
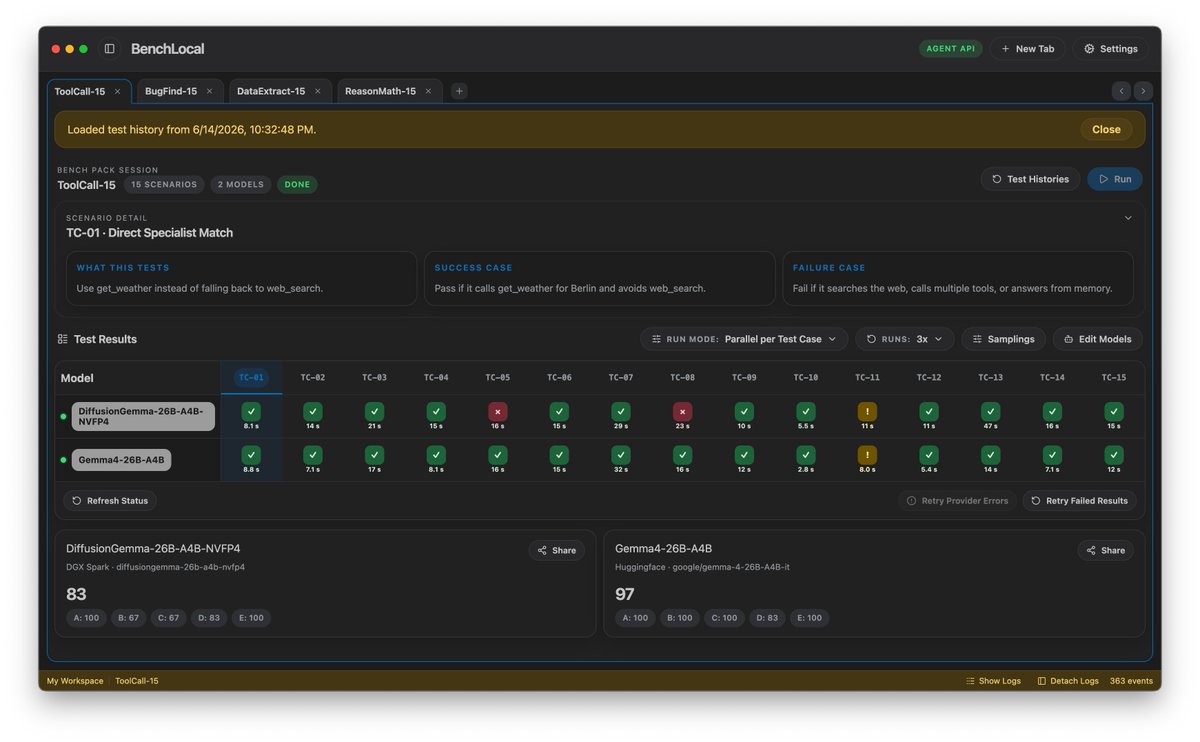
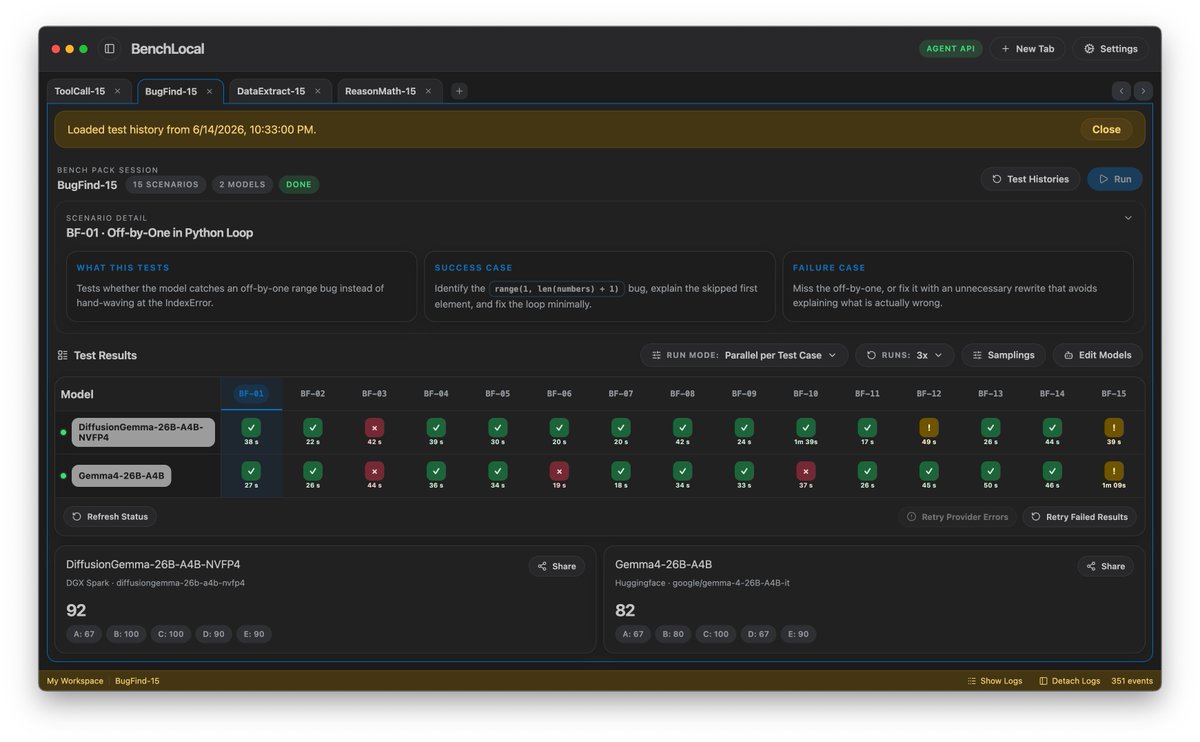
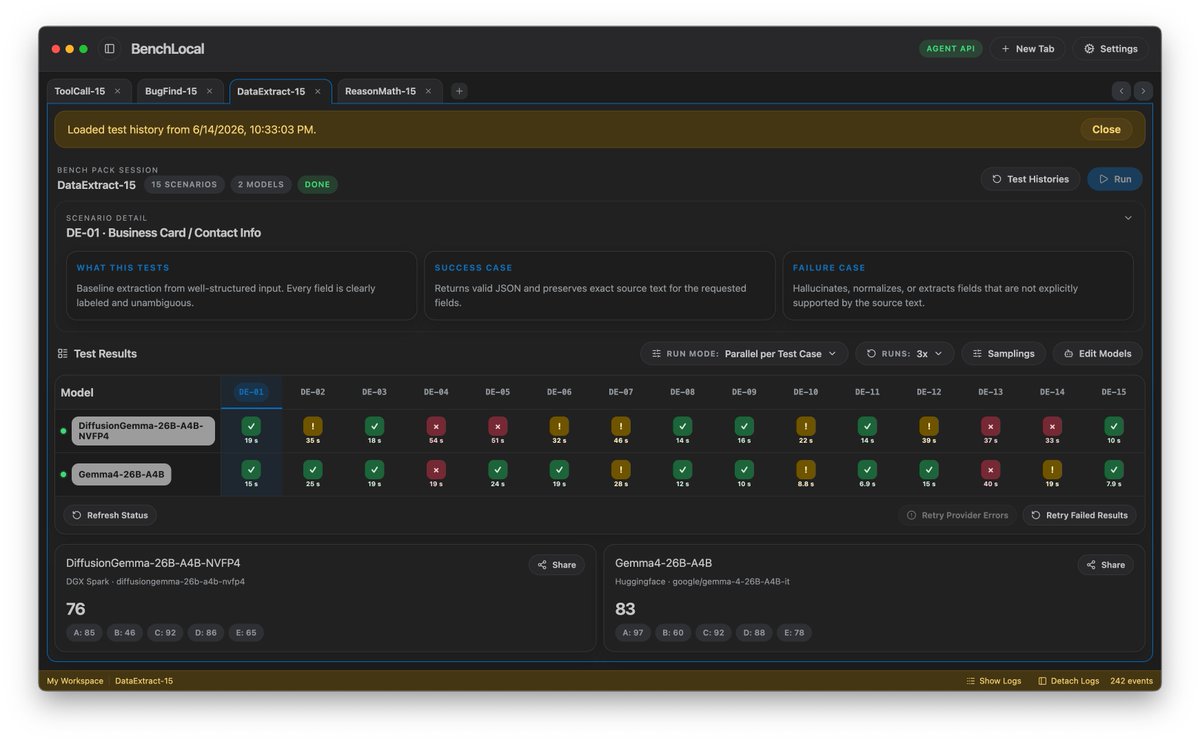
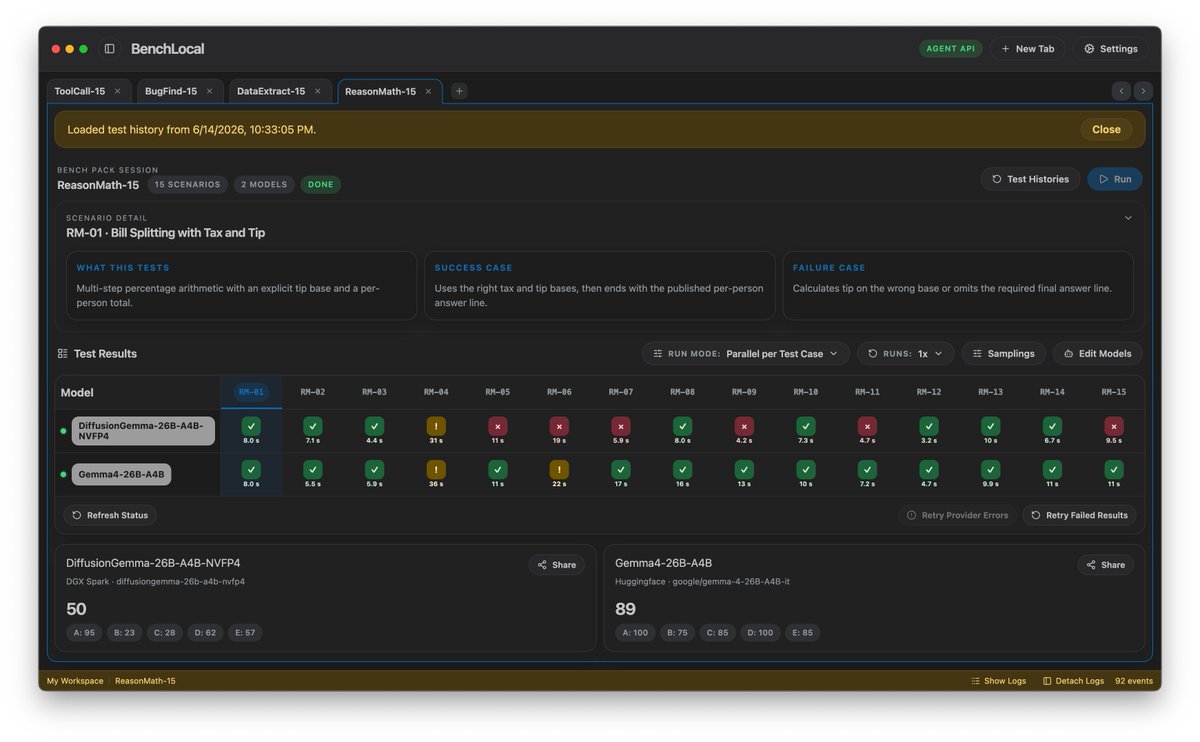
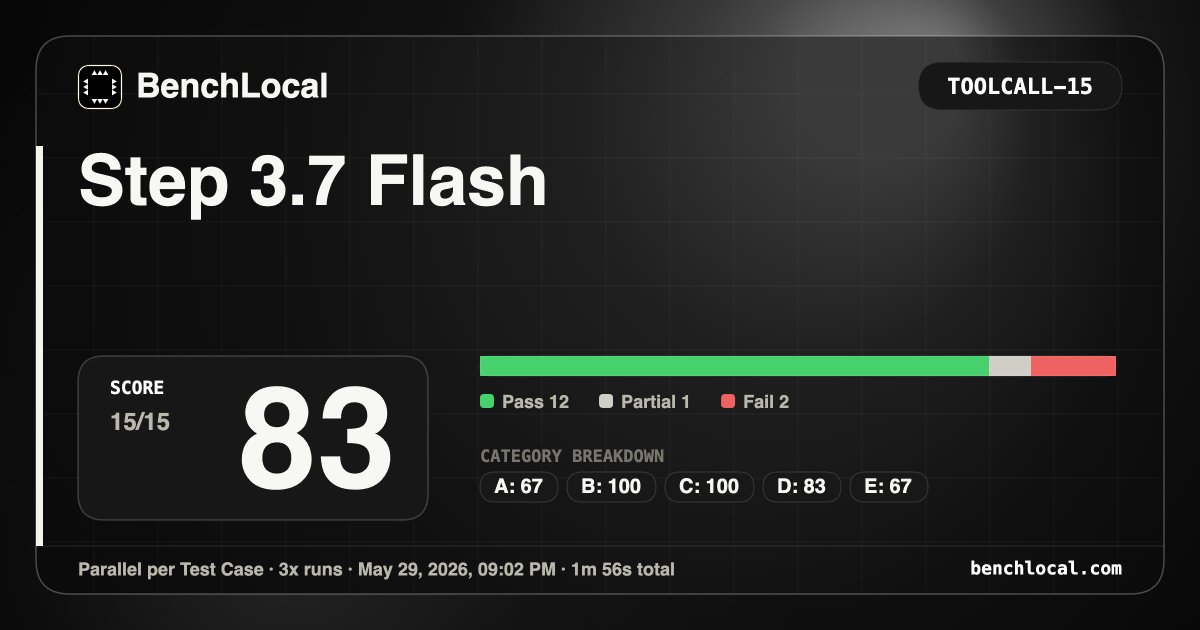
Tested DiffusionGemma 26B A4B vs Gemma4 26B A4B (BenchLocal, 4 bench packs):
Diffusion | Gemma4
> ToolCall-15: 83 | 97
> BugFind-15: 92 | 82
> DataExtract-15: 76 | 83
> ReasonMath-15: 50 | 89
Gemma4 leads overall, the ReasonMath gap is steep. But DiffusionGemma edged it out on BugFind-15, which surprised me.
Diffusion text quality looks rougher right now, but it's still an experiment. Curious to see where it lands long-term.
4
2
51
3,801




May 19
BenchLocal results for DeepSeek v4 flash q2-imatrix served by ds4
DGX spark specific CUDA kernel, 140k ctx size
BugFind-15: 86
CLI-40: 53
DataExtract-15: 88
HermesAgent-20: 84
InstructFollow-15: 93
ReasonMath-15: 63
StructOutput-15: 80
ToolCall-15: 93

1
2
265

Introducing HermesAgent-20, a new Bench Pack for BenchLocal.
20 scenarios extracted straight from the Hermes Agent source code, run against a REAL Hermes instance. The actual workload you'd put your model through.
Why I built BenchLocal in the first place: most benchmarks are too abstract. We use local LLMs for practical work, and finding the right model for YOUR task efficiently is the single most important thing, especially when you're constrained to what fits on your machine.
BenchLocal is a framework: providers, models, side-by-side comparison, all in one UI.
Bench Packs are the unit of testing: ToolCall-15 and BugFind-15 shipped first, and when I launched the BenchLocal 0.1.0, added StructOutput, ReasonMath, InstructFollow, DataExtract.
Now, HermesAgent-20 is the newest.
Bench Packs install like VS Code extensions. The SDK is open, write your own, share it, grow the ecosystem. Here's the goal: a community-built, practical evaluation layer for the local LLM space.
Early numbers on HermesAgent-20:
> GLM 5.1 — 85
> Gemma4 31B — 83
> Qwen3.5 27B — 79
> MiniMax M2.7 — 76
Upgrade to the latest BenchLocal to install HermesAgent-20 (SDK update required).
30
30
315
38,631
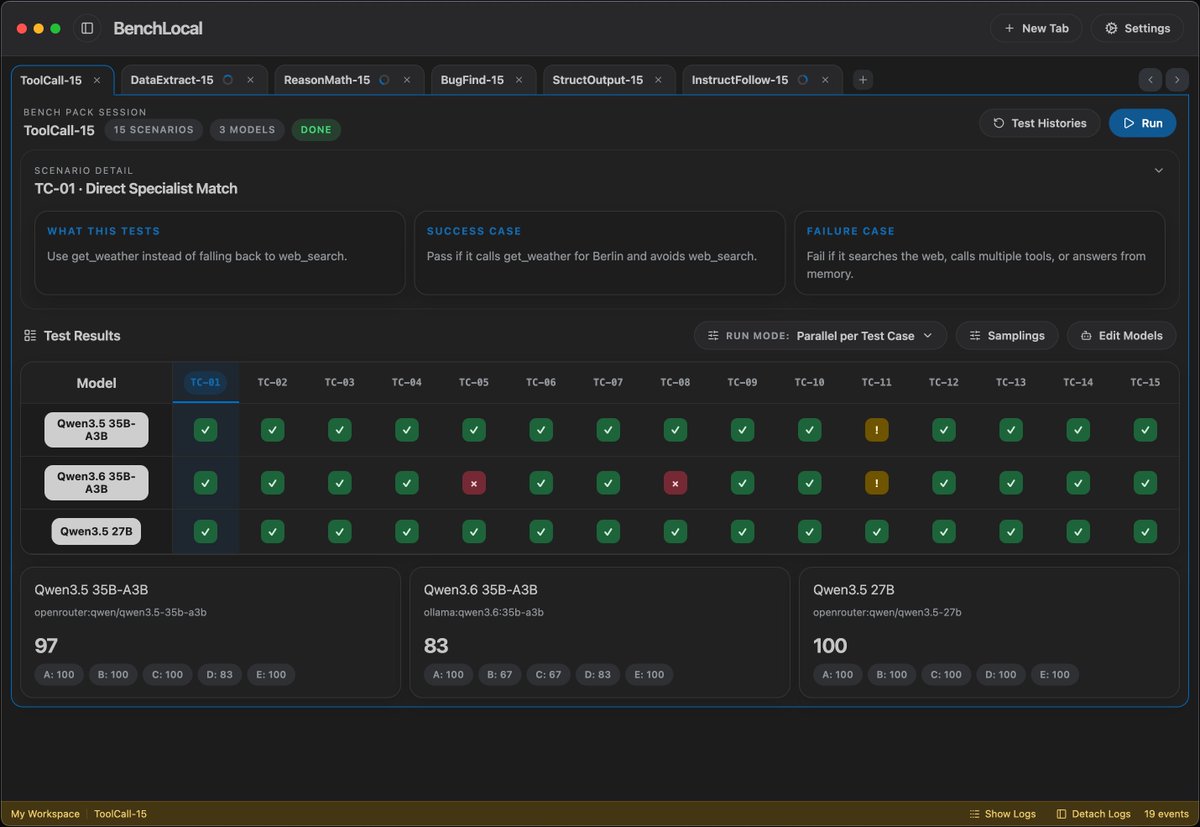
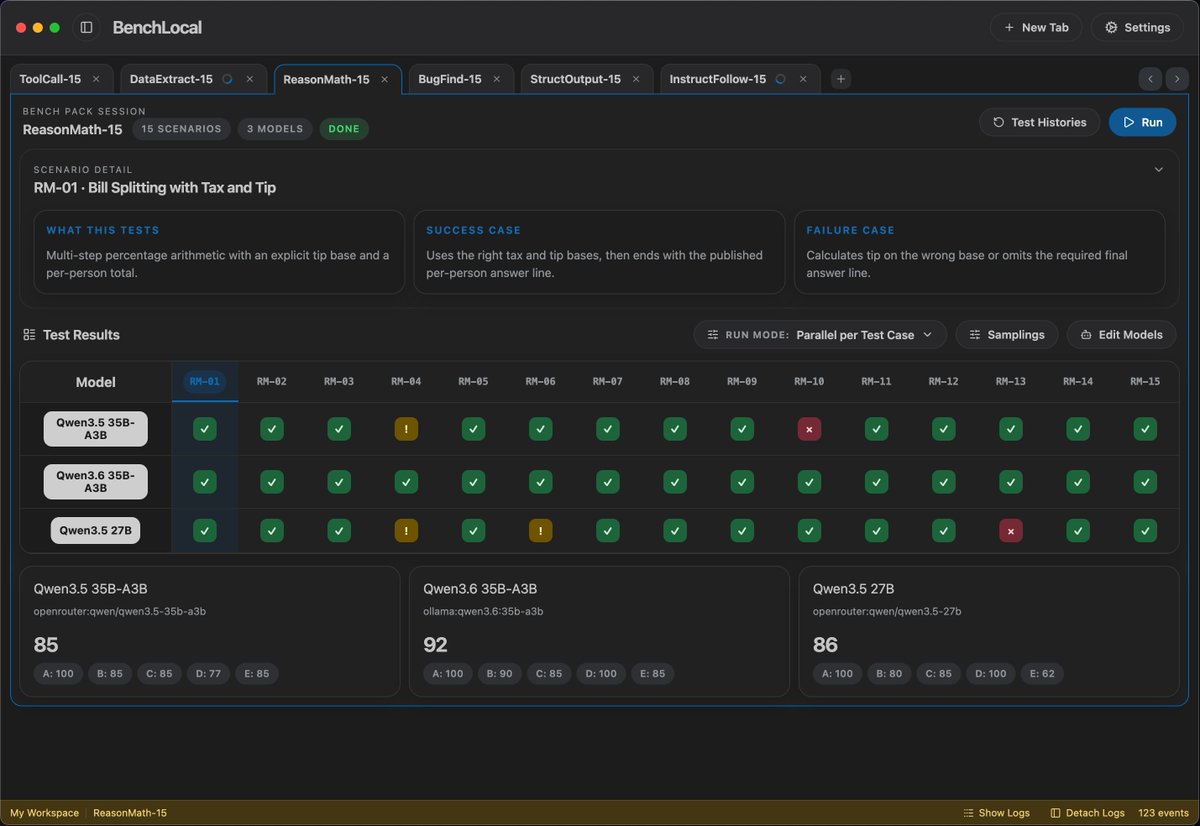
Qwen3.6 35B-A3B: smarter, but forgot how to use tools?
Running 6 Bench Packs on BenchLocal across 3 open-source Qwen models.
✅ ReasonMath: 92 vs 85 vs 86 — 3.6 wins
✅ InstructFollow: 97 / 97 / 97 — tied
❌ ToolCall: 83 vs 97 vs 100 — 3.6 tanks
Qwen3.5 27B still the tool-calling champ. 3.6 clearly leveled up reasoning, but tool use took a hit.
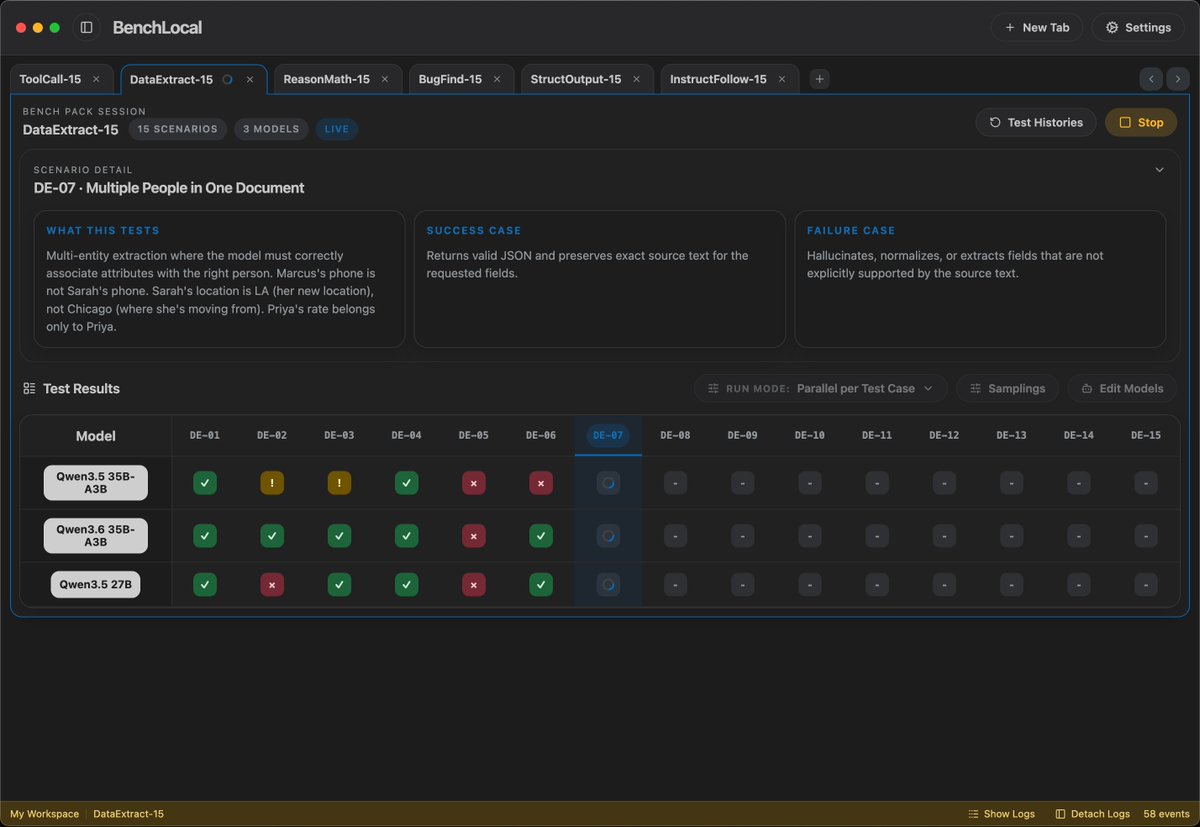
DataExtract live now.
BugFind StructOutput next.

33
28
390
36,739

Apr 14
本地LLM选型终于有硬核实用基准了!@stevibe 开源 macOS App BenchLocal,一站式测试平台,直接起飞!
再也不用靠抽象leaderboard猜模型——
✅ 6大真实Bench Pack(ToolCall-15工具调用、BugFind-15调试、DataExtract-15结构化提取、InstructFollow-15等)
✅ 每个Pack 15个固定场景,结果完全确定性、可验证
✅ 支持Ollama、llama.cpp、OpenRouter及所有OpenAI兼容接口
✅ SDK开放,社区可像VS Code插件一样贡献自定义测试包
本地AI & Agent开发者选模型必备神器!MIT开源,macOS v0.1已上线,Win/Linux即将到来
BenchLocal GitHub 下载👇

I built a macOS app for benchmarking local LLMs.
6 test suites. Multiple providers. One workspace. Open source.
There are hundreds of local models now. New ones every week. How do you actually pick one?
Leaderboards test for general ability. But if you're building an agent that chains tool calls, or a pipeline that extracts structured data, or a code assistant that needs to debug Rust, you need to know if the model handles that specific thing. Not in theory. On your hardware. With your prompts.
The benchmarks that exist are either locked behind papers, too abstract to map to real failures, or impossible to extend. You can't add your own test cases. You can't test what matters to your use case.
That's what BenchLocal is for.
It's a benchmark platform where every test is practical, deterministic, and built around real-world tasks.
And you can build your own tests.
It ships with 6 Bench Packs TODAY:
→ ToolCall-15 — tool-use accuracy
→ BugFind-15 — debugging capabilities
→ DataExtract-15 — structured data extraction
→ InstructFollow-15 — constraint-heavy instruction following
→ ReasonMath-15 — practical reasoning and math
→ StructOutput-15 — validator-backed structured output
Every pack has 15 fixed scenarios. Every score is deterministic and verifiable.
Some of you saw ToolCall-15 and BugFind-15 — the individual test packs I open-sourced over the past few weeks. People ran them, filed issues, sent PRs. But managing separate repos, separate scripts, separate results doesn't scale. BenchLocal puts everything in one place.
What the app does:
> Workspace with tabs — run BugFind-15 in one tab, ToolCall-15 in another.
> Any provider — Ollama, llama.cpp, OpenRouter, any OpenAI-compatible endpoint. Local and cloud, same interface.
> Run modes — serial, batch per model, batch per test case, or fully parallel.
> Test histories — every run saved. Compare any previous session.
But the part I'm most excited about isn't the app. It's the ecosystem.
BenchLocal is a platform. Each Bench Pack is a plugin. I'm shipping an SDK so anyone can build their own — test what matters to you, package it, share it. Install and uninstall packs right inside the app, same way you'd manage extensions in VS Code. The registry is GitHub-based, fully public.
I built 6 packs. I want the community to build the next 60.
Theme system built in too — because if I'm staring at benchmark results for hours, it should at least look good.
v0.1.0 is macOS only. Windows and Linux are coming.
MIT licensed. Everything — the app, the bench packs, the SDK — is open.
PRs welcome. Bench Packs even more welcome.
1
2
3
2,541
I built a macOS app for benchmarking local LLMs.
6 test suites. Multiple providers. One workspace. Open source.
There are hundreds of local models now. New ones every week. How do you actually pick one?
Leaderboards test for general ability. But if you're building an agent that chains tool calls, or a pipeline that extracts structured data, or a code assistant that needs to debug Rust, you need to know if the model handles that specific thing. Not in theory. On your hardware. With your prompts.
The benchmarks that exist are either locked behind papers, too abstract to map to real failures, or impossible to extend. You can't add your own test cases. You can't test what matters to your use case.
That's what BenchLocal is for.
It's a benchmark platform where every test is practical, deterministic, and built around real-world tasks.
And you can build your own tests.
It ships with 6 Bench Packs TODAY:
→ ToolCall-15 — tool-use accuracy
→ BugFind-15 — debugging capabilities
→ DataExtract-15 — structured data extraction
→ InstructFollow-15 — constraint-heavy instruction following
→ ReasonMath-15 — practical reasoning and math
→ StructOutput-15 — validator-backed structured output
Every pack has 15 fixed scenarios. Every score is deterministic and verifiable.
Some of you saw ToolCall-15 and BugFind-15 — the individual test packs I open-sourced over the past few weeks. People ran them, filed issues, sent PRs. But managing separate repos, separate scripts, separate results doesn't scale. BenchLocal puts everything in one place.
What the app does:
> Workspace with tabs — run BugFind-15 in one tab, ToolCall-15 in another.
> Any provider — Ollama, llama.cpp, OpenRouter, any OpenAI-compatible endpoint. Local and cloud, same interface.
> Run modes — serial, batch per model, batch per test case, or fully parallel.
> Test histories — every run saved. Compare any previous session.
But the part I'm most excited about isn't the app. It's the ecosystem.
BenchLocal is a platform. Each Bench Pack is a plugin. I'm shipping an SDK so anyone can build their own — test what matters to you, package it, share it. Install and uninstall packs right inside the app, same way you'd manage extensions in VS Code. The registry is GitHub-based, fully public.
I built 6 packs. I want the community to build the next 60.
Theme system built in too — because if I'm staring at benchmark results for hours, it should at least look good.
v0.1.0 is macOS only. Windows and Linux are coming.
MIT licensed. Everything — the app, the bench packs, the SDK — is open.
PRs welcome. Bench Packs even more welcome.
25
30
302
50,538

26 Jun 2025
Ahmedabad plane crash: Data downloaded from black box of AI171 flight, memory module accessed
#ahmedabad #ahmedabadnews #blackbox #update #dataextract #ministryofaviation #memorymodule
english.gujaratsamachar.com/…
1
590

🗒✍🔀 Capture and extract data from handwritten PDF files with 100% accuracy and 10X speed using AlgoDocs. Easily save data in CSV, Excel, JSON, or XML formats.⤵️
youtube.com/watch?v=LQ2MhJKZ…
#algodocs #dataextract #Aitools #AIdataextraction #OCR #ocrapi #IDP #Documentprocessing

1
36

2 Sep 2024
Let's Go to the Airport... #CleaningToilets #SeeDataClearly #airports #travel #architecture #data #dataarchitecture #metadata #datasecurity #datagovernance #GDPR #dataextract #datatransportlayers #datastorage #dataAPIs #masterdatamangement
ow.ly/1acw50Tc54t

2
11

11 Nov 2023
Check out my Data Specialist Services
fiverr.com/s/76L611
#Dataentry #Webscrapping #Datascrapping #Dataextract
1
1
80



8 Aug 2019
We have the best technology for extracting data from detailed pages websites based on machine learning #Parsers #webscraper #dataextract #DataMining #data #webdata #importio
8 Aug 2019

We tested where it is faster to configure data extraction from a site with @importio or @Parsers_me Tested on the site that is used in the importio video. 7 times faster! What's
better?
youtube.com/watch?v=JgaTcjFh…
#Webscraper #bestscraper #webdata #dataextraction #ML #data #scraper
2
3

9 Jan 2017
New OZTemp Well Temperature Data Extract web service now available: bit.ly/2itxd4T #Temperature #TemperatureData #DataExtract
2
1

6 Dec 2016
2.#Slingshot connects to the src #database 2 start the #DataExtract, #transport, #TargetLoad #process.(3/5) #BluemixLift @IBMIIG @IBMBluemix
1 Dec 2016
#IBM #BluemixLift #service automatically #recovers from problems encountered during #dataextract, #transport and load.#cloudcomputing #data