
Joined July 2025
- Tweets 276
- Following 32
- Followers 59
- Likes 103
112 Photos and videos










Pinned Tweet

Apr 23
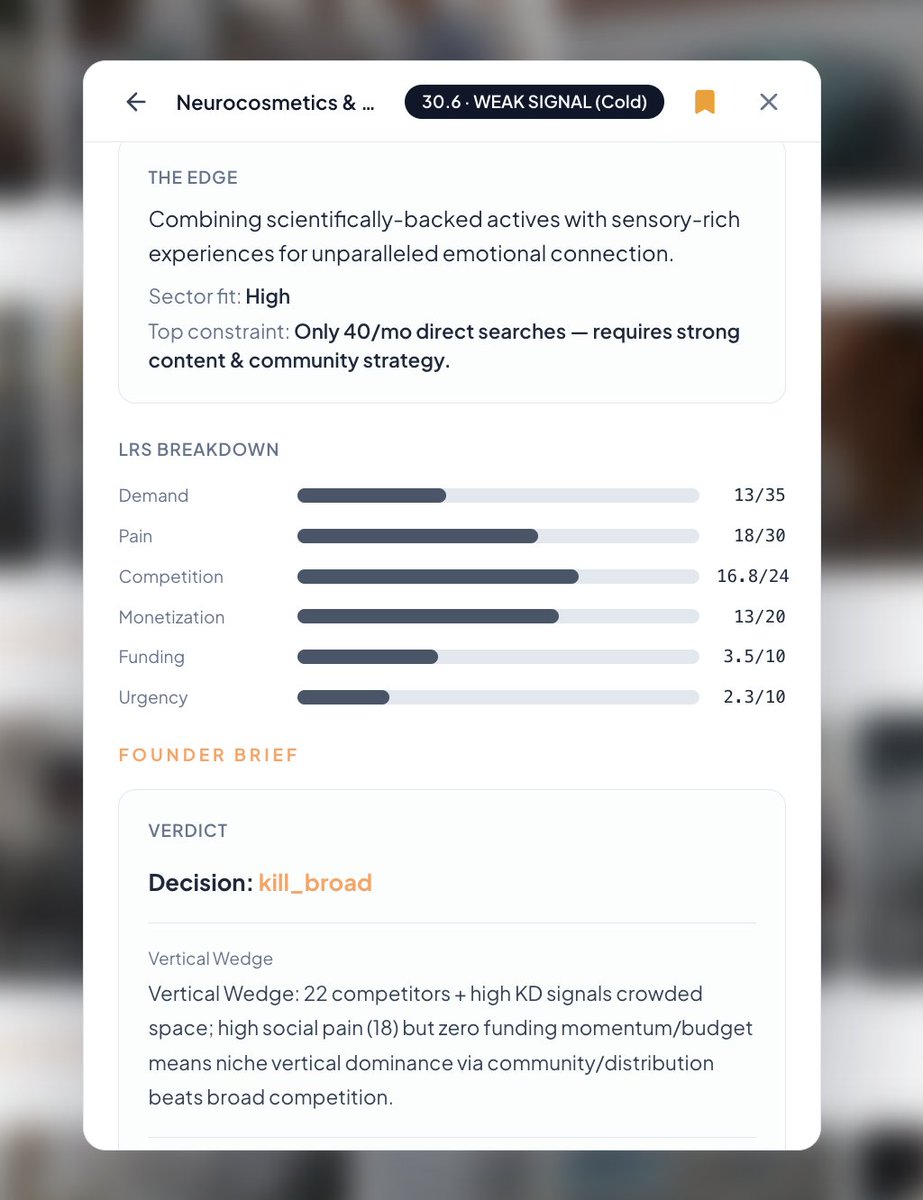
Neurocosmetics: 30.6/100.
Press calls it "the future of beauty."
Our 6 live signals say otherwise — low search growth, zero funding last 6 months, saturated SERP.
Fluenta scores every startup idea like this.
Free preview → fluenta.space

4
4
9
343
Jun 12
YC Demo Day, June 16
The biggest stage in startups opens in four days. The Spring 2026 batch puts 194 companies on stage - ycombinator.com/companies?ba…. We scored all 194 before they walk on, then split the batch into four groups and we're dropping one a day.
The method: 6 public signals, a 0 to 100 Launch Readiness Score (LRS). Search demand, social pain, competition, monetization, funding, urgency. Public data only. The outside view every investor in that room runs before the meeting.
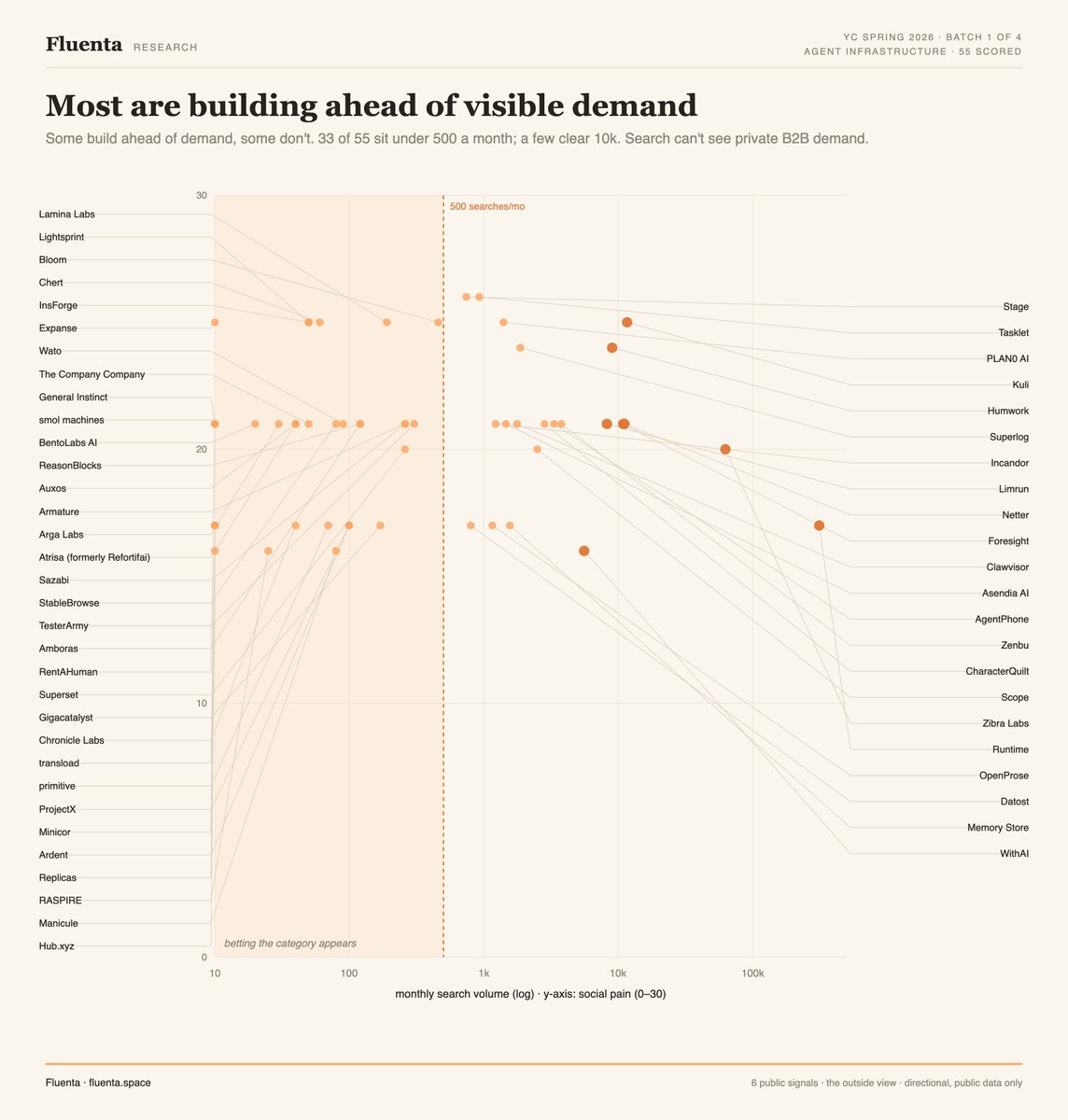
Group 1 of 4: Agent Infrastructure. The picks and shovels. 55 startups building the rails everyone else builds agents on. Group average: 50.3.
Highest scored:
1. Kuli, 65.5, automated influencer marketing - @maradoh22
2. Armature, 63.2, product analytics for agents - @Totzenberger
3. Superlog, 63.2, self-healing logging - @superlogYC , @ArseniySvist , @nicolomagnante
4. Memory Store, 62.4, memory layer for agents - @memorydotstore , @IshitaJindal17 , @diwanksingh
5. Netter, 62.4, data ops for mid-market
Lowest on the outside view:
51. Hub xyz, 38.2, real-world AI datasets - @hubxyz, @xarmin @tim404x
52. The Company Company, 38.2, autonomous company - @thecompanyai, @juliuslip
53. General Instinct, 38.0, physical-AI deployment - @BillJiao930 @Guanming717
54. Minicor, 37.7, self-healing desktop agents - @minicor_ , @faizchishtie @sahee_d
55. RentAHuman, 32.7, real-world tasks marketplace @rentahumanx, @AlexanderTw33ts
If the score reads low, it usually means the data on 6 public signals (search demand, social pain, competition, monetization, funding, urgency) is either poor or hardly available. Could be worth closing that gap on stage on June 16.
3 things the data says about this group:
1) Some are building ahead of demand, some aren't, and search alone won't tell you which. 33 of 55 sit under 500 searches a month (nobody googles "agent memory" yet). But a few have real pull: Kuli and Netter clear 11k at 80 to 94% purchase intent, and the biggest raw number, Runtime's 311k, is mostly generic "runtime" spill, not category demand. The caveat that matters most: this is public search only. Infrastructure sells through private B2B motion, so a low score can sit on top of signed LOIs, paid design partners, or institutional pre-orders the outside view can't see. If that's you, that private demand is the single strongest thing to put on stage June 16.
2) One bet, 55 ways, and from the outside every idea could have the same shape. Half literally build "for agents," 71% sit in dev tools or AI automation, median 10 direct competitors each. Strong willingness to pay, crowded competition, and weak funding, not because these founders can't raise, but because the capital already came to some of these categories in 2020 to 2022 and got absorbed, not broken out. The batch converged on one thesis and now competes with itself.
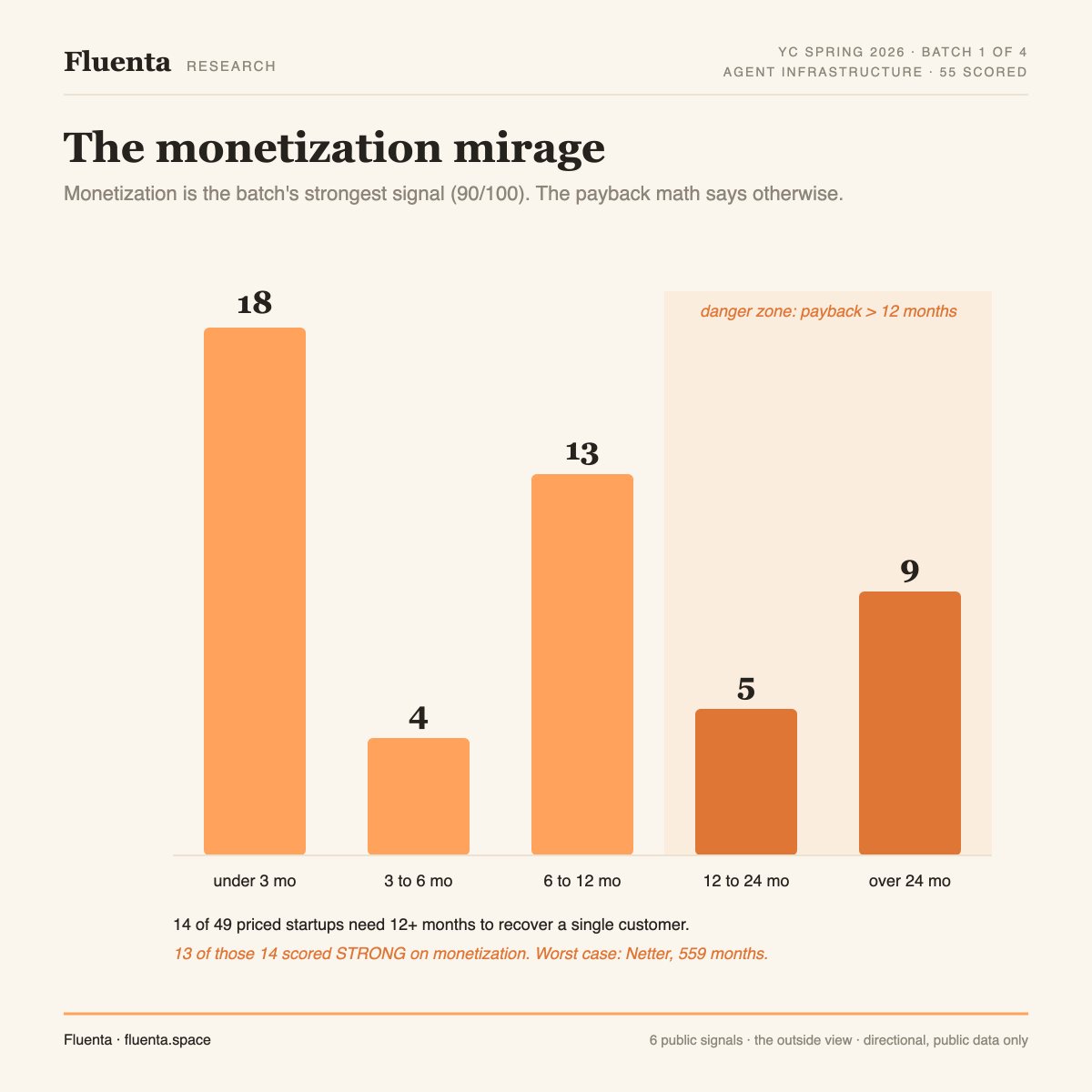
3) The strongest signal is the one that lies. Monetization scores highest across the board, people pay. But that score measures whether a market pays, not whether you can afford to win it. On the real CAC vs payback math, 14 of 49 priced startups need 12 months to earn back one customer, and 13 of those 14 scored STRONG on monetization. So the question isn't "is there a business," it's "is this a company or a feature." That's what you get pushed on June 16.
How to use it:
- Founders in the batch: find your card, look at your lowest of the 6 signals. Those could be the questions coming. Worth prepping now.
- VCs and angels: want the full breakdown on any project, competitors, the CAC vs payback math, search demand, etc? Check on fluenta.space/app. DM us to uncover the paywalled parts as well. The reports are done, so no additional costs here. Or use Fluenta MCP to pull all reports in one batch and do a thorough analysis on each one in Claude, Cursor, etc.
- Everyone not in the room June 16: the high-LRS names are the ones who’d mostly likely get funded, and who get cloned in every local market inside 90 days. Browse the board for your business inspiration.
Tomorrow, Batch 2 of 4: The AI Workforce. The agents coming for entire job functions.
Tagging the teams above in case you want to grab your report. No hidden subscription, no signup gate - the analysis is already done, the file is yours to pick up. DM here or email hello@fluenta.space and we'll send it same-day.
If the score reads you wrong, that gap is the thing to close on stage.

1
2
8
732
10h

57
14h
YC Demo Day is in 3 days, June 16
The biggest of the four groups (out of 194 YC-listed projects) is up: The AI Workforce, the agents coming for entire job functions. 56 startups automating the work people currently do, the largest group in the batch. Group average LRS: 49.1.
Same method as published yesterday: 6 public signals, a 0 to 100 Launch Readiness Score (LRS). Search demand, social pain, competition, monetization, funding, urgency. Public data only, the outside view every investor can run before the meeting.
Highest scored:
1. Saffron, 59.9, AI-aware engineer tests
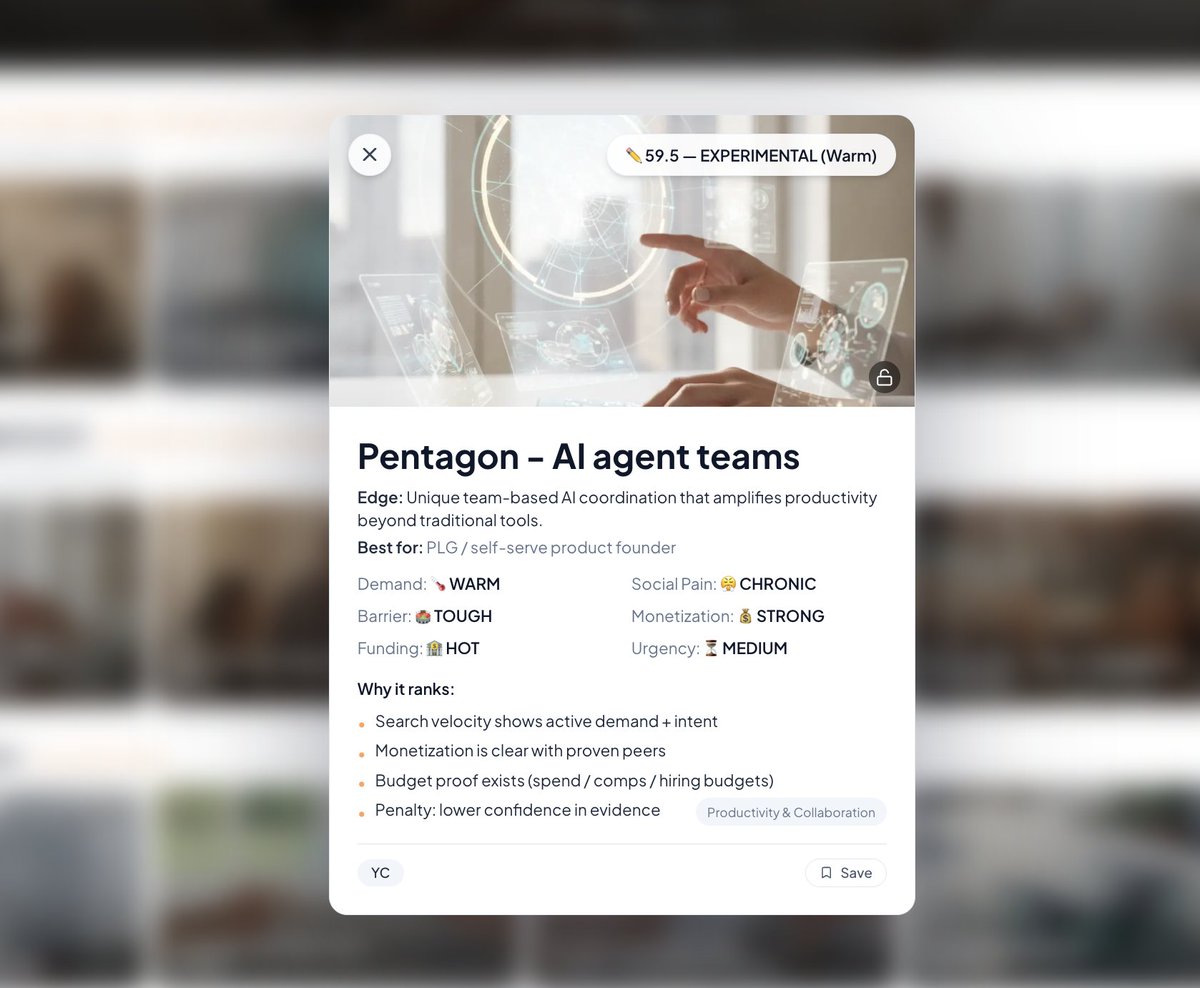
2. Pentagon, 59.5, AI agent teams
3. InstaAgent, 58.8, multi-persona ad campaigns
4. OpenWork, 58.5, self-hosted agent workspace
5. Userlens, 58.2, customer-success signals
Lowest on the outside view:
52. Sidekick, 40.8, text-based frontline helpdesk
53. Keyframe Labs, 39.3, photoreal AI video calls
54. Light Anchor, 39.1, agent-operated brands
55. Pops, 38.7, social AI gaming
56. Drafted, 37.6, AI home blueprints
If the score reads a team low, it usually means real traction the public data can't see yet. Signed customers, design partners, private demand, LOIs - make a big difference. Closing that gap is the Demo Day job.
3 things the data says about this group:
1. The batch is fighting a dozen landlords. For 29 of 56, a frontier lab or Big Tech platform could be regarded as a direct competitor, or a potential acquirer: Microsoft or Copilot shows up in 21 of the reports, OpenAI or ChatGPT in 16, GitHub in 13. Most of these read less like standalone companies and more like features orbiting a handful of giants that can ship the same thing and bundle it for free. The real question for each one is what the platform can't, or won't, absorb.
2. The crowd goes to the back office; the score rewards the rooms nobody's in. 19 of 56 automate back-office ops, the most crowded lane, and it scores middling (avg LRS 48.5). The highest-scoring jobs are the least crowded: recruiting and HR (57.0) and sales (52.7). The agents are piling into repetitive desk work, while the score pays off for the teams that went where others didn't.
3. "AI and Automation" is the lowest-scoring label in the batch. The 29 vague AI-automation plays average 46.1; the 27 that name a specific job average 52.3, a 6.2-point gap, and every one of the bottom 6 is a generalist. Saffron does engineer tests, Userlens does customer-success signals, Pentagon does agent teams. The score pays a premium for specificity, and the engine says 39 of 56 still have to niche down.
How to use it:
- Founders in the batch: find your card, look at your lowest of the 6 signals. That's the question coming June 16. And if your one-liner is "AI automation for X," the room will ask which X you actually own.
- VCs and angels: want the full breakdown on any project, competitors, the category's funding history, the CAC vs payback math? The board is free at fluenta.space. DM us for the full per-project file, same-day, no charge. Or pull every report over the Fluenta MCP and run your own diligence in Claude or Cursor.
- Everyone watching from outside the room: the top of this board is a preview of what's coming. The highest-scoring names are the ones most likely to raise, and the ones a dozen builders will copy in their own market within a quarter. Scroll it if you're hunting for your next thing to build.
Browse all 194 scored: fluenta.space/app
Tomorrow, Group 3 of 4: AI Meets the Real World - robots, drones, defense, factories, energy, logistics, property.
Tagging the teams above in case you want to grab your report. No hidden subscription, no signup gate - the analysis is already done, the file is yours to pick up. DM here or email hello@fluenta.space and we'll send it same-day.
If the score reads you wrong, that gap is the thing to close on stage.
@roblukan (Saffron) · @edgarpavlovsky (Pentagon) · @klwongkyle (InstaAgent) · @benjaminshafii (OpenWork) · @ankur_d (Userlens) · @designtday (tday.com) · @burnedchris (Inth) · @aidan__pratt (Autostep) · @nikolas_keller (Walter)
Grab your full report: fluenta.space/app or DM us


3
6
186
10h
1
40
10h
Saturday Kill List - 13 June 2026
5 ideas we'd kill before you write a line of code.
This week every one came from a source that only proves the thing already exists. A startup database. A YC company page. A "top 10 emerging startups" list. A trade-press trend roundup. A freelance gig. Five proofs that someone is already building or selling it. Not one is a customer.
From the deadest up.
1 Imitation Learning Middleware - LRS 30.7 - YC list
0 monthly searches. Source was a "top 10 emerging startups revolutionizing robotics" listicle. Universal Robots, Fanuc and NVIDIA already own the stack. VCs are pouring in (funding signal 10/10), but budget proof is 3/10. Money is moving; buyers are not.
Funded is not the same as wanted.
2 5G Optimization Software - LRS 30.8 - Seedtable
0 monthly searches. Source was a startup-database profile of a funded company already doing it. Nokia, Huawei and Ericsson are the market. The entry you found is not a gap. It is your competitor's listing.
A database entry is a competitor, not a customer.
3 Botanical Hormone Support Lattes - LRS 32.0 - FoodNavigator
The one with traffic: 2,205 searches a month. But only 8% want to buy, you'd fight Amazon and 30 brands, and category budget proof is 0/10. Source was a "top functional food trends 2026" roundup.
Searched is not the same as bought.
4 Hardware R&D Talent Pipeline - LRS 32.2 - Freelancer
0 monthly searches. The entire idea came from one gig posted on Freelancer. Robert Half, TEKsystems and Kforce already staff this for a living. From r/ECE: "I am very frustrated when it comes to applying for entry level jobs."
One gig is one buyer, not a market.
5 RentAHuman, real-world tasks marketplace - LRS 32.7 - YC
0 monthly searches. Source was a YC company page. A funded company is not your validation. It is your competitor. TaskRabbit, Upwork, Fiverr and Thumbtack already own real-world tasks.
Someone already shipped it. That is the problem, not the proof.
5 ideas. 5 sources. Zero of them were "I found a painful problem nobody is solving."
All 5 were "someone is already building this, so it must be real."
Supply you can see. Demand you have to prove. The market did not show up: 4 of these 5 have zero monthly searches; the fifth has 2,205 searches and 8% real buy-intent.
A note on what LRS cannot see.
LRS reads public, consumer-style demand only. Search volume, complaint threads, named incumbents, funding rounds, monetization patterns. It cannot see institutional demand that lives in private sales cycles.
Two of this week's five, Imitation Learning Middleware and 5G Optimization Software, sell into exactly that world: funded robotics teams and telecom carriers. If a founder there is holding signed LOIs or MOUs from tier-1 buyers, the real market may exist exactly where no public signal can show it. That is a genuine green light the score will miss.
The named incumbents above are the wall. A signed pipeline the public cannot read is your ladder. Absent that private edge, a founder confusing thesis with traction loses six months and a runway.
If you have it, the kill argument is wrong. Tell us what we missed. We will re-score.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ fluenta.space/x-ray
More kills next Saturday.
Disagree with a call? Reply with which one we killed unfairly. The strongest pushback gets a follow-up post.
73
Jun 10
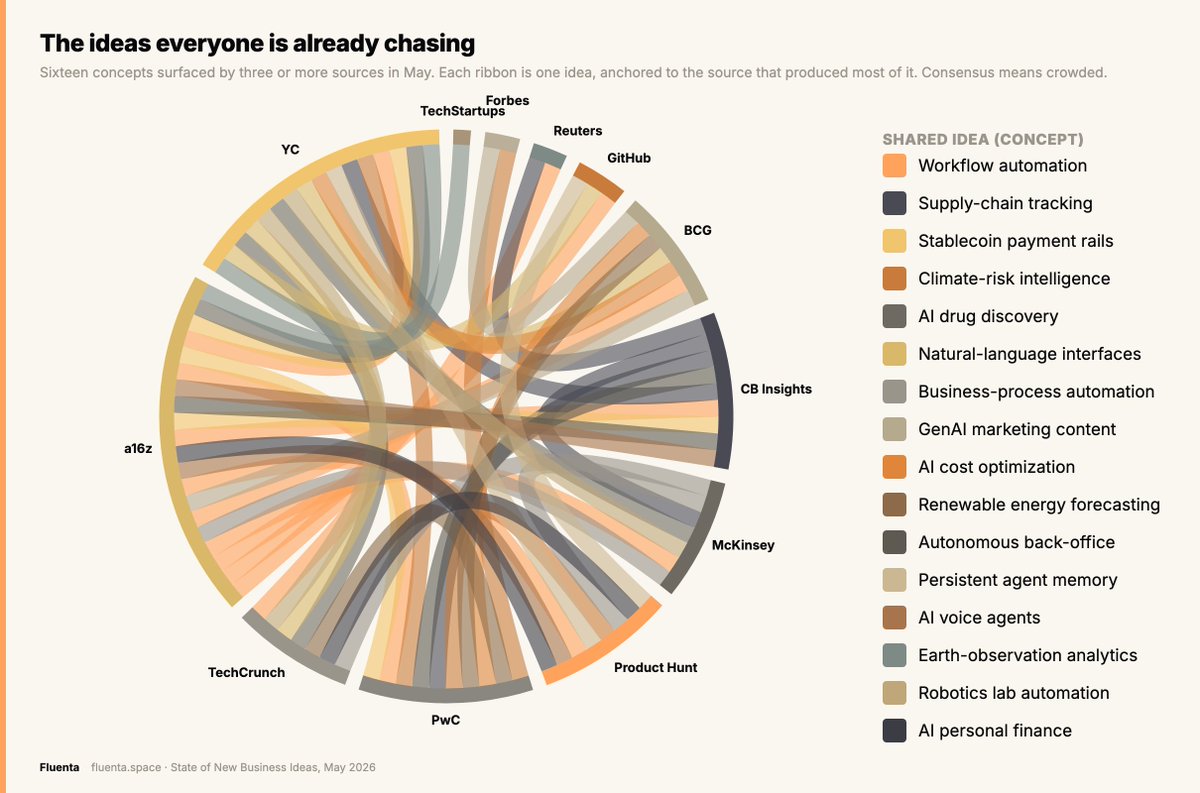
We spent days cleaning, transforming, and aggregating a month of startup-idea data. It gave us a hairball.
Then we read the hairball: 16 ideas that 3 or more major sources all chased in May. a16z, YC, McKinsey, TechCrunch, tangled around the same handful of concepts.
The mess is the point. This is what "market consensus" looks like up close, and consensus means crowded.
So how do you read this: as a decorative ornament, or as 16 traffic jams with a waiting list?
Full State of Business Ideas May Report here - fluenta.space/resources/repo…
1
38
Jun 9
First edition of the Fluenta State of New Business Ideas, May 2026
tldr: The market is manufacturing the one thing founders aren't trying to build.
We collected 4,092 new business ideas across 74 sources in May and deep-scored 386 on six live market signals.
38% of every idea surfaced this month was AI.
Founder demand for AI, measured by what people actually bring us to validate: under 2%.
The feed sells AI agents. Founders are quietly trying to build services, vertical tools, and boring niche businesses.
Three more findings:
- Pain is cheap. A quarter of all ideas are burning problems nobody pays to solve.
- The whole ecosystem converged on the same 16 concepts. Consensus means crowded.
- The quiet sectors score highest: legal, HR, productivity, dev tools.
The market in one number: BIDI (Business Idea Demand Index) opened at 57 out of 100. Busy. A good month to find an idea, a hard month to fund one.
Full report, free, no signup:
fluenta.space/resources/repo…
1
64


Jun 7
Three ideas on the Fluenta board right now:
A lab-grown rhino horn business.
An AI value-at-risk pricing engine for banks.
A streetwear culture magazine.
One came from a startup database. One from BCG. One from Hypebeast.
Same six signals. Same screen.
This week's board was pulled from 80 sources across 8 worlds that rarely meet in one place: McKinsey, BCG and Bain. a16z, Sequoia and YC. MIT, Stanford and Harvard. Inman, Hypebeast and Modern Retail. Product Hunt, GitHub and the App Store. Breaking Defense, Hacker News and Reddit.
Most idea databases scrape one or two feeds. We as humans tend to scroll the same launches everyone else already saw.
Fluenta looks different because the inputs are different. Synthetic biology next to bank-grade fintech next to a culture play, each one scored on demand, pain, competition, monetization, funding and urgency, each stamped with the exact source it came from.
The rhino horn idea scored 36.5. You can see the six numbers that say we would kill it. The interesting part is which ideas are winning, and where they came from.
Go find out.
→ fluenta.space
2
78
Jun 6
Saturday Kill List - 6 June 2026
5 ideas we'd kill before you write a line of code.
All 5 came from a different room where smart people decide what's next. A VC. A magazine. The App Store. An ag journal. A defense newsletter. Five sources, five confident calls.
From the deadest up.
1 Missile Seeker Systems - LRS 26.2 - Defense News
0 monthly searches. Source was Defense News on the Army wanting thousands of Stinger replacements. BAE, Raytheon, Lockheed and Northrop own it. Seekers go for ~$0.9M each on government contracts; BAE shipped its 1,000th THAAD seeker last year.
A procurement headline is not a market opening.
2 Robotic Crop Platform - LRS 29.4 - AgFunderNews
0 monthly searches. Source was AgFunder calling this "the golden age of robotics in agriculture." Carbon Robotics, FarmWise, Naio and Monarch already put 1,000 machines in the field. From r/robotics: "Why do agri-robots work in demos but not the field?"
The golden age already shipped. You'd be entrant 1,001.
3 Seller Incentive Package - LRS 34.7 - App Store (TikTok Shop)
0 monthly searches. Zero category funding. Source was the TikTok Shop Seller Center trending on the App Store. Amazon, Walmart, Shopify and TikTok all hand new sellers discounts and credits free, because seller acquisition is their loss leader.
You'd be selling back what the platforms give away.
4 Culture Media Gallery Platform - LRS 34.7 - Hypebeast
0 monthly searches. Last meaningful raise in the category: 2016. Source was a Hypebeast profile of a Shoreditch gallery. Your competitors are Hypebeast, Highsnobiety, i-D and Dazed.
You'd be building Hypebeast to compete with the Hypebeast article that gave you the idea.
5 System Controls Engineering - LRS 36.1 - Lightspeed
5,060 searches/mo, but only 8% transactional intent and budget proof of 0/10. Source was a Lightspeed portfolio job posting. People research robot control; none have shown they'll pay a startup for it. Boston Dynamics, ABB, Siemens and Fanuc own it.
Search traffic without a checkbook is a syllabus, not a market.
5 ideas. 5 sources. Zero of them were "I noticed a painful problem nobody is solving."
All 5 were "a credentialed source pointed, so I pointed too."
Attention is not demand. The rubric reads the market, not the room, and the market did not show up: 4 of these 5 have zero monthly searches.
A note on what the rubric cannot see.
Our 6-signal score reads public demand and supply only. Search volume. Complaint threads. Named incumbents. Funding rounds. Monetization patterns. It does not see your private edge.
If you have a distribution channel competitors cannot copy, a co-founder with industry trust nobody else can buy, a technical moat invisible from a job board or a launch page, or a customer pipeline already warm, the picture changes.
The named incumbents above are the wall. Your edge is whether you brought a ladder. The rubric scores the wall. Only you know if you have the ladder.
If you do, the kill argument is wrong. Tell us what we missed. We will re-score.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ fluenta.space/x-ray
More kills next Saturday.
Disagree with a call? Reply with which one we killed unfairly. The strongest pushback gets a follow-up post.
1
3
217
Jun 3
Fluenta MCP is live
One API key. Your AI agent now has the full Fluenta surface inside Claude Code, Cursor, or Codex.
Stop tabbing. Start asking.
After signup (email verification, key from your dashboard):
→ Show today's fresh business ideas and new collections.
→ Show ideas with LRS above 60.
→ Find ideas in real estate. Any sector works. Search runs on context, not strict tags.
→ Show the top 5 ideas by search demand or by recent funding.
→ Compare idea X and Y on LRS metrics. Show me where the gap is.
→ Save this idea to my pipeline. Or remove it.
→ Pull the full report on the top Trending Now idea. Download as txt or md.
→ Score my idea (whatever yours is) with Fluenta X-Ray.
Or in free form, no commands: "I'm thinking about a new business. Here are the candidates I'm weighing. Which one gets me to first revenue fastest, and why? Use Fluenta MCP to check fresh ideas and compare."
Free tier is real, not a teaser. You get a daily-refreshed search slice filtered by LRS. The day's #1 Trending Now idea is fully unlocked. Full report, downloadable as txt or md, processed inline in your chat. Every metric, every link, every named competitor, every business model, real user complaints with source URLs.
You can also delegate. Set your agent to pull MCP daily and drop fresh ideas into your chat (Notion, Slack, wherever you live). Open it in the morning, the day's curated batch is already there. All on the free tier.
Paid tier is $9/mo. Full access to every idea, every sector, every collection. We are keeping it wide open while the base is growing. We will rate-limit later, before someone tries to vacuum the database in one afternoon.
For your own ideas: run the sandbox preview free. The depth is noticeably less than the paid full run. Smart move before you commit credits: download a free Top Trending report first, see the actual depth, then decide if you want the same on your own idea.
Install in 90 seconds. JSON snippet, API key, restart your client.
Docs: fluenta.space/docs/api-and-m…
We ship new functionality every week. Reply with what you want first, or what is missing. We prioritize what you actually use.

5
1
7
730
Jun 2
12 poorest business ideas of May 2026
Out of 4,238 ideas spotted across 74 sources in May, Fluenta scored 393 on six live market signals. The average LRS (Launch Readiness Signal) came in at 46.7 out of 100.
These 12 scored lowest, from 30.1 down to 24.4.
Full report: fluenta.space/resources/repo…
1
3
33
May 30
Saturday Kill List - 30 May 2026
5 ideas we'd kill before you write a line of code.
All 5 came from "where ideas live" platforms. Sources that catalog what already exists, not signals of unsolved problems.
From the deadest up.
1 Native Compiler Porting Service - LRS 32.1 - GitHub Trending
0 monthly searches. Source was Microsoft's TypeScript-to-Go port trending on GitHub. The "idea" was a service to port other compilers. 17 competitors. $659M flowing into the category. The trend is Microsoft eating the market.
A trend is not a wedge.
2 Halal Beauty DTC Brand - LRS 33.5 - Tracxn SEA
1,120 searches/mo, only 8% transactional intent. Wardah, Safi, Solek, Iba, Emina, Sariayu, Make Over all sell halal beauty in Southeast Asia. Tracxn lists them. You found the list.
The list is the market. Finding it is not finding a gap.
3 Resync Revitalizing Night Cream - LRS 34.0 - Product Hunt
This is not an idea. Resync is a COSMEDIX product. It is on Dermstore right now. The Product Hunt page is a launch announcement for an existing brand. The rubric did not score an idea. It scored an inventory.
You cannot launch what is already on Dermstore.
4 Defense Drone Pre-Production Studio - LRS 34.5 - Newskart
10 monthly searches. Newskart was reporting $341M flowing into defense drones (Quantum Systems $184M, Shield AI $165M, Performance Drone Works $110M). The article you read about the funding is the same article every other founder read.
Reading the same press release is not differentiation.
5 Korea K-Beauty AI Skin Diagnostic - LRS 38.6 - Altos Ventures
80 monthly searches. Source was Altos Ventures' portfolio (they backed BPlant for $5M in January 2025). Chowis, Lululab, PerfectCorp, Revieve, Haut ai, ModiFace all run the same workflow.
Imitating a VC's bet is not investing in your own edge.
5 ideas. 5 sources. Zero of them were "I noticed a painful problem nobody is solving."
All 5 were "I looked at a list of things that exist and picked one to do."
Looking at what exists is not research. It is just looking.
The rubric finds the original every time, because the original already shipped.
A note on what the rubric cannot see.
Our 6-signal score reads public demand and supply only. Search volume. Complaint threads. Named incumbents. Funding rounds. Monetization patterns. It does not see your private edge.
If you have a distribution channel competitors cannot copy, a co-founder with industry trust nobody else can buy, a technical moat invisible from a launch page, or a customer pipeline already warm, the picture changes.
The named incumbents above are the wall. Your edge is whether you brought a ladder. The rubric scores the wall. Only you know if you have the ladder.
If you do, the kill argument is wrong. Tell us what we missed. We will re-score.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ fluenta.space/x-ray
More kills next Saturday.
Disagree with a call? Reply with which one we killed unfairly. The strongest pushback gets a follow-up post.
1
1
4
35
May 27
Garry Tan publicly promoted 17 projects this week on Product Hunt and GitHub. We ran our 6-signal Launch Readiness Score over each. 5 landed in PROMISING. 1 sits on our Saturday Kill List threshold.
We have been tracking Garry Tan's (CEO of Y Combinator) public promotion activity. He has been heavily on Product Hunt and GitHub these last 8 days. Open upvotes, retweets, hunts. Public signals you can scrape.
We pulled the 17 projects he flagged between May 19 and May 26 and ran our standard Fluenta 6-signal Launch Readiness Score over each. Public-launch info only. Directional, not final, but useful as a "what is the most influential accelerator CEO actually betting on this week" read.
There is a pattern in how investor signal sources mature. Twenty years ago a founder's edge was a Sequoia partner's lunch schedule. Ten years ago it was the portfolio page on a VC homepage. This week it is a Product Hunt upvote feed scraped on a Monday morning. The infrastructure for tracking taste has gotten faster than the taste itself.
The 17, by LRS:
PROMISING band (LRS 60 ):
→ Open Vibe - 65.9 - AI SaaS coding flow
→ Willow Scribe - 63.3 - voice-to-text Mac app
→ Superset - 61.8 - coding agent orchestration
→ Runtime - 61.5 - sandboxed agent execution
→ Airbyte Agents - 60.3 - AI agent data layer
EXPERIMENTAL band (LRS 40-59):
→ Voker - 54.4 - AI agent analytics
→ Contrario - 52 - AI-human recruiting
→ Emdash - 52 - multi-agent desktop hub
→ Mailx - 51 - email deliverability
→ Chert - 50 - iMessage AI agent platform
→ Prism - 48 - AI candidate sourcing
→ Lingo dev - 46 - AI localization
→ Ara - 46 - Mac-notch AI agent
→ Motion - 45 - AI motion-design video
→ Open Finance MCP - 44 - bank data MCP server
→ Mintlify Workflows - 41 - auto-updating docs
WEAK SIGNAL band (LRS under 40):
→ Asteroid - 33.6 - computer-use agent SDK
Two things worth noting before the breakdowns.
Open Vibe at 65.9 is the 2nd-highest LRS we have ever scored. Across thousands of ideas. 0.3 below our prior all-time high. Worth flagging where the prior record came from: a Fiverr gig last month, scored at 66.2. Not a YC graduate. Not an a16z portfolio company. A single freelancer on a gig marketplace, selling a service that compounded. The top of our all-time leaderboard now spans a YC partner's promotion feed, a Stanford accelerator, and a Fiverr listing. The rubric does not care where the idea comes from. Markets do not either.
Second: 5 of 17 in PROMISING band. Compare to Stanford Blockchain Cohort 8 we scored last week, which shipped 0 of 10 PROMISING and 9 EXPERIMENTAL. Different stage, different info depth, but the gap is real. Public-launch signal beats pre-launch tagline signal.
Universal pattern across the 17: every project needs a narrow vertical wedge to survive. Saturated horizontals get crushed. Sharp wedges compound. The rubric flagged "narrow-vertical-or-die" on all 17 of 17.
Per-project tactical breakdowns for the top 5 plus the spotlight at the bottom.
- Open Vibe (65.9). The MOAT play: not "another AI coder." Cursor, Replit, GitHub, Bolt, V0, Windsurf, Lovable, Base44 own horizontal with $355M flowing into the category. Pick ONE bottleneck (debugging visibility, project-context memory, prompt reusability) and become the daily driver for that one thing. Demand is 34/35 with 100% transactional intent at 610 searches/mo. Real budget waiting on the right wedge.
- Willow Scribe (63.3). Otter ai users are bailing in real time. r/Journalism quote: "Otter feels mega bloated and overpriced." r/podcasting, r/therapists, r/medicine all complaining. There is a recurring pattern in how knowledge-worker tools die. Evernote did not get killed by a competitor. Users got tired of it. Skype too. Pocket too. Heavy-use verticals start complaining publicly, the category trade press loses interest, and 18 months later the leader is irrelevant. The complaint threads on r/Journalism right now read like the early Evernote bailout in 2015. Which is why Willow Scribe's vertical wedge play is well timed. Wispr Flow, SuperWhisper, MacWhisper hold the Mac slot. Pick ONE workflow (medical dictation, therapy notes, journalism interview transcription) and own the templates, custom phrases, EMR integrations for that one job. Category funding is 1/10. Cold capital means clean lane for a focused entrant.
- Superset (61.8). 6,680 monthly searches is the highest demand signal in the cohort. But r/ClaudeCode skeptics are vocal: "Most 'multi-agent orchestration' is just a single agent calling a function." The wedge that survives the critique: stop selling orchestration. Sell a workflow outcome. Code review automation. Incident response. Release coordination. Orchestration is the means, not the pitch.
- Runtime (61.5). E2B is the elephant. Half of the Fortune 500. Millions of sandboxes a week. Daytona, Modal, Browserbase, Northflank also fight that fight. Category funding is 0/10. Wedge: own regulated execution. HIPAA audit trails. SOC2 policy enforcement. Financial-services exec sandboxing. E2B is general. Regulated-industry execution is a moatable sub-vertical they will not chase.
- Airbyte Agents (60.3). Tough room. Airbyte, Fivetran, Hightouch, Polytomic, Stitch, Hevo all own enterprise data plumbing. But agent-specific data context is genuinely new. Wedge: do not sell "AI data layer" (reads as Airbyte 2.0, buyer ignores). Sell agent-ready context stores for one painful job (CRM-to-agent grounding, data-warehouse-to-agent retrieval, ops-data-to-LangChain reliability). Vertical pitch reads as "the only thing that makes my pipeline reliable." Buyer pays.
The 11 EXPERIMENTAL-band projects (LRS 40-59) all follow the same playbook from our rubric: narrow vertical, defensible workflow, ship against named incumbents. Per-project incumbents wedge in the full report.
Actually one correction worth making before we move on. We called Asteroid the "only WEAK SIGNAL." That is not quite right. Asteroid is the only entry that BARELY landed below 40. Three of the mid-band EXPERIMENTAL entries (Mintlify Workflows 41, Open Finance MCP 44, Motion 45) sit close enough to the WEAK SIGNAL line that a single bad data point could push them below. Watch the mid-band, not just the bottom.
The spotlight at the bottom:
- Asteroid (33.6). 0 monthly searches. Demand 13/35 COLD. Category funding 1/10. Browserbase, Skyvern, Anthropic Computer Use, UiPath, OpenAI, Google, Simular, OpenInterpreter all dominate already. The "computer-use SDK" tagline is the problem, not the product. There may be a real wedge in regulated back-office automation (insurance claims, healthcare admin, banking ops) where Asteroid can ship faster than UiPath. But current positioning lands close to our Saturday Kill List threshold. Sharpen the wedge or expect benchmark traffic to stay cold.
Methodology note: these scores read public Product Hunt launches GitHub activity, not full product walkthroughs. Directional, not final. Every founder here has data we cannot see from a launch listing. Existing distribution. Team depth. Technical defensibility. Treat the LRS as one outside read, not a verdict.
For the 17 founders Garry promoted this week: the full X-Ray report for your project is already generated. Yours to claim. Each report includes:
→ Full 6-signal breakdown with reasoning per pillar (your actual sub-scores)
→ 10 named direct competitors with public pricing anchors and recent funding rounds
→ 3 business model paths with full unit economics (CAC, ARPU, gross margin, year-1 revenue projections, deal cycle, LTV:CAC)
→ 30 ICP pain quotes pulled from Reddit, HN, IndieHackers, Quora with source URLs you can cite in your pitch deck
→ Funding momentum analysis with recent rounds in your category
→ Keyword targeting with KD scores for SEO and SEM
→ A week-by-week first-100-customers playbook with named subreddits and communities for cold reach
Plus 30 days of full Fluenta access to score variants and adjacent ideas.
No subscription. No signup gate. The analysis is already done. The file is yours to pick up. DM here or email hello@fluenta.space and we'll send it same-day.
Full collection lives at fluenta.space.
@garrytan, thank you for a public-signal-rich week. This list exists because your hunt feed is one of the cleanest VC signal sources online. We'll keep tracking. More projects are being added as you keep promoting.
Tagging the cohort below in case you want to claim your report.
→ Open Vibe: @WaspLang
→ Willow Scribe: @willowvoiceai · @lawrenceliuu · @_allanguo
→ Superset: @superset_sh · @FlyaKiet · @avimakesrobots
→ Runtime: @runtm_com · @gustavo_trigos
→ Airbyte Agents: @AirbyteHQ
→ Voker: @voker_ai · @tyler_postle · @alrudolph
→ Contrario: @ContrarioAI · @arya_marwaha · @soodadityab
→ Emdash: @emdashsh · @arnestrickmann · @rabanspiegel
→ Mailx: @themailx · @thamibenjelloun
→ Chert: @cherthq · @garygao · @yannaner
→ Prism: @tryprism · @theokitsberg
→ Lingo.dev: @lingodotdev · @MaxPrilutskiy
→ Ara: @xadisingh · @svemyhre
→ Motion: @motion_so · @adishj · @shivvtrivedi
→ Open Finance MCP: @appcumbuca
→ Mintlify Workflows: @mintlify · @handotdev · @hahnbeelee
→ Asteroid: @asteroid_inc · @MlcochDavid
Fluenta Research · fluenta.space
#ProductHunt #YCombinator #LaunchReadinessScore
1
1
10
729
May 28
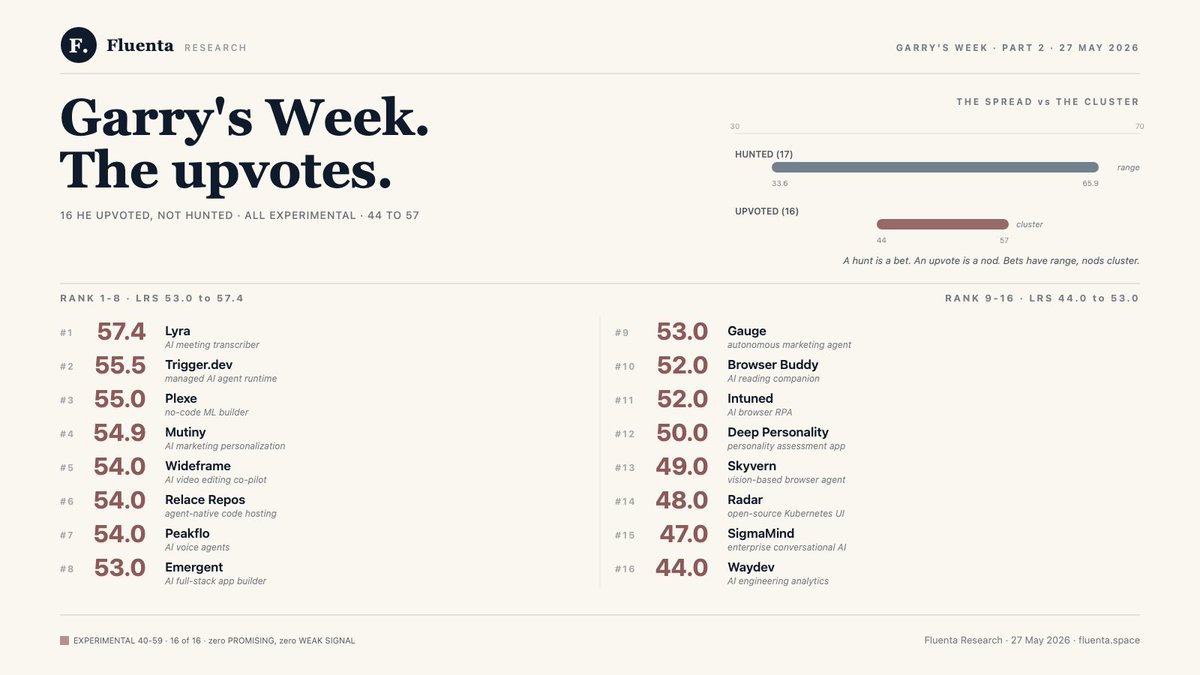
Quick follow-up to the thread above, because the second batch told us something the first one didn't.
Yesterday we scored the 17 projects Garry Tan actively hunted. Today we ran the next 16 he upvoted but did not hunt. Same scraper, same 6-signal rubric.
The spread is the story.
The 17 he hunted: 5 PROMISING, 11 EXPERIMENTAL, 1 WEAK SIGNAL. Outliers at both ends. A record-adjacent 65.9 at the top, a near-Kill-List 33.6 at the bottom.
The 16 he only upvoted: all 16 in EXPERIMENTAL. Range 44 to 57. Zero crossed 60. Zero dropped below 44. A tight cluster in the safe middle.
A hunt is a bet. An upvote is a nod. The bets have range. The nods cluster.
The 16, by LRS:
→ Lyra - 57.4 - AI meeting transcriber
→ Trigger dev - 55.5 - managed AI agent runtime
→ Plexe - 55 - no-code ML builder
→ Mutiny - 54.9 - AI marketing personalization
→ Wideframe - 54 - AI video editing co-pilot
→ Relace Repos - 54 - agent-native code hosting
→ Peakflo - 54 - AI voice agents
→ Emergent - 53 - AI full-stack app builder
→ Gauge - 53 - autonomous marketing agent
→ Browser Buddy - 52 - AI reading companion
→ Intuned - 52 - AI browser RPA
→ Deep Personality - 50 - personality assessment
→ Skyvern - 49 - vision-based browser agent
→ Radar - 48 - open-source Kubernetes UI
→ SigmaMind - 47 - enterprise conversational AI
→ Waydev - 44 - AI engineering analytics
Three worth a closer look.
- Trigger dev (55.5). Loudest funding signal in the batch: 10/10, $188M into the category. Temporal, Inngest, n8n, Windmill all own slices. The lane that is not crowded yet: TypeScript-native, observable, long-running agent runtime. Sell "reliable agents in code," not "an agent platform."
- Lyra (57.4). Highest LRS in the batch, but read the fine print. 660 searches a month with only 8% transactional intent. People are curious, not buying. Fireflies, Gong, Otter, Fathom own the shelf. The wedge is not a better notetaker. It is transcription as a means to a CRM-hygiene or compliance outcome a specific buyer already pays for.
- Waydev (44). Lowest in the batch, most interesting tension. Demand 10/mo, almost nothing. Social pain 25/30, burning. That gap means the pain is real but nobody knows to search for a tool yet. Outbound and concierge pilots, not SEO. Category education is the whole game.
Actually, correction to the framing above. "Nods cluster" is true for the score, not for the money underneath it. Trigger dev sits mid-pack at 55 with 10/10 funding and $188M in its category. The LRS compresses the surface. The capital still varies a lot below it. Read both.
The pattern across all 16 is the same one from batch 1: every project needs a narrow vertical wedge. The difference is these sit closer to the line. Solid execution, needs a sharper edge. Which describes most good companies, honestly.
Same standing offer as the thread above. The full X-Ray report for each project is already generated. No signup gate, no subscription. DM or email hello@fluenta.space and we'll send yours same-day.
Tagging this batch so you can grab your report.
→ Lyra: @uselyra · @courtnemarland
→ Trigger.dev: @triggerdotdev · @mattaitken · @maverickdotdev
→ Plexe: @PlexeAI · @VaibhavMDubey · @marcellodbrnrd
→ Mutiny: @jalehr
→ Wideframe: @wideframeai · @danielpearson · @heyzk
→ Relace: @relace_ai · @pfactorialz · @EBorgnia
→ Peakflo: @GetPeakflo
→ Emergent: @emergentlabs · @mukundjha · @madhavjha
→ Gauge: @gauge_sh
→ Browser Buddy: @jeremyjsuh
→ Intuned: @IntunedHQ · @faisalilaiwi
→ Deep Personality: @DeepPersonApp · @awilkinson
→ Skyvern: @skyvernai · @itssuchintan
→ SigmaMind: @sigmamind_ai · @_ashishagarwal_ · @mundrapratik90
→ Waydev: @waydevco · @alexcircei
(Radar - could not find a public X handle. Drop it below if that is you.)
2
146
May 25
The "SaaS-in-your-AI" Shift: Why the Old Software Playbook is Officially Dead
Lenny Rachitsky (@lennysan) just dropped a new episode with Dan Shipper (@danshipper) that is worth every single minute of your time. Even Marc Andreessen (@pmarca) is already weighing in on it.
If you haven't caught it yet, stop what you’re doing and open this link: x.com/lennysan/status/205891…
The entire 90-minute episode is a masterclass in where the AI ecosystem is actually moving, but Dan dropped one core thesis that completely flips how we think about software:
"For a long time we thought the optimal experience of AI was going to be take AI and put it in a browser. The reverse is starting to happen. Take the AI agent that you use all the time and put a browser in it."
Let that sink in.
The Old Playbook vs. The New Reality
The Old Playbook: Build a shiny wrapper, force AI features into a legacy SaaS dashboard, and try to sell the exact same old workflow with a chatbot bolted on top.
The New Reality: Knowledge work is migrating entirely inside central agent surfaces—whether that’s Codex, Claude Code, Cursor, or whichever interface nails the UX first.
Your SaaS tools stop being destinations. They stop being apps users switch to. Instead, they become background infrastructure—tools that the agent reaches for via API while the human stays entirely in their native chat environment.
If your software still requires a human to leave their agent surface, log in, click through 5 dropdowns, and copy-paste data back... you are building for the past. That motion is pure friction in an agent-first world.
The Blind Spot: Why This is Bullish for SaaS Margins
The second-order effect Dan calls out is the part most founders and investors are completely missing: this will create massive new demand for SaaS, not less. 1. High Volume: Instead of one human clicking around a UI twice a day, an autonomous agent can query a SaaS product hundreds of times in seconds to validate a thesis or execute a workflow.
2. Margin Protection: SaaS company margins actually improve. Why? Because when users bring their own AI (via Codex or Claude Code) to interact with your data, the user pays for the LLM tokens, not the SaaS provider.
The clear winners of this era won't be the ones with the prettiest dashboards. It will be the companies that expose a clean, robust tool surface that an LLM agent can call seamlessly.
This isn't some distant 2030 projection. Dan's team at Every is already living in this future today.
Are we ready to accept that our favorite SaaS dashboards are turning into backend APIs for agents, or are we holding onto the era of tabs and clicks?
Drop your thoughts below. 👇
Disclaimer: Watching this episode might cause an urgent desire to refactor your entire product roadmap😀
May 25

My biggest takeaways from @danshipper:
1. The future of work will happen inside Codex or Claude Code. Instead of putting AI into your SaaS tool, you’ll use your SaaS tools inside your favorite AI agents' in-app browser. Dan spends all his time in Codex now—writing documents, managing email, doing research, everything. He's using Google Docs, PostHog, and everything he needs within the agent's in-app browser. The agent can see what he’s doing, and has all of his context, so he and his agent collaborate quickly and super effectively.
2. Automation is a lie—every automation needs a human. Dan's company doubled in size this year despite being incredibly AI-forward. Why? Because in order to make automation work well, you need humans making sure everything keeps working. This is why benchmarks are misleading—they measure AI on problems we’ve already framed and can score, but there’s always a higher frame.
3. PMs will win the AI era. Marcus, a former PM who previously ran Axios’s writing product, joined Every after getting super AI-pilled. Now he runs their product Spiral, and ships faster than anyone on the team. He pairs technical knowledge with spiky product sense, deep user empathy, and an eye for what matters. Dan thinks any PM who gets really AI-native will be incredibly dangerous because the building is done for you—what matters is figuring out what to build and if it’s great.
4. Full-stack designers are becoming superheroes. Designers used to make beautiful interactions that engineers didn’t want to build or couldn’t execute properly. Now designers don’t need to hand things off; they can build it themselves. Designers are naturally creative people, and AI is the perfect tool for them because it lets them bring their vision to life without the traditional bottlenecks.
5. SaaS is not dead. In fact, Dan is bullish on SaaS stocks. When users bring their own AI (via Codex or Claude Code) to use SaaS products, the user—not the SaaS company—pays for tokens. This saves SaaS company’s margins. Since the agents need their own seats, Dan predicts that agents will create massive new demand for SaaS because there will be tons of agents using these products at high volume.
6. Every company will have one “super-agent” inside their Slack that every employee will use. Dan initially thought every employee would have their personal work agent, like a shadow AI org chart, but he’s completely flipped his view. He realized agents need humans who care about them. When someone gets tired of maintaining their personal agent, it becomes useless. The winning model is one forward-deployed engineer or AI-savvy person who maintains a company-wide agent (like Shopify’s River or Viktor), and then it trickles down to more specialized team agents as models improve and become less fiddly.
7. The AI job apocalypse is not happening, but you do need to evolve to stay relevant. Models make yesterday’s human competence cheap. But because everyone uses the same models, it all looks the same if you use it the default way; it becomes commoditized slop. Humans then take that frozen competence and use it to make something new and interesting for their specific situation. The key: “ride the models”—use them for everything you do, try new models when they drop, keep turning over rocks.
8. We will read way more AI-generated writing, and we will like it. Human writing is incredibly important for things that matter, but for internal docs, planning, and email, AI-generated is often better because most people are bad at writing strategy documents.
9. Build software for humans and agents to use together. The current model is building a CLI that an agent uses independently. Instead, you and your agent should be using the app together. This creates new design challenges—agents can make a billion requests in three seconds, so you need approval flows, inboxes that summarize what happened, logs, and easy rollback.
10. Forward-deployed engineers are the new most essential role. The big model companies have teams of people managing their internal agents, and those teams aren’t going away. It’s different from traditional software building, and certain engineers love it. As models get better, this role will evolve—you’ll be managing more agents doing more things.
2
76
May 23
Saturday Kill List - 23 May 2026
5 startup ideas we'd kill before you write a line of code.
3 of the 5 launched on Product Hunt this week.
The other 2 are from a CB Insights brief and a FoodNavigator trade round-up.
What all 5 share:
→ a real working product
→ a real launch page
→ a real category
→ 0–420 monthly searches
→ named incumbents already taking the money
From the deadest up.
#1 Nostalgia Content Platform - LRS 31.7 - CB Insights
0 searches/mo. The "top competitors" returned by the scoring run are TikTok, Instagram, YouTube, Pinterest, Patreon, Substack. The $843M in cited category funding belongs to Runway, Whatnot, Suno - neighboring creator-economy, not nostalgia.
Nostalgia is a feeling. Not a category. Vibes don't have a search bar.
#2 GLP-1 Companion Food Program - LRS 32.0 - FoodNavigator
420 searches/mo. 8% transactional intent. 32 direct competitors including Mayo Clinic and Cleveland Clinic. $0 category funding. Budget proof 0/10.
The pharma sells the GLP-1. The clinic sells the meal plan. Not a third app.
#3 Private Luxury Fashion Flash Sales - LRS 33.0 - Product Hunt
0 searches/mo. Vente-Privée: €1B annual. Saks OFF 5TH: billions. Rue La La: hundreds of millions. Total category funding to the next entrant: $4.6M.
The category isn't empty. It's saturated. No door to walk through. Only a wall to climb.
#4 Fuse · Semi-Anonymous Community App - LRS 36.2 - Product Hunt
20 searches/mo. Funding momentum 1/10. Largest round: Secret $25M July 2014 - dead. Next: Sphere $20M March 2019 - dead.
Anonymous social is a graveyard with a $45M tombstone.
#5 Dog's Reactivity Progress Tracker - LRS 37.9 - Product Hunt
30 searches/mo. Estimated CAC $535–$1,783. Comparable app ARPU $30/year. Payback 65.9 months.
You'd pay $1,000 to acquire a customer who pays $30. The math doesn't break. It never started.
3 of these 5 shipped this week. The interfaces work. The carousels are polished. The Product Hunt comments are warm.
And nobody is searching for any of it.
Shipped is not demanded.
The search bar is the receipt buyers haven't written yet.
Want your idea graded on the same 6 signals before you sink a quarter into it?
$7. ~10 min. Human-readable report.
→ fluenta.space/x-ray
Do not miss the next Saturday's Kill List.
Disagree with a call? Reply with which one we killed unfairly — strongest pushback gets a follow-up post.

4
93
May 21
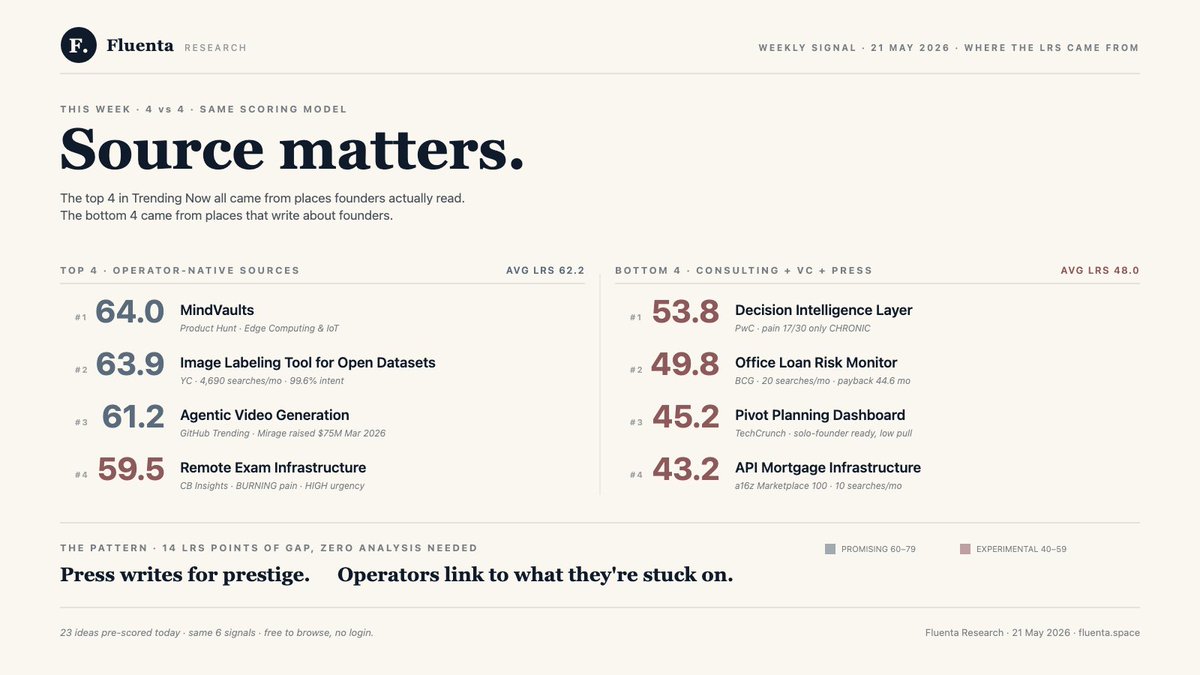
4 ideas in today's Trending Now batch.
All 4 from places founders actually read.
→ MindVaults — LRS 64.0 — Product Hunt
→ Image Labeling Tool for Open Datasets — LRS 63.9 — YC
→ Agentic Video Generation — LRS 61.2 — GitHub Trending
→ Remote Exam Infrastructure — LRS 59.5 — CB Insights
What they share:
→ BURNING social pain (25/30 on 3 of 4)
→ Named paying customers already in the wild
Glean. Roboflow. Synthesia. Honorlock.
→ Multi-surface demand: Google search Reddit threads in the last 90 days
→ STRONG monetization (17–20/20), $20–$2,500/mo
Now the bottom 4 in today's run. Same week. Same scoring model.
→ Decision Intelligence Layer — LRS 53.8 — PwC
→ Office Loan Risk Monitor — LRS 49.8 — BCG
→ Pivot Planning Dashboard — LRS 45.2 — TechCrunch
→ API Mortgage Infrastructure — LRS 43.2 — a16z
The gap isn't sector. It's signal source.
The diagnostic, pair by pair:
Image Labeling (YC) → 4,690 searches/mo. 99.6% purchase intent. r/computervision complaining Roboflow lags at 12k images.
API Mortgage (a16z) → 10 searches/mo. Cold demand. The category sits in a Marketplace 100 report. Not in anyone's browser.
Agentic Video (GitHub) → 33 burning-tone complaint mentions in 90 days. Mirage raised $75M Mar 2026, lead Index Benchmark.
Office Loan Risk Monitor (BCG) → 20 searches/mo. Est. CAC $1,053–$3,510. Payback 44.6 months. Wins a procurement slide. Loses a Reddit thread.
Same 6 signals. Same scoring run. Different sources.
Press writes for prestige.
Operators link to what they're stuck on.
The search bar is a more honest signal than a TED stage.
Today's full batch of 23 ideas is pre-scored at fluenta.space. Free to browse, no login.
Want your own idea graded on the same 6 signals?
10 min.
→ fluenta.space/x-ray
3
84