
Feb 5
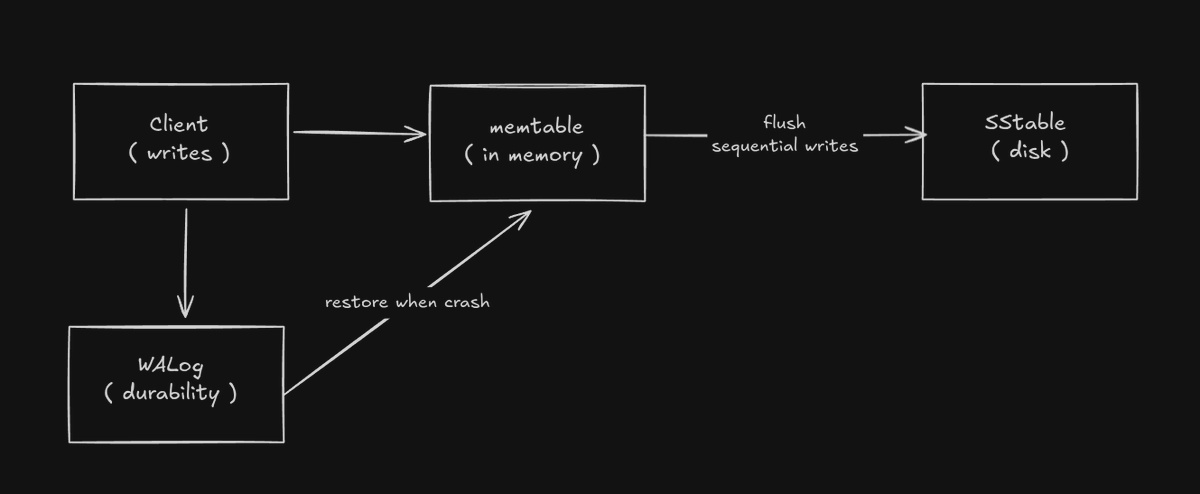
i m implementing a toy LSMTree based k-v store
no optimizations initially.
just
WAL -> memtable -> SSTable
3
157

Jan 19
We often think of a database as a single giant file on a hard drive that gets updated whenever we save data. But for write-heavy powerhouses like Cassandra, RocksDB, or LevelDB, that approach is too slow.
Enter the LSM Tree (Log-Structured Merge Tree).
The secret sauce of an LSM Tree is that it doesn’t force a choice between Memory and Disk - it uses both in a relay race to maximize speed.
Here is the lifecycle of a write in an LSM-based database:
1. The Landing Zone: Memory (MemTable) 🧠
When you write data, it doesn't touch the hard drive immediately (except for a sequential append to a commit log for recovery). Instead, it goes straight into RAM.
This structure is called a MemTable.
It is mutable (changeable).
It organizes data in a sorted structure (often a Red-Black Tree or Skip List).
Why? Writing to RAM is lightning fast.
2. The Freeze: Flushing to Disk (SSTable) ❄️
Eventually, the MemTable fills up. When it hits a certain threshold (e.g., 256MB), the database says, "Okay, let's save this."
The entire MemTable is flushed to the disk as a new file called an SSTable (Sorted String Table).
Crucial Detail: SSTables are Immutable. Once written, they can never be modified.
If you update a record, you aren't overwriting the old one. You are just writing a new entry with a newer timestamp in a new SSTable.
3. The Cleanup: Compaction 🧹
Over time, you end up with hundreds of SSTables on your disk. This makes reading slow (you have to check too many files).
To fix this, a background process called Compaction kicks in. It takes several smaller SSTables, merges them, discards old/deleted data, and writes out a new, larger sorted file.
💡 Why this architecture wins
The genius of the LSM tree is Sequential I/O.
Traditional databases (B-Trees) often require "Random I/O" (jumping around the disk to update specific pages). LSM Trees turn random write requests into sequential batch writes. It treats the disk like a tape recorder, always appending, rarely seeking.
Summary:
- Write to RAM (Fast).
- Flush sorted chunks to Disk (Immutable).
- Merge chunks later to save space.
Have you worked with LSM-based stores before? Do you prefer them over B-Tree based systems like Postgres/MySQL for your specific use cases? Let’s discuss in the comments! 👇
#SystemDesign #Database #Cassandra #Engineering #LSMTree #TechTips
1
1
4
88

20 Dec 2025
Storage Engines: LSM Trees vs. B-Trees 🌳
In Advanced HLD, your choice of database isn't about "SQL vs NoSQL" it's about the Storage Engine.
B-Trees (MySQL/Postgres): Update data "in-place." Excellent for Read-Heavy workloads. Suffer on massive write ingestion due to random I/O and page splitting.
LSM Trees (Cassandra/RocksDB): "Append-only" writes. Data is flushed to disk sequentially and merged later (Compaction). The king of Write-Heavy ingestion (Logs, IoT, Chat).
Rule: If you are building a system ingesting 100k events/sec, a B-Tree will likely choke. Choose an LSM-based store.
#DatabaseInternals #SystemDesign #LSMTree #Engineering #HLD
7
381

25 Sep 2025
كنت حابب اجرب حاجة بgolang ف بنيت lsmtree وعملتلها ديبلويمنت، ممكن تخزنوا عليها معلومات مهمة زي api keys و payment details، سكيور 100% من هنا:
curl lsmtree.alhadad.me/your-key
curl -X PUT lsmtree.alhadad.me/your-key -d "very-secure-data"
بس ياريت محدش يعمل ddos علشان السيرفر بفلوس
1
2
11
401

30 Jul 2025
💡 #DolphinDB’s TSDB engine—built on an optimized LSM-Tree—delivers high-throughput writes, fast queries, and efficient storage for real-time workloads like market data, logs, and IoT streams.
🔗: medium.com/@DolphinDB_Inc/ts… #TimeSeries #TSDB #BigData #Analytics #LSMTree #DataEngineering
📊 Struggling with massive time series data in traditional databases? Curious how it works under the hood? We break down:
- Storage architecture
- Indexing & compaction
- Write/read optimization
- CRUD behavior & deduplication
📩 Learn more about us: dolphindb.com/
#TimeSeries #TSDB #BigData #Analytics #LSMTree #DataEngineering
1
4
47

26 Oct 2024
1
60

26 Aug 2024
No; it uses ideas from several other papers and actually FASTER is one of them.
Many have tried to beat a heavily optimised BTree like AND an LSMTree like storage engine.
They make a radical change in the buffer manager/data structure and that seems to do the trick.
2
71


8 Nov 2022
Great talk by Subarna Chatterjee from @HarvardDASlab on COSINE, a self-designing #KeyValueStore for the Cloud! Check it out here: youtu.be/ECsVwbgsyxg
#CloudComputing #AI #ML #DataScience #DB #Database @Harvard #CornellDBseminar #StorageEngine #LSMtree

2
1
3

20 Sep 2022
Implementing data structures can help you power up your database. LSM-Trees are one of the known data structures when it comes to databases. Wondering how it works? Give this post a read!
harisbinsaif.com/blog/f/data…
#dataengineering #LSMTree #databases #datastructures
2
1
13



7 May 2022
Synecdoche is a figure of speech, not an IT definition. This would be like saying BTree, Heap table or LSMtree are databases. But:
storage tech < datastore < database < DBMS
SQL is an API for databases. NoSQL is often just a datastore. A storage technique is not a database
3
1 Dec 2021
Imagine that you want to stay compatible with a DB built for heap tables and btree PK, but where they are the same lsmtree object 😬
Oracle differenciated table and segment early, which made the dictionary compatible with partitions, index-organized tables... 👍
2
21 Nov 2021
A very clear talk by @ifesdjeen about modern storage access patterns in databases. #read/#write. #sequential/#random. #mutable/#immutable. #Btree/#LSMtree. youtu.be/wxcCHvQeZ-U
1
9
48

13 Jul 2021
昔mongodbというとデータがディスクに書き込まれた保証はなく、検索が早いというのもデータが全部メモリに乗るという大前提があり、マーケの上手なインチキDBという印象だったのだけど、wiredtiger LSMTreeだと本当に優位性のある製品になっているのだろうか。
1
1
