
✩⃛:.。 𝘌𝘷𝘦𝘳𝘺 𝘣𝘦𝘢𝘵 𝘰𝘧 𝘮𝘺 𝘩𝘦𝘢𝘳𝘵 𝘸𝘩𝘪𝘴𝘱𝘦𝘳𝘴 𝘺𝘰𝘶𝘳 𝘯𝘢𝘮𝘦, 𝘳𝘦𝘮𝘪𝘯𝘥𝘪𝘯𝘨 𝘮𝘦 𝘰𝘧 𝘵𝘩𝘦 𝘥𝘦𝘱𝘵𝘩 𝘰𝘧 𝘮𝘺 𝘭𝘰𝘷𝘦 𝘧𝘰𝘳 𝘺𝘰𝘶
© lowdata (crepe)

55
77
159
2,904

7 May 2025
Leveraging Protein Language Model Embeddings for Catalytic Turnover Prediction of Adenylate Kinase Orthologs in a Low-Data Regime
1. This study benchmarks the use of protein language model (PLM) embeddings for predicting catalytic turnover rates (kcat) across 175 diverse orthologs of Adenylate Kinase (ADK), demonstrating that PLM-based probing outperforms all traditional and specialized kcat prediction models.
2. The top-performing configuration used zero-shot ESMC-600M embeddings with a simple MLP probe, achieving RMSE of 0.473 and R² of 0.416, surpassing models like DLKcat and CatPred by large margins, particularly in this low-data, high-diversity setting.
3. Learnable aggregation techniques (e.g., Transformer-based attention layers) offered only marginal gains over fixed pooling strategies (e.g., min, mean), indicating that simple aggregation is often sufficient when using strong pretrained embeddings.
4. Surprisingly, fine-tuning PLMs with LoRA on relevant subspaces (e.g., ADK homologs or EC 2.7 enzymes) failed to improve kcat prediction performance and, in the case of direct fine-tuning, even degraded generalization due to overfitting.
5. The study also evaluated embeddings from all hidden layers of Ankh-base and found no consistent improvement over the final layer, with intermediate layers often requiring normalization due to exploding gradient issues.
6. Embeddings derived from PLMs consistently outperformed those from pseudo-one-hot encodings and BLOSUM62-optimized vectors, confirming that pretrained models capture deeper functional signals beyond primary sequence similarity.
7. A lid-type-aware cross-validation scheme ensured robustness by accounting for known structural determinants of ADK activity, preventing information leakage and improving the relevance of benchmarking in evolutionary diverse contexts.
8. The results emphasize that while PLMs enable significant gains in enzyme activity prediction, architectural overengineering or excessive fine-tuning can backfire in small or niche datasets, reinforcing the value of simple, zero-shot probing strategies.
9. This study provides a practical reference point for protein engineers, demonstrating that well-chosen embeddings and lightweight downstream models can rival or exceed complex kcat-specific architectures even with minimal labeled data.
10. As enzyme design increasingly adopts ML workflows, this work illustrates how to systematically evaluate PLMs for sequence-to-function modeling, and underscores the need for diverse, high-quality enzymology datasets.
💻Code: github.com/keiserlab/face-pl…
📜Paper: arxiv.org/abs/2505.03066
#ProteinEngineering #Enzymology #ProteinLanguageModels #kcat #DeepLearning #PLM #ESMC #LoRA #Bioinformatics #LowData #EnzymeDesign #ADK #SequenceToFunction #FacePLM

4
707
7 May 2025
Leveraging Protein Language Model Embeddings for Catalytic Turnover Prediction of Adenylate Kinase Orthologs in a Low-Data Regime
1. This study benchmarks the use of protein language model (PLM) embeddings for predicting catalytic turnover rates (kcat) across 175 diverse orthologs of Adenylate Kinase (ADK), demonstrating that PLM-based probing outperforms all traditional and specialized kcat prediction models.
2. The top-performing configuration used zero-shot ESMC-600M embeddings with a simple MLP probe, achieving RMSE of 0.473 and R² of 0.416, surpassing models like DLKcat and CatPred by large margins, particularly in this low-data, high-diversity setting.
3. Learnable aggregation techniques (e.g., Transformer-based attention layers) offered only marginal gains over fixed pooling strategies (e.g., min, mean), indicating that simple aggregation is often sufficient when using strong pretrained embeddings.
4. Surprisingly, fine-tuning PLMs with LoRA on relevant subspaces (e.g., ADK homologs or EC 2.7 enzymes) failed to improve kcat prediction performance and, in the case of direct fine-tuning, even degraded generalization due to overfitting.
5. The study also evaluated embeddings from all hidden layers of Ankh-base and found no consistent improvement over the final layer, with intermediate layers often requiring normalization due to exploding gradient issues.
6. Embeddings derived from PLMs consistently outperformed those from pseudo-one-hot encodings and BLOSUM62-optimized vectors, confirming that pretrained models capture deeper functional signals beyond primary sequence similarity.
7. A lid-type-aware cross-validation scheme ensured robustness by accounting for known structural determinants of ADK activity, preventing information leakage and improving the relevance of benchmarking in evolutionary diverse contexts.
8. The results emphasize that while PLMs enable significant gains in enzyme activity prediction, architectural overengineering or excessive fine-tuning can backfire in small or niche datasets, reinforcing the value of simple, zero-shot probing strategies.
9. This study provides a practical reference point for protein engineers, demonstrating that well-chosen embeddings and lightweight downstream models can rival or exceed complex kcat-specific architectures even with minimal labeled data.
10. As enzyme design increasingly adopts ML workflows, this work illustrates how to systematically evaluate PLMs for sequence-to-function modeling, and underscores the need for diverse, high-quality enzymology datasets.
💻Code: github.com/keiserlab/face-pl…
📜Paper: arxiv.org/abs/2505.03066
#ProteinEngineering #Enzymology #ProteinLanguageModels #kcat #DeepLearning #PLM #ESMC #LoRA #Bioinformatics #LowData #EnzymeDesign #ADK #SequenceToFunction #FacePLM

2
11
780

2 May 2025
Likelihood of No Data Access in Cybersecurity Scenarios
Below is an analysis of common cybersecurity incident scenarios, evaluating how realistic it is to claim that no data was accessed. Each scenario considers typical threat actor behavior and the feasibility of preventing data access.
1. Phishing Attack Leading to Credential Theft
Typical Behavior: Threat actors use stolen credentials to log into mailboxes or systems, often accessing data quickly.
Likelihood of No Data Access: Moderate to LowIf detected and credentials reset immediately, access might be prevented. However, threat actors often act fast, making some data access likely before containment.
Key Factors: Speed of detection and response.
2. Ransomware Infection via Exploit Kit
Typical Behavior: Many ransomware strains exfiltrate data before encrypting it, as part of a double-extortion strategy.
Likelihood of No Data Access: LowData access or theft is common before encryption occurs, even if backups remain intact.
Key Factors: Time between infection and encryption; presence of exfiltration tools.
3. Insider Threat with Data Exfiltration
Typical Behavior: Insiders may misuse legitimate access to exfiltrate data, which can be hard to detect quickly.
Likelihood of No Data Access: ModerateIf caught early, exfiltration might be prevented, but insiders’ authorized access complicates detection.
Key Factors: Monitoring and timing of intervention.
4. Supply Chain Compromise
Typical Behavior: Attackers exploit third-party vulnerabilities, potentially accessing data indirectly.
Likelihood of No Data Access: ModerateThe complexity of supply chain attacks makes data access possible, though not always immediate or evident.
Key Factors: Scope of compromise and investigation depth.
5. Advanced Persistent Threat (APT) with Lateral Movement
Typical Behavior: APTs are stealthy, often involving data reconnaissance over time.
Likelihood of No Data Access: Low to ModerateTheir persistence and sophistication make some data access likely, even if undetected initially.
Key Factors: Detection capabilities and attack duration.
6. DDoS Attack Targeting Critical Services
Typical Behavior: Focuses on disrupting service availability, not data access.
Likelihood of No Data Access: HighData compromise is not a primary goal, making access unlikely.
Key Factors: Attack type and intent.
7. Zero-Day Exploit Against Public-Facing Application
Typical Behavior: Exploits unknown vulnerabilities, potentially allowing rapid data access.
Likelihood of No Data Access: ModerateQuick isolation might prevent access, but success depends on response speed.
Key Factors: Response time and exploit severity.
8. Business Email Compromise (BEC)
Typical Behavior: Attackers use compromised email accounts to deceive users or access data.
Likelihood of No Data Access: ModerateEarly detection and account isolation can limit access, but swift action by attackers is common.
Key Factors: Detection speed and account privileges.
Conclusion
Your observation is spot-on: in phishing and ransomware scenarios, data access is particularly likely due to the nature of these attacks. While rapid response can reduce the risk, claiming "no data was accessed" is often optimistic without thorough evidence. Scenarios like DDoS attacks are exceptions where data access is unlikely, but for most others—especially phishing, ransomware, and APTs—some level of data compromise is plausible or even probable unless proven otherwise. Transparency about ongoing investigations is key to balancing reassurance with realism.
1
1
885
21 Apr 2025
Finding Drug Candidate Hits With a Hundred Samples: Ultra-low Data Screening With Active Learning
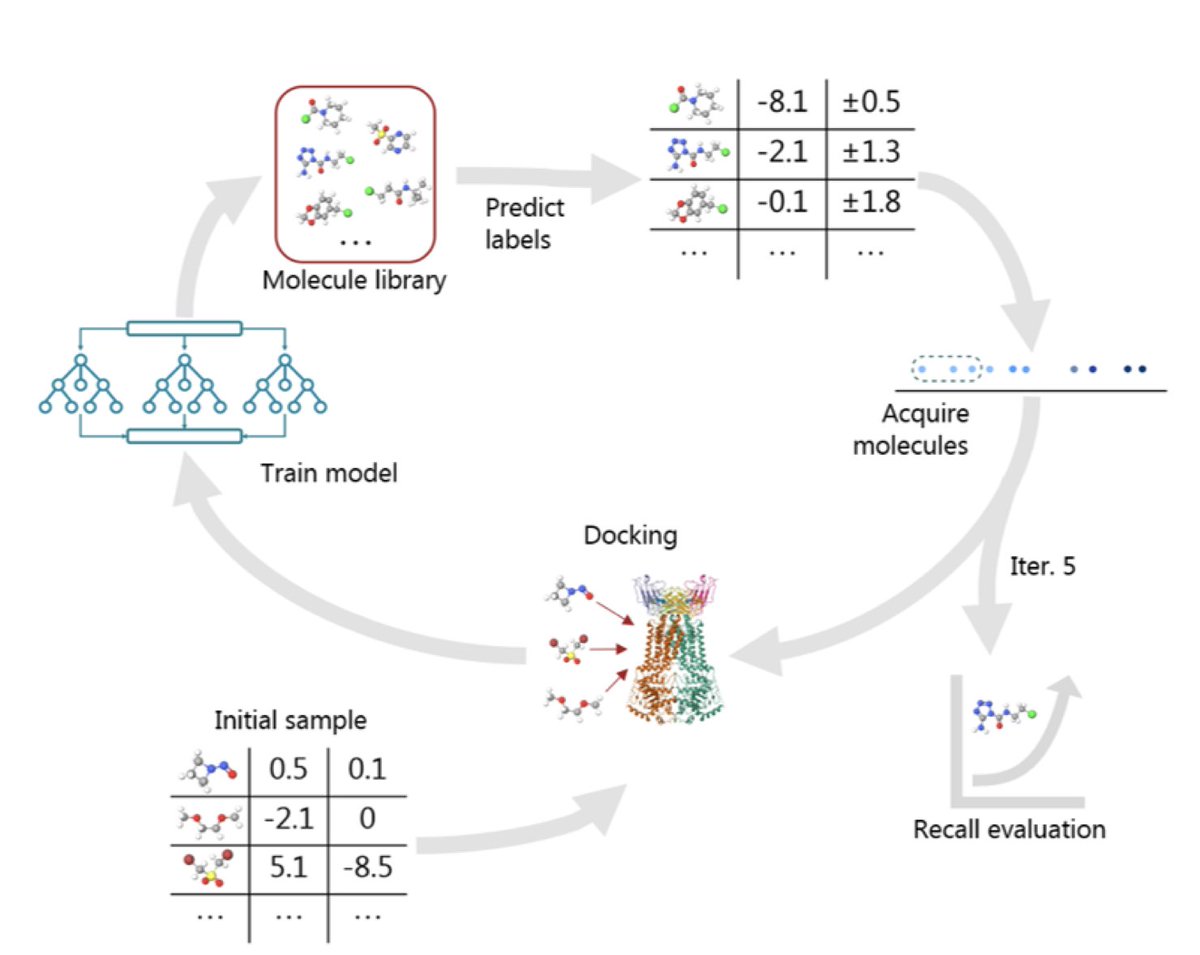
1. This study demonstrates that it's possible to reliably identify drug candidate hits using just 110 affinity evaluations, making active learning viable for academic labs with limited resources.
2. The authors identify a top-performing combination—Multi-Layer Perceptron (MLP) with Continuous and Data-Driven Descriptors (CDDD), enhanced by Pairwise Difference Regression (PADRE)—that achieves a 100% probability of finding at least five top-1% hits in a large chemical library.
3. PADRE plays a key role by augmenting data from as few as 10 initial molecules, dramatically boosting early-phase model performance and hit discovery rates, even under noisy or uncertain conditions.
4. Greedy, Expected Improvement (EI), and Upper Confidence Bound (UCB) acquisition strategies all outperform random selection, but greedy acquisition remains surprisingly effective and simple for ultra-low data regimes.
5. The study includes realistic noise simulations (10–30%) to mirror experimental variability, showing that robust setups (especially RF MQN PADRE) maintain strong hit discovery even under noisy conditions.
6. Enriching the initial pool with just one known active molecule (from the top 1% of docking scores) further improves the likelihood of success—raising the hit probability from 73% to 93% for the top model.
7. Even in the smaller Enamine DDS-10 library (~10k molecules), the pipeline remains reliable: top strategies still consistently discover 10 hits with 100% probability, showing the framework’s versatility across dataset sizes.
8. Key design choices—simple models (MLP, RF), expressive descriptors (CDDD, MQN), and thoughtful acquisition functions—enable efficient screening without the need for complex GNNs or large datasets.
9. These results emphasize that accurate prediction of weak binders early in the AL cycle is essential to steer the model toward potent candidates—especially when only a few hundred experiments are feasible.
10. Overall, this work offers a robust, practical blueprint for hit discovery in low-data settings, highlighting the power of combining thoughtful data representation, augmentation, and acquisition strategies.
💻Code: github.com/jensengroup/AL_pa…
📜Paper: doi.org/10.26434/chemrxiv-20…
#ActiveLearning #DrugDiscovery #LowData #Cheminformatics #MolecularScreening #AI4Science #ComputationalBiology
2
7
1,232
21 Apr 2025
Finding Drug Candidate Hits With a Hundred Samples: Ultra-low Data Screening With Active Learning
1. This study demonstrates that it's possible to reliably identify drug candidate hits using just 110 affinity evaluations, making active learning viable for academic labs with limited resources.
2. The authors identify a top-performing combination—Multi-Layer Perceptron (MLP) with Continuous and Data-Driven Descriptors (CDDD), enhanced by Pairwise Difference Regression (PADRE)—that achieves a 100% probability of finding at least five top-1% hits in a large chemical library.
3. PADRE plays a key role by augmenting data from as few as 10 initial molecules, dramatically boosting early-phase model performance and hit discovery rates, even under noisy or uncertain conditions.
4. Greedy, Expected Improvement (EI), and Upper Confidence Bound (UCB) acquisition strategies all outperform random selection, but greedy acquisition remains surprisingly effective and simple for ultra-low data regimes.
5. The study includes realistic noise simulations (10–30%) to mirror experimental variability, showing that robust setups (especially RF MQN PADRE) maintain strong hit discovery even under noisy conditions.
6. Enriching the initial pool with just one known active molecule (from the top 1% of docking scores) further improves the likelihood of success—raising the hit probability from 73% to 93% for the top model.
7. Even in the smaller Enamine DDS-10 library (~10k molecules), the pipeline remains reliable: top strategies still consistently discover 10 hits with 100% probability, showing the framework’s versatility across dataset sizes.
8. Key design choices—simple models (MLP, RF), expressive descriptors (CDDD, MQN), and thoughtful acquisition functions—enable efficient screening without the need for complex GNNs or large datasets.
9. These results emphasize that accurate prediction of weak binders early in the AL cycle is essential to steer the model toward potent candidates—especially when only a few hundred experiments are feasible.
10. Overall, this work offers a robust, practical blueprint for hit discovery in low-data settings, highlighting the power of combining thoughtful data representation, augmentation, and acquisition strategies.
💻Code: github.com/jensengroup/AL_pa…
📜Paper: doi.org/10.26434/chemrxiv-20…
#ActiveLearning #DrugDiscovery #LowData #Cheminformatics #MolecularScreening #AI4Science #ComputationalBiology

1
9
42
3,025

15 May 2024
This special issue explores low-data, few-shot, & active learning techniques. Join us as we tackle data scarcity & showcase cutting-edge #research, #applications & #innovations.
#Lowdata #AI #activelearn #compchem #chemtwitter #CallForPapers
🔗bit.ly/3FcBwNz
1
4
402
28 Feb 2024
This special issue explores low-data, few-shot, & active learning techniques. Join us as we tackle data scarcity & showcase cutting-edge #research, #applications & #innovations.
#lowdata #AI #activelearn #compchem #chemtwitter #CallForPapers @ELSpharma
2
82

28 Jul 2023
Even if I didn't win any giveaway,i stil send a massage of appreciation on behalf of the winners.
although
I waited all day for this,follwing ur tweets wasn't easy,batrrylow,lowdata errands,haa it wsznt.
But
I know mine will come.
I believe.
Thank you @XAUUSDPREACHER
GOODNIGHT
28 Jul 2023

⚡Most Active Follower⚡
Winner 4🏆: @kolapo56981799
Congratulation, You can claim your 100k giveaway by opening a Support ticket in the @fxifycom discord.
discord.gg/fxify
1
2
74

25 Mar 2023
そういえば、LowDataって名前の、生データっぽいエクセルシートをコンサルが見せてきたけど、RawDataじゃないんかな?このコンサル大丈夫なんかな。
1
81


27 Jul 2022
因みにこの問題を理解しているかどうかは
「ローデータを横文字で書かせる」と簡単に判別できたりする(笑)
LawDataでもLowData無いんだ…
1


3 Mar 2022
この記事で紹介する論文では、分布の変化を細かく分析できるフレームワークを導入し、実世界に影響を与えうる三つの分布シフト(spurious correlation, lowdata drift, unseen data shift)を定義しました。
ai-scholar.tech/articles/dom…
13
38


19 Nov 2020
Running low or have no data? No worries... We have you covered! Dial the # shown in the pic to hear @PodcastBonds over the phone thru phone call thanks to @bullhorn_fm!
-The Podcast Pulse x DBPodcasts
#BullhornFM #NoData #LowData #DataFree #PodcastRecommendations #PodRecs #JBP

1
2

4 Sep 2020
🎤 #SIDO2020 Aurélie Fournier présente en 20s les activités de Light And Shadows. Elle et son équipe vous accueillent au @SIDOevent stand E104. @LS_VR_company #XR #technologies #XRSuite #innovation #lowdata #energy #DeepLearning @LaFrenchTech
2
2
3 Sep 2020
#SIDO2020 Réalité mixte, vecteur de la stratégie marketing de l’entreprise de demain ce jeudi 3 septembre à @SIDOevent @fbarbin @_synergiz_ @dgrpro
@Minalogic @PierreFabre @bnppre Florian couret @VRArlesFestival #IA #innovation #lowdata #energy #DeepLearning



3
6

3 Sep 2020
Une vision novatrice de l'intelligence artificielle, avec des applications autonomes dans les chaînes de productions automobiles ➡️Visitez le stand de @_AnotherBrain en W204 🤩
📌 Badge gratuit #SIDO2020 : bit.ly/2Nbs8zm
#IA #innovation #lowdata #energy #DeepLearning

1
2

20 Jul 2020
Le monde s'en fout de ce que tu crois, les chiens aboient la caravane passe .
T'as autre chose à dire?
1
2