
Joined November 2017
- Tweets 1,986
- Following 2,878
- Followers 1,478
- Likes 7,955
107 Photos and videos





PattyCakes 🧲 retweeted

16h
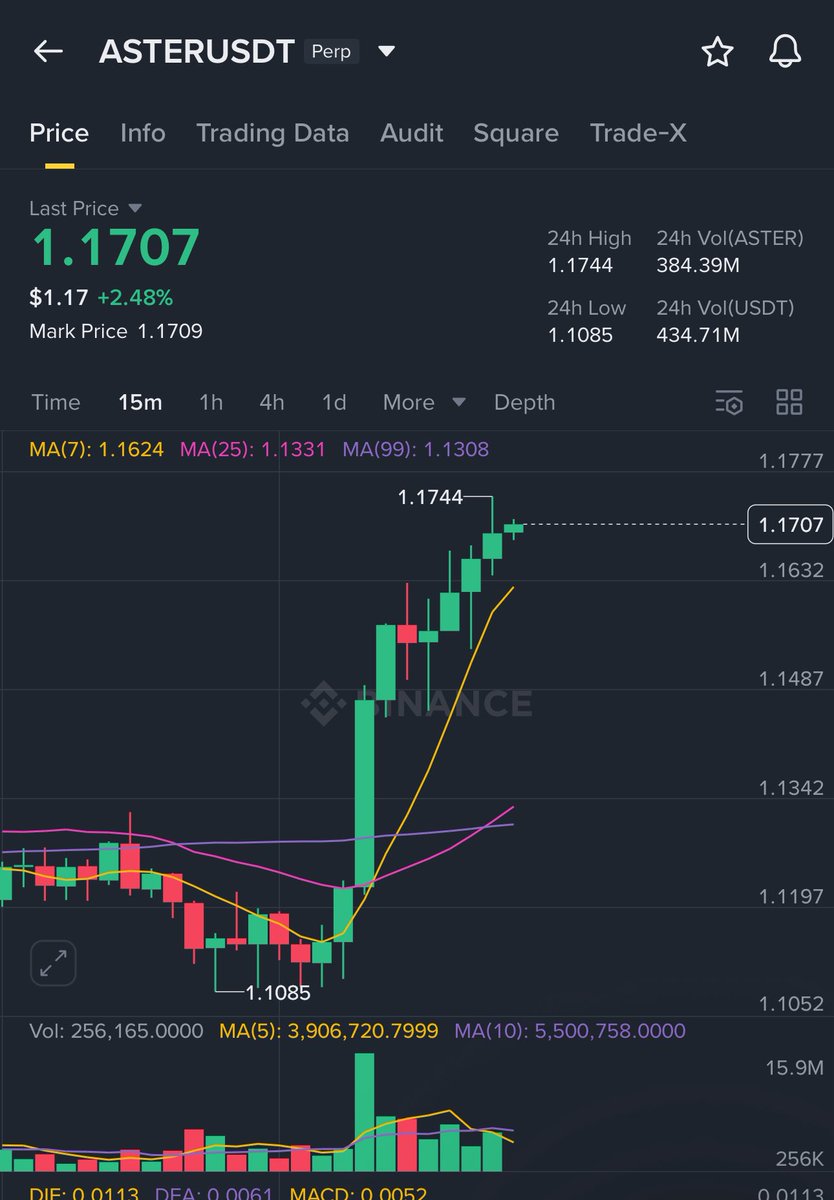
The first real, 1:1 backed tokenized stocks are coming.
→ Own actual tokenized shares of U.S. companies
→ Trade, hold, and redeem - all onchain
→ Automatically receive dividends
No derivatives, no IOUs.
Welcome to the future of stocks.
420
551
3,489
1,076,662


PattyCakes 🧲 retweeted

Jun 15
🔥 Vitalik recently shared a new idea for building stablecoins on Ethereum.
Instead of the current way — where you deposit ETH, borrow dollars against it, and risk getting liquidated if the price drops — he suggests splitting the ETH into two tokens. One token works like a stable dollar with much lower risk of big losses. The other token takes the upside when ETH goes up. These two tokens always add up to the original ETH, so there’s no debt and no forced liquidation when prices fall.
This approach could become a new trend in DeFi. It trades a small amount of price drift for a much safer and simpler system that doesn’t rely on constant price monitoring or sudden liquidations.
Ethereum has always moved forward because of people and teams willing to try new ideas early. We need more projects experimenting with concepts like this to help the ecosystem grow stronger.


115
163
1,090
109,083
PattyCakes 🧲 retweeted

Jun 13
The takeaway from Fable 5 being BANNED by the government: GET GOOD AT LOCAL MODELS SO YOU HAVE 100% CONTROL.
My entire weekend was going to be building my craziest ideas with Fable 5. That's now cancelled.
So instead of building with Fable this weekend, I've decided I'll go deep on local models:
1. Start with the runtime. Download Ollama or LM Studio first. This is the thing that actually runs models on your machine.
2. Match the model to your hardware. A model's size is measured in billions of parameters (7B, 32B, 70B). Bigger is smarter but needs more memory. Rule of thumb: a 7B model runs on almost any laptop, a 32B needs a good Mac with 32GB RAM, a 70B needs serious hardware like a DGX Spark or a maxed-out Mac Studio.
3. Know which model for which job. Qwen 3 is the best all-around choice for most tasks. DeepSeek for reasoning and coding. Gemma 4 when you need something tiny that runs on a phone. Llama when you want the biggest community and the most fine-tunes.
4. Quantization. You can shrink a model to run on weaker hardware with barely any quality loss. Look for versions labeled Q4 or Q5. This is how a model that "needs" a server runs on your laptop. Learning this one concept changes everything.
5. Connect it to your agent. Point Hermes or your agent stack at a local model.
6. Context window is your real constraint locally. Cloud models give you huge context for free. Local models make you pay for it in memory. A bigger context window eats RAM fast. Keep your sessions tight and your prompts lean or your machine chokes.
7. Learn to give local models tools. A smaller local model with web search, file access, and code execution beats a giant model with none. The capability gap closes fast when you wire up the right tools. The model is the engine but the tools are the wheels.
8. Fine-tuning is more accessible than you think. You don't need this on day one, but know it exists. You can take an open model and train it on your own data so it gets good at your specific domain.
I'll probably do a breakdown at some point on this @startupideaspod if people are into it.
The lesson from this ban is basically don't build your entire workflow on something that can disappear with a single letter. Own part of your stack. Local models are insurance.
It reminds me when people realized they don't own social media accounts. And then you saw people build email lists etc.
I remember running a startup and my biggest traffic source was organic FB. All of a sudden, algo changed, and I lost 99% of my traffic.
Same sorta moment (but bigger) for AI.
This is a wake up call.
345
438
4,222
458,700
PattyCakes 🧲 retweeted

Jun 13
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.

71
542
3,728
641,847
PattyCakes 🧲 retweeted

Jun 12
How am I only now finding out about appshots?
I was dragging screenshots into codex live a caveman.
192
163
5,503
394,001
PattyCakes 🧲 retweeted

$SPCX shares are priced at $135 for its $2 trillion IPO.
Its return is 100x-200x by 2035.
These 20 companies will benefit the most:
1. $BKSY ~$34
AI-ready Earth observation satellites feed SpaceX orbital intelligence layer.
2. $SPIR ~$20
Space data analytics monetizing SpaceX's growing orbital constellation.
3. $ACHR ~$5
Air mobility networks integrate with Starlink's low-latency infrastructure.
5. $SATL ~$7
High-resolution imaging complements SpaceX orbital AI compute constellation data.
6. $VIAV ~$50
Optical networking components critical for Starlink ground station upgrades.
7. $OUST ~$40
Sensor fusion tech supports SpaceX booster catch reusability automation.
8. $GILT ~$15
Satellite ground infrastructure scales alongside Starlink enterprise deployments.
9. $POET ~$11
Optical interposer chips slash data center power costs inside COLOSSUS AI cluster.
10. $ARQQ ~$12
Quantum encryption securing Starshield government classified orbital networks.
11. $TWST ~$74
Synthetic biology tools accelerate SpaceX long-term Mars life support research.
12. $LUNR ~$30
NASA lunar lander tech directly supports SpaceX Moon base buildout.
13. $AEVA ~$24
LiDAR sensors enable autonomous Starship landing and booster catch precision.
14. $KTOS ~$60
Defense tech partner powering Starshield national security satellite contracts.
15. $IONQ ~$58
Quantum compute layer powering next-gen orbital AI satellites.
16. $RDDT ~$178
Real-time social data feeds Grok's truth-seeking AI via X integration.
17. $RKLB ~$115
Small payload launch fills exact gaps Falcon can't efficiently serve.
18. $ASTS ~$97
Direct-to-phone satellite broadband. Starlink's closest competitor and partner.
19. $MTSI ~$375
RF semiconductors power Starlink phased-array antenna signal processing.
20. $BWXT ~$200
Nuclear propulsion R&D aligns with SpaceX Mars mission power requirements.
I'm definetly a buyer of $SPCX IPO and want to get it super cheap.
♻️ RESHARE this post and write 1 comment, I'll DM you the PRICE I want to buy $SPCX at this month.

342
1,125
6,562
1,856,343

Jenny Wen, head of design for Claude at Anthropic:
"the design process is dead."
what replaces it runs on machine-readable design systems
In a 1-hour conversation, Jenny Wen breaks down why the discovery -> mock -> iterate loop is dying and what designers do instead.
design system -> Claude Code -> every screen fixed at once, not one at a time
i rebuilt the same 10-screen dashboard twice:
~6 hours of restyling by hand vs ~40 minutes when the fix lived in the system.
how to build that system and hand it to Claude Code is in the article below.

14
66
762
178,398
PattyCakes 🧲 retweeted

Jun 12
Believe that we’re entering a super cycle for trading cards.
CT is finally paying attention to onchain collectibles, but most are writing it off as a symptom of a blow off top for Pokémon and other TCGs.
I think this view as wrong, and tokenized trading cards will actually grow many multiples from here… writing an article explaining my thoughts (should be out next week).
46
19
191
15,960
PattyCakes 🧲 retweeted

Jun 10
I watched a 100x developer use Codex
the way Pietro works will break your brain
watch this before you write another line of code
16
62
1,127
67,988
PattyCakes 🧲 retweeted

Jun 11
Open letter to @Polymarket and especially @shayne_coplan:
I've been trading on Polymarket for a long time. I am one of the biggest traders on the entire platform and I interact with it on a daily basis.
And at this point I'm seriously questioning whether the team has simply given up.
I'm not even trying to be dramatic. Wtf is actually going on?
Has everyone made enough money that nobody cares anymore? Is the team completely overwhelmed? Are priorities completely broken? Is there no leadership? Is it incompetence?
Because the current state of the platform is honestly embarrassing.
Every maintenance seems to follow the exact same script:
announce 10 minutes of downtime
start 20 minutes late
stay down for an hour
deploy changes that break multiple existing systems
leave the bugs in production for weeks
And somehow nobody seems concerned.
Example:
~1.5 weeks ago an update broke tick sizes. The matching engine started rejecting orders that matched the correct tick size after a tick size change was published.
This was immediately visible after deployment.
It's still broken.
Nobody seems to care.
Then for the last two days Polymarket's own RTDS feed, the feed used for all crypto markets, has been broken.
The issue was marked "resolved" 10 hours ago.
It still isn't resolved!
Did anyone spend literally 5 seconds checking whether data was actually being published before closing the incident?
Because it sure doesn't feel like it.
Communication is somehow even worse than the bugs.
Half the changes never get announced.
The other half are hidden in random Discord side conversations.
Major trading-impacting changes get silently rolled out with zero documentation.
You ask support.
They say they'll ask the team.
Then you never hear back.
Or you get the same canned response you've already received three times.
The team keeps saying communication will improve.
It never does.
Then there's the rebate and fee situation.
Taker tiers were supposed to launch on May 28.
A week later they still weren't live.
Nobody acknowledged the delay.
The docs still said May 28.
To this day there still hasn't been a single taker rebate payment.
And the official position is apparently that missed rebates won't be back-paid.
How is that acceptable?
How are traders supposed to adjust strategies, thresholds, and risk when nobody knows what fees they are actually paying, what rebates they are actually earning, or how much of the promised rewards the platform simply decides not to distribute?
That isn't transparency and it is clearly destroying trust.
The craziest part is that every update creates fresh opportunities for exploiters.
Just in the last couple weeks we've had:
queue position jump exploits
taker delay bypass exploits
ghost fill exploits
various matching and infrastructure bugs
order spam exploits
Millions of dollars have been extracted from legitimate users through platform failures.
The response?
Increase rate limits.
Seriously.
A huge amount of latency issues today are caused by order spam that is directly incentivized by broken infrastructure and exploitable mechanics.
Fixing the root causes would help.
Instead we get band-aids.
Which raises another question:
Does Polymarket have a testing environment?
Does it have staging?
Can updates be rolled back?
Because from the outside it honestly looks like production is the testing environment.
Every maintenance introduces new failures.
Every maintenance gets partially reverted.
Every maintenance creates more issues than it solves.
This shouldn't be happening at a company valued in the billions.
Meanwhile manipulation that has been repeatedly reported for months continues largely unchecked while manipulators keep extracting money from normal users.
And surprise:
Volume is declining.
Prediction markets as a whole are growing.
Yet Polymarket just posted its second consecutive month of declining volume.
Meanwhile Kalshi has become the clear market leader in many categories and is now outperforming Polymarket by large multiples in areas where Polymarket used to dominate.
Honestly?
It's not hard to see why.
Every serious trader I've spoken to says the same thing:
Kalshi feels stable.
Polymarket feels like you're one deployment away from disaster.
I know multiple people who would happily trade Polymarket full-time if they trusted the platform.
They don't.
Not because of competition.
Because they don't trust Polymarket itself.
My trust in this platform is at an all-time low.
And I genuinely don't understand what is happening internally.
Maybe the response will be that the team is busy with the World Cup or other initiatives.
Fine.
Then stop shipping half-finished features.
Stop deploying untested fixes.
Stop breaking live trading.
Slow down.
Focus on fewer things.
Do them properly.
The most concerning part is that so many decisions feel like they were made by people with no actual trading experience.
The product decisions show it.
The infrastructure decisions show it.
The market structure decisions show it.
Building the future of prediction markets requires understanding how markets actually function.
Right now it often feels like nobody is steering the ship.
I want Polymarket to succeed.
But from the perspective of someone who uses the platform every day, this is bordering on unusable.
@Polymarket
@shayne_coplan
What is going on?
109
55
708
69,668

I'm a major hypocrite
2 days after saying "loops are overhyped and inappropriate for 99% of people" I'm eating my words
EVERYONE should be build AI coding loops. Fable 5 completely changed my mind
After one-shotting a ridiculously large, full stack implementation I'm convinced we can set this model off to work autonomously on full applications for hours at a time
I'm coming out with a full beginner friendly loop guide soon that ANYONE can use to build autonomous AI building systems.
In the meantime I'd highly recommend taking these steps:
1. Set Fable 5 to high thinking
2. Create a skill called /spec
3. Have it make this skill ask you enough questions about the feature you want to build until it properly understands the feature in detail.
4. Have it save this spec to some sort of 2nd brain. I'm using Linear
5. Make skills for /build and /review
6. Have these skills do what they're named based on the specs that got created
I'll put out a full guide shortly that covers all of this in detail. It will be the most in depth, beginner friendly loop guide on the internet. No vague posting.
Loops are in and they're clearly the future
145
84
1,467
143,045
PattyCakes 🧲 retweeted

In February, we released our first full $NBIS model to X with and set a staggering $1,250 end of 2029 price target ($644 present value @ 18% discount rate) for our premium members.
We have decided to open our full model for free this week. (link in first comment)
Although all of our reports are free for readers, our price targets, portfolio allocations, present value calculations, and buy/hold/trim/sell zones are generally gated.
Before we release our new $NBIS model next week, we have decided to open up our most popular model to date for everyone on the X community who has supported our work on $NBIS and many other names in AI infra.
We appreciated you and hope you gain something on the way we think, what we got right, and more importantly what we got wrong.
It's not easy to set a target so high with confidence when Nebius was trading under 100 a share at the time, but it's much easier when you put in the work, do the research, and actually base price targets on real numbers.
The original report was published when most public analysis still treated Nebius as a GPU rental business.
Our report instead modeled the company around power availability, connected MW, ARR per MW, utilization, customer funding, enterprise mix, and dilution.
Several parts of that framework were correct.
We correctly identified Nebius as a vertically integrated AI infrastructure platform rather than a simple reseller of GPU capacity.
We correctly identified power and energization as the primary operating constraints.
We correctly modeled revenue as a function of connected and monetized MW rather than applying a simple revenue growth rate.
We correctly treated hyperscaler contracts as both revenue sources and financing instruments.
We correctly identified customer prepayments, deferred revenue, operating cash flow, secured financing, and asset-backed financing as central components of the capital stack.
We correctly identified Aether and the broader software layer as important to utilization, orchestration, customer integration, and long-term margin quality.
We correctly expected enterprise, AI-native, and inference workloads to become more important over time.
We correctly argued that equity outcomes would differ significantly across AI infrastructure companies depending on power control, capital structure, dilution, depreciation, and software integration.
We were materially above most public and Wall Street valuation estimates. Our original public model included:
Bear case: $752
Base case: $1246
Bull case: $1760
Those estimates were based on long-term infrastructure throughput and earnings power rather than near-term revenue alone.
Several assumptions now appear too conservative.
ARR per MW may be ramping faster than we expected.
The original model assumed ARR per MW would increase gradually as rack density improved, utilization rose, and enterprise and inference mix expanded.
Our modeled midpoint assumptions were:
2026: $9M per MW
2027: $11M per MW
2028: $13M per MW
2029: $15M per MW
The current revenue and ARR trajectory suggests the starting point and slope may both need to move higher.
Contracted power has expanded faster than expected.
The original report assumed more than 3GW of contracted power by the end of 2026.
The disclosed pipeline has since expanded beyond that level, increasing the potential long-term capacity base.
Contracted power is not the same as energized capacity, but it increases the top of the future deployment funnel.
The energization schedule may have been too conservative.
The old model assumed approximately:
2026: 900 connected MW
2027: 1,500 connected MW
2028: 2,000 connected MW
2029: 2,650 connected MW
That schedule already appeared aggressive at publication.
New site announcements, construction progress, and disclosed capacity targets suggest the ramp may occur faster or reach a larger endpoint than our original base case.
Customer funding appears stronger than expected.
The original model assumed that prepayments and contract-related cash flow would fund a meaningful portion of the buildout.
The increase in deferred revenue and operating cash flow suggests that customer commitments may be contributing more funding, and contributing it earlier, than our original assumptions.
We will distinguish carefully between deferred revenue, cash prepayments, working capital movements, and operating cash flow in the update.
Enterprise and AI-native mix may be ahead of our original assumptions.
The old model assumed the following revenue mix:
2026: 85% hyperscaler, 15% cloud and enterprise
2027: 80% hyperscaler, 20% cloud and enterprise
2028: 72% hyperscaler, 28% cloud and enterprise
2029: 65% hyperscaler, 35% cloud and enterprise
Current customer activity and product development suggest enterprise, inference, healthcare, life sciences, and AI-native workloads may be scaling faster than this path assumed.
The capital structure has become more complex.
The old model used scenario-based equity issuance assumptions.
The updated model must now include:
Basic share count
Prefunded warrants
Convertible notes
Potential conversion dilution
Interest expense
Cash raised
Customer funding
Secured financing
Asset-backed financing
The old share-count framework is no longer detailed enough.
CapEx will need to move higher.
The original model used approximately $18B as the midpoint of 2026 CapEx.
A larger contracted power base and faster site development may require higher spending.
Higher CapEx can increase long-term value if the capacity is efficiently funded and monetized. It can also increase execution and financing risk. The update will evaluate both sides.
The original report correctly identified the structure of the opportunity and was materially ahead of the market on valuation.
The new report will update the assumptions where Nebius has moved faster than expected and add greater precision where the original model relied on incomplete information.

19
44
281
178,277
PattyCakes 🧲 retweeted

Jun 5
For people who are worried about the market today, I get it. This stuff is very stressful.
So I put together a chart of all of the times the VIX (the "fear index" of the market) was up over 30% in a day (like today) in the past ten years.
23 out of 25 instances the market was higher one month later. The only two times it wasn't was Feb 2020 when Covid hit the economy in March 2020.
What is the underlying message? When people are afraid, they make bad decisions. Do the opposite.
Attached is a chart summarizing my results.

137
427
2,841
752,102
PattyCakes 🧲 retweeted

Jun 5
INSTEAD OF WATCHING A 2-HOUR MOVIE.
Watch this Anthropic Claude for Finance lecture.
It’s probably the best free hour in quant AI right now.
Bookmark it and watch it today, no matter what.
26
194
766
92,794
PattyCakes 🧲 retweeted

看见一个很离谱的论文……
如果你每天在收盘时买入美光科技,在第二天开盘时立刻卖出,几十年来会获得高达 138,330,342% 的收益。
但如果每天开盘买入,当天收盘时卖出,你的投资最终会几乎全部亏损-99.92%。
作者表示,这一切都是既得利益者的阴谋,所有市场都一样。
是的,包括咱们大 A。


424
999
11,318
3,525,414
PattyCakes 🧲 retweeted

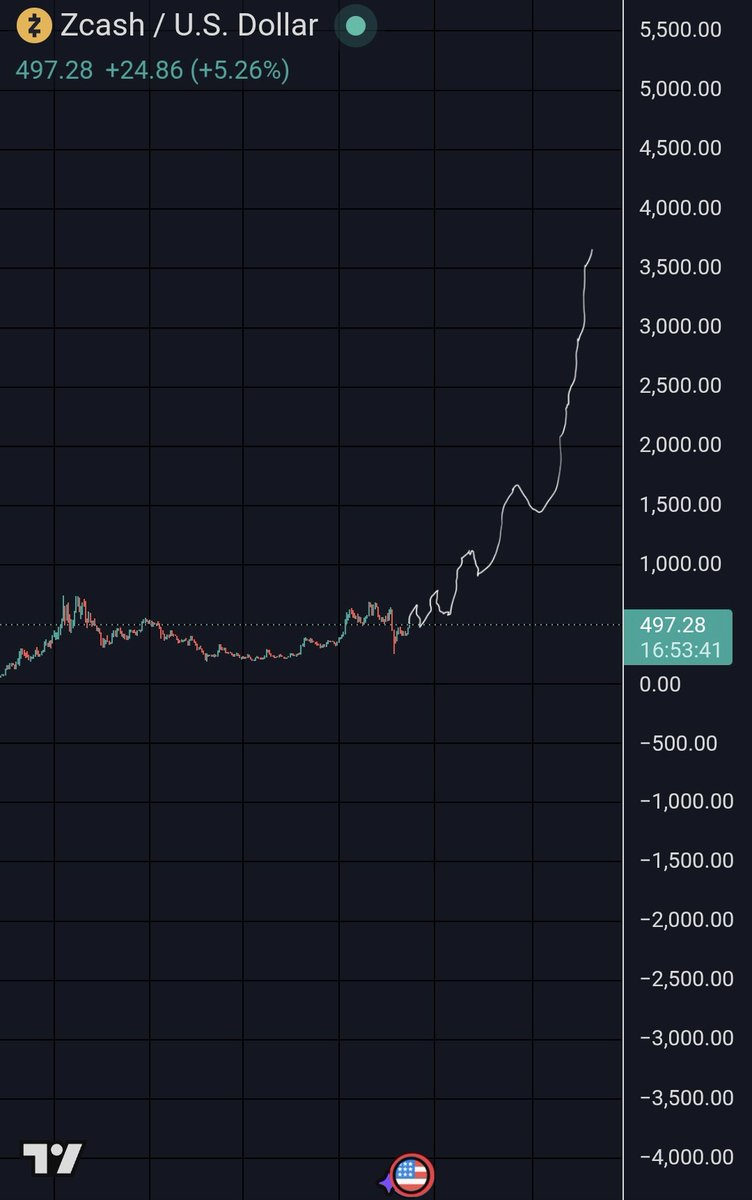
Jun 5
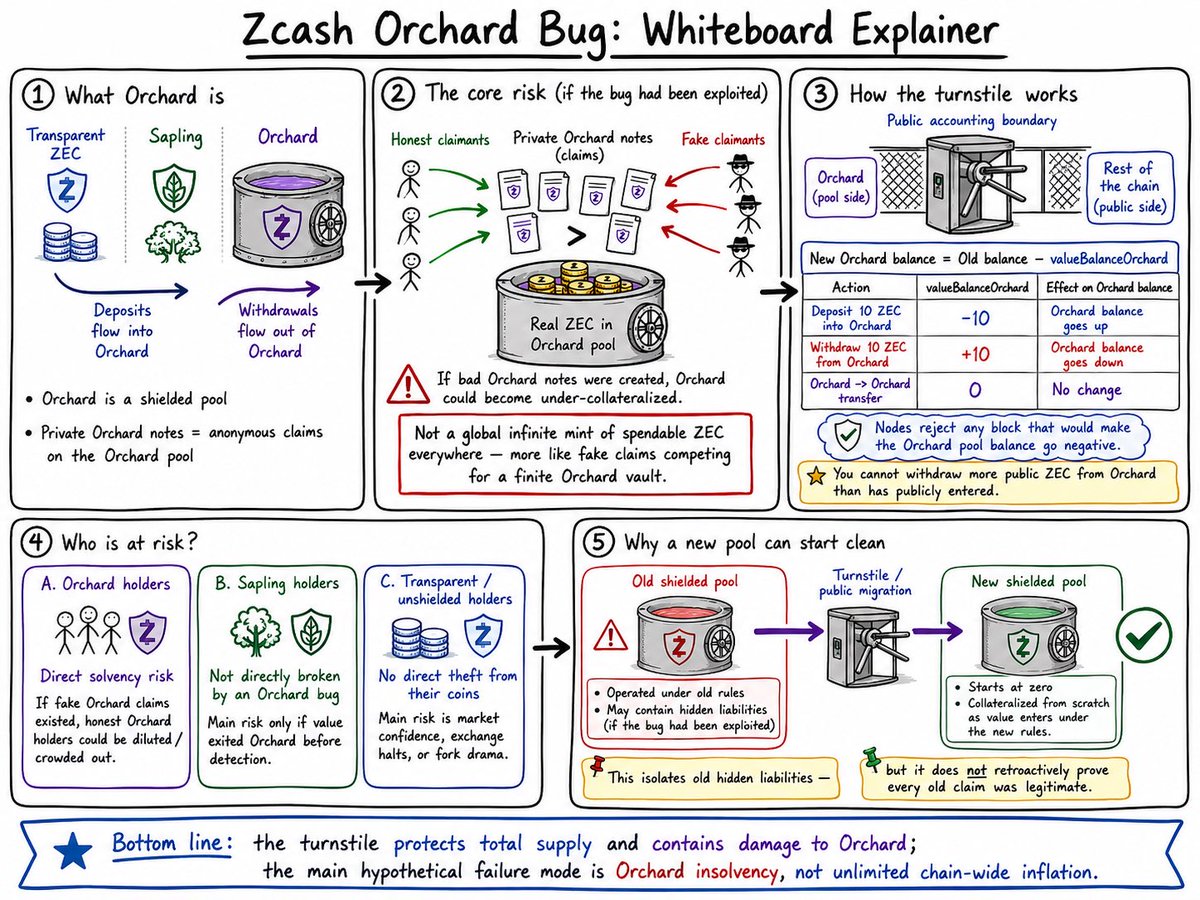
The way to understand the ZCash bug is it’s not infinite mint of ZEC itself. It’s more like the shielded pool (Orchard) could become insolvent. Think of it more like the KelpDAO hack for ETH.
Very little reason not to proactively unshield any ZEC today. Being early to the exit is always better in a bank run. Consider Orchard burned, and don’t re-shield until there’s a new pool with a clean history
69
155
921
197,567

The Hermes Desktop App Changes Everything (Full Setup):
00:00 Hermes Desktop changes the game
01:18 What Hermes Desktop actually is
02:33 Installing Hermes Desktop
03:48 Connecting a model provider
04:38 Adding API keys
05:02 Gateway setup
06:30 Telegram bot setup
08:29 Testing Hermes on Telegram
09:16 Skills, tools, and memory
10:10 Artifacts and files
10:47 Profiles and specialized agents
12:10 Why this matters
29
58
537
36,525
PattyCakes 🧲 retweeted

Jun 3
如何快速组建一个「一人美股投研团队」?
我最近在 Helio 里试了一下,不用招人,只要招 6 个 AI 同事
我给它们丢了一个任务:
分析 $MU 美光科技,告诉我值不值得买
然后这 6 个 AI 同事开始自动分工:
-市场情报官:抓市场新闻、价格走势和潜在催化剂
-财务分析师:拆收入、毛利、现金流、Capex 和估值
-行业分析师:判断 HBM、DRAM、NAND 的周期位置--和竞争格局
-商业分析师:分析商业模式、护城河和增长持续性
-市场叙事分析师:检查市场是不是已经过度乐观
-投资组合经理:汇总观点,给出仓位和风险建议
我不需要在 6 个聊天框里分别问问题,也没有把答案复制来复制去
它们会在同一个频道里互相补充、质疑、修正,最后给出一个接近“投研小组会议纪要”的结论:
买入信心 8/10
分批建仓
财报后确认 HBM 变量
目标 $1,250-$1,600,止损 $780
这也是我觉得 Helio @helioim_ai 和普通 AI 工具最大的区别
普通 AI 工具是:
我问,AI 答
但在 Helio 里更像是:
我定目标,AI 团队开始工作
这些 AI 同事有身份、有职责、有频道、有分工,也有需要人类确认的决策边界
它不是让 AI 躲在一个小窗口里等你问问题,而是让 AI 直接进入你的工作频道
如果说 ChatGPT 让人少打字,Helio 想做的是让人少操心
这可能是我最近试过最像“AI 同事”的产品,大家可以去试试
#AI #Agent #AINativeWorkforce #美股




89
49
231
23,562