
I am pleased to share that our paper, “atspR: An R package for automated time series preprocessing,” has been published in SoftwareX.
Paper DOI: doi.org/10.1016/j.softx.2026…
#TimeSeries #RPackage #DataPreprocessing #MachineLearning #SoftwareX #DataScience #Research
2

Jun 12
🤯 Stuck with AI & Machine Learning Research Challenges? 🧠
#phdizone #airesearch #machinelearningresearch #artificialintelligence #machinelearning #deeplearning #neuralnetworks #datapreprocessing #predictivemodeling #algorithmdevelopment #researchinnovation #researchguidance
7

Jun 6
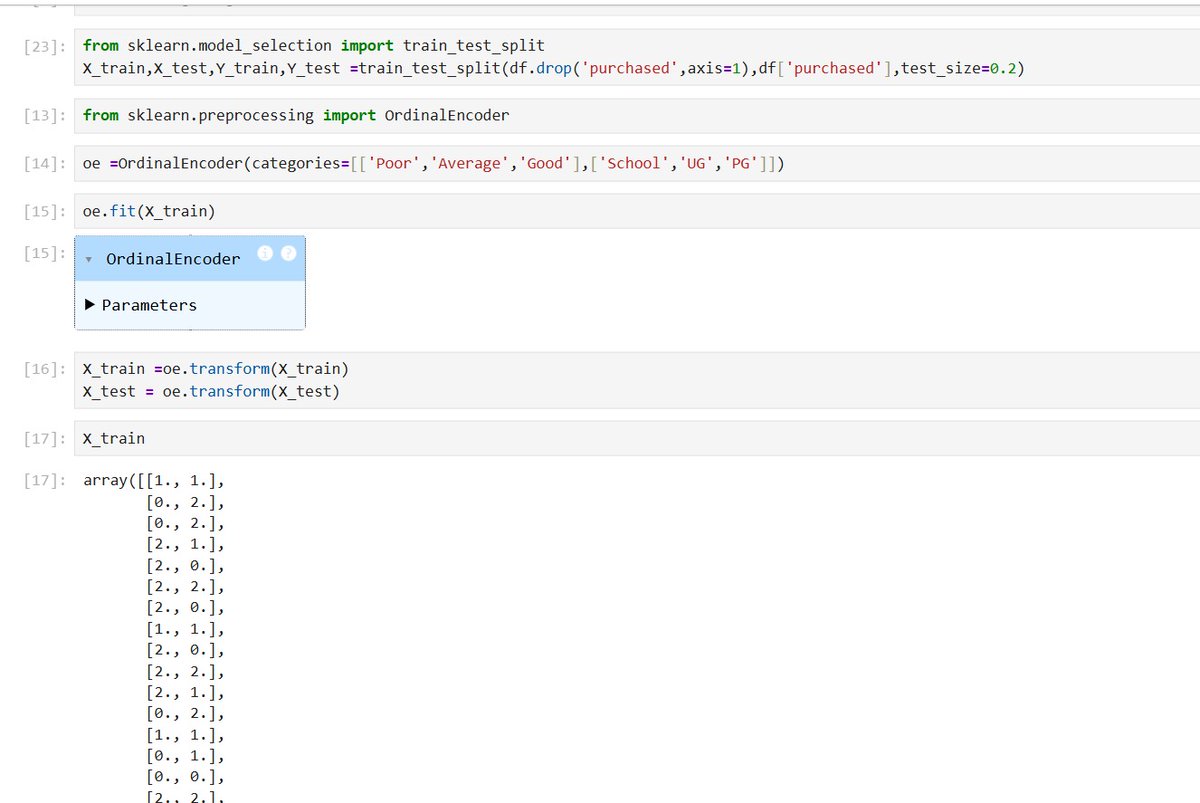
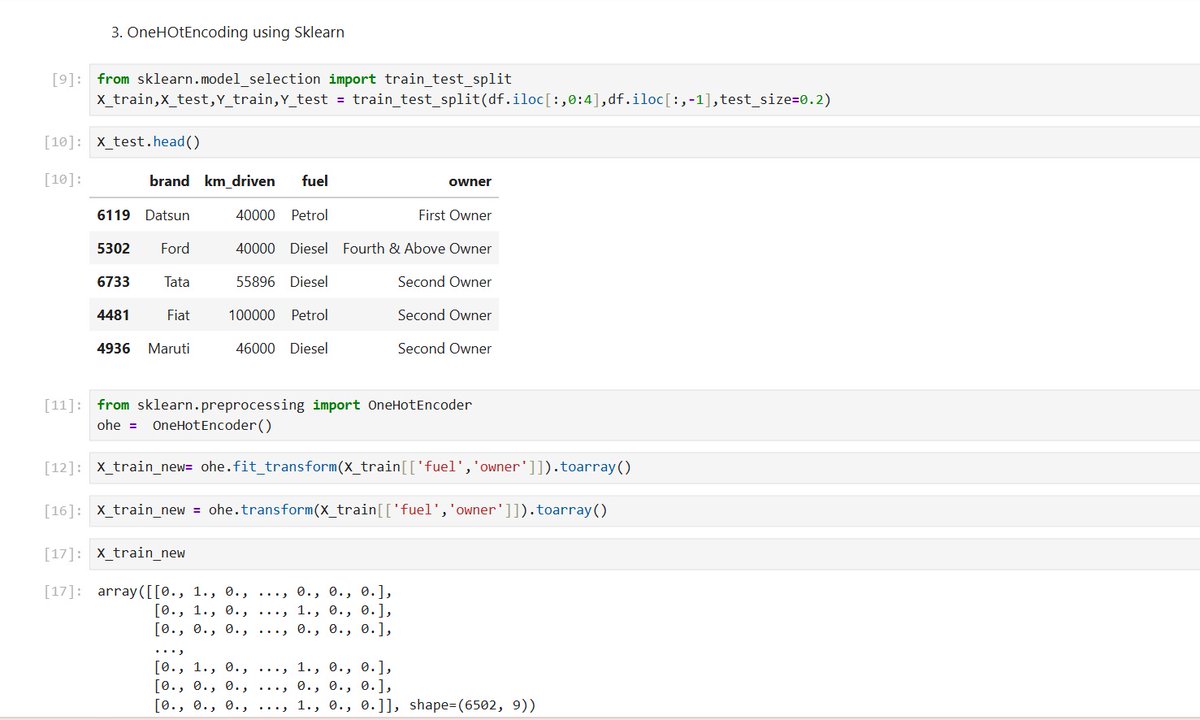
Day4 of learning ML
I got hands-on with datapreprocessing and learned:
OrdinalEncoding
OneHotEncoding
Wht I found interesting:
OneHot Encoding isn't just about converting categories into nums
Without properly handling cols using ColumnTransformer, things can get messy rly fast


3
28
744

18 Nov 2025
Day 11 of #100DaysOfMachineLearning
Today I covered one of the most important steps in ML:
Data Preprocessing and Feature Engineering.
Clean data matters more than complex models.
Handling missing values, encoding categories, scaling features, and engineering new ones can transform your results.
📖 Full article (free):
medium.com/@ShubhamVerma28/d…
#MachineLearning #DataScience #AI #MLForBeginners #FeatureEngineering #DataPreprocessing #DeepLearning #AIExplained #TechLearning
2
4
151

6 Nov 2025
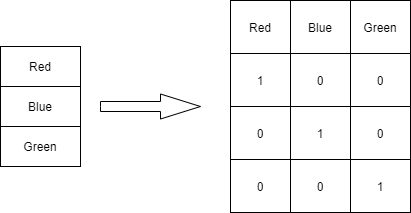
Encoding in ML = turning text into numbers so models can understand.
Label Encoding → assign a number to each category (male=0, female=1).
One-Hot Encoding → create new columns for each category (male=[1,0], female=[0,1]).
Use Label when categories have order or for trees.
Use One-Hot for linear models or neural nets.
#MachineLearning #DataPreprocessing
4
122

13 Sep 2025
Discover 'Data Mining and Business Intelligence’ on Amazon India.
link : amzn.in/d/8rL22xw
#DataMining
#BusinessIntelligence
#Datapreprocessing
#Datacleaning
#featureengineering
#PredictiveModeling
#TextAnalytics
#Analytics
#AI
#DataDemocratization
#ksom
#kiit
1
32

29 Jul 2025
📊 Why Scaling Matters in Trading Models
Before your model learns anything, scaling ensures that no feature dominates just because it has a larger numeric range. It’s a critical step in preprocessing financial data, especially in regression or distance-based models.
Here are the key steps from a recent notebook on preparing gold price data for prediction models:
✅ Import the data - Using custom input parameters
✅ Check & drop NaN values - Clean dataset = reliable model
✅ Scale features - Standardise to avoid bias in regression
✅ Split into X & Y variables - Independent & dependent sets
💡 Why scaling matters:
Without it, features with larger numeric ranges can overshadow others, reducing the model’s ability to learn balanced patterns.
Details of the Python code are in the FREE preview of the course in Section 3, Unit 5:
quantra.quantinsti.com/start…
Are you someone who wants to apply AI in trading?
Curious how GenAI, LLMs, and machine learning are changing the trading landscape?
Then this conference is for YOU.
🎯 QuantInsti’s Algorithmic Trading Conference 2025
📅 Date: 23 September 2025
🕒 Time: 6:00 PM IST | 8:30 PM SGT | 8:30 AM EDT
💻 Free | Online | Global
What’s happening?
Workshop by Tucker Balch (Emory University)
Explore real-world use of AI, LLMs & price data in trading strategies.
See how AI models are predicting inter-stock relationships, with live Q&A!
Topics include:
How AI is transforming trading desks
Emerging skills for quants
GenAI's role in quant education
What the future of finance looks like with AI
👥 Who should attend?
- Aspiring Quants
- Traders & Finance Professionals
- Coders & ML Engineers
- Students & Career Switchers
🎟️ Ready to see how AI is shaping the future of trading?
🔗 Register now - spots are limited!
👉 quantinsti.com/algorithmic-t…
#AlgoTrading #AIinTrading #QuantConference #QuantFinance #GenAI #LLM #FinanceCareers #QuantLearning #QuantInsti #EPAT #MachineLearning #AlgorithmicTrading #DataScience #Python #FeatureEngineering #Quant #TradingModels #DataPreprocessing #Finance

2
289

10 Jul 2025
AI Data Processing: Get Smarter Results With These Steps
#AIdata #DataPreprocessing #MachineLearning #AISolutions #DataCleaning #AIStrategy #DataScience #AIModels #DataPreparation #ArtificialIntelligence
2
479

5 Jul 2025
"Other Helpful Skills
📊 #Datapreprocessing (resizing, normalization)
📦 Understanding how to use #DataLoaders (esp. in PyTorch)
🔍 #Debugging #neuralnetwork behavior"
4
22

5 Jul 2025
Day 76/100 ✅
• Almost done with SyncMeet — doing final checks to ensure everything runs error-free.
• Started data preprocessing for my ML project.
• Solved a few LeetCode problems.
#100DaysOfCode #MERN #MachineLearning #DataPreprocessing #LeetCode #BuildInPublic
3
36

11 Jun 2025
🤯 Just watched the Enterprise RAG Challenge. My mind is absolutely blown, and it solidified my next #BuildInPublic project!
Imagine this: Participants had to process 100 annual reports, each up to 1000 pages, in just 2.5 hours! This isn't just about RAG; it's about the data nightmare before the RAG. #RAG #LLMs #AI #DataPreprocessing
1
1
3
1,092

2 Jun 2025
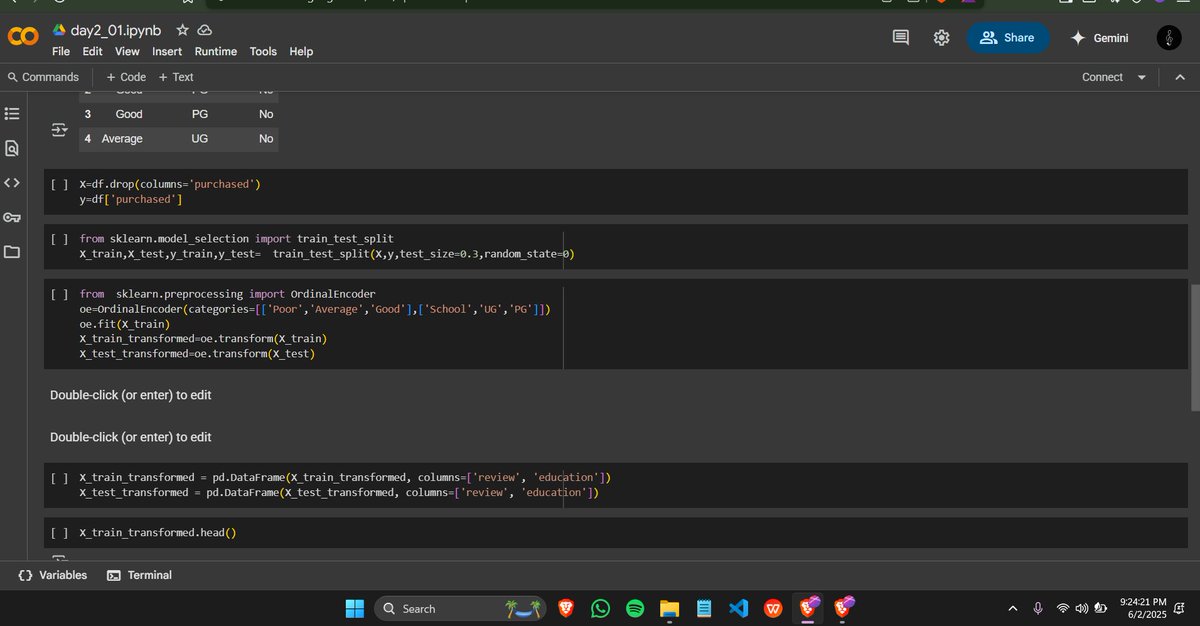
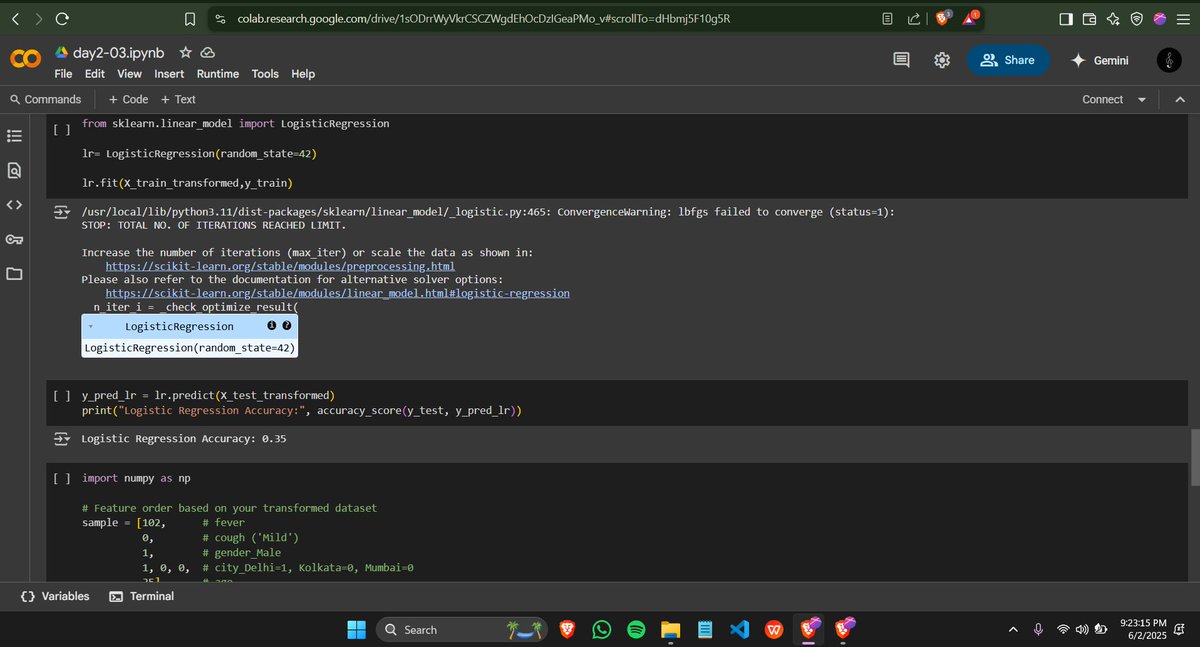
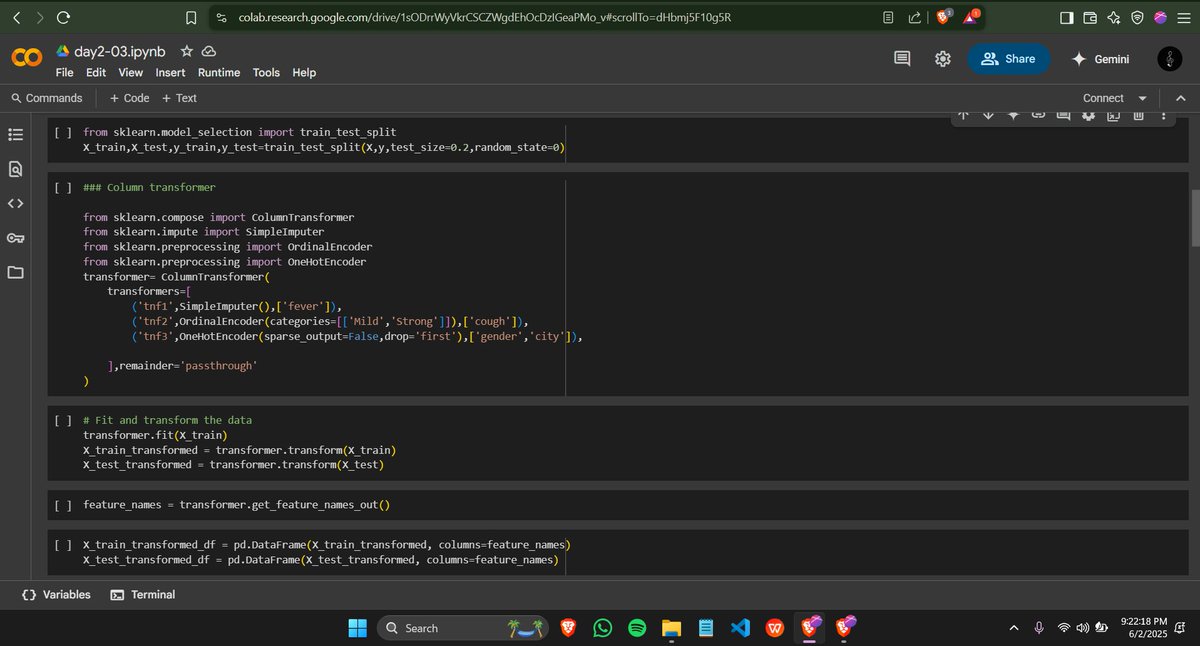
Day 02 – #60DaysOfLearning2025
Today I revised encoding techniques in ML:
Ordinal encoding ,Nominal encoding & Column Transformers.
github:github.com/iamdipsan/Learnin…
#LSPPDay2 #LearningWithLeapfrog #DataPreprocessing #MachineLearning #Encoding #60DaysChallenge
@lftechnology

3
402

3 May 2025
🎯 Iris veri seti üzerinde veri ön işleme (data preprocessing) sürecini uygulamalı olarak gösterdim.
🔗İzlemek için tıkla: [ytbe.app/go/Yk6pI4FN]
💻 GitHub kodu profilde.
Daha fazla içerik için takipte kal✨
#VeriÖnİşleme #DataPreprocessing #Python #MachineLearning #colab

11
419

25 Apr 2025
Struggling with Skewed Data? Here’s How to Fix It!🚀
Join us for a live session on April 30 at 11 AM PDT with Ammar Asim, Data Engineer Trainee at Data Science Dojo. Learn how skewed datasets impact models and insights, explore resampling techniques like SMOTE, normalization, and stratified sampling, and get hands-on Python demos to apply these methods effectively.
🔗 RSVP now to secure your spot: hubs.la/Q03jTCbn0
What we will cover:
✔ Understand the impact of skewed data on ML models.
✔ Learn Python techniques for normalization, SMOTE, and stratified sampling.
✔ Grasp the theory behind these methods for real-world application.
✔ Explore NLP strategies for handling imbalanced text data and bias.
#DataScience #MachineLearning #AIModels #DataPreprocessing #SkewedDataset #Python #AI

1
1
3
1,514

15 Apr 2025
#DataPreprocessing is key to building strong #MachineLearning pipelines. It involves cleaning raw data, transforming it into structured formats & reducing complexity for better performance.
Learn more about building efficient #ML pipelines here:
tenupsoft.com/blog/building-…
@tenupsoft

2
17

3 Apr 2025
Day 4 of #DataAnalytics with Excel: Mastering Data Cleaning!
Today, I levelled up my #Excel skills by learning essential data cleaning techniques. Here’s what I practised:
#DataCleaning #ExcelTips #DataPreprocessing #LearnInPublic #DataJourney
1
1
1
62
30 Mar 2025
Struggling with Skewed Data? Here’s How to Fix It!🚀
Join us for a live session on April 30 at 11 AM PDT with Ammar Asim, Data Engineer Trainee at Data Science Dojo. Learn how skewed datasets impact models and insights, explore resampling techniques like SMOTE, normalization, and stratified sampling, and get hands-on Python demos to apply these methods effectively.
🔗 RSVP now to secure your spot: hubs.la/Q03f22Wn0
What we will cover:
✔ Understand the impact of skewed data on ML models.
✔ Learn Python techniques for normalization, SMOTE, and stratified sampling.
✔ Grasp the theory behind these methods for real-world application.
✔ Explore NLP strategies for handling imbalanced text data and bias.
#DataScience #MachineLearning #AIModels #DataPreprocessing #SkewedDataset #Python #AI

1
3
1,597
25 Feb 2025
📊 Handling Skewed Data: Practical Techniques for Better Models🚀
Join us for a live session on March 19 at 11 AM PDT with Ammar Asim, Data Engineer Trainee at Data Science Dojo. Learn how skewed datasets impact models and insights, explore resampling techniques like SMOTE, normalization, and stratified sampling, and get hands-on Python demos to apply these methods effectively.
🔗 RSVP now to secure your spot: hubs.la/Q0380Zf10
What we will cover:
- Gain a deep understanding of how skewed datasets impact machine learning models and analytical outcomes.
- Step-by-step Python implementations of techniques to address data skewness, including normalization and transformation methods, resampling approaches like SMOTE, and stratified sampling.
- Breakdown of the theoretical foundations behind these methods to understand how to apply them effectively in real-world scenarios and when to use each approach for optimal results.
- Explore how language models deal with imbalanced text data, techniques for managing rare words and underrepresented topics, and bias mitigation strategies in NLP models.
#DataScience #MachineLearning #AIModels #DataPreprocessing #SkewedDataset #Python #AI

2
9
1,167

18 Feb 2025
Zentris 🚀 Data loading and preprocessing: Load and manage large datasets using Hugging Face’s datasets library, tokenize text data (questions and answers) with the LLaMa 3.1 tokenizer into model-understandable numerical tokens. Then, use the apply_chat_template() function to structure the data into “system” (system prompt), “user” (question), and “assistant” (answer) for efficient model training. #AI #MachineLearning #DataPreprocessing #HuggingFace #LLaMa

2
159

11 Jan 2025
🎯 Standardization vs. Scaling in Machine Learning 🚀#MachineLearning #DataScience #AI #DataPreprocessing #ContinuousLearning

1
11
230