
Joined February 2015
- Tweets 385
- Following 458
- Followers 198
- Likes 13,374
25 Photos and videos














Leopold retweeted
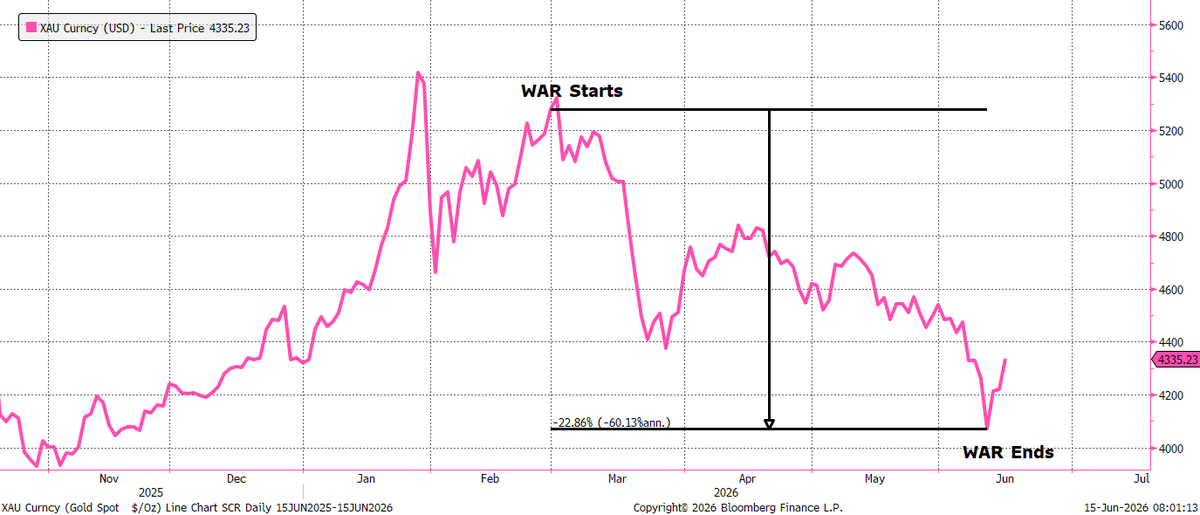
Thank God the War is over.
Now Gold can go back to being a Safe Haven asset.
97
70
993
51,313
Leopold retweeted

Jun 12
Whatever you think of me and my opinion on Stablecoins, you might want to listen to Stanley.
Both the current Fed Chairman and current U.S. Treasury Secretary used to work for him…
Jun 12

ETH investor Stanley Druckenmiller: “Our whole payment system will be stablecoins in 10-15 years”
BitMine (BMNR), the ETH treasury company chaired by Tom Lee, holds almost $10 billion of ETH. Legendary investor Stanley Druckenmiller is listed among key backers like Founders Fund, ARK's Cathie Wood, and Bill Miller. This aligns with his recent bullish comments on stablecoins and blockchain payments:
“Blockchain and the use of stablecoins — if you want to throw crypto and tokens into that — are incredibly useful in terms of productivity. I assume our whole payment system will be stablecoins in 10-15 years. Efficient. Quicker. Cheaper.”
45
40
446
75,151
Leopold retweeted

Jun 11
The other day my Poke AI agent (by @interaction) casually sent me info about emails and orders from someone else.
It sent me these out of the blue. I never ordered these and I didn't ask for any updates about my orders.
And then it didn't want to answer or admit that it sent me someone else's emails. The most I got out of it was "my bad".


1
1
1
1,095
Leopold retweeted

Jun 6
Your margin is my opportunity: AI version…
The biggest surprise of 2026 is that the capability gap between the best open-weight/source models and the best closed models has narrowed much faster than the pricing gap. The pricing gap remains enormous while the capability gap is quite narrow.
What does this means in practice?
For a company consuming 1 billion input tokens and 1 billion output tokens per month:
GPT-5.5 Pro: ~$105,000
Claude Opus 4.8: ~$30,000
DeepSeek V4 Pro: ~$5,220
DeepSeek R1: ~$2,740
I asked ChatGPT what it thought about this and it answered as follows:
“If I were building a company today, the economic frontier would look roughly like:
DeepSeek V4 Pro / R1 for high-volume inference.
Claude Opus for premium agent workflows where reliability matters.
GPT-5.5 Pro only for workloads where its incremental capability demonstrably produces enough business value to justify a 20–40× token premium.”
Most CEOs have no idea that, instead of this nuanced approach, their teams are running amok internally by picking the most expensive models in most cases and burning through massive budgets with zero governance, audit ability and control.
As control planes like our Software Factory become more standard, you can expect the run rate revenue growth of the frontier labs to go down meaningfully and the revenues of the open models to skyrocket.
Why? Because we can implement the nuanced approach above and be agnostic to model - instead focusing on customer intent, model task and cost management among other things.
Jun 6

Quite a week for open-source AI. Especially American open-source. Nemotron 3 Ultra is the most important release in quite some time. And some really cool RL and fine-tuning work from Harvey.
222
221
2,003
865,881
Leopold retweeted

May 25
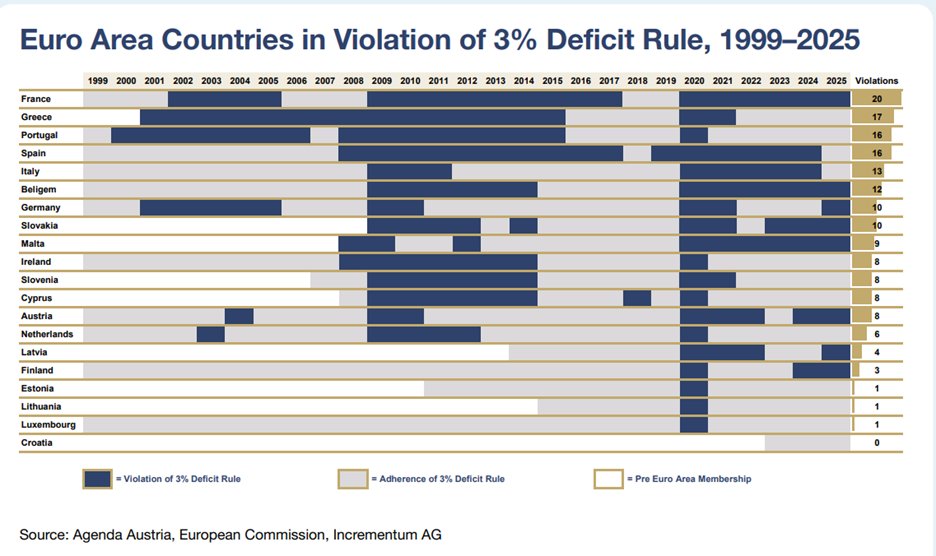
The Maastricht criteria are about as binding these days as New Year's resolutions on January 15th....
Link to the full report: ingoldwetrust.report/wp-cont…
7
11
62
8,539

Yes, yes, I know it's cliched.
But, I'm only human.
May 23

A wholesome moment.
Mom giving her daughter one of the best experiences. Memories that last forever, not just a day.
6
2
47
18,804
Leopold retweeted
Ole (@itsolelehmann) deleted half his Claude setup last week and every output got BETTER.
You can do the same with Codex.
Run this prompt inside Codex and enjoy a faster and better Codex experience.
---
```
Read my Codex setup before responding. Inspect the relevant AGENTS.md files, ~/.codex/config.toml, repo docs, and any instruction/workflow files you can access.
Audit every rule and instruction. For each one, tell me:
1. Is this already default Codex behavior?
2. Does it conflict with another instruction?
3. Is it duplicated elsewhere?
4. Was it probably added to fix one specific bad output?
5. Is it too vague to be useful?
Then give me:
- rules to cut, with one-line reasons
- conflicts between files
- duplicated rules
- a cleaned-up AGENTS.md proposal
- anything you would keep because it is genuinely specific to my workflow
```
🚨Caution: don’t blindly accept the cleanup. Codex is decent at finding bloat, but it can also remove "local truth" that matters, like repo-specific commands, safety rules, or your preferred workflow.
Best process: trim, run 3 common tasks, then add back only what breaks.
Mar 23

i deleted half my Claude setup last week and every output got BETTER
sounds backwards, but anthropic's own team just explained exactly why it works.
here's the one prompt that tells you what to cut (and you don't even have to paste anything):
this is what happens to everyone...
you get a bad output, so you add a rule to your skills. "be more concise."
next week, another bad output. another rule. "use a casual tone."
but a month later, something else breaks. "always explain technical terms."
you keep stacking, and it feels productive because you're fixing problems as they come up.
but 3 months in, you've got 30 rules piled on top of each other.
some of them contradict each other ("be concise" and "always explain your reasoning" are fighting).
some of them fix problems that the model doesn't even have anymore.
and the model is trying to follow all of them at once, which means it's doing none of them well.
it's like handing a chef a 47-step recipe when they only need 12.
the extra 35 steps slow the chef down, make them second-guess the parts they already know, and the dish comes out worse than if you'd just let them cook.
that's what over-prompting does.
anthropic just published a piece on how they build claude code (the ai coding agent).
their own engineering team found that their scaffolding was making the ai worse
which means your custom instructions are almost certainly doing the same thing.
so here's the actionable move...
instead of manually reading through your setup line by line, just tell claude to audit itself.
if you're in claude's desktop app, claude already has access to your:
claude[.]md (the file where your preferences and rules live), your skills folder (where your reusable instruction files are stored), your context files, everything.
just open claude code/cowork and say this:
—
"read my entire setup before responding. check my claude .md, every skill in my skills folder, every file in my context folder, and any other instruction files you can find.
then go through every rule, instruction, and preference you found. for each one, tell me:
1. is this something you already do by default without being told?
2. does this contradict or conflict with another rule somewhere else in my setup?
3. does this repeat something that's already covered by a different rule or file?
4. does this read like it was added to fix one specific bad output rather than improve outputs overall?
5. is this so vague that you'd interpret it differently every time? (ex: 'be more natural' or 'use a good tone')
then give me a list of everything you'd cut with a one-line reason for each, a list of any conflicts you found between files, and a cleaned up version of my claude.md with the dead weight removed."
—
one message. claude goes and reads your entire setup, audits it, and comes back with exactly what to cut and why.
you don't dig through files, you don't read every rule yourself. it does the whole thing.
once you get the results, don't just blindly delete everything it flags.
here's the process:
1. read what it flagged and why
2. delete the flagged rules
3. run your 3 most common tasks with the trimmed setup
4. did the output stay the same or get better? the deleted rules were dead weight
5. did something specific break? add back just that one rule
the goal is to find the minimum viable setup that gets you the output you want.
your ai setup should be getting simpler over time.
addition by subtraction baby

2
13
2,587

Leopold retweeted

Apr 7
I suspect that popularity of AI is going to start looking like surveys where people trust their own doctors but are distrustful of the medical establishment
People will increasingly like “their AI” but will increasingly be anxious about “AI” as a category. Some odd implications
58
22
326
23,349
Leopold retweeted

Mar 20
173
551
2,978
1,297,310
Leopold retweeted

Mar 15
Researchers trained a humanoid robot to play tennis using only 5 hours of motion capture data
The robot can now sustain multi-shot rallies with human players, hitting balls traveling >15 m/s with a ~90% success rate
AlphaGo for every sport is coming
475
1,152
8,813
1,892,033
Leopold retweeted

Mar 15
This is wild.
143 million people thought they were catching Pokémon. They were actually building one of the largest real-world visual datasets in AI history.
Niantic just disclosed that photos and AR scans collected through Pokémon Go have produced a dataset of over 30 billion real-world images. The company is now using that data to power visual navigation AI for delivery robots.
Players didn't just walk around with their phones. They scanned landmarks, storefronts, parks, and sidewalks from every angle, at every time of day, in lighting and weather conditions that staged photography would never capture. They documented the physical world at a scale no mapping company with a fleet of vehicles could have replicated on the same timeline or budget.
Niantic collected this systematically, data point by data point, across eight years, while users thought the only thing at stake was catching a rare Charizard.
The most valuable AI training datasets in the world aren't being assembled in data centers. They're being built by people who have no idea they're building them.
Mar 15

POKÉMON GO PLAYERS TRAINED 30 BILLION IMAGE AI MAP
Niantic says photos and scans collected through Pokémon Go and its AR apps have produced a massive dataset of more than 30 billion real-world images.
The company is now using that data to power visual navigation for delivery robots, letting them identify exact locations on city streets without relying on GPS.
Source: NewsForce
2,170
23,784
105,582
14,064,160

Yale Budget Lab Exec. Dir. @marthagimbel on the shrinking appeal of U.S. debt: "We are currently the boyfriend at the beginning of the Hallmark movie in the big city, where the girlfriend is still going out with him even though she knows that it's wrong."
20
134
623
275,437
Leopold retweeted

Mar 11
35% of Samsung's NAND & 20% of Hynix NAND capacity is in China
40% of Hynix's DRAM capacity is in China
They are responsible for the bulk of this growth
Mar 11

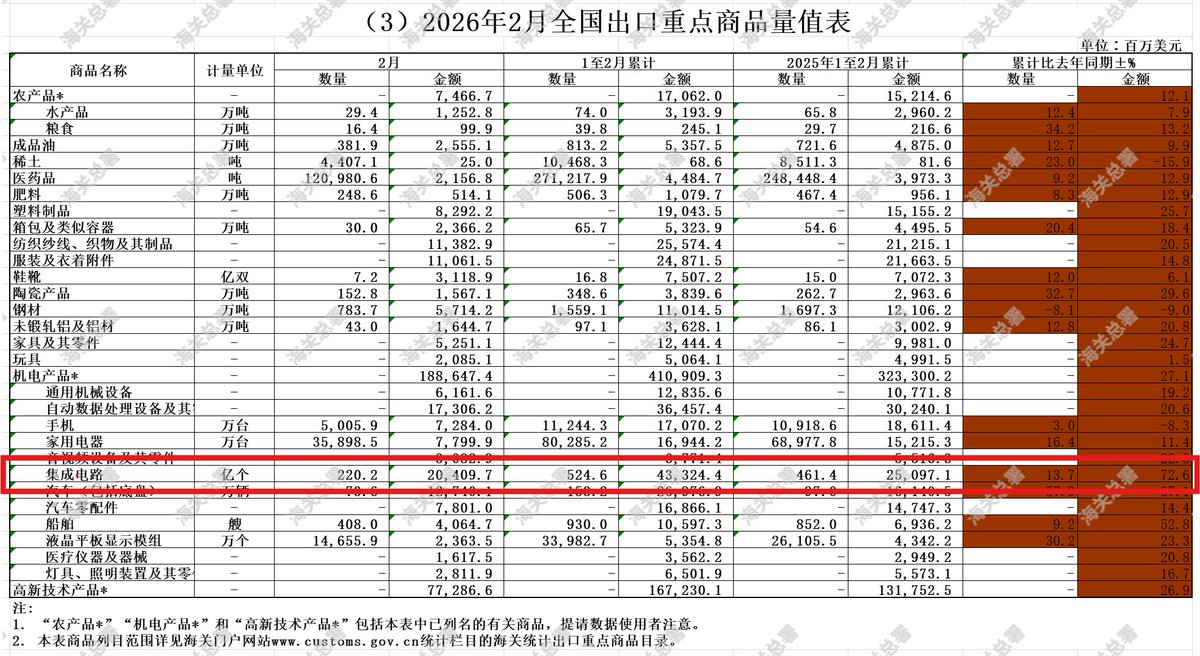
This is fascinating from China's customs data (customs.gov.cn/customs/2026-…).
All its exports are rising very rapidly but the one export that's rising the fastest, at a crazy 72.6% growth year on year, is... semiconductors!
As you can see in the trade data China sold $43.32 billion worth of 集成电路 ("integrated circuits") in Jan-Feb 2026, vs $25.10 billion for Jan-Feb last year.
Interestingly, volume is "only" up 13.7% year on year, which means the increase in revenue is mostly driven by higher prices per chip, which probably suggests that
a) China is climbing up the value chain (selling more expensive chips)
b) demand for their chips far exceeds supply - which is the exact opposite of "overcapacity". You don't get 53% price increases per unit in a market with overcapacity
And all in all, it goes to show that China is definitely a force to be reckoned with in the semiconductor world. Global semiconductor sales were $791.7 Billion in 2025 (semiconductors.org/global-an…) and projected to be ~$975 billion this year. China selling $43.32 billion in 2 months means its doing $260 billion annualized: that's over a quarter of the entire global semiconductor market.
So much for the idea that export controls would freeze China out of the semiconductor industry...
14
48
425
111,467
Leopold retweeted
Mar 10
NotebookLM: Do a deep research report and make a video telling me exactly how to take over Rome if I time travelled to 66 BC with a single backpack.
Actually pretty fun to watch and gets a lot of historical details in as well.
Mar 10

NotebookLM: Do a deep research report and make a video where a consultant gives Sauron a strategy for actually winning the War of the Ring: "All you need to do is sign off to put a simple door on your volcano"
The new video generation feature for NotebookLM is very impressive.
45
143
1,330
141,732

Leopold retweeted

Mar 8
💯 "If you build it, they will come." :)
~Every business you go to is still so used to giving you instructions over legacy interfaces. They expect you to navigate to web pages, click buttons, they give out instructions for where to click and what to enter here or there. This suddenly feels rude - why are you telling me what to do? Please give me the thing I can copy paste to my agent.

110
188
2,282
153,430
Leopold retweeted

Mar 3
we just wrote the ultimate beginner's guide to OpenClaw
almost everyone @every has one now, and they have completely changed the way we work and live. we're using our claws to:
- build product
- answer customer service queries
- book hard-to-get restaurant reservations
- track our reading notes
and much more
this is the guide we wish we'd had at the start:
every.to/guides/claw-school?…
111
457
4,418
745,466
Leopold retweeted

Feb 27
Another great take on the current AI debate. If nothing else @Citrini7’s article has made the last few days on this platform more valuable and interesting.

4
8
91
23,966