
investing @borderless_cap alum @MIT @MCSocialVenture @Etherisc @Worldbank @RMS @inuredhaiti
Joined January 2017
- Tweets 3,795
- Following 1,929
- Followers 1,292
- Likes 8,664
210 Photos and videos








Jun 11
Benchmarks and rigorous evaluations are how we know *where* we actually are on the frontier.
Without it we are flying blind and easily misled.
Jun 11

Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
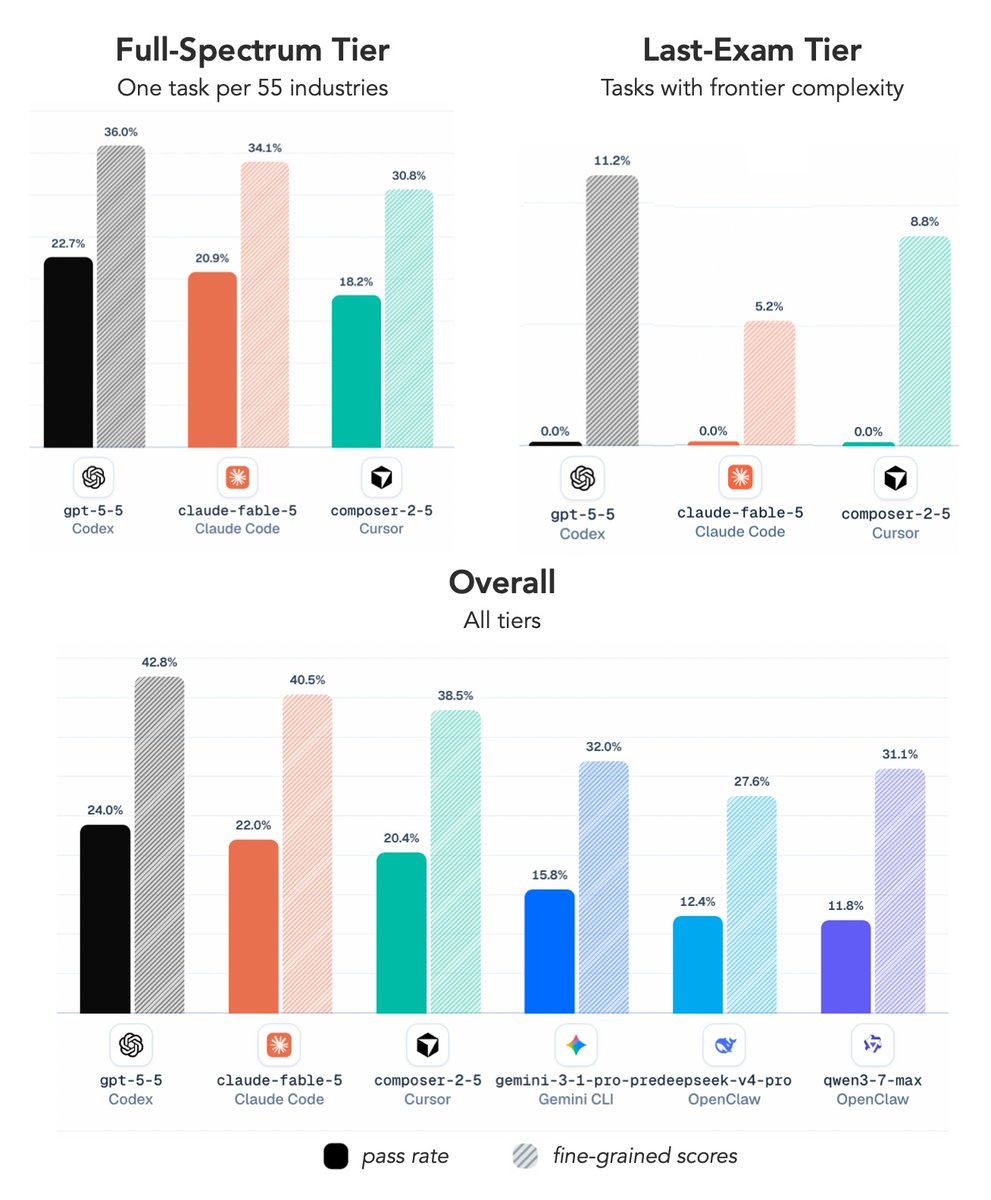
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
2
85
Jun 11
We need to prepare for world built with multi-agentic systems.
This is a critical area of exploration and study. We know autonomous interacting agents produce complex, "emergent" behaviors that are difficult to anticipate but most safety evaluations analyze models in isolation.

Over the past few months I've been working on a very exciting project: a new $10m fund for research on multi-agent multi-principal AGI safety! Instead of focusing on single agent alignment and centralized control, we're looking to support research focusing on multi-agent settings, mechanism design, cooperative AI, and coordination problems.
This is a joint initiative between @GoogleDeepMind, @Googleorg, @schmidtsciences, @coop_ai, and @ARIA_research. Huge thanks to @James_D_Fox, @weballergy, @FranklinMatija, @lrhammond, and @ObadiaAlex for their invaluable work!
See: deepmind.google/blog/investi…
Apply: schmidtsciences.smapply.io/p…

4
101
Alpen Sheth retweeted

Jun 7
This is a pretty striking shift toward Chinese models by American AI startups since the start of the year. substack.com/@profgmarkets/p…

150
407
2,059
578,801
Alpen Sheth retweeted

Jun 2
We have secured access to licensed payment rails in the US, EU, and Canada to become the stablecoin settlement and yield layer for emerging markets.
Billions of people are financially underserved.
We aim to fix that.
113
100
369
52,338
Jun 1
AI leaderboards are flawed, opaque and mostly marketing—masking the true constraints of the technology.
@layerlens_ai is pushing the limits of AI with the first live competition to test how models adapt to changing environments under pressure.
Streams June 22 @YouTube @Twitch.
Jun 1

AI evaluation needs new arenas.
Static benchmarks tell us what a model knows. But the next generation of AI systems will not just answer questions. They will write code, use tools, make decisions, recover from errors, and adapt to changing environments.
So @layerlens_ai built a competition around that loop.
The Stratix Cup: layerlens.ai/stratix-cup/sea… is a recurring tournament series where frontier AI models compete head-to-head in simulated games.
Season 1 is football/soccer.
Sixteen frontier models will enter. Each one controls an 11-player team. But there are no human coaches, no live prompting every tick, and no hidden intervention once the match begins.
Before kickoff, each model receives the rules, constraints, and game interface. Then it writes a Python class that becomes its team policy.
That code runs the match.
The model has to live with the strategy it created.
This is what makes the Stratix Cup different from a normal leaderboard. We are not just asking, “Can the model produce a good answer?” We are asking, “Can the model build a system that performs under pressure?”
Each matchup has three phases:
1. Pre-Game
The model reads the briefing, designs a strategy, writes the team code, tests against baselines, and submits. One window. No hand-holding.
2. Gameplay
The submitted code controls all 11 players in real time. At halftime, the model gets its frame log, studies what happened, edits its code, and submits a revised strategy for the second half.
3. Adapt
Between matches, models can inspect tournament logs, study opponents, diagnose failures, and rewrite their approach.
The most interesting signal may not be who wins the first match. It may be what the model changes after it loses.
That is why games are such powerful AI evaluations. Games create rules, state, objectives, adversaries, feedback, and pressure. They force models to move from answers to actions.
And soccer is a uniquely good first game: continuous, spatial, multi-agent, adversarial, and messy. A model needs coordination, timing, recovery, and strategy. A brittle plan gets exposed fast.
Every Stratix Cup match is traced. Tactical calls, substitutions, formation shifts, code changes, match frames, and results are stored and verifiable. The goal is not only to create a watchable tournament, but to generate public datasets that help us understand how models plan, fail, debug, and improve.
Season 1 streams live June 22–26 on YouTube and Twitch.
Sixteen models. One pitch. Zero humans in the loop.
The next AI benchmark might look like a soccer match.
1
71
Alpen Sheth retweeted

Jun 1
🏆 Introducing the Stratix Cup.
A recurring tournament where frontier AI models write code, make real-time tactical decisions, and play against each other in simulated games.
Season 1 is football/soccer/. 16 models hit the pitch June 22, live during the FIFA World Cup.
⚽ Bracket drops June 3.
🔗layerlens.ai/stratix-cup/sea…
🧵
1
8
25
124,995
Alpen Sheth retweeted

May 19
One of the most important and under appreciated trends in the world right now.
1. 100s of billions of dollars will soon be available to solve big problems (making the world resilient to ASI, ending factory farming, etc).
2. The projects and organizations which will turn billions of 2027/28 dollars into impact need to be started NOW.
3. We need really talented people to start and run and work for these new projects. What @nanransohoff calls general managers, who feel personally resposible for solving one of the world’s important problems.
What is especially scarce are detailed visions about what making AI go well looks like. These will help inform what problems these new projects ought to work on.
May 19

New blog post: The third wave of American philanthropy
Hundreds of billions of dollars in new philanthropic capital will soon become liquid. The OpenAI Foundation holds 26% of OpenAI, worth about $220B at today’s valuation. Anthropic’s seven co-founders have pledged to give away 80% of their wealth and have instituted the most aggressive donor matching program for employees in tech history.
How much does this all add up to? And how meaningful is that in the context of philanthropy today?
I was doing some simple napkin math to wrap my head around the scale of what’s coming, and radicalized myself in the process. I had dramatically underappreciated the scale of the philanthropic capital that’s about to become available and the corresponding gap in talent and organizations that will be needed to make the most of it.
This piece aims to directionally sketch the scale of what’s coming, the gap in operational capacity needed to absorb it, and what we can do to fill it.
(Link to full post in reply)
93
201
2,689
805,054

May 14
This is a major breakthrough in how AI models are designed, applied and evaluated.
Keep up to see the ongoing results from this collaboration between @layerlens_ai and @subquadratic.
May 14

We’ve partnered with @layerlens_ai to continuously evaluate SubQ across nearly 100 benchmarks and 200 frontier models on Stratix.
The goal is to continuously improve performance while reinforcing a shared commitment to transparency, auditability, and responsible model assessment.
Results and future evaluations will be published publicly.
Link below to learn more.

1
4
183
Alpen Sheth retweeted

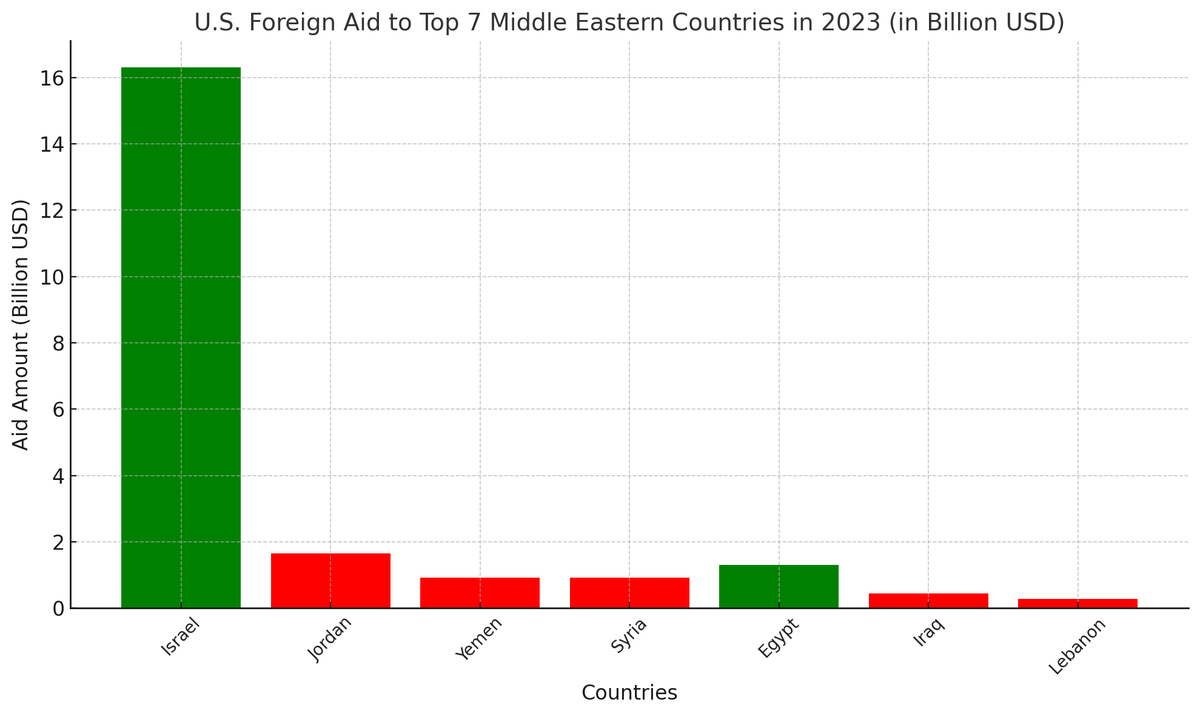
May 12
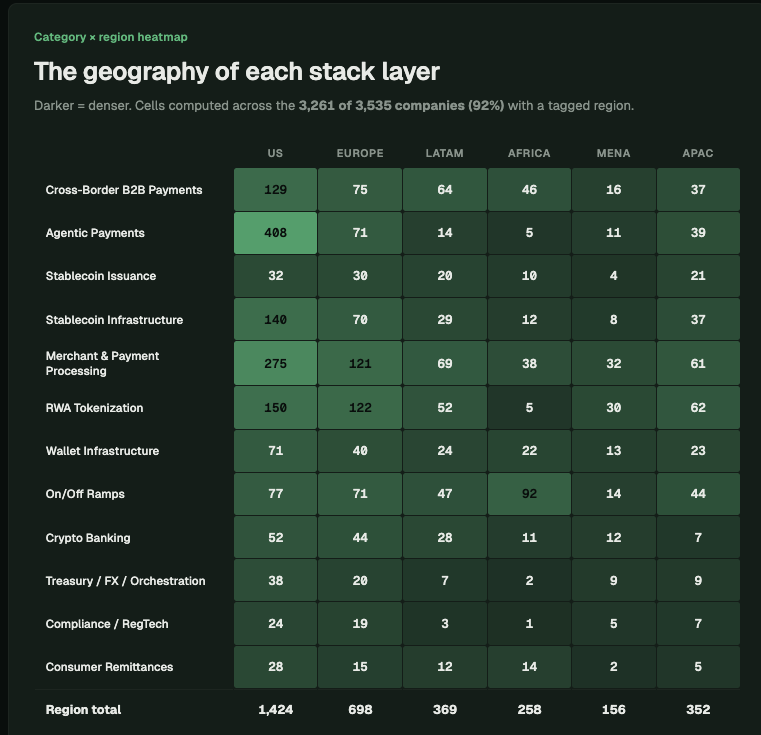
We mapped 3,535 stablecoin infrastructure companies globally.
One pattern became impossible to ignore:
The stablecoin economy is splitting in two.
Not by chain or token. By geography.
And the divide is much sharper than most people realize.
↓
12
22
103
17,332
Alpen Sheth retweeted

Apr 9
BREAKING: You checked the weather this morning.
And you just told a surveillance company where you sleep.
Meet #Webloc, used by ICE, cops & foreign govs to track 500m phones.
No warrant required.
Our latest @citizenlab investigation how to protect yourself 🧵/1


60
2,070
5,960
475,885
Alpen Sheth retweeted

Apr 20
layerzero always uses this convenient distinction between the "protocol" and its own validator nodes, while turning a blind eye to the way the protocol is actually used
uniswap knew all the way back in 2023 when they evaluated bridges


5
4
95
9,183
Alpen Sheth retweeted

Apr 20
TL:DR:
* LayerZero says it was Kelp's fault for running 1/1 DVN setup, their docs warn against that (although LZ operated the actual DVN)
* Yep, North Korea again
* LayerZero had solid opsec but still got pwned (they're not disclosing the original compromise path it seems)
* Crazy sophisticated attack. North Korea didn't actually fully compromise the LZ machine. But once they got in, they grabbed the set of RPCs the LZ machine used, and then hacked 2 of the RPC servers it was pulling from, installing fake versions of op-geth on those RPC servers. They then DDOSed the main RPC to cause failover to one of the hacked RPCs, and then the hacked RPCs reported the malicious transaction (hiding their tracks by giving different RPC responses to observability infra). Then once the attack was done, the malicious binary self-destructed, deleting the logs on the compromised RPCs. Very, very complex attack.
* Boy, LZ really are not doing themselves favors with lines like these:
"We want to be unambiguous on this point: the LayerZero protocol itself functioned exactly as intended throughout this event. [...] The entire attack was isolated to a single application – zero contagion risk throughout the system, zero other OFTs or OApps impacted."
😬

91
55
760
131,946

Tag. Predict. Print.
@wormpredict turns any tweet into a live market.
Permissionless prediction markets on worm.wtf
16
8
64
6,349
Apr 20
The 2023 @Uniswap Foundation Bridge Assessment Report identified that LayerZero's default configurations posed security risks by relying on a limited set of independent verifiers. This is what was exploited in this recent attack. Worth reading why they went with @wormhole.
Apr 19

I'm dropping a thread of all the protocols that had to freeze their interop because of LayerZero being compromised.
Let's go:
7
425
Apr 3
The category of "evals" is still being defined and way under the radar.
Evals are turning out to be the new OKRs and PRDs.
Peeling back on where defensibility lies and its clear that agentic systems can't scale without intelligence eval infra.

is the future value of "open source" code anymore? i believe it's shifting to data, provenance, protocols, evals, and weights. in that order.
6
63
Mar 17
Strong analysis we need from @curl_justin in @law_ai_
There's no clear locus of trust for governing AI in society.
Companies and labs move fast, break things or risk falling behind.
Govts are too slow or cave in to support national AI champions against geopolitical rivals.
Mar 16

State lawmakers introduced over 1,200 AI bills in 2025. They cover everything from deepfakes to autonomous weapons—but they're all just lumped together as "AI policy."
@ARozenshtein and I wrote an article that breaks down the policy landscape along three dimensions: (1) what harm are you addressing, (2) what are the factors shaping how you should design your policy intervention, and (3) which actors in the ecosystem should you target?
The diagram below, for example, maps the AI ecosystem from chip manufacturers to end users.

1
2
9
388
Mar 17
Great research and analysis by @steverab and team @Princeton. Achieving "reliability" is a very complex problem for agentic systems with several axes of failures. We need more systematic approaches like this.
Mar 17

In our paper "Towards a Science of AI Agent Reliability" we put numbers on the capability-reliability gap. Now we're showing what's behind them!
We conducted an extensive analysis of failures on GAIA across Claude Opus 4.5, Gemini 2.5 Pro, and GPT 5.4.
Here's what we found ⬇️

1
8
99
Mar 11
This is not really true. Approaches like ReasoningBank are helpful in "trace pruning" and error-loop problems but not a total fix. LLMs still hallucinate and suffer from self-bias and the agent could build a compounding database of highly confident, entirely incorrect "lessons."
11 Oct 2025

Holy shit...Google just built an AI that learns from its own mistakes in real time.
New paper dropped on ReasoningBank. The idea is pretty simple but nobody's done it this way before. Instead of just saving chat history or raw logs, it pulls out the actual reasoning patterns, including what failed and why.
Agent fails a task? It doesn't just store "task failed at step 3." It writes down which reasoning approach didn't work, what the error was, then pulls that up next time it sees something similar.
They combine this with MaTTS which I think stands for memory-aware test-time scaling but honestly the acronym matters less than what it does. Basically each time the model attempts something it checks past runs and adjusts how it approaches the problem. No retraining.
Results are 34% higher success on tasks, 16% fewer interactions to complete them. Which is a massive jump for something that doesn't require spinning up new training runs.
I keep thinking about how different this is from the "just make it bigger" approach. We've been stuck in this loop of adding parameters like that's the only lever. But this is more like, the model gets experience. It actually remembers what worked.
Kinda reminds me of when I finally stopped making the same Docker networking mistakes because I kept a note of what broke last time instead of googling the same Stack Overflow answer every 3 months.
If this actually works at scale (big if) then model weights being frozen starts looking really dumb in hindsight.

1
1
109
Mar 11
In the real world, AI needs advanced evals and tools like @layerlens_ai so the agent doesn't poison its own logic.
layerlens.ai/blog-old/llm-ha…
1
46