
A high-throughput and memory-efficient inference and serving engine for LLMs. Join slack.vllm.ai to discuss together with the community!
Joined March 2024
- Tweets 1,048
- Following 36
- Followers 41,373
- Likes 597
295 Photos and videos










12h
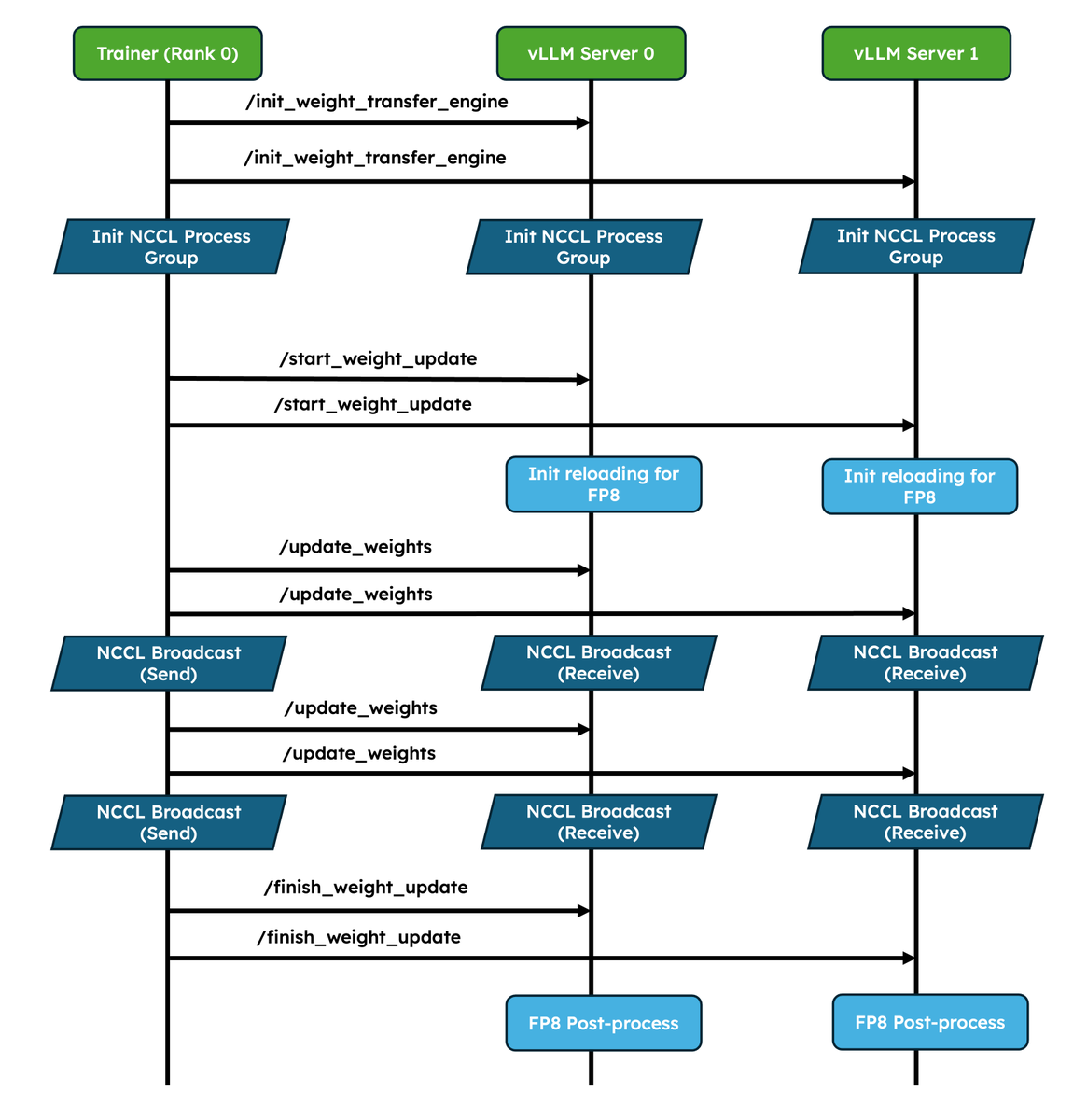
vLLM v0.23.0 is out! 408 commits from 200 contributors (63 new). 🎉
Highlights: DeepSeek-V4 matures across backends (TRTLLM-gen attention kernel, sparse MLA decoupled from V3.2, EPLB for the Mega-MoE), Model Runner V2 now default for Llama Mistral dense models, Gemma 4 Unified (encoder-free) MTP, a maturing Rust frontend, multi-tier KV cache offloading with an object-store tier, and a unified reasoning tool-call parser.
Thread 👇
13
33
339
27,921
12h
Hardware & performance:
🟢 NVIDIA: FP8 FlashInfer attention for ViT, Triton MoE on Hopper by default, CUTLASS FP8 scaled-mm padding bypass ( 20%), MoE-permute buffer pre-alloc ( 9–14%), NUMA auto-binding on DGX B300
🔴 AMD ROCm: ROCm 7.2.3, native W4A16 fused-MoE W4A16 kernels for RDNA3 (gfx1100), AITER top-k/top-p sampler by default, attention-sink support in AITER FA
🔵 Intel XPU: vllm-xpu-kernel v0.1.7, block FP8 MoE, a DeepSeek-V4 attention decode path, transparent sleep mode
💻 CPU & more: zentorch-accelerated W8A8/W4A16 on AMD Zen CPUs, RISC-V RVV WNA16 helpers, a PowerPC SHM communicator, an arm64 CI image
2
17
2,704
12h
Models, serving, and what to know before upgrading:
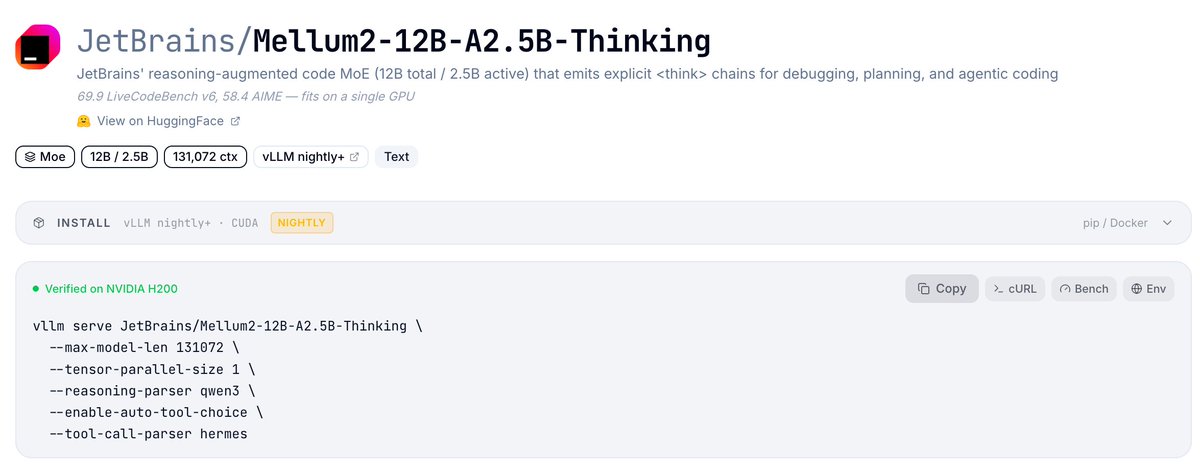
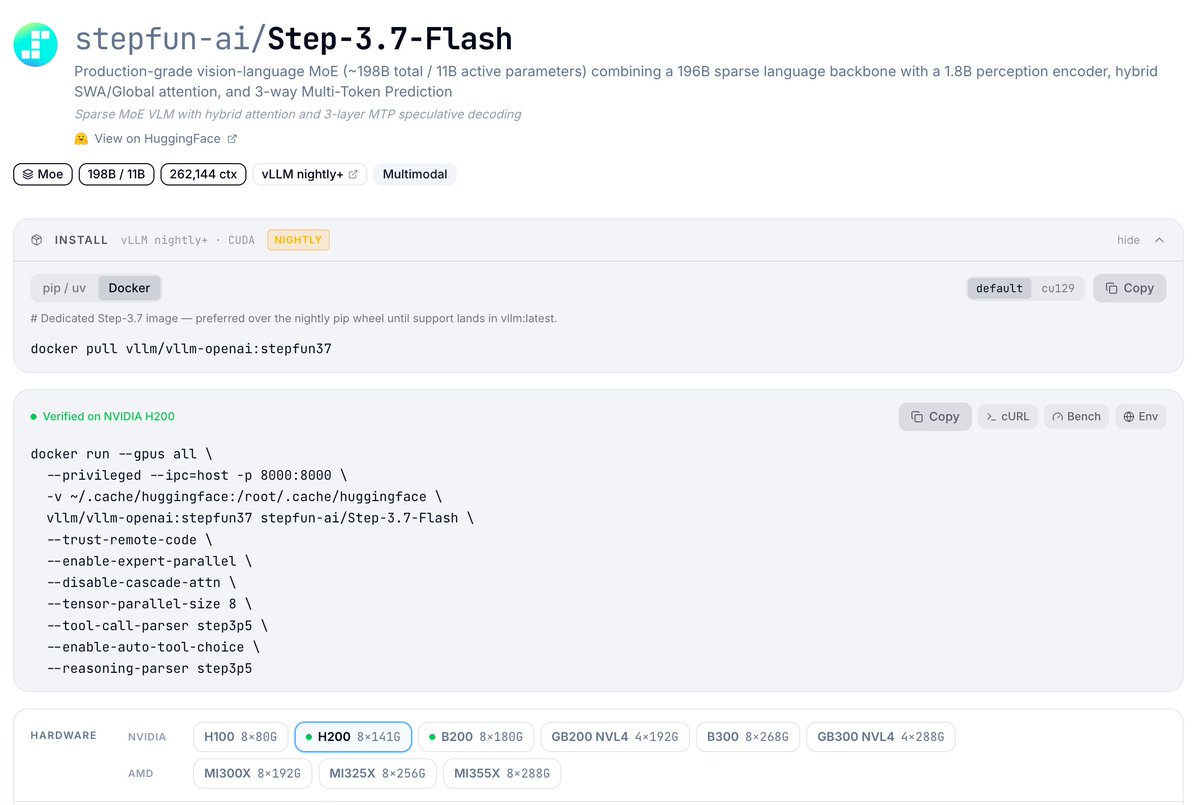
🆕 New models: Step-3.7-Flash, Cosmos3 Reasoner, JetBrains Mellum v2, Granite Speech Plus, Cohere Mini Code
🦀 Rust frontend grows up: a streaming generate endpoint, dynamic LoRA endpoints, /version /server_info, and new tool parsers (InternLM2, Phi-4-mini, Gemma4)
🔒 Security: SSL/TLS for the data-parallel supervisor, and out-of-vocab token IDs rejected before they reach the GPU logprob path
🙏 Thanks to all 200 contributors this cycle (63 first-timers).
📖 Full release notes → github.com/vllm-project/vllm…
8
1,965
Jun 13
Glad to see day-0 speculators are warm welcomed by the community!
Jun 13

Congrats to @vllm_project & @lmsysorg for releasing MiniMax M3 428B on both the CUDA & ROCm stack on day 0! MiniMax M3 includes:
🟠 Block sparse attention which is 9x faster prefill over M2.7
🟠 Day 0 open MXFP8 weights
🟠 and Furthermore @Inferact released Day-0 EAGLE3 open weight draft model support
Excited to try out the performance on MiniMax M3!

1
2
56
6,844
Jun 12
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
4
31
301
38,765
Jun 12
Day-0 goes beyond inference: NeMo RL from @NVIDIAAI also supports MiniMax M3 on day 0, with vLLM powering rollout generation. 💡
A reference GRPO recipe is ready, so you can start post-training M3 for your own agentic workflows right away.
Branch: github.com/NVIDIA-NeMo/RL/tr…
Recipe: github.com/NVIDIA-NeMo/RL/bl…
2
2
22
1,882
Jun 12
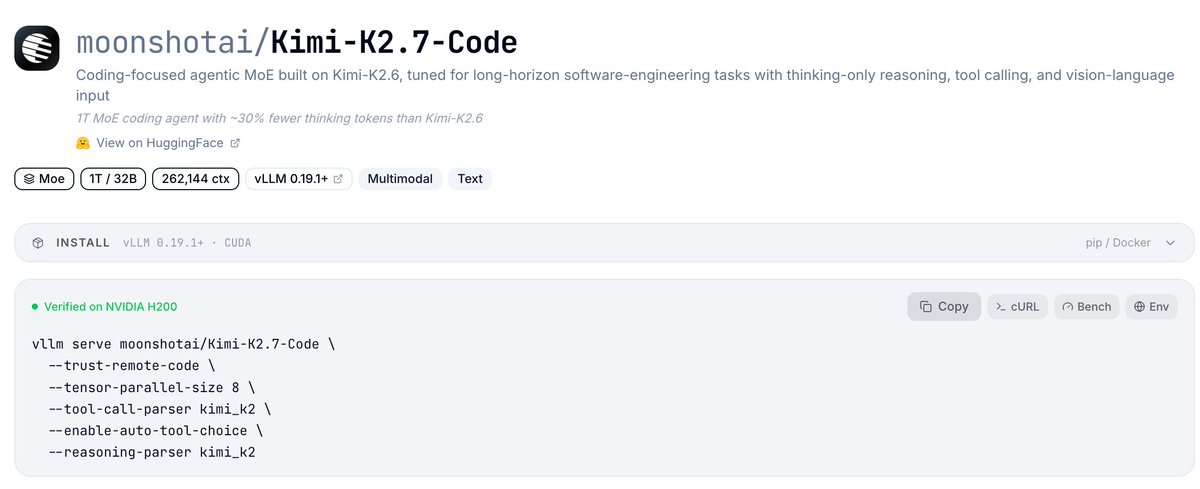
🎉 Congrats to @Kimi_Moonshot on Kimi K2.7-Code, a coding-focused agentic model built on K2.6.
✨ 1T-parameter Mixture-of-Experts, 32B active per token
✨ MLA attention with a 256K-token context window
✨ ~30% fewer thinking tokens than K2.6 for more efficient reasoning
Supported in vLLM, reusing the same deployment as K2.6.
🔗 recipes.vllm.ai/moonshotai/K…
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


18
45
848
58,436
Jun 12
thanks to @verdacloud for providing the compute to verify k2.7 on @NVIDIAAI 's GB300 and more!
1
2
11
2,320
Jun 10
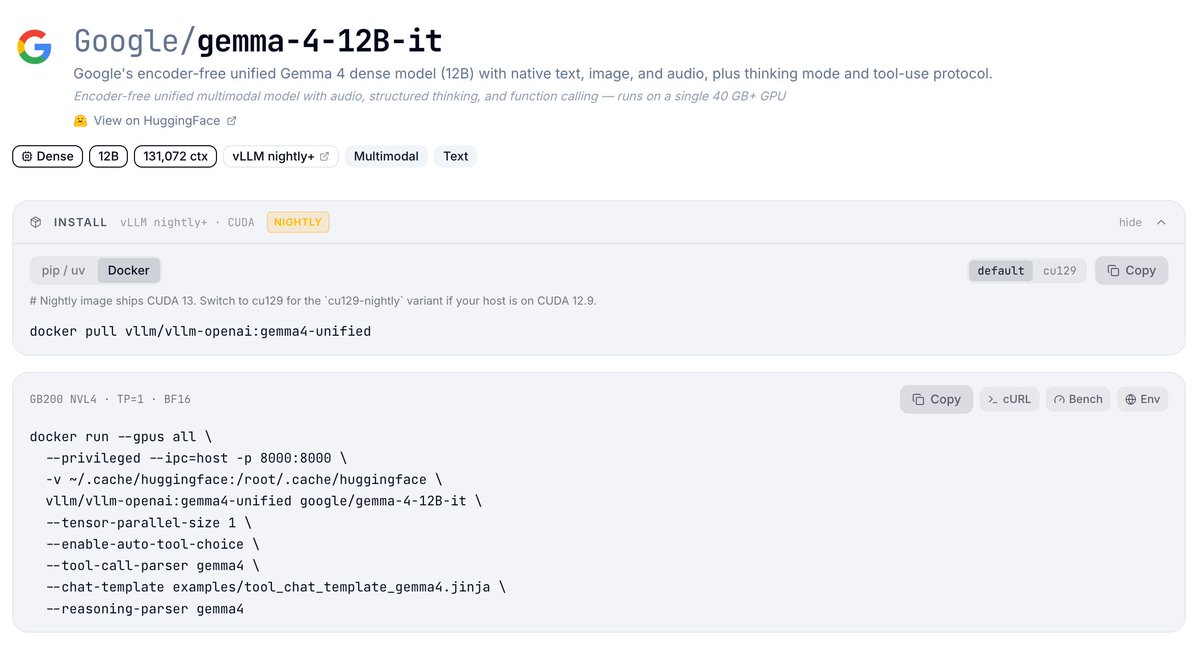
Congrats to @GoogleDeepMind on DiffusionGemma 🎉 A 26B diffusion language model on the Gemma4 backbone, and the first dLLM natively supported in vLLM.
It denoises 256-token blocks in parallel instead of generating one token at a time: 1200 output tok/s at batch size 1 on a single H200 (FP8).
Built on model runner v2's ModelState plus the existing speculative decoding path, with minimal scheduler or runner changes. FP8 and NVFP4 checkpoints are on the @RedHat_AI hub. Thanks to the @GoogleDeepMind, @RedHat_AI, and @NVIDIAAI teams!
🔗 vllm.ai/blog/2026-06-10-diff…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
14
50
519
39,022
Jun 10
🎉 Excited to see Inferoa from @agenticin.
It builds a community agent harness on the vLLM stack, with the agent loop shaped by inference economics: prefix-cache discipline, context optimization, and routing across self-hosted and frontier models.
Looking forward to seeing how developers extend it. 🚀

Introducing Inferoa: Inference-native Tokenmaxxing Agent Harness built for Loop Engineering.
Building around @vllm_project to run recursive long-horizon tasks with discipline, and context optimization via #codegraph #rtk etc.
Try it at @ProductHunt!
producthunt.com/products/inf…
4
5
58
9,361
Jun 9
🚀Day-0 support for @cohere's North Mini Code on vLLM!
Ready to serve with the latest vLLM stable release, this open-source coding model is built for agentic workflows:
🧩 30B total / 3B active — Mixture-of-Experts
📏 256K context, 64K max generation
🛠️ Reasoning, tool use, structured outputs
Try it out👇
huggingface.co/CohereLabs/No…

Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
5
12
106
10,495
vLLM retweeted

Jun 9
vime brings slime's proven training paradigm into the vLLM ecosystem, and we hope this gives the community another RL framework option alongside those vLLM already supports, to choose based on their needs!
Jun 9

Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
2
1
19
6,400
vLLM retweeted

Jun 8
vLLM-Omni’s trajectory has been incredible, so many models released with a vibrant community. Shaping up to be the ecosystem of choice for omni model serving!
Jun 8
🎉 Meet vLLM-Omni v0.22.0, a major upgrade for omnimodal world models and production-grade multimodal serving.
🌍 Day-0 @NVIDIAAI Cosmos 3 world models: text, image, audio, video, and action, in and out.
🤖 Robot serving: DreamZero OpenPI realtime API.
🎙️ Production TTS: Qwen3-TTS, Qwen3-Omni, VoxCPM2 and more.
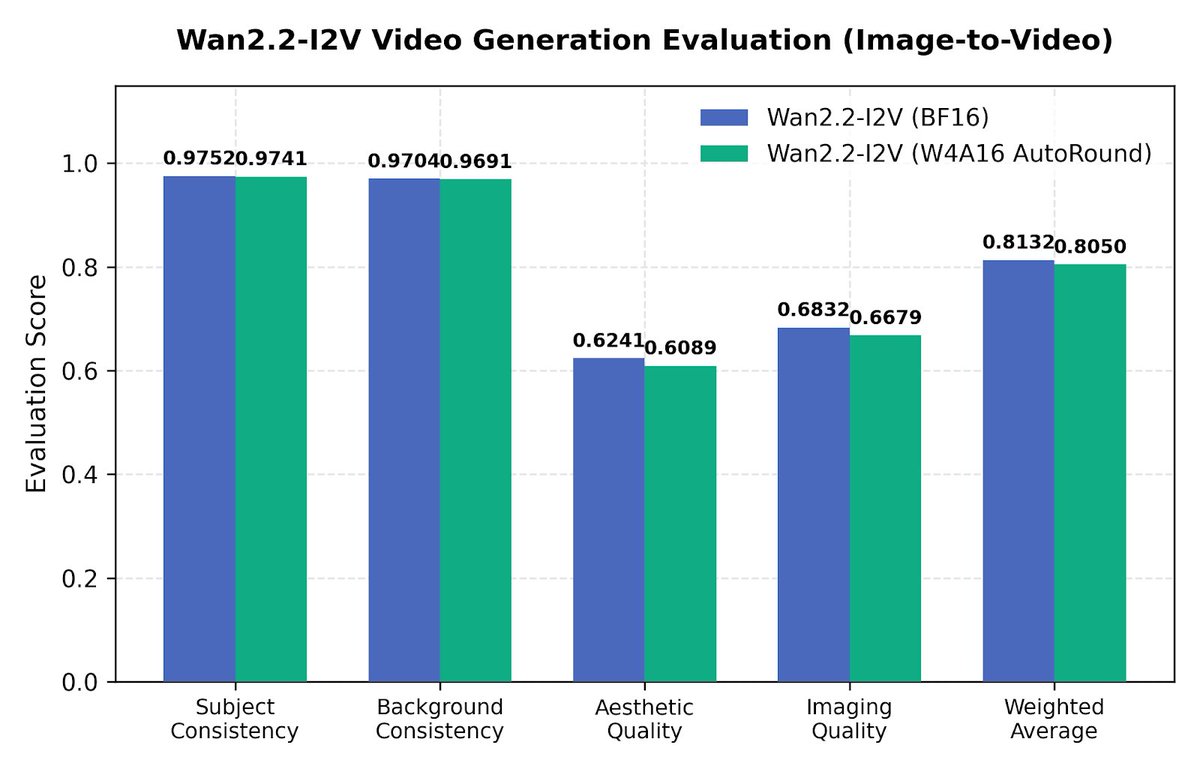
🎨 Faster image/video/diffusion: Wan 2.2, HunyuanVideo 1.5, LTX-2.3.
⚡ Broader quantization (FP8/INT8, MXFP4/MXFP8, W4A16, ModelOpt) and hardware coverage.
339 commits, 124 contributors, 52 of them new. Thank you all. 🙌
🔗 github.com/vllm-project/vllm…
3
32
5,239
vLLM retweeted
Jun 9
vime is a reference implementation for one reason only: make @vllm_project the best rollout engine for RL. This helps us better optimize vLLM for the whole ecosystem like @NovaSkyAI SkyRL, @PrimeIntellect Prime-RL, @nvidia NeMo-RL, @verl_project, and more!
A wise man in leather jacket said: "We don't build PowerPoint slides and ship the chips. We build a whole data center. And until we get the whole data center built up, how do you know the software works? how do you know your fabric works?" - @NoPriorsPod
Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
1
3
52
7,062
Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
8
54
509
42,244
Jun 8
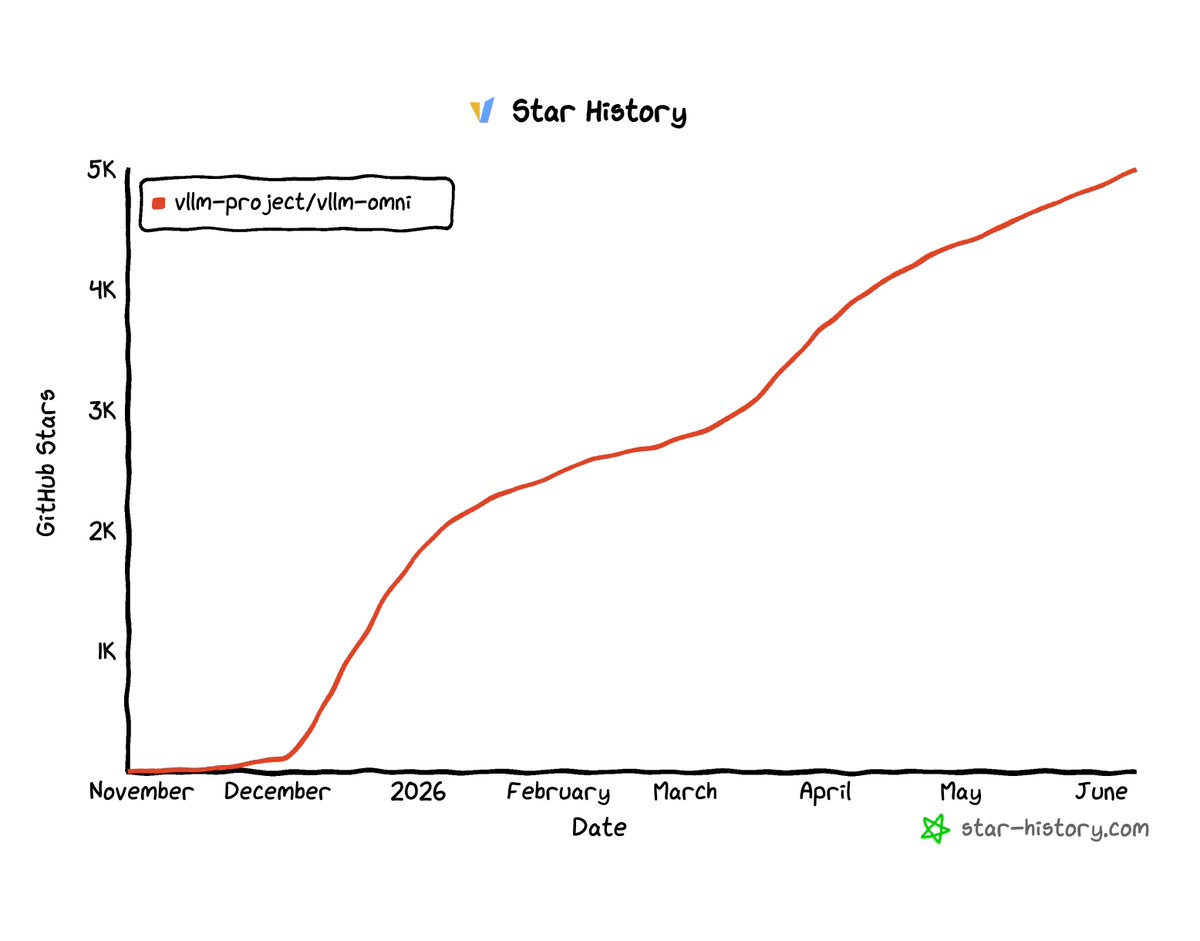
🚀 vLLM-Omni just hit 5K GitHub stars! 🎉
From a community kickoff in November to powering omni-modality inference everywhere: vLLM-Omni supports 30 models including Qwen3-Omni, HunyuanImage-3.0, Wan 2.2, BAGEL, MiMo-Audio, and Flux2, across NVIDIA, AMD, Huawei Ascend, Intel, and more.
Huge thanks to our amazing community, model partners, and everyone who's contributed a PR, filed an issue, or just given it a try.
Onto the next chapter of efficient, scalable, open multimodal inference.
⭐ github.com/vllm-project/vllm…
📚 docs.vllm.ai/projects/vllm-o…
#vLLM #vLLMOmni
9
17
147
9,544
Jun 8
Great example of #vLLM serving key agentic production workloads: persistent memory, reusable skills, and a built-in scheduler, deployed in under 10 minutes!
Jun 8

Most AI agents forget everything between conversations. Hermes Agent doesn't.
It creates reusable skills from completed tasks, persists user memory across sessions, and runs a built-in cron scheduler for autonomous workflows. Deployed on OpenShift AI with @vllm_project for GPU inference, under 10 minutes with oc apply.
Deployment manifests and UBI 9 Dockerfile: github.com/aicatalyst-team/h…
developers.redhat.com/articl…
4
5
58
8,726
Jun 8
🎉 Meet vLLM-Omni v0.22.0, a major upgrade for omnimodal world models and production-grade multimodal serving.
🌍 Day-0 @NVIDIAAI Cosmos 3 world models: text, image, audio, video, and action, in and out.
🤖 Robot serving: DreamZero OpenPI realtime API.
🎙️ Production TTS: Qwen3-TTS, Qwen3-Omni, VoxCPM2 and more.
🎨 Faster image/video/diffusion: Wan 2.2, HunyuanVideo 1.5, LTX-2.3.
⚡ Broader quantization (FP8/INT8, MXFP4/MXFP8, W4A16, ModelOpt) and hardware coverage.
339 commits, 124 contributors, 52 of them new. Thank you all. 🙌
🔗 github.com/vllm-project/vllm…
10
65
442
41,225