
Feb 2
boolean search is boring. google scholar...
valve AND (~airflow OR CFM OR (mass flow) OR flow) AND ~engine AND intake -diesel AND port AND (flowbench OR (flow bench))
is this good? I've never done this before...
1
2
27

4 Dec 2025
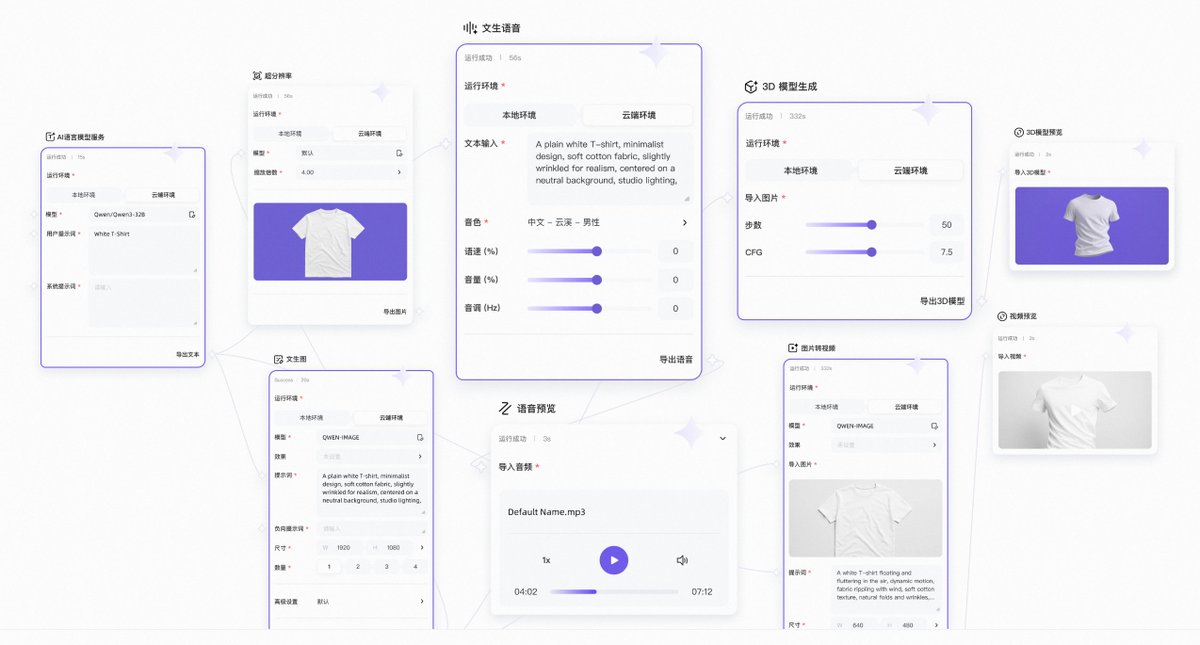
🚀 Introducing Flowra by ModelScope & WULI!
The open-source engine behind FlowBench makes building AI workflows as easy as snapping LEGO bricks.
✅ Unified handling of images, audio, video & 3D
✅ DAG-based execution w/ smart caching & distributed scaling
✅ One-line ModelScope model integration
✅ Full dev toolkit: flowra create → build → debug → deploy
Turn your ML model into a visual node in minutes.
✨ No more dependency hell. No more blind debugging.
🔗 GitHub: github.com/modelscope/flowra
📥 FlowBench client: modelscope.cn/flowbench/down…


3
3
44
3,456
17 Oct 2025
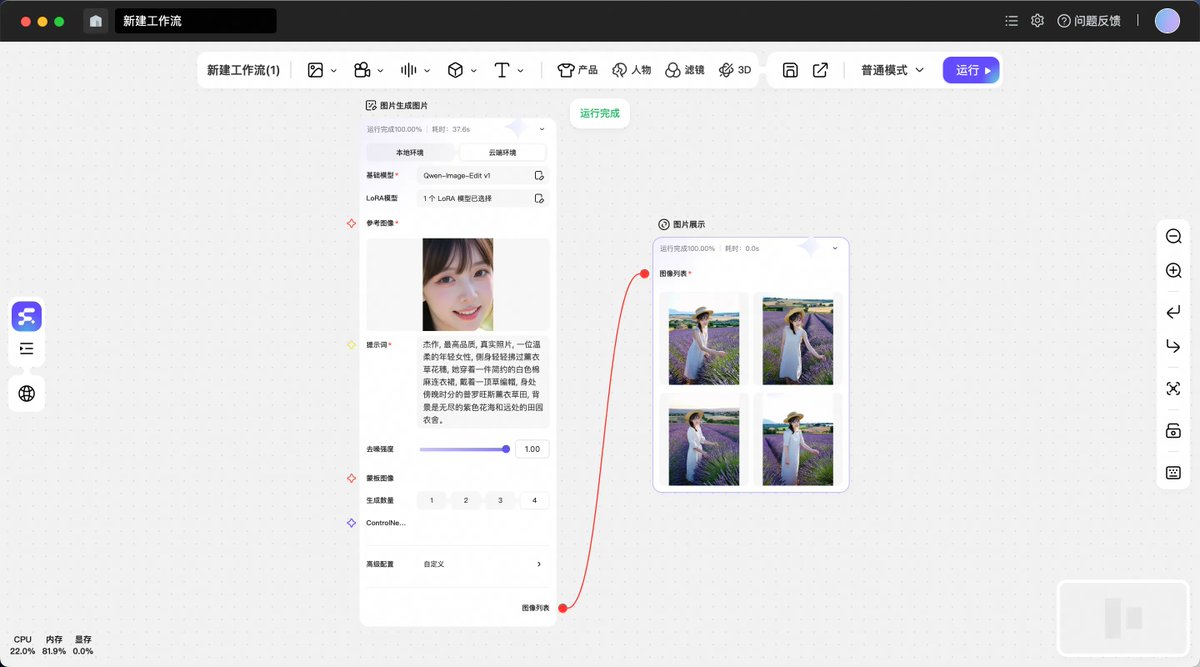
[3/3] 💻 Experience it in FlowBench:
Use the “Image-to-Image Generation” node → select Qwen-Image-Edit v1 DiffSynth-Studio/Qwen-Image-Edit-F2P LoRA → generate high-quality portraits with one click.
Mac:cdn-muse-cn-1.modelscope.cn/…
Windows:cdn-muse-cn-1.modelscope.cn/…
1
4
1,146
25 Sep 2025
That's a great question! Unfortunately, they're not compatible. The main reason is that Flowbench took a different product design approach.😎
3
77
25 Sep 2025
🚀ModelScope FlowBench is now live!
A local-cloud collaborative platform for text / image / 3D / video / audio workflows.
✅Free cloud compute — run QwenImage, Wan2.2, Flux, SD, and more with zero GPU hassle.
✅ One-click workflow cloning — copy pro pipelines instantly. Change outfits, swap background, figurine effects — all in a single prompt.
✅ 10,000 built-in LoRAs — choose, switch, and apply with ease.
✅ Drag-and-drop nodes real-time preview — build complex pipelines with generation, editing, and pose control all in one.
💻 For Free — jump in today!
Local client download in the comments
#Aiart️ #AITools
5
6
16
3,041

27 Aug 2025
🎉 Our TMLR paper, FlowBench, is out!
Optical flow keeps getting better on benchmarks, but reliability and generalization remain a challenge for safety-critical tasks.
FlowBench provides the most comprehensive robustness benchmark to date.
📄 openreview.net/forum?id=Kh4b…

6
138

Evaluating LLM-based Agents - arxiv.org/pdf/2503.16416v1
A comprehensive list of methods for evaluating AI Agents.
#AQUARAT #HotpotQA #StrategyQA #GSM8K #MATH #Gameof24 #MiniWAT #PlanBench #FlowBench #FOLIO #PFOLIO #MULtIrc #MUSR #BeeT #BoolQ #AutoPlanBench #APCBench #NarrativeQA #QMSum #QUALITY #MemGPT #LoCoMo #AMEM #StreamBench #LLMEvolve #ReflectionBench #ToolBench #ToolAlpaca #APIBench #NexusRaven #SealTools #ComplexFuncBench #RestBench #APIgen #StableToolBench #WebShop #MindWeb #WebShopV2 #WebArena #MMH #AssistInBench #Camas #WorkArena #HumanEval #SWEbench #SWEbenchLite #SWEbenchMultimodal #ProofBench #SWFBench

2
5
184

27 Jun 2025
4 intakes. 2 dudes. 1 Silverado
Live on YouTube now!
Bert and Christian are kicking off the ultimate cold air intake showdown.
Flowbench ✅
Dyno ✅
Drag strip ✅
👉 youtu.be/ongYqvi3gzw
#knfilters #knnextgen #performance #dyno #silverado #flowbench
3
407
24 Jun 2025
4 intakes. 3 tests. 1 winner.
We strapped 4 intake systems to a Silverado 6.2L and ran them through the wringer:
🔥 Flowbench
💪 Dyno
🏁 Drag strip
👀 Full video drops Friday, June 27 on YouTube.
Can you guess the winner?
#knfilters #knnextgen #silverado #dyno #shootout #racing

1
5
868


12 Nov 2024
Some more Ford small block E7 head info for you or someone you know who may find it interesting.
With every casting there is an ultimate upper limit no different than a 175lb man has an upper strength limit that will likely be lower than a 275lb man.
With the E7 head it’s limitation is that even though the casting starts out thick, as you grind away to get the dimensions for increased area and airflow rate you start to run close to the edge of the casting.
Those who are willing to push the casting closer to the limit are able to achieve larger dimensions and more airflow, but the purpose of the head has to be taken into account.
Will it be a tow vehicle that sees a lot of hard use? Should probably keep walls at 0.100 thickness then and I say this because people who port diesel heads say they keep thickness at 0.100” because diesels are typically hard working vehicles that see long periods of heavy load.
If it’s going to be a hot rod that maybe sees 5k miles a year then grind away until you reach .050” thickness to the water jacket.
I typically grind to .050” on the sonic tester which is about .070” in reality based on mechanical measurements. Sometimes it gets down to .040” but not often and even then there is actually .060” left and I’ve never had one come back with a leak at that casting thickness.
Now a 201 cfm reading may not seem like a large number with the stock 1.78” intake valve but the reality is that is a 24% increase from the stock 162 cfm and that 201 can support as much as 414 hp.
CFM x .258 x number of cylinders=hp
So if you own an anemic 302 or 351w from the E7 era, you can still make significant gains for your work truck or your hot rod and it will just cost you some time and you may enjoy it or you may not but at least you’ll have an appreciation of those who do like to carve on metal.
The dimensions also show you why the early Ford 289 head is able to achieve more airflow. It simply starts out with a slightly larger bowl (1.47” width vice 1.34” E7 width).
Because of that the 289 head can go to 1.60” bowl width and maintain good thickness to whereas the E7 is pretty close to maxxed out at 1.51-ish…
Larger bowls help the air expand, slow down and make the short turn into the throat area.
So the shape of the short turn and a large enough bowl area to support that turning event are important to the flow curve.
The throat is the last part so if you keep it smallish, you’ll hurt ultimate flow potential but also help control the curve by not allowing the throat to pull too hard on the turn and elevate airspeed to the point of separation which is around 380-435.
Larry Meaux, who is an amazing head porter has said online he is able to shape the short turn well enough that it can support an airspeed of 435 FPS. I doubt that I am at that level. Normally my shapes seem to detach at 380-400 fps.
So I may keep the throats a little smaller than I should but it helps crutch me & keep a stable port.
The rule of thumb is that for 45° seats you can go up to valve diameter size minus 0.200” but you can see by my dimensions that I’m smaller than that. If the bowl can be made big enough and the height of the short turn can support a certain size radius then I go up to the 2x’s the radius measurement and no larger. When I’ve gone larger, the flow curve has broken off at some value above the .25D (25% of valve diameter) point.
For a 1.78” valve, the .25D is 0.445” which is why you see the curve ramp up quickly up to that point and then the gains slow way down becsuse the valve is mostly out of the way at .25D
For the exhaust, the numbers can be made larger by among the exit area larger but the flowbench is not a good tool for the exhaust because it cannot replicate the high temp and pressure that the exhaust valve and port see from the residuals of the combustion process. That energy drives out the exhaust and its throat can be larger than the thumbrules would say.
Enjoy and have a a good night.



2
79
7 Nov 2024
My philosophy on hot rodding and/or head porting as a hobby is this.
1. It must be somewhat affordable. When it becomes a financial drain it becomes less enjoyable and people leave the sport.
2. It must bring in young people to survive since youth is the future of any organization or hobby.
3. It must be something that people feel pride in accomplishing through their own efforts. Just ordering an item takes some of the fun away from creating part of the successful combination with your own mind/hands.
4. If more people try their hand at cylinder head porting some of them will find themselves to be pretty good at it and can leverage that into hobby income to help their own financial situation out. This will help keep the sport and the art of head porting alive.
5. It can especially help local areas where you want to find a person to work your cast iron heads (or you work them yourself) because shipping cast iron heads is very expensive.
Plus if you try your hand and make decent gains, the local machine shop or flow bench owner will be happy to do valve jobs, guide work and flow tests for you.
They say the flowbench is good for predicting hp gains up to the 1.7 hp/cubic inch range. That’s a big number, like 513hp naturally aspirated out of a Ford 302 cubic inch engine and if you are making beyond that with 60s tech you’re at a whole different level than the audience these posts are intended for.
These are for young men and women who don’t have a lot of net worth and are trying to grow their lives and skill sets and some of them might just be handy with a die grinder and appreciate someone giving them some guidance on what works.
Head porters are all competitive and want to be the best, which is natural and some will be better than others but if you really want to find the best you need a large pool to draw from.
Based on the results I get, I consider myself competent but nowhere near the level of the upper tier artists.
My goal is to help those starting out with the information that took me many years to figure out so they can accelerate their learning curve and get the results they are looking for in the most cost efficient manner possible.
I believe this will keep the hobby sport healthy for the long haul.
Pick up a grinder, a long burr, a speed controller, some safety glasses and a $50 set of junkyard heads and give it a try. You might actually like and be good at it and then find it is a way to earn some extra income towards your first house, flow bench, valve grinder, seat/guide machine, etc.
If you take measurements you’ll find that your ports will be fairly consistent because the way you port is similar to a signature. The upper end head porters can all tell whose work it is just by looking at the port.
And just like your signature is very similar time after time, you’ll find that your work is similar port after port.
Read the article by Judson Massingill, lots of tips there. Listen to the Speedtalk interview with Darin Morgan. Read lots of posts on Speedtalk, look for deals as others retire or upgrade to newer equipment.
Get excited when the flowbench “grading machine” gives you a good score because it has no hidden agenda. Get bummed when it says “try harder” and then… try harder. It’s a form of problem solving.
Have fun!


1
34

Cavity流れの中に色んなものいれてておもろいw
[2409.18032] FlowBench: A Large Scale Benchmark for Flow Simulation over Complex Geometries arxiv.org/abs/2409.18032
1
4
456

13 Aug 2024
For those trying to figure out how to get LLMs to best follow workflows, the paper “FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents” introduces FlowBench, the first benchmark designed to evaluate LLM agents in planning tasks guided by workflow knowledge. Skip to Appendix section C.2 for the relevant prompts and data input formats.
🔹 Key Challenges Addressed:
1. Planning Hallucinations: LLM agents often generate actions that conflict with task knowledge, especially in expertise-intensive tasks.
2. Workflow Knowledge Integration: The paper formalizes and tests different formats of workflow knowledge (text, code, flowchart) for improving planning accuracy.
3. Comprehensiveness of Evaluation: FlowBench covers 51 scenarios across 6 domains, providing a multi-tiered evaluation framework to assess how well LLM agents use workflow knowledge in planning.
🔹 Main Contributions:
1. Workflow Formalization: The paper revisits different workflow formats, including natural language, symbolic code, and flowchart schema, offering insights into their efficacy in guiding LLM agents.
2. FlowBench: A benchmark that includes diverse domains like customer service, personal assistants, and robotic process automation. It provides structured tasks for LLM agents, assessing their planning reliability across various real-world scenarios.
3. Evaluation Framework: The study presents a static turn-level and dynamic session-level evaluation framework to measure agent performance in using workflow knowledge.
🔹 Key Findings:
1. Flowchart Superiority: Flowcharts strike the best balance among performance, adaptability, and user-friendliness, outperforming text and code formats in both single-scenario and cross-scenario evaluations.
2. Need for Improvement: Even the best-performing LLM (GPT-4o) struggles with planning in certain tasks, highlighting the need for further research.
Results: The study demonstrates that structured workflow knowledge, especially in flowchart format, significantly enhances LLM agents’ planning capabilities but that many real-world tasks are still unattainable.
Paper: arXiv:2406.14884v1
5
1,035

24 Jun 2024
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents
This paper introduces FlowBench, the first benchmark for workflow-guided planning in LLM-based agents, addressing issues with planning hallucinations in expertise-intensive tasks. FlowBench includes 51 scenarios across 6 domains with diverse workflow knowledge formats. A multi-tiered evaluation framework assesses LLMs, revealing significant room for improvement in planning reliability.
arxiv.org/pdf/2406.14884

4
121

11 Jun 2024
Discover More...
High Speed Turbo Core Balancing and Flowbench
mbs-balance.com
#turbo #turbocharger #flow #balance #balancing #auto #automotive #industrial #mbs #machine #air #high #speed #core

2
289

19 Jan 2024
3)...national event. Now it's summer of 1969 and the Nationals at Indy are coming up and the CJ Mustangs are still several tenths too slow. Al Buckmaster is Ford's head flowbench guy, and his opinion is that the CJ heads just don't move enough air.
1
8
121

24 Apr 2023
#MotorMonday - Here's episode #7 from this year's Engine Performance Expo.
loom.ly/ae_Vrxg
#Engine #Horsepower #RacingEngine #Dyno #CylinderHead #FlowBench #NHRA #ProStock
2
37

5 Apr 2023
Omega is at the Measurement Science Conference! Join us today through April 7th at the Disneyland Hotel in Anaheim, CA. Stop by booth #20 to see our innovative temperature, pressure, flow, and IIoT products in action.
#measurementscienceconference #omegaengineering #flowbench

2
68

27 Mar 2023
Flawed for 50 years. How we fixed the flowbench. | Banks Entry Level - In this episode of Entry Level, Banks' Special Projects Lead Erik Reider explains the function of a flowbench and its uses. #bankspower #science #engineering #diesel #engine #dieseltrucks
6
530