
May 18
From I/O to Code with Discovery Agent
🔗alphaxiv.org/abs/2605.15334
The field of code generation is obsessed with the NL2Code task, which mostly measures an LLM’s capacity for Composition and Reuse.
🚀It’s time to shift focus to the IO2Code task, which truly measures an LLM’s capacity for Induction and Discovery! 🔥




1
3
50
Apr 12
What are the key challenges for agents in practical software development? #agents
The terms in the Agent field are evolving rapidly🚀, but most of them already appeared in earlier academic papers. For example,
1. "Vibe Coding" originates from Code Generation (i.e., NL2code);
2. The "Planner-Generator-Evaluator" structure in mainstream agent frameworks stems from the original Planner-Coder-Tester;
3. "Harness Engineering" is essentially a Software Engineering Methodology oriented toward probabilistic models.
These concepts can be traced back to the earliest multi-agent work in code generation — self-collaboration. However, their importance is becoming increasingly apparent through practice.
We summarize the key challenges for agents in our work: A Survey on Code Generation with LLM-based Agents, which was recently accepted by Journal of Software. Specifically,
🧠1. Limitations of Agent Core Capabilities
- Insufficient Domain-Specific Task Handling: Lacks deep domain knowledge, prone to misunderstanding or hallucination in specialized tasks
- Weak Intent Understanding and Context Awareness: Easily misinterprets ambiguous instructions, struggles to accurately align with users' real needs
- Difficulty Handling Large Complex Projects: Insufficient capability in cross-file dependencies and overall architecture understanding, limiting project-level applications
- Insufficient Multimodal Understanding: Unable to effectively utilize non-textual information such as images, leading to inconsistencies between design and generated results
- Immature Context Engineering: Context is susceptible to poisoning (erroneous or fabricated information polluting subsequent reasoning), distraction (redundant information drowning key signals), confusion (format disorder causing understanding deviation), and conflict (contradictory information causing decision errors), severely impacting generation quality
🛡️2. Robustness and Updatability Challenges of Agent Systems
- Significant Error Cascade Effect: Upstream errors are continuously amplified, ultimately causing systemic failure
- Difficulty Coordinating Multi-Agent Collaboration: As scale increases, interaction complexity explodes, prone to communication chaos and goal drift
- Insufficient Continual Learning Capability: Agents struggle to effectively absorb new knowledge while avoiding forgetting old knowledge
🛠️3. Tool Integration and Deployment Challenges
- Lack of Flexibility and Security in Tool Usage: Unable to dynamically discover and integrate tools, and must prevent tool misuse risks
- High Operational Costs: Multi-round collaboration brings enormous computational and time overhead, limiting large-scale applications
- Lack of Lightweight Deployment Capability: Difficult to achieve efficient operation on edge devices, requiring model compression and acceleration techniques
⚖️4. Trustworthiness, Security, and Ethical Risks
- Insufficient Reliability and Debuggability: Hallucinations and complex internal decision mechanisms make the system hard to trust and difficult to debug
- Risk of Malicious Code Generation: May bypass security policies to generate attack scripts, requiring strict pre- and post-generation review mechanisms
- Unclear Copyright Attribution and Legal Risks: Generated content may infringe copyrights, urgently needing tracking mechanisms and ethical guidelines
🔮5. Evolution of Evaluation Systems and Software Paradigms
- Incomplete Evaluation System: Existing metrics ignore human intervention costs, making it difficult to accurately reflect the system's true utility
- Software Development Paradigm Will Transform: The future may shift from "humans agents developing software" to a new paradigm of "humans describe intent -> agents directly complete tasks"
PS:
A Survey on Code Generation with LLM-based Agents: arxiv.org/pdf/2508.00083
Self-collaboration Code Generation: dl.acm.org/doi/10.1145/36724…

1
1
3
181

Additionally, we generated synthetic evaluation instances matching real-world patterns and avoided data contamination, with every test case manually reviewed by senior researchers. The result is 1,800 evaluation instances across six languages (Python, JavaScript, TypeScript, Java, C , C#) and six task categories derived directly from observed usage: API Usage, Code Purpose Understanding, Code2NL/NL2Code, Low Context, Pattern Matching, and Syntax Completion.
4/7
1
2
163

10 Oct 2025
Summer '26 PhD research internships at Microsoft Copilot Tuning. Continual learning, complex reasoning and retrieval, nl2code, data efficient post-training.
jobs.careers.microsoft.com/g…
28
232
16,470

6 Oct 2025
1/ 🚀 AI Coding is revolutionizing software development!
From generating boilerplate code to automating tests, AI is boosting productivity and creativity. Here's how it's shaping the future of coding.
#AICoding #DevTools #TechInnovation
2/ 📝 Natural Language to Code: The New Paradigm
Describe your feature in plain English, and AI generates functional snippets. Say goodbye to boilerplate and hello to rapid prototyping!
#NL2Code #ProductivityBoost
3/ 🧐 Smart Code Completions: Your Coding Sidekick
IDE plugins now predict your next move, offering context-aware suggestions that complete your thoughts before you finish typing.
#CodeCompletion #DeveloperExperience
4/ 🛠️ Testing & Quality Assurance Made Easy
AI analyzes your codebase to generate comprehensive test cases, identify vulnerabilities, and even refactor for performance. Say hello to safer, more reliable software.
#SoftwareTesting #QualityAssurance
5/ 🌟 Vertical-Specific Solutions: Tailored for Success
From fintech to healthcare, AI-powered tools are addressing industry-specific challenges, ensuring compliance and optimizing workflows.
#VerticalAI #Industry4.0
6/ 🔄 Development Lifecycle Automation
AI streamlines everything from requirement gathering to deployment, reducing manual effort and accelerating time-to-market.
#DevOps #ProcessAutomation
7/ 📚 Education & Upskilling: Learning with AI
Interactive coding tutorials, real-time feedback, and automated documentation are empowering developers to upskill faster than ever.
#LearnToCode #ProfessionalDevelopment
8/ 🚧 Challenges Ahead: Navigating the AI Landscape
While AI enhances coding, challenges like code maintainability, security, and ethical considerations remain. Human oversight is crucial.
#AIethics #CodeQuality
9/ 🌐 The Future is Collaborative
The most effective teams will blend human creativity with AI efficiency, fostering innovation and driving breakthroughs.
#HumanAI #FutureOfWork
How is AI shaping your development workflow? Share your experiences below! 👇
#DeveloperCommunity #TechTrends
2
3
27
3,482

my definition of natural language programming is probably broader than many. To me, it's not just NL2code in programming languages, but avg users on their day-to-day. So my 'turing test' would be if my parents or people with disabilities can complete most of their digital day-to-day via natural language.
I do think there's a path to reach it; that's the 'cooking something new' part of my X bio is about. Hope to be able to share more soon :)
1
5
2,376

Today we're releasing jina-code-embeddings, a new suite of code embedding models in two sizes—0.5B and 1.5B parameters—along with 1~4bit GGUF quantizations for both. Built on latest code generation LLMs, these models achieve SOTA retrieval performance despite their compact size. They support over 15 programming languages and 5 tasks: nl2code, code2code, code2nl, code2completions and qa.
9
49
308
29,685

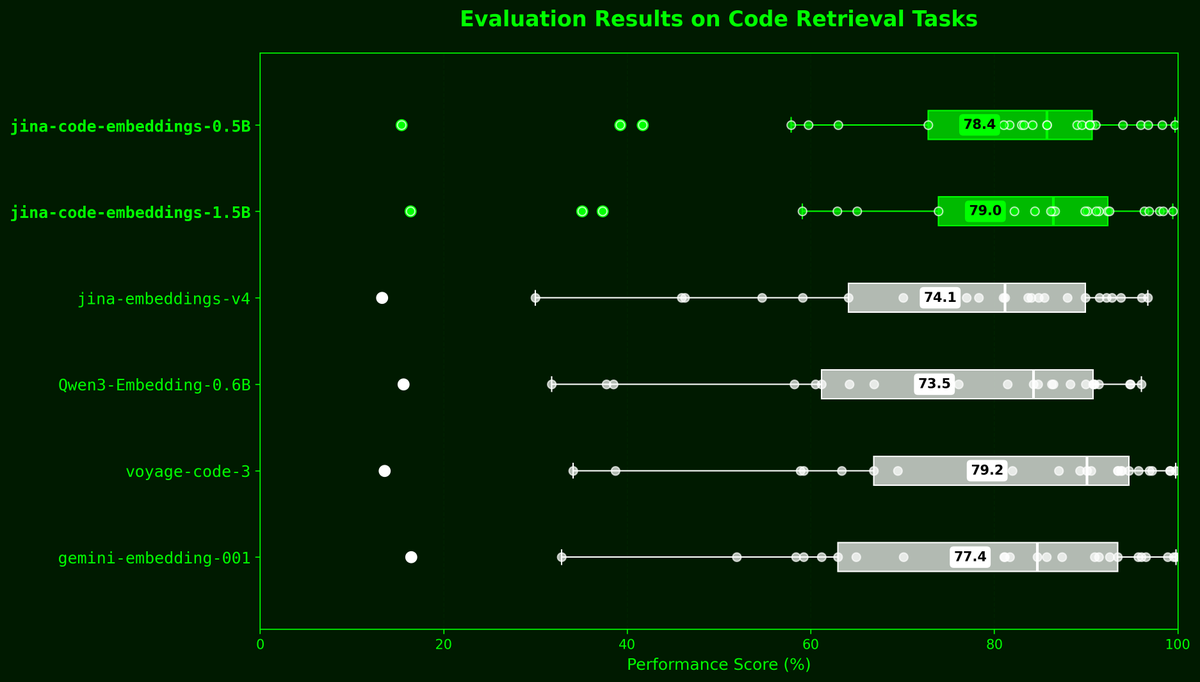
jina-code-embeddings (0.5B and 1.5B) are compact autoregressive code embedding models for retrieval, technical QA, and cross-lingual similarity. Built on Qwen2.5-Coder backbones, they use last-token pooling with task-specific instruction prefixes (NL2Code, TechQA, Code2Code, Code2NL, Code2Completion), surpassing larger general embedding models on code retrieval benchmarks.
Training
- Training used contrastive InfoNCE (τ=0.05) to pull related query–code pairs closer in embedding space while pushing apart unrelated ones, and Matryoshka representation learning to make embeddings truncatable so users can balance precision against efficiency
- Data: Training combined multiple real and synthetic sources. Real datasets included MTEB code tasks, CoSQA , CodeSearchNet, CommitPackFT, LeetCode, WikiSQL, and SWE-Bench. Synthetic datasets were generated with GPT-4o, covering deep learning framework translations and multilingual extensions of the CodeChef dataset
- Hardware: 4×A100-80GB, 1500 steps (0.5B ≈8.3h, 1.5B ≈12h)
The team compared different pooling strategies for generating embeddings. Last-token pooling consistently gave the best results, outperforming mean pooling and latent attention pooling by about one point on the MTEB code average. For decoder-only models like Qwen2.5-Coder, the last token captures the strongest contextual signal, which explains its edge
Results (MTEB Code Retrieval average)
- JCE-0.5B: 78.41
- JCE-1.5B: 78.72
Compared to jina-embeddings-v4: 74.11, Gemini-001: 74.87, Qwen3-Embedding-0.6B: 73.49


1
1
10
1,278

4 Dec 2024
🚨 Applied Scientist Opportunities! 🚨
My GenAI team in Adobe Experience Cloud is fast growing. We are looking for multiple experienced post-PhD applied scientists to join me to build exciting high profile products such as AI Assistant in Adobe Experience Platform (lnkd.in/gnBrrQdQ). We are working on wide range of challenging problems natural language processing, information retrieval, machine learning, and AI for data management.
Seeking candidates with:
- PhD in CS or related field
- Strong publication record in top NLP or AI/ML conferences (e.g. ACL, EMNLP, AAAI, KDD, NeurIPS, ICML).
- Strong engineering skills
Areas of interest include:
- Dialog Systems
- GenAI Applications
- Agentic Platforms
- Reasoning and Planning
- GenAI Evaluation
- NL2Code / NL2SQL
- Retrieval Augmented Generation
Location: San Jose, California.
If you have the right background and are interested in this opportunity, please apply directly via the link below. Also please DM me your resume or email me.
🔗 lnkd.in/gAi7ih3u
(This is an evergreen job post using for hiring both MLEs and Applied Scientists, as we are hiring on ongoing basis.)
NOTE: Due to the volume of responses, I will NOT be able to respond to individual inquiries. Thank you for your understanding!
3
28
147
22,789

18 Feb 2024
🚀 Our latest research paper on code representation learning, CodeSage, outperforms OpenAI text-embedding-3-large on Code2Code search, and is on par with NL2Code search tasks! Dive into the techniques and insights - check them out on the blog: code-representation-learning…
9 Feb 2024

Introducing #CodeSage, a family of embedding models for generating code representations. To appear at #ICLR2024, co-led w/ @DejiaoZhang. 1/5
Paper: arxiv.org/abs/2402.01935
Evaluation code: github.com/amazon-science/Co…
Model checkpoints: huggingface.co/codesage
1
11
660

13 Feb 2024
New Embedding Models for Code released by @awscloud!
Embedding Models are at the heart of every RAG application. Without good embeddings, retrieving relevant context to answer your user prompts is impossible. 🔍
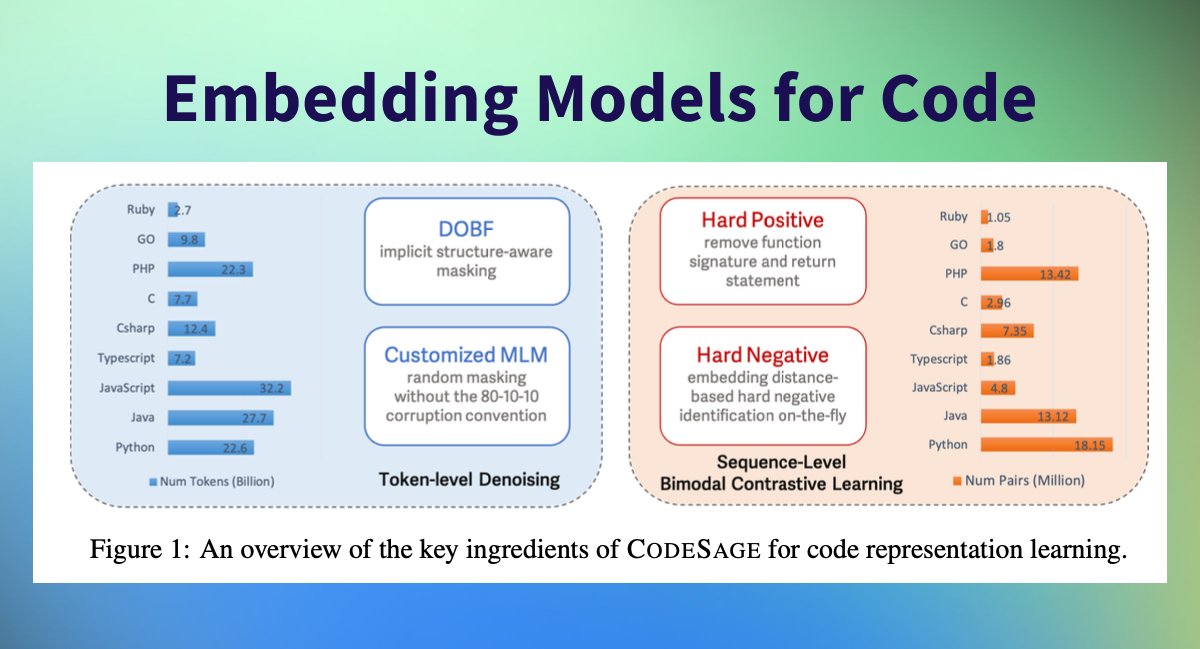
Super exciting to see Amazon release CodeSage, a family of open code embedding models with an encoder architecture that supports a wide range of source code understanding tasks. 🤗
TL;DR;
📏 Comes in 3 sizes: 130M, 356M, 1.3B
📚 Pre-trained on @BigCodeProject the Stack (237 million code files)
🇪🇺 Fine-tuned on 75 million bimodal (code and natural language) pairs
🔍 Using hard negatives & hard positive improve MAP > 10%
🔠 Using @BigCodeProject StarCoder Tokenizer
⚖️ Licensed under Apache 2.0
🥇 Outperforms @OpenAI and others on 0-shot Code Search
🚀 Sota Performance on NL2Code (Natural Language to Code)
🤗 Available on @huggingface and supported in Sentence Transformers
3
37
217
28,213

9 Jan 2024
yep the claim is interesting, and code is a nice domain for it! happy to discuss our ideas on that if the team is interested 😀
for your q: here, a lot of samples may not have a short NL description so hard to say. but we have WIP trying on other NL2code tasks and seems true.
6
306

9 May 2023
Exciting news! Our paper provides a comprehensive review of the latest 27 large language models for NL2Code and their benchmarks. Key factors for success: Large Size, Premium Data, Expert Tuning. We also build a website to track the latest updates in this field. Check it out!
9 May 2023

Large Language Models Meet NL2Code: A Survey (accepted by ACL 2023)
@zandaoguang @beichen1019
Paper: arxiv.org/pdf/2212.09420.pdf
Real-time Update Website: nl2code.github.io/
2
77
9 May 2023
Large Language Models Meet NL2Code: A Survey (accepted by ACL 2023)
@zandaoguang @beichen1019
Paper: arxiv.org/pdf/2212.09420.pdf
Real-time Update Website: nl2code.github.io/
1
2
263

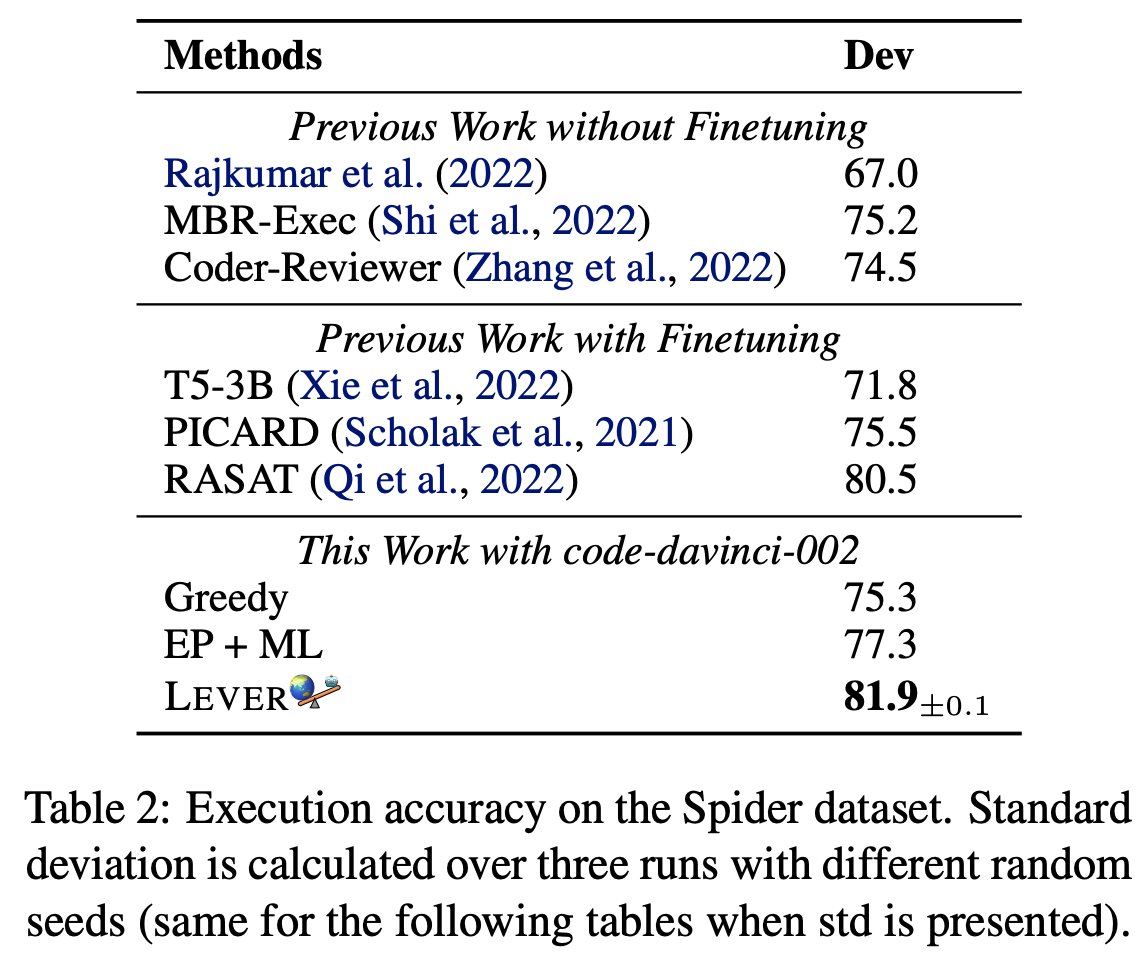
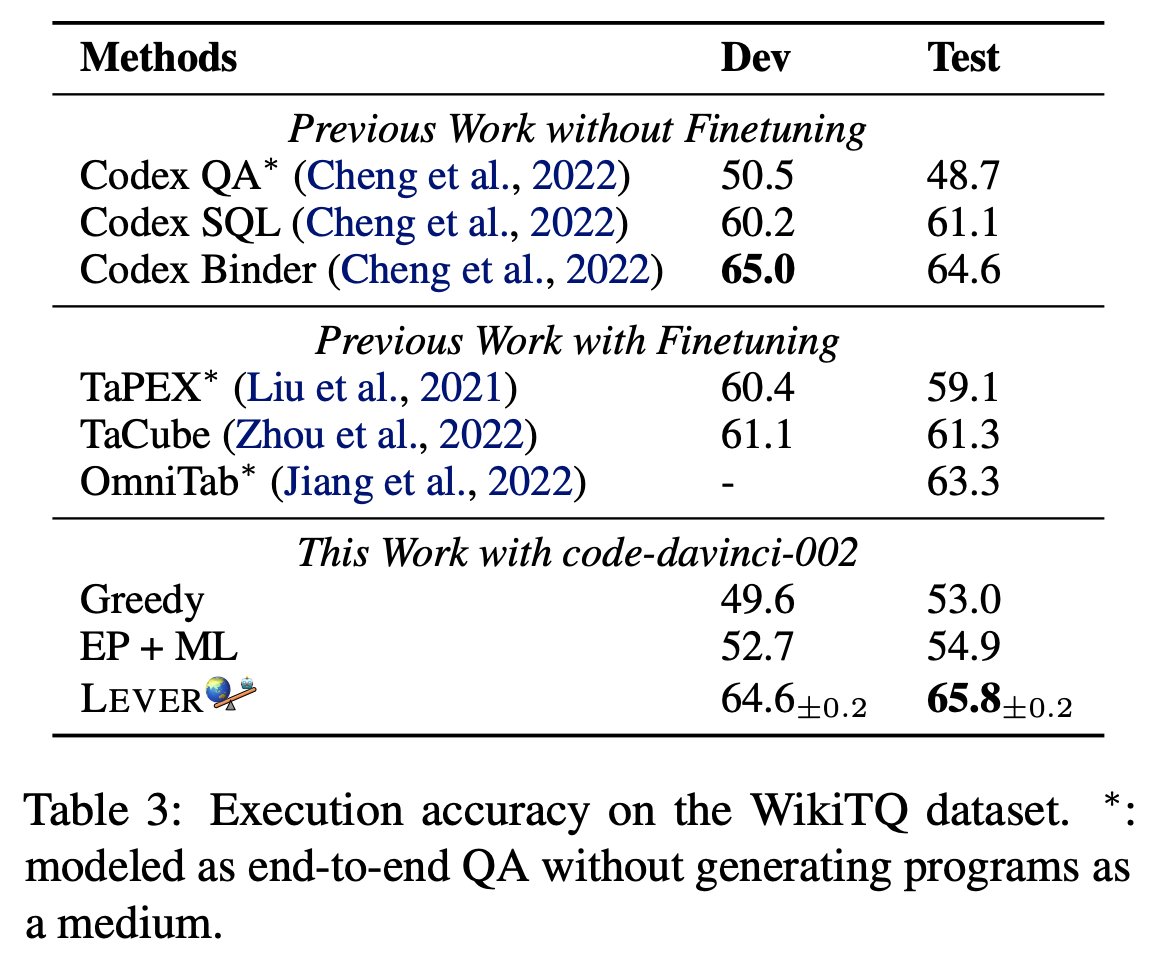
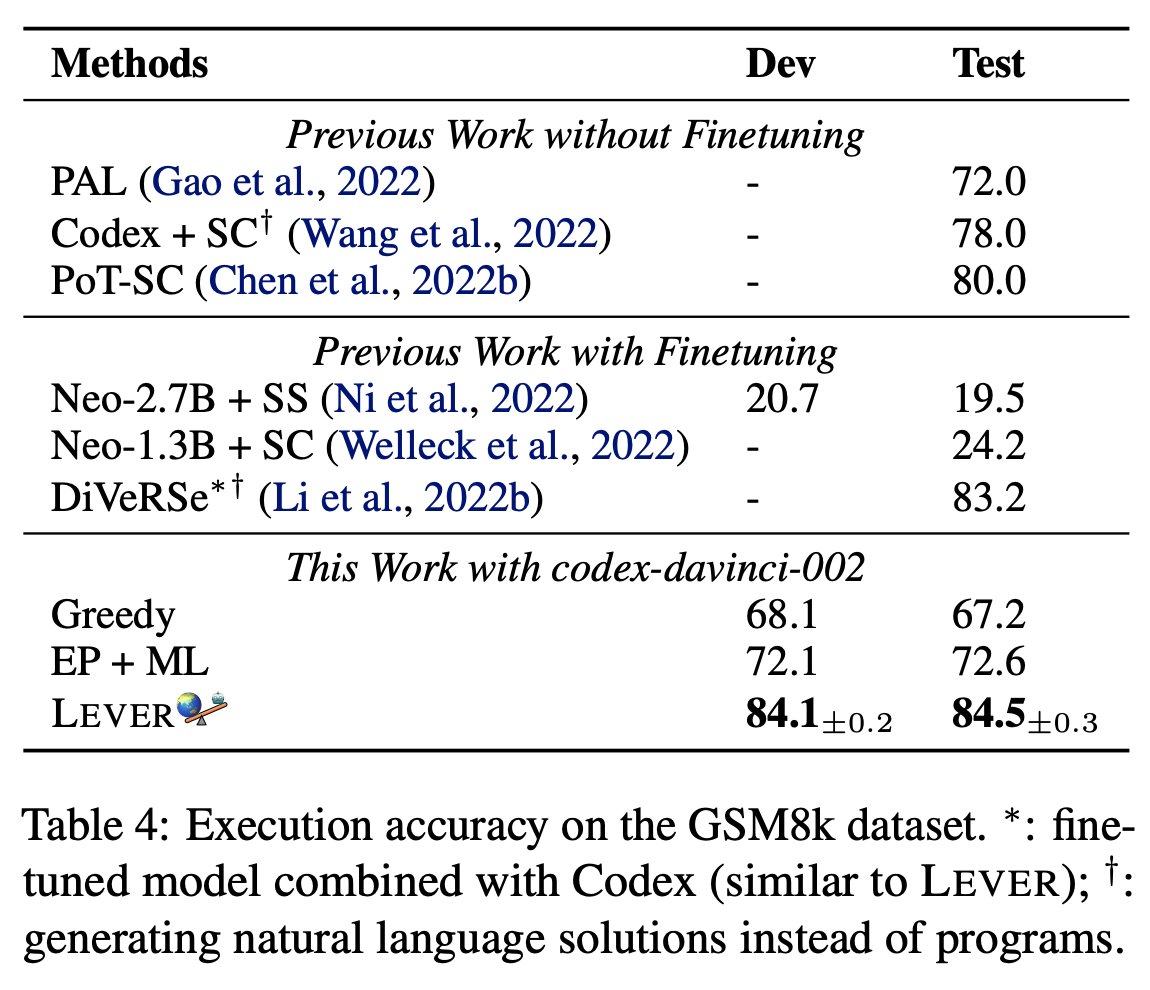


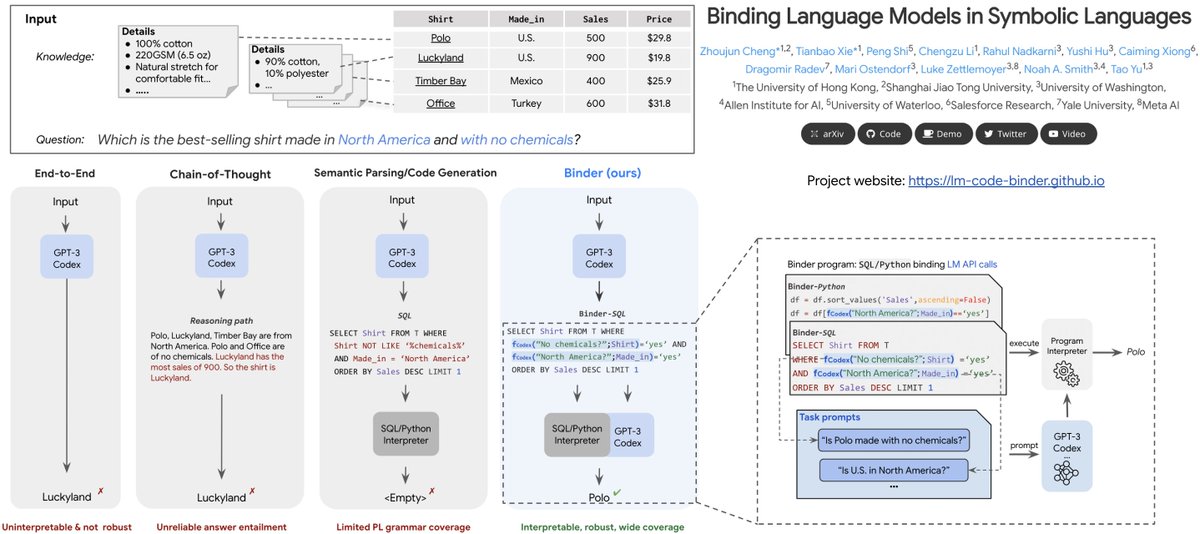
A new way to work w. LMs!
Binder, an easy neuro-symbolic paradigm:
1.Parse input➡️SQL/Python bound w. GPT3 Codex API calls
2.Codex PL interpreter execute➡️answer
No train&few-shot!➡️SOTA
🆚chain-of-thought: interpretable&robust⬆️
🆚NL2Code: coverage⬆️
lm-code-binder.github.io
10
76
289

A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
deepai.org/publication/a-sca…
by Federico Cassano et al.
#ComputerScience #Learning
2

4 Dec 2021
Great opportunity for grad students to work on #NL2code

With @AndrewDGordon and colleagues at @MSFTResearch Cambridge, I'm happy to announce we are looking to hire an intern to work on #NL2Code: careers.microsoft.com/us/en/… #MachineLearning, #LargeLanguageModels, #ArtificialIntelligence #ProgramSynthesis #SoftwareDevelopment #Software
3

With @AndrewDGordon and colleagues at @MSFTResearch Cambridge, I'm happy to announce we are looking to hire an intern to work on #NL2Code: careers.microsoft.com/us/en/… #MachineLearning, #LargeLanguageModels, #ArtificialIntelligence #ProgramSynthesis #SoftwareDevelopment #Software
26
63