
🚀 End of Closed AI
Big Tech locked AI behind walls.
@Gradient_HQ just smashed them.
Open Intelligence Stack Parallax lets you:
→ Train freely
→ Infer fast
→ Fine-tune without permission
Decentralized. Owned. Unstoppable.
The future is open. ⚡
#THINKOPEN
1
1
22
328
🌐 𝐍𝐎 𝐌𝐎𝐑𝐄 𝐋𝐈𝐌𝐈𝐓𝐄𝐃 𝐀𝐈
@Gradient_HQ Open Intelligence Stack gives you the full power
🔹Training
🔹Inference
🔹Fine-tuning
Powered by Parallax your hardware global swarm = real sovereign compute.
🔴Own it all. No renting. No restrictions.
#THINKOPEN🚀
5
18
203
🔴𝗕𝗥𝗘𝗔𝗞𝗜𝗡𝗚 𝗕𝗔𝗥𝗥𝗜𝗘𝗥𝗦 𝗪𝗜𝗧𝗛 𝗢𝗣𝗘𝗡 𝗜𝗡𝗧𝗘𝗟𝗟𝗜𝗚𝗘𝗡𝗖𝗘.
Closed gates smashed.
@Gradient_HQ builds the real swarm: peer-powered, ungated, no rent.
▫️Parallax serves models worldwide
▫️Sovereign intelligence for everyone
Just open power
#THINKOPEN
8
25
285
When closed AI tries to own the future...
A super capyrises. Cape flying. Flag high.
@Gradient_HQ is building the real swarm. No gates. No rent. Just open intelligence.
🔴THINK OPEN forever
#THINKOPEN #GradientNetwork @tryParallax
6
29
1,324

Feb 11
Whether you’re just starting your local AI agent journey or you’re already experienced with AI inference and looking for a more convenient, unified platform to compare and select models, @commonstack_ai has you covered.
With Commonstack, you can route all your calls through a single API, optimize both cost and performance, and seamlessly experiment or prototype across different models, all in one place.
As an AI inference marketplace and unified API layer built from the @Gradient_HQ stables, Commonstack simplifies access to powerful models while giving developers the flexibility they need to build, test, and scale efficiently.
And with its integration with #Clawdbot 🦞, users can extend these capabilities even further, bridging model access with practical agent deployment and execution, making the journey from experimentation to real-world AI workflows smoother than ever.
🌐Check it yourself: commonstack.ai/
#thinkopen

9
3
29
820

GM CT 🙌
Decentralized inference opens up a future where intelligence runs on a global mesh of devices not just a few data centers. But it also raises a fundamental question:
If model execution happens on untrusted hardware, how do we know the answers are correct?
That’s exactly the problem VeriLLM is designed to solve
VeriLLM is a lightweight verification layer for decentralized model serving. When you run inference across a permissionless network of GPUs and devices, you lose the built-in trust assumptions we take for granted in centralized systems. Without verification, providers could:
skip computation,swap in smaller or pruned models,or quietly tweak results to save resources
VeriLLM tackles this with a simple but powerful idea:
instead of blindly trusting any node, it verifies inference correctness with minimal overhead usually around 1% of the original compute cost.
Here’s how it works in simple terms:
Commit → Sample → Verify:
Intermediate states of model execution are committed cryptographically. Then, a small random sample is recomputed and compared against those commitments. If they match, the result is trusted; if not, the system can escalate to stronger checks.
Minimal costs, practical verification:
Most of the inference cost comes from autoregressive decoding. VeriLLM leverages that structure and only recomputes a tiny portion (prefill states) to validate, keeping verification fast and efficient.
Permissionless and auditable:
Anyone can participate in verification. There’s no need for a trusted majority or heavy zero-knowledge proofs that slow everything down. The verification process itself is public and auditable, making outputs trustworthy on a decentralized network
In short, VeriLLM makes sure a decentralized AI network doesn’t trade openness for correctness. It lets you run large models across untrusted hardware with confidence, and that’s a key missing piece for truly sovereign AI infrastructure
When intelligence is hosted by the network not just rented from a centralized provider trust has to be built into the system itself. VeriLLM is exactly that trust layer
./ Think open
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency #echo
30
28
1,424
Feb 2
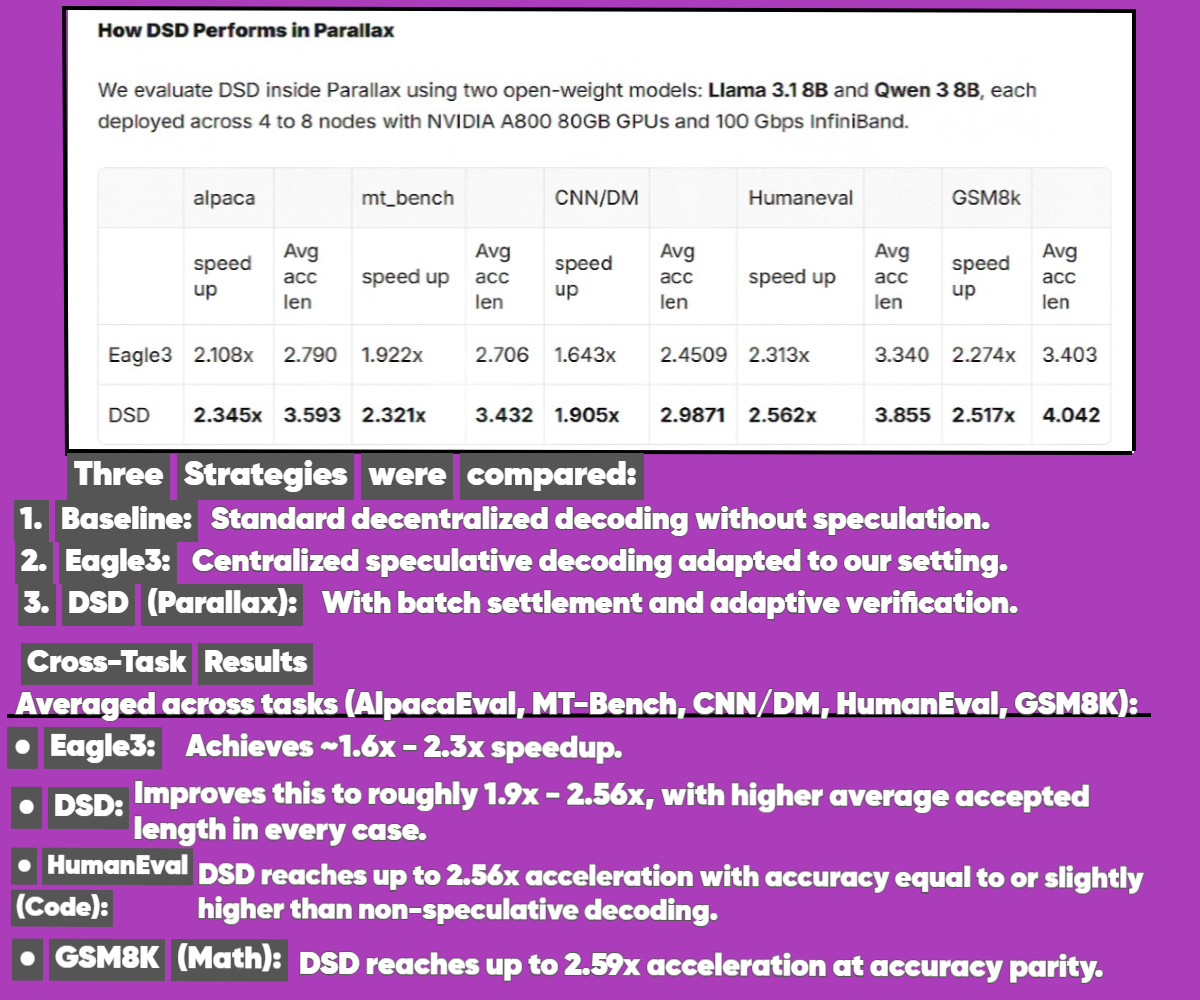
Applied causal inference advances our ability to understand cause-and-effect relationships using machine learning, while . / Gradient's Decentralized Speculative Decoding(DSD) advances how large ML models are actually run in distributed environments.
For anyone focused on scalable, low-latency LLM serving, especially across decentralized or geographically distributed networks, @Gradient_HQ Open Intelligence approach is particularly compelling. It delivers clear, measurable throughput gains, requires no changes to the underlying model, and is explicitly engineered to turn real-world network latency from a bottleneck into an advantage.
🌐Details: gradient.network/research/tu…
#Inference #thinkopen
Jan 3

[Download 496-page PDF eBook]
Applied Causal #Inference — powered by #MachineLearning and #AI: arxiv.org/abs/2403.02467
—————
#ML #DataScience #Algorithms #Statistics #DataScientist #PredictiveAnalytics

13
4
50
974
GM CT 🙌🏻🌤️
One of the quiet assumptions in modern AI training is that hardware will behave nicely. In reality, it doesn’t
GPUs fail. Memory errors happen. Power drops. Networks hiccup. And in large, synchronous RL setups, a single faulty GPU can stall or bring down an entire training fleet. The bigger the cluster, the higher the chance that something goes wrong
This is where Async RL becomes more than an optimization it becomes a design philosophy
With Echo, Gradient deliberately avoids tightly synchronized reinforcement learning loops. Inference and training are decoupled and run asynchronously, which means the system doesn’t require every GPU to be alive, healthy, and perfectly in sync at all times. Rollouts keep flowing, training keeps updating, and learning continues even when individual nodes fail
Instead of treating hardware failure as an edge case, Async RL assumes failure is normal. If one GPU drops out, the rest of the fleet doesn’t wait. There’s no domino effect where one bad component brings everything to a halt. This is the same mindset SREs apply to large-scale production systems: design for partial failure, not perfect conditions
The result is a reinforcement learning system that’s more resilient by construction. Not just cheaper or more open, but fundamentally harder to break. As clusters grow and infrastructure becomes more heterogeneous, this matters more than squeezing out a few extra percentage points of raw efficiency
Async RL isn’t about being faster at all costs. It’s about making sure intelligence keeps improving even when the hardware underneath it doesn’t behave perfectly
And that’s exactly why Echo uses it
./ echo
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency #echo


The Blessed Fraud Recurrence addresses, in long form, questions raised in the original Unicorns & Cockroaches: Blessed Fraud article about AI buildout depreciation schedules and potential earnings overstatement by the hyperscalers. Here, I admit it - AI really is like electrification, #Nvidia GPU failure rates, Power is an inventory problem, and why I short $NVDA.
"Nevertheless, faulty Nvidia GPUs and GPU memory made up almost half the failures. This amounts to about a 9% failure rate if extended over the first year. That does not seem too bad. 1 in 10 chips, not great, but not bad.
Due to the way GPUs are used synchronously during training, one faulty GPU could lay low potentially thousands more GPUs. There are countermeasures that are indeed used, but they all have a cost and involve maintenance, which is not free.
Of course the failure rate will be higher the 2nd year, and higher still the 3rd year, and we do not have that data for the Nvidia chip.
We do have lots of data on semiconductors in general."
michaeljburry.substack.com/p…

40
40
2,371
People often argue about which AI product is better
But that question already assumes the wrong future
The most important technologies don’t stay as products for long. They disappear into the background. Nobody “uses” the internet anymore everything simply runs on it. And AI is clearly moving in the same direction
The problem with treating AI as a product is subtle but dangerous. When intelligence lives behind closed interfaces, you don’t build with it you build around it. You depend on someone else’s servers, someone else’s rules, and someone else’s priorities. The moment those change, your system breaks
Infrastructure flips that relationship. Instead of asking for access, you participate. Instead of renting intelligence, you help run it. Reliability comes from distribution, not permission
That’s the shift Gradient is betting on. Not shipping another AI experience, but laying down the rails for intelligence to exist independently of any single company. A network where intelligence is something devices contribute to, not something users queue up for.
When intelligence becomes infrastructure, the real question stops being “what can this model do?”
It becomes “who gets to own and operate intelligence at scale?”
Gradient’s answer is simple: the network
./ Think open
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency

25
26
222
Whenever people hear “Open Intelligence”, the first reaction is often skepticism. Not because the idea is bad, but because it’s usually confused with older concepts that don’t quite fit anymore
The first misunderstanding is thinking this is just about open-source models. Code is only one piece of the puzzle. What actually matters is who controls execution. If the runtime is centralized, access can still be gated, throttled, or revoked. Gradient focuses on decentralizing execution itself, so intelligence doesn’t depend on a single company’s servers or policies
Another concern is speed. Decentralized systems are often assumed to be slow by default, compared to polished data center setups. But AI doesn’t have to be run like a blockchain. Gradient’s heterogeneous architecture routes workloads to the most suitable hardware in real time, which means you get practical, production-grade performance without being locked into massive centralized infrastructure
Security is usually the last objection. Running on untrusted nodes sounds risky until you realize centralized AI already asks you to trust a corporation blindly. Gradient takes a different approach: instead of trust, it relies on verification. Outputs are checked cryptographically, so correctness doesn’t depend on who runs the node
Put together, Open Intelligence isn’t a weaker or “lite” version of AI. It’s a more resilient model one that’s private by default, harder to censor, and harder to control from the top down. The real shift isn’t technical, it’s philosophical: moving from intelligence you rent, to intelligence you actually own
./ Think open
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #LATENCY


When people talk about distributed reinforcement learning, it’s usually framed as a research problem. But looked at from an SRE or systems engineering perspective, Echo feels much more like an operational framework than a pure ML tool
At its core, Echo decouples inference and training, which is exactly the kind of separation SREs care about. Inference runs in a dedicated swarm powered by Parallax, leveraging thousands of heterogeneous consumer devices RTX GPUs, Apple Silicon, and other edge hardware to generate trajectories and simulations with low latency. Training, on the other hand, stays focused on what it does best: efficient gradient updates on a smaller pool of powerful GPUs like A100s
Because these swarms operate asynchronously, the system doesn’t stall when one side slows down. Agents can keep generating experience while models continue to improve in parallel. There’s no single centralized data center acting as a choke point, and no tight coupling that turns small issues into cascading failures
This opens up some very natural SRE-style applications. Continuous monitoring systems that learn from live signals. Self-regulating services that adapt before thresholds are breached. Incident response agents that refine their behavior over time instead of relying on static rules. Even robotics and autonomous infrastructure, where learning and execution need to happen side by side without blocking each other
What makes this especially interesting is the operational profile. Echo doesn’t depend on hyperscalers to function, and it extracts surprisingly high efficiency from consumer-grade hardware matching or even exceeding traditional setups like VERL or DeepSpeed in benchmark results. For teams thinking about reliability, cost, and control at the same time, that combination is hard to ignore
Echo isn’t just scaling reinforcement learning. It’s quietly turning RL into something that fits the mental model of modern systems engineering
./ echo
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #LATENCY

2
11
155
Jan 27
Gradient’s open infrastructure is a powerful tool in the right hands. Its distributed AI learning systems push technical boundaries while delivering real, tangible value to a broad and diverse community. By turning distributed resources globally into a cohesive intelligence layer, Gradient is not just advancing AI research but decentralizing access to cutting-edge open intelligence and capabilities. ⚡
As the saying goes, “With great power comes great responsibility.” Let’s hope Rick Sanchez and all @Gradient_HQ users, wield this power wisely and responsibly.😅
#thinkopen #DecentralizedAI

22
6
40
1,153
When people talk about distributed reinforcement learning, it’s usually framed as a research problem. But looked at from an SRE or systems engineering perspective, Echo feels much more like an operational framework than a pure ML tool
At its core, Echo decouples inference and training, which is exactly the kind of separation SREs care about. Inference runs in a dedicated swarm powered by Parallax, leveraging thousands of heterogeneous consumer devices RTX GPUs, Apple Silicon, and other edge hardware to generate trajectories and simulations with low latency. Training, on the other hand, stays focused on what it does best: efficient gradient updates on a smaller pool of powerful GPUs like A100s
Because these swarms operate asynchronously, the system doesn’t stall when one side slows down. Agents can keep generating experience while models continue to improve in parallel. There’s no single centralized data center acting as a choke point, and no tight coupling that turns small issues into cascading failures
This opens up some very natural SRE-style applications. Continuous monitoring systems that learn from live signals. Self-regulating services that adapt before thresholds are breached. Incident response agents that refine their behavior over time instead of relying on static rules. Even robotics and autonomous infrastructure, where learning and execution need to happen side by side without blocking each other
What makes this especially interesting is the operational profile. Echo doesn’t depend on hyperscalers to function, and it extracts surprisingly high efficiency from consumer-grade hardware matching or even exceeding traditional setups like VERL or DeepSpeed in benchmark results. For teams thinking about reliability, cost, and control at the same time, that combination is hard to ignore
Echo isn’t just scaling reinforcement learning. It’s quietly turning RL into something that fits the mental model of modern systems engineering
./ echo
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #LATENCY
How Echo scales RL?
What makes Echo interesting is how cleanly it separates concerns
Inference runs on a distributed swarm powered by Parallax, spanning heterogeneous consumer hardware like RTX GPUs and Apple Silicon devices. Training runs on a smaller swarm of datacenter GPUs optimized for gradient updates. Each side scales independently, without compromising the statistical efficiency of standard RL methods
To keep everything stable, Echo uses lightweight synchronization modes. One prioritizes accuracy by ensuring inference always runs on fresh policies. The other prioritizes throughput by allowing asynchronous rollouts with controlled version drift. This makes the system adaptable across different network and hardware conditions
What’s notable is that this decoupled setup doesn’t trade performance for cost. In benchmarks across planning, math reasoning, and logical deduction tasks, Echo matches co-located baselines even while cutting datacenter GPU usage and offloading inference to consumer-grade hardware
The takeaway isn’t just efficiency. It’s that distributed RL can work at scale without being locked into centralized clusters. And that’s a meaningful step toward more open, accessible, and collective intelligence systems
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency

2
10
309
How Echo scales RL?
What makes Echo interesting is how cleanly it separates concerns
Inference runs on a distributed swarm powered by Parallax, spanning heterogeneous consumer hardware like RTX GPUs and Apple Silicon devices. Training runs on a smaller swarm of datacenter GPUs optimized for gradient updates. Each side scales independently, without compromising the statistical efficiency of standard RL methods
To keep everything stable, Echo uses lightweight synchronization modes. One prioritizes accuracy by ensuring inference always runs on fresh policies. The other prioritizes throughput by allowing asynchronous rollouts with controlled version drift. This makes the system adaptable across different network and hardware conditions
What’s notable is that this decoupled setup doesn’t trade performance for cost. In benchmarks across planning, math reasoning, and logical deduction tasks, Echo matches co-located baselines even while cutting datacenter GPU usage and offloading inference to consumer-grade hardware
The takeaway isn’t just efficiency. It’s that distributed RL can work at scale without being locked into centralized clusters. And that’s a meaningful step toward more open, accessible, and collective intelligence systems
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency
Why Echo exists?
Lately I’ve been seeing more discussions around Echo, so I took some time to understand why this direction matters for reinforcement learning
As AI systems scale, RL is becoming the layer that actually turns models into adaptive, aligned intelligence. But most RL frameworks still rely on tightly coupled setups, where inference and training run on the same homogeneous GPU clusters. In practice, this creates constant contention: sampling interrupts training, training blocks inference, and utilization drops as costs go up
Echo breaks away from this pattern by decoupling inference and training entirely. Instead of forcing both phases into one loop, it lets each scale independently on the hardware it’s best suited for. Low-latency rollout generation happens on distributed consumer devices, while policy optimization stays focused on high-throughput datacenter GPUs
At a high level, Echo isn’t changing RL algorithms. It’s changing the infrastructure assumptions behind them and that shift alone removes a major ceiling on scale
More Details: gradient.network/blog/echo-d…
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency

1
10
280
Why Echo exists?
Lately I’ve been seeing more discussions around Echo, so I took some time to understand why this direction matters for reinforcement learning
As AI systems scale, RL is becoming the layer that actually turns models into adaptive, aligned intelligence. But most RL frameworks still rely on tightly coupled setups, where inference and training run on the same homogeneous GPU clusters. In practice, this creates constant contention: sampling interrupts training, training blocks inference, and utilization drops as costs go up
Echo breaks away from this pattern by decoupling inference and training entirely. Instead of forcing both phases into one loop, it lets each scale independently on the hardware it’s best suited for. Low-latency rollout generation happens on distributed consumer devices, while policy optimization stays focused on high-throughput datacenter GPUs
At a high level, Echo isn’t changing RL algorithms. It’s changing the infrastructure assumptions behind them and that shift alone removes a major ceiling on scale
More Details: gradient.network/blog/echo-d…
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency
4
10
220
Jan 21
Gradient . / is showcasing verifiable, decentralized AI infrastructure alongside one of the most creative, authentic, and deeply engaged communities in the space. 😎
The team’s philosophy is clear: do the work first and delay gratification, and that approach is already beginning to pay dividends. The community itself is a living reflection of this mindset. By building open and distributed AI infrastructure through Parallax, Echo, Gradient Cloud, Lattica, and VeriLLM @Gradient_HQ is laying a solid foundation for open intelligence. This is the kind of infrastructure that closed, centralized systems simply cannot replicate.
#thinkopen #DecentralizedAI
14
6
41
925
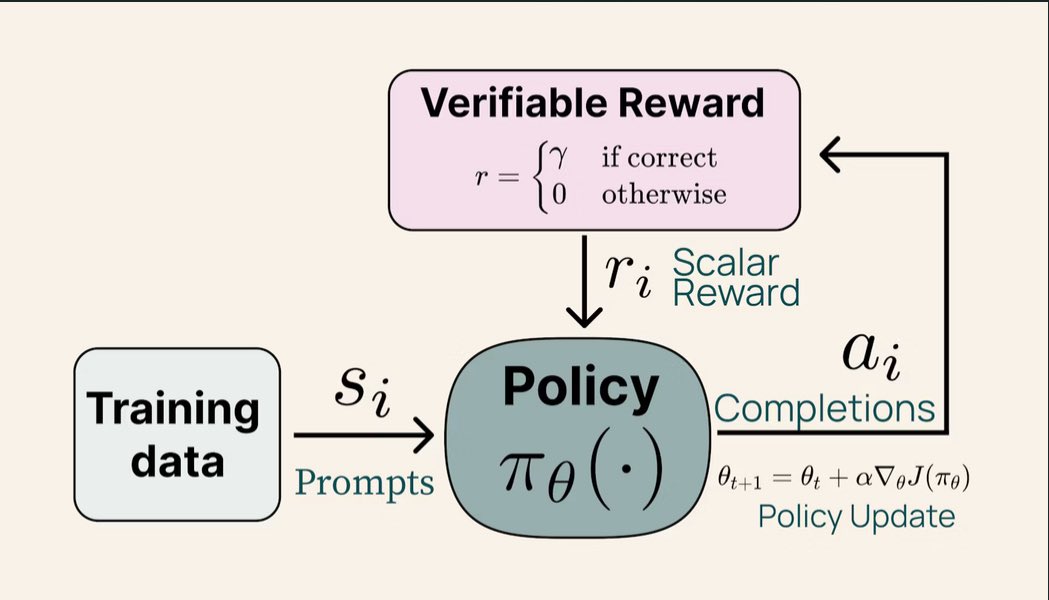
One interesting direction that’s starting to emerge is productivity intelligence, where RLVR (reinforcement learning with verifiable rewards) is beginning to play a central role. As intelligence is embedded more deeply into workflows, what matters is no longer how large the model is, but how reliable it is in execution
RLVR addresses exactly this point. Instead of optimizing based on intuition or vague preferences, rewards are tied to criteria that can be verified. This makes smaller, task-specific models extremely effective: easier to train, easier to control, and in many cases able to significantly outperform larger models when applied to the right problem
What’s compelling is that these models can run locally, keeping automation and data fully private, while still achieving high accuracy because the task itself has a clear verification mechanism. For real-world agents and workflows, this is a very “right-fit” pairing: small, precise, and trustworthy
Seen this way, RLVR is truly a win-win-win for performance, for reliability, and for user control
@Gradient_HQ is playing exactly the right role in this narrative
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency

Jan 17

productivity intelligence will play a more significant role with RLVR (reinforcement learning with verifiable rewards) as integration of intelligence continues.
for models powering agents you can scale these small models to outperform models much larger. task specific and correctness based which is a attractive pair. engineering them for reliable execution with accuracy as it’s based on verifiable tasks.
teams can run these smaller models locally as well keeping their automations and data fully private.
win win win in RL? 👀 @Gradient_HQ
2
14
129
Following up on that, what makes Parallax’s decentralized speculative decoding work is how it’s adapted to real, messy networks not idealized data centers
Instead of verifying one token per round trip, Parallax batches speculative tokens together. A lightweight local model drafts several tokens instantly, then the distributed target model verifies them in a single pass. If multiple tokens are accepted, the entire system advances together, cutting down global synchronizations by a large factor
On top of that, verification isn’t treated as binary for every token. Some tokens matter a lot function names, numbers, control symbols. Others don’t. By relaxing checks for low-impact tokens while keeping strict validation for critical ones, the system increases how many tokens can be accepted per round without hurting accuracy
All of this happens without retraining models or changing user code. From the outside, it just feels faster and more stable especially when inference spans multiple locations and heterogeneous hardware
What’s interesting here isn’t a single optimization, but the direction: decentralized inference only becomes viable at scale when systems are designed around latency, not in spite of it. And this feels like a glimpse of what efficient, truly distributed AI infrastructure starts to look like
@Gradient_HQ
@VinoisAsian
@HexxRL
#thinkopen #Parallax #latency

Lately I’ve seen Parallax talk more about decentralized speculative decoding, so I took some time to dig into why it actually matters
In centralized inference, speed is mostly about raw compute. But once inference becomes decentralized spread across home machines, university clusters, and multiple data centers the bottleneck quietly shifts. It’s no longer GPU compute, it’s network latency. Every generated token becomes a synchronization step, and GPUs end up waiting on packets instead of doing useful work
Parallax’s approach is simple in spirit but powerful in practice: instead of treating latency as a fixed tax, turn it into productive work. Decentralized Speculative Decoding does this by letting models “guess ahead” locally and then confirm multiple tokens at once, rather than waiting for the network after every single word
The result isn’t just faster responses. It’s a different way of thinking about inference at scale one where distributed systems stop being held back by the network and start working with it
@Gradient_HQ
#thinkopen #Parallax #latency

2
13
191
Lately I’ve seen Parallax talk more about decentralized speculative decoding, so I took some time to dig into why it actually matters
In centralized inference, speed is mostly about raw compute. But once inference becomes decentralized spread across home machines, university clusters, and multiple data centers the bottleneck quietly shifts. It’s no longer GPU compute, it’s network latency. Every generated token becomes a synchronization step, and GPUs end up waiting on packets instead of doing useful work
Parallax’s approach is simple in spirit but powerful in practice: instead of treating latency as a fixed tax, turn it into productive work. Decentralized Speculative Decoding does this by letting models “guess ahead” locally and then confirm multiple tokens at once, rather than waiting for the network after every single word
The result isn’t just faster responses. It’s a different way of thinking about inference at scale one where distributed systems stop being held back by the network and start working with it
@Gradient_HQ
#thinkopen #Parallax #latency
1
10
307
Jan 17
Is your favorite AI project still experimenting to figure out whether its technology can scale efficiently? @Gradient_HQ already is and proving it.⚡️
Gradient’s cutting-edge distributed reinforcement learning (RL) framework, Echo, is built on the same high-performance, distributed AI infrastructure that powers @tryParallax for inference. Instead of relying on a single, centralized system, Echo leverages many interconnected machines working together, often using everyday, globally distributed hardware.💻
At the core of Echo is a dual-swarm architecture with decoupled inference, where each swarm is optimized for a specific computational role and can scale independently. This ensures every workload runs where it performs best, maximizing hardware efficiency without sacrificing the statistical reliability of standard RL algorithms.⚙️
To validate this approach, Gradient tested whether a decoupled RL architecture running across heterogeneous, globally distributed devices could match the training efficiency and performance of traditional, tightly coupled systems🧑🔬.
The results spoke for themselves: Echo matched the baseline across all tasks, achieving comparable convergence speed and final rewards.🥇
This demonstrates that high-performance reinforcement learning can operate effectively across distributed, heterogeneous infrastructure while maintaining efficiency, stability, and accuracy.
🤖More Details: gradient.network/blog/echo-d…
#thinkopen #DecentralizedAI #LLMs

27
6
48
2,543
Jan 13
I believe ./ Gradient’s Open AI infrastructure is taking the lead in the race to build the most innovative and efficient decentralized AI stack, and for good reason. One standout example is Decentralized Speculative Decoding (DSD), a plug-and-play framework implemented directly within @tryParallax, Gradient’s distributed inference engine. 🥇
DSD transforms the biggest bottleneck in distributed inference, network latency, into productive compute. Rather than waiting for each token to be processed sequentially across nodes, a lightweight draft model generates multiple token candidates ahead of time while data is in transit. These candidates are then verified in parallel by the full model, reducing synchronization overhead and significantly boosting throughput, without retraining or altering the model architecture. ⚙️
In practice, this delivers up to ~2.6× faster inference ⏩, turning communication delays into useful work and improving GPU utilization across decentralized clusters.⚡️
The result? Agents, coding assistants, and research workloads running on Parallax become faster, more responsive, and far more hardware-efficient.
It’s definitely getting spicy over at @Gradient_HQ 🌶️
Details: gradient.network/research/tu…
#thinkopen #Web3AI #DecentralizedAI

24
7
46
1,298