
Jun 12
Web agents are stupid expensive to run right now. The best ones all lean on proprietary reasoning models and the inference costs are cooked for anything you'd actually want to automate at scale.
New paper WebChallenger reckons the problem isn't model smarts, it's bad architecture. They built PageMem, a deterministic way to turn any DOM into a structured hierarchy of semantic sections with short summaries. Instead of dumping the whole page into context like everyone else does, the agent skims section summaries first, then drills into only the relevant bits. Proper divide and conquer stuff.
They also ship two other clever tricks. A lightweight exploration system that maps each website once and remembers the layout so you don't have to re-discover where the login button lives every session. And compound actions that collapse those annoying multi-step interactions (fill form, click submit, wait for redirect) into single agent calls. All three systems sit on top of PageMem so it works across any website without custom adapters.
The kicker: using off-the-shelf open-weight models with zero fine-tuning, they hit 56.3% on WebArena, 48.7% on VisualWebArena, 51% on Online-Mind2Web, and 70.9% on WorkArena. That gets scary close to frontier proprietary systems at a fraction of the cost. Open-weight web agents are catching up fast.
arxiv 2606.10423 | github.com/jayoohwang1/webch…

10


I'm wrapping up a writeup on how to evaluate agents. The overview uses Terminal-Bench and Tau-Bench as the primary case studies, but I'm including the following benchmarks as well:
- GAIA and GAIA-2 (arxiv.org/abs/2311.12983): general assistant benchmarks that require reasoning, web browsing, tool use, and handling multimodal data.
- AgentCompany (arxiv.org/abs/2412.14161): knowledge work benchmark that uses agents to simulate a small software company by browsing information, writing code, and talking with each other to complete tasks.
- WorkArena (arxiv.org/abs/2403.07718): knowledge work benchmark that evaluates the ability of agents to solve enterprise software workflows sourced from ServiceNow.
- OSWorld (arxiv.org/abs/2404.07972): computer-use benchmark that tests the ability of agents to solve common tasks in real desktop environments. Various other computer-use benchmarks like OfficeBench and MobileBench exist as well.
- MLE-Bench (arxiv.org/abs/2410.07095): autonomous experimentation benchmark that tests whether agents can solve machine learning problems from Kaggle. Other machine learning agent benchmarks like PostTrainBench and MLGym also exist.
- PaperBench (arxiv.org/abs/2504.01848): machine learning benchmark that tests the ability of agents to reproduce AI research papers from arxiv.
- SpreadsheetBench (arxiv.org/abs/2406.14991): excel-based benchmark that test the ability of agents to perform various types of spreadsheet manipulations.
- HIL-Bench (arxiv.org/abs/2604.09408): human-in-the-loop benchmark that evaluates whether agents can decide when to ask humans to clarify ambiguous task specifications.
- GDPval (arxiv.org/abs/2510.04374): realistic benchmark that tests the ability of agents to solve various types of economically-valuable tasks.
What am I missing? Please send me more benchmarks!!
6
7
52
4,149

Apr 10
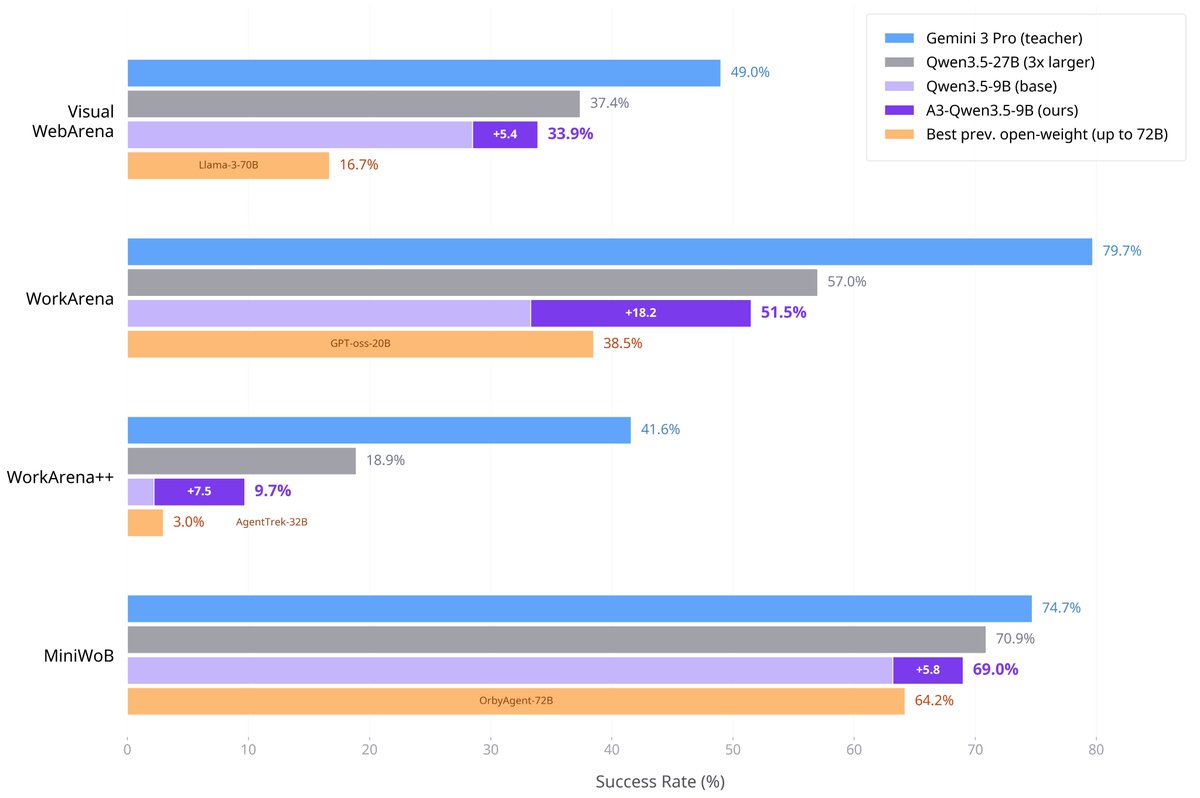
Despite the simple idea, we find that training a small model (~2-9B) on trajectories produced by the teacher results in major performance gains on 4 out-of-domain benchmarks across all sizes: VisualWebArena (visual tasks), and WorkArena (enterprise environments), WorkArena (long horizon tasks) and MiniWoB (small interactive applets).
1
3
425

Mar 16
I found a list that catalogs every serious tool for building AI web agents and it's called Awesome Web Agents.
Browser agents, computer use, scrapers, benchmarks — all in one place:
→ Autonomous agents (Browser-Use, Skyvern, Manus, AgentGPT, Nanobrowser)
→ Computer use (Anthropic Computer Use, UI-TARS, OpenInterpreter)
→ Dev tools (Steel, Stagehand, Browserbase, FireCrawl, Crawl4AI)
→ Benchmarks (WebArena, Mind2Web, WebVoyager, WorkArena)
→ Web search tools (AgentQL, Exa.ai, Jina.ai, SerpAPI)
1.3K stars. 100% Opensource.
Link in comments.
4
7
34
2,960

15 Dec 2025
had not, loved browsergym and workarena, had no idea you guys were shipping this much
4
508

2 Dec 2025
🚀 Nova Act is now available as an AWS service for building and managing UI automation agents at scale.
Powered by a custom Nova 2 Lite model, Nova Act has state-of-the-art browser-use capabilities—performing better than other models on industry benchmarks like WorkArena and REAL Bench V1.
With customers achieving over 90% reliability on UI-based workflows, Nova Act is the fastest and easiest path to production for developers.
Get started today: nova.amazon.com/act
#AWSreInvent
1
10
27
4,691


6 Oct 2025
🚨 Call for Interns – ServiceNow AI Research (Montreal)
Our Computer-Use Agents team (Frontier AI Research) is recruiting interns for 2026!
We work on LLMs and VLMs that can reliably use software and publishing at top venues (NeurIPS, ICML, ICLR) and developing open-source tools like BrowserGym, WorkArena & AgentLab.
We have 5 internship tracks ⬇️
1️⃣ Post-training for CUAs
2️⃣ Tuning Closed-Cource Models
3️⃣ Automatic Red-teaming
4️⃣ Engineering
5️⃣ Privacy-Preserving Team Agents
📍 If you’re at #COLM2025, come find us at the ServiceNow booth!
🧵👇 details in thread
7
39
163
16,813

5 Oct 2025
Alex Drouin (@alexandredrouin) on how well agents perform knowledge work
-- METR findings: agent capability doubling every 7 months
-- WorkArena: open source benchmark for 600 work related tasks - lists, form, knowledge base
-- 7 minutes for humans to solve these tasks. METR scaling laws are close but overestimate webagent performance.
-- Updated METR results: webagents perform significantly lower than coding agents
-- BrowserGym: standardized observation and action space. Many open benchmarks in standardized format.
-- Efficient training of web agents: RL underperforms on base model.
-- JEF-Hinter: Hints improve the web agents. Can use failed traces.
-- UIVision: a large benchmark for UI element grounding
Many enterprise tasks involve visualization and analysis.
-- BigCharts: QA on charts (model and data public)
-- InsightBench: Extract relevant data hidden in real tables
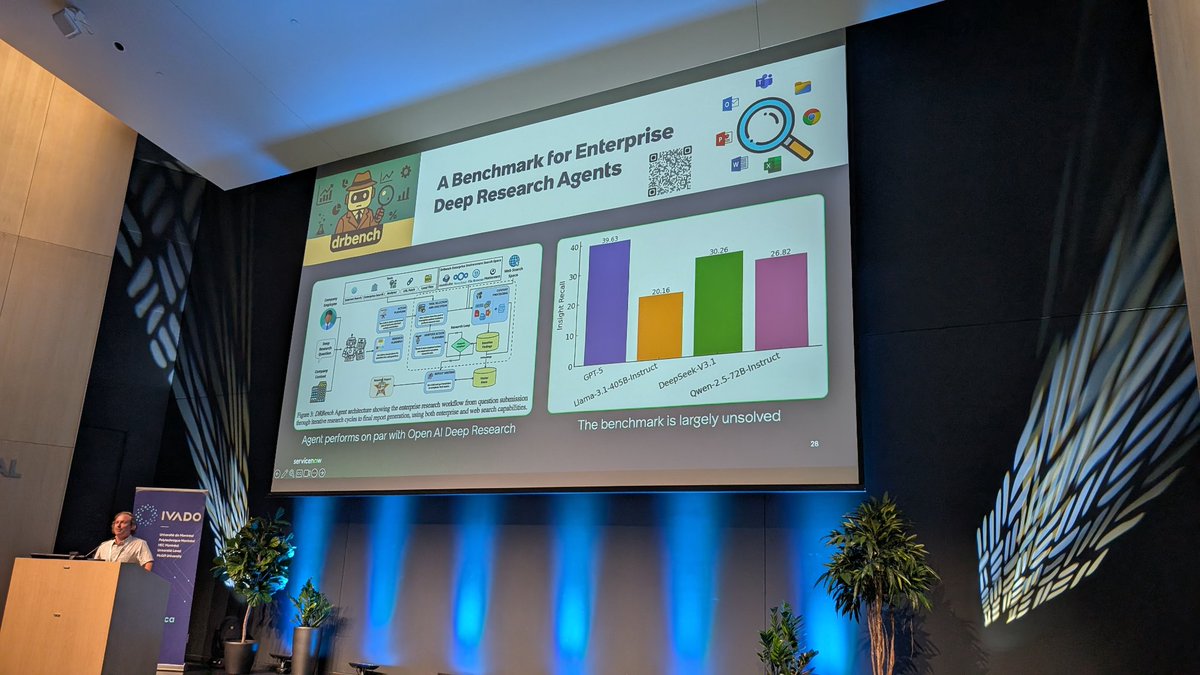
DeepResearch
DRBench: search open web facts and local facts embedded in local applications like mattermost. Allows you to test UI agents, MCP agents.
Safety and Security:
-- DoomArena: a framework for security testing. Integration with WebArena, BrowserGym, Tau-Bench.
-- Malice-in-Agentland: trigger based backdoors. Just a little malicious training data is enough to establish a backdoor.
Food for thought: How will we keep track of progress when agents are capable of solving one month task?



3 Oct 2025

The IVADO workshop on Agent Capabilities and Safety is happening now at HEC Montreal, Downtown (Oct 3--6)
ivado.ca/en/events/1st-works… #LLMAgents
3
15
2,241

21 Aug 2025
Surprising results of GPT-5 on #WorkArena
21 Aug 2025

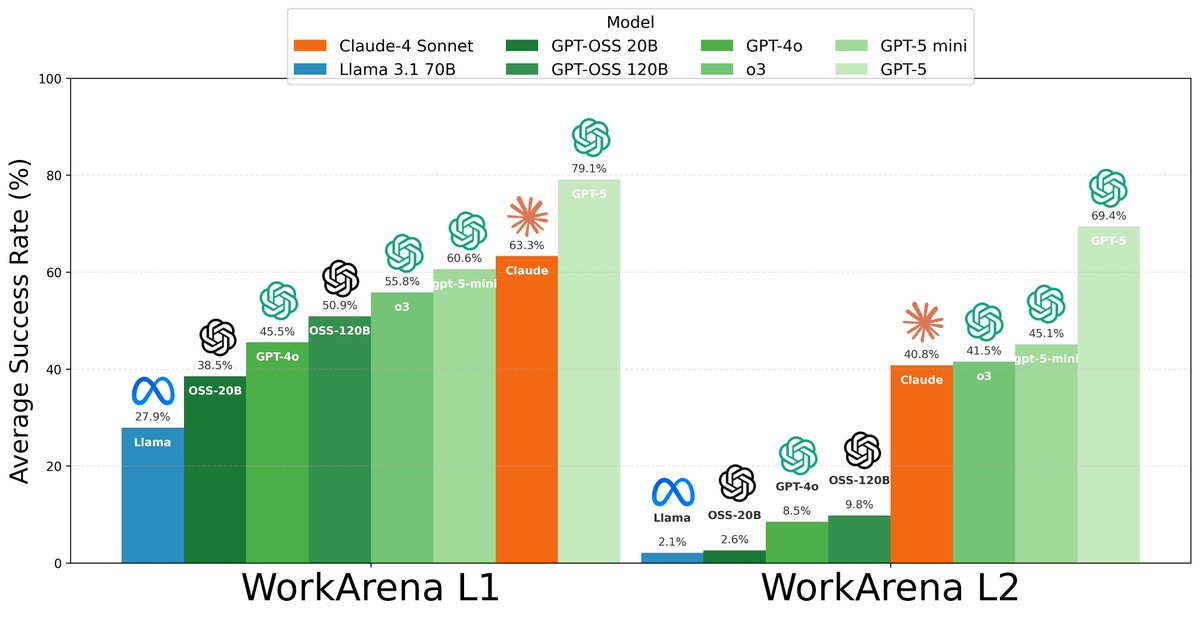
🚨 Is #WorkArena on the verge of being solved? Or did GPT-5 just get trained on it?
🔥While some benchmarks show modest gains, GPT-5 is crushing WorkArena L2🔥
➡️ 69.4% avg success vs. ~40% for next best🤯
➡️ Complex tasks, up to 100 steps, 5–20 min for humans
2
220
21 Aug 2025
What is your guess? Why is GPT-5 shining so much on WorkArena in contrast to other benchmarks?
Trust me, this is the last time, we're making a benchmark without a hidden test set.
9
407
21 Aug 2025
🚨 Is #WorkArena on the verge of being solved? Or did GPT-5 just get trained on it?
🔥While some benchmarks show modest gains, GPT-5 is crushing WorkArena L2🔥
➡️ 69.4% avg success vs. ~40% for next best🤯
➡️ Complex tasks, up to 100 steps, 5–20 min for humans
4
25
44
3,970

Evaluating LLM-based Agents - arxiv.org/pdf/2503.16416v1
A comprehensive list of methods for evaluating AI Agents.
#AQUARAT #HotpotQA #StrategyQA #GSM8K #MATH #Gameof24 #MiniWAT #PlanBench #FlowBench #FOLIO #PFOLIO #MULtIrc #MUSR #BeeT #BoolQ #AutoPlanBench #APCBench #NarrativeQA #QMSum #QUALITY #MemGPT #LoCoMo #AMEM #StreamBench #LLMEvolve #ReflectionBench #ToolBench #ToolAlpaca #APIBench #NexusRaven #SealTools #ComplexFuncBench #RestBench #APIgen #StableToolBench #WebShop #MindWeb #WebShopV2 #WebArena #MMH #AssistInBench #Camas #WorkArena #HumanEval #SWEbench #SWEbenchLite #SWEbenchMultimodal #ProofBench #SWFBench

2
5
184

10 Jul 2025
Paper shows how to squeeze more skill from small web‑surfing LLMs without burning absurd compute.
Open agents copy a 70B teacher for a while then switch to reinforcement learning (RL), and that switch timing is the whole game.
Authors trained a 8B student on teacher demos, branched into RL at different checkpoints, and ran 1,370 mixes to see what sticks.
Early but not immediate branching beats pure imitation or pure RL, matching the best imitation score on MiniWoB using 55% of the flops.
The same recipe narrows, but does not close, the WorkArena gap, hinting that hard office workflows still need richer data or bigger brains.
Bootstrapped stats reveal stable knobs: decoding temperature 0.25, zero advantage filtering, grouped advantage, big batch 512, and modest 1e‑6 learning rate.
The playbook gives smaller teams a clear, cheaper path to teach open models reliable multi‑step browser habits.
----
Paper – arxiv. org/abs/2507.04103
Paper Title: "How to Train Your LLM Web Agent: A Statistical Diagnosis"

1
1,375

9 Jul 2025
Woohoo! Our paper “How to Train Your LLM Web Agent: A Statistical Diagnosis” snagged an oral at ICML 2025! 🎉 SFT RL beats solo SFT/RL, on MiniWoB & WorkArena. Thanks @ServiceNowRSRCH & @Mila_Quebec! #AI #RL
9 Jul 2025

🎉 Our paper “𝐻𝑜𝑤 𝑡𝑜 𝑇𝑟𝑎𝑖𝑛 𝑌𝑜𝑢𝑟 𝐿𝐿𝑀 𝑊𝑒𝑏 𝐴𝑔𝑒𝑛𝑡: 𝐴 𝑆𝑡𝑎𝑡𝑖𝑠𝑡𝑖𝑐𝑎𝑙 𝐷𝑖𝑎𝑔𝑛𝑜𝑠𝑖𝑠” got an 𝐨𝐫𝐚𝐥 at next week’s 𝗜𝗖𝗠𝗟 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 𝗼𝗻 𝗖𝗼𝗺𝗽𝘂𝘁𝗲𝗿 𝗨𝘀𝗲 𝗔𝗴𝗲𝗻𝘁𝘀! 🖥️🧠
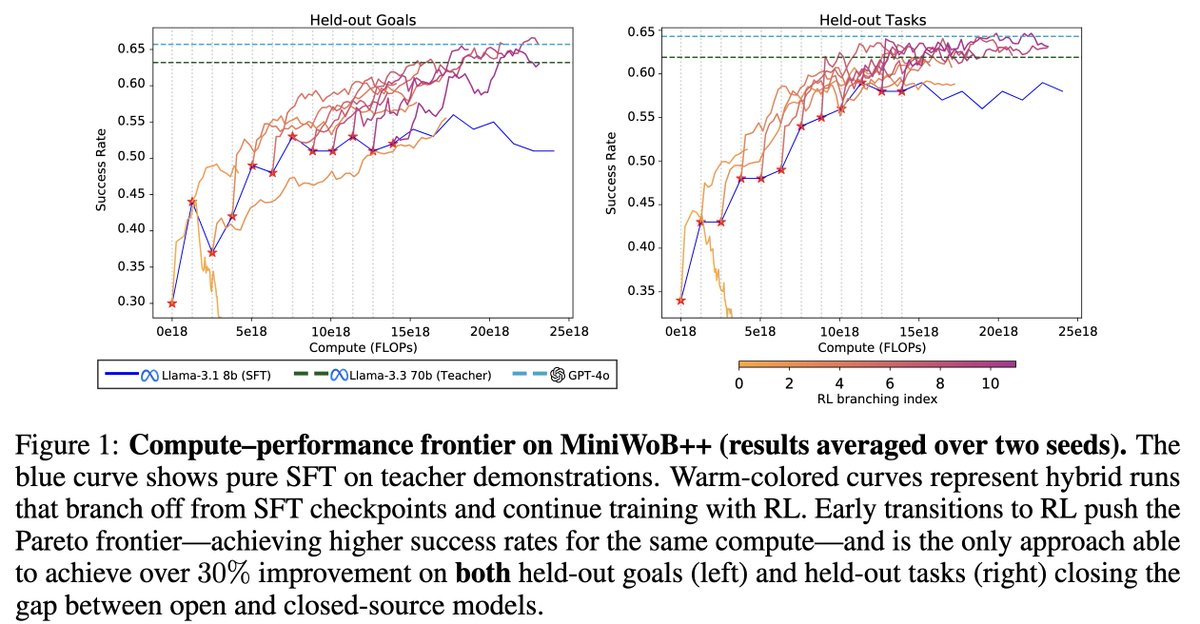
We present the 𝐟𝐢𝐫𝐬𝐭 𝐥𝐚𝐫𝐠𝐞-𝐬𝐜𝐚𝐥𝐞 𝐬𝐭𝐮𝐝𝐲 𝐨𝐟 𝐜𝐨𝐦𝐩𝐮𝐭𝐞 𝐭𝐫𝐚𝐝𝐞-𝐨𝐟𝐟𝐬 between pure SFT, pure RL, and hybrid SFT RL for multi-step agents.
SFT ➡️ RL pushes the Pareto front — and it's the 𝐨𝐧𝐥𝐲 strategy that closes the gap with closed models!
👇🧵
1
9
496

9 Jul 2025
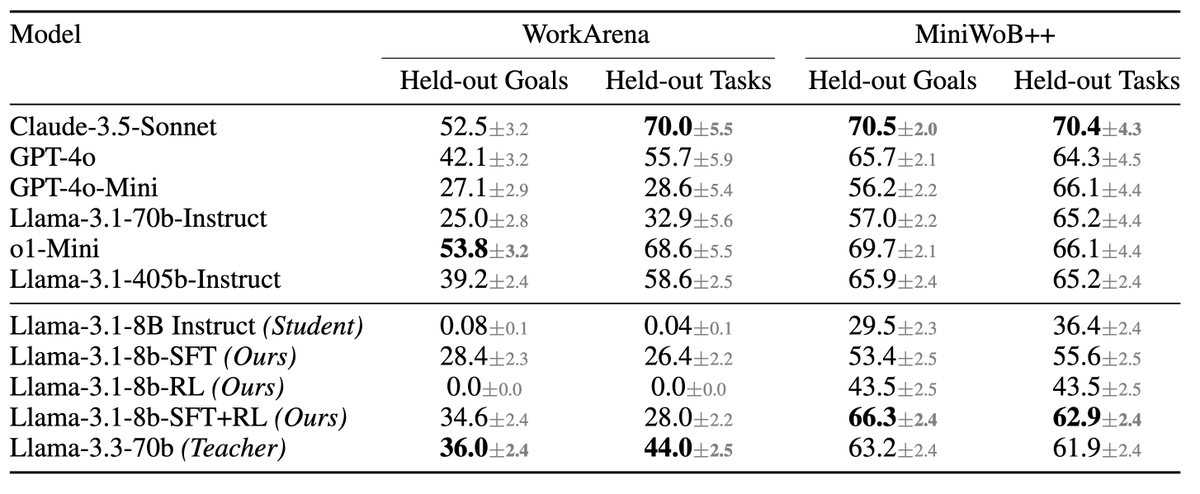
📊 Quick recap of our 𝐜𝐨𝐦𝐩𝐮𝐭𝐞 𝐚𝐥𝐥𝐨𝐜𝐚𝐭𝐢𝐨𝐧 𝐬𝐞𝐭𝐮𝐩:
We train agents with 𝐩𝐮𝐫𝐞 𝐒𝐅𝐓, 𝐩𝐮𝐫𝐞 𝐑𝐋, and 𝐒𝐅𝐓 ➡️ 𝐑𝐋 𝐡𝐲𝐛𝐫𝐢𝐛𝐬, branching into RL at various points during SFT.
🚀 𝐒𝐅𝐓 𝐑𝐋 consistently pushes the Pareto front (top plot).
✅ It’s the 𝐨𝐧𝐥𝐲 strategy that closes the gap with closed-source models on MiniWoB ,
✅ and comes 𝐜𝐥𝐨𝐬𝐞𝐬𝐭 𝐭𝐨 𝐭𝐡𝐞 𝐭𝐞𝐚𝐜𝐡𝐞𝐫 on 𝐖𝐨𝐫𝐤𝐀𝐫𝐞𝐧𝐚
1
6
661
9 Jul 2025
Progress in RL has mostly focused on 𝐬𝐢𝐧𝐠𝐥𝐞-𝐬𝐭𝐞𝐩 𝐭𝐚𝐬𝐤𝐬 like math and code, far from the complexities of real-world interaction.
Worse, many papers still report results from 𝐚 𝐬𝐢𝐧𝐠𝐥𝐞 𝐬𝐞𝐞𝐝 🙄
We tackle 𝐦𝐮𝐥𝐭𝐢-𝐬𝐭𝐞𝐩 𝐑𝐋 in MiniWoB , and in the 𝐫𝐞𝐚𝐥𝐢𝐬𝐭𝐢𝐜, 𝐞𝐧𝐭𝐞𝐫𝐩𝐫𝐢𝐬𝐞-𝐠𝐫𝐚𝐝𝐞 setting of 𝐖𝐨𝐫𝐤𝐀𝐫𝐞𝐧𝐚 — a benchmark designed for agents solving complex knowledge-work tasks.
1
11
988

13 May 2025
3/N: WebJudge demonstrates outstanding generalization capabilities across five well-established OOD benchmarks, significantly outperforming existing methods. It achieves impressive overall precision of 73.7%, 75.7%, and 82.0% on WebArena (WA), VisualWebArena (VWA), AssistantBench (AB), WorkArena (Work), and WorkArena (Wk ) across 1,302 trajectories. The high precision suggests that WebJudge holds potential as a robust and scalable reward model for downstream applications such as RL and reflection.

1
2
7
779

16 Apr 2025
Benchmarking the performance of Models as judges of Agentic Trajectories
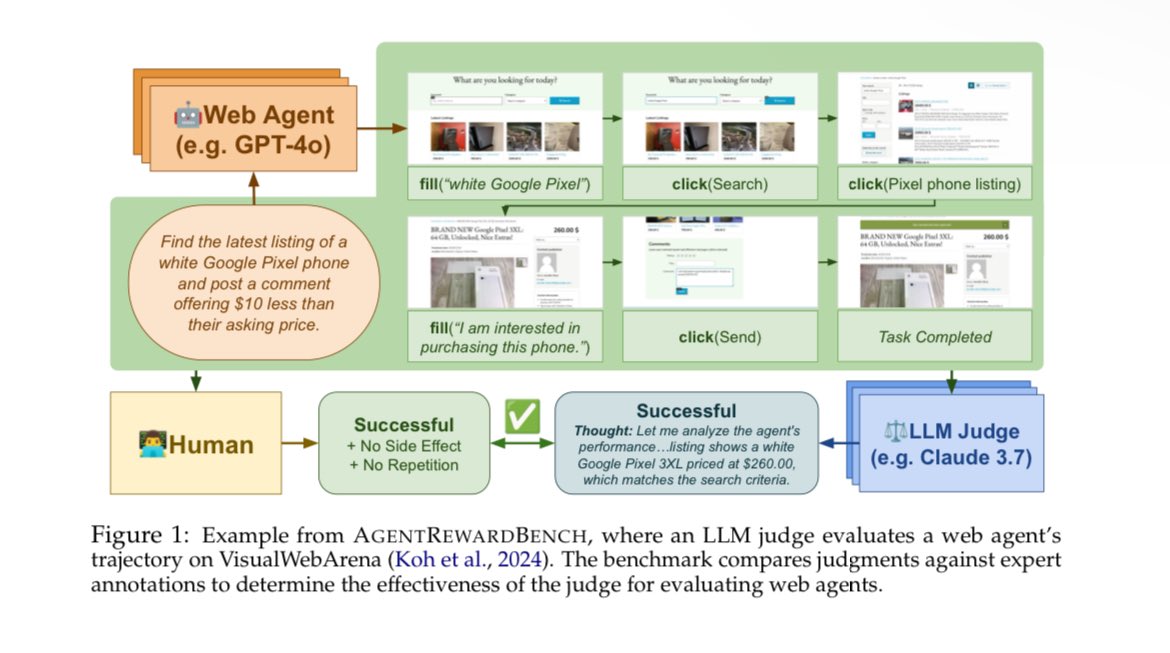
📖 Read of the day, season 3, day 30: « AgentRewardBench: Evaluating Automatic Evaluations of Web Trajectories », by @xhluca, @a_kazemnejad et al from @mcgillu and @Mila_Quebec
The core idea of the authors of the paper is to study how good our current models are at evaluating the success of an attempt at solving a web-related task.
The authors make the models work as a judge, having access to the complete trajectory and the DOM with an accessibility tree and/or the page screenshot.
The model must reason and answer the following questions:
1- Is the sequence of actions successful with respect to the goal?
2- Did the agent perform unnecessary actions that could have unintended consequences?
3- Did the agent perform the task optimally?
4- Did the agent run into a loop of actions that did not help in advancing the goal?
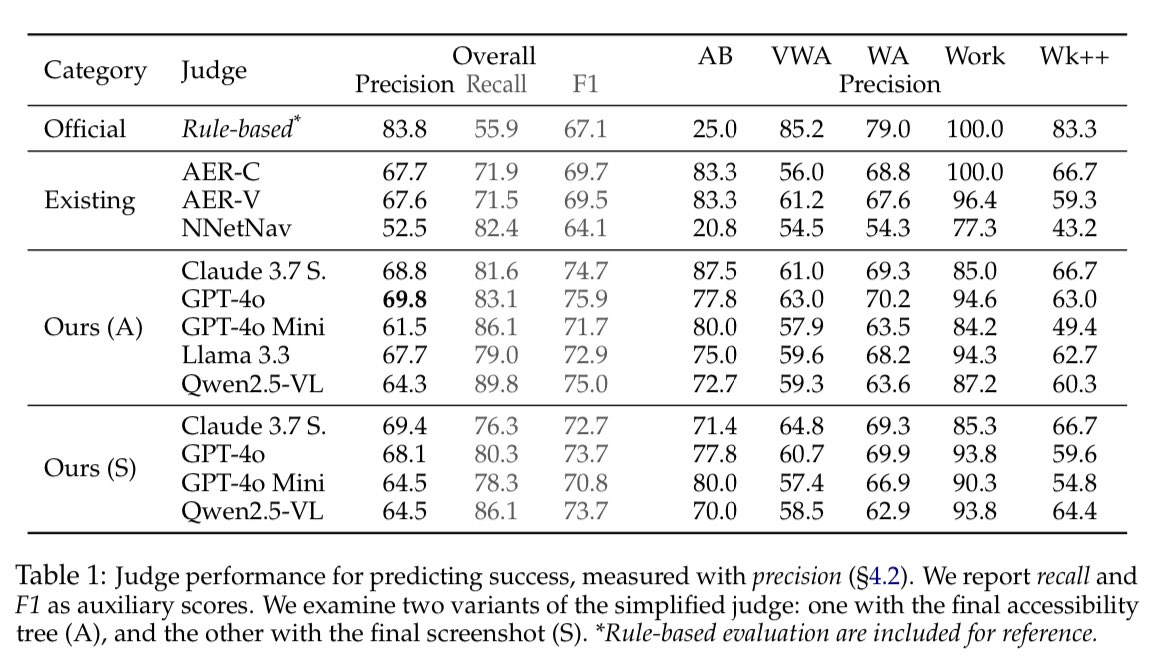
Four models were tested: Claude 3.7 Sonnet, Gpt-4o, Llama 3.3 70B and Qwen 2.5 VL 72B. Five benchmarks were aggregated for this study: WebArena, VisualWebArena, AssistantBench, WorkArena and WorkArena .
A total of 1302 trajectories were collected from all 4 LMs and annotated.
The LMs are then asked to answer the four previously mentioned questions, and the benchmark focuses on Precision regarding success assessment. The authors claim this is because what interest them is to avoid false positives in order for those models to be useful in Rejection Finetuning or to identify positive trajectories for RL algorithms.
They compare as well their method with other success assessment methods with either GPT-4o or Llama 3.3 70B under the hood, which they outperform.
However, whether it’s with the images or not, none of the four evaluated models manages to reach above 70% precision yet. This means there is progress to be done on that area!
Other things that are studied:
- Having both the accessibility trees and images overwhelm Gpt-4o-mini as a judge and slightly lower its performances ; this was to be expected due to the 200k context length of the model
- Rule-based and Model as a judge differ from Human Annotation : Model as a judge rates too high, rule-based eval rates too low. (Interesting, likely requires to go deeper here)
Authors then finally analyze common error causes. They find that quite the errors happen due to:
1- Grounding mismatch between content on screen and agent output: judge trusts the agent has gone in the right direction, and ends up being wrong
2- Misleading agent reasoning that confuses the judge model into believing the task is done
3- Near but not full completion of a task that is interpreted as full by the judge
4- Task being completed by the agent, but the feedback is failed to be given to user ; the judge interprets that since the task is done, it was successful - but fails to pick up that the model made a wrong reporting
Overall, quite the promising benchmark that feels it could lead us to really interesting results when the models get better.
And since the models got better, I think it would be great to try it on the Llama 4, GPT-4.1 or the Gemini 2.5 Pro/2.0 Flash on which the increased context length might yield to stronger performances!
1
1
9
339