
Compatible with Scanpy, scVI, scANVI out of the box. Code is public.
Paper: doi.org/10.70401/EXO.2026.00…
Code: github.com/surPoudel/STAMP_d…
Working with spatial or multimodal single-cell data? trinobia.com/contact/
#SpatialTranscriptomics #Bioinformatics
1

Jun 11
Yes, they fixed the pseudocount issue for fold-change which is good. Although despite trying we were unsuccessful in the Seurat and Scanpy teams coordinating their defaults and other implementation details following sciencedirect.com/science/ar…
2
20
Shaun Jackman retweeted
Jun 10
The standard normalization is log(x/s*K 1) w/ K=10,000 in Seurat and Scanpy. It's been used in hundreds of thousands of studies. AI agents nowadays run it routinely.
In an expansive benchmark in @naturemethods, Ahlmann-Eltze & Huber conclude it's pretty much best in class. 2/
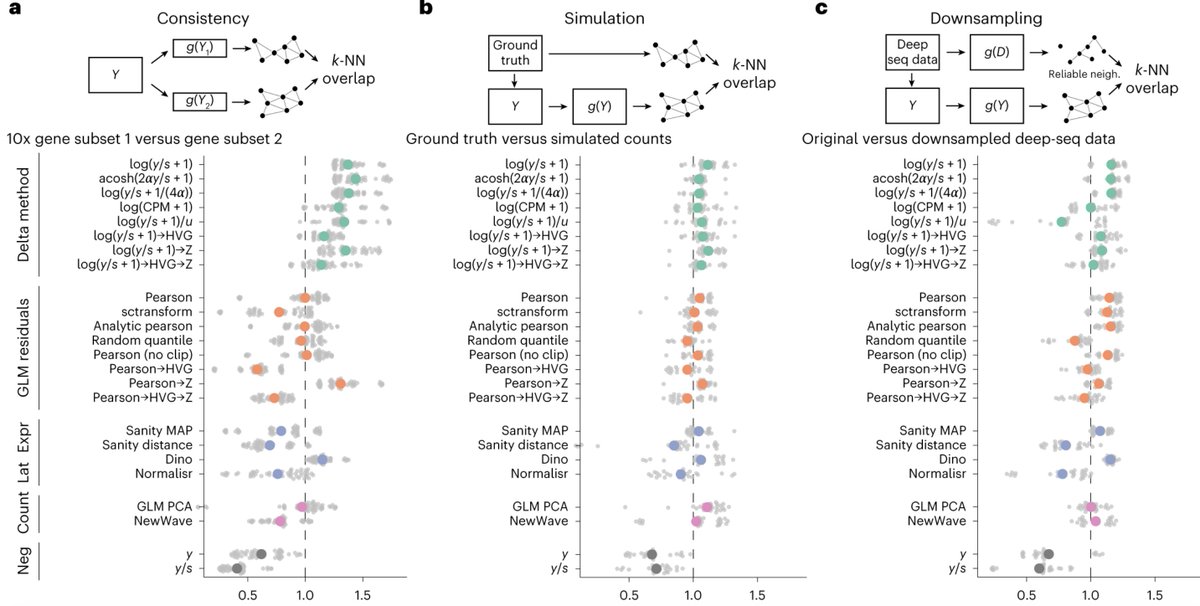

1
5
49
12,290

I am a scanpy evangelist so I asked ChatGPT to implement for me ca. 2023, going to check the code now 😅
1
45

Jun 10
I saw that, but many bioinformaticians will never leave the scanpy API, and forcing people to copy paste this, edit it to make it work with an AnnData introduces friction and room for mistakes. Also this implementation densifies the data which would make it a no-go for my work
1
1
105
Jun 10
this is amazing work, but it would be 10x better if you also included code for using this method in scanpy/seurat workflows. Otherwise one of us will try, mess it up, and we will be right back here again
1
391

Jun 10
MiMo Code @XiaomiMiMo @_LuoFuli just launched with a free MiMo V2.5 channel (1M context).
And I turned it into a bio agent: 1,676 biology SKILL.md files, one command to install.
735 skills run purely local (BioPython, scanpy, DESeq2 — no API key needed).
Protein design suite (AlphaFold, RFdiffusion) uses Modal GPU — $30/mo free tier.
github.com/BioTender-max/bio…

A strong model evolution needs a solid harness system, and vice versa. 14 days, 5 people, one vibe-coding journey — and MiMo Code was born. It's open source: github.com/XiaomiMiMo/MiMo-C…

1
2
210
Jun 10
The Seurat team was informed that Seurat "CLR" is problematic (e.g., github.com/satijalab/seurat/…), but that's a story for another thread. BTW Scanpy doesn't have a CLR implementation. So even though CLR is used frequently in, e.g. metagenomics, it is not in single-cell fields. 18/
1
2
28
4,193

We're especially interested in experts with deep, hands-on experience in the following area:
Bioinformatics & Single-Cell Genomics Working with tools like scanpy, scvelo, squidpy, and gudhi for single-cell RNA-seq analysis, trajectory inference, spatial transcriptomics, and
1
1
48

Jun 9
Right, and it doesn't stop at retrieval. The same need runs up the whole analysis stack, and compbio has been building those layers for years (Bioconductor, scanpy, seurat). The trick isn't to reinvent them, it's to teach agents to use them.
How I do it: modules, a skill plus an R/Python template script.
The script templates one analysis, packages and all. The skill says when to fire it and what to watch for. The agent just bends varying inputs to fit, clean columns or messy samples alike, which is the kind of bounded task it's actually good at. Then chain them: Load/QC -> differential expression -> pathway -> plots.
Will better models make harnesses like this unnecessary? For modules, the opposite. They keep your institutional knowledge enforced by construction, not rediscovered on every run, however good the model gets.
Jun 8

New Science Blog: Why has AI advanced faster in coding than in biology?
To agents, bio databases are like cities built before cars—maddening to drive in because they're designed for different traffic.
How do we build infrastructure agents can use?
anthropic.com/research/agent…
6
410

Jun 8
I can ask any chatbot how to run a differential expression analysis and get a decent explanation. What I actually wanted was something that runs scanpy on my data, hits the databases, and gives me the figures. So that's what we built.
github.com/K-Dense-AI/k-dens…
1
4
143

Yessss! Wanted to share #STAMPede - a new Python toolkit for exploring and analyzing #STAMP data by @mhlangalab’s talented duo Niels Velthuijs and Siebren Frölich (mhlangalab.org)
If you haven't heard of #STAMP yet…check this paper out cell.com/cell/fulltext/S0092……it's a single-cell method published in @CellCellPress last year, repurposing spatial-omics imagers to profile millions of cells at the lowest cost yet, without compromising data quality - no sequencing required. It retains cell morphology and supports multimodal profiling (RNA, protein, and HnE) all in one workflow.
But powerful data needs powerful tools. That's where #STAMPede comes in.
Built to handle the massive, shallow-depth datasets that #STAMP generates, #STAMPede gives you:
→ Familiar scanpy-style syntax so there's almost no learning curve
→ Full pipeline support: QC, filtering, binarization, dimensionality reduction, clustering, and differential expression
→ Easy installation via pip or conda
Whether you're exploring rare cell populations or running large-scale perturbation studies, STAMPede is designed to keep up.
Check it out 👉 siebrenf.github.io/stampede/
@DrJasPlummer
#SingleCell #Bioinformatics #Genomics #OpenSource #STAMP #scRNAseq #ComputationalBiology
1
5
22
2,357

May 24
GitHub 上有个 repo,138 个科学研究工具的 Agent Skill,24.7k stars。
覆盖生物信息、药物发现、临床数据库——Scanpy、RDKit、DeepChem、UniProt、AlphaFold 全在里面。
一行装进你的 agent:
npx skills add K-Dense-AI/scientific-agent-skills
装完之后 agent 不用靠猜,直接拿到正确的 API 调用方式。
好的 agent 不靠更大的模型,靠更精准的工具知识。
2
1
10
941

May 21
🧬 24K stars 的全学科的辅助科研项目:138个现成的科研Agent Skills,一键把Claude Code/Codex变成AI科学家!
该项目覆盖生物、化学、医学、药物发现、生物信息学、临床研究等多个领域,主要包含:
100 科学数据库一键调用
70 专业Python包深度集成(RDKit、Scanpy、BioPython等)
与之前分享的ARIS轻量科研流程形成良好互补,可显著提升AI在文献分析、实验设计、数据处理和科学写作等方面的实际能力。
安装只需一句: npx skills add K-Dense-AI/scientific-agent-skills
github.com/K-Dense-AI/scient…
#AI科研 #ClaudeCode #AgentSkills #ScientificAgent #AutoResearch #Codex
4
30
95
4,089

Scientific Agent Skills 是一个面向科研场景的 Agent 技能库。
它提供 138 个可直接使用的科研技能,可以让 Claude Code、Cursor、Codex 等 Agent 更好地处理科学研究、数据分析、文献写作和工程计算任务。
GitHub:github.com/K-Dense-AI/scient…
主要内容:
-138 个科研 Agent Skills
-覆盖生物信息学、药物发现、医学影像、机器学习、材料科学等方向
-支持 100 科研/金融数据库查询
-包含 RDKit、Scanpy、BioPython、OpenMM、Qiskit 等常用工具技能
-支持文献综述、科研写作、图表、海报、引用管理等任务
-可用于 Claude Code、Cursor、Codex、Gemini CLI 等 Agent
这个项目适合科研人员、数据分析师、AI 科研工具爱好者。

7
228