
I learned today the they will retroactively remove disclosure from live recorded videos. 👌 live stuff, and even ad alternative content. The video you see could be entirely different from what I upload, or entire accounts made in millisecond...
That'll be fun
#riggedmarket
#Deepfake #SyntheticMedia #DiminishedReality #VideoForensics #SportsBetting #OddsManipulation #WeatherDeepfakes #ClimateOSINT #WorldEvents #CrisisActors #CrimeForensics #EvidenceTampering #OSINT
#Comprehensive Analysis of Real-Time Video Manipulation, Synthetic Media Diffusion, and Cognitive Anchoring Methodologie
Section 1: Introduction and Foundational Architectural Frameworks
The structural integrity of live digital evidence has been fundamentally altered by the convergence of high-throughput computing architectures and real-time generative artificial intelligence. Historically, video verification processes relied on the implicit assumption that live-streamed data possessed structural fidelity due to the computational impossibility of performing frame-by-frame contextual modifications on the fly. This structural guarantee no longer exists.
Modern ingestion and streaming pipelines can execute arbitrary frame modification, ambient lighting reconfiguration, and object elimination in real time. These alterations occur within the transient space between raw sensor capture and network distribution. The systemic implementation of these technologies allows for the seamless modification of broadcast environments, the retroactive extraction or insertion of critical physical evidence, and the deliberate exploitation of human memory vulnerabilities.
The Live Streaming Data Pipeline
To understand how video manipulation occurs without introducing perceptible latency, one must examine the baseline mechanics of modern video distribution networks. A standard live stream operates via a sequential pipeline:
1. Sensor Ingestion: The camera sensor captures raw visual data, converting photons into electronic signals organized as distinct pixel matrices.
2. Hardware Encoding: The raw matrices are compressed using specialized hardware codecs (e.g., H.264, H.265, AV1) to minimize bandwidth requirements.
3. Protocol Packetization: The encoded bitstream is segmented into network packets via transmission protocols such as Real-Time Messaging Protocol (RTMP), Web Real-Time Communication (WebRTC), or Secure Reliable Transport (SRT).
4. Content Delivery Network (CDN) Edge Distribution: Packets are routed through localized edge servers to minimize geographic latency before reaching the end-user rendering engine.
Real-time tampering systems insert an intermediate computation layer between Sensor Ingestion and Hardware Encoding. This layer is designated as the Generative Inference Intercept (GII). By processing the uncompressed or shallowly encoded frames directly within high-bandwidth video memory (VRAM), deep learning models can evaluate, mask, and reconstruct the pixel landscape of a live broadcast prior to protocol packetization. Consequently, the viewer receives a compromised stream that appears structurally sound, devoid of typical post-production artifacts, and accompanied by authentic network timestamps that falsely validate its integrity.
[Camera Sensor] ──> [Generative Inference Intercept] ──> [Hardware Encoder] ──> [CDN Distribution] ──> [Viewer]
│ (AI Frame Re-Synthesis)
└──> Latency Budget: < 33.3ms (for 30 FPS)
------------------------------


45



China reveals the paradox of the modern era: nations want global integration for growth, but control and independence for power. Centralization vs interdependence may define the century.
buff.ly/E2V3niW
#GlobalSystems #Technology #Philosophy #WorldEvents
6

Jun 12
🚨 THE WORLD IS CHANGING FAST... BUT IS THERE A BIGGER PLAN? 🌎
Wars. Economic uncertainty. AI. Disclosure.
How are all these events connected?
This Saturday, Charlie Ward welcomes back Ishmael Perez for a fascinating live discussion exploring the bigger picture behind today's headlines and the changes taking place around the world.
👽 Disclosure
🛸 Galactics
🌎 Humanity's Future
❓ Live Q&A
Bring your questions and join the conversation.
📅 Saturday
🕒 3PM UK | 10AM New York
#CharlieWard #IshmaelPerez #InsidersClub #Disclosure #Galactics #UFO #Aliens #CurrentEvents #SpiritualAwakening #TruthSeekers #LiveQA #WorldEvents #Humanity #CosmicDisclosure #CharlieWardShow
6
20
867

Jun 12
🚨 THE WORLD IS CHANGING FAST... BUT IS THERE A BIGGER PLAN? 🌎
Wars. Economic uncertainty. AI. Disclosure.
How are all these events connected?
This Saturday, Charlie Ward welcomes back Ishmael Perez for a fascinating live discussion exploring the bigger picture behind today's headlines and the changes taking place around the world.
👽 Disclosure
🛸 Galactics
🌎 Humanity's Future
❓ Live Q&A
Bring your questions and join the conversation.
📅 Saturday
🕒 3PM UK | 10AM New York
#CharlieWard #IshmaelPerez #InsidersClub #Disclosure #Galactics #UFO #Aliens #CurrentEvents #SpiritualAwakening #TruthSeekers #LiveQA #WorldEvents #Humanity #CosmicDisclosure #CharlieWardShow
1
20

Jun 12
I think the HealthRanger decoded TRUMPS pattern.
Not politics.
A loop.
A repeating divergence point where reality keeps snapping back to the same sequence of events — statements, escalations, deals, denials — over and over again.
Like we’re stuck at the edge of a collapsing timeline… where every outcome bends back into the same shape.
A kind of political Groundhog Day event horizon.
Where diplomacy gets stretched…
competence gets distorted…
and everything eventually falls back into repetition.
Same headlines.
Same shocks.
Same cycle.
Until something finally breaks the pattern and time starts moving forward again.
Until then, it feels less like change…
and more like recursion.
#ChrisWickNews #Politics #WorldEvents #BreakingNews #GlobalShift

1
2
7
150


Jun 11
GoldenGoal Prediction SuperApp is not just building a brand around football.
Our vision goes far beyond a single sport. We are integrating the world's biggest sporting events and global competitions into our platform.
The 2026 FIFA World Cup will be the first major prediction market to be fully integrated into the GoldenGoal ecosystem.
We continue to build and improve this system relentlessly, regardless of our token price. Our focus remains on creating the best prediction experience possible.
The excitement of the World Cup is finally beginning.
Stay tuned and keep watching us.
We're coming with things that will surprise the entire market.
$goldengoal #worldcup #sports #worldevents

23
23
57
2,118

Jun 11
مشرق وسطی وچ اک وار فیر وڈی ج ن گ شروع ہوگئی
#MiddleEast #MiddleEastWar #BreakingNews #WarUpdate #Conflict #GlobalTensions #WorldNews #Geopolitics #InternationalNews #Crisis #WarAlert #NewsUpdate #GlobalConflict #CurrentAffairs #Peace #MiddleEastCrisis #TrendingNow #WorldEvents
3

Jun 11
Another busy week. Let’s slow it down and think clearly. New episode drops tomorrow.
If you want the episode as soon as it’s live — and the occasional written note — the email list is the best way to stay connected.
Link below.
#Military #WorldEvents #PoliticsWithPerspective
1
42

Jun 10
#BreakingNews
In a strongly worded social media post, the President of the United States stated that Iran's military is "in a completely disorganized state" following U.S. military strikes carried out in response to an alleged attack on an American helicopter.
He strongly defended the military action and warned that further strikes could be carried out against Iran's military and security targets if additional threats emerge in the future.
These remarks come at a time when tensions between the United States and Iran are rapidly escalating. The developments have raised fresh concerns about the future of diplomatic negotiations between the two countries and the possibility of a broader conflict across the Middle East region.
Recent events are being viewed as a significant turning point that could have an impact on regional security, international relations, and the global economy. As the situation continues to grow more tense, upcoming political and military actions are drawing the attention of countries around the world.
#USIranTensions #MiddleEast #Geopolitics #InternationalRelations #GlobalSecurity #MilitaryOperations #DiplomaticCrisis #WorldNews #RegionalStability #ForeignPolicy #GlobalAffairs #SecurityAlert #InternationalPolitics #ConflictWatch #MiddleEastCrisis #StrategicDevelopments #WorldEvents #PoliticalNews #LatestUpdate

1
49

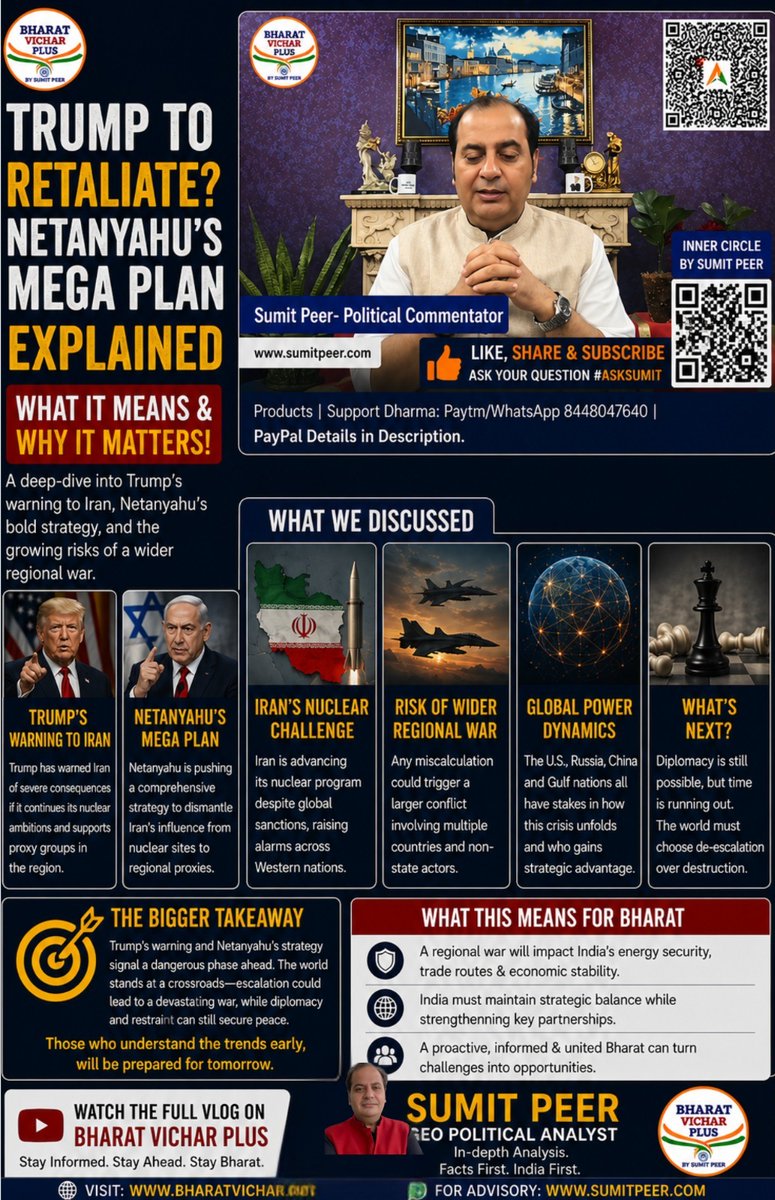

💥 Major updates: Karmelo Anthony has been found guilty and now faces up to life in prison.
The U.S. is responding to Iran after an Apache helicopter was shot down.
Protests are also breaking out in Belfast. Stay tuned for the latest on these developing stories.
#BreakingNews #WorldEvents
1,064

Are We On The Cusp Of Economic Collapse?
Watch this reel and decide for yourself. Then be sure to check out the full Episode 188 of the Eyes Open Podcast on this page for the complete discussion and analysis.
#EyesOpenPodcast #EconomicCollapse #Economy #FinancialCrisis #MarketCrash #Inflation #Recession #DebtCrisis #News #CurrentEvents #QuestionEverything #EconomicNews #FinancialSystem #WorldEvents
16

🚨 MASSIVE BREAKING NEWS! 🌍 Unmissable updates on global events! Dive into the hottest headlines and stay ahead of the curve with the latest scoop 📰🔥 Tap in or tap out! #BreakingNews #GlobalUpdate #StayInformed #ViralNews #FoxNews #Trending #WorldEvents #CurrentAffairs
20