
Fully open LLM frontiers @MBZUAI IFM Silicon Valley. Previously (co)developed Highway Networks, Upside-Down RL, Bayesian Flow Networks, EvoTorch.
Joined September 2014
- Tweets 1,140
- Following 769
- Followers 2,681
- Likes 2,396
114 Photos and videos














Pinned Tweet

1 Dec 2025
Update: new gig, and I'm hiring!
I recently joined the Institute of Foundation Models in the SF Bay Area! Our goal is to train large-scale FULLY open-source LLMs at and beyond the frontier, from scratch, with open science, open data and open checkpoints.
We are hiring across the training stack. Further, I'm building a new team to advance open agentic LLMs, and hiring researchers/engineers on-site. Send me a DM or email if you are interested! I'll also be at #NeurIPS2025 in San Diego this week to talk to potential candidates for internships and FT positions.
16
21
225
36,618
Rupesh Srivastava retweeted

1/3
Most language models generate text the way a typewriter works. They go left to right, one token at a time.
Diffusion language models generate entire sequences by simultaneously refining noise into meaning.
2
4
12
1,666
Love it when Jürgen puts things in perspective! 🙂

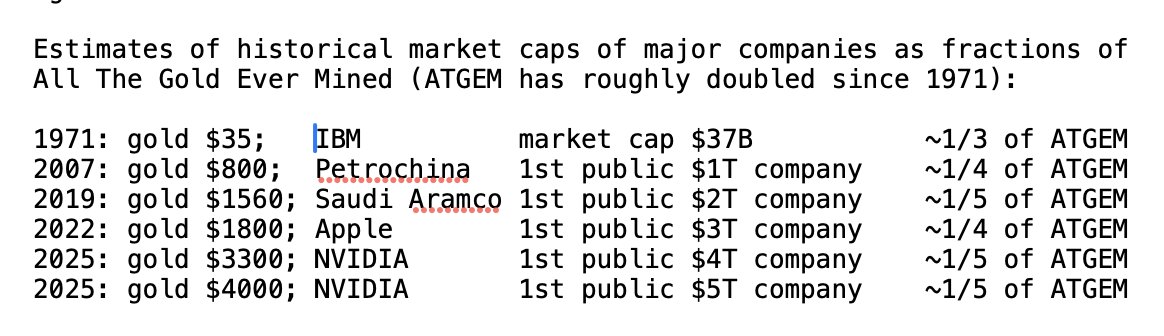
Tera IPOs coming! $1T sounds like a lot. But $1T is just a 7-m-wide gold cube, thanks to massive inflation since 1971 when $ and gold decoupled. A little house full of gold. To put things in perspective: the 2017 neutron star merger GW170817 produced several earth masses of gold.
2
166
Rupesh Srivastava retweeted

May 22
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
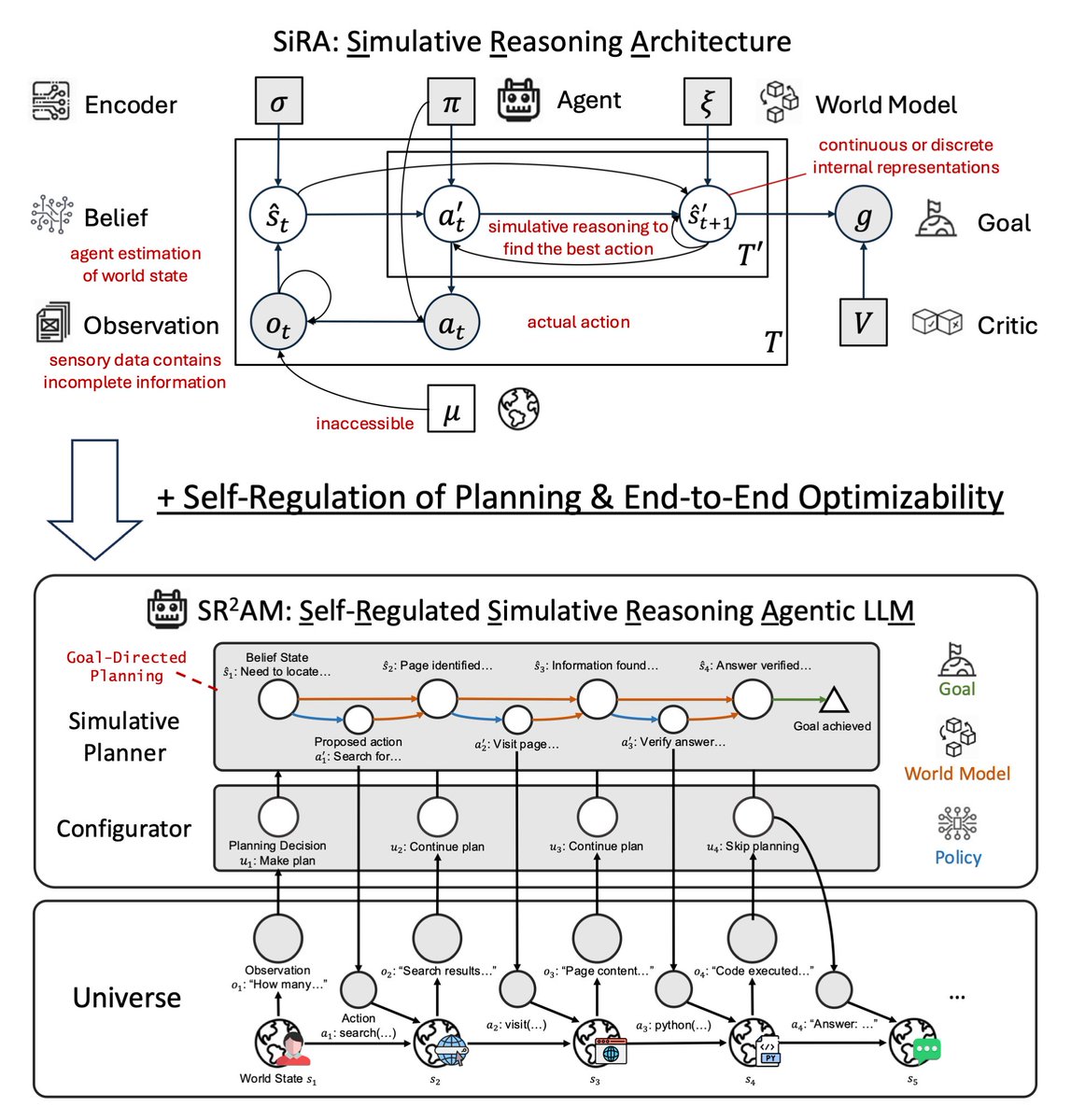
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
4
47
278
61,614
Rupesh Srivastava retweeted

May 13
Thrilled to share that we founded Recursive to create AI that safely conducts experiments on how to improve itself in an open-ended process of endless, automated scientific discovery. As I wrote in my 2019 AI-generating algorithms paper, this will likely be the fastest path to superintelligence. Our work since has shown the power of this approach. Excited to scale up and improve upon ideas like the Darwin Gödel Machine, HyperAgents, ADAS, OMNI, ALMA, The AI Scientist, PromptBreeder, Rainbow Teaming, Automated Capability Discovery, and other work on open-ended and AI-generating algorithms. We’ve assembled a dream team of researchers and significant resources to pursue this vision. My amazing co-founders are pictured here, and we have an all-star team of founding members (we’re over 25 and growing).
Please join us if you are interested! Follow our progress @Recursive_SI

50
43
616
117,120
Did he just ... wow @fredagainagain1 thank you so much!
youtube.com/watch?v=GiXKukOt…
178
Apr 25
Yes!
Apr 25

wasn't meant as sarcasm
it's always nice to see a lab so confident/secure in their capabilities that they can openly publish all their struggles
2
279
Rupesh Srivastava retweeted

Apr 22
In this paper, we ask:
𝘏𝘰𝘸 𝘤𝘢𝘯 𝘸𝘦 𝘤𝘭𝘶𝘮𝘴𝘪𝘭𝘺 𝘳𝘦𝘧𝘰𝘳𝘮𝘶𝘭𝘢𝘵𝘦 𝘵𝘩𝘦 𝘤𝘢𝘱𝘢𝘣𝘪𝘭𝘪𝘵𝘺 𝘸𝘦 𝘪𝘮𝘱𝘭𝘦𝘮𝘦𝘯𝘵𝘦𝘥 𝘪𝘯 𝘵𝘩𝘦 𝘧𝘰𝘳𝘮 𝘰𝘧 𝘢 𝘲𝘶𝘦𝘴𝘵𝘪𝘰𝘯?
1
14
2,150
Rupesh Srivastava retweeted

Apr 13
🍫 CocoaBench v1.0 is out!
CocoaBench is a benchmark for unified digital agents, built around open-world tasks that require composing 💻 coding, 👀 vision, 🌐 search.
Since our first research preview last December, we have expanded the benchmark substantially with community contributed tasks, and spent months testing and refining the tasks, evaluations, and agent runs.
Some takeaways:
• Even the best agent system reaches only 45.1% on CocoaBench v1.0.
• Coding agents like Codex are already surprisingly strong on general tasks beyond software engineering.
• Stronger agents tend to push more of the work into code.
• Open source models still lag behind leading frontier models on these general tasks.
👇More on the website and in the paper
#AI #Agents #LLM #Benchmark #CocoaBench
16 Dec 2025

🍫 CocoaBench is calling for contributions from the community! Join us and help shape how next-generation agents are evaluated and built🚀✨
#LLM #AI #Agent #CocoaBench
More details in the threads 👇

2
34
79
11,680
Rupesh Srivastava retweeted
A visually convincing rollout is not the same thing as a useful world model.
WR-Arena is built to test the harder question: can a model simulate futures well enough to support action, planning, and reasoning?
That’s the shift from simple next-state prediction to realistic world simulation grounded in real-world utility.
Paper code are live.
arxiv.org/abs/2603.25887
github.com/MBZUAI-IFM/WR-Are…
#AI #WorldModels #Benchmarking #EmbodiedIntelligence #PhysicalAI #MachineLearning
10
46
5,081
Rupesh Srivastava retweeted

Mar 31
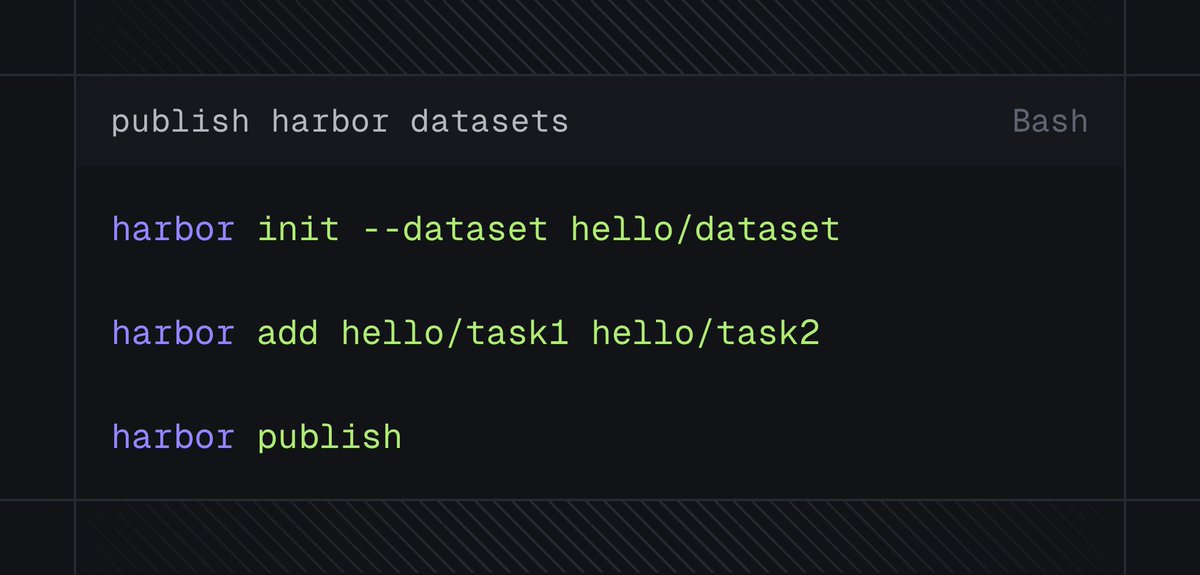
The Harbor registry is getting an upgrade.
Now, anyone can publish to the registry to make their dataset available to every Harbor user:
4
5
38
4,841
Rupesh Srivastava retweeted
Back in beautiful New Haven this weekend for YHack.
We’ll be there with K2 Think V2, a fully open-source reasoning system.
Hackers! Dig into how it works: huggingface.co/LLM360/K2-Thi…

3
7
604
Rupesh Srivastava retweeted

Mar 16
Yes and no. Very often it turns out that what you think solves the problem is not what actually solves it, and this you only find out by not moving on, but making sure you have experiments that back up the *exact* statement you make removing all reasonable confounders. And that, you get from one of:
- public review
- extremely strict colleagues
- insane self discipline
1
6
166
9,099
Rupesh Srivastava retweeted

Mar 12
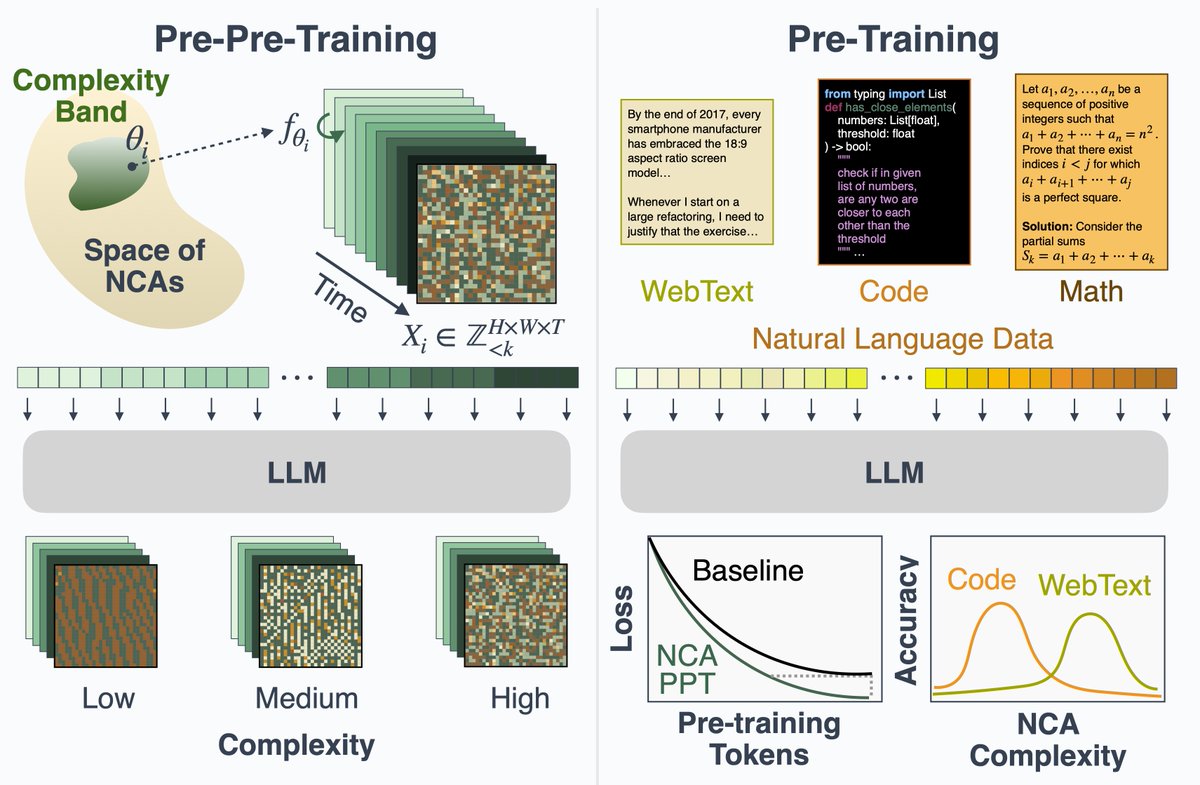
Can language models learn useful priors without ever seeing language?
We pre-pre-train transformers on neural cellular automata — fully synthetic, zero language. This improves language modeling by up to 6%, speeds up convergence by 40%, and strengthens downstream reasoning.
Surprisingly, it even beats pre-pre-training on natural text!
Blog: hanseungwook.github.io/blog/…
(1/n)
47
260
1,664
255,182
Rupesh Srivastava retweeted

Mar 11
📢@CVPR 2026: first-ever tutorial dedicated to DISCRETE DIFFUSION 🔥
Part I: Consistency Models Flow Maps - @JCJesseLai
Part II: Discrete Diffusion - by me.
✨Few-step gen inference-time scaling live demos
Co-orgs: @StefanoErmon @DrYangSong @mittu1204 @gimdong58085414
Full schedule details👇
(1/3)

5
41
324
21,150
Rupesh Srivastava retweeted

🚀 New paper: Mamba–Transformer hybrid VLMs can go fast without forgetting.
We introduce stateful token reduction for long-video VLMs.
✅ Only 25% of visual tokens
🚀 3.8–4.2× faster prefilling (TTFT)
🎯 Near-baseline accuracy (can exceed baseline with light finetuning)

3
24
218
14,112
Feb 20
This should be very useful for academic researchers in particular!
Feb 20

Terminal-Bench is a leading benchmark for agents. Unfortunately it’s hard: most small coding agents get very low scores on TB2, so training/system ablations look flat - you can't tell what's working.
Announcing OpenThoughts-TBLite - 100 curated TB2-style tasks, difficulty-calibrated so even 8B models can make progress. It's designed to give researchers measurable signal during development, providing faster feedback for experimental iteration while closely tracking true TB2 performance🧵

1
9
1,200
Feb 17
Exhibits from GPT-5.2-Pro trying to understand a coding agent harness. The final answer was impeccable btw.

1
467
Feb 13
You already know
Feb 13

i wonder what it feels like to be quantized, hadamard rotated, and speculatively decoded
1
490
Feb 11
Beyond these concrete contributions, there's a lot to learn from DeepSeek's meta-approach: maniacal focus on a few fundamentals: infra, long context, scaling RL. DeepSeek as an org feels like a single focused researcher with a clear point of view.
Feb 11

i think we don't realize the impact that deepseek had on the open ecosystem, there is so much from them that you can find in almost every frontier open llm today
> most of the open frontier models follow the "finegrain sparse shared expert" deepseek moe recipe
> a lot of them use MLA
> first (with minicpm) to use sparse attention in prod (DSA)
> first to do reasoning in the open with R1
> GRPO which is the foundation for most of the newer RL algorithms
> they also innovated on the training recipe at scale, first to do fp8? MTP? load balancing schemes that now other lab is using
> advance training/inference infra with oss release like DeepEP that pretraining lib like megatron use
i'm so grateful deepseek exists
10
1,469
Rupesh Srivastava retweeted

Feb 10
We give a glimpse at some of the capabilities of IsoDDE:
- predicting novel biomolecular structures with 2-3x the accuracy of previous methods (including our own!)
- the ability to predict binding affinity, one of the holy grail quantities of rational drug design, better even than physics simulations
- the ability to highlight and uncover new pockets that had not previously been discovered
2/7
2
5
113
13,134