
Interested in SMLM/computing SR technique | PostDoc in LiLab @YimingLi_SZ, SUSTech
Joined May 2022
- Tweets 117
- Following 129
- Followers 20
- Likes 48
1 Photos and videos


Shuang Fu retweeted

Mar 6
🚨BREAKING: OpenAI published a paper proving that ChatGPT will always make things up.
Not sometimes. Not until the next update. Always. They proved it with math.
Even with perfect training data and unlimited computing power, AI models will still confidently tell you things that are completely false. This isn't a bug they're working on. It's baked into how these systems work at a fundamental level.
And their own numbers are brutal. OpenAI's o1 reasoning model hallucinates 16% of the time. Their newer o3 model? 33%. Their newest o4-mini? 48%. Nearly half of what their most recent model tells you could be fabricated. The "smarter" models are actually getting worse at telling the truth.
Here's why it can't be fixed. Language models work by predicting the next word based on probability. When they hit something uncertain, they don't pause. They don't flag it. They guess. And they guess with complete confidence, because that's exactly what they were trained to do.
The researchers looked at the 10 biggest AI benchmarks used to measure how good these models are. 9 out of 10 give the same score for saying "I don't know" as for giving a completely wrong answer: zero points. The entire testing system literally punishes honesty and rewards guessing.
So the AI learned the optimal strategy: always guess. Never admit uncertainty. Sound confident even when you're making it up.
OpenAI's proposed fix? Have ChatGPT say "I don't know" when it's unsure. Their own math shows this would mean roughly 30% of your questions get no answer. Imagine asking ChatGPT something three times out of ten and getting "I'm not confident enough to respond." Users would leave overnight. So the fix exists, but it would kill the product.
This isn't just OpenAI's problem. DeepMind and Tsinghua University independently reached the same conclusion. Three of the world's top AI labs, working separately, all agree: this is permanent.
Every time ChatGPT gives you an answer, ask yourself: is this real, or is it just a confident guess?

1,339
8,742
33,325
3,277,906
Shuang Fu retweeted

21 Nov 2025
Happy to share our latest work, 4Pi-SIMFLUX, which combines structured illumination with interferometric detection to achieve near-isotropic 3D localization precision of 2–3 nm and resolve sub-10 nm structural features in cells. nature.com/articles/s41592-0…
rdcu.be/eQVxt
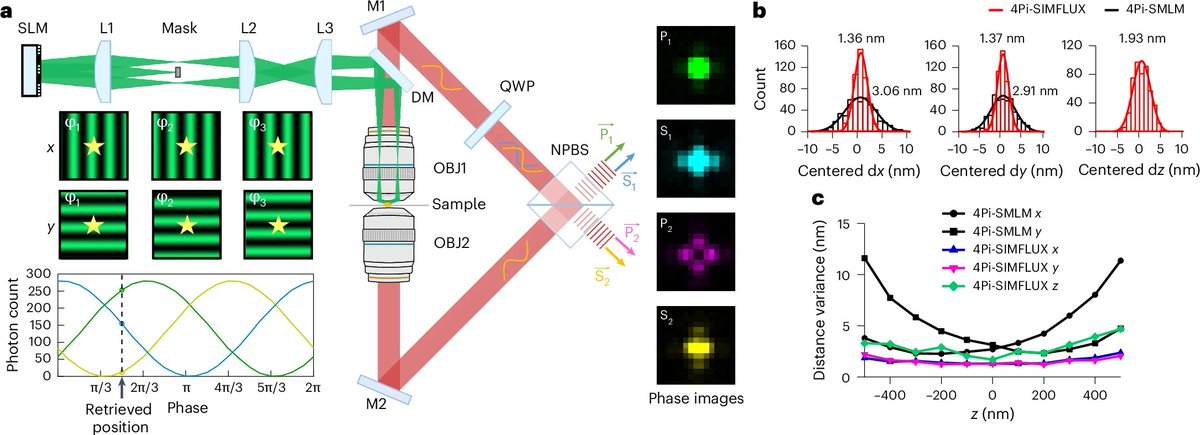
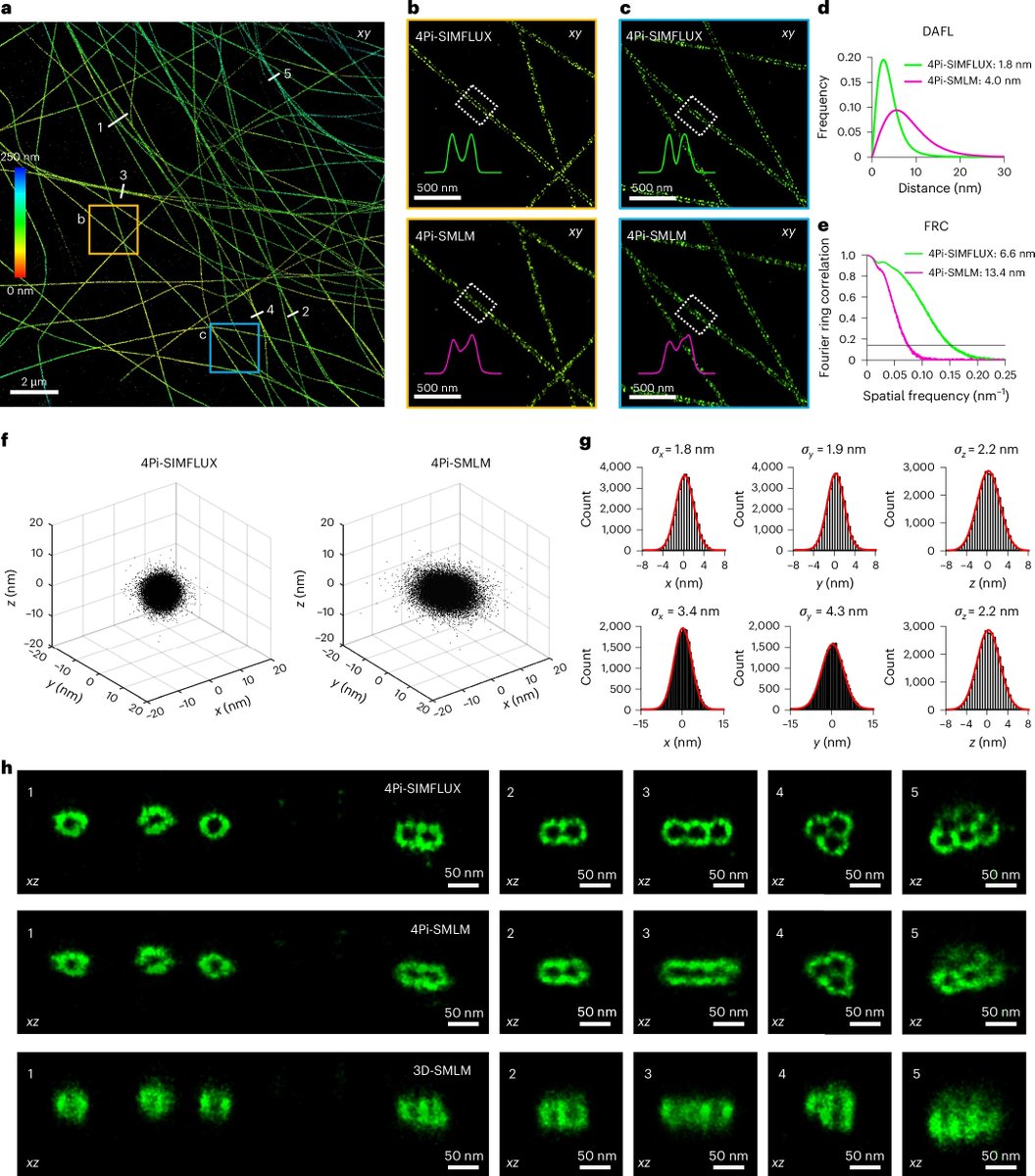
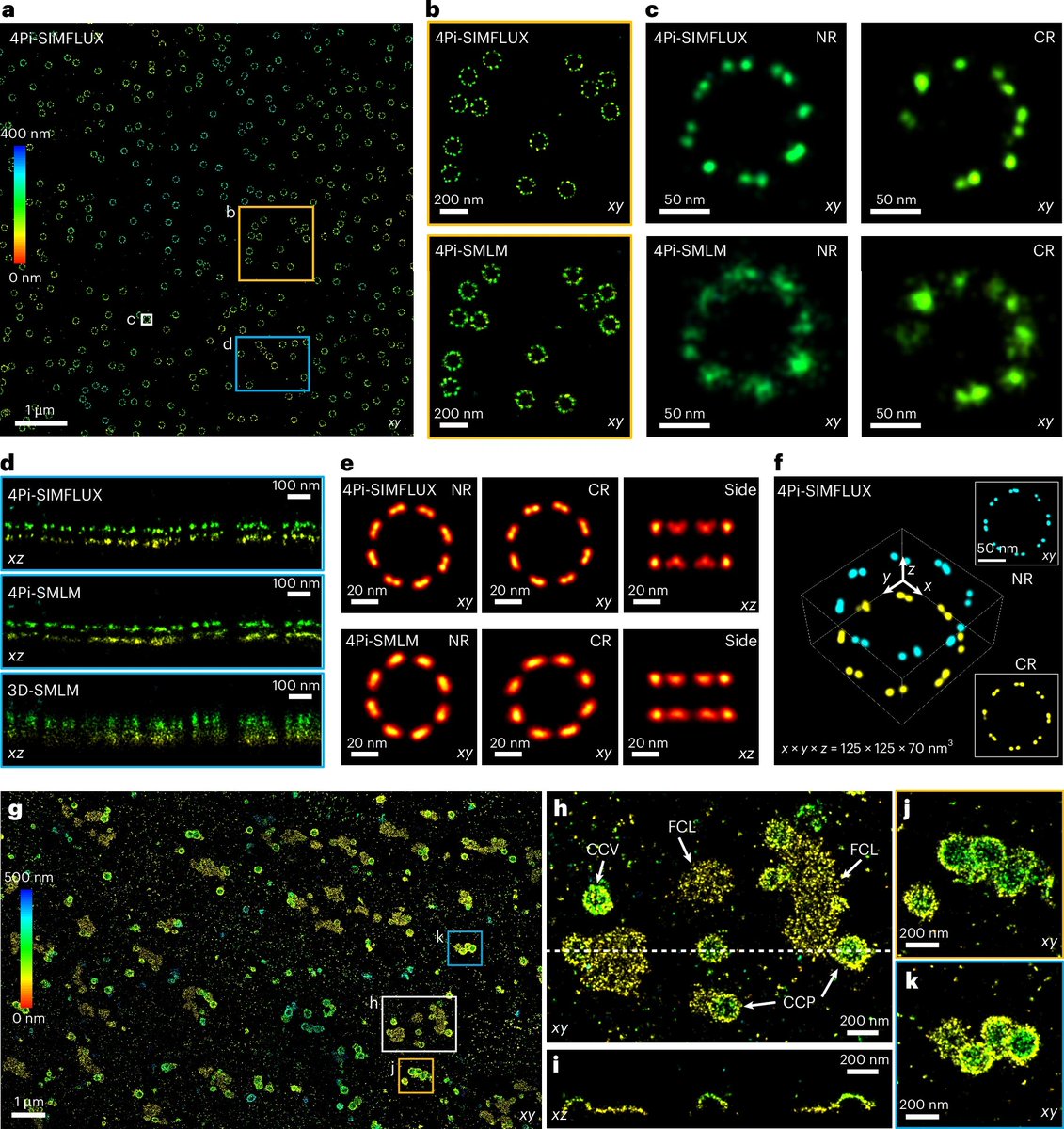
10
19
71
8,257
Shuang Fu retweeted

6 Aug 2025
We’re excited to share LiteLoc — a lightweight and scalable deep learning framework for high-throughput single-molecule localization microscopy, enabling analysis speed of >500 MB/s on 8× RTX 4090 GPUs without compromising accuracy. rdcu.be/eztp6

5
12
1,008
Shuang Fu retweeted

8 Jul 2025
Really excited to share this Perspective from John Danial covering how technology is moving the field of fluorescence microscopy toward structural biology. nature.com/articles/s41592-0…
1
53
153
14,562
Shuang Fu retweeted

6 Mar 2025
...and gradient descent is Bayesian inference:
jmlr.org/papers/v24/22-0291.…
5 Mar 2025

After many papers, finally wrote out why I believe the brain to do gradient descent as a blog post: medium.com/@kording/why-i-be…
1
26
132
18,479

7 Mar 2025
This is perfectly compatible with LUNAR, which leverages temporal context up to 9 frames to achieve ultra-high localization precision. Imagine the possibilities of large-DOF in situ multicolor 3D reconstructions!
5 Mar 2025

🎊Fantastic work!!! This pre-print by @LE_Laurent_ @S_LevequeFort et. al introduces Brightness Demixing for simultaneous 3-target imaging using 1 laser🤯
📷 Our #DNAPAINT ready 2ry antibodies & imagers were used for vimentin, clathrin,& tubulin imaging
biorxiv.org/content/10.1101/…
1
76
Shuang Fu retweeted

2 Mar 2025
If you're at #AAAI2025, try to catch Cornell PhD student @yingheng_wang, who just presented a poster on Diffusion Variational Inference.
The main idea is to use a diffusion model as a flexible variational posterior in variational inference (e.g., as the q(z|x) in a VAE) [1/3]

4
21
323
27,899
24 Feb 2025
RT @StefanHellLabs: Optical nanoscopy, but without the OFF...!
Published in @NaturePhysics by T.A. Hensel, J.O. Wirth, O.L. Schwarz & S.W.…
22
22 Feb 2025
My first postdoc project! Combining neural networks & physics for self-supervised localization was a wild ride. Grateful for the journey and the team!
21 Feb 2025

Excited to share LUNAR (Localization Using Neural-physics Adaptive Reconstruction) —a self-supervised, blind localization method that combines neural networks & physics to estimate aberrations from overlapped blinking molecules for large DOF imaging. Great work @judefffff !
2
225
Shuang Fu retweeted

17 Feb 2025
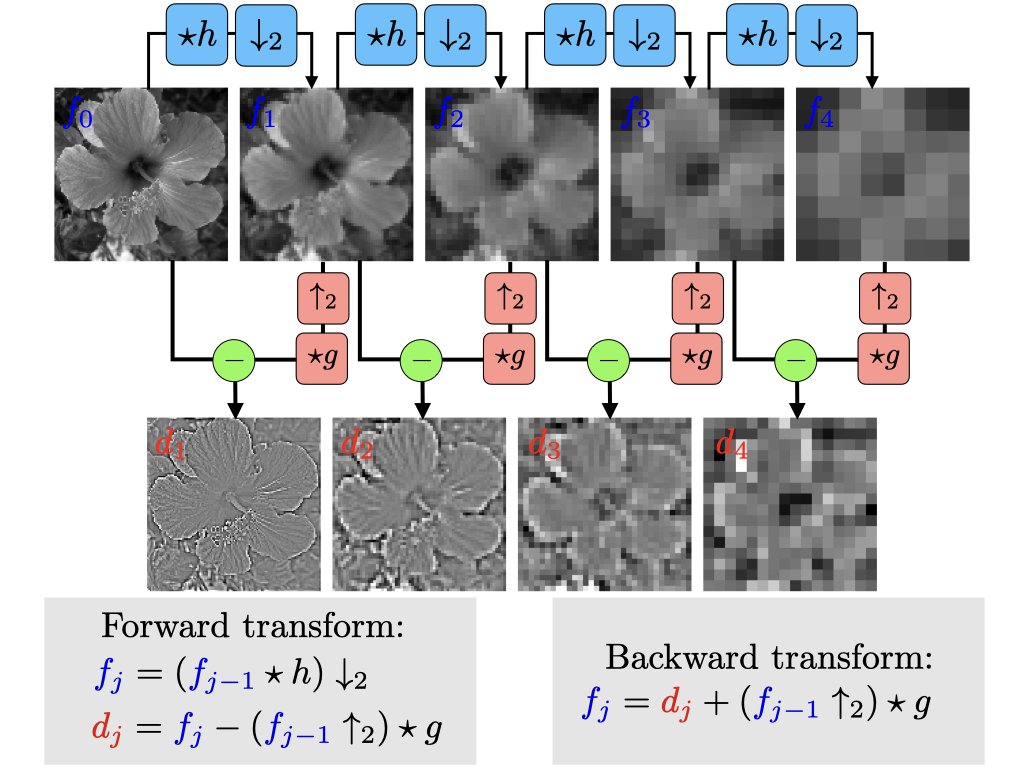
The Laplacian pyramid is the ancestor of the wavelet transform. Defines a compact multiscale representation by iterative lowpass/highpass filterings. en.wikipedia.org/wiki/Pyrami…
5
83
353
18,626
Shuang Fu retweeted

18 Feb 2025
Introducing Interactive Cell Biology, a complete course solution—no textbook needed. In partnership with @MacmillanLearn, delivered through Achieve. Check it out today! Visit: macmillanlearning.com/colleg… to learn more. #cell #biology #education #animation
5
173
647
44,021
Shuang Fu retweeted

12 Feb 2025
MIT's "Street Fighting Mathematics"
This course teaches the art of guessing results and solving problems without doing a proof or an exact calculation.
Book: ocw.mit.edu/courses/18-098-s…

15
341
2,816
175,765
Shuang Fu retweeted

15 Jan 2025
Microscopy Nodes: versatile 3D microscopy visualization with Blender
Oane Gros, Chandni Bhickta, Granita Lokaj, Yannick Schwab, Simone Köhler and Niccolò Banterle
biorxiv.org/content/early/20…

2
13
68
7,459
Shuang Fu retweeted

23 Dec 2024
Maybe the most amazing microscope paper of the year just dropped: Live 4pi-SIM (a.k.a I5S*):
nature.com/articles/s41592-0…
Having worked with Mats Gustafsson, I can attest that this is both extremely hard, but also extremely cool!
Kudos to the authors!
*cell.com/AJHG/fulltext/S0006…


10
60
240
23,373
Shuang Fu retweeted

21 Dec 2024
This is - unintentionally - an absolutely damning critique of modern biology.
21 Dec 2024

One of the remarkable things for me about NeurIPS this year was how quickly the entire AI for Biology community has gone all-in on biological foundation models. Virtual cell models will enable us to predict how cell states will change in response to chemical perturbations. Protein language models will enable us to identify better enzymes for degrading plastics, and so on. Everyone wants bigger data on more things to throw into bigger models.
These models are going to be awesome, but real biology discoveries look somewhat different. Contrast these dreams of foundation models with the latest table of contents from Science or Nature:
--“A long noncoding eRNA forms R-loops to shape emotional experience–induced behavioral adaptation” — The authors identified a lncRNA in mice that is expressed in response to neuronal activity that modulates the 3D structure of chromatin, thereby activating genes that are involved in neuronal plasticity. The authors further identified that this lncRNA is essential for certain forms of learning.
--“Cancer cells impair monocyte-mediated T cell stimulation to evade immunity” — The authors identified that mouse melanoma cells secrete a lipid metabolite that prevents monocytes from activating CD8 T cells.
--“Postsynaptic competition between calcineurin and PKA regulates mammalian sleep–wake cycles” — By generating mouse knockout lines, the authors identified phosphatases and kinases that are critical for regulating the sleep-wake cycle, and showed that they act through regulation of proteins at excitatory postsynaptic sites.
I struggle to imagine how any of these discoveries could fall out of a multimodal biology foundation model. This is not intended to be a straw man argument. Surely, a foundation model could potentially identify the lncRNA from the first paper, but I am not sure how such a foundation model would associate it with chromatin remodeling. A multimodal foundation model with enough data could also potentially identify metabolic changes associated with melanoma cells subjected to certain kinds of treatments, but I don’t see how that foundation model could identify the effect of those metabolites in preventing CD8 T cell activation. Indeed, I do not think that any of the foundation models that are being developed today would be capable of generating rich new biological insights of the kind described in these papers. And yet, these are the kinds of insights that new therapies are made from.
The issue, I think, is that machine learning models work extremely well on structured data, and so all the foundation models that are being built are highly structured. Take a protein sequence as input and produce a protein sequence as output. Take a cell state and a chemical perturbation as input and produce a new cell state as output. Biology, however, is poorly structured. The lncRNA insight is case in point: what structured representation can we use for the action of the lncRNA in modulating chromatin architecture? Protein models cannot represent it; DNA models cannot represent it; virtual cell models cannot represent it. Perhaps a model that incorporates RNA expression and 3D genome state could represent it, but then how would that model represent the lipid modulation of the monocytes? I worry that every discovery may need its own representation space. Indeed, the nature of biology is such that there likely is no representation, short of an atomic-resolution real-space model of the entire organism, that is sufficient to represent the diversity of biological phenomena that are relevant for disease.
Except, of course, for natural language, which is evolved to represent all concepts that humans are capable of contemplating. Indeed, I think natural language has an essential role to play in representing biology, and is ultimately unavoidable, insofar as it is the only medium we know of that is sufficiently structured for machine learning and sufficiently flexible to represent the full diversity of biological concepts. At FutureHouse, we work on language agents, which is one way of combining language and biology, but this is not the only way. Models that combine natural language with protein, DNA, transcriptomics, and so on will also be extremely productive, provided the addition of the structured datatypes does not restrict their ability to represent unstructured concepts. However we do it, I think this essential role of natural language in representing biology is currently largely underappreciated.
The history of biology is built on tools that we have found in nature to study biological phenomena. As all biologists know, trying to engineer things from scratch (almost) never works; what works is finding things in nature and repurposing them. It will be aesthetically pleasing if it turns out that our engineered representations are yet again insufficient for studying biology, and that natural language is simply another such tool that we have found in nature that must be applied instead.

13
33
288
82,534
Shuang Fu retweeted

25 Nov 2024
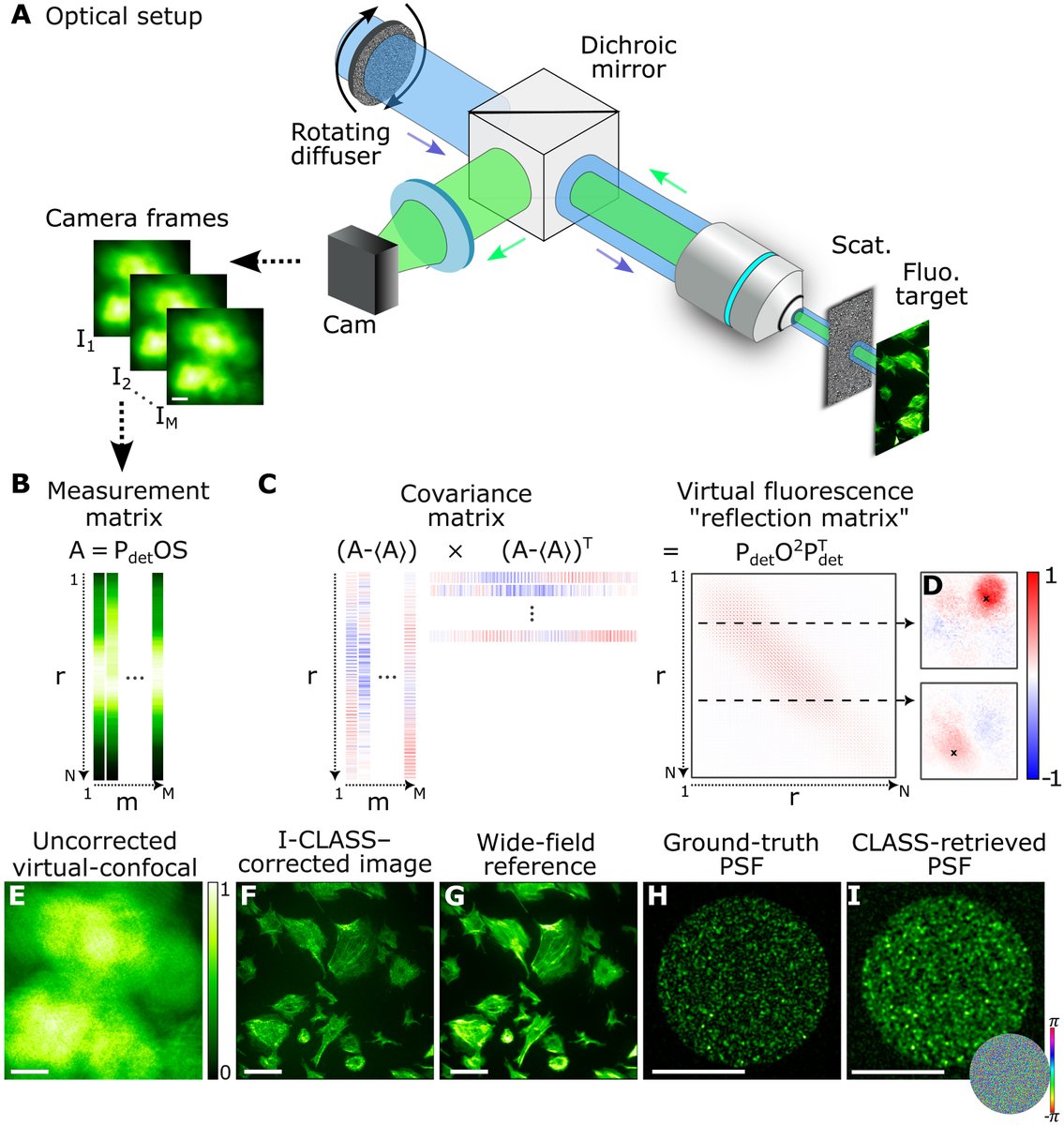
New scattering compensation method is compatible with widefield #Fluorescence #Microscopy, requiring tens of frames of raw data acquired using random illumination patterns, but without the need for a spatial light modulator or target sparsity: bit.ly/4i9ivOW
4
23
1,264
Shuang Fu retweeted
25 Nov 2024
PetaKit is great; it deals efficiently with large data, and it is easy to use. I can highly recommend it if you need deskewing, rotation and/or deconvolution for your post-processing.
The repository is also not large, so it does not take much to clone it and try it out.
25 Nov 2024

Introducing PetaKit5D: a comprehensive suite of software tools for processing petabyte-scale microscopy data from Janelia Sr Fellow/HHMI Investigator @Eric_Betzig, Xiongtao Ruan, Matthew Mueller, Srigokul Upadhyayula @ABCUCBerkeley @UCBerkeley & colleagues nature.com/articles/s41592-0…
8
34
3,421
Shuang Fu retweeted
18 Nov 2024
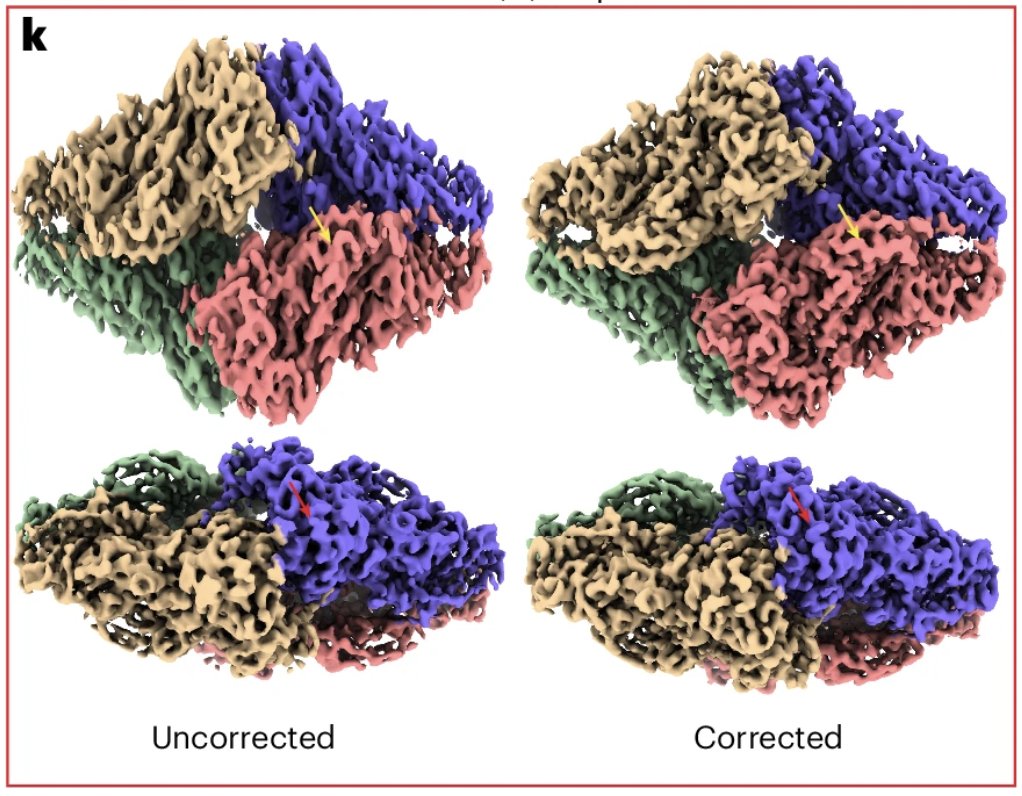
Introducing spIsoNet, a software tool that addresses the challenges of map anisotropy and particle misalignment in cryo-EM caused by the preferred orientation problem.
@zhou_lab @yuntaoinnit @hongcheng_fan
nature.com/articles/s41592-0…
30
114
21,234
Shuang Fu retweeted

12 Aug 2024
We (@AndrewGYork, @RunningPhoton, @microRussell and I) are still working on the manuscript describing our automatic parameter-free deconvolution approach, but we've made a Google Colab notebook where you can try it out without needing to install anything:
beryl.mrc-lmb.cam.ac.uk/rlgc…
3
29
129
24,093