
We are pleased to invite submissions to SIGIR-AP 2026, the 4th ACM SIGIR Conference on Information Retrieval in the Asia Pacific, which will be held in Singapore, 13–15 December 2026. The conference will be organized in a hybrid format, supporting both in-person and remote participation. #SIGIRAP2026 #InformationRetrieval #RecommenderSystems #LLM #GenerativeAI #Search #NLP #MachineLearning

1
28

May 27
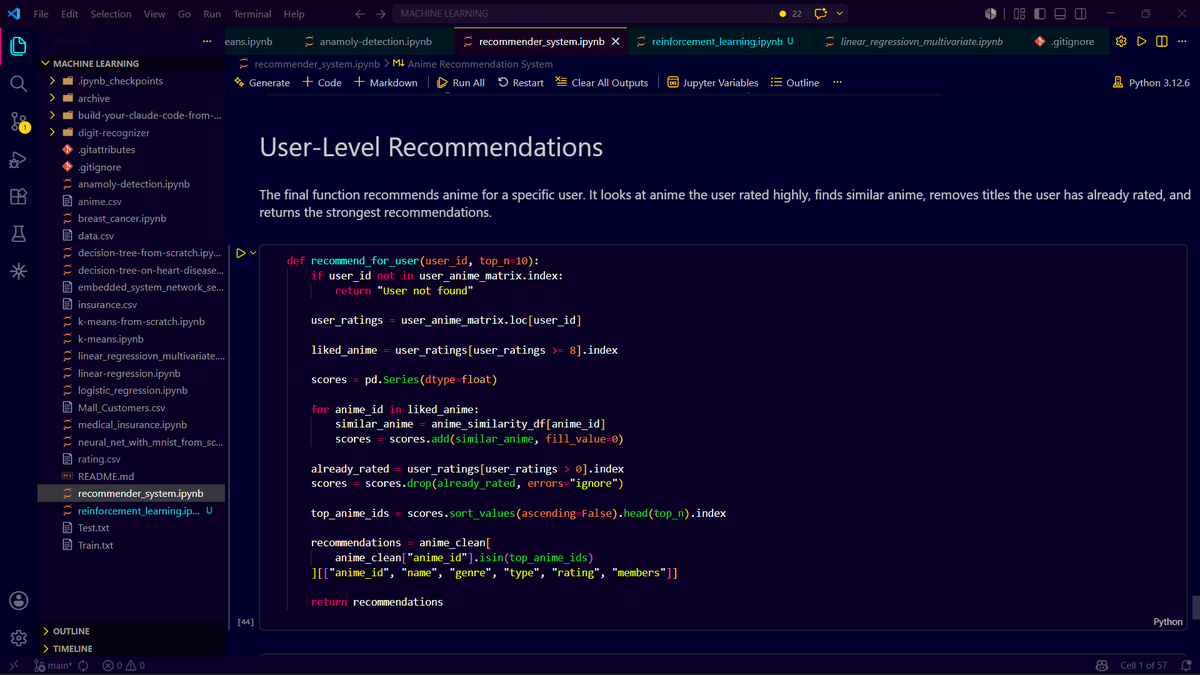
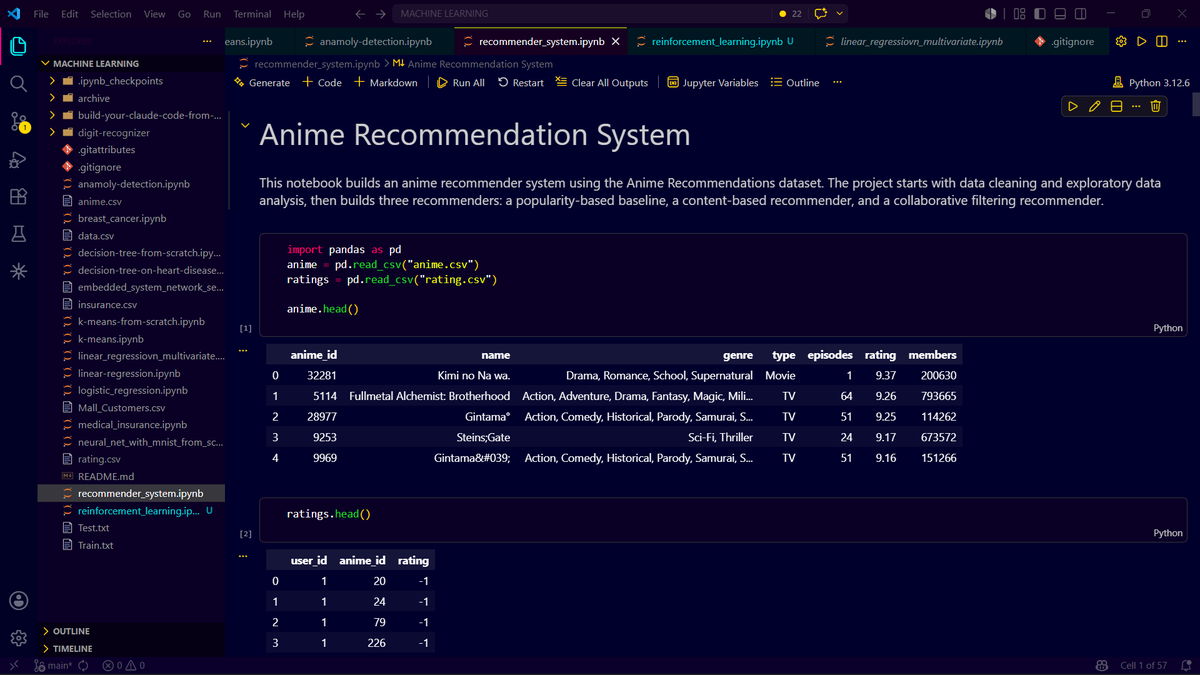
Just finished building a Recommendation System from scratch using an anime dataset, implemented and experimented with:
Popularity-based recommendations
Content-based filtering
Collaborative-filtering.
#machinelearning #python #recommendersystems #datascience #ai #learningbydoing
2
77

🚨 New Publication in AISE
“Online Learning in a Creator Economy”
This work studies how platforms can jointly optimize:
• creator incentives
• recommendation policies
• online learning strategies
📄 doi.org/10.23919/AISE.2026.0…
#AI #OnlineLearning #RecommenderSystems
1
2
33

May 6
TikTok’s algorithm shapes political information for millions of voters — but does it treat political sides equally?
In our new Nature paper, we audited TikTok during the 2024 US presidential election using hundreds of automated accounts.
Across 27 weeks and 280k recommendations, we found a consistent partisan asymmetry:
Republican-aligned accounts received significantly more reinforcing content, while Democrat-aligned accounts were exposed to substantially more opposing content.
Importantly, these differences could not be explained by content popularity alone.
A large-scale audit of one of the world’s most influential recommendation systems.
Paper: nature.com/articles/s41586-0…
@talalrahwan @hazemibr_ @nherohonor @aaronrkaufman @NYUAbuDhabi
#Nature #TikTok #AI #Algorithms #SocialMedia #Elections #Politics #MachineLearning #DigitalDemocracy #RecommenderSystems
2
3
13
2,031

Apr 29
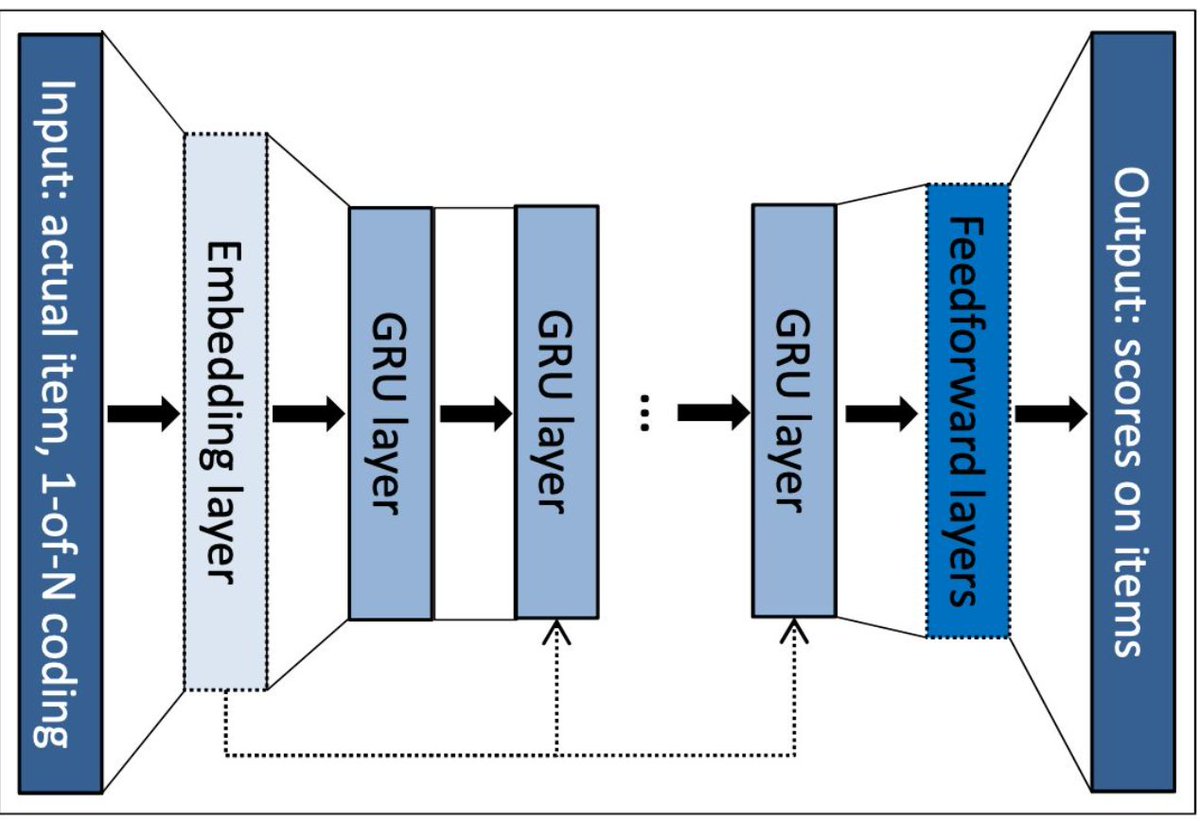
𝗦𝗲𝘀𝘀𝗶𝗼𝗻-𝗕𝗮𝘀𝗲𝗱 𝗥𝗲𝗰𝘀𝘆𝘀 𝘂𝘀𝗶𝗻𝗴 𝗚𝗥𝗨:
As discussed in the previous post, this paper models session-based recommender systems using a GRU.
The workflow is pretty simple:
Suppose we have a user who visits an e-commerce website (without logging in) and clicks:
Earphones → Headphones → JBL Speaker
For each click, the item is encoded as a one-hot vector, which is the input to the GRU at that particular timestep, and the hidden state travels right through.
Then the model outputs an updated hidden state which is a compressed representation of the entire session so far.
This passes through an output MLP layer to produce a score for every item and the item scoring the highest is recommended.
Now the three modifications they had to make to vanilla GRU so that it is feasible to be implemented:
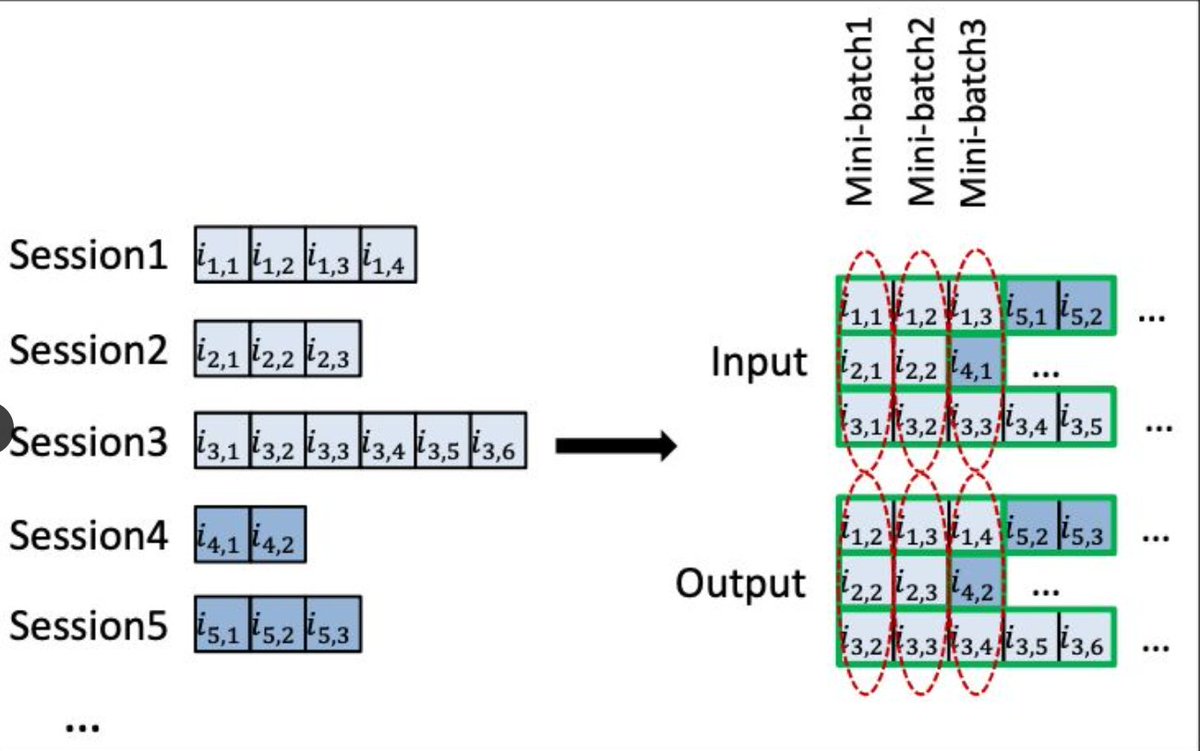
1. 𝗦𝗲𝘀𝘀𝗶𝗼𝗻-𝗽𝗮𝗿𝗮𝗹𝗹𝗲𝗹 𝗺𝗶𝗻𝗶-𝗯𝗮𝘁𝗰𝗵𝗲𝘀
Unlike NLP we can't break these sessions into chunks because the main motive is to capture the temporal relationship and the sessions vary wildly in length (2 to 300 events).
Instead the paper runs multiple sessions in parallel and forms batches based on the positions as shown in the second image.
So Mini-batch 1 = first event of sessions 1, 2, 3. Mini-batch 2 = the second events of those sessions themselves.
If by chance a short session ends then a new session slides into that slot and its hidden state is reset to zero.
Obviously you would not want a laptop shopping context bleeding into a new user shopping for shoes.
2. 𝗢𝘂𝘁𝗽𝘂𝘁 𝘀𝗮𝗺𝗽𝗹𝗶𝗻𝗴 𝘃𝗶𝗮 𝗺𝗶𝗻𝗶-𝗯𝗮𝘁𝗰𝗵 𝗻𝗲𝗴𝗮𝘁𝗶𝘃𝗲𝘀
Computing softmax over 50k items at every training step is infeasible.
The obvious fix which I have been mentioning a lot in my recent posts is negative sampling.
Instead of generating separate negative samples which is computationally expensive, they use the other items in the mini-batch as negatives.
This acts like a popularity-based sampling so if a user has not clicked a popular item it is a strong signal that he dislikes that item rather than labelling an item a negative event even though the user was never aware of it.
3. 𝗥𝗮𝗻𝗸𝗶𝗻𝗴 𝗹𝗼𝘀𝘀 — 𝗕𝗣𝗥 𝗮𝗻𝗱 𝗧𝗢𝗣1
Recsys is a ranking problem, not a classification problem so the loss function coming to mind is BPR (Bayesian Personalised Ranking) which directly optimises the score(positive) > score(negative).
But the issue with it is that it only enforces relative ordering. So the absolute scores are not prioritised and the negative item score just needs to be less than the positive ones.
The paper introduces TOP1: BPR's pairwise term a regularisation term that explicitly anchors negative item scores near zero. More stable and better performing.
#MachineLearning #RecommenderSystems #DeepLearning #RecSys #GRU4Rec
2
45
📣 Deal of the Day 📣 Mar 12
Save 45% TODAY ONLY!
Hidden Influences: How algorithmic recommenders shape our lives & selected titles: hubs.la/Q046xShB0
You don’t choose what you see on the internet. Algorithms choose for you. #recommendersystems #societalimpact #algorithmicamplification #filterbubbles #socialmedia #auditing
If you care about what you read, see and believe - and why - you need to understand recommendation systems.
Dr Luca Belli, co-founder and former research lead for Twitter's Machine Learning Ethics, Transparency and Accountability team, has been on the front lines of how recommender systems work and impact society. In this book, he lays out who uses this powerful technology to shape our world, and exactly how they do it.

1
3
11
560

Mar 3
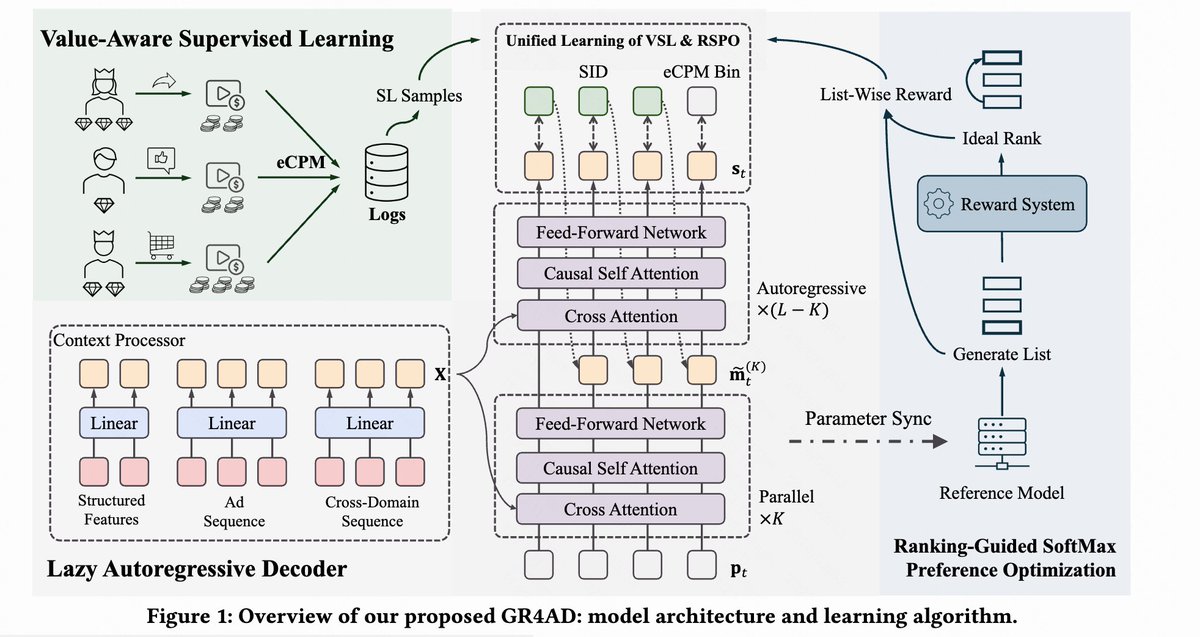
Our latest work on Generative Recommendation now deployed at Kuaishou! 🚀
Real-world deployment shows significant gains in user engagement. 📈
Check out the full paper on alphaXiv: alphaxiv.org/abs/2602.22732
#RecommenderSystems #GenAI #MachineLearning #Kuaishou
2
14
2,619

Feb 28
Post-doctoral Research Fellow Level 2, UCD School of Computer Science
🇮🇪 فرصة ذهبية للباحثين (Post-doc Level 2) في جامعة كوليدج دبلن - أيرلندا
تعلن مدرسة علوم الحاسوب في جامعة UCD العريقة عن توفر وظيفة باحث "ما بعد الدكتوراه - المستوى الثاني" للعمل على مشروع متطور في أنظمة الترشيح (Recommender Systems) والنمذجة السلوكية والأساليب التوليدية.
📍 تفاصيل العرض:
التخصص: Computer Science / Data Analytics.
الراتب: مرتفع جداً يتراوح بين 54,850€ إلى 59,654€ سنوياً.
مدة العقد: وظيفة مؤقتة مستمرة حتى 13 ديسمبر 2027.
الموعد النهائي: 23 مارس 2026 (الساعة 12 ظهراً بتوقيت أيرلندا).
🔍 طبيعة العمل:
ستعمل ضمن "مركز إنسيت لتحليل البيانات" (Insight Centre) وبالتعاون مع شريك صناعي لتطوير أنظمة ترشيح قابلة للتوسع، مع فرصة للنشر في أرقى المجلات العلمية تحت إشراف الدكتور Aonghus Lawlor.
🎓 الشروط الهامة:
مخصص للباحثين الذين أتموا مرحلة (PD1).
خبرة سابقة قوية في علوم الحاسوب وتحليل البيانات.
يجب ألا تتجاوز خبرتك الكلية كباحث ما بعد الدكتوراه 6 سنوات عند نهاية العقد.
🛠️ طريقة التقديم:
التقديم يتم حصراً عبر النظام الإلكتروني لجامعة UCD قبل الموعد النهائي. 🔗 رابط التقديم والمعلومات:
ucd.ie/workatucd/jobs/
#المنح_الدراسية #ذكاء_اصطناعي #علوم_الحاسوب #البحث_العلمي #الدراسات_العليا #دكتوراه #ما_بعد_الدكتوراه #فرص_أكاديمية #أيرلندا #دبلن #الطلبة_العرب #مبتعث #الابتعاث #تحليل_البيانات #وظائف_تقنية #ComputerScience #AI #DataScience #Ireland #UCD #Dublin #Postdoc #PhD #Research #AcademicJobs #MachineLearning #RecommenderSystems #GenerativeAI #Scholarships #STEM #TechJobs #HigherEducation #BigData #InsightCentre #Innovation #ScientificResearch #CareerInTech #EuropeJobs

1
2
214

Excited to share my latest project: A Hybrid Book Recommendation System! 📚✨
Traditional search often misses the mark, so I built a system that combines Collaborative Filtering with the power of LLMs to provide highly relevant, personalised suggestions.
Key Features:
🔍 Query Expansion – Uses Generative AI to better understand user intent.
🤖 Hybrid Engine – Blends SVD-based filtering with LLM-driven content analysis.
📊 Smart Clustering – Groups results using K-Means for better discovery.
🚀 Tech Stack – Python, FastAPI, OpenAI, Scikit-learn, Streamlit, and Docker.
Check out the repo here: github.com/avikumart/Book-re…
#DataScience #MachineLearning #LLM #Python #AI #RecommenderSystems
5
310

Feb 11
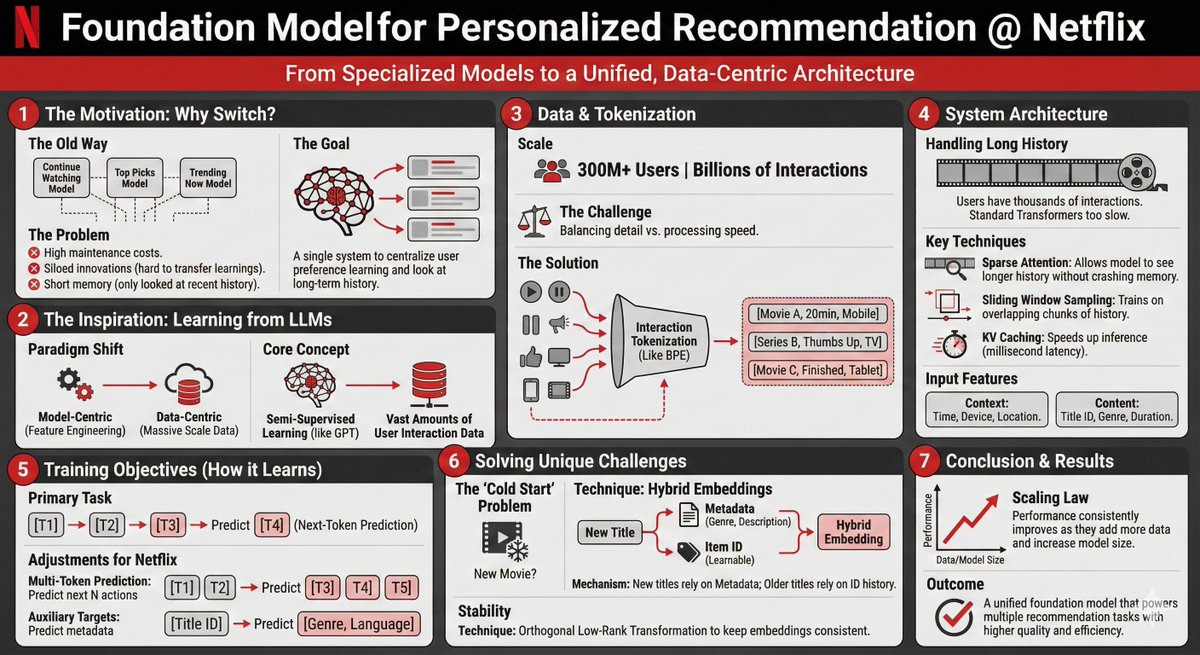
Deja de construir decenas de modelos de recomendación desconectados.
El movimiento de Netflix hacia un Foundation Model para personalización muestra claramente hacia dónde van los sistemas de recomendación a gran escala.
En lugar de mantener modelos separados para “Top Picks”, “Continue Watching”, “Trending”, etc., consolidaron todo en un solo modelo tipo transformer entrenado con secuencias masivas de interacción de usuarios.
¿Por qué importa?
• Un modelo que captura comportamiento de largo plazo
• Embeddings reutilizables en múltiples superficies de personalización
• Menos fragmentación en los pipelines
• Más velocidad para experimentar y desplegar nuevos casos de ranking
Es el playbook de los foundation models aplicado a recomendación: modelado secuencial transferencia de aprendizaje representaciones compartidas a escala.
Si lideras AI, growth o personalización, esto no es solo un cambio técnico — es un cambio arquitectónico.
#IA #MachineLearning #Personalización #RecommenderSystems
9
64
2,269

Jan 26
🎯 Why doesn't your "For You" feed ever run dry?
Behind the scenes, X relies on Recommender System Foundations to navigate massive information overload. It’s the engine that transforms your sparse history of clicks into a personalized landscape, using statistical models to solve the "cold-start" problem so even new users find their niche instantly. These foundations are the indispensable maps that guide us through the vast digital world of X.
🔗 Recommender Systems: bohrium.com/en/sciencepedia/…
#RecommenderSystems #DataScience #XAlgorithm
4
37

Jan 9
🚀 DataRec is now on PyPI!
A Python library for standardized & reproducible dataset management in recommender systems 📊🤖
Built for research and real-world pipelines.
Install it with:
pip install datarec-lib
🔗 pypi.org/project/datarec-lib…
#RecommenderSystems #Python #OpenSource

1
4
212
📣 Deal of the Day 📣 Jan 5
HALF OFF NEW MEAP!
Hidden Influences: How algorithmic recommenders shape our lives & selected titles: hubs.la/Q03Zxrb60
You don't choose what you see on the internet. Algorithms choose for you. This book is written for all audiences. No advanced technical knowledge is required.
Algorithmic #recommendersystems are some of the Internet's most closely guarded secrets. Dr Luca Belli, co-founder and former research lead for Twitter's Machine Learning Ethics, Transparency and Accountability team, pulls back the curtain, showing why they're so seductive and how they influence your beliefs, desires, and behavior. This book tells you how they work and gives you tools to reclaim your agency.
#societalimpact #algorithmicamplification #filterbubbles #socialmedia #auditing

2
2
14
1,036

9 Dec 2025
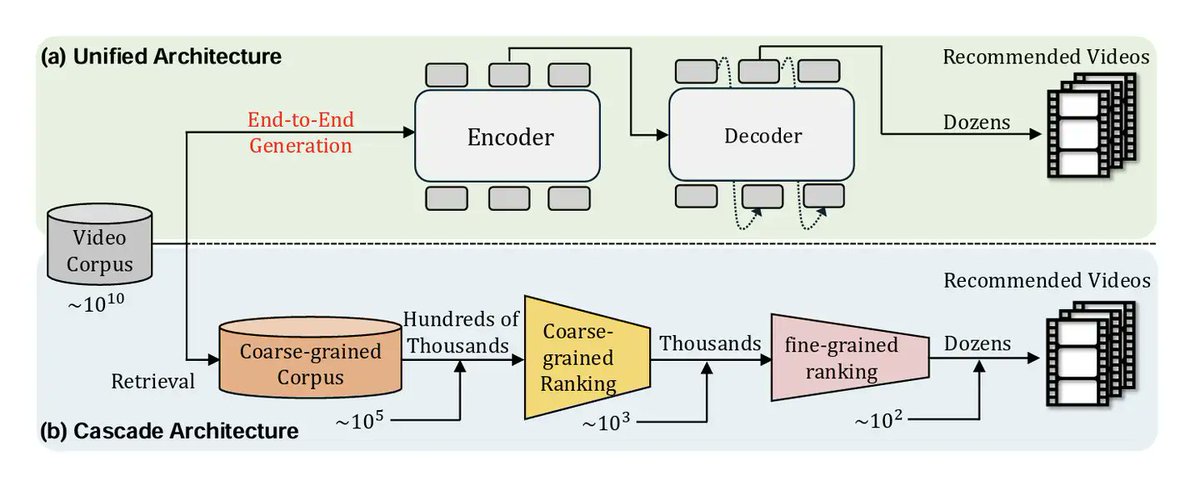
🚀 Will Generative Recommendation Become the Next Paradigm?
A hot debate has been unfolding on Zhihu lately — sparked by an in-depth write-up from engineering director & Zhihu contributor @王喆
Ever since Meta's GR and Kuaishou's OneRec, Generative Recommendation (GR) has become the hottest idea in RecSys—powerful, promising, but also controversial. Here's a distilled look at what's real vs. hype:
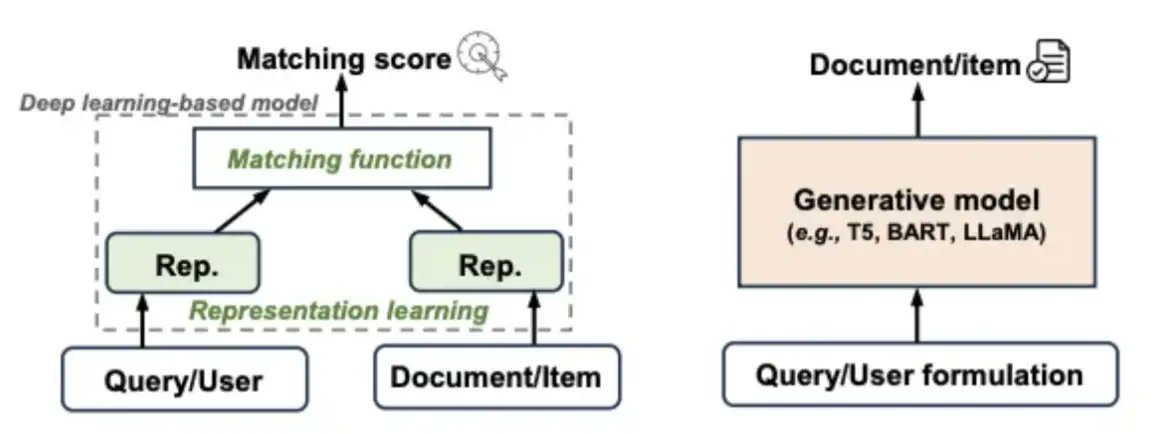
🤖 What exactly is Generative Recommendation?
In short: Use a user's behavioral sequence a generative model to produce the next N items the user is most likely to engage with.
Example:
User history: [A, B, C] → model generates [D, E, F]
Key points:
• Input must be a sequence (each step = a behavioral event)
• Model must be generative, not discriminative
This differs from classic recommender models that predict “Probability(user likes item)” for each user-item pair (Fig 1).
➡️ GR = open-ended generation.
Discriminative models = ranking inside a fixed candidate set.
🔥 Why GR matters
Traditional discriminative RecSys has hit diminishing returns:
• Model complexity grows but gains flatten
• Multi-stage pipelines bring heavy infra inconsistent objectives
GR offers three potential breakthroughs:
1️⃣ Scaling law gains from large sequence models
2️⃣ Long-range user behavior modeling that raises the "effect ceiling"
3️⃣ Architecture unification → simpler system, aligned objectives, lower infra cost
📈 What the evidence says
Meta GR shows solid trends:
• Longer sequences → better performance
• Larger model → clear scaling gains
But the reported 12% CTR lift is still viewed with skepticism; most industry teams only see 1–3% real gains.
Kuaishou OneRec shows something even more interesting (Fig 3):
• 1.68% watch time
• MFU: 11% → 28.8%
• Runtime cost ≈ 10% of multi-stage cascades
A strong sign that the engineering paradigm shift may be more important than the modeling shift.
🧩 When GR works—and when it won't
‼️Suitable for:
• Large companies with dense, high-quality behavior sequences
• Teams already pushing SOTA deep learning rec models
• Scenarios benefiting from pipeline unification
❌Not suitable for:
• Sparse-data teams (If the behavior sequence breaks, GR fails to kick in)
• Ad systems with low sequential coherence
• Teams expecting "overnight 10% lifts"
🧠 The real paradigm shift
GR may not revolutionize metrics overnight—but it can revolutionize system architecture and team structure:
• End-to-end pipelines
• Simplified infra
• Unified optimization
• Fewer silos between recall/rank/rough rank
This architectural reshaping may ultimately be the biggest win.
⚠️ Hype or future?
• Top-tier teams should embrace it — the paradigm is real, results are reproducible, and the structural gains are huge.
• Teams hoping for shortcuts should be cautious — GR can be a "sweet trap" if fundamentals (features, data flow, training pipelines) aren't solid.
GR is not a magic ladder. It's a powerful but demanding paradigm that rewards fundamentals, scale, and engineering excellence.
🔗 Full article on Zhihu:
zhihu.com/question/191620787…
#RecommenderSystems #GenAI #AI #AIInfra #LLM

1
2
10
916

4 Dec 2025
📣 Deal of the Day 📣 Dec 4
HALF OFF NEW MEAP!
Hidden Influences & selected titles: hubs.la/Q03WWxXk0
You don't choose what you see on the internet. Algorithms choose for you. #recommendersystems #societalimpact #algorithmicamplification #filterbubbles #socialmedia #auditing
Dr Luca Belli, co-founder and former research lead for Twitter's Machine Learning Ethics, Transparency and Accountability team, has been on the front lines of how recommender systems work and impact society.
In 'Hidden Influences', he lays out who uses this powerful technology to shape our world; tells you how algorithmic recommender systems work, and gives you tools to reclaim your agency.
Countdown to 2026: hubs.la/Q03WWy3D0

1
1
15
760

2 Dec 2025
Shoutout to Reputeo, @yandex , AI Nation team! Special thanks to @ArhitektaKadic for strategic advice & @njmarko for guidance since uni days at Faculty of Technical Sciences, Novi Sad. Your support rocks! 🙌
Check it out & let's connect on nightlife AI!
#NightTwin #LLM #RecommenderSystems
1
1
3
219

2 Dec 2025
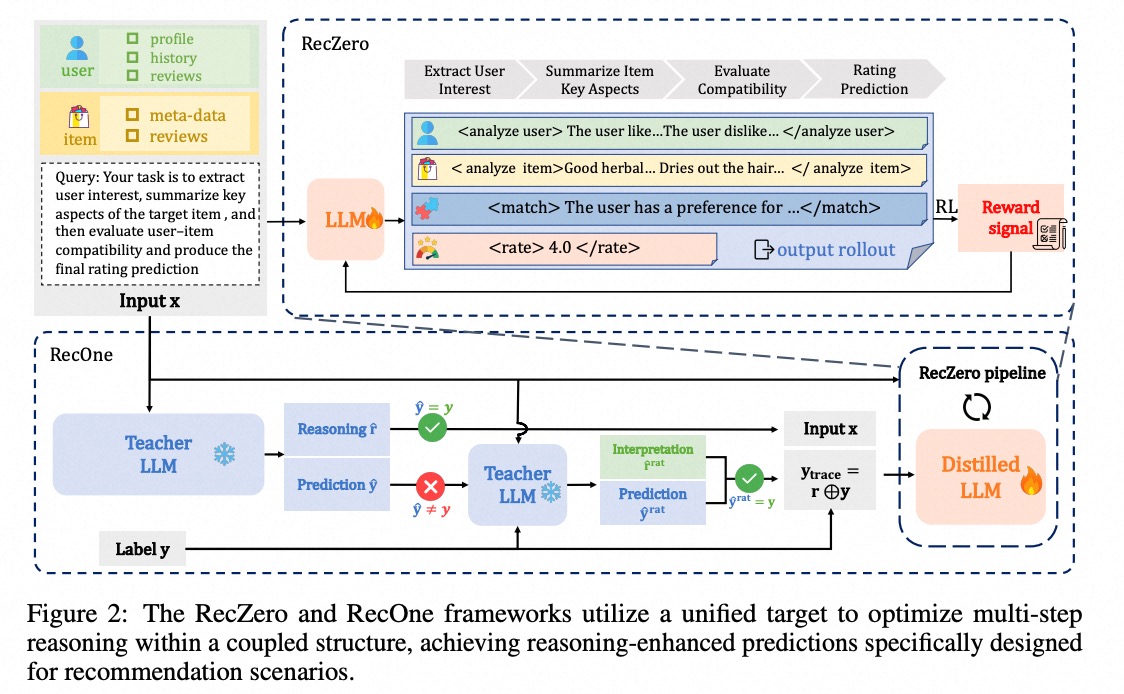
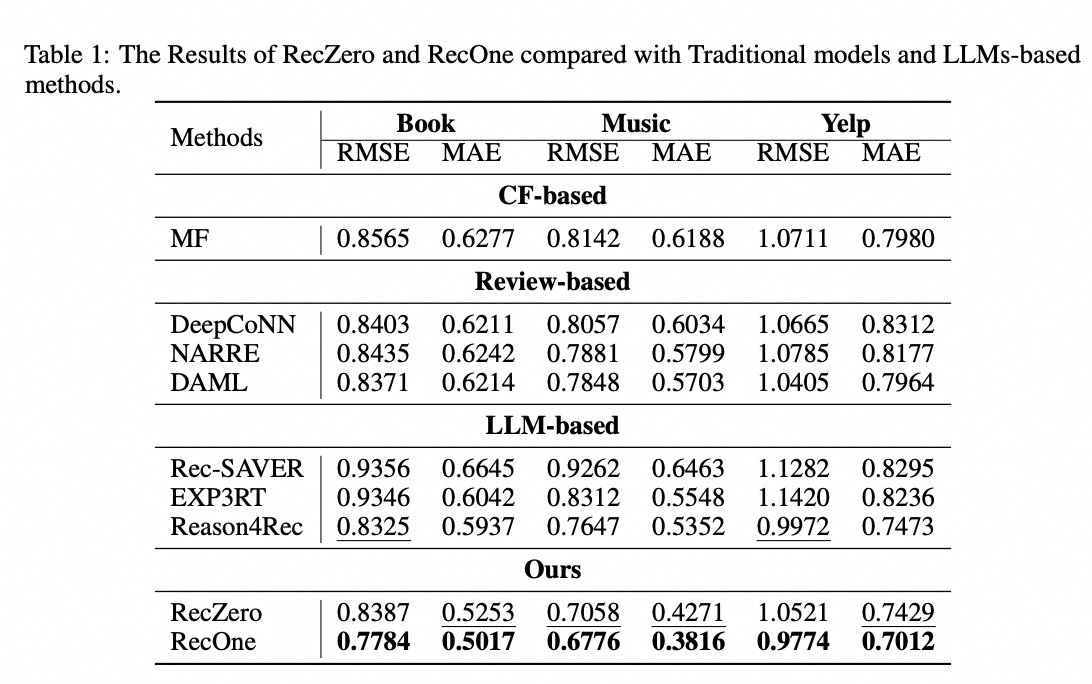
Excited to share our NeurIPS 2025 poster: RecZero — a fresh, RL-powered approach to building recommender systems that reason, not just predict! 🌟
Recommender systems aim to understand user preferences—but how do we get them to reason like humans?
Past attempts used distillation from LLMs, but they’re held back by weak teachers, costly static labels, and shallow reasoning transfer.
We took a different path:
✨ RecZero trains a single LLM from scratch using pure reinforcement learning—no distillation, no multi-stage pipeline. Just autonomous reasoning for rating prediction.
🔑 Two key ideas:
🧠 “Think-before-Recommendation”: Structured prompts guide step-by-step analysis of users, items, and compatibility—like a thoughtful human would.
🎯 Rule-based rewards GRPO: We reward how the model reasons, not just the final score, using group-relative policy optimization.
Plus, we introduce RecOne—a hybrid that warm-starts with supervised reasoning examples and refines with RL (great for cold starts!).
✅ Both methods beat strong baselines across multiple benchmarks—proving RL can help LLMs reason for recommendation.
Come say hi and dive into the details!
📍 Poster #4319, Exhibit Hall C/D/E
📅 Thu, Dec 4 | 11 a.m. – 2 p.m. PST
🌊 See you in sunny San Diego!@NeurIPSConf
🔗:arxiv.org/abs/2510.23077
#NeurIPS2025 #AI #LLM #RecommenderSystems #RL #GRPO

2
473
27 Nov 2025
Now it comes to the second part. Zhihu is pushing multimodal tech deeper into real-world recommender systems — and the numbers look promising. 🚀
🔍 1) High-dimensional multimodal tags
We applied rich, fine-grained tags to cold-start content, boosting new-item exposure & interactions by 3.26%.
The tags also serve as ID-like features for ranking and as side-info for modeling long-tail behaviors — both delivering solid online gains.
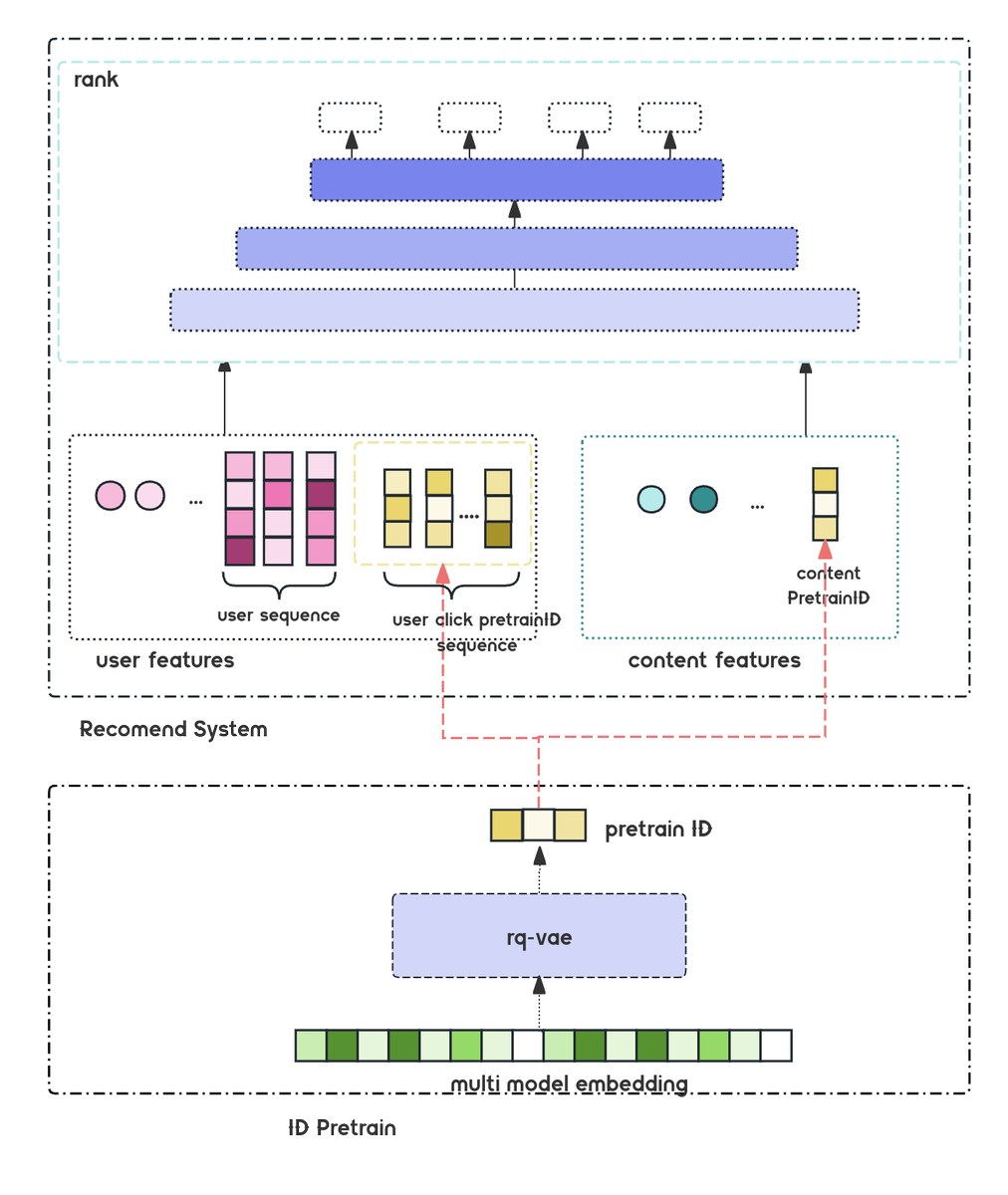
🔗 2) General multimodal embeddings in rec
Raw embeddings are powerful but hard to fuse directly into traditional recsys architectures.
We explored two practical pathways that make multimodal vectors "recsys-ready" (Fig 1):
🧩 (a) Quantizing multimodal embeddings
Using RQ-VAE hierarchical quantization, we map high-dim vectors into structured residual IDs (Fig 2):
• keeps semantic structure
• low-cost to integrate
• easy to update
🔧 Pipeline:
• Initialize N-level codebooks via K-means to avoid collapse
• Encode each item layer-by-layer via nearest-centroid search
• Produce both hierarchical IDs residual vectors
📊 Results:
• Offline: 100% accuracy on fine-grained recall cases & 71% on next-fine-level semantic grouping
• Online: Applied across recall, features, and ranking with consistent improvements (Fig 3).
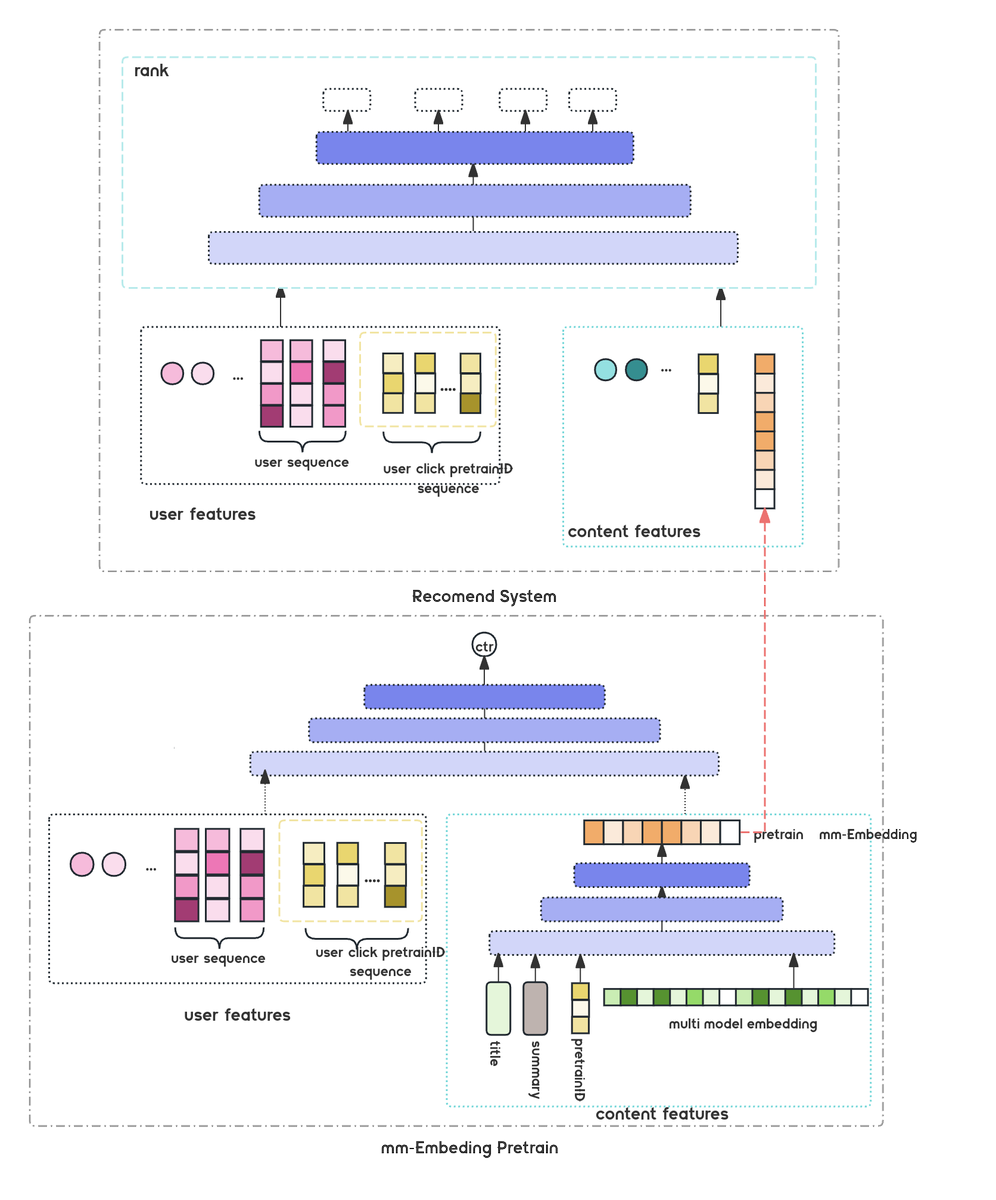
🔧 (b) Recsys-aware embedding finetuning
We inject collaborative signals into multimodal representations through two strategies:
1️⃣ Use multimodal vectors as the sole item feature in a CTR model to distill co-occurrence patterns (Fig 4).
2️⃣ Use itemCF / dual-tower neighbors as positive pairs and randomly sampled negatives from rank 300-1200 to run contrastive finetuning.
📈 Results:
• Maintains ~90% original semantic similarity
• Stronger alignment with collaboration signals
• Online: 2.8% CTR for new items, 9.2% exposure–interaction rate
🔮 Outlook
Multimodal LLMs are reshaping recommendation: better semantics, better generalization and with quantization finetuning — practical engineering pathways that scale.
We're still early, but the direction is clear: richer content understanding → smarter, more adaptive recommender systems.
Full article (CN): zhuanlan.zhihu.com/p/1969072… #AI #RecommenderSystems #LLM #Qwen #Zhihu


26 Nov 2025

How far can multimodal LLMs push real-world recommendations? 🤔
Today we're sharing China knowledge platform Zhihu's latest technical practice: how multimodal LLMs (Qwen2.5-VL) upgrade content understanding and cold-start performance in large-scale recsys.
‼️Modern recsys has moved from rules → CF → deep models → now LLM-augmented pipelines. Multimodal LLMs bring two major capabilities:
1️⃣ Richer representation learning — semantic grounding, visual reasoning, zero-shot generalization, cross-domain transfer.
2️⃣ Generative recommendation — unified interfaces, stronger feature interactions, emerging scaling effects.
For platforms like Zhihu with text, images and videos rapidly growing—traditional text-only features struggle. Two core gaps emerged:
• Under-interpreted content: textual tags alone can't capture visual semantics (e.g., food reviews, travel scenes).
• Cold start: new posts lack user signals, making retrieval unreliable.
To break the modality wall, Zhihu built a full-stack multimodal pipeline with LLMs, focusing on explicit high-dimensional labels implicit multimodal embeddings.
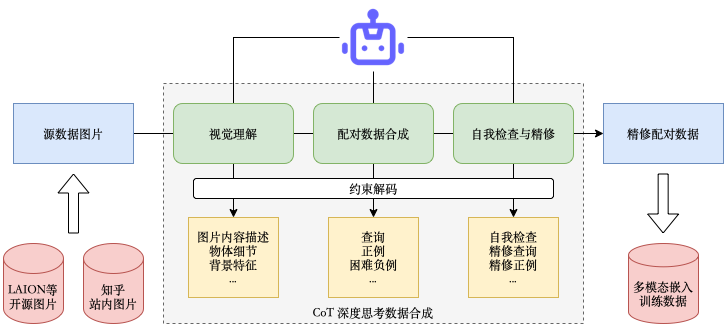
🔍 1. High-dimensional multimodal labels
Using Qwen2.5-VL-72B, Zhihu generates fine-grained tags from text, images, and video frames.
• 20k ideas 6.5k videos were synthetically expanded and human-verified (Fig 1).
• Multiple SFT variants were tested; the Qwen2.5-VL-3B (strong-related fine-tuned) model achieved 80.23% accuracy on image-heavy content and significant gains on OCR-light videos.
• This model serves as the production label generator.
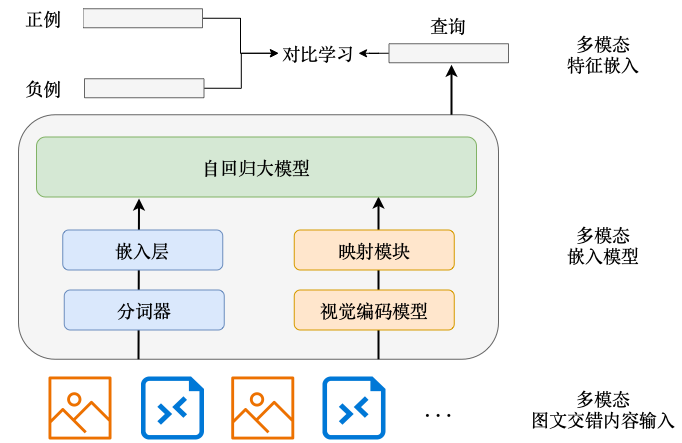
🧩 2. Multimodal implicit embeddings
Zhihu further trains a contrastive embedding model based on Qwen2-VL-7B using LoRA (Fig 2).
• The last-token hidden state becomes the unified embedding.
• Synthetic Chinese multimodal data is generated with Qwen2.5-VL-72B through structured "deep reasoning self-refinement" prompts (Fig 3).
• A second round of synthetic data is built via M1 retrieval 72B ReRank to produce high-quality hard negatives.
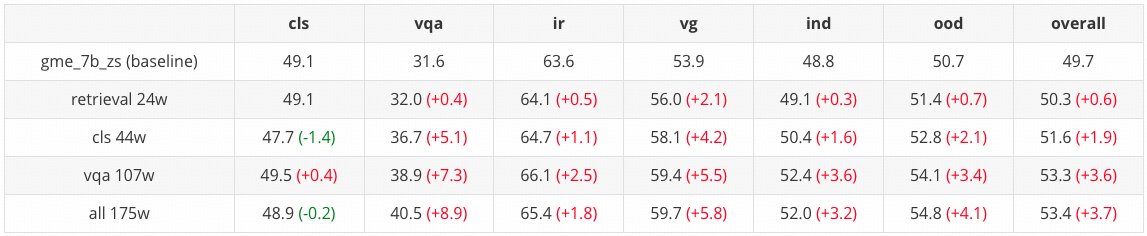
📊 On the MMEB-eval-zh benchmark, this model delivers a 7.4% overall improvement (Fig 4, 49.7 → 53.4) over comparable GME-7B baselines—showing strong gains across classification, retrieval, VQA, and localization.
🚀 Takeaway
Multimodal LLMs are reshaping recommendation: richer semantics, stronger generalization, and data-efficient cold-start handling. Zhihu's exploration shows that high-quality synthetic data tailored multimodal fine-tuning can meaningfully upgrade real-world recsys performance.
🙋 More updates coming soon — stay tuned for Part II. Full article (CN): zhuanlan.zhihu.com/p/1969072…
#AI #RecommendSystems #Multimodal #LLM #Qwen #Zhihu #Tech

13
1,008

24 Nov 2025
Jensen Huang, NVIDIA’s CEO, was asked at the Saudi Investment Forum if AI is a bubble, and his answer resonated and validated exactly why we built #DEEPCEEK Here's why the forces driving AI are permanent foundational shifts not just hype.
#DataProcessing – Every time you use your credit card on Amazon or send a text, that data gets processed, verified, and secured. The world already spends billions a year processing these transactions long before training AI models. CPUs can’t handle it anymore. Accelerated computing, the GPU NVIDIA builds is a needed to do this now.
#RecommenderSystems – The engine of the internet, decide what you see online. Without it, finding anything would be like searching for one grain of sand on a beach. Now Gen AI is replacing them, and runs on GPUs.
#AgenticAI doesn’t just suggest; it acts. And it needs more GPU power. 6 years ago, 90% of supercomputers were CPU-based. Today only 15% are. That’s the world switching to accelerated computing.
For 20 years, Jensen didn’t just preach accelerated computing — he built it. That’s why NVIDIA owns the world now. At CEEK, we’re building the next essential layer: the human one. Because even with infinite information in our pockets, obesity climbs, depression soars, wealth gaps widens. People are starving for access, connection and a lifeline to proven people with real maps and real playbooks who can empower them. If information alone created success, everyone with Google, YouTube, and ChatGPT would already be successful.
That’s the paradox: the more information there is, the harder it becomes to find what matters.
CEEK’s core truth is simple: the world needs skill transfer and access to the right people, pathways, and proof. Knowledge ≠ success. Success = WHO you know and WHO shows you the way. Your network decides your net worth. That World Cup player on CEEK doesn’t share “soccer tips” you can google, he shares which teams to contact and what they look for at tryouts. That information only lives in the irreplaceable experience and expertise of those who have actually done it.
CEEK AI is Human AI integration that brings empathy, lived experience, meaningful connection and trusted guidance. We convert real human experience into hyper-personalized adaptive coaching, AI Digital Twins trained by real humans, trusted recommendations, and immersive learning across mobile, TV, VR, AR, wearables, and whatever comes next. Connecting foundational models and AI applications, enabling everyone, even those with no technical background, to monetize what they know, love, and do with AI.
We engineered CEEK to make the digital world feel human again — useful instead of overwhelming, personal instead of generic. The future belongs to platforms like CEEK that scale and empower people. This is #superintelligence. the next big thing in Ai is #YOU. Somewhere, someone is waiting for the insight only you can give. Empower the next generation of seekers. Join us at ceek.com

1
2
96

Today's recommendation! Check our paper: “Exploring Coresets for Efficient Training and Consistent Evaluation of Recommender Systems”
doi.org/10.1145/3640457.3691…
#RecommenderSystems #Coresets #MLResearch
2
58