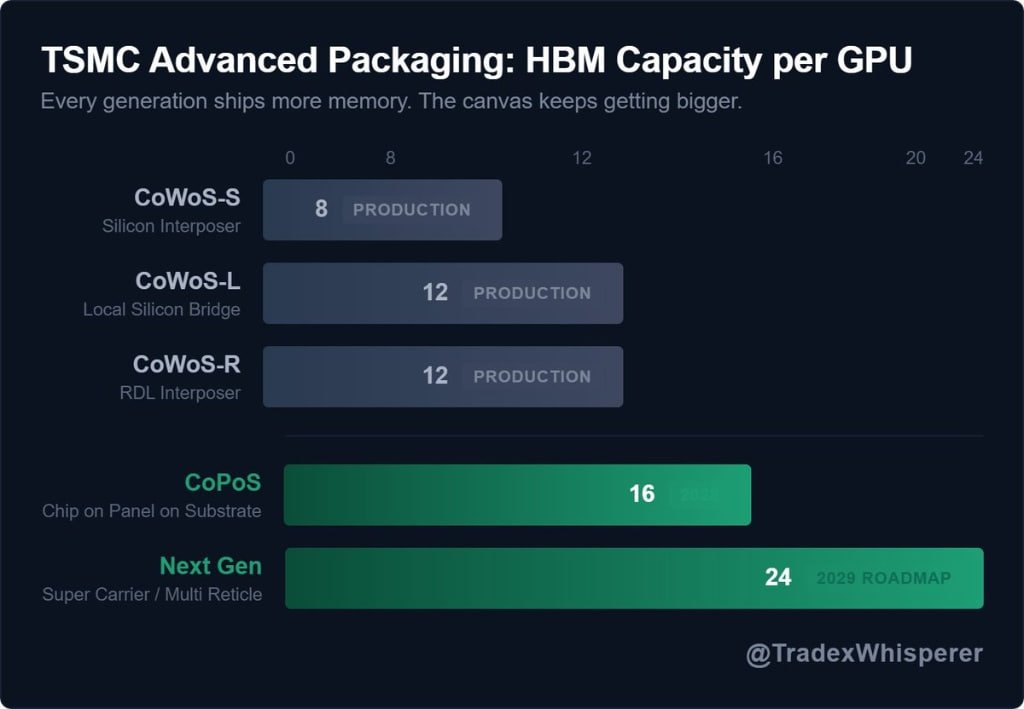
TSMC 첨단 패키징 로드맵: GPU당 HBM 용량 변화
CoWoS-S (Silicon Interposer): 현재 양산 중이며, GPU당 8개의 HBM 스택을 지원
CoWoS-L (Local Silicon Bridge): 현재 양산 중이며, GPU당 12개의 HBM 스택을 지원
CoWoS-R (RDL Interposer): 현재 양산 중이며, GPU당 12개의 HBM 스택을 지원
CoPoS (Chip on Panel on Substrate): 2028년 도입 예정이며, GPU당 16개의 HBM 스택을 지원.
Next Gen (Super Carrier / Multi Reticle): 2029년 로드맵에 포함되어 있으며, GPU당 최대 24개의 HBM 스택을 지원할 예정
핵심 의미
물리적 한계의 돌파: 과거에는 GPU 칩 하나에 메모리를 붙일 수 있는 공간(캔버스)이 제한되어 있었습니다. 하지만 TSMC는 'CoPoS'같은 차세대 패키징 기술을 통해 이 공간을 물리적으로 넓히는중
이는 본질적으로 전체 HBM 시장의 TAM을 지속적으로 키우는 동력
AI 시대의 메모리 사이클은 이전과 달리 지속적으로 팽창하는 구조적 성장 시장에 더 가까워질 수 있음
10

Jun 13
Doesn't matter there's a huge shortage atm. It can save DRAM but manufacturing is prioritising HBMs
117

silver.. project vault after 4 months still at getting up stage.. talk adn talk. Stockpile still Zero
Banksters clobberiing silver price adn yet talk of mineral floor price etc. Other countries are onto Mineral sovereignty
cld Terafab be just a pipe dream as elon has not secured his Silver?,
Without silver..no silver no chips.. no Nvdia chips not HBMs.. seriously??
21

Jun 9
What size of the die for 18A yields? What size of the package and how many compute dies and HBMs for the EMIB yields? Now 90% and tomorrow 95% and 98% two days later.
2
96


One of them will not and will buy more GPUs and HBMs to get ahead of other hyperscalers. The pricing power is here to stay. HBM is devouring DRAM wafers, there is none left for severs unless we expand.
10
1,066
As long as demand for intelligence is there, nothing else will matter. Demand will demand it and hyperscalers will have to provide one way another. If one of them gets more aggressive buying more GPUs/HBMs and the other one chickens out, it's game over for one of them and they won't become a Mag7 anymore.
Have you used Claude to build? It's pretty crazy where we're going.
1
3
244
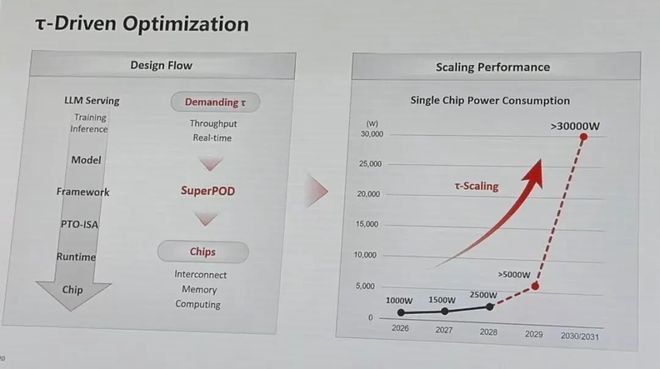
Tau Scaling slides:
AI chips (not necessarily Ascend) are heading to 30kW per chip thru advanced pkg
2.5D -> System folding lowers consumption by stacking NAND/DRAM/Logic/others on top of each other - instead of HBM next to AI chip.
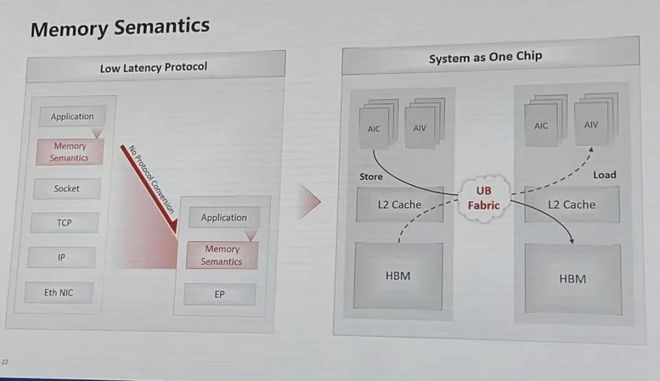
UB - NPU, CPU, MEM & DPU connect to UB Fabric w/ switch, NiC & OCS
Memory Semantics for this super chip - UB Fabric does store & load bw L2 Cache & HBM like single chip internal memory. You don't see HBM is from another chip.
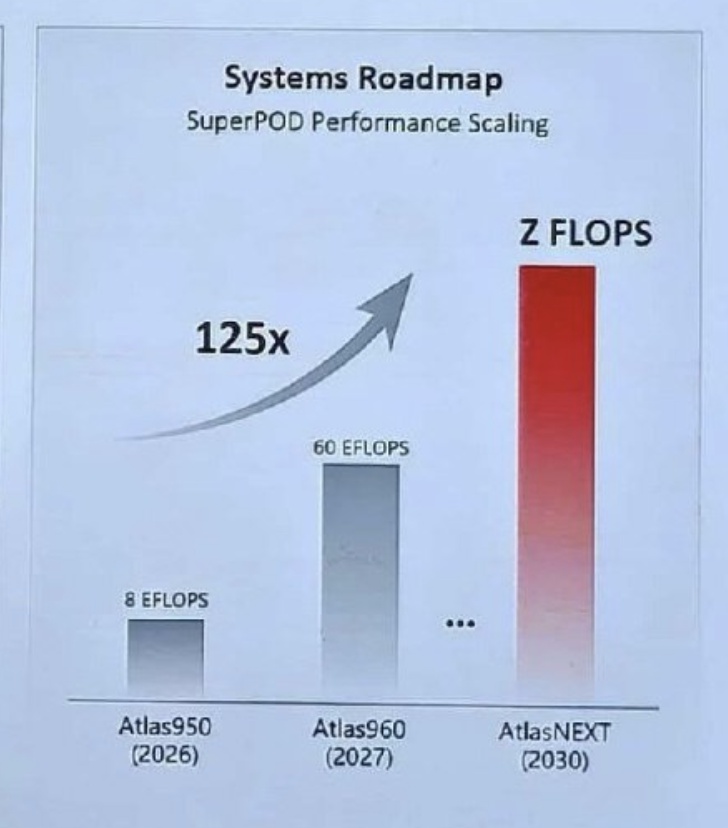
That's how HW gets to Z FLOPS - not thru packaging more AI dies together in 1 super chip like Rubin, but connecting more chips together in 1 Super Chip/PoD.
@teortaxesTex did ask about HBM, so it seems to me that HW itself is just buying DDR5 DRAMs & stacking them directly on its AI chip. Not sure if that's for Ascend-950DT or future Ascends, but its "HBM" is proprietary, so likely not using CXMT HBMs. It's doing own advanced packaging.
As for yield. It talked about achieving 100% yield thru "smart redundancies". I guess using its high end testing tools to detect defects on NPU dies & work around that.

5
13
89
5,076

Yup it was but do you know enterprises that use tokens and AI? If yes, then they have to use HBM. Each HBM replaces 4x Dram bits. Only 3 players are good at HBM it’s not your grandma’s HDD or Flash or Dram. Look up how to produce HBMs. Yes in 2028 or 2029 capacity would catch up to demand. But they are talking about 3-5 year LTAs at current prices which are driving 70% of $100 in EPS. So, while not 20x multiple, it’s also not cyclical - it’s in the middle. Also CPUs need enterprise grade DRAMs so double benefit for $MU starting 2H2026CY or their 1QFY27. We can only connect these dots by October
2
12
1,431

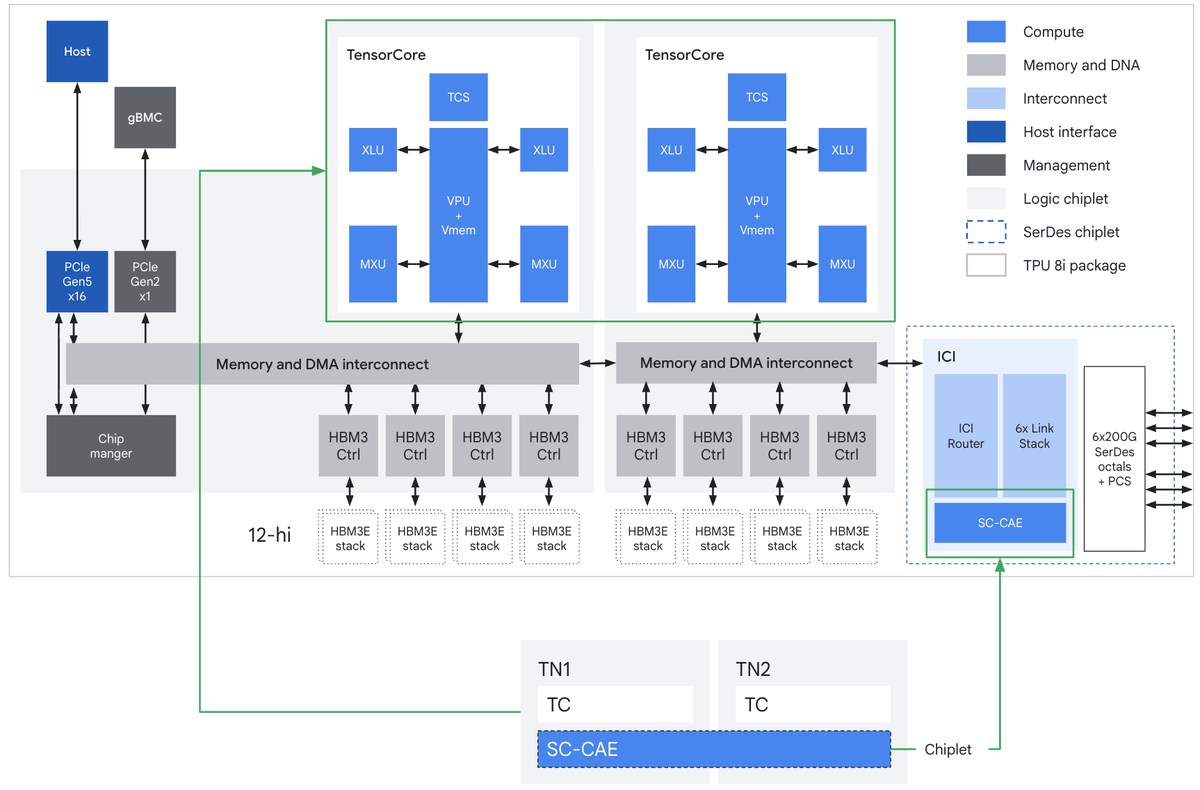
Just like we saw with NVIDIA, TPUs are offloading many phases of inference away from HBMs (TPU8i)
The clearest case is on the 8i (serving/inference) side. It carries 3x more on-chip SRAM than the previous generation, and the stated purpose is that TPU 8i can host a larger KV Cache entirely on silicon, significantly reducing the idle time of the cores during long-context decoding.
That's a direct HBM offload: in autoregressive decoding the KV cache is normally the dominant bandwidth consumer streaming out of HBM every token, so pulling it into Vmem (384 MB vs. 128 MB on the 8t per the spec table) takes that traffic off the HBM line entirely.
TPU 8t216 GB128 MB~1,700:1
TPU 8i288 GB384 MB~750:1
As models get larger and inference demands get tighter, SRAM and KV-cache residency.
Demand for HBM is still increasing, but the necessity of HBM in many phases is gradually decreasing. This allows us to focus on the long-term operating margin rather than simply volume sold.
1
2
35

\今年度初!参加者募集!/
HBMS・MBA説明会(HBMS概要説明、在学生・修了生Q&A、個別相談)を開催します!
皆様のお申し込みをお待ちしております!
開催日時:2026年7月15日(水)19:00~20:10
開催方法:オンライン(Zoom)開催
詳細・お申込みはこちら!⇒ mba.pu-hiroshima.ac.jp/ja/ev…
#MBA

3
56