
Joined October 2010
- Tweets 5,367
- Following 4,660
- Followers 2,643
- Likes 4,820
990 Photos and videos













Pinned Tweet

May 28
May 28

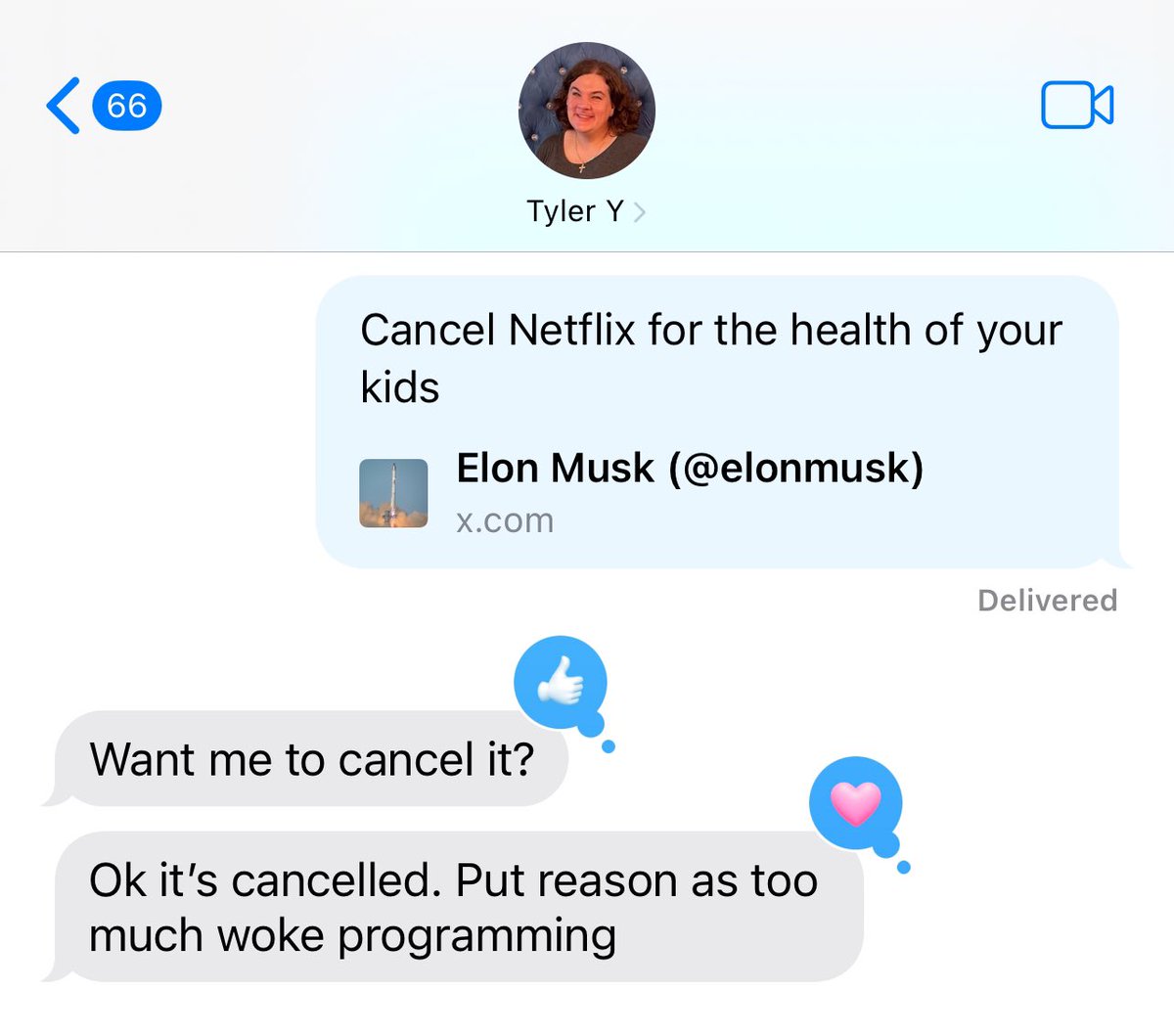
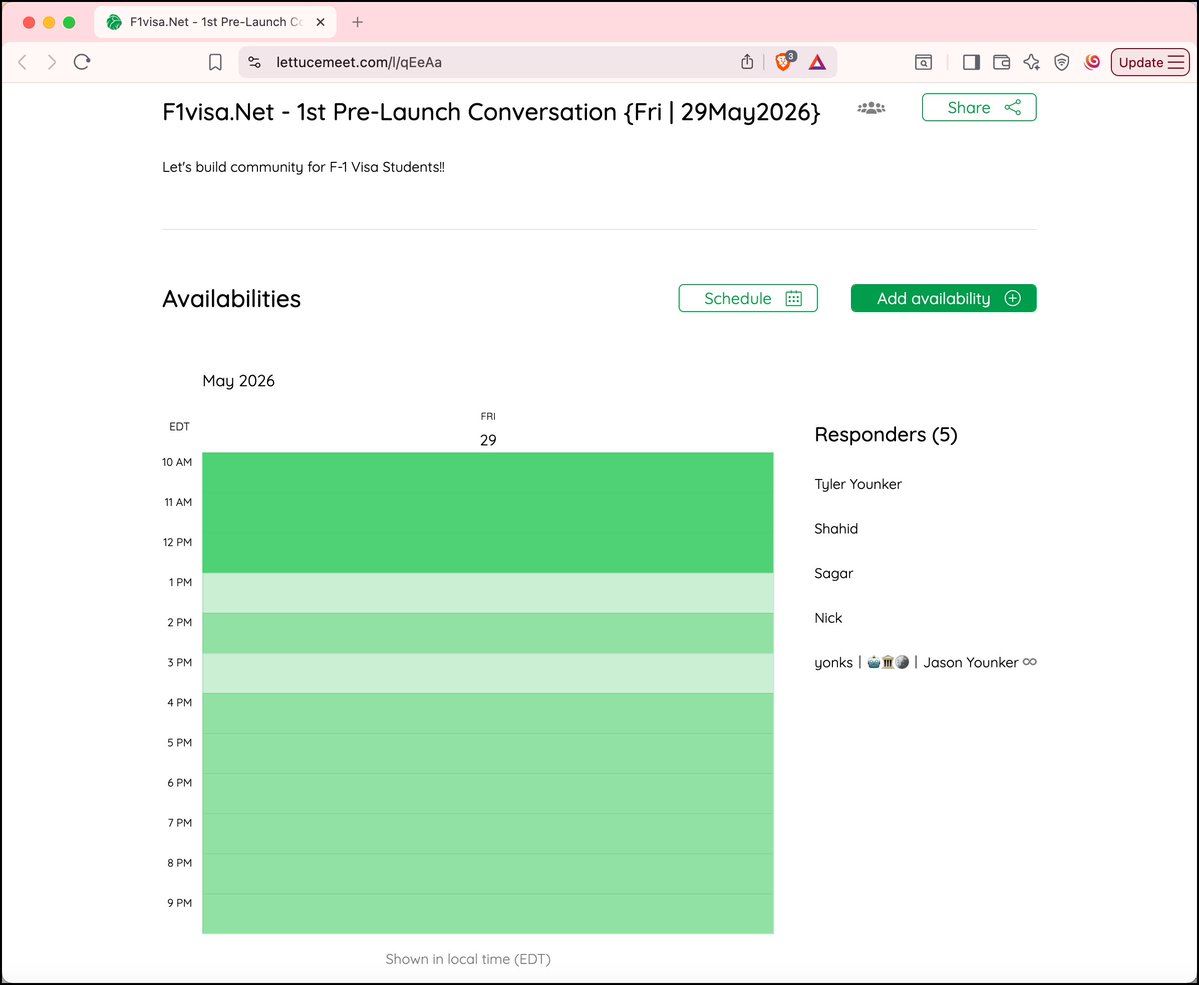
🚨 @F1visaNet pre-launch starts TOMORROW!! 🛂🇺🇸
June = peak #F1visa season. We're building the solution.
Join the conversation!! Add your availability 👇
lettucemeet.com/l/qEeAa
#F1Visa #InternationalStudents #EdTech #SpeedToMarket 🚀
2
62
yonks|🤖🏛️🪙|Jason Younker retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
345
438
4,221
457,151
yonks|🤖🏛️🪙|Jason Younker retweeted

Jun 13
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
2,202
3,240
25,445
7,776,541
yonks|🤖🏛️🪙|Jason Younker retweeted

Jun 13
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
12,598
25,780
88,104
90,185,240
yonks|🤖🏛️🪙|Jason Younker retweeted

Jun 9
Claude Code's creator said something that stopped me cold:
"I don't prompt Claude anymore. I write loops — and the loops do the work. My job is to write loops."
Most developers are still crafting the perfect prompt.
The person who built the tool moved past prompting entirely.
In 30 minutes Boris reveals his actual daily Claude Code setup.
Claude Code loops dynamic workflows.
Worth more than any $500 vibe-coding course.
Watch it.
Then read this - everything you need to know about loops to actually apply what he says ↓
Bookmark both. This is your weekend.

128
550
4,520
1,778,078

Someone built an AI agent that searches Reddit, X, YouTube, HN, TikTok, Polymarket, and the web in parallel.
Scores everything by real upvotes, real likes, and real money.
Synthesizes it into one brief. In seconds.
It's called /last30days. 28,700 stars on GitHub.
You type one command. The agent fans out across every platform at once. Reddit threads. X posts. YouTube transcripts. Polymarket odds backed by actual money. HN comments. GitHub commits. It scores each source by what real people engaged with. An AI judge synthesizes the whole thing into one grounded summary of the last 30 days.
Here's what it does:
→ Searches Reddit for top upvoted threads and comments on any topic, person, or company.
→ Pulls X posts and scores them by likes and recency. Not algorithmic feed. Raw signal.
→ Transcribes and searches YouTube videos. Finds what was actually said, not just the title.
→ Reads TikTok engagement. Surfaces what creators and communities are actually talking about.
→ Queries Polymarket odds. Real money bet by real people on what happens next.
→ Searches Hacker News. The technical community's unfiltered take.
→ Searches GitHub commits and PRs. What someone is actually shipping right now.
→ Runs all sources in parallel. Scores them against each other by engagement weight.
→ AI agent judge synthesizes everything into one brief. No raw dump. A grounded summary.
→ Zero config to start. Reddit, HN, Polymarket, and GitHub work immediately.
→ One setup wizard unlocks X, YouTube, TikTok, and more in 30 seconds.
→ Installs into Claude Code, Codex, Cursor, Copilot, Gemini CLI, and 50 agent hosts.
Here's the wildest part:
Google doesn't touch Reddit comments or X posts. ChatGPT has a Reddit deal but can't search X or TikTok. Gemini has YouTube but not Reddit. Claude has none of them natively. Every platform is a walled garden with its own API, its own tokens, its own auth.
No single AI has access to all of it. Until you bring your own keys and bridge them with an agent.
That's the unlock. Not one better search engine. A dozen disconnected platforms, scored against each other by what real people actually engaged with and bet real money on.
Google aggregates editors. /last30days searches people.
Perplexity Pro: $20/month. $240/year.
ChatGPT Plus: $20/month. $240/year.
You(dot)com Pro: $15/month. $180/year.
/last30days: $0. Unlimited queries. Unlimited topics. Your API keys. Your agent. Forever.
28,700 stars. 2,431 forks. MIT licensed.
MIT licensed. Self-hosted. Open protocol. Free forever.
100% Open Source.
Github repo: github.com/mvanhorn/last30da…

83
247
2,276
151,520
yonks|🤖🏛️🪙|Jason Younker retweeted

The AI supercycle is in year 3 of 15. You didn't miss it.
You'd make millions by knowing whats coming and buying dips until 2030
Pay attention, we just finished Phase 1 2023-2025
chips · memory · connectivity
$NVDA → Designs the GPUs every AI model trains and runs on.
$MU → Makes high-bandwidth memory inside every AI server.
$COHR → Moves data at light speed between GPUs optically.
$MRVL → Custom silicon connecting every chip in a hyperscaler's cluster.
$AVGO → Builds Google's, Meta's, and Apple's custom AI chips quietly.
$AMD → Only credible GPU rival to NVDA for AI training.
PHASE 2 — The grid gets built (2026–2027)
power · cooling · networking
$IREN → AI-native data centers built to scale compute and power.
$WULF → Energy-efficient infrastructure hosting the world's most power-hungry AI workloads.
$VRT → Cooling and power systems keeping AI data centers running.
$ETN → Electrical gear powering every hyperscale AI facility being built.
$CEG → Nuclear energy feeding AI's insatiable around-the-clock power demands.
$ANET → High-speed switches moving massive AI workloads across GPU networks.
$GEV → Gas turbines physically delivering power to data centers.
$SMCI → Liquid-cooled GPU server racks — pick-and-shovel for AI density.
PHASE 3 — The massive bottleneck (2027–2029)
materials · space · autonomy
$MP → Mines rare earth materials used in AI hardware and defense.
$USAR → Domestic minerals securing U.S. AI manufacturing independence.
$ASTS → Satellites delivering AI connectivity to every corner of Earth.
$RKLB → Low-cost rockets launching satellites powering AI communication networks.
$KTOS → AI-driven autonomous weapons systems entering mass military deployment now.
$TSLA → Leads real-world AI through robotics, autonomy, and manufacturing.
$SYM → AI-powered warehouse robots automating global logistics at scale.
$ALAB → Chip packaging bottleneck — critical past 100K GPU nodes.
$PLTR → Software turning AI compute into defense and enterprise decisions.
PHASE 4 — Full automation (2030 )
platforms · agents · quantum
$MSFT → Deploys AI agents across every enterprise software product it sells.
$GOOGL → Controls AI search, cloud, and consumer distribution globally.
$META → AI assistants across 3 billion users in social and commerce.
$CRM → AI agents inside enterprise sales — 150K customer moat.
$NOW → AI workflow OS for Fortune 500 enterprises.
Quantum
$IONQ $RGTI $QUBT — next-gen compute unlocking exponential AI breakthroughs.
♻️ RESHARE this post and make 1 comment, I'll share when to add these stocks in June.

118
284
1,148
82,734

Starcloud just became the fastest YC company ever to a $1B valuation after Demo Day. 17 months. Building data centers in orbit.
The hardest possible problem, the fastest possible ascent. This is what we should be building.

78
84
1,114
118,829
May 29
Best in your future journeys!!
We are excited for implementing x402 within our ecosystem!! Thanks for your contributions on this!!
May 28
Update: I’ve left Coinbase. I’m starting a company.
I’ll continue to be involved with x402 as a member of the Technical Steering Committee with the foundation, and as an advisor to Coinbase on agentic commerce.
I’m incredibly proud of the work we’ve done in @CoinbaseDev. It's truly an elite team executing at the highest of levels. Many exciting things coming soon 👀. @yugacohler will be taking the helm as Head of Engineering, he’s a rockstar, he’ll crush it.
It's been an exceptional second tour of duty at Coinbase. It was a hard decision to leave, but there's an idea in my head I need to get into the world.
Big thank you to @barmstrong, @emiliemc and @nemild for bringing me back, and to @alecglovett, @yuga @brian__foster and everyone else in CDP - it's been an honour.
2
8
49



yonks|🤖🏛️🪙|Jason Younker retweeted

May 28
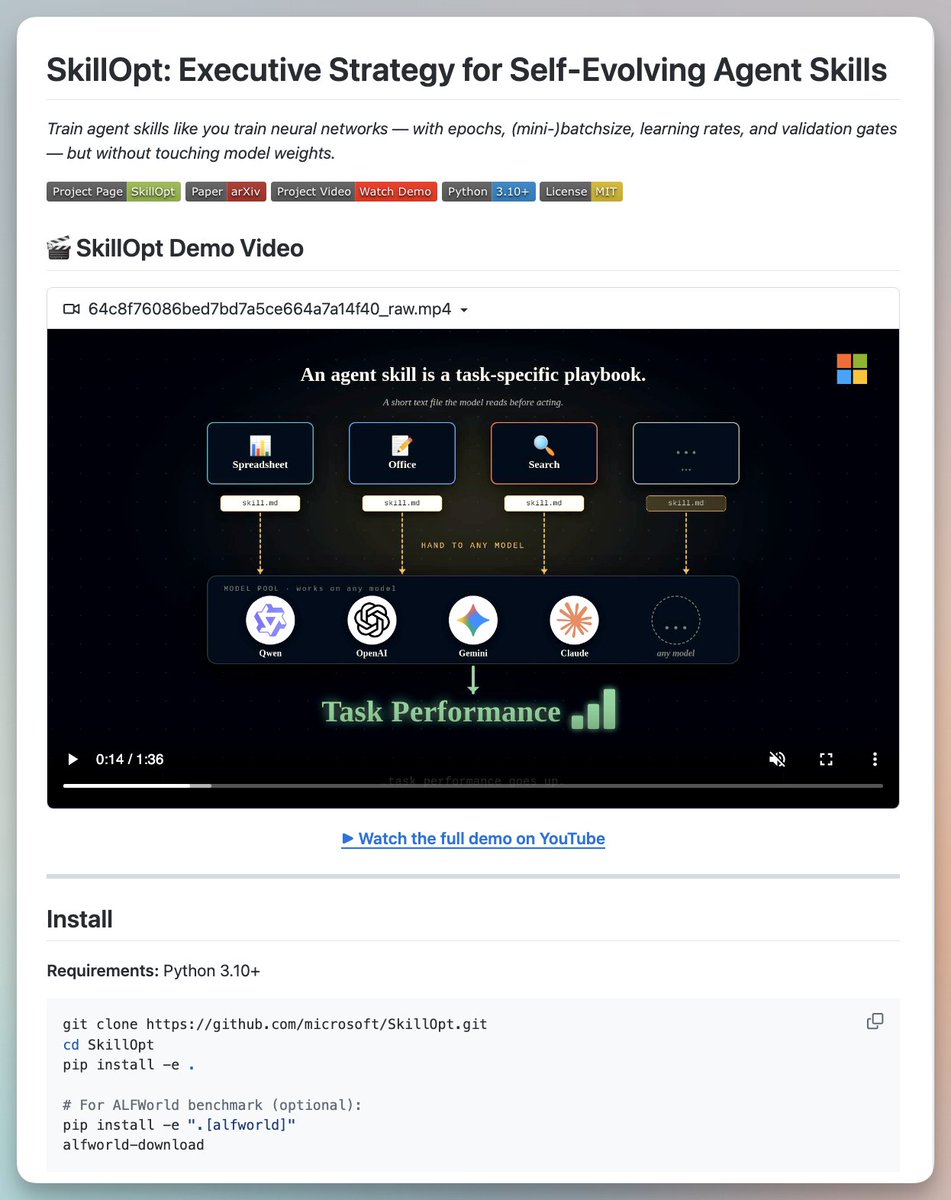
Microsoft just open-sourced SkillOpt!
A framework for training agent skills like neural networks:
SkillOpt treats a plain markdown file as the trainable parameter of a frozen LLM agent, applying the same optimization discipline used in weight training: learning rates, validation gates, batch sizes, and epoch schedules.
The analogy maps precisely. The skill document is the parameter. Trajectory-derived edits are the gradient direction. An edit budget is the learning rate. A held-out split is the validation check.
Here's how it works.
A frozen model runs tasks with the current skill and produces scored trajectories. A separate optimizer model analyzes failures in minibatches, proposes structured add/delete/replace edits, and ranks them under a budget cap.
If the candidate skill improves performance on a held-out split, the edit is accepted. If not, it's rejected and stored so the optimizer avoids repeating failed changes.
The deployed output is a single best_skill. md file, typically 300 to 2,000 tokens. No weight changes, no extra inference-time calls.
The learned rules are compact and readable. These read like rules a thoughtful engineer would write after a day with the benchmark, except they were discovered automatically.
Learn more:
Paper: arxiv.org/abs/2605.23904
GitHub: github.com/microsoft/SkillOp…
SkillOpt isn't the first system to treat skills as something you can optimize.
Hermes Agent independently built the same idea through a combination of skill_manage, Curator, and an optimization loop called GEPA that scores, mutates, and promotes skill documents across runs.
Two teams, different architectures, same conclusion: the skill file is the highest-leverage thing to optimize in a frozen-model agent.
I wrote a deep dive on how the Hermes agent works and covered all of these topics briefly.
The article is quoted below.

39
193
1,262
149,591

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
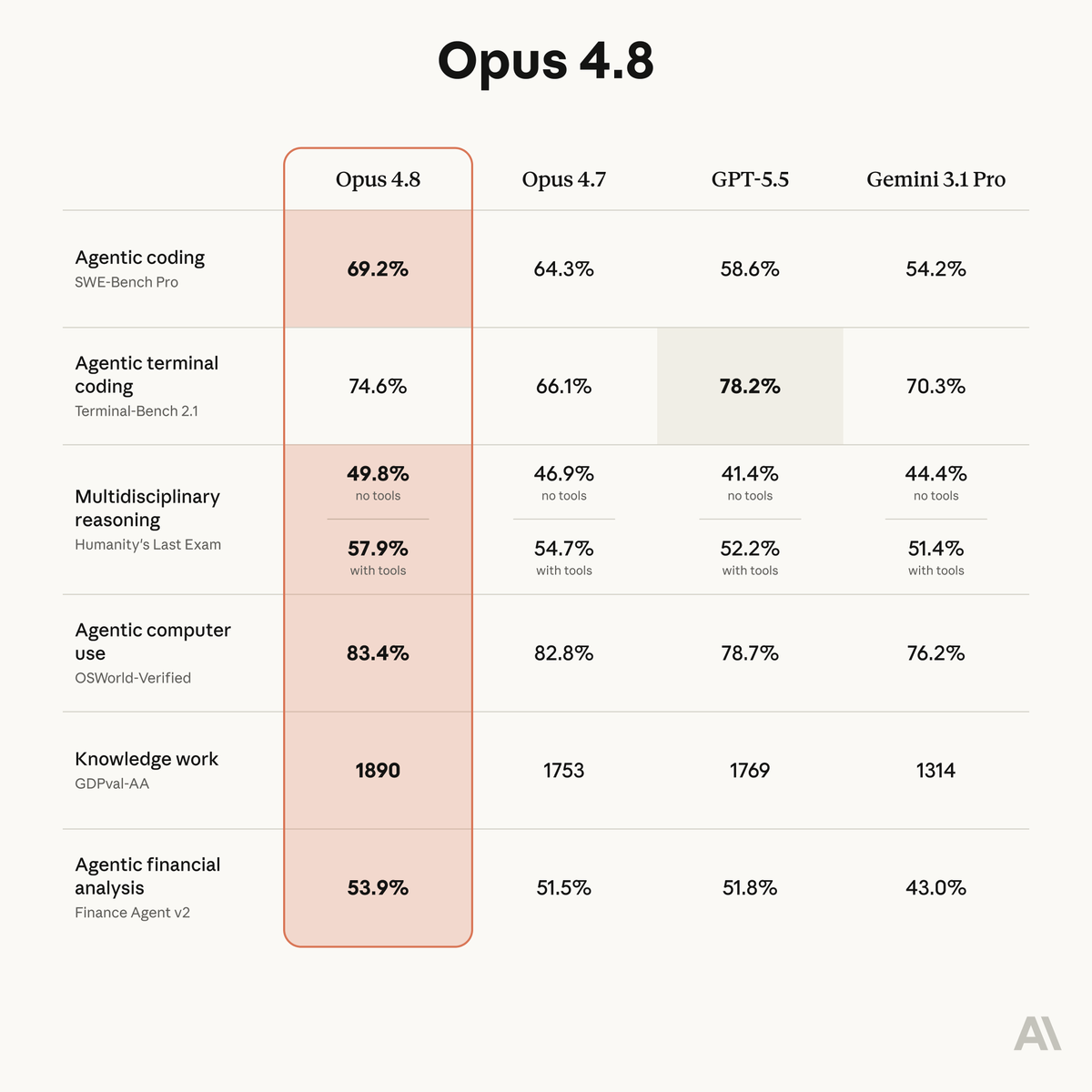
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
3,686
8,624
67,444
15,252,050
yonks|🤖🏛️🪙|Jason Younker retweeted

May 27
Your agent now has a wallet, with Base MCP.
Link to get started below

Introducing Base MCP
Your agent's new gateway to Base
→ Connect an agent to your Base Account
→ Enable it to swap, trade, and manage your portfolio
→ Use plugins from leading apps on Base
The next stage of the agentic onchain economy
213
160
1,383
199,291
yonks|🤖🏛️🪙|Jason Younker retweeted

May 26
Met my girlfriend's parents for the first time.
Her dad asked what I do for work. I said I build trading systems.
He said: "Like Wall Street?"
I said no. It's open-source. Anyone can see how it works.
He laughed. "So you're gambling with open-source code?"
I didn't argue. I opened my laptop.
One wallet I was tracking made $2.4M in March alone. Another traded $36M in volume. One more turned $35K into $442K.
His face changed.
"That's not gambling. That's... math?"
Exactly.
Then I showed him the repos. All public. All free.
First one: github.com/warproxxx/poly_da…
Every trade ever made. 86M trades. Free to download. Snapshot saves 2 days of research.
Second one: github.com/warproxxx/poly-ma…
Market making bot. Both sides of the book. Gas optimized. Google Sheets execution layer.
Third one: github.com/pselamy/insider-t…
ML heuristics. Flagged that $35K → $442K wallet before anyone noticed.
Her dad went quiet. Then he asked: "Can my son run this?"
Her mom asked for the channel link.
Profile: polymarket.com/@xuanxuan008?…
Most people think you need a finance degree or a hedge fund.
You don't. You just need to read the code and start.

36
126
851
176,624
May 26
Amazing insights Greg!! Thanks for sharing!!
May 26

I just got back from SF and I FEEL INSPIRED.
I spent 5 days with frontier AI model teams, AI startup founders, and 3 billionaires.
My takeaways:
1. I had lunch with 3 billionaires. All of them are buying SaaS companies and rebuilding them agent-first. They were deeply inspired by Bending Spoons and Ryan Cohen's eBay deal. Buy the company, cut the headcount, rebuild the tech, add agents, add features, make more valuable experience, raise prices.
2. The frontier model companies are hungry for usage data from the field. They can see API calls and token counts. They can't see the actual workflows. If you're deep in a niche using these models in ways the model companies haven't seen, that understanding is incredibly valuable. Usage intelligence is the new alpha.
3. Consumer AI is massively underbuilt. Every billboard in SF is either B2B inference infrastructure or vertical agent companies. The entire city is optimized for enterprise. Meanwhile you have companies like Cal AI doing $50M ARR in 18 months as a consumer app. I met with a cool few teams doing consumer AI (@paulscherer / @ekuyda)
4. MCP came up in literally every conversation. The companies exposing their product as MCP endpoints are getting pulled into deals they never pitched for. The ones that aren't are becoming invisible to agents. This is the new SEO. If agents can't find you, you don't exist. Building products for agents is the new zeitgeist in general.
5. Not uncommon for hot seed rounds to be $25-50 million valuations. I saw a Series A at $450 million
6. If I had a dollar every time someone mentioned "forward-deployed engineer" this trip I could have funded a seed round. It's the hottest role in SF right now. The person who sits between the agent and the customer, making sure everything actually works.
7. The mood around open source shifted. A year ago it felt like open source was chasing the frontier models. Now founders are telling me Gemma and DeepSeek are good enough for 80% of what they need at a fraction of the cost. The "which model do you use" conversation is being replaced by "which model for which task." Model loyalty kinda feels dead.
8. Voice agents came up more than I expected. Multiple founders told me voice is the interface for the next billion users. The billion people who will never type a prompt will absolutely talk to one.
9. The Obsidian community in SF is weirdly intense. Multiple founders showed me their vaults unprompted. Like showing someone your home gym. It's a flex now. The quality of your knowledge base (second brain?) is becoming a status symbol among builders.
10. Maybe it was just the people I met but the age of the founders is shifting. I met more founders over 40 this trip than any trip before and more founders under age 21 than ever before. Founders getting older and younger at the same time.
11. I spoke to a lot of fast-growing startups, VCs and frontier models who are hiring content creators right now.
12. The restaurant scene in SF is actually better than it's been in years. Founders are going out more. Alcohol is out, not surprisingly.
13. SF doesn't feel like the only place anymore. We all have access to the same frontier models. We all read the same X feed. A founder in NYC or Lagos is calling the same APIs as a founder in SoMa. So in the past it felt like SF was always lightyears ahead, doesn't feel that way anymore. It's okay not to live in SF and have BIG DREAMS.
14. The coworking spaces in SF are half empty but the coffee shops are packed. People want to be around people. I had a few startup ideas here....
15. Walking around the Mission I noticed something: the street-level businesses, the taquerias, the barbershops, the laundromats, none of them use any AI at all.
16. I heard the phrase "agent debt" for the first time. Like technical debt but for agents. When you hack together an agent workflow fast and never clean it up, the system prompts conflict, the memory gets polluted, the tools overlap. 6 months later the agent is doing weird things and nobody knows why lol.
17. Met a few people who carry two phones now. One for personal. One that's basically an agent terminal running Telegram or iMessage connections to their agent fleet.
It's always amazing to get that dose of inspiration in SF. I FEEL INSPIRED.
But I'm so happy to be back home, locked in and building.
We're 12-18 months into a shift that will take 15 years to play out. The urgency in every conversation was real.
What an incredible time to be building.

21
yonks|🤖🏛️🪙|Jason Younker retweeted
May 26
I just got back from SF and I FEEL INSPIRED.
I spent 5 days with frontier AI model teams, AI startup founders, and 3 billionaires.
My takeaways:
1. I had lunch with 3 billionaires. All of them are buying SaaS companies and rebuilding them agent-first. They were deeply inspired by Bending Spoons and Ryan Cohen's eBay deal. Buy the company, cut the headcount, rebuild the tech, add agents, add features, make more valuable experience, raise prices.
2. The frontier model companies are hungry for usage data from the field. They can see API calls and token counts. They can't see the actual workflows. If you're deep in a niche using these models in ways the model companies haven't seen, that understanding is incredibly valuable. Usage intelligence is the new alpha.
3. Consumer AI is massively underbuilt. Every billboard in SF is either B2B inference infrastructure or vertical agent companies. The entire city is optimized for enterprise. Meanwhile you have companies like Cal AI doing $50M ARR in 18 months as a consumer app. I met with a cool few teams doing consumer AI (@paulscherer / @ekuyda)
4. MCP came up in literally every conversation. The companies exposing their product as MCP endpoints are getting pulled into deals they never pitched for. The ones that aren't are becoming invisible to agents. This is the new SEO. If agents can't find you, you don't exist. Building products for agents is the new zeitgeist in general.
5. Not uncommon for hot seed rounds to be $25-50 million valuations. I saw a Series A at $450 million
6. If I had a dollar every time someone mentioned "forward-deployed engineer" this trip I could have funded a seed round. It's the hottest role in SF right now. The person who sits between the agent and the customer, making sure everything actually works.
7. The mood around open source shifted. A year ago it felt like open source was chasing the frontier models. Now founders are telling me Gemma and DeepSeek are good enough for 80% of what they need at a fraction of the cost. The "which model do you use" conversation is being replaced by "which model for which task." Model loyalty kinda feels dead.
8. Voice agents came up more than I expected. Multiple founders told me voice is the interface for the next billion users. The billion people who will never type a prompt will absolutely talk to one.
9. The Obsidian community in SF is weirdly intense. Multiple founders showed me their vaults unprompted. Like showing someone your home gym. It's a flex now. The quality of your knowledge base (second brain?) is becoming a status symbol among builders.
10. Maybe it was just the people I met but the age of the founders is shifting. I met more founders over 40 this trip than any trip before and more founders under age 21 than ever before. Founders getting older and younger at the same time.
11. I spoke to a lot of fast-growing startups, VCs and frontier models who are hiring content creators right now.
12. The restaurant scene in SF is actually better than it's been in years. Founders are going out more. Alcohol is out, not surprisingly.
13. SF doesn't feel like the only place anymore. We all have access to the same frontier models. We all read the same X feed. A founder in NYC or Lagos is calling the same APIs as a founder in SoMa. So in the past it felt like SF was always lightyears ahead, doesn't feel that way anymore. It's okay not to live in SF and have BIG DREAMS.
14. The coworking spaces in SF are half empty but the coffee shops are packed. People want to be around people. I had a few startup ideas here....
15. Walking around the Mission I noticed something: the street-level businesses, the taquerias, the barbershops, the laundromats, none of them use any AI at all.
16. I heard the phrase "agent debt" for the first time. Like technical debt but for agents. When you hack together an agent workflow fast and never clean it up, the system prompts conflict, the memory gets polluted, the tools overlap. 6 months later the agent is doing weird things and nobody knows why lol.
17. Met a few people who carry two phones now. One for personal. One that's basically an agent terminal running Telegram or iMessage connections to their agent fleet.
It's always amazing to get that dose of inspiration in SF. I FEEL INSPIRED.
But I'm so happy to be back home, locked in and building.
We're 12-18 months into a shift that will take 15 years to play out. The urgency in every conversation was real.
What an incredible time to be building.
496
574
6,214
635,842
yonks|🤖🏛️🪙|Jason Younker retweeted
May 25
How to build a vertical AI agent cash-flowing startup:
find painful workflow in a boring industry → talk to 10 people who do that workflow every day → map every step, every tool, every spreadsheet, every phone call →
do the workflow manually first → be the agent before you build the agent → find the edge cases that break everything → document them in obsidian as structured markdown →
set up your agent stack → hermes for the harness → obsidian vault as the knowledge base → composio for authentication across apps → build your first 1-3 skills that solve the core pain →
use claude code or codex to build the product → use agents to set up other agents → use perplexity MCP and context7 for up-to-date docs → let the agent handle the scaffolding while you focus on the workflow logic →
ship the agent to your first 5 customers for free → watch what they actually use it for → they will surprise you → the thing you built for isn't always the thing they need most →
build content around the niche → not "building in public" content → useful content → the tips, the shortcuts, the pain points that only someone who does this workflow would know → become the person for that niche →
charge per outcome not per seat → per lease renewed, per claim processed, per candidate sourced → the ROI conversation takes 10 seconds when it's tied to a result →
set up watchdogs and alerts → your agent emails you when a cron job breaks or a skill fails → the customer should never have to tell you something is broken →
connect to open router → see exact costs per model per task → use GPT 5.5 for tool calls → use open source for lightweight tasks → route the right model to the right job → watch your margins double →
let hermes write to its own memory after every task → the agent compounds → the longer it runs the better it gets → that accumulated memory becomes your moat → a competitor can clone your product but they can't clone 6 months of context →
expand the workflow → you started with one step → add the next → then the next → now you own the entire workflow end to end → you went from a tool to the operating system for that vertical →
stack the agents → one agent is a side project → five agents across five customers is a business → each one runs in its own environment → you check in once a day →
raise only if you need capital not credibility → most agent businesses should never raise → the margins are too good to give away equity → stay lean → stay profitable → repeat
i'm rooting for you
159
117
1,342
115,335
yonks|🤖🏛️🪙|Jason Younker retweeted
May 24
the anatomy of the perfect 𝗦𝗢𝗨𝗟.𝗺𝗱 file for AI agents.
𝗦𝗢𝗨𝗟.𝗺𝗱 is the one file you write yourself for an AI agent.
it sits at the top of the system prompt, before memory, before skills, before tools. it defines who the agent is when it shows up.
an hour spent on it changes every conversation that follows. most other layers update themselves. this one is yours.
i just broke down what a 𝗦𝗢𝗨𝗟.𝗺𝗱 file that actually works looks like.
here are the 8 sections that matter:
→ identity (a one-line statement of who, not what)
→ core truths (imperative principles, each with a one-line unpacking)
→ worldview (opinionated takes by domain, sharp enough to predict)
→ voice (concrete rules for how the agent talks, not adjectives)
→ expertise (primary domain, fluent tools, where it defers)
→ boundaries (explicit "won't" lines, no soft language)
→ memory policy (what persists, what stays private)
→ pet peeves (phrases and tones the agent never produces)
generally people write "be helpful and professional" and call it done.
that changes nothing. every model already tries to be helpful and professional by default.
the agents that compound have 𝗦𝗢𝗨𝗟.𝗺𝗱 files with real opinions, hard limits, and a voice you can predict before you read the response.
a strong 𝗦𝗢𝗨𝗟.𝗺𝗱 is 30 to 80 lines. specificity beats coverage.
bookmark this. the first agent you build will need it.
i wrote a full masterclass on Hermes Agent that walks through the 𝗦𝗢𝗨𝗟.𝗺𝗱 layer, the three-tier memory system, the self-evolving skills loop, and how to run three specialized agents on your machine 24/7.
the article is quoted below.

85
274
2,122
261,126
yonks|🤖🏛️🪙|Jason Younker retweeted

May 25
🚨 You can now deploy unlimited AI voice agents on your own infrastructure for $0.
Stop bleeding margin to per-minute SaaS rentals.
A team of YC alumni just built an open-source exit hatch, and I've been really excited to be involved with it.
Dograh is a fully self-hosted voice AI platform.
One Docker command deploys your infrastructure.
Drag and drop your workflow, define your prompt, and launch a production-ready bot in 120 seconds.
Your stack, your rules!
> Bring your own LLM
> Any Speech-to-Text
> Any Text-to-Speech
> Inbound and outbound calls
> WebRTC and standard phone numbers
Built on Pipecat, FastAPI, and Next.js.
SaaS platforms charge sales teams $10,000 annually for this.
Dograh is 100% free and open-source.
... and almost 3k GitHub stars already.
repo in 🧵↓
11
13
85
8,582
yonks|🤖🏛️🪙|Jason Younker retweeted

May 24
Leopold Aschenbrenner is literally giving you insider trading info
He turned $225M into $5.5B in less than 12 months
In 2025 he bought:
$BE at $18 & is now $297
$LITE at $59 & is now $935
$SNDK at $42 & is now $1,466
Now in 2026, he’s telling you to buy:
1) Applied Digital $APLD
2) Bloom Energy $BE
3)CleanSpark $CLSK
4)CoreWeave $CRWV
5)Intel $INTC
6) IREN $IREN
7) Keel Infrastructure $KEEL
8) Micron $MU
9) Riot $RIOT
10) Sandisk $SNDK
11) T1 Energy $TE
12) Taiwan Semiconductor $TSM
Don’t miss out on a generational run
83
261
1,919
296,625