
All-atomistic Transferable Neural Potentials for Protein Solvation
1 PHNN (Protein Hydration Neural Network) is introduced as an implicit solvent model that keeps the speed advantages of continuum solvation while learning environment-dependent corrections that remain predictive on out-of-domain proteins.
2 The key design shift vs typical “delta-learning” is that PHNN does not just add a post hoc energy correction; it learns corrections to the underlying GBn2 equation parameters (e.g., local dielectrics, screening, charges, SASA-related terms), so the analytical backbone remains the scaffold and the neural network fills known physical gaps.
3 PHNN is built on a GBn2 backbone and trained by force matching to explicit-solvent reference forces (CHARMM36 TIP3P), aiming to approximate mean solvation forces (PMF-consistent) using many instantaneous-force frames as noisy samples.
4 Architecture-wise, PHNN uses an E(3)-equivariant GNN (custom pseudo-MACE via cuEquivariance) to produce atom-centered embeddings that can represent higher-order geometric effects (up to quadrupolar information), which are relevant for anisotropic hydration structure and packing asymmetry near protein surfaces.
5 To avoid overfitting to stochastic instantaneous solvent forces, PHNN uses a heteroscedastic (variance-aware) training objective (β-NLL style). A separate invariant GNN estimates per-sample uncertainty using predicted forces plus key GBn2 parameters.
6 PHNN targets specific known GB/continuum failure modes with learned, physically interpretable modifications: (i) a learned modulation of the nonpolar SASA term with a learnable surface tension coefficient, (ii) atom-specific local solute dielectric and local solvent dielectric, (iii) a learned correction to the GB screening function to better handle mutual desolvation (important for salt bridges), and (iv) per-atom charge corrections to partially capture electrostriction-like effects.
7 On an independent OOD test (39 proteins), PHNN reports mean force MAE 66.6 ± 9.4 kJ/(mol·nm) vs explicit solvent, improving over GBn2 at 97.5 ± 9.0 kJ/(mol·nm) (about 31.7% lower error). The paper notes an intrinsic ceiling because explicit-solvent instantaneous forces have large variance, so deterministic implicit models cannot match every fluctuation.
8 In dynamical tests (4 domains, up to ~5400 atoms), PHNN better preserves native-like behavior than GBn2 when comparing RMSD/ROG/RMSF distributions and KDE-derived free-energy landscapes; GBn2 shows stronger unfolding tendencies, especially for larger domains.
9 Targeted error breakdowns suggest PHNN improves across secondary-structure classes and residue types; the largest gains are reported for lysine (consistent with improved salt-bridge screening). Remaining challenges include arginine (delocalized guanidinium charge is difficult to fix with per-atom corrections) and buried regions where long-range electrostatics may require larger interaction radii or deeper models.
10 Transferability limits are probed with alanine dipeptide (near-zero sequence similarity to training domains): PHNN reproduces major Ramachandran basins but distorts basin shapes and mis-ranks some regions (notably αR), motivating future training that explicitly enriches boundary/strained conformations via umbrella sampling and broader conformational coverage (including IDPs and 300K data).
📜Paper: arxiv.org/abs/2605.14584
#ComputationalBiophysics #MolecularDynamics #ImplicitSolvent #ForceFields #NeuralPotentials #EquivariantGNN #ProteinSimulation #Solvation #MLforScience

2
12
1,793
CellFluxRL: Biologically-Constrained Virtual Cell Modeling via Reinforcement Learning
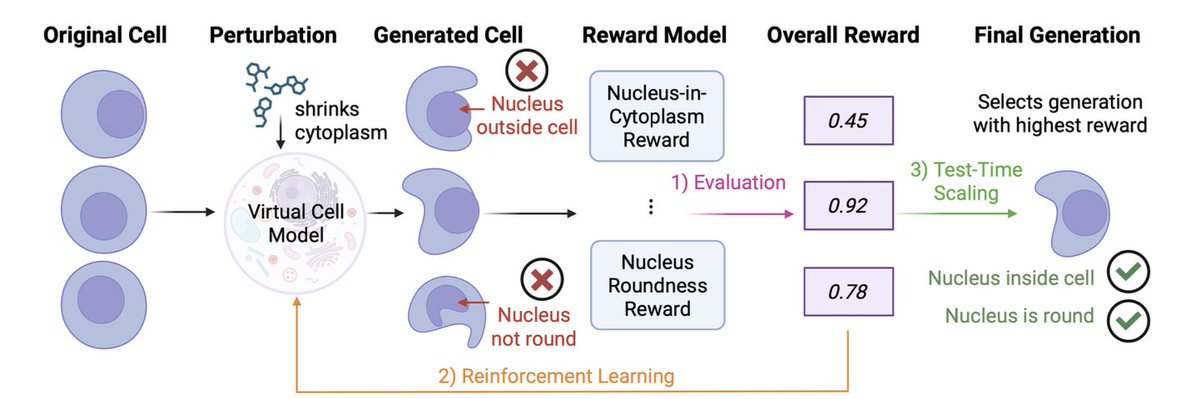
1. CellFluxRL addresses a practical failure mode in image-based “virtual cell” generators: samples can look realistic yet violate basic biology (e.g., nuclei appearing outside cytoplasm), limiting downstream use in drug discovery workflows.
2. The core idea is RL post-training of a pretrained perturbation model (CellFlux, a flow-matching approach) using biologically meaningful, mostly non-differentiable evaluators as reward functions—explicitly aligning generation with physical/biological constraints rather than only pixel-level objectives.
3. The paper designs 7 rewards in 3 categories: biological function (mode-of-action consistency), structural validity (nucleus-in-cytoplasm containment; nuclear roundness), and morphology statistics (nucleus/cytoplasm size and counts), combined as a weighted sum with a KL constraint to stay close to the pretrained model and reduce reward hacking.
4. Biological function reward uses a pretrained MoA classifier: reward is the predicted probability of the ground-truth MoA for the applied perturbation, turning “does this look like the right drug class?” into a trainable alignment signal.
5. Structural rewards explicitly enforce cross-channel spatial consistency via segmentation (Cellpose): nucleus-in-cytoplasm penalizes spatial incoherence across nucleus/cytoplasm channels, while a roundness reward matches MoA-conditioned nuclear shape distributions (mean/variance per MoA).
6. Morphology-statistic rewards match MoA-conditioned population statistics: maximum nucleus size, maximum cytoplasm size, nucleus count, and cytoplasm count are scored by normalized deviation from real-image distributions, encouraging correct scale and density rather than only local texture.
7. Optimization uses an online RL method in the DiffusionNFT style adapted to source-to-target flow matching: generate groups of rollouts per (control image x0, perturbation c), normalize rewards within the group into an “optimality probability,” then apply contrastive updates that increase likelihood of high-reward samples and decrease likelihood of low-reward ones.
8. Results on BBBC021 (98K three-channel 96×96 images; 26 perturbations; 12 MoAs) show consistent improvements over CellFlux and prior baselines (PhenDiff, IMPA) across all reward metrics; MoA reward increases (0.26 to 0.34), nucleus containment improves (0.88 to 0.96), and the combined overall reward flips from negative to positive after RL plus selection.
9. The same reward suite enables test-time scaling: best-of-N sampling selects the highest-reward candidate, yielding monotonic gains as N increases; with N=4, MoA reward rises further (0.34 to 0.56) and overall reward improves substantially, illustrating a compute-quality tradeoff at inference.
10. Ablations show single-reward RL improves the targeted metric but transfers poorly; the combined multi-reward objective yields balanced improvements across biological, structural, and morphological criteria. Sensitivity analysis on the KL weight indicates a tradeoff between allowing larger model shifts (better structure/morphology) vs staying closer to the base model (slightly better biological-function reward).
📜Paper: arxiv.org/abs/2603.21743
#ComputationalBiology #BioimageAnalysis #GenerativeModels #ReinforcementLearning #FlowMatching #VirtualCells #DrugDiscovery #Microscopy #MLforScience
3
8
1,021

Amid the adoption of #AI, coupled with social and economic challenges, who will be the primary producers of chemical knowledge in the future?.. With @daniil_boiko, in @ChemEurJ. #LabAutomation #MLforScience #DigitalChemistry #LLM #ScientificPublishing
doi.org/10.1002/chem.2025036…
1
2
2
1,232

Feb 6
Stochastic sampling guided by PDEs: when randomness knows its limits. This hybrid approach could reshape how we simulate nature itself, one particle at a time.
physicsAI MLforScience SMC
arxiv.org/abs/2601.23262v1
8

Looking forward to comparisons, experiences, and pointers to similar tools. #ComputationalChemistry #Enzymology #QMMM #MachineLearning #MolecularSimulation #MLforScience #ReactionMechanisms #DrugDiscovery #HPC #ChemRxiv 🧵 12/12
1
43

27 Nov 2025
The Global Race to Build AI-Ready Scientific Datasets
Read more: ow.ly/V7iP50XyKSr
#AIForScience #ScientificData #DataReadiness #ResearchInfrastructure #HPC #HighPerformanceComputing #BigData #OpenScience #DatasetEngineering #MLforScience

65

AI-generated genomes are here. Biology just got its own “hello world.”
biorxiv.org/content/10.1101/…
#AI #MachineLearning #DeepLearning #GenerativeAI #Bioinformatics #ComputationalBiology #MLforScience #Science #Biology #Biotech #Research #STEM #SciComm #Innovation #Tech

1
10

🚨 We’re hiring a postdoc @NYU_Courant & @NYUDataScience to build #AI foundation model for ocean & atmosphere 🌊☁️ as part of #M2LInES!
Work with Profs. @ZannaLaure,Joan Bruna & Carlos Fernandez-Granda.
Apply: apply.interfolio.com/167915
#MLforScience #ClimateAI #PostdocJobs
2
6
768

14 Jul 2024
Trained my first Graph Neural Network on the HIV dataset by MoleculeNet for molecule classification. The model classifies whether a given molecule is an HIV inhibitor or not. Code repo: github.com/devnithw/hiv-gnn
#GNN #DeepChem #Biophysics #DeepLearning #MLforScience
3
8
225

11 Aug 2023
Gave the “introduction to deep learning” tutorial at ATPESC 2023 this morning. Taught the fundamentals and prerequisites for the afternoon sessions that will focus on distributed deep learning and physics based applications! #mlforscience
11 Aug 2023

After two weeks of intensive #HPC training, ATPESC 2023 comes to a close today with a track focused on using #AI and #ML for science. @exascaleproject
Slides are being posted to the agenda page. Lecture videos will be posted on YouTube at a later date.
extremecomputingtraining.anl…

ALT Argonne's Bethany Lusch introduces the machine learning track at the 2023 Argonne Training Program on Extreme-Scale Computing.

ALT Argonne's Taylor Childers leads a breakout session on deep learning at the 2023 Argonne Training Program on Extreme-Scale Computing.

ALT Argonne's Marieme Ngom delivers a talk on deep learning at the 2023 Argonne Training Program on Extreme-Scale Computing.
1
2
3
414

16 Feb 2022
RT @Dra_MPerez: New PostDoc position on my team @CMI_hub is now posted on @sacnas career services! Please check it out and share!
careercenter.sacnas.org/link…
#ChemPostdoc #chemtwitter #chemjobs #AIforScience #MLforScience #machinelearning #cheminformatics #remotework #remotejobs…
4
5

19 May 2021
Not long now until applications close for this fantastic course. Apply by the 21st to join the next cohort!
@Cambridge_CL @CambridgeSpark
#Machinelearning #AI #AIforscience #MLforscience
15 Apr 2021

If you are a PhD or postdoc at Cambridge University, apply now for a funded training course that is equipping scientists with powerful tools to progress their research. The next Data for Science course starts mid-July. ow.ly/wq7Q50EoCXg
3
2

13 Sep 2019
AI 46 gunde potential kinase inhibitor ilac tespit etmis. Insanlarin aklina gelmezdi o molekul. #MLforScience ♥️
2