
Efficient AI; Dynamic System;
Joined November 2014
- Tweets 181
- Following 227
- Followers 120
- Likes 1,492
12 Photos and videos


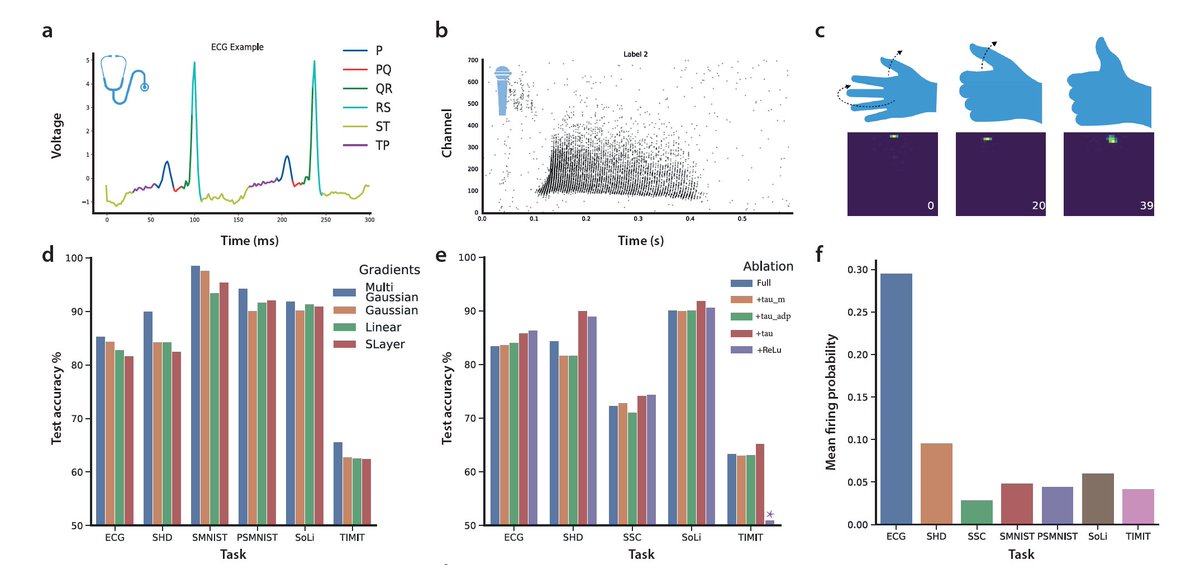

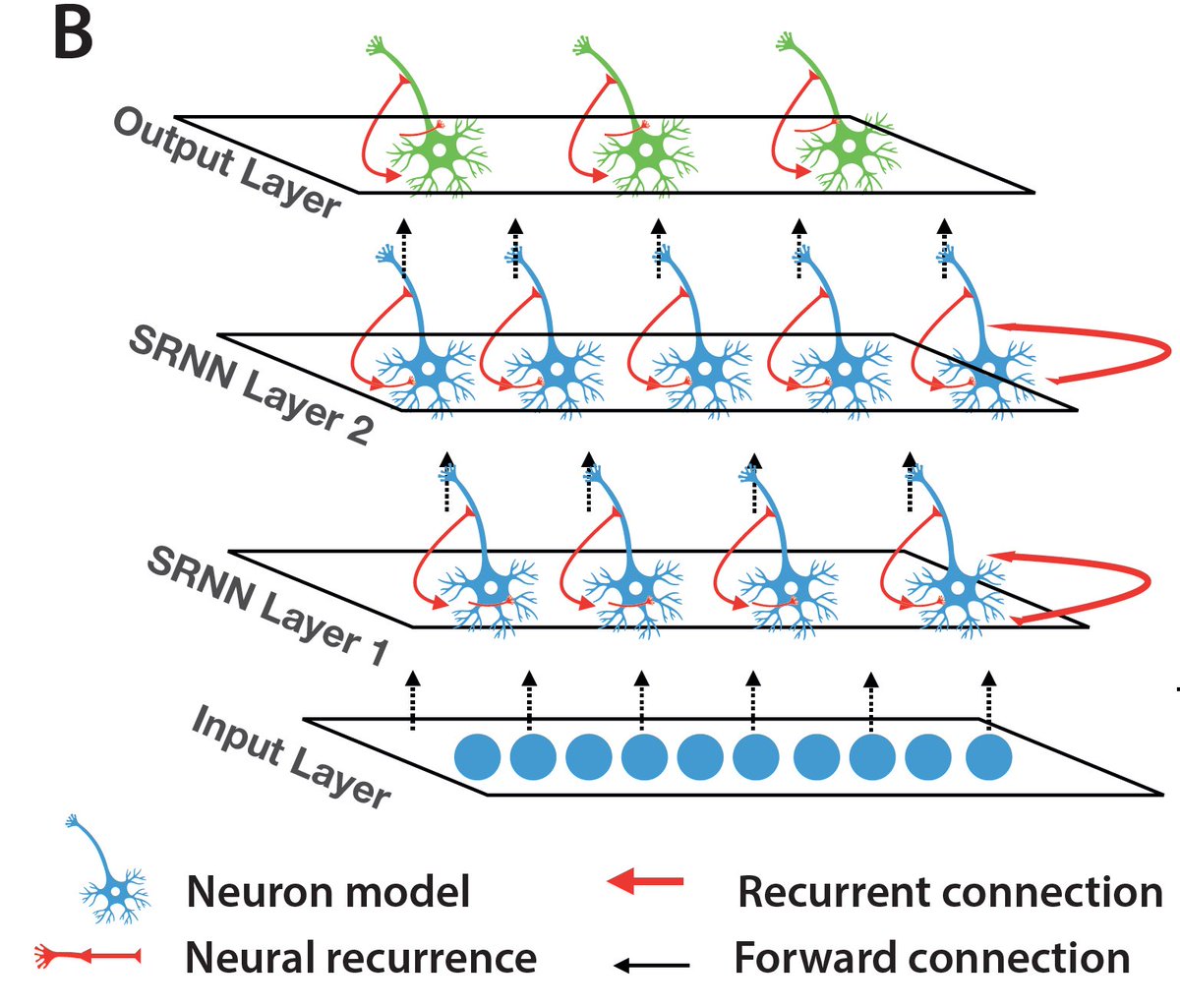



Jun 11
What makes an AI model good in 2026 is no longer its architecture. It's the part the lab won't publish. Everyone converged on the same linear hybrid, so the edge moved to data, RL, and tool use. My new piece: byin-cwi.github.io/MatrixWeb… #LLM
1
15
Jun 9
I updated my personal website:
byin-cwi.github.io/MatrixWeb…
I’ll use it to share research notes and personal reflections on learning algorithms, brain-inspired AI, LLMs, agents, scaling laws, memory, and neural network dynamics.
First posts are already online. More to come.
1
25
Bojian Yin retweeted

Jun 7
We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t 1}) → m_{t 1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: akarshkumar.com/smt/
arXiv: arxiv.org/abs/2606.06479

17
119
784
172,370
Bojian Yin retweeted

How do beta and gamma rhythms impact synaptic integration in pyramidal neurons? Our latest paper that examines this question studied this using a biophysically detailed pyramidal neuron model. Here’s what we found. A 🧵below.
elifesciences.org/articles/9…
1/10

2
32
138
8,185
Bojian Yin retweeted

May 26
Our NeuroAI study made it onto the cover of Nature Machine Intelligence (@NatMachIntell) ❤️.
In it, we demonstrate that a developmentally-inspired visual diet can drastically improve the robustness of ANN-based vision systems.
open access, open code, open weights, open science

4
29
161
9,342
May 19
Be the scientist, not just the researcher.
AI has already replaced much of research labor.
BUT it hasn’t replaced taste, judgment, courage, or the ability to ask the question that changes everything.
1
20
Bojian Yin retweeted

May 18
The "model weights are unreadable" excuse just died in one paper.
Neural networks have billions of parameters.
Nobody really knows what each one does.
A new paper introduces adVersarial Parameter Decomposition.
The method splits a model's weights into small, single-purpose subcomponents.
Each piece handles one specific job.
Things like emoticon prediction or gender identification.
Only a tiny fraction fires on any given input.
How they pulled this off:
1. Break weights into simple parts
2. Ablate components adversarially during training
3. Keep only what preserves behavior
The breakthrough is attention.
The technique decomposes attention computations even when spread across multiple heads.
That problem went unsolved for three years.
It scales beyond toy networks to real four-layer language models.
The authors now consider it a serious competitor to sparse autoencoders.
You can trace information flow through attribution graphs.
You can hand-edit specific behaviors and predict the outcome.
VPD makes weights legible.
4
23
165
13,132
May 14
The idea is simple
Take a PageIndex-style document tree.
Turn it into an evidence graph.
Use query-conditioned Personalized PageRank to let relevance flow across the graph.
Not just top-k chunks.
Not just one routed tree path.
Connected evidence.
Code: github.com/byin-cwi/PageRank…
1
1
48
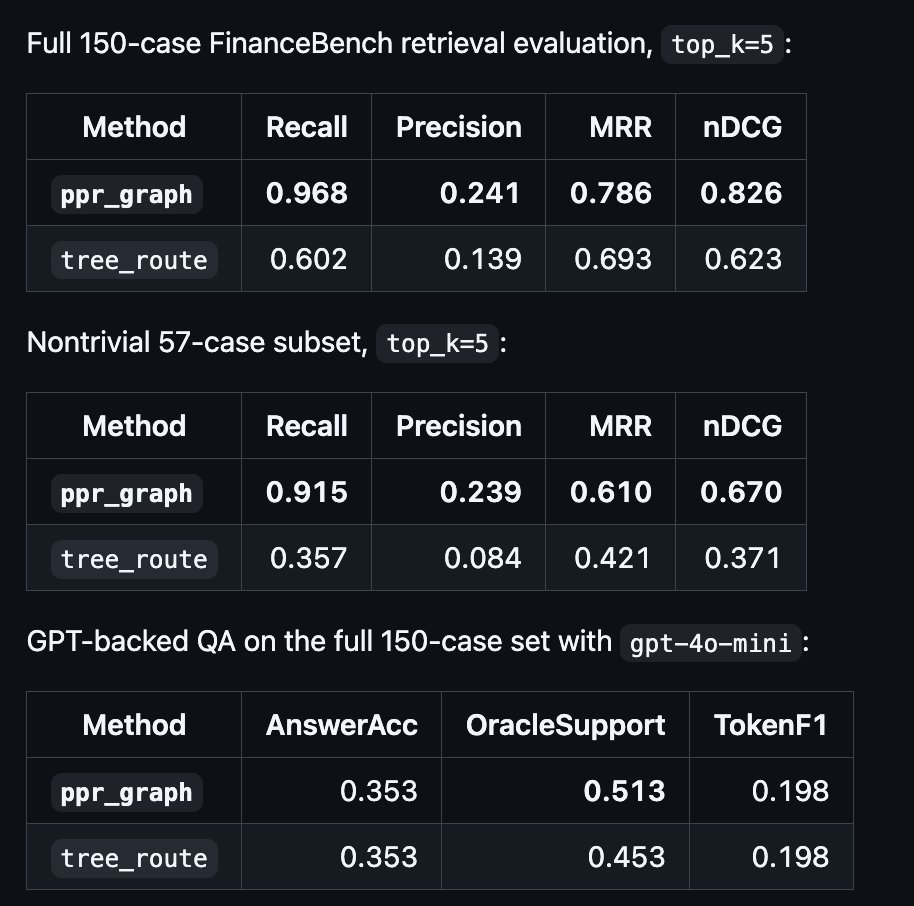
May 14
I ran a retrieval-only FinanceBench annotation-derived eval. Graph propagation helps recover evidence missed by local tree routing. So retrieval improved clearly.
Answer generation is the next bottleneck.
1
24
May 14
My current takeaway:
Standard RAG retrieves chunks.
PageIndex retrieves document structure.
PageRankRAG retrieves evidence paths.
For long-document RAG, structure may not be enough.
We may need relevance propagation over that structure.
Code: github.com/byin-cwi/PageRank…
50
May 14
The entire RAG stack may be missing one layer.
Vector RAG retrieves similar chunks.
PageIndex @PageIndexAI retrieves document tree nodes.
PageRankRAG retrieves connected evidence paths.
I built a graph propagation layer on top of PageIndex-style document trees.
1
1
62
May 8
Human brain & AI Workshop at @IJCAIconf in August 2026, Bremen, Germany hbai2026.github.io Organized by@chen_guozhang and colleagues. Join to hear from
@eckstein_maria
@AToliasLab
@NeuroNaud
@Pieters_Tweet and others!
Submit your papers by May 15 openreview.net/group?id=ijca…
1
4
733
Bojian Yin retweeted

🚀 OmniMouse is Accepted at ICLR 2026:
Poster Presentation in Rio on Friday, April 24, 3:15PM, P3-#1808
📝 Blog: enigma-brain.github.io/omnim…
💻 Code: github.com/enigma-brain/omni…
🤗 Model: hf.co/the-enigma-project/omn…
🤗 Data: hf.co/datasets/the-enigma-pr…
📄 Paper: arxiv.org/abs/2604.18827
1/
1
4
19
1,177
Bojian Yin retweeted

Apr 21
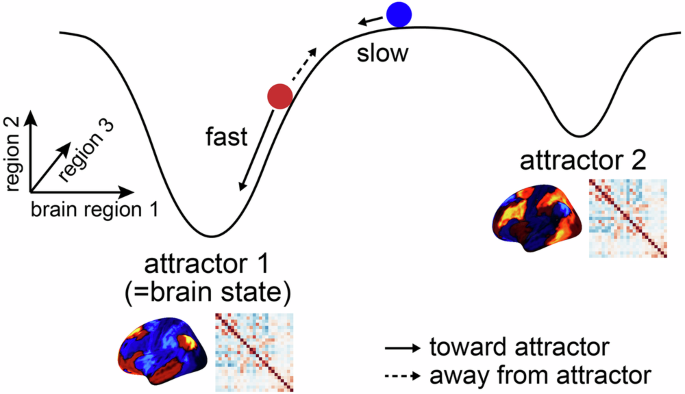
The geometry of neural dynamics along the cortical attractor landscape directly reflects changes in attention, as large-scale brain activity shifts across its hills and valleys depending on the state.
nature.com/articles/s41467-0…
3
47
172
25,452
Apr 11
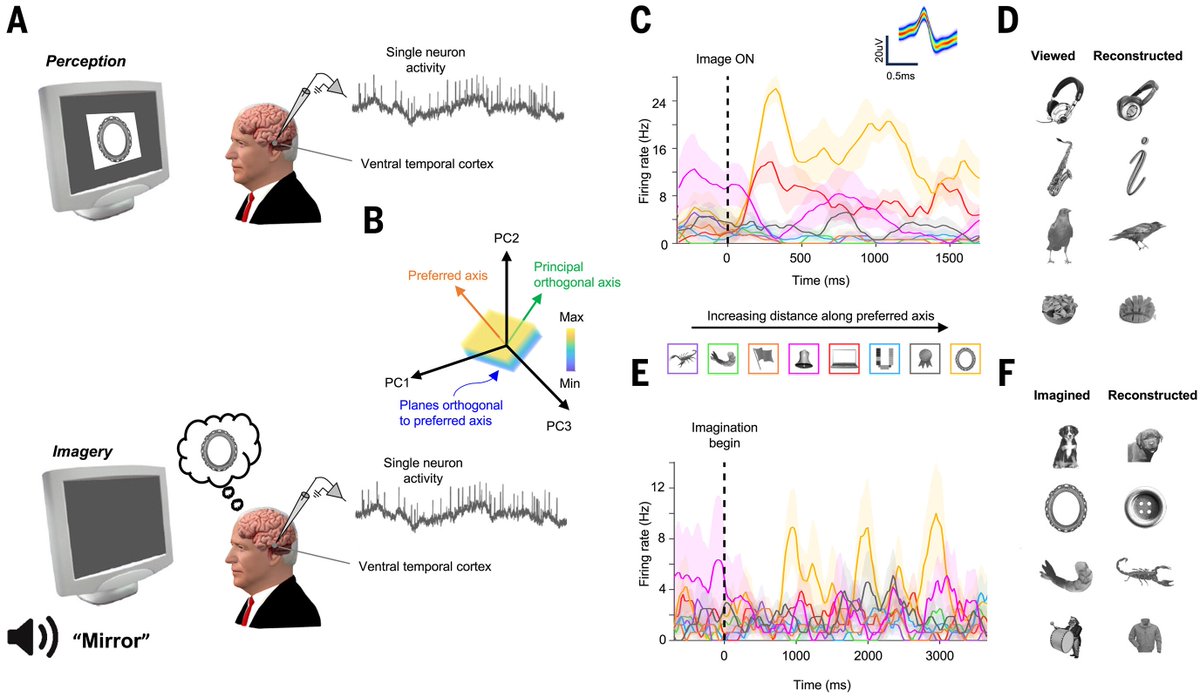
境由心现,识依缘起。

A shared code for perceiving and imagining objects in human ventral temporal cortex | Science science.org/doi/10.1126/scie…
1
49
Apr 11
📣 Submit your work to HBAI 2026!
The 5th International Workshop on Human Brain and Artificial Intelligence, co-located with IJCAI 2026, invites papers on the frontier of AI and brain research.
🗓 Deadline: May 15
🔗 hbai2026.github.io
#NeuroAI #BrainInspiredAI #IJCAI2026
Apr 10

#workshops 🚨Officially live: The 39 accepted workshops for IJCAI-ECAI 2026! 📅 Explore the sessions and start prepping your schedule:
👉 2026.ijcai.org/accepted-work…
#IJCAI2026 #ECAI2026 #Research #innovation #AI #Bremen #SummerAI
2
4
1,678
Bojian Yin retweeted

Mar 31
Preprint out arguing that we should build the techology to translate (compile) molecularly annotated connectomes into dynamics. I think this is incredibly important. arxiv.org/abs/2603.25713
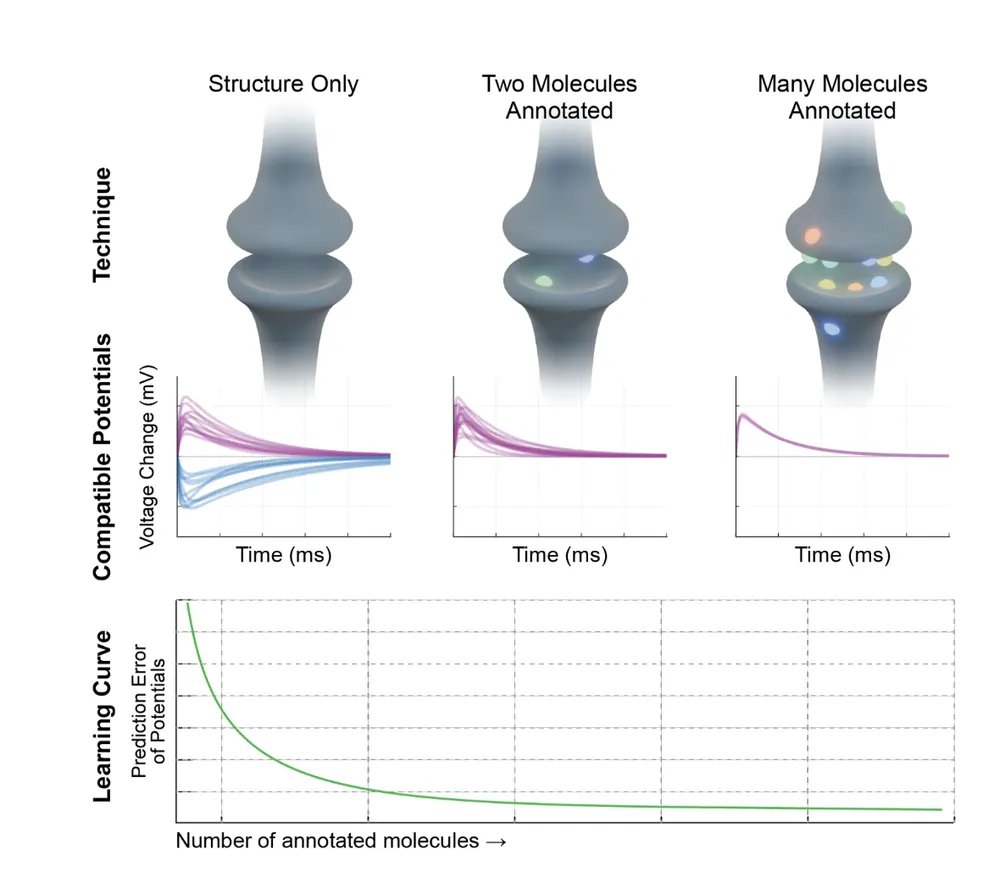

8
26
115
19,701

The weather's looking good for tomorrow's Artemis II launch, and our teams are getting the rocket ready for liftoff!
Read the latest updates on our mission around the Moon: go.nasa.gov/4tiFY4P
1,587
10,633
49,980
4,541,268
Mar 30
Coo000l project, it deserves 10k stars.
Mar 27

Google Turbo Quant running Locally in Atomic Chat
MacBook Air M4 16 GB
Model: QWEN3.5-9B
Context window: 50000
Summarising 20000 words in just seconds..
You can do 3x larger context window, processing 3x faster than before!
Community note
Atomic Chat is a rebranded copy of Jan (github.com/janhq/jan,41K stars) with git history deleted. 99% of code is unchanged.
TurboQuant support is from TheTom's fork, not original work. System prompt still says "You are Jan, trained by Menlo Research." No attribution given.
github.com/janhq/jan
github.com/TheTom/llama-c…
12