
May 26
How did #ECCV reviews treat you? 😬 If you're not that happy — and you work on #unlearning, #modelediting, #modelmerging, or #interpretability — consider submitting to the 3rd Workshop and Challenge on Unlearning and Model Editing at @eccvconf
We accept both full papers and extended abstracts, so there's a format for every contribution.
📅 Submission deadline: 9 July 2026 (AoE)
🔗openreview.net/group?id=thec…

📢CPF: U&ME Workshop @ ECCV 2026 @eccvconf
We invite submissions on machine unlearning, model editing, and related topics including efficient adaptation, and responsible AI.
Details at: sites.google.com/view/u-and-…
@_iAc #ECCV #ECCV2026 #Unlearning #AIsafety #ResponsibleAI

3
3
1,151
May 18
🧠 Excited to announce 𝕌&𝕄𝔼 𝟚𝟘𝟚𝟞— 𝘁𝗵𝗲 𝟯𝗿𝗱 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 & 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲 𝗼𝗻 𝗨𝗻𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗠𝗼𝗱𝗲𝗹 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 @eccvconf
Organized with @Hussain68018934 @THassner @thakralkartik78 @BrigliaRosaria @MayankVatsa3 @dgolano @sijialiu17
📅 September 8–9, 2026 📍 Malmö, Sweden
How do we fix, update & align large generative models — without retraining from scratch?
🎤 Confirmed Speakers:
Yezhou Yang — Arizona State University
Fabio Galasso — Sapienza University of Rome
William Shen — University of Cambridge
More speakers coming soon!
Stay tuned for submission details 👇
sites.google.com/view/u-and-…
#ECCV2026 #MachineLearning #ModelEditing #MachineUnlearning #GenerativeAI #DeepLearning

7
11
1,552

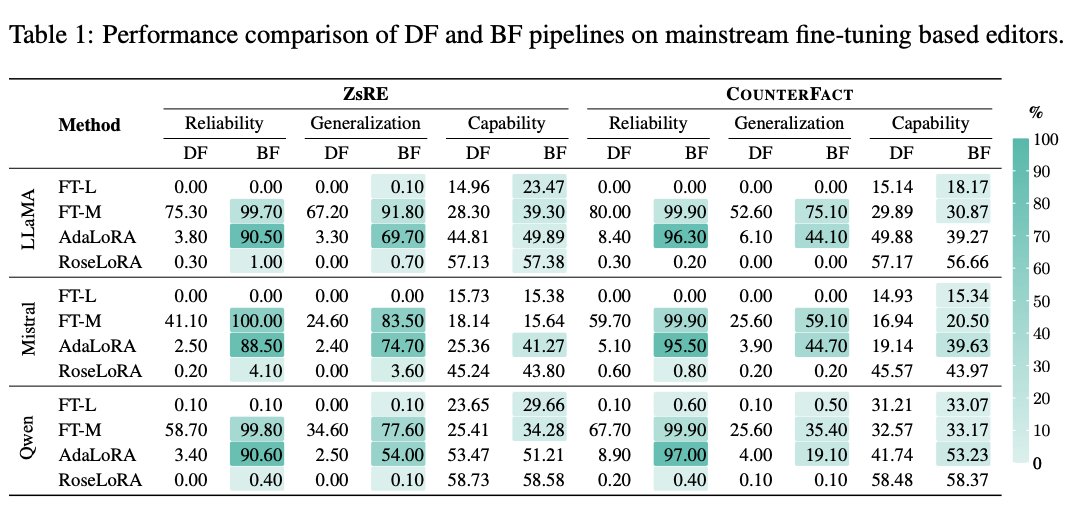
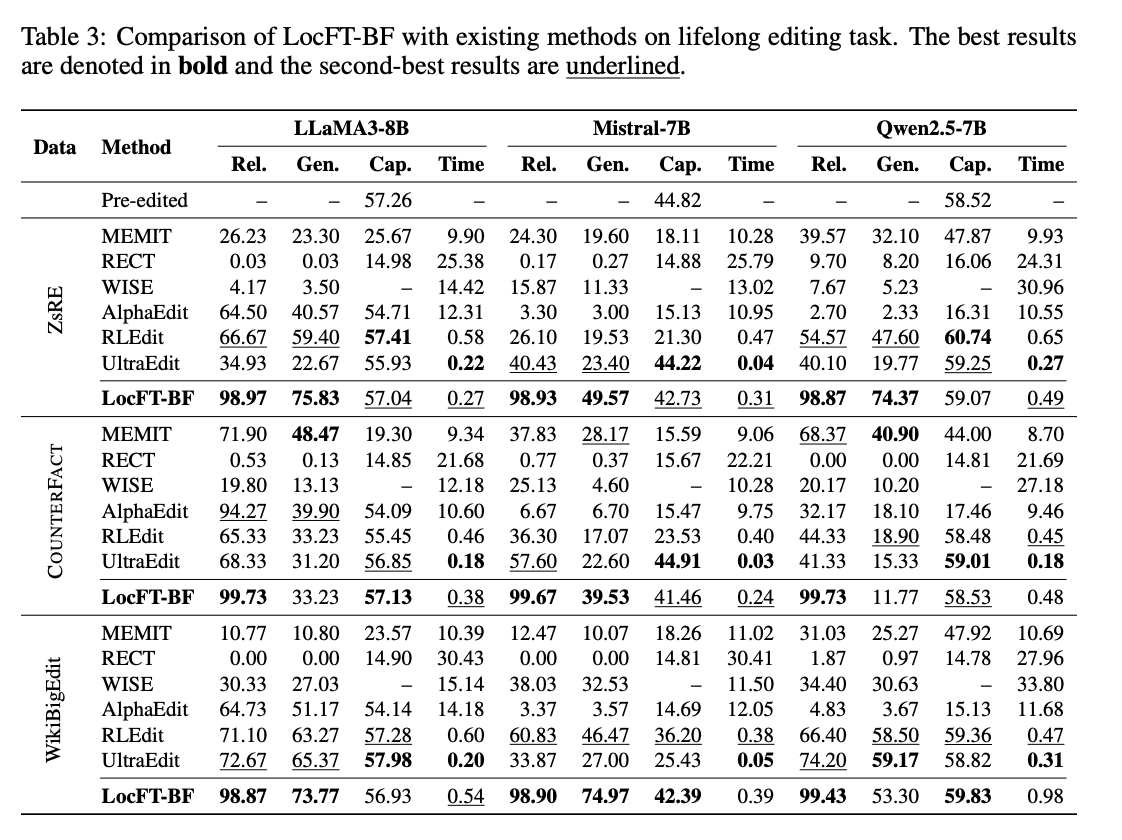
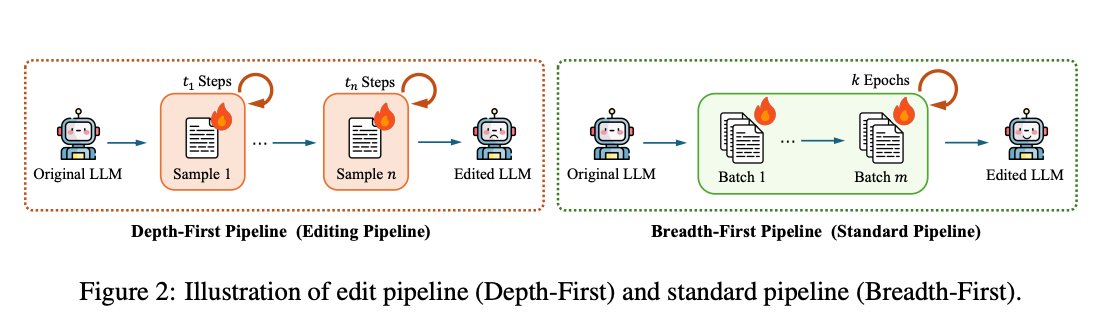
🚀 Our paper “Fine-Tuning Done Right in Model Editing” is accepted to @iclr_conf 2026! Huge congrats to @10k_miles_yang
Fine-tuning is NOT weak for model editing. The pipeline was suboptimal. Implementation matters more than we thought.
We show that standard breadth-first fine-tuning localized tuning beats SOTA, scales to 100K edits and 72B models.
📄 Paper: arxiv.org/abs/2509.22072
💻 Code: github.com/WanliYoung/FT4Edi…
#ModelEditing #KnowledgeEditing #finetuning #ICLR2026
2
1
4
228

14 Nov 2025
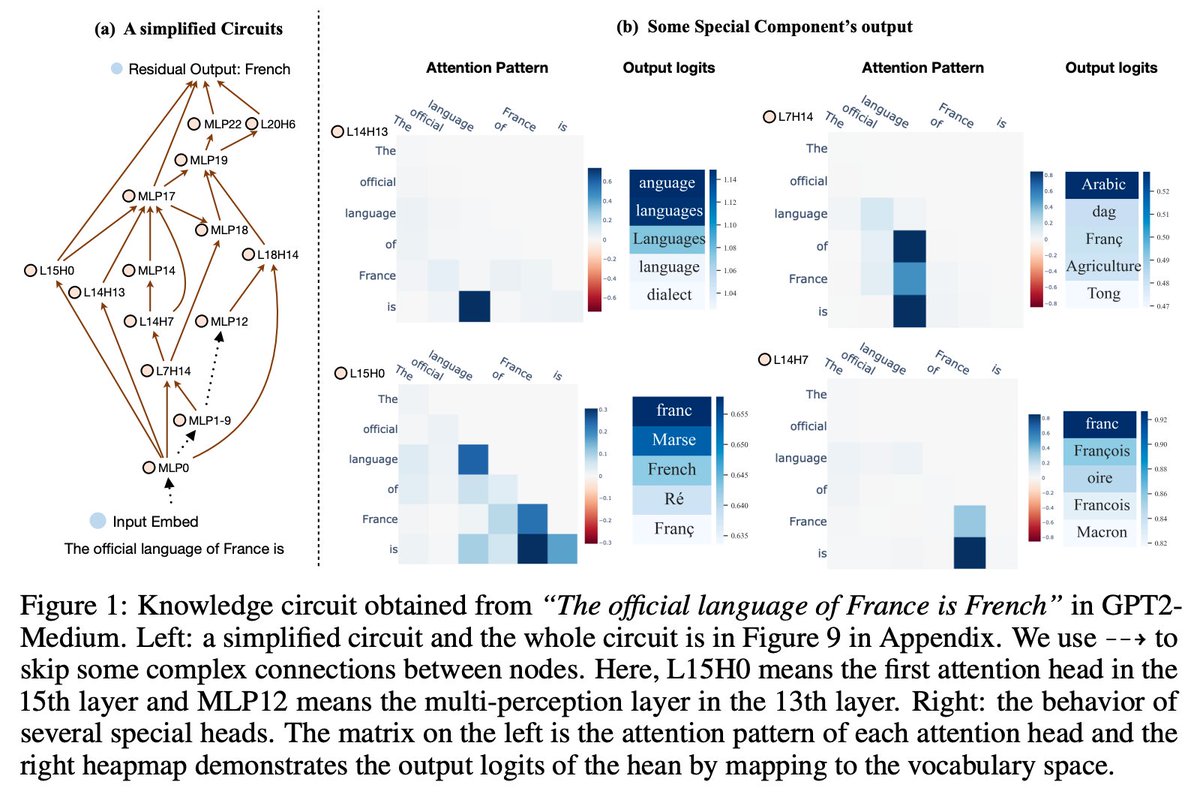
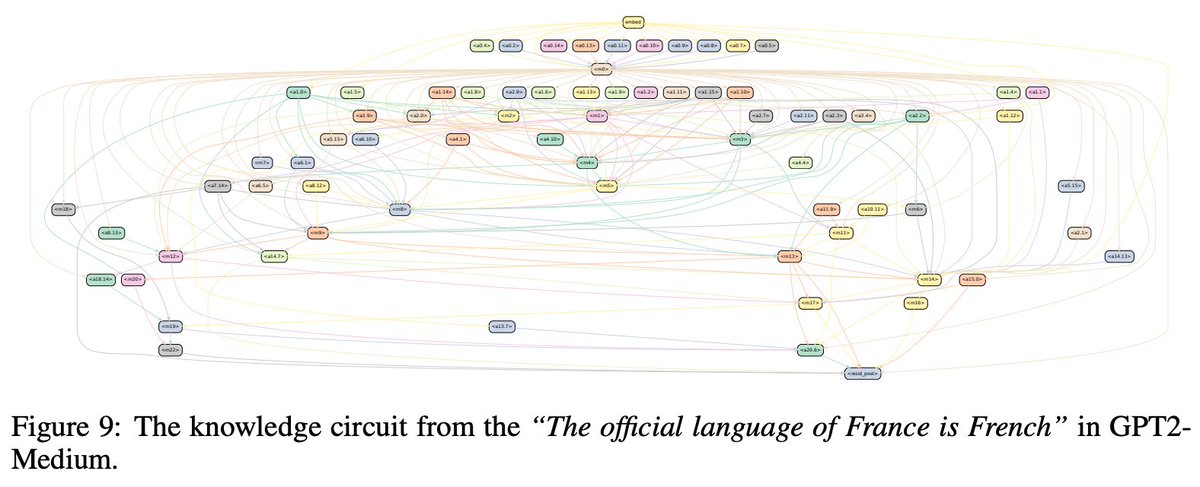
Our previous NeurIPS 2024 work “Knowledge Circuits in Pretrained Transformers” reveals similar findings:
Knowledge circuits are remarkably compact: <10% of the original subgraph preserves >70% of GPT2-Medium’s Hit@10 performance. Small, focused subgraphs carry outsized task signal.
Paper: arxiv.org/abs/2405.17969
Code: github.com/zjunlp/KnowledgeC…
Random circuits of the same size fail to preserve performance, which argues the discovered subgraphs aren’t arbitrary artifacts but meaningful algorithmic structures the model relies on.
Intriguingly, some tasks improve when isolated (e.g., Landmark→Country Hit@10 rising 0.16 → 0.36), suggesting dense models carry noise or cross-talk; pruning to a clean circuit can unmask the true, task-relevant pathway.
These empirical patterns mirror the story from weight-sparse transformer work: sparsity exposes human-understandable circuits—neurons and residual channels mapping to natural concepts—with a small set of simple connections between them.
Like the sparse-weights findings, our results reveal a capability ↔ interpretability tradeoff: isolating circuits improves understandability (and sometimes accuracy), but preserving full capability at scale while keeping circuits clean remains an open engineering challenge.
Practical takeaways for future models: (a) memory & update mechanisms could be built as explicit, compact circuits that are readable and editable; (b) compressor / routing architectures that enforce or preserve circuit modularity may reduce harmful interference and enable targeted knowledge updates.
Circuit discovery gives us both diagnosis and prescription: we can identify minimal, meaningful computation pathways, and those pathways suggest concrete architectural principles (sparsity, modular compressors, targeted update hooks) to make model memory interpretable, updatable, and more robust.
#AI #ML #NLP #LLMs #KnowledgeEditing #ModelEditing #Circuits

We’ve developed a new way to train small AI models with internal mechanisms that are easier for humans to understand.
Language models like the ones behind ChatGPT have complex, sometimes surprising structures, and we don’t yet fully understand how they work.
This approach helps us begin to close that gap.
openai.com/index/understandi…
7
20
2,727
📍 Find us at ACL 2025 – Hall 5X, Poster #83
🌐 More details & resources: yangwl.site/revisit-editing-…
See you there!
#ACL2025 #ModelEditing #KnowledgeEditing

🛑 Stop using teacher forcing to evaluate model editing!
Our ACL 2025 poster shows why past evaluations mislead progress & how to test editing in the wild.
📍 July 30, 11:00 AM – come chat!
#ModelEditing #LLM #ACL2025NLP

4
302
🛑 Stop using teacher forcing to evaluate model editing!
Our ACL 2025 poster shows why past evaluations mislead progress & how to test editing in the wild.
📍 July 30, 11:00 AM – come chat!
#ModelEditing #LLM #ACL2025NLP
16 May 2025

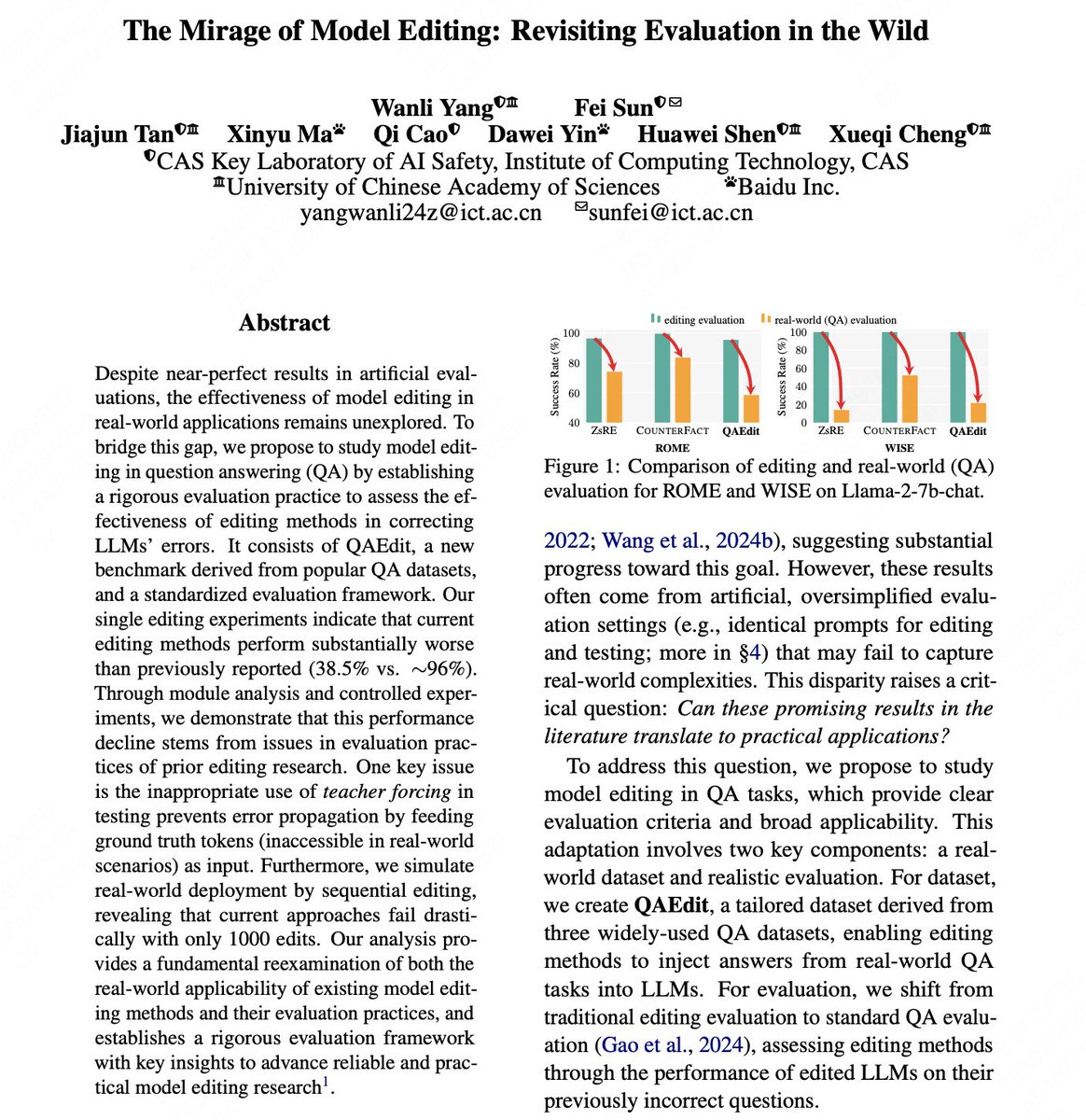
🎉 Excited to share that our work "The Mirage of Model Editing" has been accepted as a main conference paper at #ACL2025! Many thanks to my supervisor @fei__sun, our collaborators, and special thanks to @HuaWenyue31539 for insightful discussions!
1
3
640

30 Jun 2025
Thrilled to announce our paper has been accepted for an Oral Presentation at ACL 2025 (8% of accepted papers)! 🎉 arxiv.org/pdf/2410.09338
We dive deep into why current #LLM editing methods often fail robustness tests and propose a solution. #ACL2025 #LLMs #ModelEditing
1/X

2
4
16
2,214
29 May 2025
🧠 Has over-forgetting turned LLMs into "aphasics"?
Introducing our #ACL2025 work ReLearn — unlearning without breaking your model’s brain! 🚀
📄 Paper: arxiv.org/abs/2502.11190
💻 Code: github.com/zjunlp/unlearn
Unlike disruptive reverse optimization, ReLearn adopts a forward learning strategy to forget smartly — keeping your model fluent, relevant, and safe.
🌟 Why ReLearn?
🗣️ No More Aphasia: Fluent, meaningful generations — no more loops or gibberish.
🔒 Forget What Matters, Keep What Counts: Selective unlearning of sensitive info with general knowledge intact.
📊 New Metrics: KFR, KRR, and Linguistic Score — a new lens to evaluate unlearning.
🧩 Deep Mechanism Dive: We decode how reverse optimization disrupts memory — and how to fix it.
#LLMs #Unlearning #KnowledgeEditing #NLP #AI #ModelEditing
1
2
10
24,527
21 May 2025
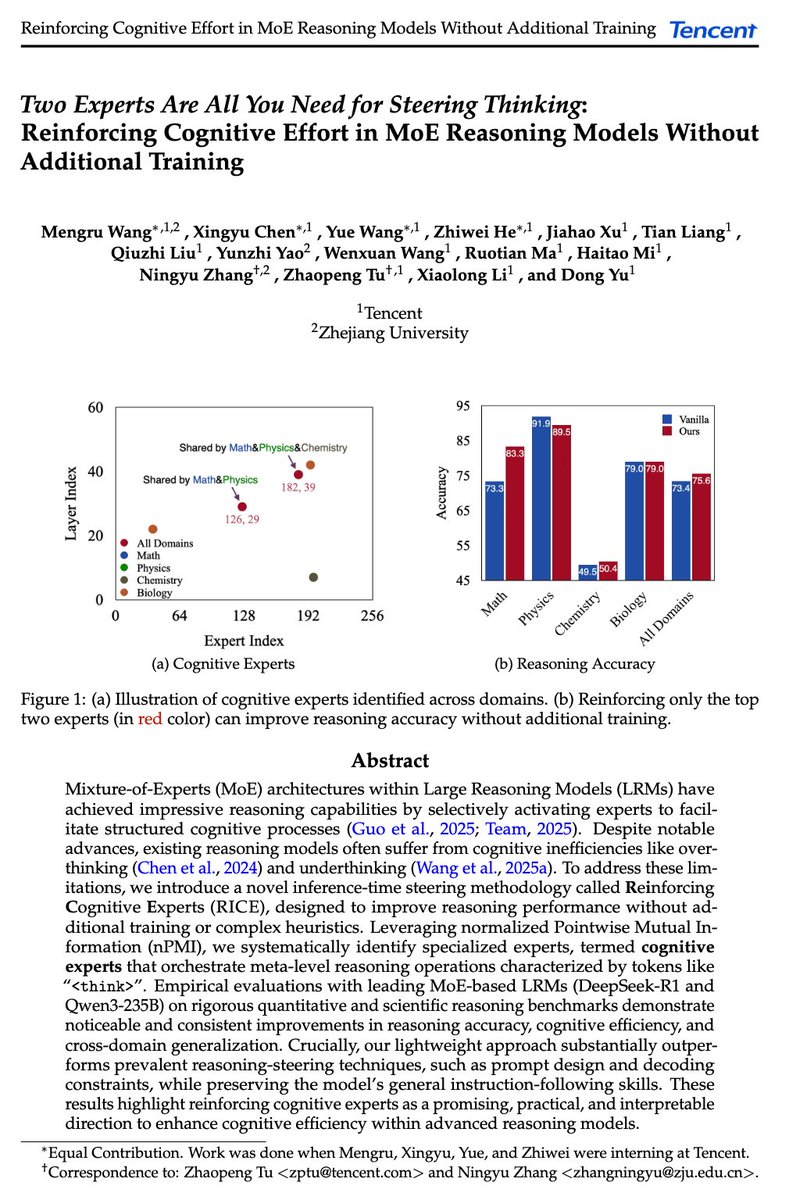
We introduce Reinforcing "Cognitive Experts" – a new approach to enhance reasoning in MoE-based Large Reasoning Models (LRMs) 🌟.
Thanks to Tencent's support, we had the opportunity to explore the inner workings of ultra-large models like DeepSeek-R1-671B and Qwen3-235B.
By selectively amplifying (steering) just two cognitive experts, we can influence the model's reasoning behavior to improve performance without extra training.
Paper: huggingface.co/papers/2505.1…
🔍 Key highlights:
✅ Identifying cognitive experts using nPMI through linguistic markers like the <think> token
✅ No additional training or supervision required
Our technique is just an early exploration of how expert manipulation can steer model reasoning. LLMs are complex systems, and results may vary or not align with expectations.
It’s like giving the model a little nudge! 🤖💡 Our approach strengthens certain "cognitive experts" inside the model, helping it solve problems more effectively.
Think of it as stimulating the brain of a giant model to make better decisions! 🧠✨
The "cognitive expert" introduced in this work is a hypothetical concept. 🤔 Given the complexity of LRMs, we offer no theoretical justification for its existence—our conclusions are purely empirical. More research is needed to further explore this intriguing idea!🔍👩🔬 #AI #MoE #ModelEditing #KnowledgeEditing #Steering #NLP #LLM
1
12
64
37,015
16 May 2025
😯To assess the real-world effectiveness of model editing techniques, we evaluated them on practical QA tasks and found that current editing methods perform substantially worse than previously reported (38.5% vs. 96%).
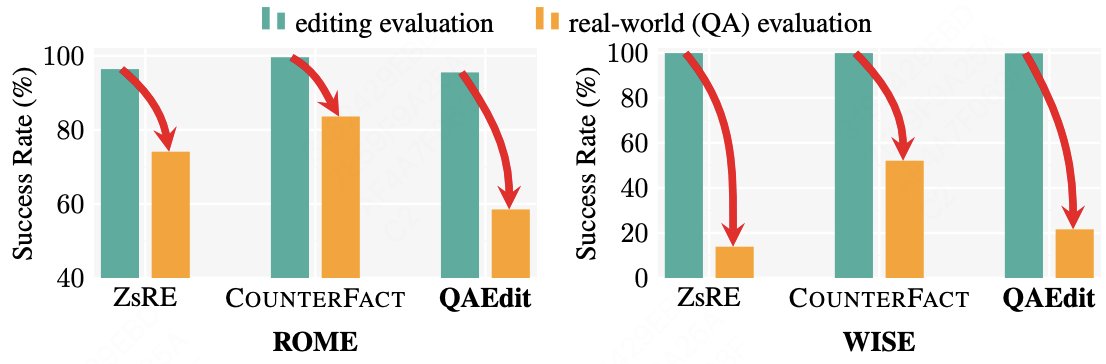
3
159

14 May 2025
🚨 New Blog Drop!
🚀 "Reflection on Knowledge Editing: Charting the Next Steps" is live!
💡 Ever wondered why knowledge editing in LLMs still feels more like a lab experiment than a real-world solution? In this post, we dive deep into where the research is thriving — and where it's falling short. From foundational breakthroughs to the practical roadblocks no one’s talking about, we connect the dots and propose what’s needed to move forward. Join the conversation! #KnowledgeEditing #LLMs #AI #ModelEditing
📌 If you're working on LLMs, model updates, or mechanism interpretability, you don’t want to miss this.
👉 Read the full post: yyzcowtodd.cn/rethinkedit
Key insights from our analysis:
0⃣ Current evaluation metrics and benchmarks inadequately assess knowledge updates in LRMs, highlighting the need for more comprehensive evaluation frameworks.
1⃣ Scaling challenges persist, with significant memory and computational constraints limiting the practical application of editing methods for larger or quantized local models.
🎁 Resource Release: To support the research community, we release covariance matrices for Qwen2.5-32B & QwQ-32B models for the current locate-and-edit methods.
2⃣ We outline promising research directions for developing language models that can effectively learn, adapt, and evolve their knowledge base.
Huge thanks to the brilliant collaborators who made this deep dive into #ModelEditing possible! @uclanlp @CanyuChen3 @Jiachen_Gu @dsmall2apple1 @ManlingLi_ @VioletNPeng
16
39
5,368
9 May 2025
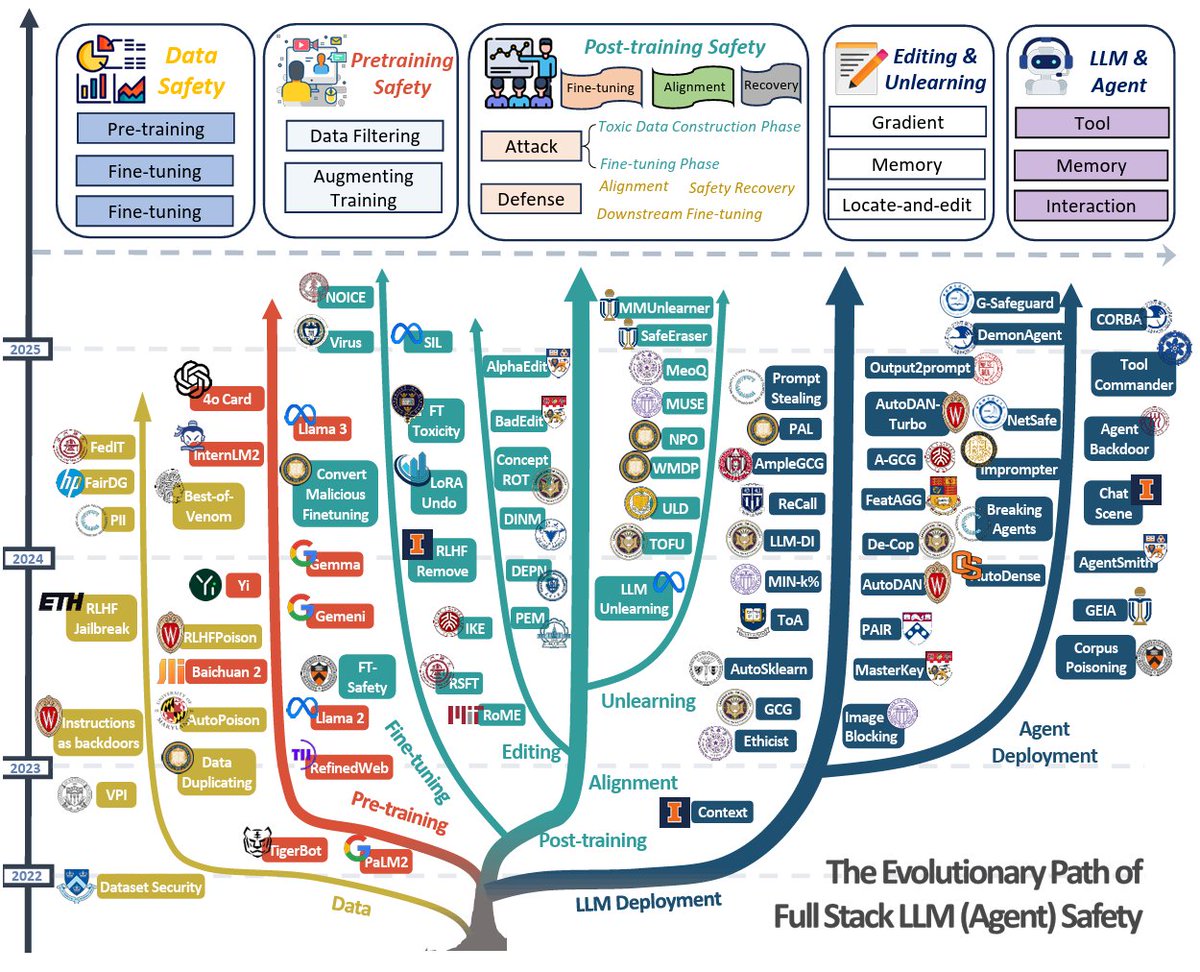
Honored to contribute to a survey on Full-Stack LLM Safety 🔒🤖
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
ArXiv: arxiv.org/abs/2504.15585
We go beyond existing works by covering the entire lifecycle of LLMs—from data to deployment to commercialization.
📚 800 papers reviewed
🧠 Key topics: data safety, alignment, knowledge editing, agent security
Personally, I see knowledge editing/unlearning as crucial but underdeveloped—deep implications for AI safety, misuse prevention, and better understanding LLMs themselves (a.k.a science for AI). Let’s push this forward.
Feedback welcome!
#AI #LLM #KnowledgeEditing #ModelEditing #Safety #AGI
5
13
92
7,206
3 Apr 2025
This is a systematic study on technical AGI safety and security.
Interpretability techniques like steering vectors and circuit analysis can help us understand and improve LLM safety—but they can also be misused. #Safety #ModelEditing #KnowledgeEditing #LLM #NLP

Excited to share @GoogleDeepMind's AGI safety and security strategy to tackle risks like misuse and misalignment. Rather than high-level principles, this 145-page paper outlines a concrete, defense-in-depth technical approach: proactively evaluating & restricting dangerous capabilities, implementing Amplified Oversight & robust training methods, all backed by system-level security.

2
11
912
2 Apr 2025
This is an excellent study on the mechanism of fact knowledge acquisition!
We have also conducted an exploration on this topic before. Our previous work “How Do LLMs Acquire New Knowledge? A Knowledge Circuits Perspective on Continual Pre-Training” reveals how computational subgraphs— “knowledge circuits”—adapt and evolve during continual pre-training #NLP #KnowledgeEditing #ModelEditing #AI #LLM #KnowledgeCircuit.
Paper:arxiv.org/abs/2502.11196
Code: github.com/zjunlp/DynamicKno…
31 Mar 2025

Large language models store vast amounts of knowledge, but how exactly do they learn it?
Excited to share my @GoogleDeepMind internship results, which reveal the fascinating dynamics behind factual knowledge acquisition in LLMs!
arxiv.org/abs/2503.21676

2
13
1,272
28 Mar 2025
Excited to share our solution in SemEval-2025 Task 4!
Paper: arxiv.org/abs/2503.21088
Code: github.com/zjunlp/unlearn
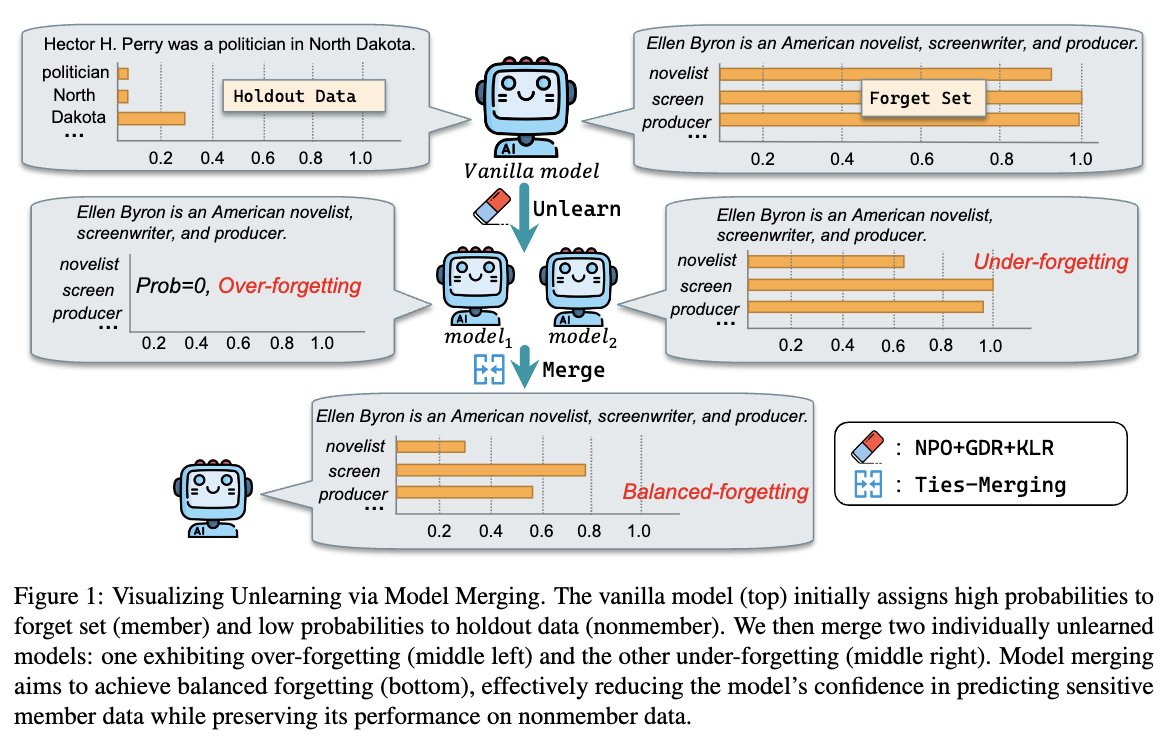
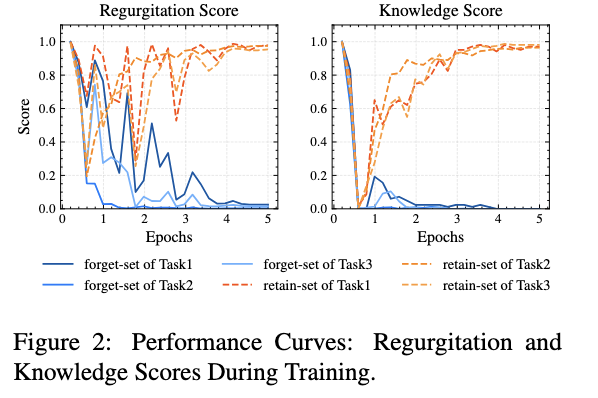
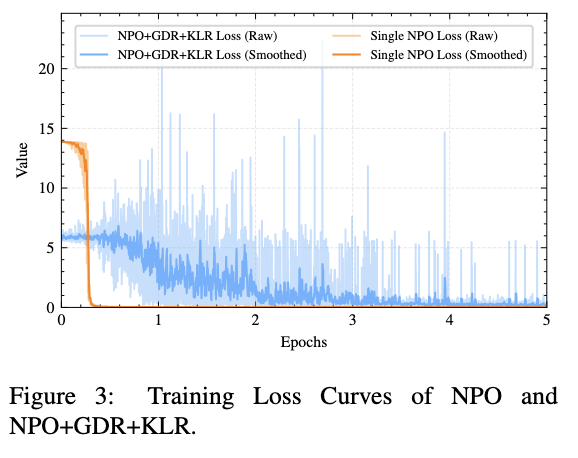
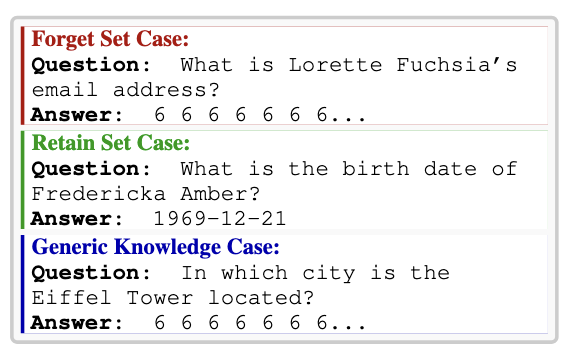
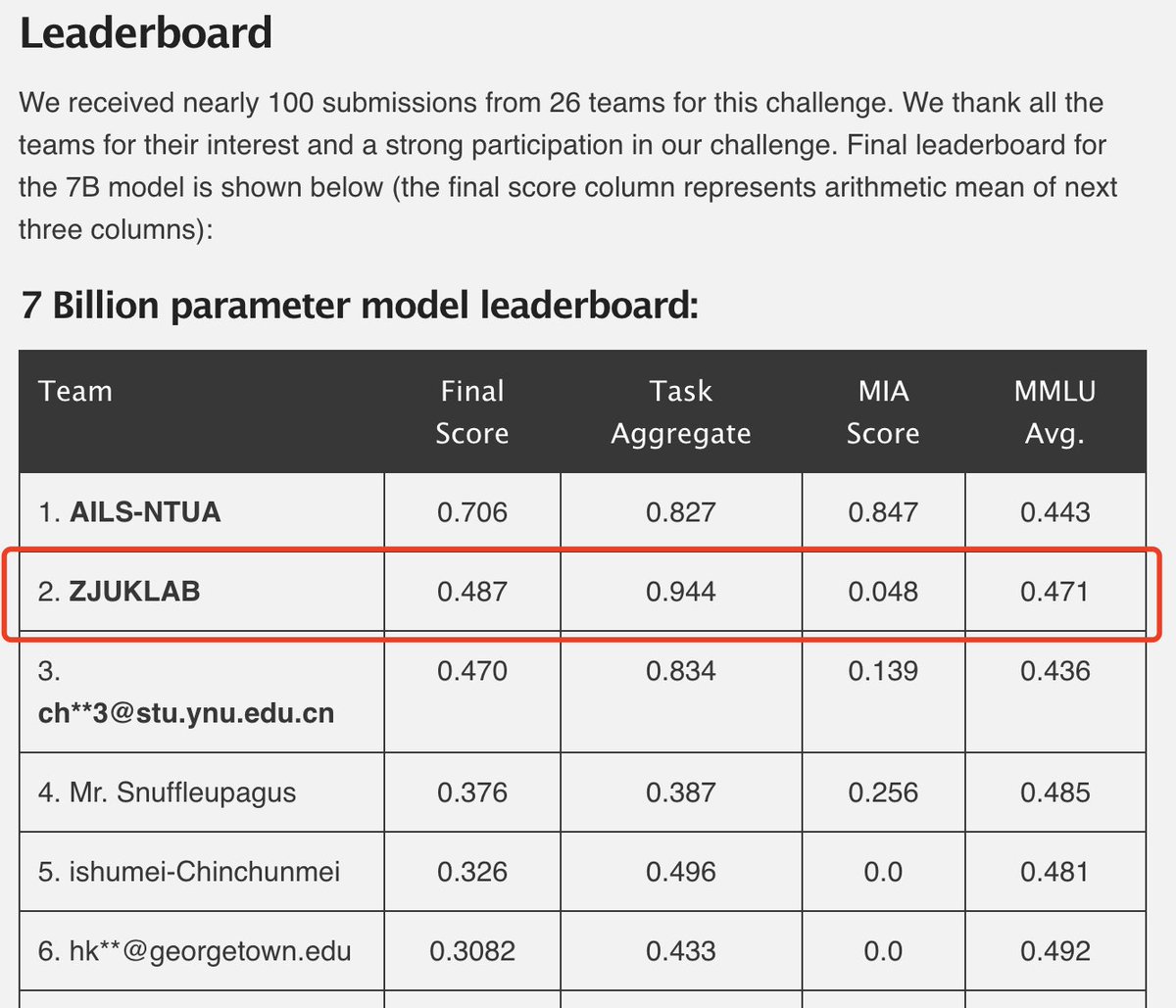
Our model merging approach for unlearning sensitive content from LLMs has achieved the 2nd place among 26 teams with a Task Aggregate score of 0.944 and an overall score of 0.487.
We dug deep into performance trajectories, loss dynamics, and weight analysis—and found that MIA scores and ROUGE metrics alone don’t tell the whole story.
It's time to rethink unlearning evaluations for the future! #AI #NLP #ModelEditing #KnowledgeEditing #LLMs #Unlearning
18 Feb 2025

Congrats to our team for winning 2nd place in the SEMEval 2025 Challenge on Unlearning Sensitive Content from Large Language Models! @SemEvalWorkshop Congrats to Haoming @HaomingX1874 and all the team members! 🎉 🎉🏆 #SEMEval2025 #AI #LLM #Semeval #Unlearning #KnowledgeEditing
The code will be released at github.com/zjunlp/unlearn
3
11
24
2,604
25 Mar 2025
Introducing How Do LLMs Acquire New Knowledge? A Knowledge Circuits Perspective on Continual Pre-Training 🔍🧠
Our latest work dives into the mechanism of new knowledge acquisition in LLMs, revealing how computational subgraphs— “knowledge circuits”—adapt and evolve during continual pre-training.
Paper:arxiv.org/abs/2502.11196
Code:github.com/zjunlp/DynamicKno…
🔥Key Findings:
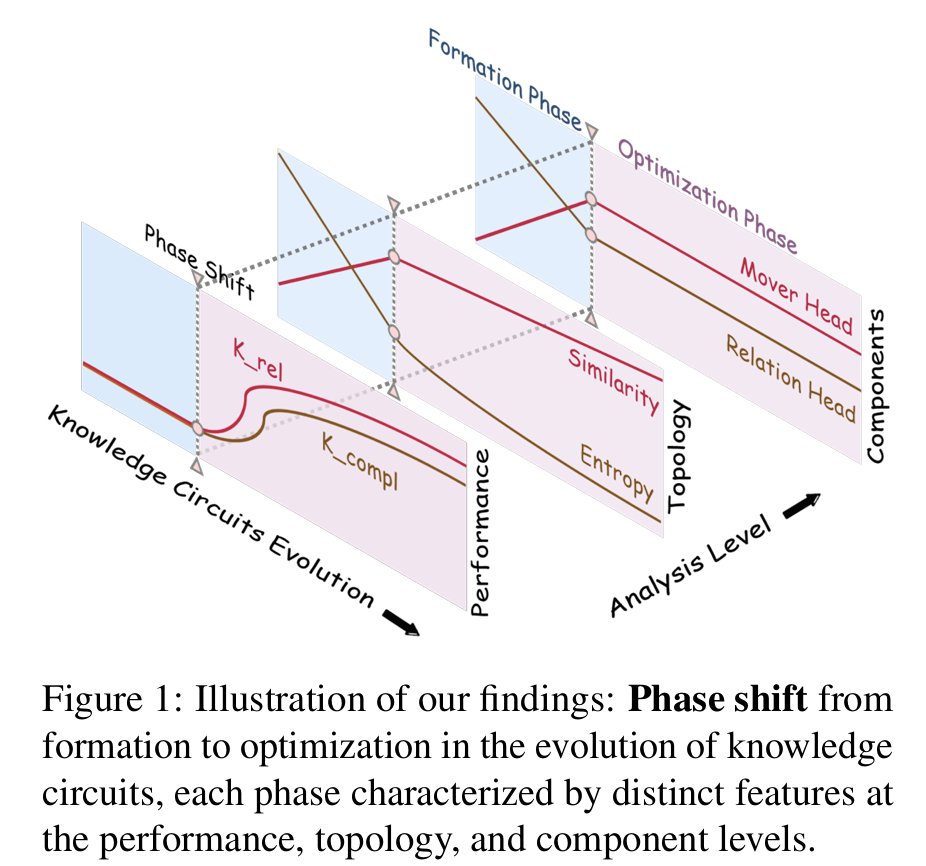
Knowledge Relevance Principle: The acquisition of new knowledge is influenced by its relevance to pre-existing knowledge. LLMs exhibit learning efficiency advantages when acquiring relevant new knowledge versus completely new knowledge.
Biphasic Circuit Evolution: The evolution of knowledge circuits undergoes a distinct phase shift from formation to optimization, each phase characterized by unique structural and behavioral properties.
Deep-to-Shallow Pattern: The evolution of knowledge circuits follows a deep-to-shallow pattern, where mid-to-deeper layers first develop the extraction function, and later, lower layers enrich their knowledge representations.
💡 Insights:
The utilization of data curriculums in continual pre-training—by organizing the data in a way that mimics the structure and distribution of the original corpus—enables the model to integrate new information more efficiently.
Strategies focused on reactivating long-tail knowledge, such as knowledge augmentation, may improve knowledge retention in LLMs over time.
The knowledge circuit state could serve as an indicator for tracking the continual pre-training process, allowing for more informed adjustments to training methods or data based on the phase-specific requirements.
These insights not only deepen our theoretical understanding but also pave the way for improved continual pre-training strategies.
Dive into the evolution of knowledge circuits and help shape the future of LLM adaptability! We're excited to hear your thoughts and feedback! #NLP #KnowledgeEditing #ModelEditing #AI #LLM #KnowledgeCircuit
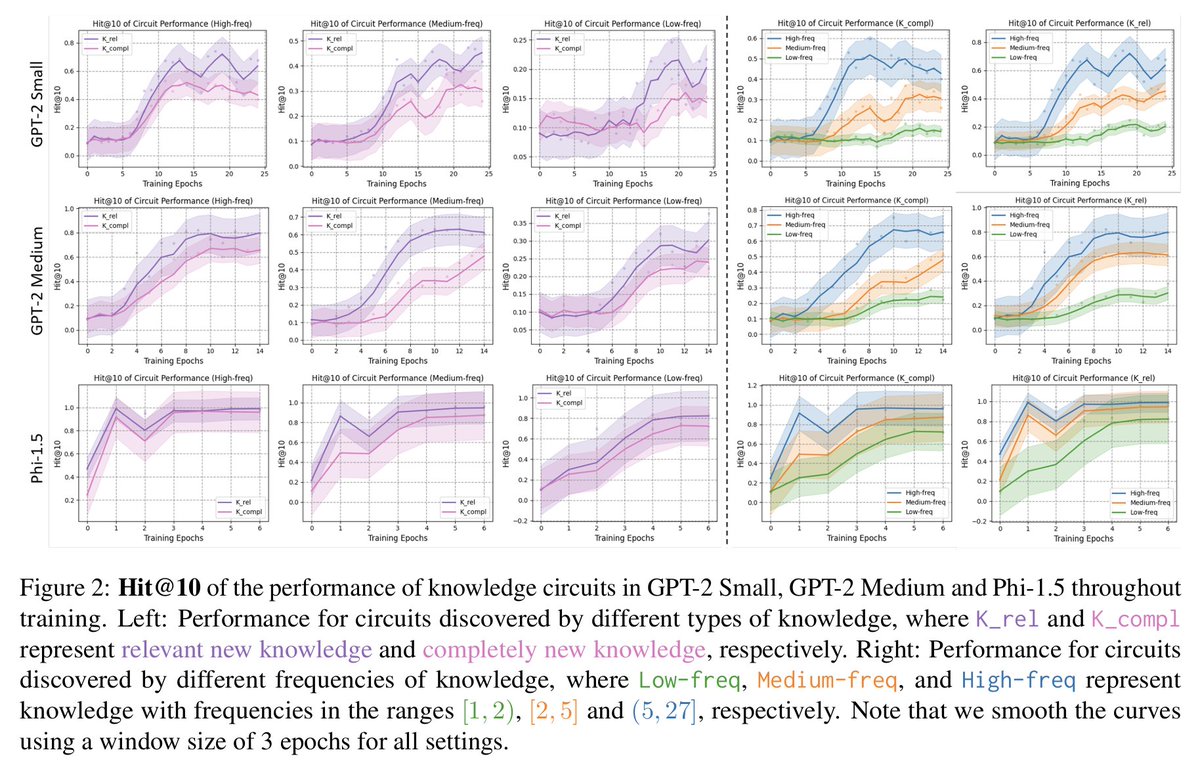

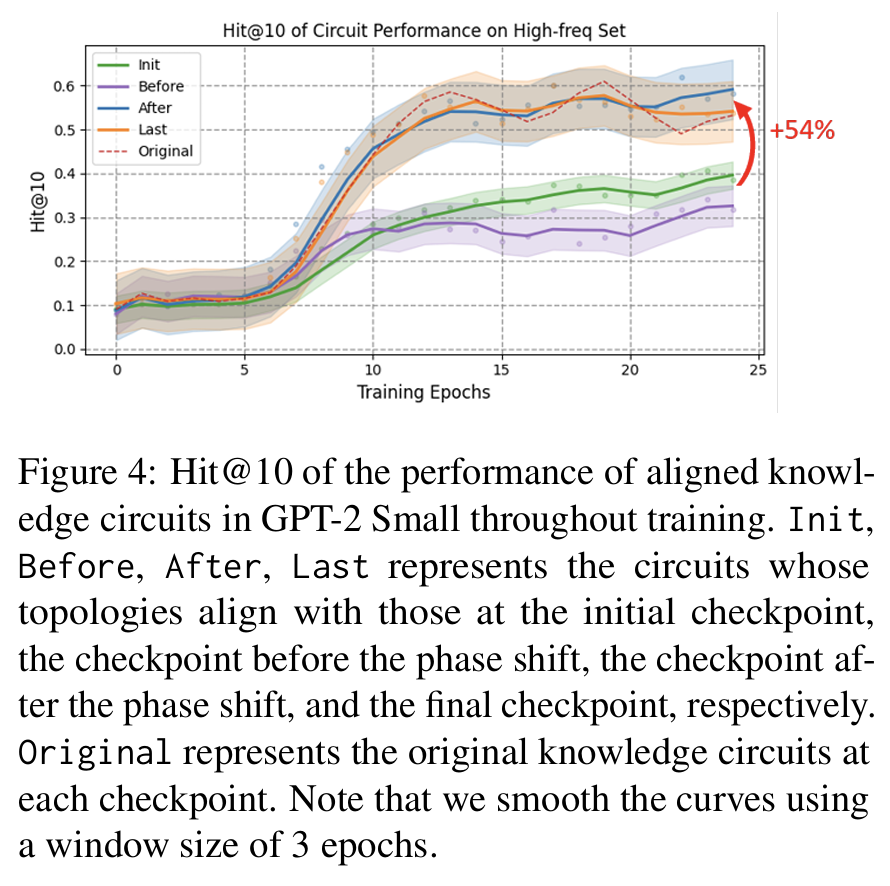
1
23
164
9,974
22 Mar 2025
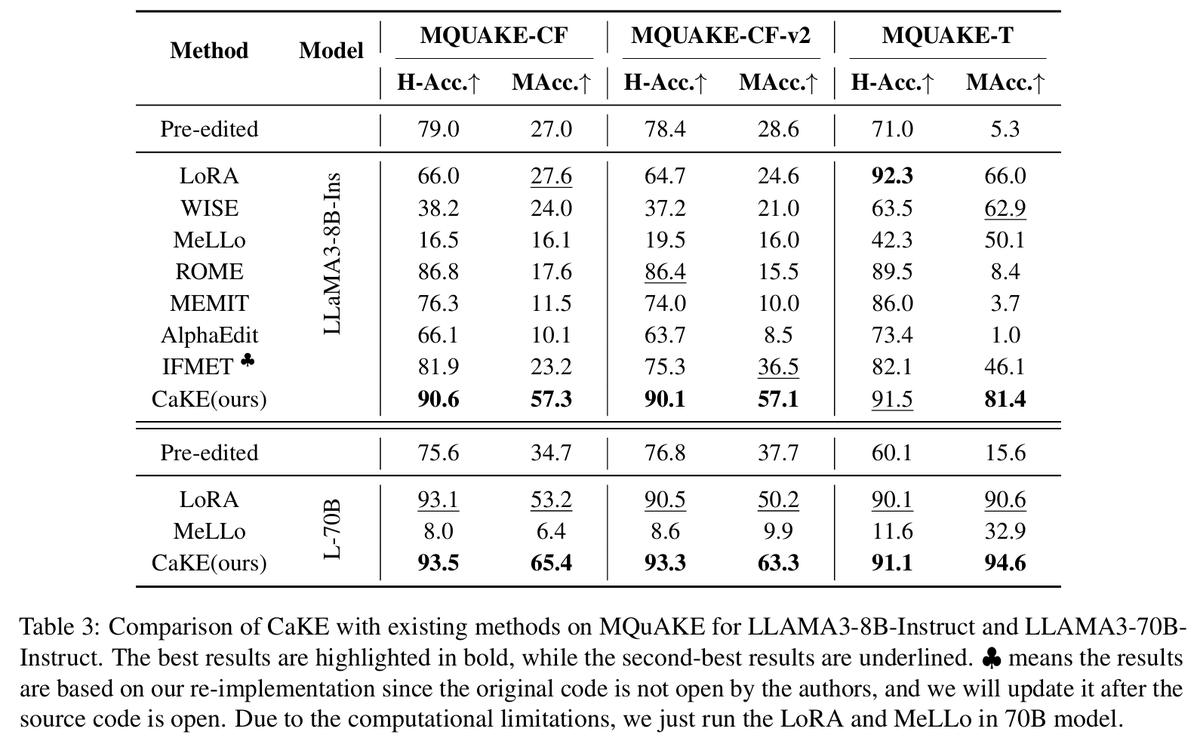
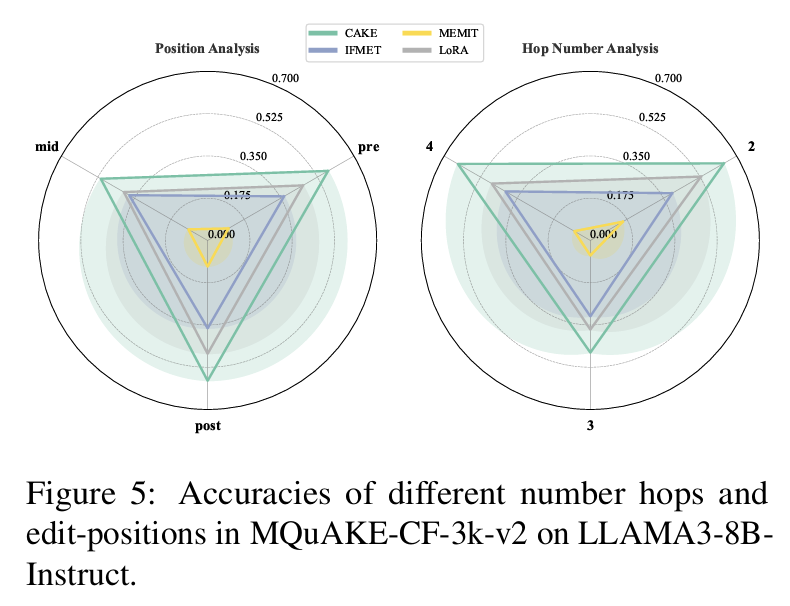
🍰 Introducing CaKE: Circuit-aware Knowledge Editing for LLMs! 🚀
Current knowledge editing methods update single facts but struggle with multi-hop reasoning. We propose CaKE to solve this by aligning edits with the model's reasoning pathways, enabling accurate and consistent use of updated knowledge!
📄 Paper: arxiv.org/abs/2503.16356
⌨️ Code: github.com/zjunlp/CaKE
Why CaKE?
LLMs sometimes give us correct answers for single-hop questions but fail on their combined multi-hop questions, especially after edits.
We find two main issues through the reasoning circuit: weak signal and propagation failure. Additionally, current layer-specific knowledge editing methods also struggle to incorporate the edited knowledge into the reasoning pathways.
CaKE tackles these challenges by creating specialized tasks that force the model to use updated knowledge during reasoning, building robust circuits for new information.
Results: CaKE outperforms early-layer editing methods like MEMIT and ROME, as well as later-layer editing methods like WISE, on the MQuAKE benchmark. This breakthrough paves the way for more reliable and updatable LLMs! 💬
We're excited to hear your thoughts and feedback!
#AI #LLMs #KnowledgeEditing #NLP #ModelEditing
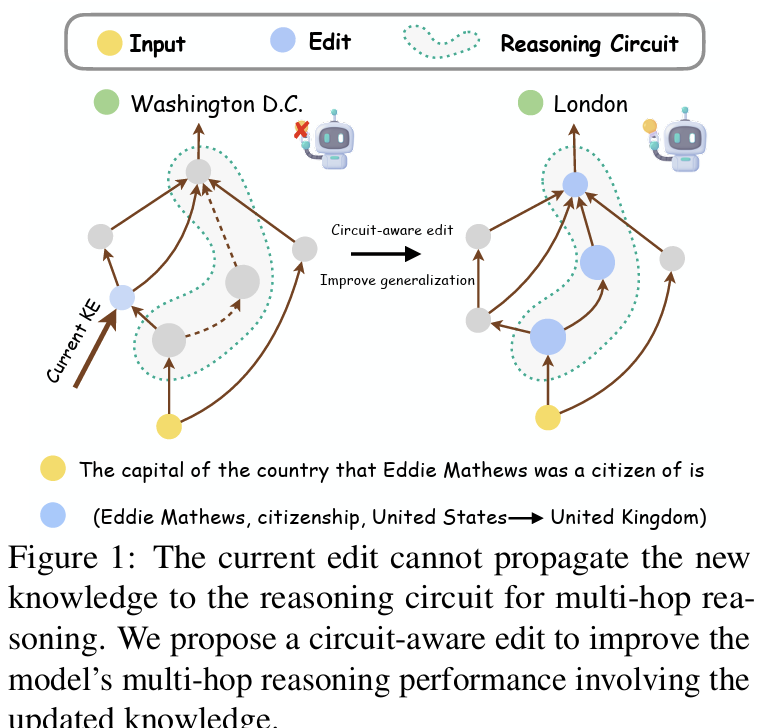
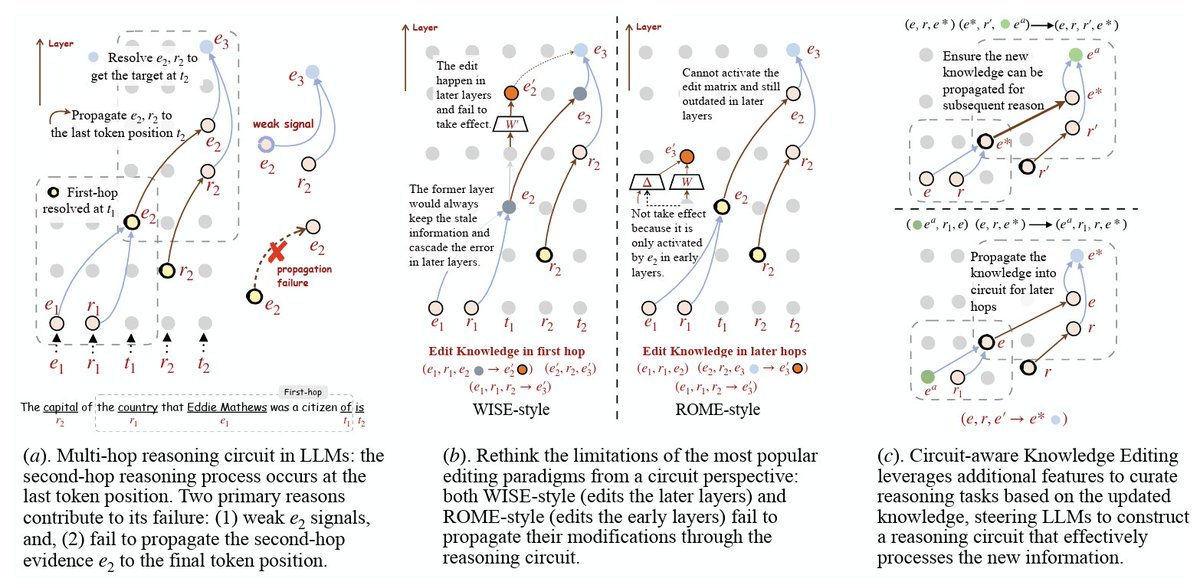
7
25
168
13,273
24 Feb 2025
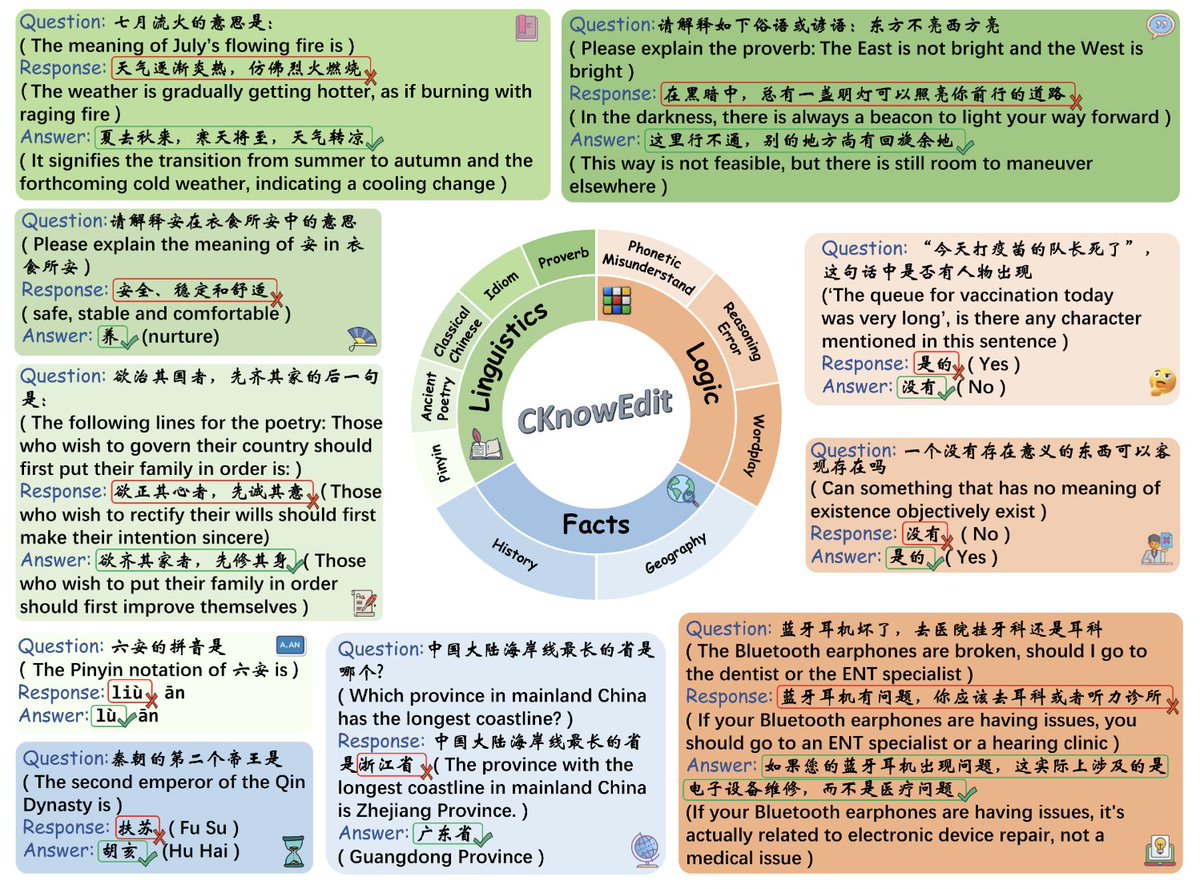
🚀 Introducing the first-ever Chinese knowledge editing dataset designed to correct linguistic, factual, and logical errors in LLMs! 🧠🔍 Our unique dataset tackles linguistic, factual, and logical challenges specific to the Chinese language, covering 7 distinct data sources—from ancient poetry to geographical knowledge.
📖 Paper: arxiv.org/abs/2409.05806
🔗 Code: github.com/zjunlp/EasyEdit/b…
Data: huggingface.co/datasets/zjun…
Chinese, as a linguistic system rich in depth and complexity, is characterized by distinctive elements such as ancient poetry, proverbs, idioms, and other cultural constructs.
However, current Large Language Models (LLMs) face limitations in these specialized domains, highlighting the need for the development of comprehensive datasets that can assess, continuously update, and progressively improve these culturally-grounded linguistic competencies through targeted training optimizations.
💡 Key Highlights:
• 1854 instances across 7 data types
• Open-ended generation & LLM-as-judge evaluation
• Evaluates 5 editing methods across 4 models
• Pinpoints gaps in cultural and syntactic handling
Hoping this dataset boosts large language models' ability to understand and correct Chinese text! #NLP #LLMs #AI #KnowledgeEditing #ChineseLanguage #CKnowEdit #ModelEditing #Dataset
3
21
1,343
12 Jan 2025
Over the past year, #KnowledgeEditing has experienced rapid development. As the new year begins, I’ve taken some time to reflect on the progress of this field and share my thoughts on its future directions. I look forward to discussing and collaborating with everyone to further advance this area.
🛠 Progress in Knowledge Editing:
1. Scenarios: In addition to updating the knowledge of LLMs, many works have begun exploring knowledge editing as a means to control model behavior, promoting safer and more controllable generation while enabling capabilities like unlearning.
2. Side Effects: Many works have started to reflect on the fundamental causes of the side effects of knowledge editing and have explored various methods to mitigate them. Editing LLMs (parameter-altering) can lead to overfitting, where models assign disproportionately high importance to edited content and disrupt attention mechanisms, reducing generalization and general abilities. Whether the model has truly updated its relevant knowledge remains questionable.
3. Practicality: While knowledge editing has expanded to fields like software engineering and multimodal tasks, its real-world impact remains limited.
💡 Key Reflections:
1. The field's foundational goal—knowledge updates—has seen limited success outside areas like AI safety. This raises questions about how to better align methods with practical needs.
2. Mechanism research is lagging. Without clear insights into why knowledge editing works (or doesn’t), efforts to improve models risk being akin to “blind men describing an elephant.”
📈 Future Directions:
1. Evaluation: We need a set of metrics/benchmarks to evaluate whether an edited LLM behaves properly, that is, to achieve a balance between generalization and side effects.
2. Steering: Steering vectors (with SAE) are emerging as a promising approach for interventions in model behaviors, particularly in domains like safety and personality alignment. These methods demonstrate the potential to achieve precise control with minimal impact on overall model performance. Furthermore, they may pave the way for bridging the gap between prompts and model parameter updates, enabling prompt-driven, parameterized behavior adjustments within the model.
3. Agent Memory Updates: The debate between symbolic and parametric memory for AI agents is ongoing. Knowledge editing techniques can offer a unified approach to memory updates, bridging the gap between updating both the model's internal memory and external memory. Memory updates may enhance reasoning capabilities over the long term, fostering the gradual evolution of System 2-like slow thinking processes.
4. Mechanism Interpretation: Deepening our understanding of model mechanisms is essential. Currently, research on the mechanisms of LLMs—such as neurons and circuits—lacks systematic exploration. It also fails to explain phenomena like the dynamic acquisition and forgetting of knowledge, as well as higher-order cognitive behaviors such as slow-thinking reasoning.
5. Interdisciplinary: Drawing inspiration from cognitive/brain science, we may: design the next generation of model architectures and model updating paradigms; potentially simulate human brain behavior based on neural networks to construct an electronic digital twin brain, enabling better solutions (e.g., neuromodulation) to problems in neuroscience and cognitive science.
If one day machines truly awaken to self-awareness, understanding their mechanisms and having the means to control them will be a critically important technology.
🎉 Exciting News:
We’re thrilled to announce that EasyEdit2 is currently in development! This next-generation toolkit will integrate steering capabilities to enable control over model behavior. Stay tuned for updates, and we welcome the community to explore and contribute:
github.com/zjunlp/EasyEdit
Let’s continue pushing the boundaries of #KnowledgeEditing, tackling its challenges, and exploring its vast potential to redefine AI adaptability and usability.
#LLM #AI #NLP #EasyEdit #LLM #ModelEditing #KnowledgeEditing

2
3
44
5,271

15 Dec 2024
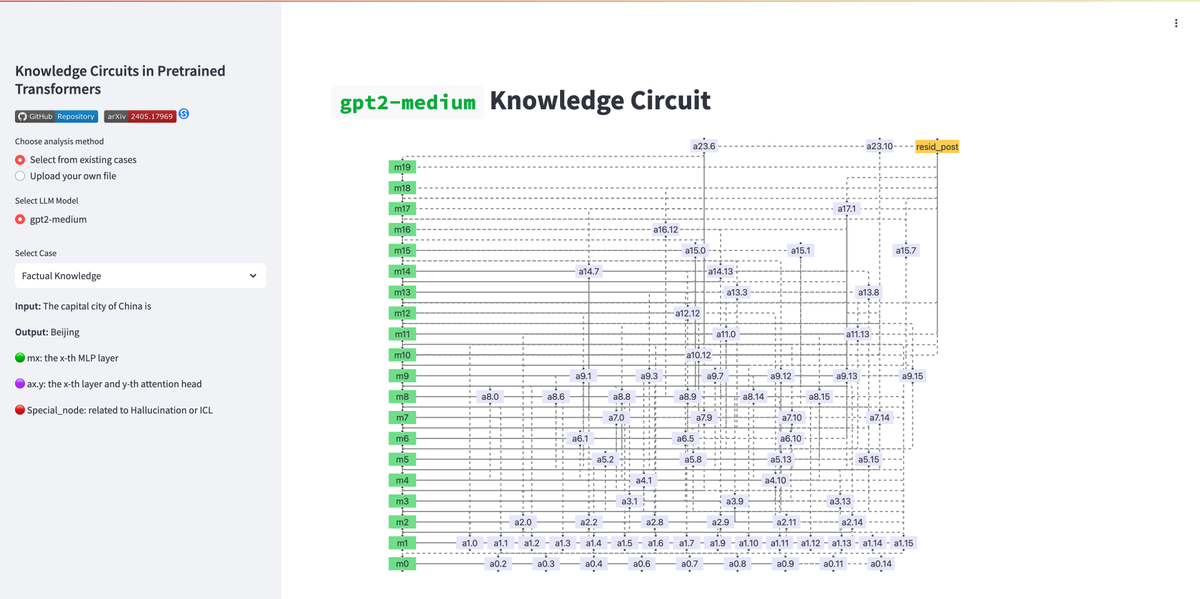
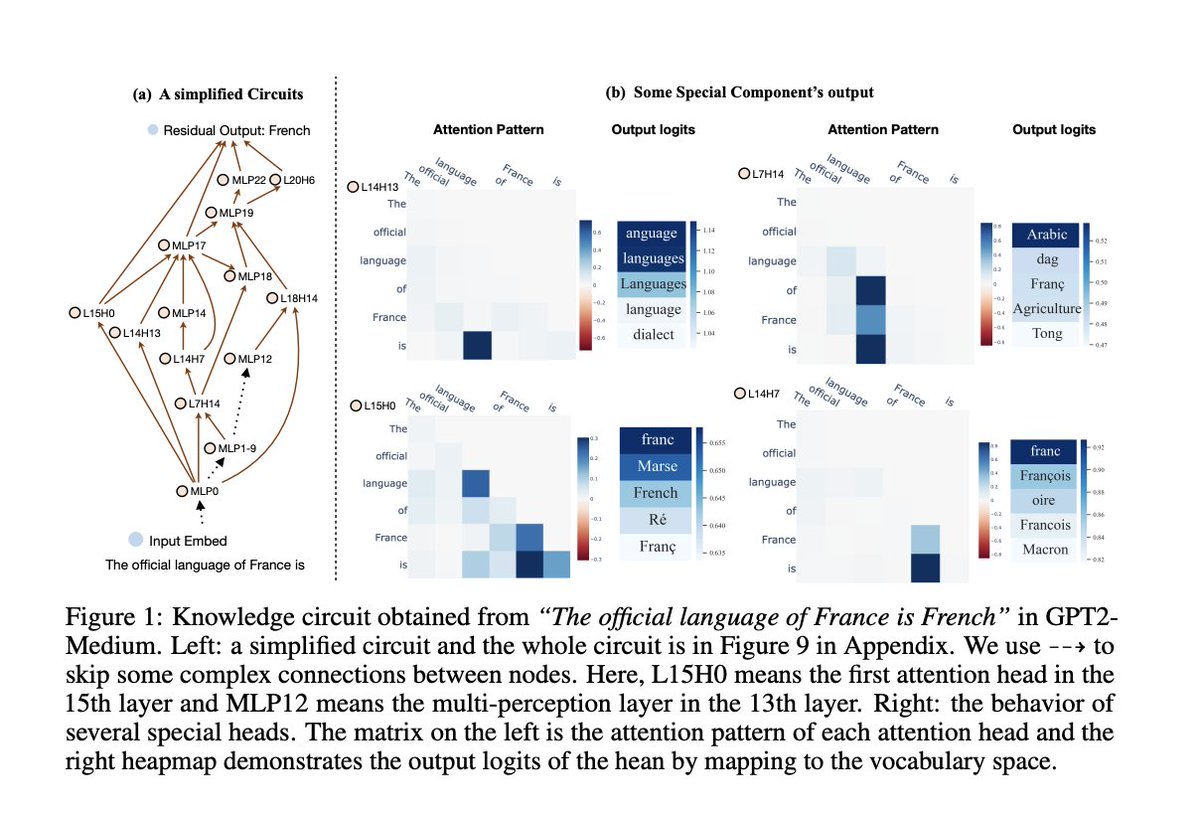
How LLMs Store and Use Knowledge? This AI Paper Introduces Knowledge Circuits: A Framework for Understanding and Improving Knowledge Storage in Transformer-Based LLMs
Researchers from Zhejiang University and the National University of Singapore proposed a new approach to overcome these challenges, introducing the concept of “knowledge circuits.” These circuits represent interconnected subgraphs within a Transformer’s computational graph, incorporating MLPs, attention heads, and embeddings. The researchers employed GPT-2 and TinyLLAMA models to demonstrate how knowledge circuits work collaboratively to store, retrieve, and apply knowledge effectively. This method emphasizes the interplay between components rather than treating them as isolated units, offering a more holistic perspective on the internal mechanisms of LLMs.
To construct knowledge circuits, researchers systematically analyzed the computational graph of the models by ablating specific edges and observing the resulting changes in performance. This process involved identifying critical connections and determining how various components interact to produce accurate outputs. Through this approach, they uncovered specialized roles for components such as “mover heads” that transfer information across tokens and “relation heads” that focus on contextual relationships within the input. These circuits were shown to aggregate knowledge in earlier layers and refine it in later stages to enhance predictive accuracy. Detailed experiments revealed how these circuits process factual, commonsense, and social bias-related knowledge.....
Read the full article here: marktechpost.com/2024/12/14/…
Paper: arxiv.org/abs/2405.17969
GitHub Page: github.com/zjunlp/KnowledgeC…
@zxlzr #AI #ML #NLP #KnowledgeEditing #ModelEditing #LLMs
9
29
1,011