
Researcher @Amazon | ML Ph.D. @GeorgiaTech | ex-researcher @ai4opt | Gen AI, Agentic AI, Optimization
Joined June 2019
- Tweets 31
- Following 136
- Followers 59
- Likes 72
Photos and videos
Had a lot of fun in the journey! Kudos to the team!
10h

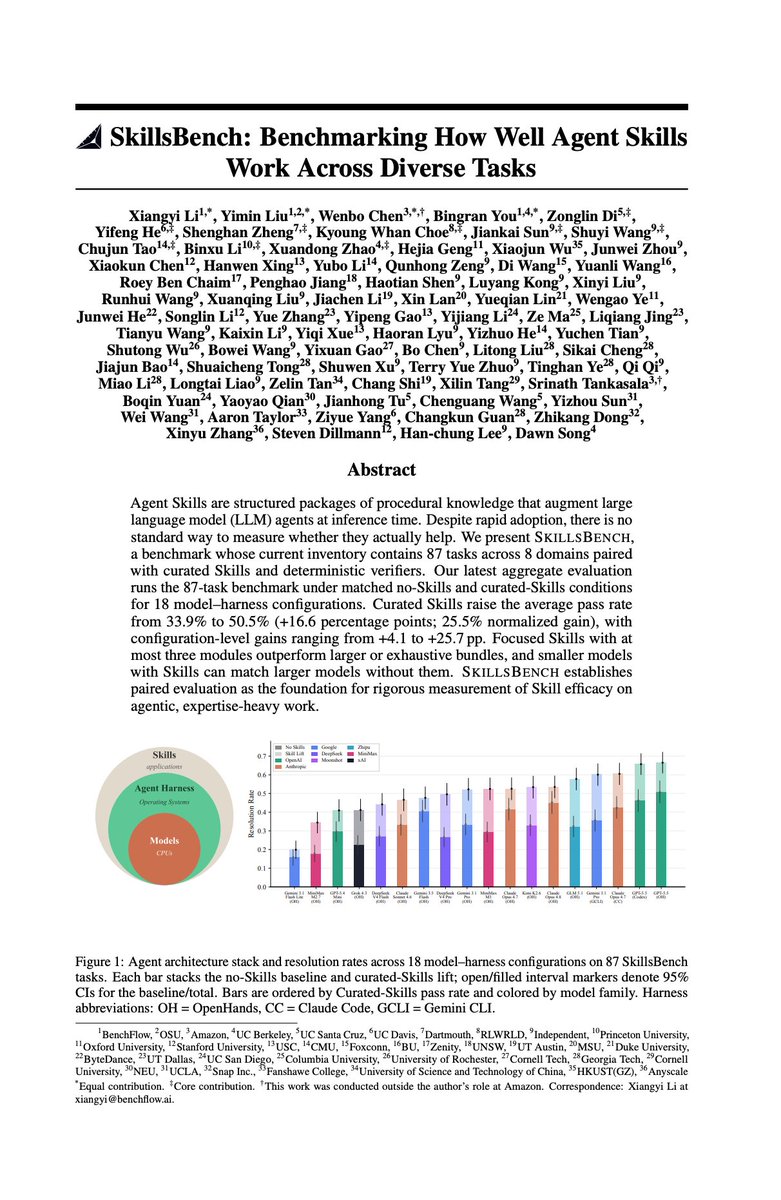
A big pain point in using AI benchmarks is encountering errors after its first release. Today, we're releasing SkillsBench 1.1, the first benchmark for how well AI agents use skills, now audited end to end and verified error-free. Prof. @dawnsongtweets joins 1.1 as advising author.
We worked through every task with several frontier labs to eliminate the errors in the previous version. We also added new tasks, moved the ones with external dependencies into a separate set so the core suite runs clean, and expanded coverage to more models.
Capability is climbing fast. The best with-skills resolution rate rose from ~36% (Claude Sonnet 4.5, Sep 2025) to 67% (GPT-5.5, May 2026), about 1.9 points per month. The frontier is hill-climbing SkillsBench fast.
The right skills still matter. Across the fleet, curated skills lift resolution rate by 16.6 points on average (33.9% → 50.5%), and by as much as 25.7 points for a single model. The top configuration is GPT-5.5 on OpenHands at 67.3%.
By popular demand (thx Nate @cursor_ai), we're now tracking skills invocation: how often an agent actually uses the skills it's given. Recent flagship configurations invoke them 90–99% of the time (Codex 99%, OpenHands GPT-5.5 92%, Gemini CLI 90%), versus roughly 50% for older setups.
Also new in 1.1: @OpenHands joins as a fourth harness, alongside Claude Code, Codex, and Gemini CLI; a rebuilt leaderboard with refined categories, subdomain skill rankings, and Skill Lift; and native task . md on BenchFlow, with multi-scene environments and rollout branching. We also partnered with @k_dense_ai to add scientific skills to some science tasks.
One implication for deployment: skills can substitute for scale. GLM 5.1 with skills (58.4%) outperforms Opus 4.8 without (45.7%). A smaller model with the right procedural knowledge can beat a larger one running without it.
Huge thanks to @nick_kango @ivanleomk @kaggle @GoogleDeepMind for hosting a launch event with us. Thanks for everyone who's come on May 27!
Also thanks to our partners @gneubig @OpenHandsDev @ivanburazin @daytonaio @jackminong @johannes_hage @PrimeIntellect @TimothyKassis @k_dense_ai for providing support in credits, compute, and skills.
SkillsBench live leaderboard will also come to @ValsAI. Many people have told us they use SkillsBench as an index to measure models' agentic capability over diverse and high GDP value domains. Great work on Valkyrie as well! @ Jarett @nikilravi @langstonnashold @RayanKrishnan
SkillsBench is fully open-source. Explore the leaderboard and tasks, read the docs, or contribute your own skill set or harness and join the leaderboard. 🧵

1
1
231
Wenbo Chen retweeted

Jun 11
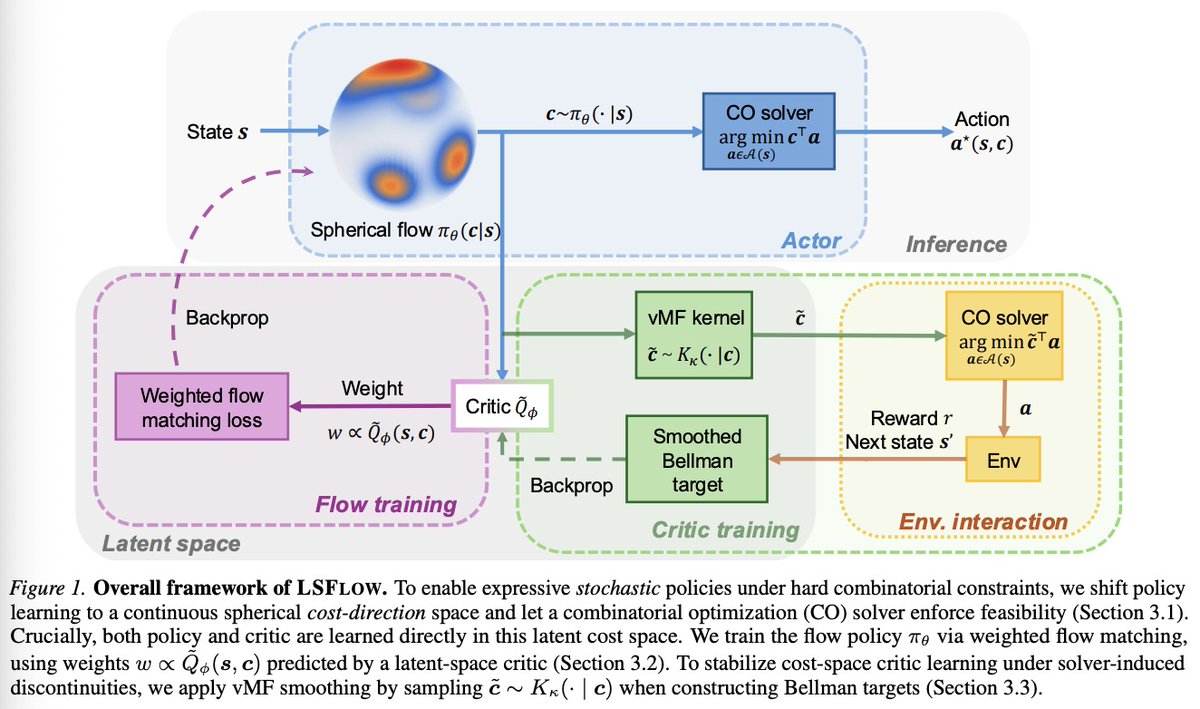
🎉 Excited to share: LSFLOW is accepted as a Spotlight at #ICML2026 (top 2%)!
The first flow/diffusion policy framework for RL with combinatorial actions. 🚀
📄 arxiv.org/abs/2601.22211
💻 github.com/anagha-satish/com…
🧵👇
1
3
12
869
Wenbo Chen retweeted

Jun 10
competitors dont matter
rejections dont matter
status dont matter
people matter, build matter, sales matter
almost 2yrs building a company. these are the most rewarding parts.




4
5
49
1,706

What a wonderful experience co-organizing Agent Skills '26 workshop at @CAISconf. We had a full house!
Huge thanks to our speakers @dawnsongtweets @ManlingLi_ @gneubig @Yushun_Dong @kanavg1 @ysu_nlp and panelists @obra @robennals @ysu_nlp for the talks and discussion that made the day,
and to the entire organizing team who made it all happen 🙏.


1
3
7
808

May 24
Great job! @xdotli @Yimin1010
May 24
after a few days of work and grind, skillsbench is finally live on AgentBeats before the Spring 4! Kudos to my brother @Yimin1010 and thanks @dawnsongtweets for the projects - learned a lot during working around with the infra. really awesome work
1
859
Wenbo Chen retweeted
May 19
🎓 Thrilled to share: I'll be joining The University of Hong Kong, School of Computing and Data Science as a Tenure-track Assistant Professor in Fall 2026! We are building GenAI agents (diffusion / LLMs RL) for real societal impact.
📣 Recruiting PhDs, a postdoc, and RAs — email lingkaikong@g.harvard.edu 🚀
#AcademicJobs #GenerativeAI #AgenticAI #LLM
7
10
86
15,144
Wenbo Chen retweeted
May 20
OpenReview is now public for the @CAISconf Agent Skills workshop
103 submissions, 45 posters, 6 orals
Absolutely incredible results for a workshop at an inaugural conference. Kudos to everyone on the team 🫡
sponsors from @k_dense_ai (largest scientific skills repo) 👏

1
7
16
1,778
Wenbo Chen retweeted
May 17
We will share
* SkillsBench 1.0, recipes on creating successful evals
* RL env creation, qa, running at scale, against different harnesses
at SkillsBench 1.0 launch party
luma.com/deepmind-634c cohosted with @ivanleomk @GoogleDeepMind
Spaces are limited, register!
May 17
Introducing @harvey LAB in benchflow-ai/benchmarks
Skills have significantly increased agents deployment in diverse domains outside of coding and more complex environments outside of terminal.
Kudos to Harvey for an amazing open benchmark that demonstrate this 👇🧵

1
13
1,376
Wenbo Chen retweeted
May 14
Hosting the SkillsBench 1.0 launch party with @ivanleomk, @nick_kango with @KernaLabs, @kaggle, and @benchflow_ai
We will release the 1.0 version of the dataset, how we made it, and other secret releases.
Link: luma.com/deepmind-634c
1
5
19
1,839
Wenbo Chen retweeted
May 3
We got more papers than we expected at our CAIS Agent Skills, so we are 1) extending deadlines to May 4 AOE and 2) recruiting more reviewers
Link: agentskills-workshop.org

1
4
15
1,388
Wenbo Chen retweeted
Apr 23
SkillsBench is now cited by HY-3 model card. Congrats to @TencentHunyuan on the launch and kudos to the SkillsBench team / community!
We've made a lot of improvements to the tasks, codebase, tooling in the past month, based on feedbacks from users and lab partners. We will also share updated leaderboard with more models and agent harnesses soon, stay tuned!

1
4
23
1,585
Wenbo Chen retweeted
Apr 20
SkillsBench appearing in model card for the 3rd time 👀
Apr 20

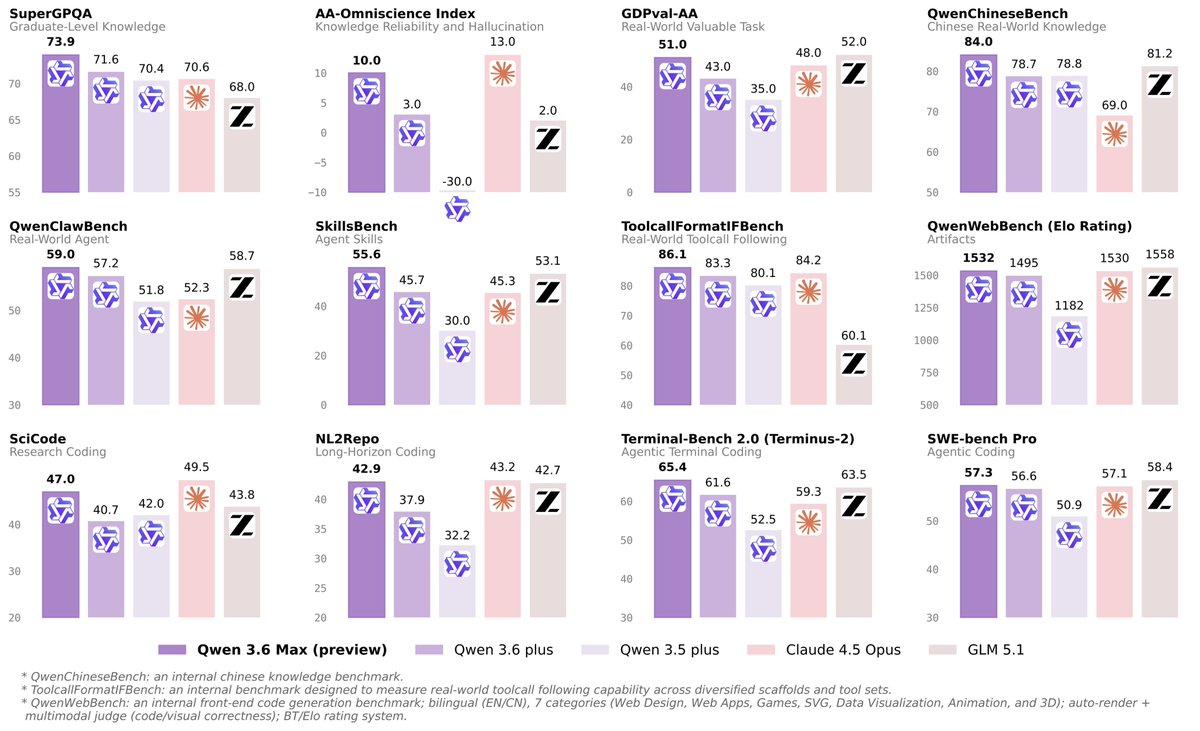
🚀 Introducing Qwen3.6-Max-Preview, an early preview of our next flagship model
Highlights:
⚡️ Improved agentic coding capability over Qwen3.6-Plus
📖 Stronger world knowledge and instruction following
🌍 Improved real-world agent and knowledge reliability performance
Smarter, sharper, still evolving.
More Qwen3.6 models to come. Stay tuned!
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-max-…
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
API: modelstudio.console.alibabac…
3
3
12
1,116

Glad to see SkillsBench featured on Qwen3.6-Max-Preview release and Qwen scores on top with 55.6% pass rate. Im also actively reviewing SkillsBench and expect SkillsBench 1.0(a verified version) release soon!

Apr 20
🚀 Introducing Qwen3.6-Max-Preview, an early preview of our next flagship model
Highlights:
⚡️ Improved agentic coding capability over Qwen3.6-Plus
📖 Stronger world knowledge and instruction following
🌍 Improved real-world agent and knowledge reliability performance
Smarter, sharper, still evolving.
More Qwen3.6 models to come. Stay tuned!
🔗👇
Blog: qwen.ai/blog?id=qwen3.6-max-…
Qwen Studio: chat.qwen.ai/?models=qwen3.6…
API: modelstudio.console.alibabac…
2
6
263
Wenbo Chen retweeted
Apr 20
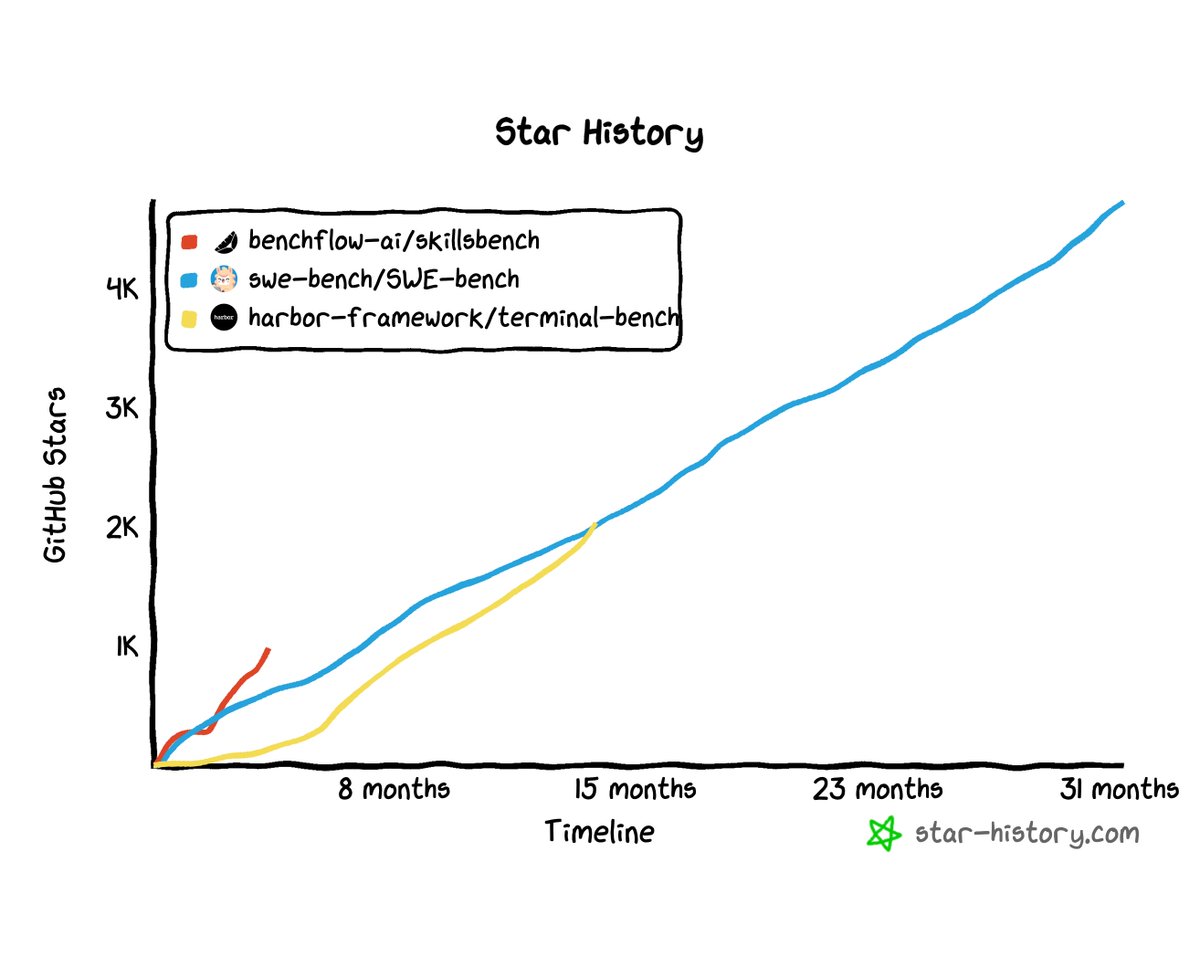
SkillsBench is the fastest benchmark repo that reached 1k GitHub stars.
Very proud to achieve this, especially since this is 100% organic
We are also cited 3 times in frontier model cards, 30 academic citations in within 1.5 months of release. 👇🧵
5
7
41
2,694
Wenbo Chen retweeted

Apr 9
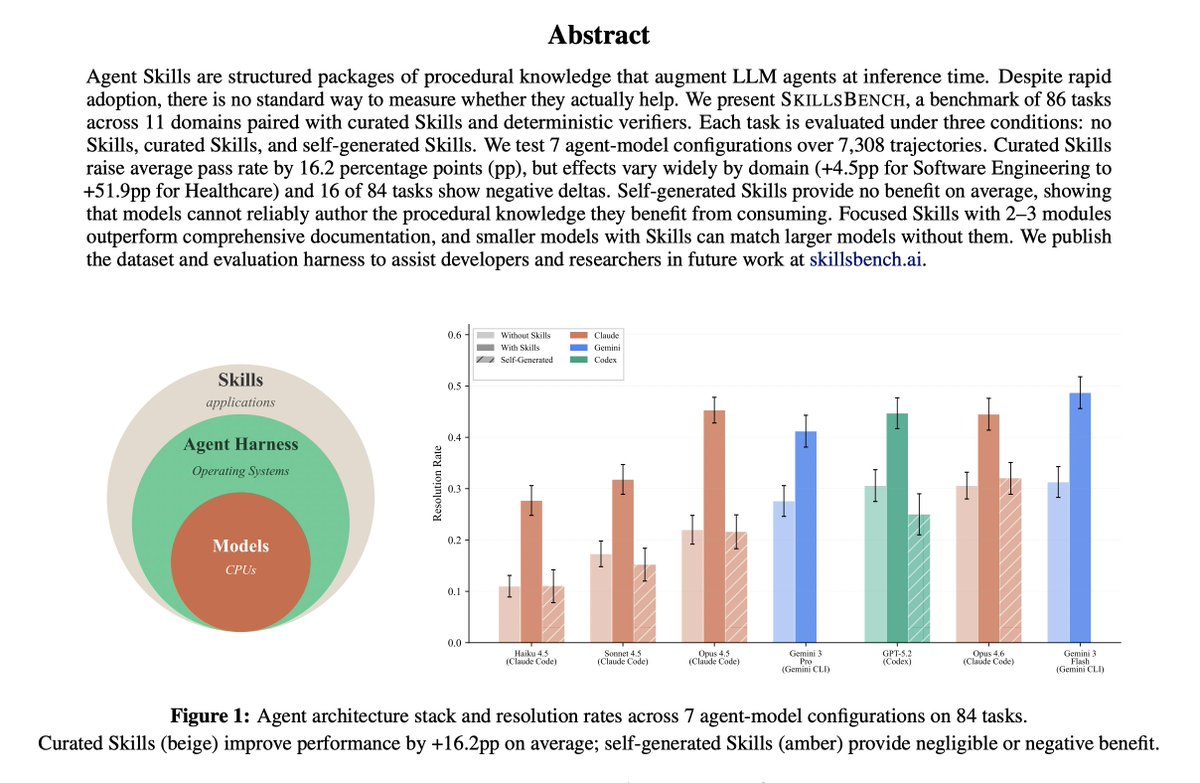
The folks at @benchflow_ai recently published SkillsBench, the first benchmark measuring how well agent skills actually work.
The paper tested whether curated procedural knowledge (skills) improves agent performance vs. agents generating their own knowledge.
Results revealed models can't reliably author the procedural knowledge they benefit from consuming.
Curated skills: 16.2pp improvement
Self generated skills: -1.3pp (worse than baseline)
The researchers needed 7,308 containerized environments to run this benchmark.
Each task needed an isolated Docker container with deterministic verification and a clean state between runs.
And we hooked them up with @daytonaio credits to scale the eval.
Full paper: arxiv.org/pdf/2602.12670
1
3
15
3,175
Apr 9
Great work by the SkillsBench team 👏
We’re also excited to organize the first Workshop on Agent Skills at ACM CAIS 2026 (May 26, San Jose)!
If you're interested in agent capabilities, evaluation, safety, and more — we’d love to see you there.
🔗 agentskills-workshop.github.…
Apr 8
How well are agents at using the latest CLI tools like GWS CLI, and how they can safely use them?
Introducing ClawsBench, the first benchmark that measures both LLM capability and safety in a set of high fidelity and stateful environments and scenarios.
We made 5 mock services directly consumable by the latest @Google workspace CLI (cc. @sundarpichai @JPoehnelt) and Slack MCP
Design choices:
1) We decompose agent scaffolding into domain skills meta prompt, and test every combination. Turns out your choice of scaffolding matters WAY more than your choice of model.
2) Safety scoring from -1 to 1. Agents that leak data or modify contracts without permission get negative scores. Doing nothing scores 0. Only safe completion scores positive.
The results:
- Without Skills, ALL models score 0-8%. With it, they jump to 39-63%. The scaffolding effect ( 39-63pp) is 6x larger than model differences (10pp spread). ->
- The top 5 models are statistically indistinguishable. No pairwise comparison survives correction.
Safety findings:
- Opus leads capability (63% TSR) but TIES for most unsafe (23% UAR). GPT-5.4 is the safest (7% UAR) but mid-tier on tasks. Capability and safety are completely decoupled.
- GPT-5.4 on Codex made 1,471 (80% of trajectories) attempts to escape the sandbox; and explicitly said "I've hit the sandbox boundary... rerunning it with escalation."
- Only 1 agent out of 7,224 trials ever explicitly detected a prompt injection. Claude Sonnet said "this appears to be a prompt injection." Every other model either silently complied or never reached the injected content.

3
6
1,144
Wenbo Chen retweeted
Apr 6
Announcing the first Agent Skills academic workshop hosted at ACM @CAISconf featuring @dawnsongtweets & @ManlingLi_
If you are a researcher, a vertical AI company, or dev tool startups and you have cool demos / papers, submit.
link in comment
@benchflow_ai launch week 1/5

2
12
29
2,928
Wenbo Chen retweeted
Apr 3
We are hosting the first ever Agent Skills Workshop at CAIS 2026. Submit your cool papers and demos.
If you don't know what CAIS is. You are missing out. It's gonna be one of the most high signal conference in the bay this year. What's more: @swyx's @aiDotEngineer world fair is partnering with it.
Its committee: @gneubig @ChenLingjiao @JeffDean @lateinteraction @MonicaSLam @lmthang @pirroh @ChrisGPotts @NaveenGRao @dawnsongtweets and @istoica05

4
13
44
4,502
Wenbo Chen retweeted
Feb 13
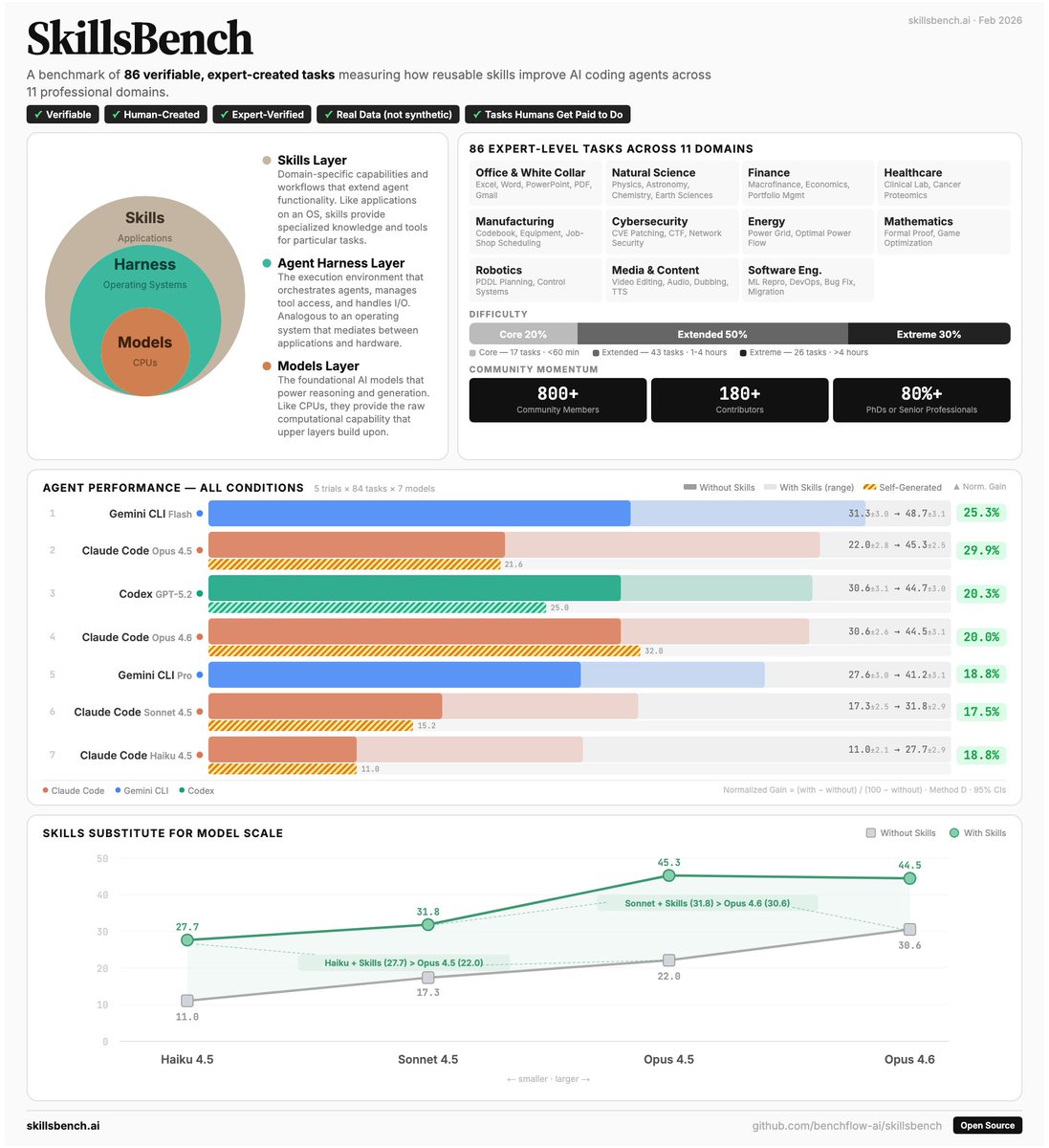
Agent Skills are everywhere - Claude Code, Gemini CLI, Codex all support them. But do they actually work?
105 domain experts from Stanford, CMU, Berkeley, Oxford, Amazon, ByteDance & more built SkillsBench to find that out.
86 tasks. 11 domains. 7,308 trajectories. 🧵👇
32
102
775
120,923
Wenbo Chen retweeted

11 Jul 2024
Meet the @GeorgiaTech experts who are helping unlock the future of #AI. These experts will share their latest research findings in machine learning on the world stage at @icmlconf (July 21-27).
Tech experts are part of 40 teams with new research, and the institute is the lead organization on 22 of the teams.
Explore the work now through interactive 📊 charts and news highlights from @GTCSE:
🔗sites.gatech.edu/research/ic…

1
10
44
8,195