
Your open-source AI ally. We are committed to making production-grade AI inference as accessible and reliable as electricity, powered by vLLM.
Joined October 2023
- Tweets 531
- Following 1,366
- Followers 1,124
- Likes 690
98 Photos and videos













EmbeddedLLM retweeted

18h
vLLM v0.23.0 is out! 408 commits from 200 contributors (63 new). 🎉
Highlights: DeepSeek-V4 matures across backends (TRTLLM-gen attention kernel, sparse MLA decoupled from V3.2, EPLB for the Mega-MoE), Model Runner V2 now default for Llama Mistral dense models, Gemma 4 Unified (encoder-free) MTP, a maturing Rust frontend, multi-tier KV cache offloading with an object-store tier, and a unified reasoning tool-call parser.
Thread 👇

14
38
405
33,575

Jun 12
Singapore has come a long way. 🇸🇬
From AI adoption to AI infrastructure, the local ecosystem is now contributing to the layers production AI depends on: @PyTorch, @vllm_project, inference, sovereign AI, and open-source infra.
Proud to see @RedHat_AI, @inferact, and @EmbeddedLLM building alongside APAC AI community.

The inaugural PyTorch Meetup Singapore brought together engineers, researchers, and community builders to talk about everything from vLLM project updates to the broader question of sovereign intelligence.
Read the full technical recap and find presentation slides in our latest blog: bit.ly/4vdcPJU




1
3
8
432
EmbeddedLLM retweeted

Jun 12
Incredible collaboration from the team!
Beyond basic inference support, we also have day-0 speculator and RL support🔥
Jun 12

🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
2
26
2,030
EmbeddedLLM retweeted
Jun 12
🎉 Congrats to @MiniMax_AI on releasing MiniMax M3! Frontier coding and agentic capabilities, native image and video input, computer use, and a 1M-token context window, all in a single open model.
At the heart of M3 is MSA, a new sparse attention architecture: instead of attending densely over the full KV cache, each query scores 128-token KV blocks and runs attention only over the top blocks. That is what makes 1M-token context practical to serve.
M3 runs in vLLM with day-0 support, verified on NVIDIA and AMD hardware:
✨ MSA sparse attention with dedicated prefill and decode kernels
✨ 1M-token context serving with prefix caching and chunked prefill
✨ BF16 and MXFP8 checkpoints, with MoE backends for both Hopper and Blackwell
✨ Native multimodal input (image video)
✨ Tool calling, reasoning parsing, and thinking-mode control for agent workloads
Day-0 support like this is a true team effort. Grateful to the teams at @MiniMax_AI, @NVIDIAAI, @AIatAMD, and @inferact, and to the vLLM community for making it happen. 🙏
Deep dive into the implementation, kernel work, and deployment recipes:
🔗 vllm.ai/blog/2026-06-12-mini…
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
4
31
302
38,898
EmbeddedLLM retweeted

Jun 9
vime is a reference implementation for one reason only: make @vllm_project the best rollout engine for RL. This helps us better optimize vLLM for the whole ecosystem like @NovaSkyAI SkyRL, @PrimeIntellect Prime-RL, @nvidia NeMo-RL, @verl_project, and more!
A wise man in leather jacket said: "We don't build PowerPoint slides and ship the chips. We build a whole data center. And until we get the whole data center built up, how do you know the software works? how do you know your fabric works?" - @NoPriorsPod
Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
1
3
52
7,072
EmbeddedLLM retweeted
Jun 10
Congrats to @GoogleDeepMind on DiffusionGemma 🎉 A 26B diffusion language model on the Gemma4 backbone, and the first dLLM natively supported in vLLM.
It denoises 256-token blocks in parallel instead of generating one token at a time: 1200 output tok/s at batch size 1 on a single H200 (FP8).
Built on model runner v2's ModelState plus the existing speculative decoding path, with minimal scheduler or runner changes. FP8 and NVFP4 checkpoints are on the @RedHat_AI hub. Thanks to the @GoogleDeepMind, @RedHat_AI, and @NVIDIAAI teams!
🔗 vllm.ai/blog/2026-06-10-diff…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
14
51
521
39,079
EmbeddedLLM retweeted
Jun 9
Today we're excited to introduce vime — a simple, stable, and efficient RL framework for LLM post-training in the vLLM ecosystem.
Built on slime's proven training design and powered by vLLM inference, vime brings another strong option to the growing vLLM post-training ecosystem.
Our goal isn't a one-size-fits-all framework. We want users with different needs to find the right vLLM-ecosystem choice for their workflows—whether that's vime, NeMo RL, OpenRLHF, verl, or others.
More choice. More interoperability. More innovation.
Learn more: vllm.ai/blog/2026-06-09-anno…
#LLM #RLHF #PostTraining #vLLM
8
54
509
42,282
EmbeddedLLM retweeted
Jun 8
🎉 Meet vLLM-Omni v0.22.0, a major upgrade for omnimodal world models and production-grade multimodal serving.
🌍 Day-0 @NVIDIAAI Cosmos 3 world models: text, image, audio, video, and action, in and out.
🤖 Robot serving: DreamZero OpenPI realtime API.
🎙️ Production TTS: Qwen3-TTS, Qwen3-Omni, VoxCPM2 and more.
🎨 Faster image/video/diffusion: Wan 2.2, HunyuanVideo 1.5, LTX-2.3.
⚡ Broader quantization (FP8/INT8, MXFP4/MXFP8, W4A16, ModelOpt) and hardware coverage.
339 commits, 124 contributors, 52 of them new. Thank you all. 🙌
🔗 github.com/vllm-project/vllm…
10
65
442
41,273
EmbeddedLLM retweeted
Jun 4
🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models.
Three labs, each on a live vLLM server:
- Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff
- Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics
- Benchmark: simulate traffic with GuideLLM and check quality with lm-eval
A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4.
~1.5 hours, 9 lessons, 3 labs. Free on DeepLearning.AI.
📝 Read more: vllm.ai/blog/2026-06-03-deep…

New short course: Fast & Efficient LLM Inference with vLLM, built in partnership with @RedHat and taught by @cedricclyburn.
Learn to quantize an open-source LLM, serve it with vLLM, and benchmark your deployment across speed, cost, and accuracy.
Free to enroll: hubs.la/Q04jXfpR0
7
39
329
55,873
EmbeddedLLM retweeted
May 30
vLLM ❤️ AMD
1
4
57
5,656
EmbeddedLLM retweeted
May 29
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!
May 28

Excited to share some of our work on improving vLLM for RL!
A number of RL frameworks, including SkyRL, use vLLM for inference, and we’ve noticed some common problems:
1. Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across frameworks.
2. Asynchronous RL is prone to break at scale, especially in P/D and DPEP deployments.
We’ve been working on improving both!
1
10
64
5,440
EmbeddedLLM retweeted
May 29
We've shipped two major upgrades for RL✨!
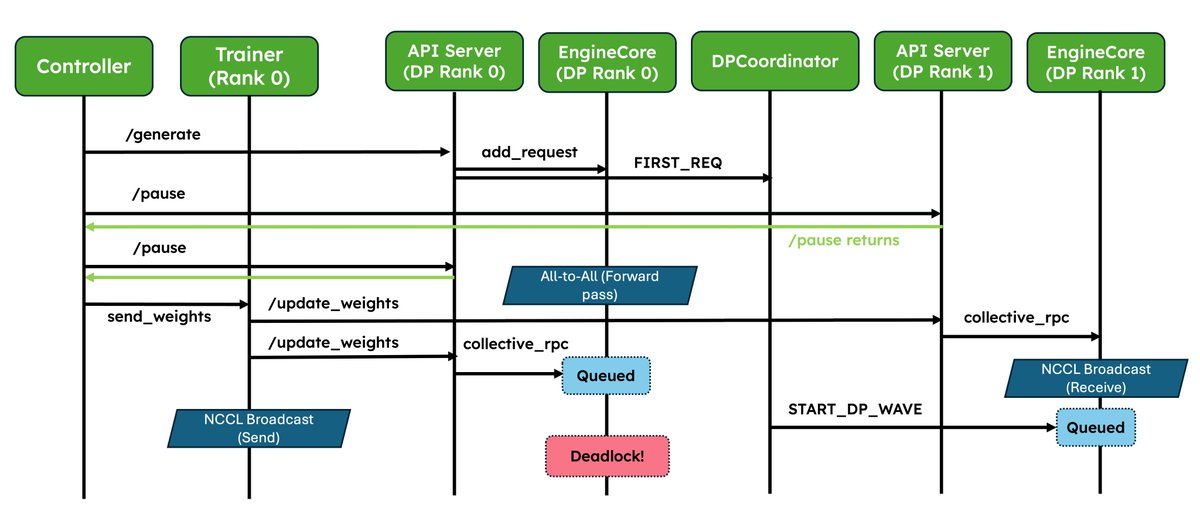
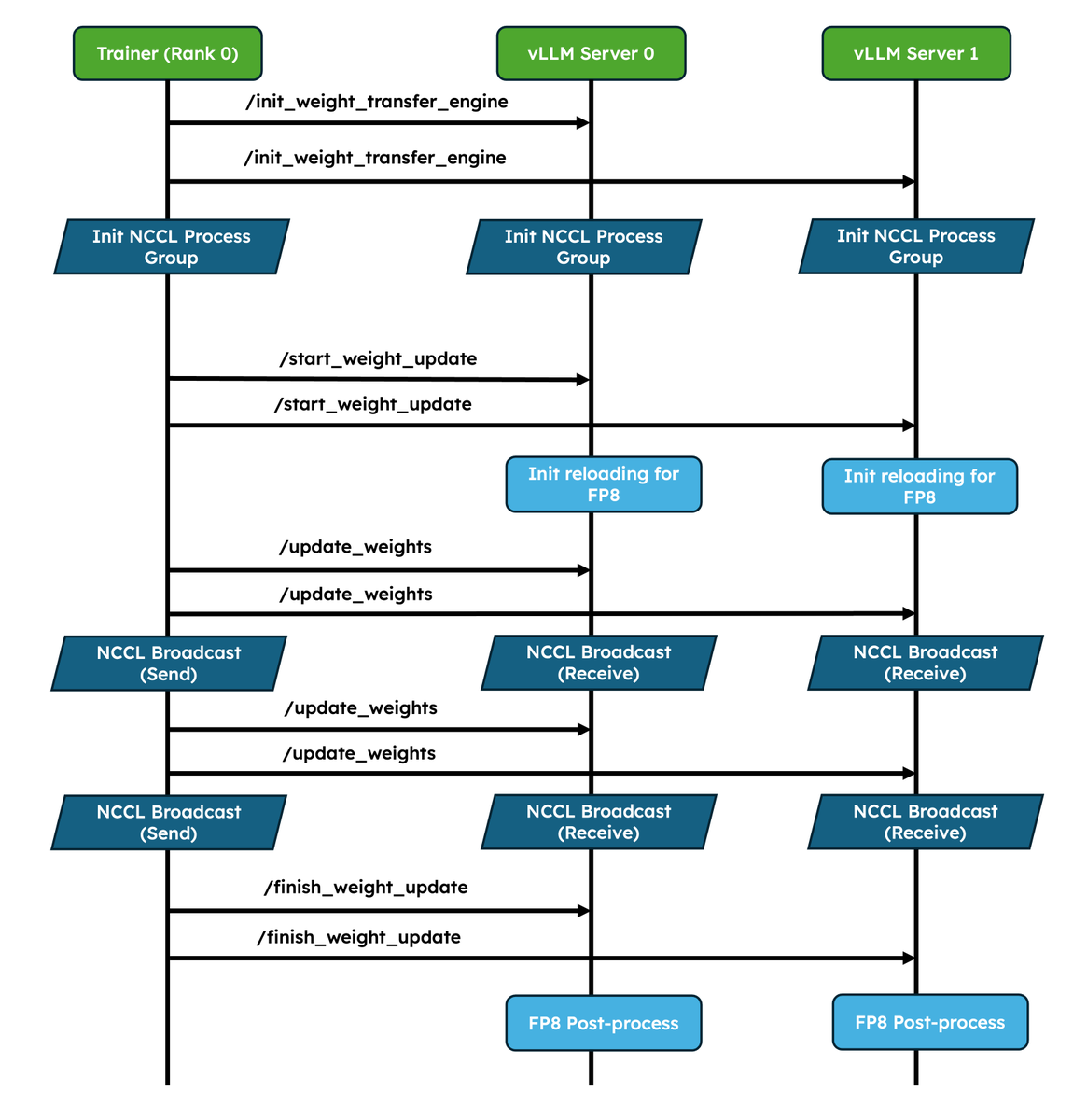
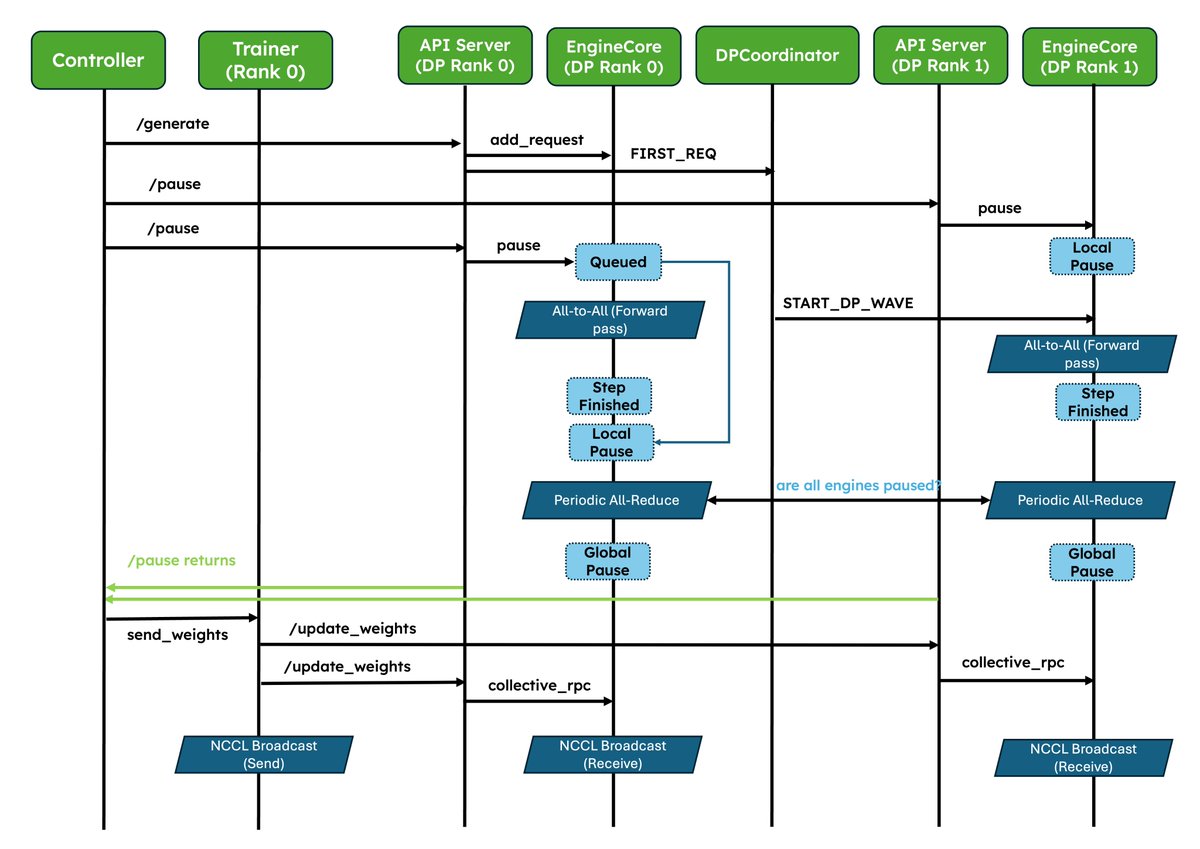
1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own.
2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups!
In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat.
More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇
vllm.ai/blog/2026-05-28-nati…
2
28
214
11,610
EmbeddedLLM retweeted
May 26
🦀 rustifying vLLM, one part at a time, great work @BugenZhao!
May 26
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
github.com/vllm-project/vllm…



4
7
68
6,071
EmbeddedLLM retweeted
May 26
🦀 The Rust frontend is officially merged into vLLM!
As GPUs get faster, the frontend has become a real share of CPU time. The new Rust frontend is a drop-in alternative to the Python API server — same engine, same ZMQ boundary. Opt in with VLLM_USE_RUST_FRONTEND=1.
Early numbers: on a preprocess-heavy workload, ~837 req/s vs ~162 req/s for default Python — ~5x in a single process.
A few design choices we're excited about:
• Layered crates with clear boundaries
• Stream-native pipeline — non-streaming for free
• Builds on stable Rust
Huge thanks to @BugenZhao from @inferact for introducing the work at @PyTorch Meetup Singapore.
github.com/vllm-project/vllm…
26
104
926
84,884

Great cohosting this luncheon with @a16z and Mirendil at MLSys 2026 yesterday! 🙌
We brought together top researchers and AI systems engineers for an afternoon of rich conversations on @vllm_project, the frontier of inference, and where AI systems are headed next.
Huge thanks to everyone who joined — the energy in the room was something else. This is exactly the kind of cross-pollination between labs, infra teams, and industry that pushes the whole stack forward.
More to come. 👀
#MLSys2026 #vLLM
2
8
26
7,098
EmbeddedLLM retweeted
May 21
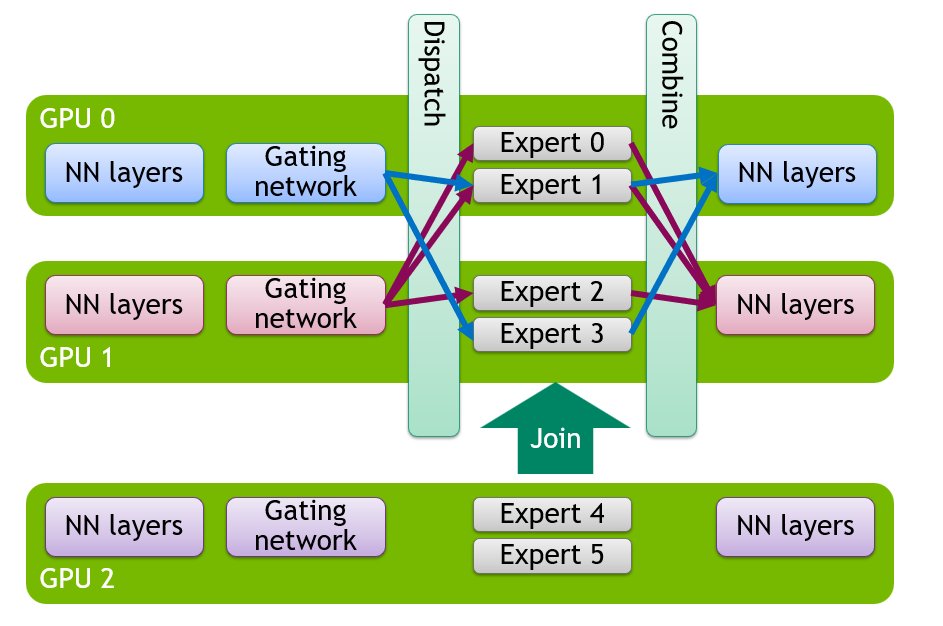
A vLLM MoE deployment's DP/EP topology used to be locked in at launch — scaling or swapping config meant a full restart, in-flight traffic dropped. Elastic Expert Parallelism changes that. One API call resizes a live deployment:
curl -X POST localhost:8000/scale_elastic_ep \
-d '{"new_data_parallel_size": 16}'
Under the hood: standby comm groups span the target topology, EPLB redistributes experts across the new EP group, and weights are transferred directly between GPUs over NVIDIA NVLink/RDMA. The same runtime reconfiguration path is what fault-tolerant serving needs: evict failed ranks, redistribute their experts, bring replacements back, no restart.
Thanks to @NVIDIAAI, Sky Computing, @anyscalecompute, @RedHat_AI, and the community.
📖 vllm.ai/blog/2026-05-14-elas…
7
23
210
25,391
EmbeddedLLM retweeted
May 20
🎉 Day-0 vLLM support for Command A ! Congrats to @cohere on their most powerful open-source model yet.
🧠 218B MoE / 25B active, Apache 2.0
🌍 Multimodal 48 languages
⚡ Runs on as little as 2× H100s @ W4A4
Serve it now in vLLM! 🚀
📖 cohere.com/blog/command-a-pl…

Introducing: Cohere Command A
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
6
25
201
30,790
EmbeddedLLM retweeted
May 20
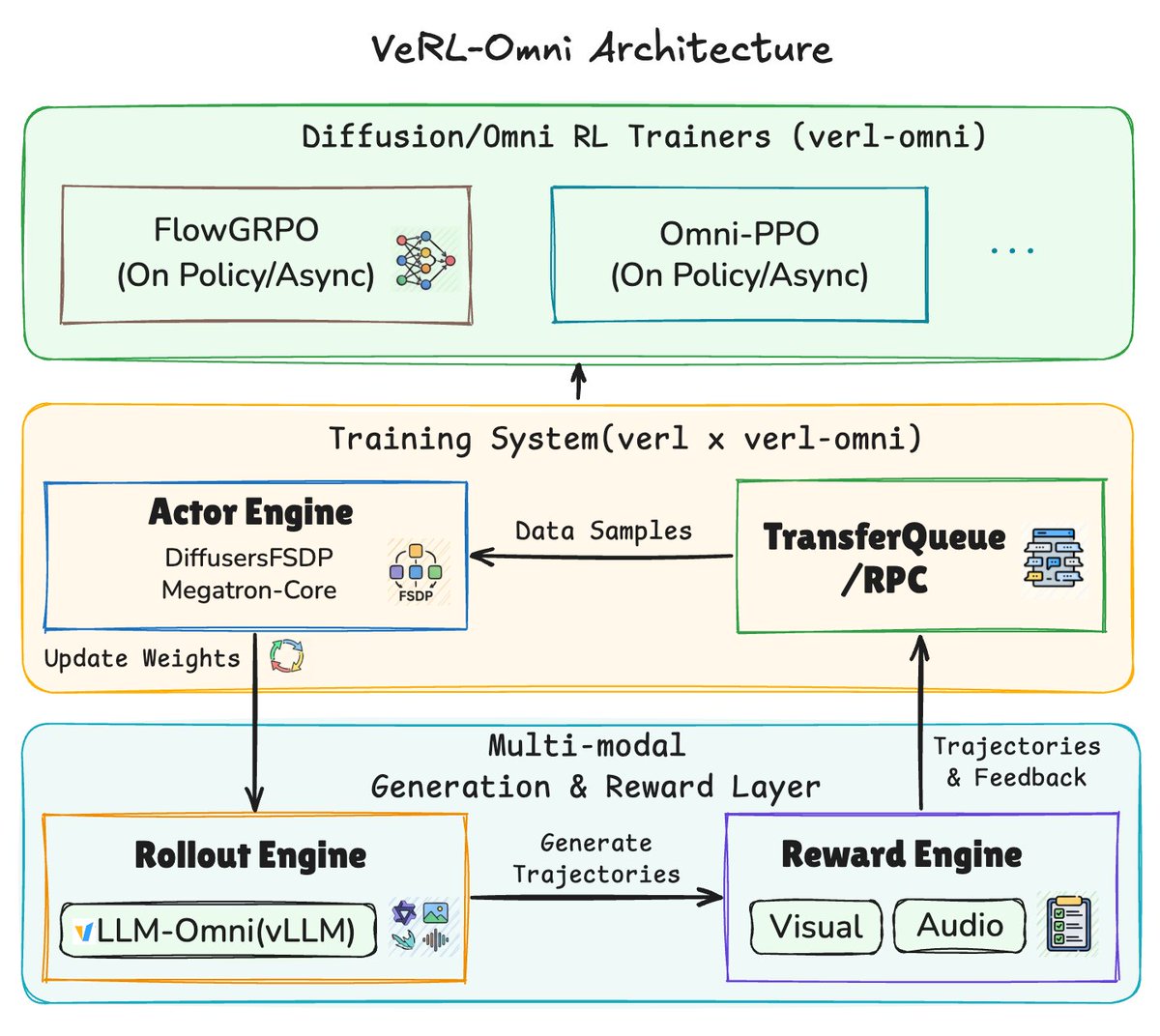
🎉 Congrats to the VeRL-Omni team on the pre-release of a general RL post-training framework for multimodal generative models. Built on verl vllm-omni.
vLLM-Omni handles the multimodal rollout with step-wise continuous batching and embedding caching; vLLM serves the VLM-as-judge / OCR reward model, overlapped with rollout and training. In the Qwen-Image OCR demo, moving the reward to its own GPU cuts per-step wall-clock by ~14%.
Released: Qwen-Image with FlowGRPO / MixGRPO / GRPO-Guard. BAGEL and Qwen3-Omni-Thinker PR-ready.
Excited to push multimodal generative RL forward together with VeRL-Omni and the broader community. 🙌
📖 vllm.ai/blog/2026-05-14-verl…
🔗 github.com/verl-project/verl…
6
23
158
22,636
May 13
$AMD is unstoppable now.
@AIatAMD ROCm flywheel is spinning hard: persistent MI355X access for @vllm_project
@EmbeddedLLM is proud to help power that loop.
AI inference is infrastructure.
And the next era of AI infra won’t be won by default distribution. It’ll be won by kernels, compilers, runtimes, and relentless execution.
We’re here for that fight. 🚀
May 13

The shock came when on Day 0 DeepSeekv4 launch, since the community vLLM/SGLang maintainers only had access to NVIDIA GPUs, they were only able to add Day 0 NVIDIA GPU support. Since then, AMD has finally priotitzed with actions and just not words by contributing an 2.5million dollar 9 node Mi355X cluster with 8x400G Pollara NICs towards open source @vllm_project maintainers including (@EmbeddedLLM maintainers, @simon_mo_ and others) & an 1.1 million dollar dev 4 node MI355 dev cluster. 2\4
2
7
218
EmbeddedLLM retweeted
May 11
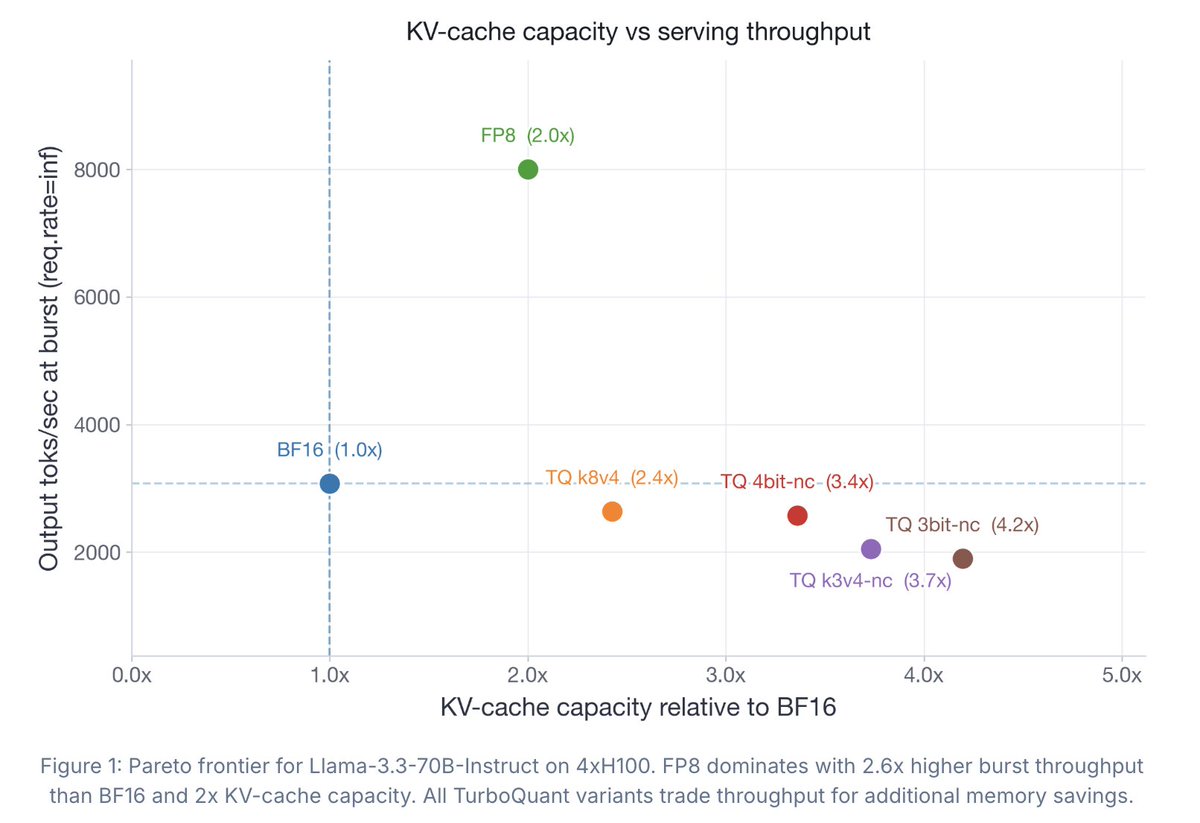
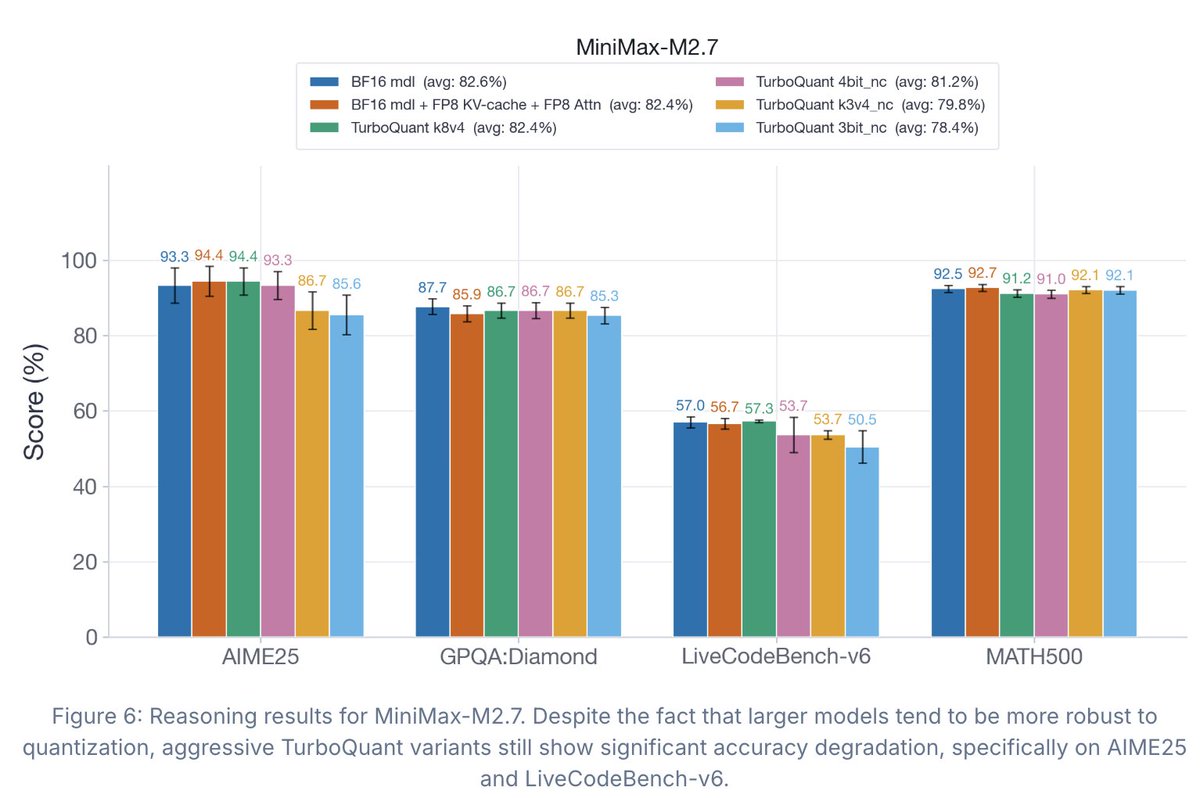
Great read from the @RedHat_AI team — a comprehensive investigation into TurboQuant in vLLM, with FP8 and BF16 as reference baselines: 4 models (30B to 200B , decoder-only and MoE) and 5 benchmarks covering long-context retrieval and reasoning, all on the stable vLLM 0.20.2 release.
If you're considering TurboQuant for your workload, this is the data to start from.
📝 vllm.ai/blog/turboquant
May 11

TurboQuant has drawn a lot of attention recently, but the accompanying evals didn't tell the full story.
So we ran what I believe is the first comprehensive study of TurboQuant: where it helps, where it falls short, and how it impacts accuracy, latency, and throughput.
Findings:
9
40
282
34,499