
I posted this exact map some time ago. I love documentational graphs of Internet communication programs and events. ARPANET is an example of how the elder computational communication systems (luh interwebz) were for Serious Purposes Only, often aimed at federal/technical uses, such as SATNET and PRNET. I'd like to mark down exactly when the Internet became suddenly so less serious and when it evolved into including a free-flow facet culture for sophisticated entertainment content and casual personification. Eleven years after ARPANET was released, Usenet was established, and eight years after that came IRC, and in 6 years after that came Geocities. The quality downgrade, (simultaneously the descent of truest digital freedom for the common man) of the contextual designations of the cyber-socio-interlink occurred at an exponentially rapid rate, from my observations. The Internet is no extension of any semblance of aristocracy, and if it could have been considered that way in the past it is sure to say it certainly didn't last that way for very long.
3
442

We’re honored to be named a 2026 The PR Net Next Gen Honoree for the fourth consecutive year. 🏆
Thank you to @_theprnet for recognizing Elev8’s continued contributions to shaping the future of communications.
Read more: bit.ly/46lTf3v
#AgencyLife #PRNet #NextGenHonoree2026

2
2
83

Jan 23
Historia DARPA, agencji finansującej projekty zbyt ryzykowne dla uniwersytetów i przemysłu, której to zawdzięczamy m. in. rozwój technologii dronowych, system GPS, PRNET (bezpośredniego przodka technologii Wi-Fi) oraz ARPANET, bezpośredniego poprzednika Internetu. Praca Weinberger jest doskonale udokumentowana źródłowo i stanowi znakomite uzupełnienie książki "The Pentagons Brain" autorstwa Annie Jacobsen, która kładzie większy nacisk na wywiady z naukowcami i wojskowymi zaangażowanymi w działalność agencji. O randze i jakości badań Weinberger świadczy m. in. fakt, że jej książki (z wiadomych względów) doczekały się tłumaczeń na język chiński.

3
170


11 Jul 2025
so you were only a good man and nice to women to get a prnet?? lol explains itself
7
34

20 Jun 2025
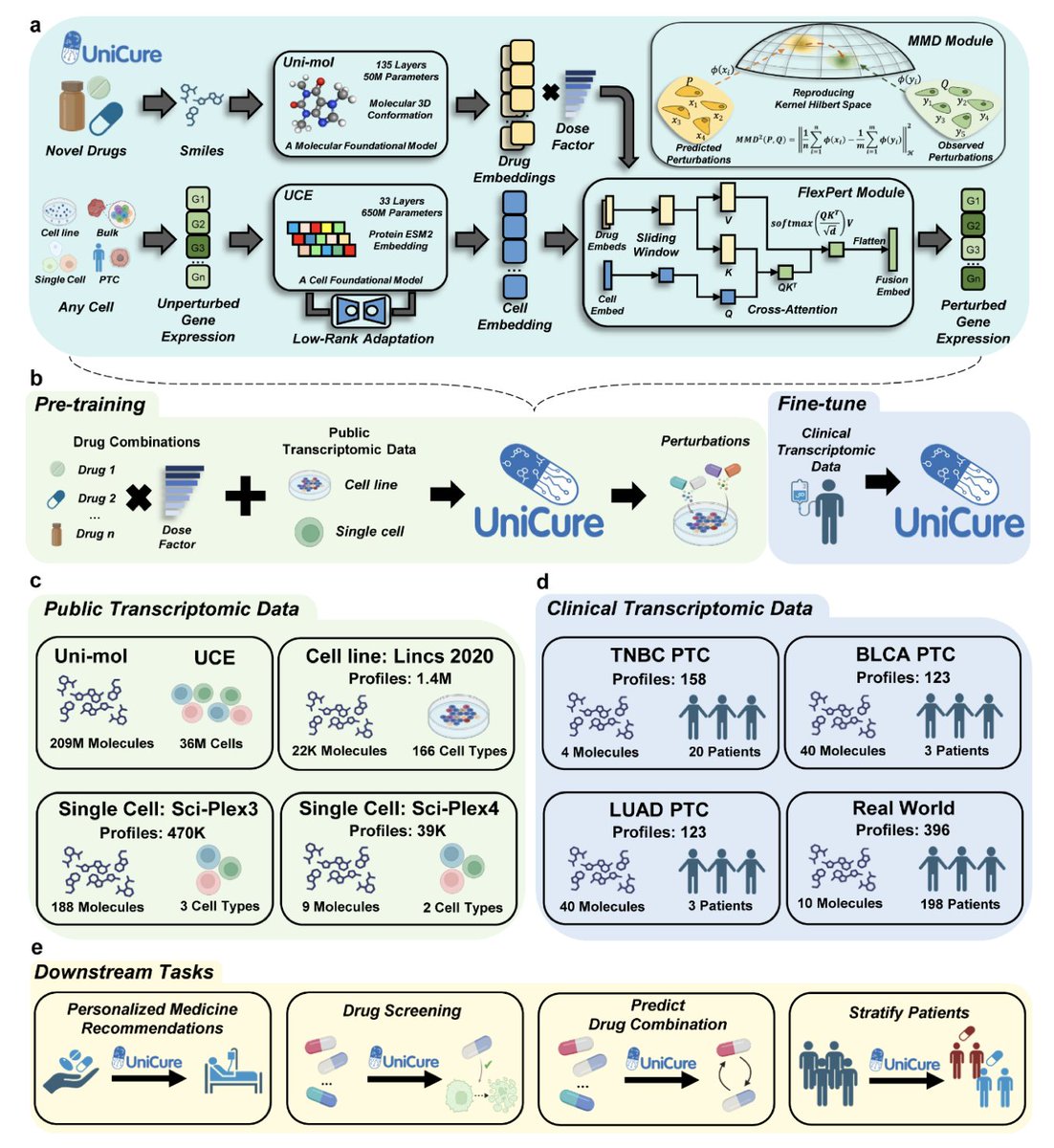
UniCure: A Foundation Model for Predicting Personalized Cancer Therapy Response
1.UniCure is a multimodal foundation model that enables personalized cancer therapy prediction by integrating pre-trained omics (UCE) and chemical (Uni-Mol) models to forecast transcriptomic responses to drugs across diverse tissues and cell types.
2.A key innovation is UniCure's FlexPert module, which models complex drug-cell interactions using a sliding-window cross-attention mechanism. This, along with Maximum Mean Discrepancy (MMD) loss, allows training on unpaired data and enhances generalization.
3.UniCure was pre-trained on over 1.8 million perturbation RNA-seq profiles, covering 22,000 compounds, 166 cell types, and 24 tissues. It was further fine-tuned on ~800 patient-derived samples including tumor-like clusters (PTCs) and real-world patient profiles.
4.The model demonstrates strong predictive accuracy for both bulk and single-cell data, with Pearson and Spearman correlations exceeding 0.9 in many benchmark datasets (LINCS2020, SciPlex3, SciPlex4).
5.Compared to existing models (PRnet, TransiGen), UniCure consistently outperforms in predicting transcriptomic perturbations and modeling cell-type–specific responses.
6.UniCure can learn dose-dependent effects, capture mechanisms of action (e.g., grouping proteasome inhibitors), and predict drug combination effects using real-world dual-compound datasets.
7.Fine-tuning with as little as 5% of patient-derived data achieves high predictive performance (e.g., correlation > 0.9 for LUAD), demonstrating strong data efficiency enabled by pre-training.
8.Through cross-cancer fine-tuning strategies, UniCure generalizes across patient populations and outperforms baselines in patient-level prediction for LUAD, BLCA, and TNBC.
9.Personalized drug rankings generated by UniCure stratify patients into clinically meaningful subgroups in late-stage BRCA and KIRC, correlating with distinct biological pathways and drug response profiles.
10.UniCure's rankings of known targeted therapies align with clinical standards in multiple cancer types. High-priority drugs as predicted by UniCure correlate with improved patient survival in LUAD and BRCA.
11.The model also enables virtual screening of natural products. Six predicted candidates were experimentally validated, showing significant anti-cancer effects in TNBC, LUAD, and BLCA cell lines.
12.UniCure represents a step forward in data-efficient, biologically-grounded precision oncology, with a modular architecture ready for future integration of multi-omics and combination treatment modeling.
📜Paper: biorxiv.org/content/10.1101/…
#AI4Science #CancerResearch #PrecisionOncology #FoundationModels #DrugDiscovery #SingleCell #DeepLearning #Bioinformatics
1
4
22
1,590
20 Jun 2025
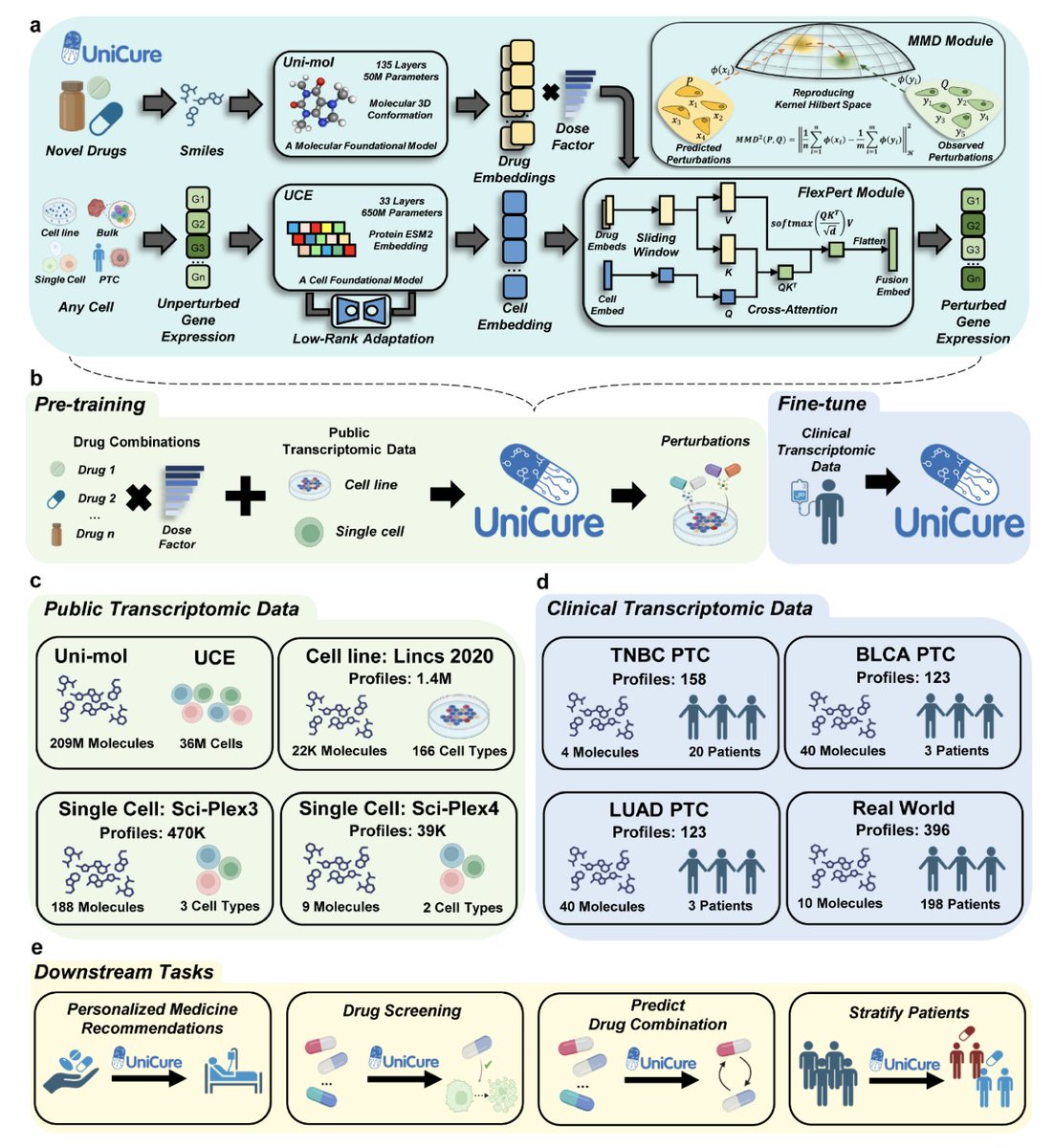
UniCure: A Foundation Model for Predicting Personalized Cancer Therapy Response
1.UniCure is a multimodal foundation model that enables personalized cancer therapy prediction by integrating pre-trained omics (UCE) and chemical (Uni-Mol) models to forecast transcriptomic responses to drugs across diverse tissues and cell types.
2.A key innovation is UniCure's FlexPert module, which models complex drug-cell interactions using a sliding-window cross-attention mechanism. This, along with Maximum Mean Discrepancy (MMD) loss, allows training on unpaired data and enhances generalization.
3.UniCure was pre-trained on over 1.8 million perturbation RNA-seq profiles, covering 22,000 compounds, 166 cell types, and 24 tissues. It was further fine-tuned on ~800 patient-derived samples including tumor-like clusters (PTCs) and real-world patient profiles.
4.The model demonstrates strong predictive accuracy for both bulk and single-cell data, with Pearson and Spearman correlations exceeding 0.9 in many benchmark datasets (LINCS2020, SciPlex3, SciPlex4).
5.Compared to existing models (PRnet, TransiGen), UniCure consistently outperforms in predicting transcriptomic perturbations and modeling cell-type–specific responses.
6.UniCure can learn dose-dependent effects, capture mechanisms of action (e.g., grouping proteasome inhibitors), and predict drug combination effects using real-world dual-compound datasets.
7.Fine-tuning with as little as 5% of patient-derived data achieves high predictive performance (e.g., correlation > 0.9 for LUAD), demonstrating strong data efficiency enabled by pre-training.
8.Through cross-cancer fine-tuning strategies, UniCure generalizes across patient populations and outperforms baselines in patient-level prediction for LUAD, BLCA, and TNBC.
9.Personalized drug rankings generated by UniCure stratify patients into clinically meaningful subgroups in late-stage BRCA and KIRC, correlating with distinct biological pathways and drug response profiles.
10.UniCure's rankings of known targeted therapies align with clinical standards in multiple cancer types. High-priority drugs as predicted by UniCure correlate with improved patient survival in LUAD and BRCA.
11.The model also enables virtual screening of natural products. Six predicted candidates were experimentally validated, showing significant anti-cancer effects in TNBC, LUAD, and BLCA cell lines.
12.UniCure represents a step forward in data-efficient, biologically-grounded precision oncology, with a modular architecture ready for future integration of multi-omics and combination treatment modeling.
📜Paper: biorxiv.org/content/10.1101/…
#AI4Science #CancerResearch #PrecisionOncology #FoundationModels #DrugDiscovery #SingleCell #DeepLearning #Bioinformatics
3
12
909
18 Jun 2025
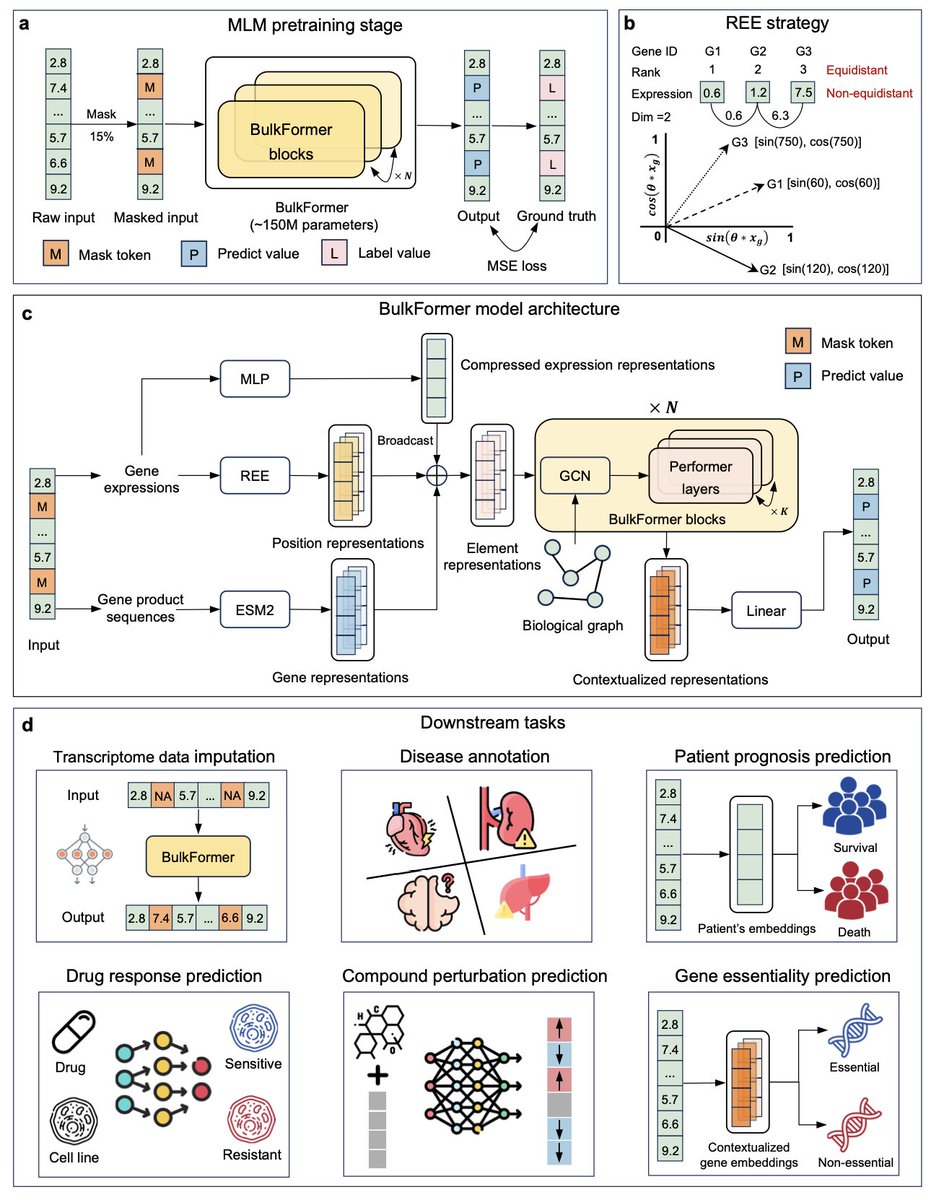
A large-scale foundation model for bulk transcriptomes
1.BulkFormer is the first large-scale foundation model designed specifically for bulk RNA-seq data, filling a critical gap left by models trained solely on sparse single-cell data.
2.It is pretrained on over 520,000 human bulk transcriptomes, modeling approximately 20,000 protein-coding genes using a hybrid encoder that integrates both graph neural networks and performer-based self-attention.
3.Despite using significantly fewer computational resources than single-cell models, BulkFormer achieves superior performance in six key tasks: transcriptome imputation, disease annotation, prognosis modeling, drug response prediction, compound perturbation simulation, and gene essentiality prediction.
4.In imputation tasks, BulkFormer reaches a Pearson correlation of 0.954 on masked gene expression recovery, outperforming variational autoencoders and single-cell foundation models, which suffer from modality mismatch.
5.Applied to pancreatic cancer data, BulkFormer recovers missing values that lead to the identification of 408 new DEGs, enriching pathways like oxidative phosphorylation—highlighting its power in uncovering latent biology.
6.The model facilitates the discovery of novel prognostic biomarkers across eight cancer types. For example, H4C1 is identified as a risk gene in kidney cancer (5.2x higher mortality), and PDE6H as protective in pancreatic cancer (HR = 0.26).
7.For disease classification, BulkFormer achieves a weighted F1 score of 0.939 across 23 diseases—substantially outperforming single-cell pretrained models like scGPT and Geneformer.
8.In cancer subtype classification across 33 cancer types, it again leads with a weighted F1 of 0.833 and yields high-quality, disease-separated UMAP projections, indicating strong representational power.
9.By generating context-aware embeddings, BulkFormer improves prognosis modeling, rescuing weak prognostic signals. For example, RPS27 becomes a strong risk gene in lower-grade glioma after embedding (HR = 4.77).
10.It also enables fine-grained prediction of transcriptomic changes upon drug treatment. In compound perturbation tasks, it outperforms PRnet and scLLMs, achieving PCC = 0.493 on unseen drugs like Dovitinib.
11.For drug response prediction (IC50) across 255 compounds and 700 cell lines, BulkFormer attains top-tier performance (PCC = 0.910), showing promise for precision oncology and drug screening.
12.Finally, BulkFormer predicts gene essentiality scores with high accuracy (PCC = 0.931) from expression alone, highlighting cancer-specific vulnerabilities and informing therapeutic strategies.
13.Its rotary expression embedding method captures expression magnitude and continuity more effectively than traditional rank-based methods, improving stability and interpretability.
14.BulkFormer offers fast training—requiring just 1–10% of the GPU time compared to scLLMs—making it both cost-effective and scalable for large-scale biomedical applications.
15.Limitations include reduced applicability to single-cell tasks and lack of modeling for non-coding RNAs, but its focus on bulk-level data makes it ideal for clinical and tissue-scale analyses.
16.Future directions include multimodal foundation models for joint bulk and single-cell data, and integration of patient metadata (age, sex, tissue type) to enhance context-awareness.
💻Code: github.com/KangBoming/BulkFo… 📜Paper: biorxiv.org/content/10.1101/…
#BulkRNAseq #FoundationModel #Transcriptomics #Bioinformatics #CancerBiomarkers #AI4Biomedicine
12
17
52
5,981
18 Jun 2025
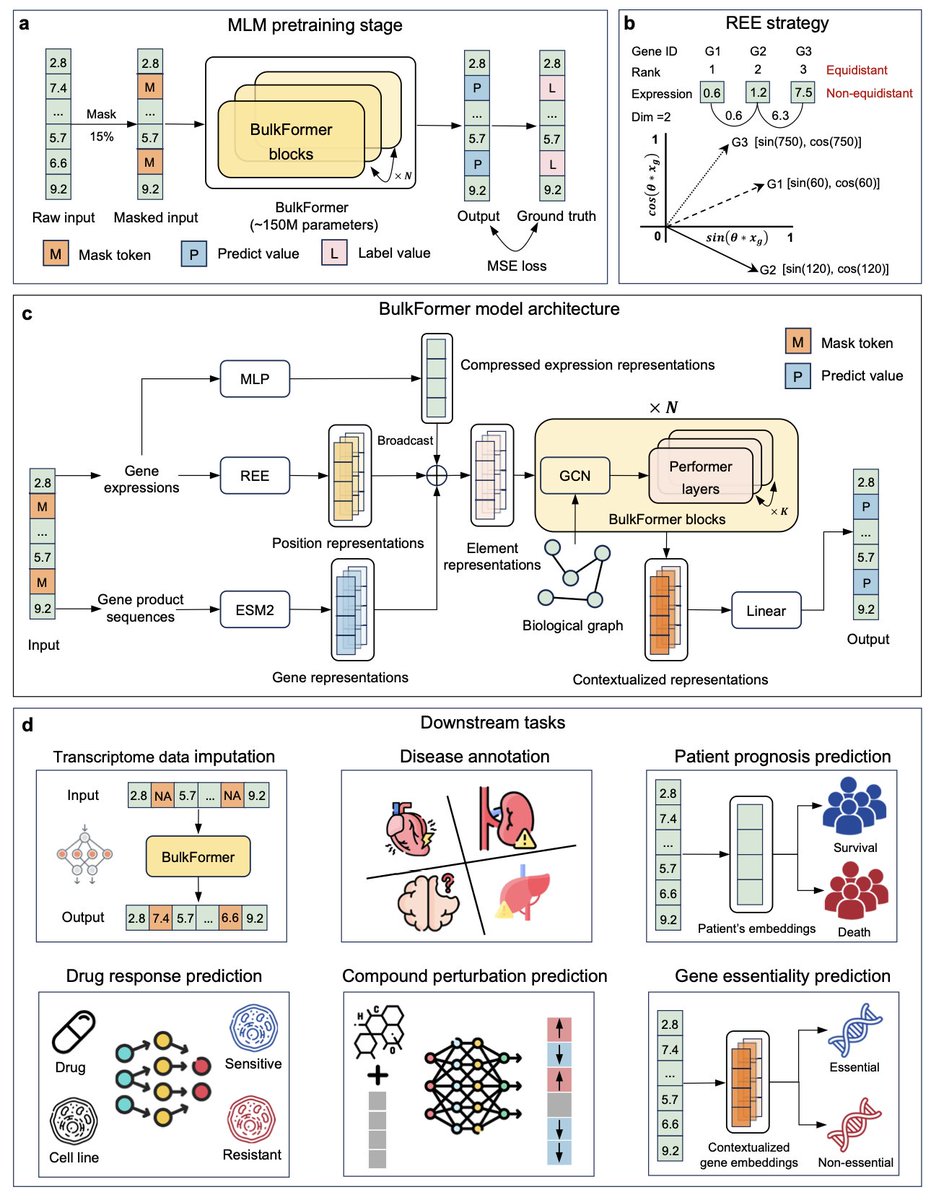
A large-scale foundation model for bulk transcriptomes
1.BulkFormer is the first large-scale foundation model designed specifically for bulk RNA-seq data, filling a critical gap left by models trained solely on sparse single-cell data.
2.It is pretrained on over 520,000 human bulk transcriptomes, modeling approximately 20,000 protein-coding genes using a hybrid encoder that integrates both graph neural networks and performer-based self-attention.
3.Despite using significantly fewer computational resources than single-cell models, BulkFormer achieves superior performance in six key tasks: transcriptome imputation, disease annotation, prognosis modeling, drug response prediction, compound perturbation simulation, and gene essentiality prediction.
4.In imputation tasks, BulkFormer reaches a Pearson correlation of 0.954 on masked gene expression recovery, outperforming variational autoencoders and single-cell foundation models, which suffer from modality mismatch.
5.Applied to pancreatic cancer data, BulkFormer recovers missing values that lead to the identification of 408 new DEGs, enriching pathways like oxidative phosphorylation—highlighting its power in uncovering latent biology.
6.The model facilitates the discovery of novel prognostic biomarkers across eight cancer types. For example, H4C1 is identified as a risk gene in kidney cancer (5.2x higher mortality), and PDE6H as protective in pancreatic cancer (HR = 0.26).
7.For disease classification, BulkFormer achieves a weighted F1 score of 0.939 across 23 diseases—substantially outperforming single-cell pretrained models like scGPT and Geneformer.
8.In cancer subtype classification across 33 cancer types, it again leads with a weighted F1 of 0.833 and yields high-quality, disease-separated UMAP projections, indicating strong representational power.
9.By generating context-aware embeddings, BulkFormer improves prognosis modeling, rescuing weak prognostic signals. For example, RPS27 becomes a strong risk gene in lower-grade glioma after embedding (HR = 4.77).
10.It also enables fine-grained prediction of transcriptomic changes upon drug treatment. In compound perturbation tasks, it outperforms PRnet and scLLMs, achieving PCC = 0.493 on unseen drugs like Dovitinib.
11.For drug response prediction (IC50) across 255 compounds and 700 cell lines, BulkFormer attains top-tier performance (PCC = 0.910), showing promise for precision oncology and drug screening.
12.Finally, BulkFormer predicts gene essentiality scores with high accuracy (PCC = 0.931) from expression alone, highlighting cancer-specific vulnerabilities and informing therapeutic strategies.
13.Its rotary expression embedding method captures expression magnitude and continuity more effectively than traditional rank-based methods, improving stability and interpretability.
14.BulkFormer offers fast training—requiring just 1–10% of the GPU time compared to scLLMs—making it both cost-effective and scalable for large-scale biomedical applications.
15.Limitations include reduced applicability to single-cell tasks and lack of modeling for non-coding RNAs, but its focus on bulk-level data makes it ideal for clinical and tissue-scale analyses.
16.Future directions include multimodal foundation models for joint bulk and single-cell data, and integration of patient metadata (age, sex, tissue type) to enhance context-awareness.
💻Code: github.com/KangBoming/BulkFo…
📜Paper: biorxiv.org/content/10.1101/…
#BulkRNAseq #FoundationModel #Transcriptomics #Bioinformatics #CancerBiomarkers #AI4Biomedicine
1
4
711

11 Jan 2025
Go back in time....
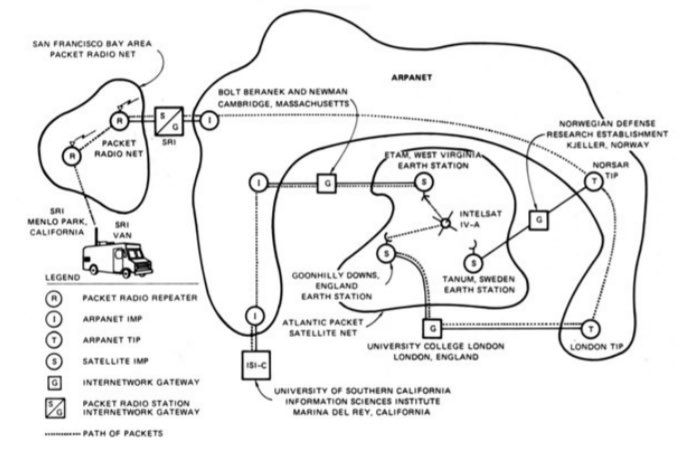
SATNET, also known as the Atlantic Packet Satellite Network, was an early satellite network that formed an initial segment of the Internet.
The first heterogeneous computer network was implemented in 1973, connecting the ARPANET to University College London. This evolved into SATNET. The first Transmission Control Program demonstration, linking SATNET, the ARPANET, and PRNET took place on November 22, 1977.
Work from here forward.......
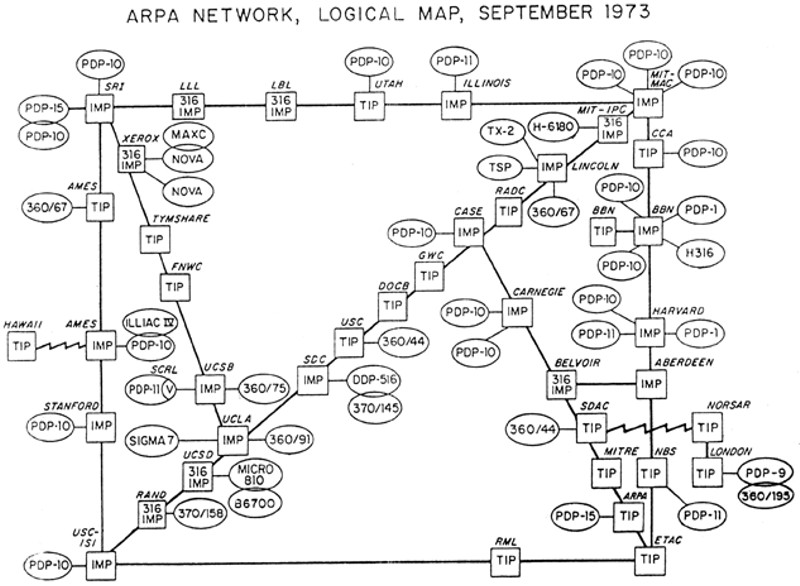
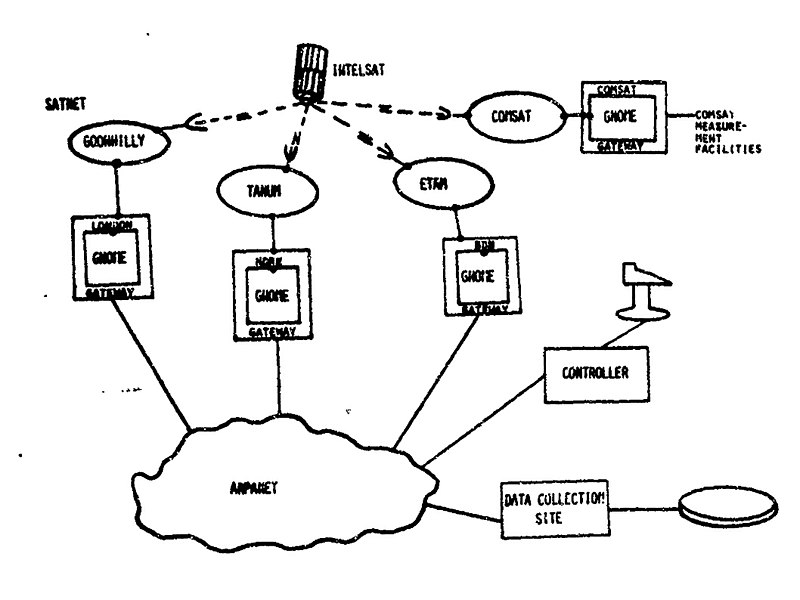
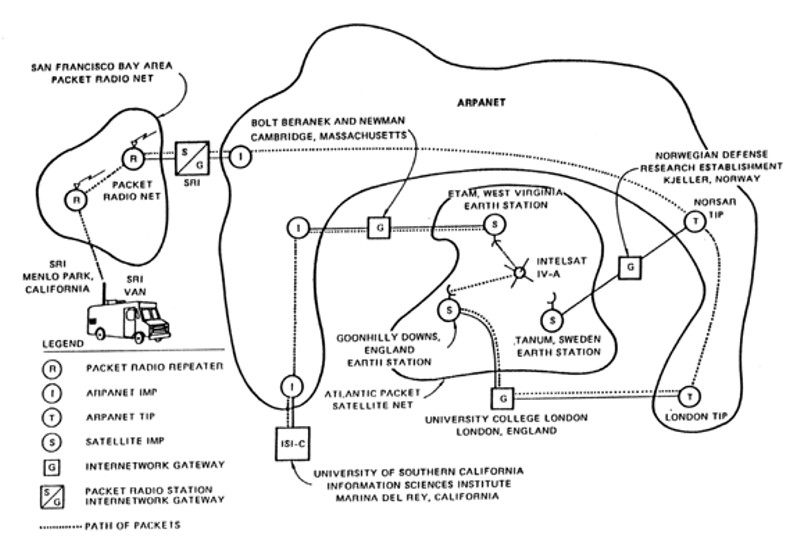
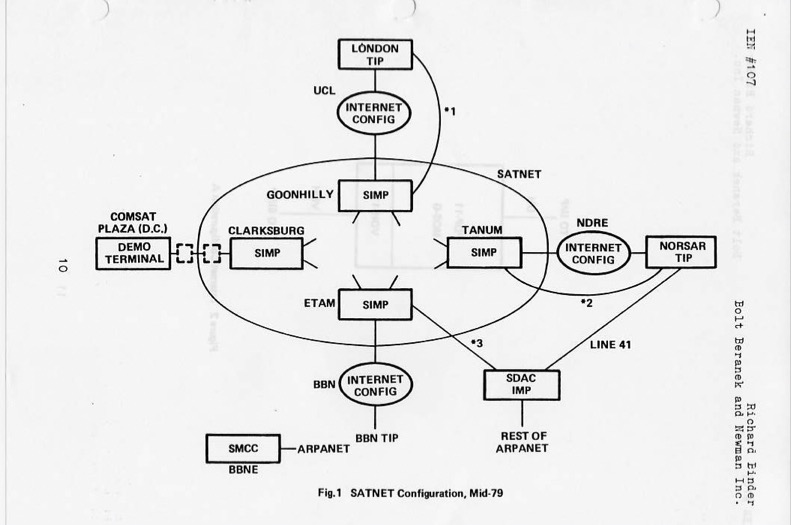
2
44

9 Jan 2025
【イベント情報】
AIで成果直結!売上急増インスタ運用戦略
生成AIを活用したInstagram運用法を学べるセミナー✨
売上に繋がる投稿術や最新SNSトレンドを徹底解説💪
講師は㈱PRNET上村菜穂さん
日時:1月23日(木)19:00~20:00
形式:オンライン
参加費:無料
rokugobase.com/event/3297/
@nahouemura
5
421



28 Oct 2024
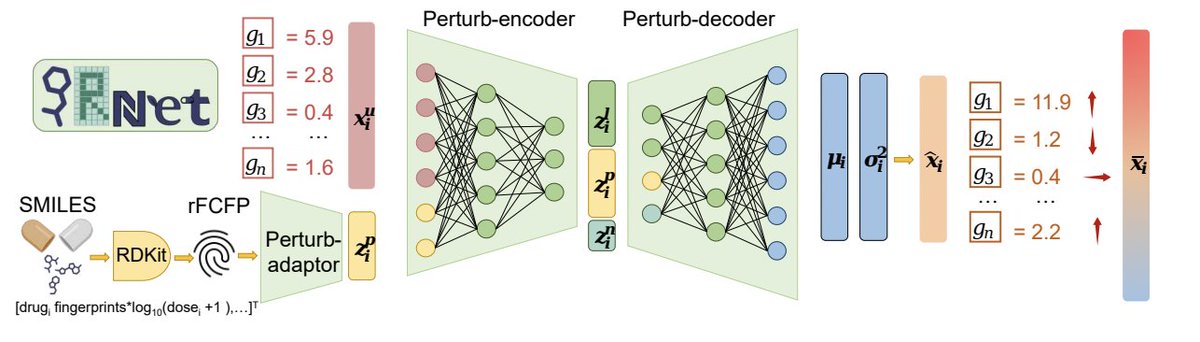
Generative AI in drug discovery: Predicting cellular responses to new compounds
Accurately predicting how cells respond to new compounds is essential for advancing drug discovery. However, traditional lab-based screening of numerous compound combinations is both costly and time-intensive. Generative AI is now transforming this process.
Recently introduced in Nature Communications by Qi and coauthors, a model named PRnet leverages a perturbation-conditioned generative model—a type of model trained to generate predictions conditioned on specific perturbations, such as the introduction of a new compound. This allows PRnet to predict transcriptional responses to novel chemical compounds across various cell types and disease pathways.
PRnet is able to perform in-silico compound screening, creating a "perturbation atlas" that maps predicted cellular responses across 88 cell lines, 52 tissues, and tens of thousands of compounds.
Paper: nature.com/articles/s41467-0…
Preprint: researchsquare.com/article/r…
24
90
7,871

20 Jul 2024
انٹرنیٹ کی ایجاد
انٹرنیٹ کس نے ایجاد کیا
انٹرنیٹ کی ایجاد کئی لوگوں کی مشترکہ کوششوں کا نتیجہ ہے اور کسی ایک شخص کی محنت نہیں ہے، مگر انٹرنیٹ کا ابتدائی تصور ایجاد کرنے کا سہرا لیونارڈ کلینروک کے سر جاتا ہے۔ انہوں نے 31 مئی 1962ء کو اپنا پہلا مقالہ "بڑی مواصلاتی نیٹ ورکس میں معلومات کا بہاؤ" کے عنوان سے شائع کیا۔ کلینروک اور لیکلیڈر کے خیالات کی مدد سے انہوں نے "ARPANET" کے نام سے مشہور نیٹ ورک کا تصور پیش کیا۔
انٹرنیٹ کی ترقی
انٹرنیٹ کی ایجاد کا عمل 1960ء کی دہائی کے آخر میں کیلیفورنیا، امریکہ میں شروع ہوا۔ وہاں "NWG" نیٹ ورک ورکنگ گروپ تشکیل دیا گیا جس کا پہلا اجلاس 1968ء میں اسٹینفورڈ ریسرچ انسٹیٹیوٹ میں ایلمر شاپیرو کی صدارت میں ہوا۔ اس گروپ نے میزبانوں کے درمیان رابطہ قائم کرنے کے طریقوں پر غور کیا۔ 1968ء میں ایلمر شاپیرو نے "کمپیوٹر نیٹ ورک ڈیزائن پیرامیٹرز کا مطالعہ" کے عنوان سے ایک رپورٹ جاری کی۔ اس رپورٹ اور دیگر لوگوں کی کوششوں کی بنیاد پر لورنس رابرٹس اور باری ویزلر نے IMP میسج انٹرفیس کی وضاحتیں تیار کیں، اور بعد میں بولٹ برینک اور نیومانٹ کو IMP سب نیٹ ورک کے ڈیزائن اور تعمیر کے لئے ٹھیکہ دیا گیا۔
نیٹ ورکس کا انضمام
1973ء میں انجینئروں نے ARPANET کو ریڈیو نیٹ ورک PRNET سے جوڑنے کا طریقہ تلاش کرنا شروع کیا۔ ریڈیو نیٹ ورک کمپیوٹروں کو وائرلیس ٹرانسمیٹرز اور ریسیورز کے ذریعے جوڑتا تھا، جس سے ٹیلیفون لائنز کے بجائے ریڈیو لہروں کے ذریعے معلومات کی ترسیل ممکن ہوتی تھی۔ یہ کام تقریباً تین سال لگا اور انجینئروں نے دونوں نیٹ ورکس کو جوڑنے میں کامیابی حاصل کی۔
ورلڈ وائڈ ویب
1990ء میں ٹم برنرز لی نے انٹرنیٹ پر نیویگیشن کو آسان بنانے کے لئے ایک نظام ڈیزائن کیا، جو بعد میں "ورلڈ وائڈ ویب" کے نام سے مشہور ہوا۔ انٹرنیٹ نے عالمی سطح پر کمپیوٹر نیٹ ورکس کو جوڑنے کا کام کیا اور ورلڈ وائڈ ویب کے استعمال سے ان نیٹ ورکس کے درمیان نقل و حرکت آسان ہوگئی۔
انٹرنیٹ کی عوامی قبولیت
ابتدائی طور پر انٹرنیٹ کا استعمال حکومتی ملازمین، فوجی افسران، گریجویٹ طلباء اور سائنسدانوں تک محدود تھا۔ ورلڈ وائڈ ویب کے آنے کے بعد انٹرنیٹ کی رسائی میں خاطر خواہ اضافہ ہوا۔ یونیورسٹیاں اور کالج انٹرنیٹ سے جڑنے لگے اور جلد ہی کاروباری ادارے بھی اس کا استعمال کرنے لگے۔ 1994ء تک انٹرنیٹ تجارت کی ایک حقیقت بن چکی تھی۔
انٹرنیٹ کی پیچیدگی
آج انٹرنیٹ پہلے سے کہیں زیادہ پیچیدہ ہے۔ یہ کمپیوٹرز، سیٹلائٹس، موبائل آلات اور دیگر بہت سے آلات کو ایک بڑی نیٹ ورک کے ذریعے جوڑتا ہے۔
انٹرنیٹ کی تاریخ
انٹرنیٹ کی تاریخ کو چند نکات میں بیان کیا جا سکتا ہے:
1. بیلجیئم کے معلوماتی ماہر پال اوٹلیٹ نے 1930ء کی دہائی میں انٹرنیٹ کے خیالات پیش کیے۔ اوٹلیٹ نے وضاحت کی کہ کیسے لوگ ایک دن اس نیٹ ورک کو پیغامات بھیجنے، فائلیں شیئر کرنے اور سوشل سینٹرز میں اکٹھا ہونے کے لئے استعمال کر سکیں گے۔
2. موجودہ انٹرنیٹ کی شروعات 1960ء کی دہائی کے آغاز میں ہوئیں جب لیکلائیڈر نے عالمی نیٹ ورکس پر اپنی منفرد خیالات کو ایک سلسلہ نوٹ میں پیش کیا۔
3. 1969ء میں ARPANET کے ذریعے کلینروک کی لیبارٹری اور اسٹینفورڈ ریسرچ انسٹیٹیوٹ کے درمیان پہلی بار رابطہ قائم ہوا۔
4. 1980ء کی دہائی میں نیشنل سائنس فاؤنڈیشن نے اپنے سپر کمپیوٹروں کو ملک گیر سطح پر جوڑنے کے لئے ایک کمپیوٹر نیٹ ورک کی تعمیر شروع کی جو وزارت دفاع کی ضروریات سے بڑھ کر تھی۔
5. 1990ء میں ARPANET کو سرکاری طور پر بند کر دیا گیا کیونکہ NSF نے حکومتی فنڈنگ سے آزاد ایک نیٹ ورک کی تعمیر کا ارادہ کیا۔ 1991ء سے 1995ء تک انٹرنیٹ کو سرکاری طور پر نجی شعبے کے حوالے کر دیا گیا اور یہ تقریباً 50,000 نیٹ ورکس پر مشتمل تھا جو سات براعظموں اور خلا تک پھیلا ہوا تھا۔
انٹرنیٹ کی اہمیت
انٹرنیٹ نے تعلیم، تجارت، صحت، تفریح اور دیگر بہت سے شعبوں میں انقلاب برپا کر دیا ہے۔ تعلیم کے میدان میں، انٹرنیٹ نے معلومات تک رسائی کو آسان بنا دیا ہے اور آن لائن کورسز اور ویبینارز کے ذریعے تعلیم حاصل کرنا ممکن بنا دیا ہے۔ تجارت میں، ای کامرس کی بدولت لوگ گھر بیٹھے خرید و فروخت کر سکتے ہیں، جس سے کاروباری دنیا میں ایک نیا موڑ آیا ہے۔
معلومات اور معلوماتی تکثیر
انٹرنیٹ نے معلومات کی کثرت کو ایک نئے انداز میں پیش کیا ہے۔ گوگل اور دیگر سرچ انجنوں کی بدولت، کسی بھی موضوع پر معلومات حاصل کرنا محض چند کلکس کی دوری پر ہے۔ یہ معلوماتی انقلاب لوگوں کو خود مختار بناتا ہے، جس سے وہ اپنی معلوماتی ضروریات کو خود پورا کر سکتے ہیں۔
#AbdulQadeer

5
6
232

14 Mar 2023
We are PROUD and THRILLED to announce that @MayhemEntrPR has been selected to be a part of this year's @theprnet's 2023 Next Gen list. We are among the honorees who are bringing forth excellence and creativity while showcasing diversity in the public relations industry. With every campaign we bring forth, our MEPR team is shaping a bright future for the world of COMMS. Thank you for this honor and we hope to continue to contribute innovative ideas while striving to break the glass ceiling for publicists of color 🖤🤍 theprnet.com/journals/the-pr…. #MayhemEntertainmentPR #NextGen #PRNet #PRNetNextGen #honoree #2023NextGenList #2023nextgen #PRFirm #blackowned #publicity #publicists #PR


1
3
51

17 Nov 2022
As real estate developments boom across the nation, how can #PR pros make clients stand out?
Our Managing Director @jsoffin spoke with #PRNet on how to make a property hot in the eyes of the media. 🔥
theprnet.com/journals/what-m…
2

3 Oct 2022
#MeetOurParticipants #45 Shahin S Eity, PRNet Development Executive at @Erasmus_Mundus.
“Our culture is as our reflection in water; changes with flows, connects against all odds.”

1

30 Sep 2022
PRNET, ARPANET and SATNET been linked by prototypical TCP — traffic routed via London and back to California
2

3 Jun 2022
You’re kinda proving my point.
Less than 10 years after ARPNET was developed it was connected to PRNET and SATNET.
Less than 10 years and computers on disparate systems were able to talk to each other, without cables, in different countries, via machines in SPACE 🤯
1

18 Feb 2022
What were the PRNet volunteers up to in 2021? 🤷
👉Find out more on our blog: em-a.eu/post/prnet-activitie…
And share if you're one of EMA's PRNet volunteers! 💙
#Erasmus #ErasmusMundus
1
1
5