
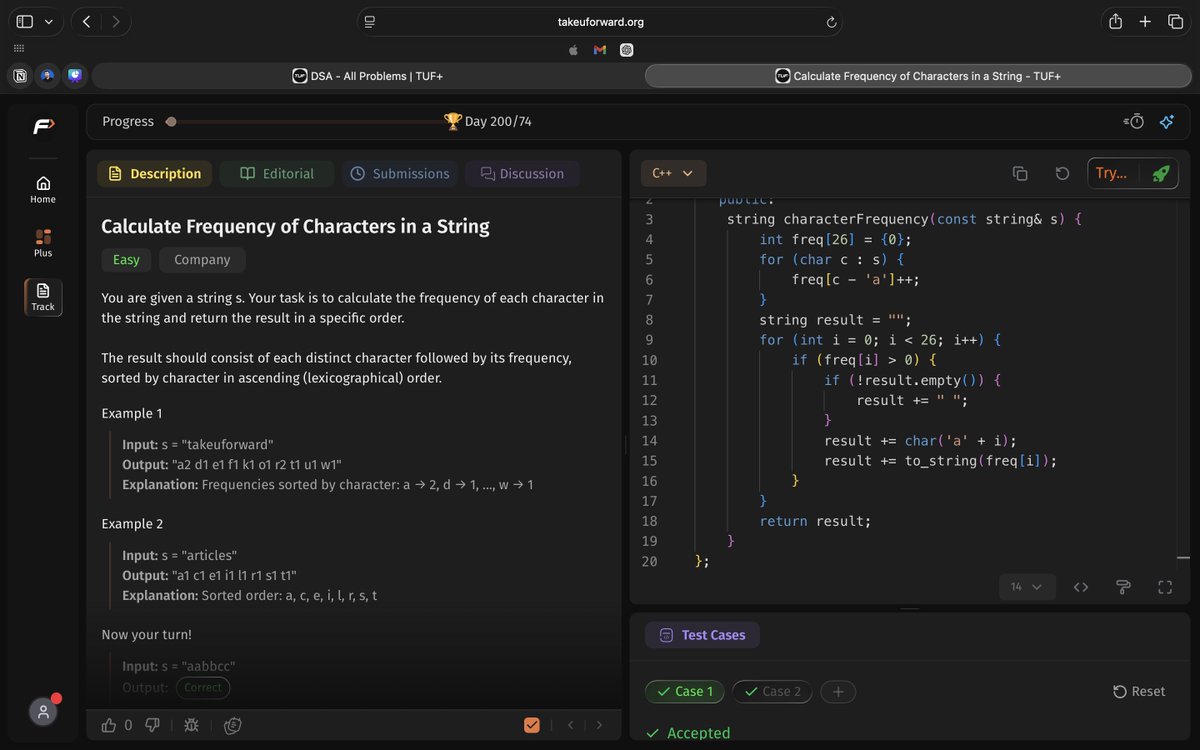
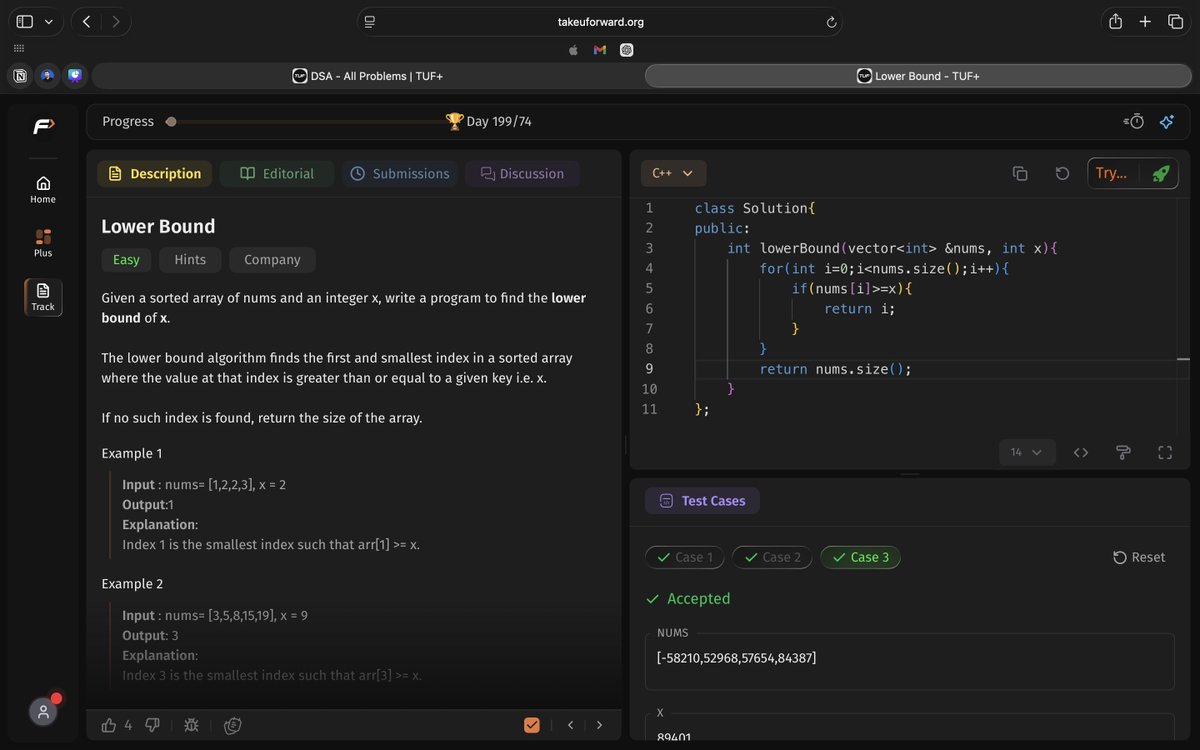
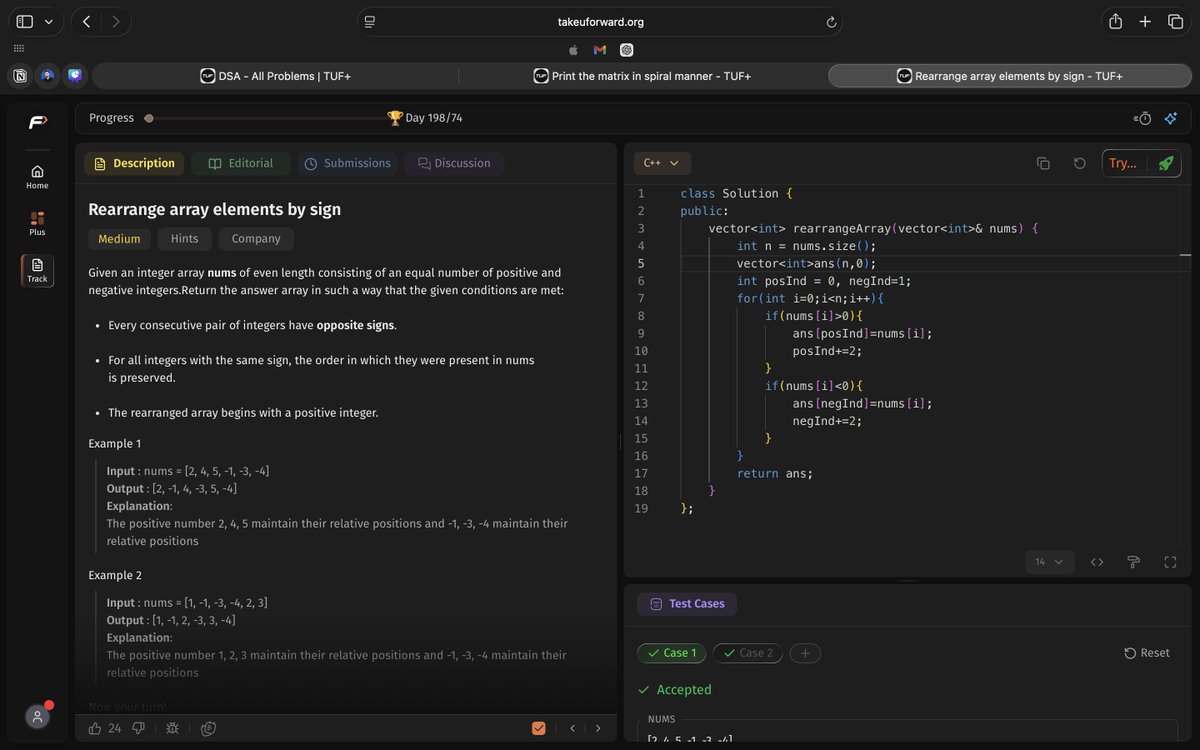
Today I did 1 sliding window question on leetcode 643, the rough work I did before jumping on leetcode @kunalstwt #publicLearning #Dsa
#slidingWindow

4
49

Feb 24
not much of the work done. but something is always better than NOTHING #100daysofcode #publiclearning #dsa #coding #100dayslearn #learn
1
6
68

Feb 19
Is QK Norm fighting the Muon Optimizer in LLM training? 📉
I’ve been researching the relationship between Query-Key Normalization (QK Norm) and the Muon optimizer, and the preliminary results regarding "Dimension Collapse" are fascinating.
Here is what the data is showing so far:
1. The Phenomenon of Dimension Collapse
In an attention head with 128 dimensions, the model often only utilizes about 51–65 of them. The rest tend to collapse to zero or near-zero during training.
2. The Impact of Gamma (Scaling)
I ran three training runs to test this:
No QK Norm: Moderate dimension collapse.
QK Norm (Fixed Gamma): Worst collapse. It seems Muon and the norm might be "fighting" each other here.
QK Norm (Learnable Gamma): Best results with the fewest collapsed dimensions. The learned Gamma likely stretches those small dimensions so they remain relevant.
3. The Loss Paradox
Here is the interesting part: Despite the dimension collapse issues, using QK Norm always resulted in better loss compared to removing it entirely.
What’s Next?
Based on feedback from a PhD student at Peking University, my next experiment involves forcing attention heads to be orthogonal to each other to potentially prevent this collapse and reduce wasted compute.
Takeaway:
Don’t hoard your ideas. By sharing these early, raw findings, I’m getting rapid feedback that accelerates the research.
Has anyone else experienced this friction between Muon and Normalization layers?
Thank you @novita_labs for providing compute for this research.
#AIResearch #LLM #MachineLearning #DeepLearning #MuonOptimizer #PublicLearning
3
38
2,862

Right now, I only know Excel, but most job postings ask for SQL, Python, and dashboards like Power BI.
Question for fellow learners: Should I start my first portfolio project with Excel or try Python from day one?
#publiclearning #DataAnalytics
3
42

14 Dec 2025
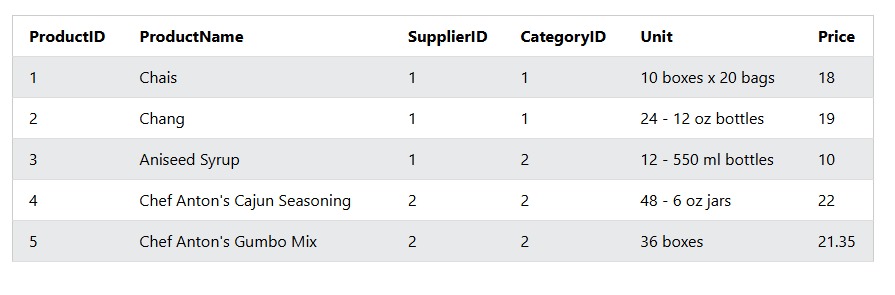
Using the AVG() function in a Sub query,to select all products that is higher than the average price in the product table .
💥 second slide is the Demo of the Product Table
#DataAnalytics
#DataDriven
#womeninSTEM
#publiclearning
2
34

18 Nov 2025
Day 1/100
Documenting my journey in cyber Security
#100DaysOfCyberSecurity #PublicLearning
@cybergirl_io @commando_skiipz @h4ruk7



4
56

3 Sep 2025
Hey connections! I have completed a very long DSA Challenge on GFG Platform for 160 days💻
Greatfull to share this with you all🌟
#gfg160days #GFG #publiclearning #dsa #java #Practice #consistency #growth #placements #learning #160daysofdsa #achieved

5
17
478


24 Jul 2025
🚀 Day 18 – DSA with @rohit_negi9
String Manipulation 🔤
1️⃣ Add String
2️⃣ Sort Vowels in a String
3️⃣ Case-specific Sorting
💡 Strings aren't simple — but patterns make them solvable!
#DSA #30DaysOfCode #DSAWithRohitNegi #StringProblems #PublicLearning
2
17
12 Jul 2025
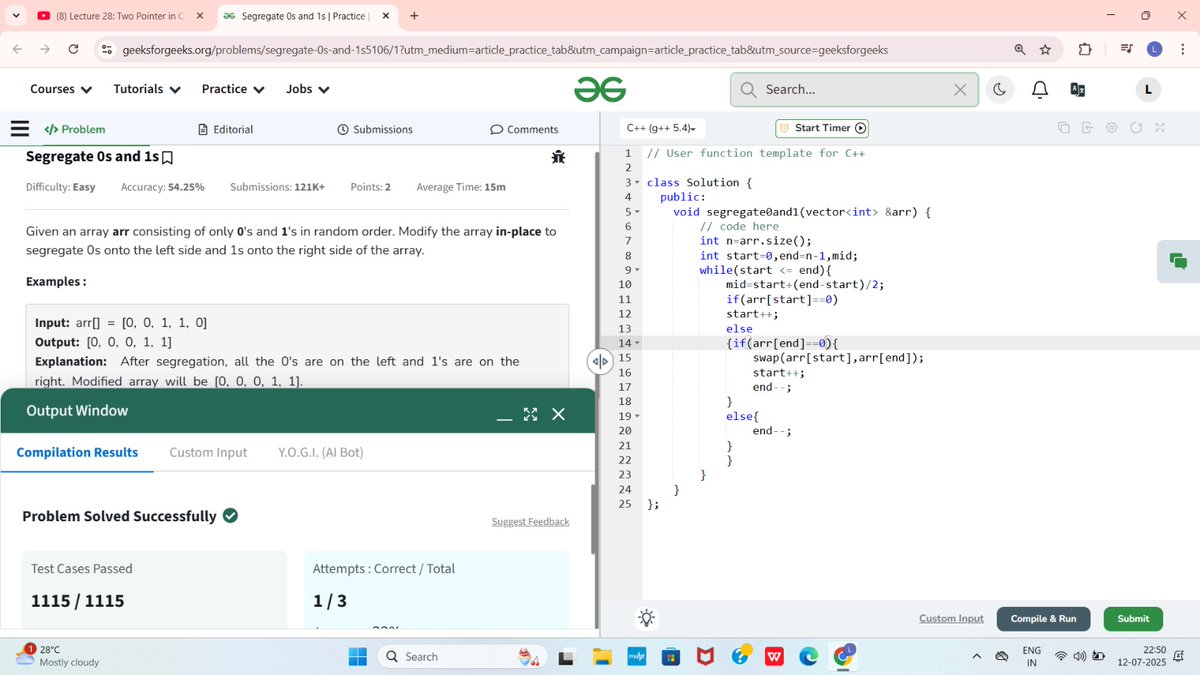
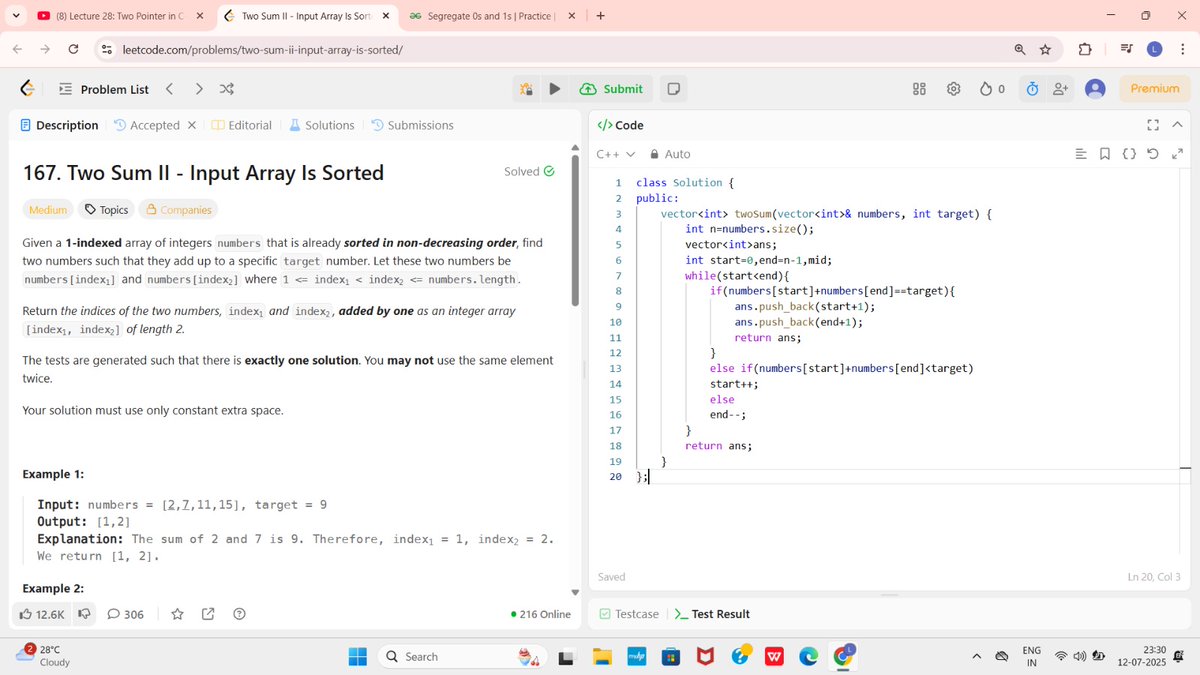
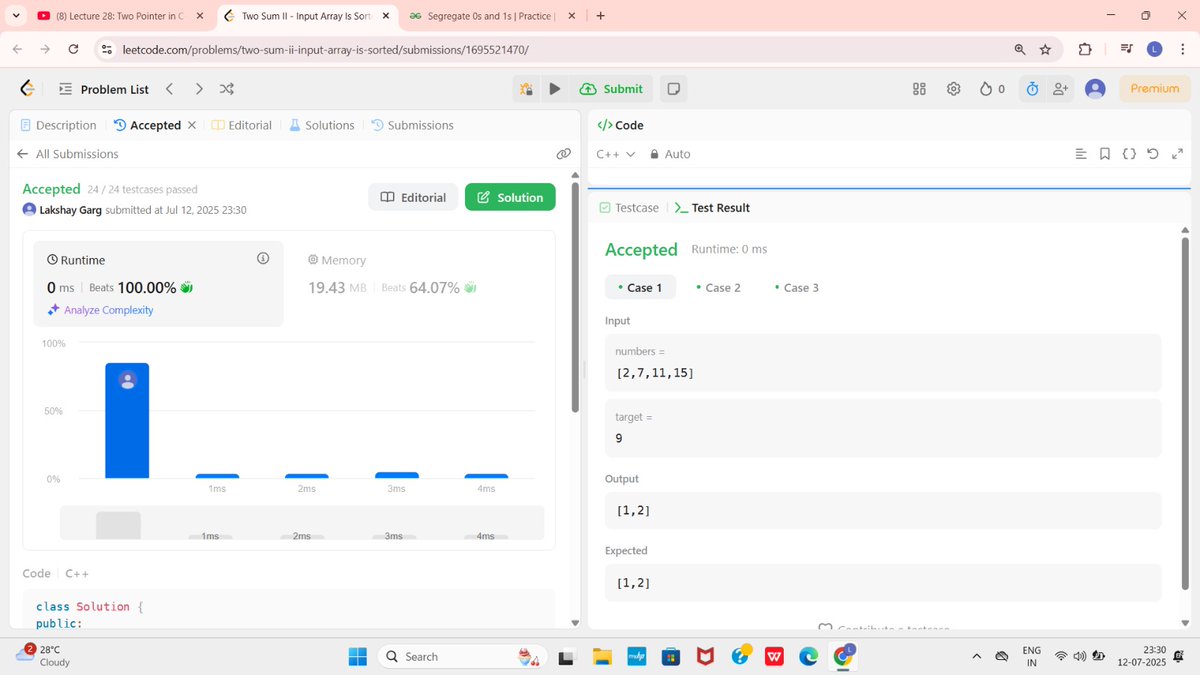
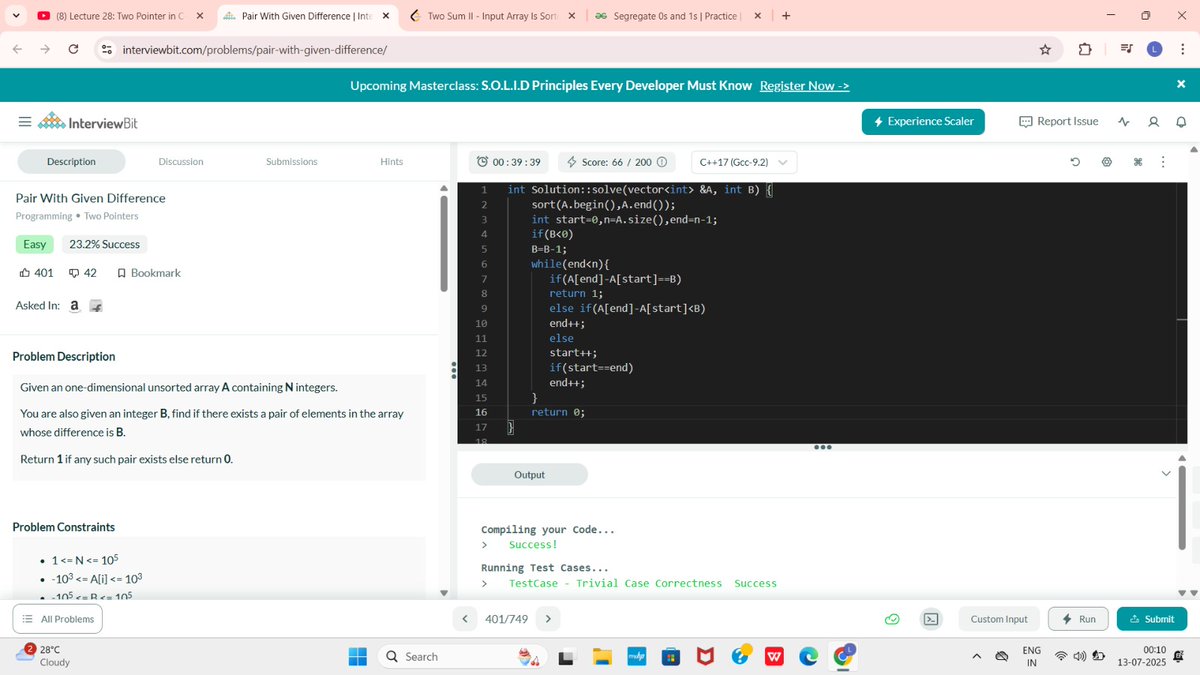
Day 13 – DSA with @rohit_negi9
🔄 Segregate 0s & 1s (2-pointer magic)
➕ Two Sum (Hash it!)
➖ Pair with Given Difference (logic > brute force)
Easy-looking problems… that teach deep lessons 📚
#DSA #PublicLearning #Hashing #MenWhoCode #30DaysOfCode #DSAWithRohitNegi
1
2
57

11 Jul 2025
DAY 19/60 LEARNING DATA ANALYSIS & LANDING A JOB.
Concluded Excel phase with this project, walked through the entire analytical process which included, Data cleaning, visualization using pivot tables, charts, dashboard and analyzes.
#publiclearning
#60daysoflearningdataanalysis
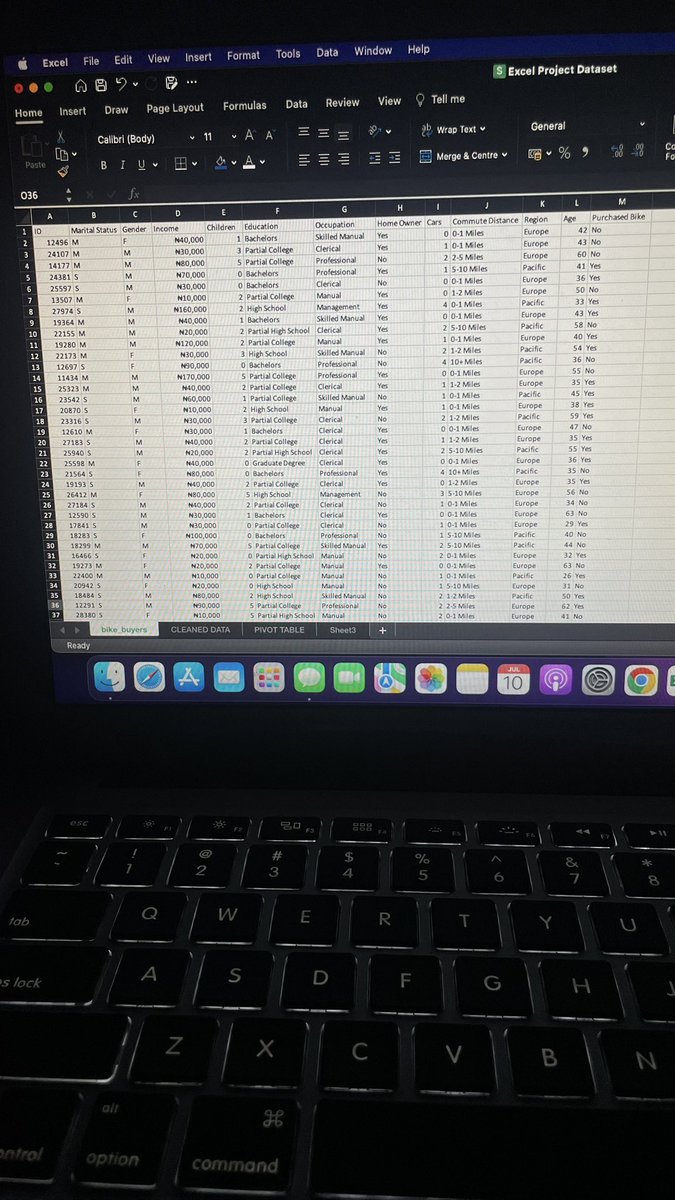
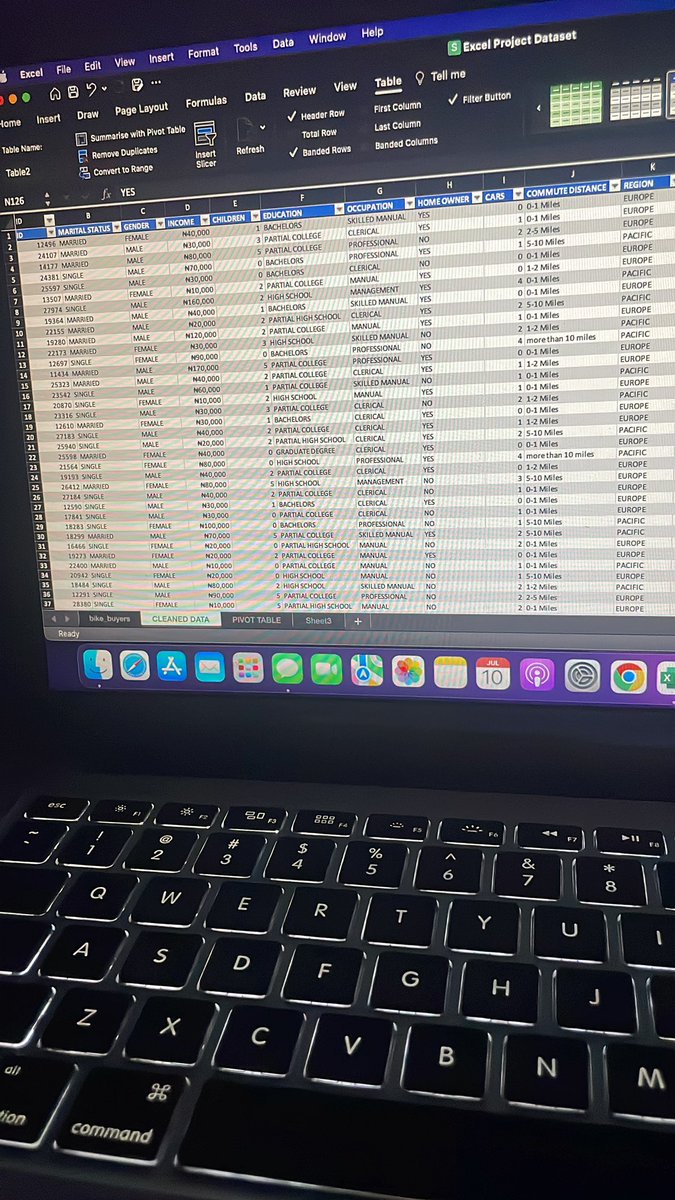
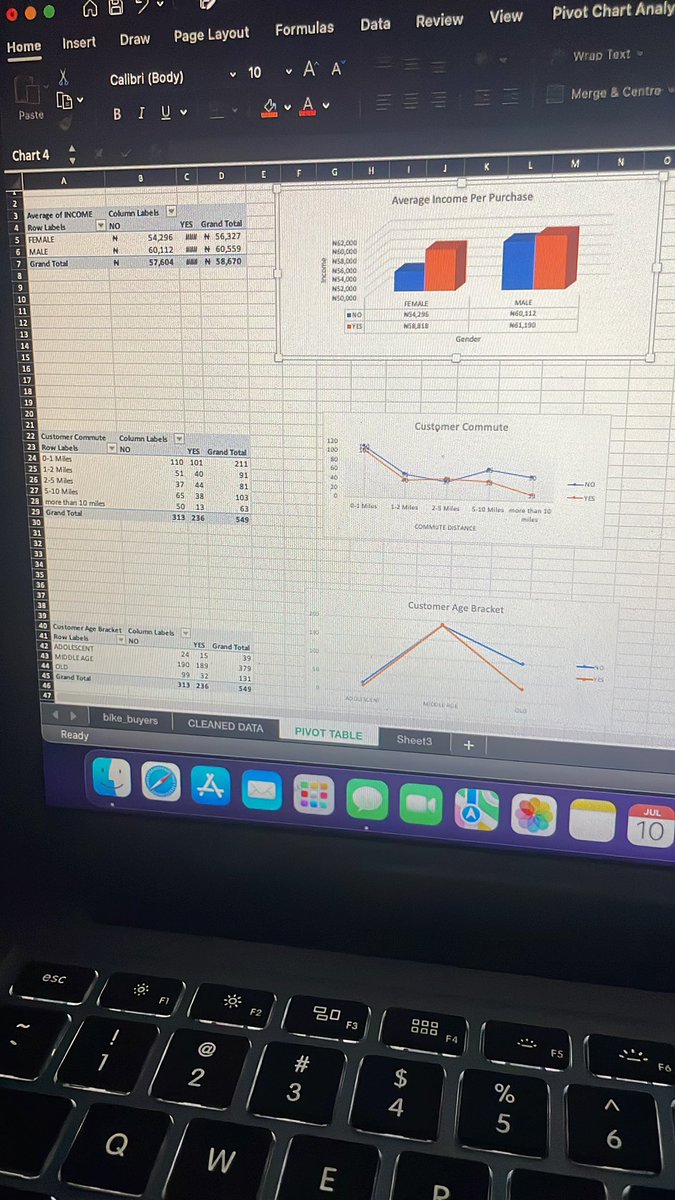
4
5
20
3,580

9 Jul 2025
DSA with @rohit_negi9
✅ Problems solved today:
🔹 Subset
🔹 Generate Parentheses
🔹 Subset Sum
🔹 Perfect Sum
🧠 Exploring recursion - to build strong problem-solving skills!
#DSA #Recursion #Leetcode #GFG #CoderArmy #RohitNegi #PublicLearning #DayWithCoding
3
29
9 Jul 2025
🚀 Day 12 – DSA with @rohit_negi9
✅ STL practice:
• count() → Occurrences
• max_element() / min_element()
• lower_bound() upper_bound()
• Passing vector to a function
🧲 Bonus: Magnetic Force Between Balls
➡️ Binary Search
#DSA #STL #BinarySearch #PublicLearning
2
71
8 Jul 2025
🚀 Day 11 – DSA with @rohit_negi9
🐄 Aggressive Cows
🍌 Koko Eats Bananas
📦 Split Array - Minimize Max Subarray Sum
Binary Search on the answer space is 🔥
It’s not about finding a number, it’s about finding the limit.
#DSA #30DaysOfCode #PublicLearning #BinarySearchOnAnswer
3
30

1 Jul 2025
#Day92 of #100DaysOfCode
- solved one question on #leetcode
- rivision of #docker
- study about basics of #django
#learninpublic #publiclearning #AppDevelopment #DSA

1
5
80

13 Jun 2025
Quiz Summary - DOM Events = 100%
#JavaScript #SoftwareEngineering #Coding #FrontEnd #MechanicalEngineer #SoftwareEngineer #PublicLearning
Aur ek kirkiri khatam! One more lesson (TASK) is completed! #SelfLearning 😤
ALT Quiz Summary - DOM Events = 100% #SelfLearning #JavaScript #SoftwareEngineering #Coding #FrontEnd #MechanicalEngineer #SoftwareEngineer #PublicLearning
1
2
112
9 Jun 2025
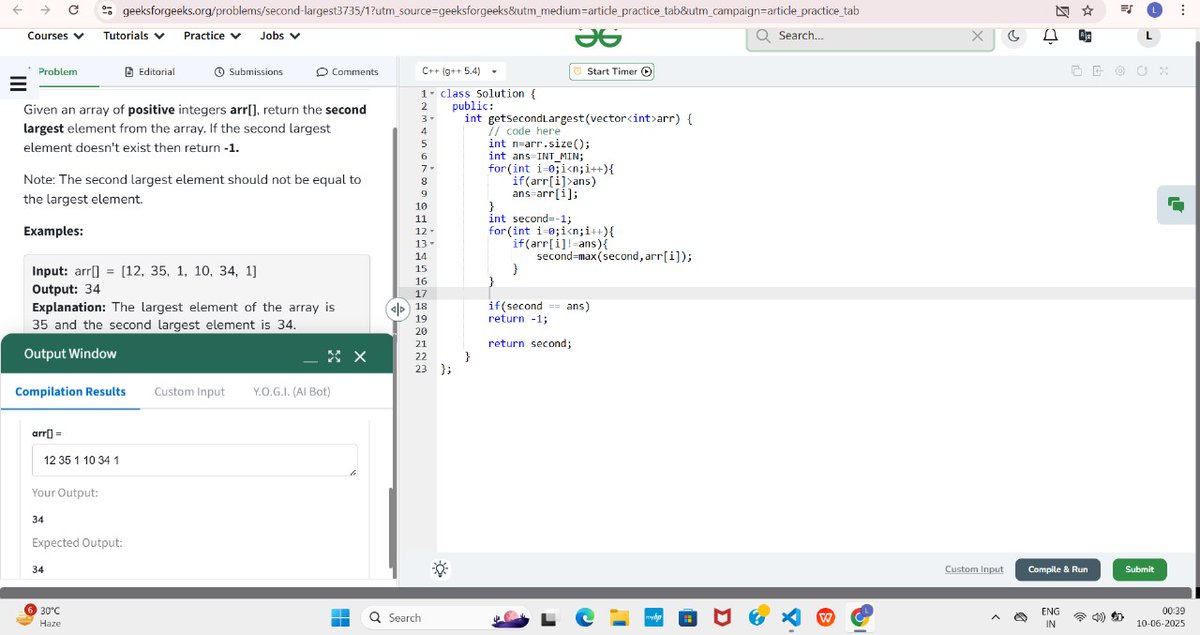
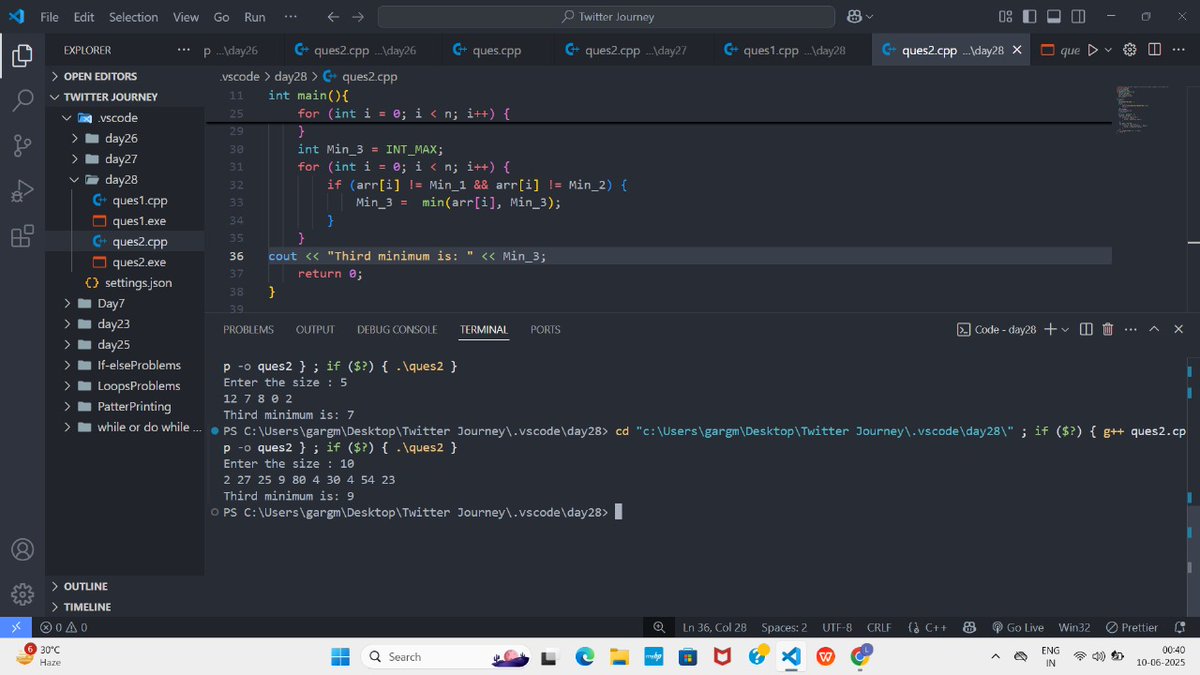
🚀 Day 28 of 30: DSA with @rohit_negi9
✅ Solved:
🔢 Find second largest number in array
🔻 Find third smallest number
💡 Sorting edge case checks = sharp thinking!
Drop a 🧠 if you’ve solved these too!
#30DaysChallenge #DSA #Arrays #Sorting #PublicLearning #CoderArmy

3
48

Here to share raw thoughts, lessons in real-time, and uncommon insights.
If that clicks with you —
Hit follow. I might follow back. Or just drop something valuable in your feed.
Your call. 🎯
#AnonVibes #PublicLearning #DigitalJournal #ThinkingOutLoud
2
7
224
2 Jun 2025
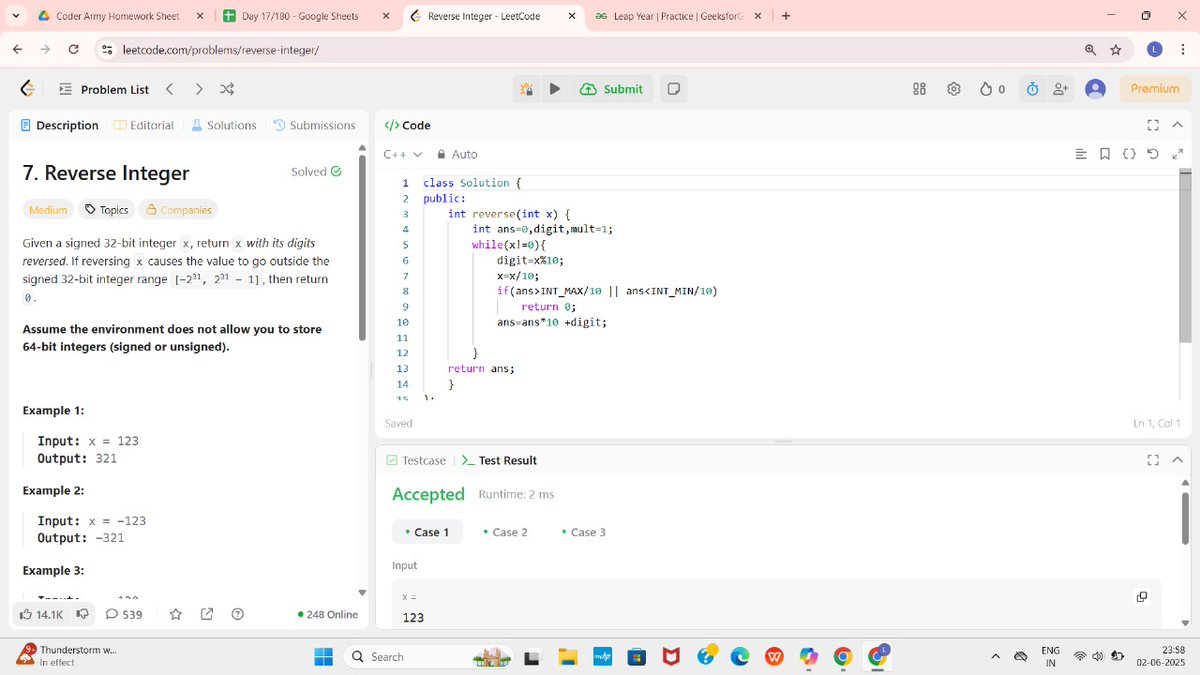
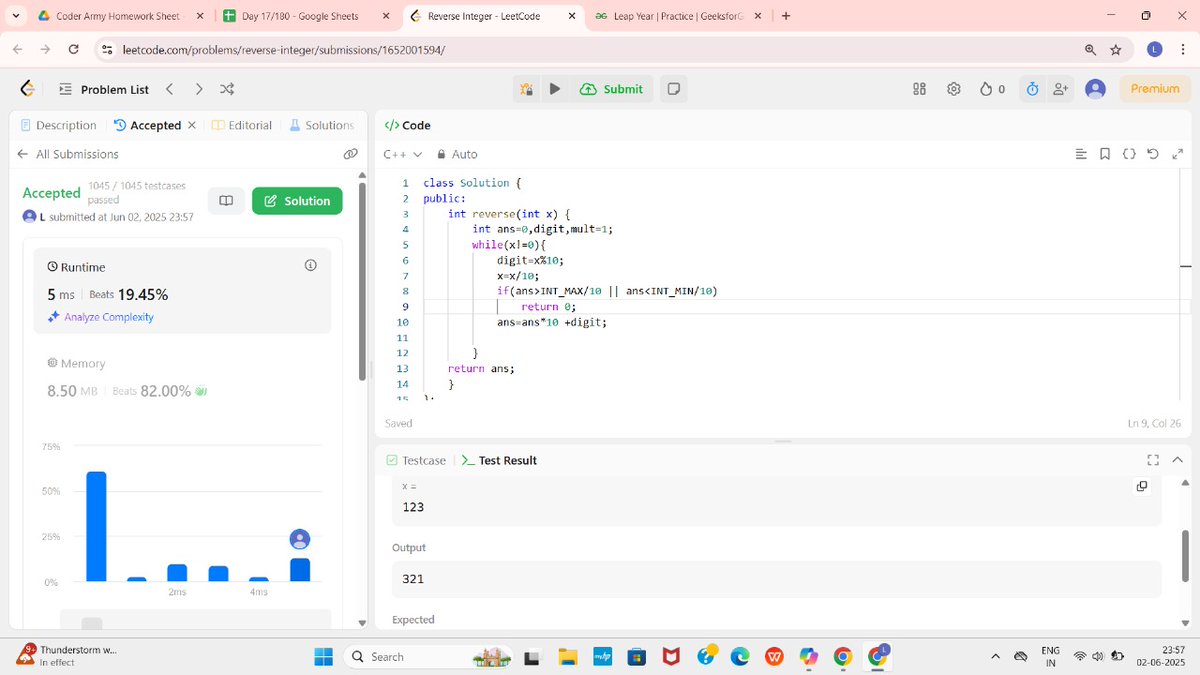
🚀 Day 21 of 30: DSA with @rohit_negi9
✅ Solved:
🔁 Reverse a number
➕ Add two numbers
💡 Refreshing the basics to build stronger logic!
Drop a 🔢 if you’re revisiting fundamentals too.
#30DaysChallenge #DSA #NumberLogic #PublicLearning #CoderArmy
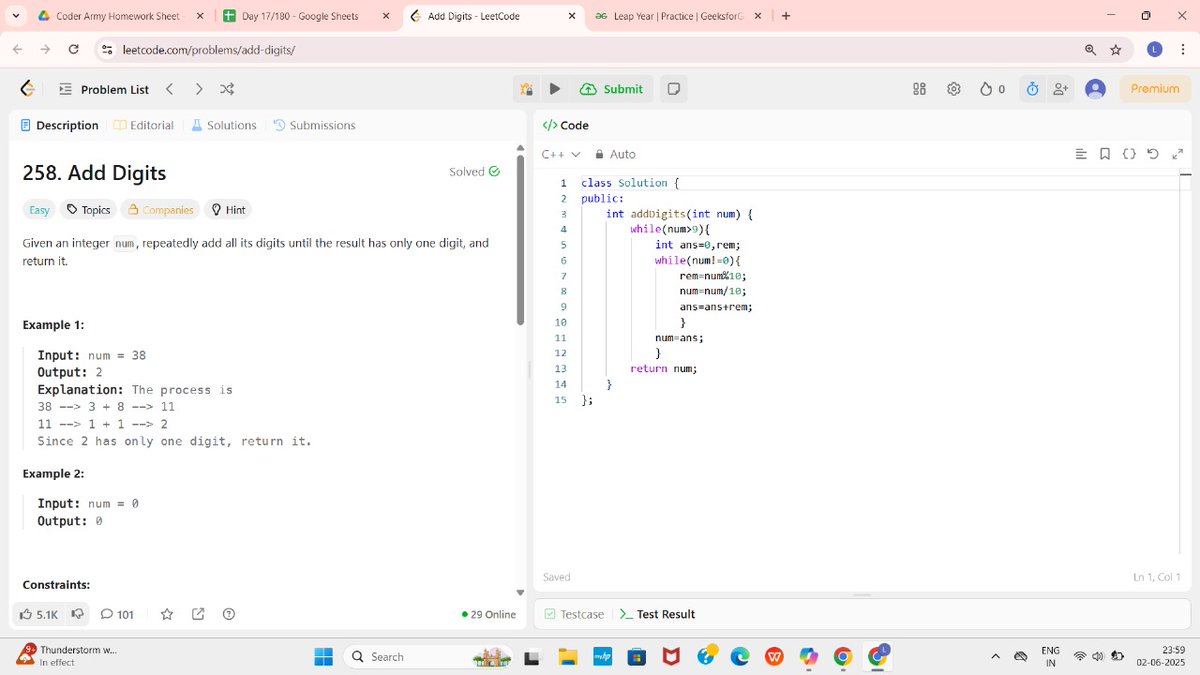
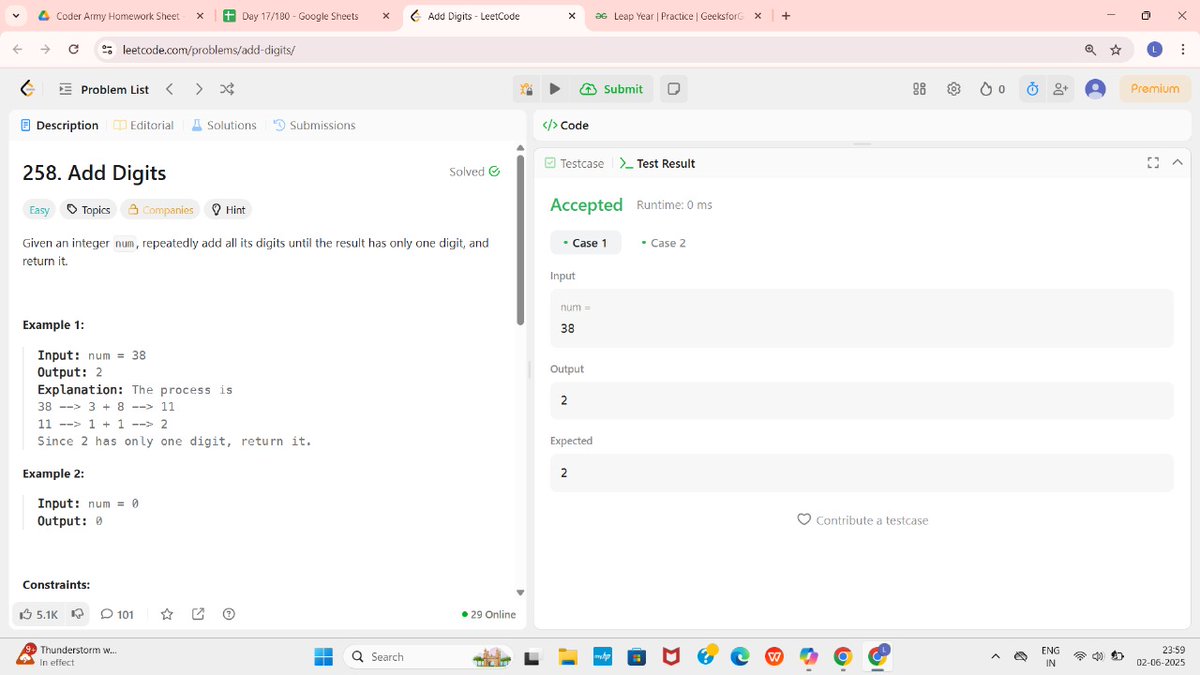
4
61
1 Jun 2025
Test Summary - JavaScript and the DOM = 100%
#SelfLearning #JavaScript #SoftwareEngineering #Coding #FrontEnd #MechanicalEngineer #SoftwareEngineer #PublicLearning
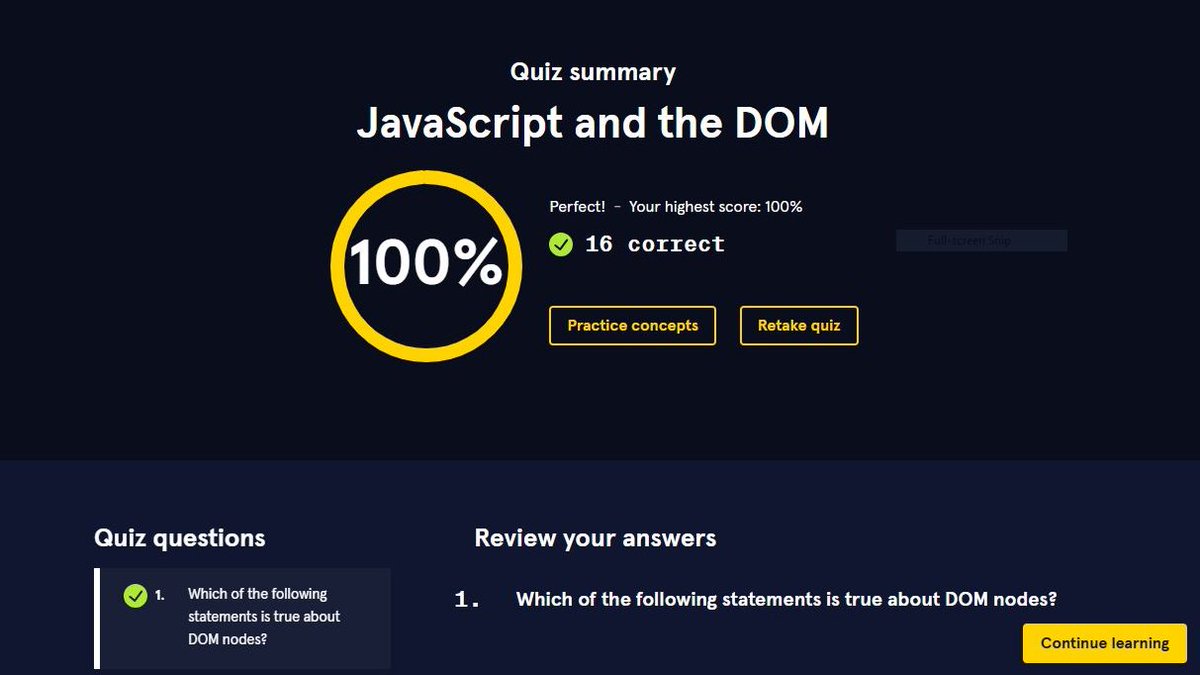
ALT Test Summary - JavaScript and the DOM = 100% #SelfLearning #JavaScript #SoftwareEngineering #Coding #FrontEnd #MechanicalEngineer #SoftwareEngineer #PublicLearning
1
3
71