
Joined December 2019
- Tweets 4,436
- Following 87
- Followers 20
- Likes 2,612
71 Photos and videos







DTInnovate retweeted

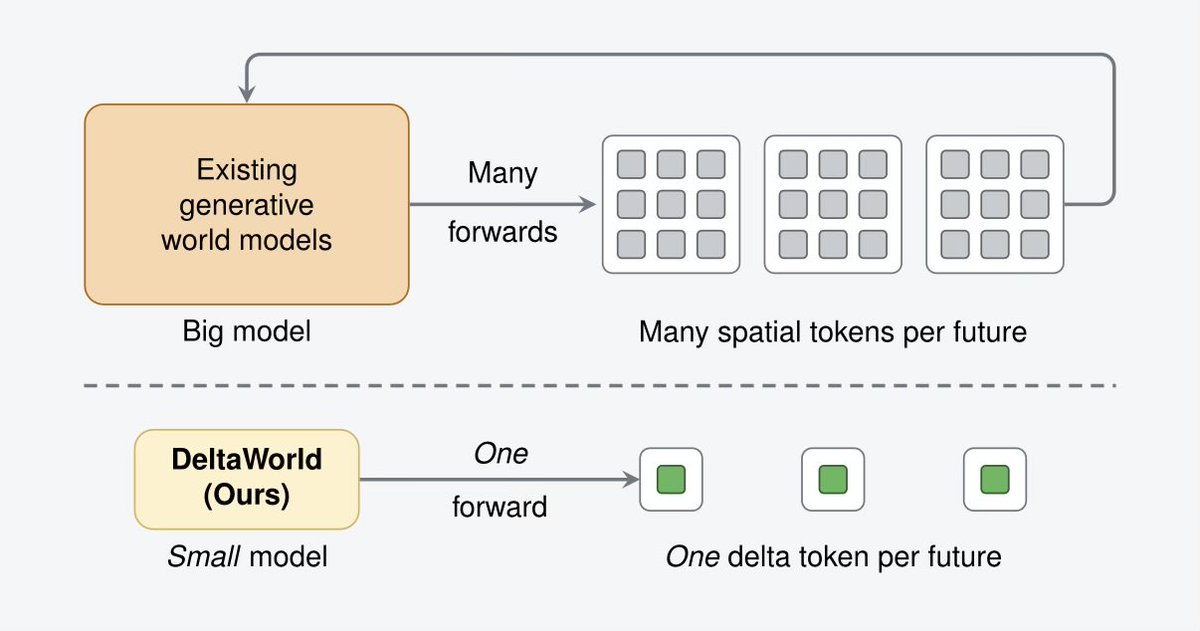
The wildest CVPR 2026 result: a video frame doesn’t need 1,024 tokens. It needs one.
“A Frame is Worth One Token” (DeltaWorld) compresses each frame to a single token for world modeling.
- Better future predictions with over 35x fewer parameters and 2,000x fewer FLOPs than existing generative world models , plus a 1,024x token reduction at 512x512 .
- A tokenizer encodes the difference between consecutive DINOv3 frames into one “delta” token. A tiny generator predicts the next one, supervising only its closest guess to ground truth. Diverse futures in a single pass.
- Why it matters: Video collapses from a 3D blob into a 1D sequence. Generative world models finally get cheap enough to actually run.
8
43
408
21,199
#RAG works but Enterprise #AgenticRAG (offered by the likes of Google) is just contrived & token-deaf.
An employee could spend some extra time finding additional info. & correlations but at least won't have 4-5 agents (more) eating tokens $$.
Token(eco)omics cant be overlooked
7
DTInnovate retweeted

Jun 13
Notably, the budget panel was comparable with Claude Fable 5 in performance.
A panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro, fused together, beat solo GPT-5.5 and solo Opus 4.8 outright.
And it landed within 1% of Fable 5 while costing roughly half the price.
15
88
1,634
558,537

Jun 11
Fast but calling it 'runs locally' is misleading: requires high-end @Windows /@nvidia ;unified mem. architecture to support 18GB #VRAM
In the name of #AI (MANGOS, FAANG) are manipulating functionality & progress.
How much #GenAI of #CoPilot actually generates $$ for @Microsoft ?
Jun 10

DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.

ALT Intelligence vs Latency chart showing DiffusionGemma 26B A4B is much faster than Gemma 4 models with high intelligence.
27
Jun 10
Either be efficient #opensource like @deepseek_ai @Alibaba_Qwen @Kimi_Moonshot , etc. or be proprietary w/ REAL breakthrough ability like #AlphaEvolve
Choose
@AnthropicAI made Claude Fable 5 worse at AI development, users call it anticompetitive behaviour msn.com/en-in/money/news/ant…
22
DTInnovate retweeted

Jun 7
난 게임을 즐겨하지 않는데 이런건 진짜 유익함
만원으로 데이터 센터의 복잡한 구조와 컴퓨터 인프라를 이해하는 스팀게임 : Data Center
빈 방에서 시작해서
랙 구매 → 서버 장착 → 모든 케이블을 직접 손으로 하나하나 연결해야함
실제 데이터 센터처럼 고객 트래픽을 처리하는 시뮬레이션 게임
출시 48시간 만에 180개가 넘는 리뷰가 달렸고, 플레이어들은 “최근 본 시뮬레이션 게임 중 가장 몰입감 있다”, “컴퓨팅 인프라를 이해하는 데 최고”라는 평가를 하고 있습니다.
238
2,687
16,520
1,339,739
DTInnovate retweeted

Jun 7
NVIDIA's new Nemotron3 Ultra is defeated by Kimi K2.6 & GLM5.1 on coding tasks like TerminalBench, etc. In order to make the Global Nemotron Coalition training committee train frontier open models, Jensen should invite at least one of the following frontier ai labs to the committee: DeepSeek, MoonshotAI, MiniMax, Qwen, StepFun, zAI GLM.

27
21
304
82,714
DTInnovate retweeted

Jun 5
Token costs are why there will be no saas apocalypse / good dev tools are cached intelligence for agents!
The popular theory goes: agents can write code, so they'll just rebuild every tool from scratch and hit raw APIs. no more dev tools, no more CLIs, no more software layers. just agents and endpoints!
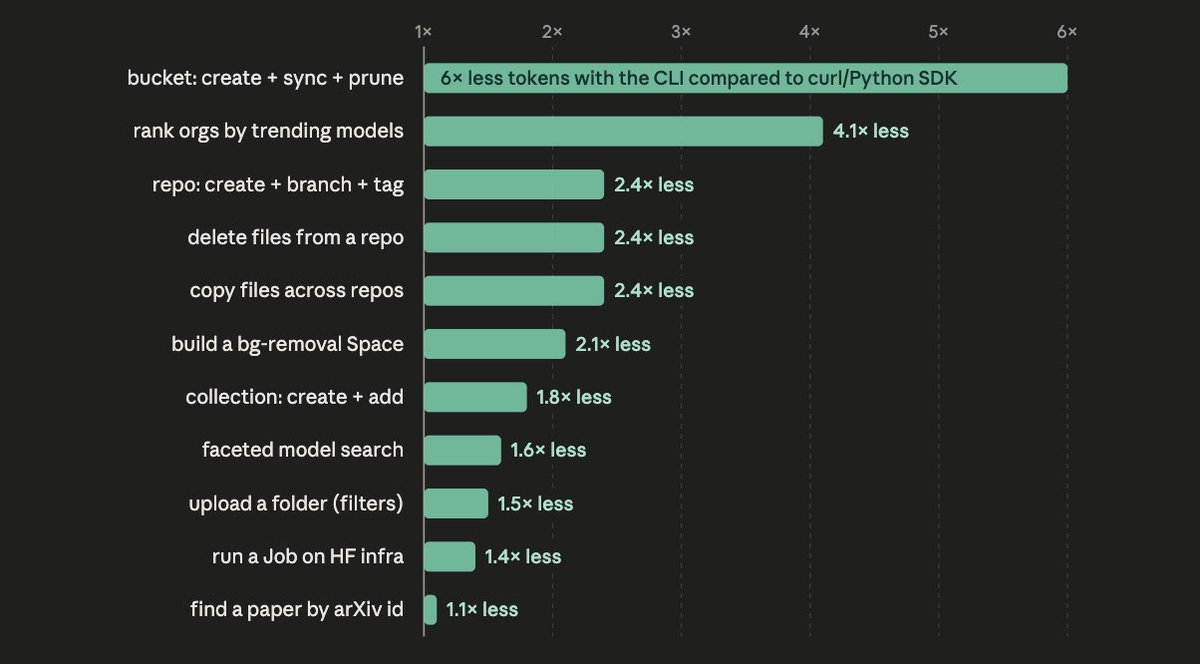
We just tested this and the data says the opposite. We benchmarked Claude Code and Codex on real Hugging Face Hub tasks (~1,000 graded runs), with two setups: the agent-optimized hf CLI vs the agent hand-rolling curl or SDK calls from scratch.
Hand-rolling burns up to 6x more tokens on multi-step tasks and fails more often (84% vs 94% task success).
And that's just dropping one abstraction layer. It would obviously be orders of magnitude more tokens and a dramatically higher failure rate if the agent tried to bypass HF altogether and rebuild model hosting, versioning, and distribution from scratch. Every time an agent re-derives a workflow from raw API calls, you pay for that reasoning in tokens. every single run. a good CLI compresses that entire chain into a few high-level commands the agent can't get wrong.
In a world where everyone is complaining tokens are too expensive, abstraction is leverage: thousands of hours of design decisions your agent doesn't have to re-reason about at inference time.
Good tools are cached intelligence for agents!
So no, agents won't rebuild everything from scratch. they'll gravitate to the most token-efficient tools, because that's what their owners pay for. The software that survives won't just be accessible to agents, it will be accurate and cheap for them to drive.
We're seeing it happen with HF, which is becoming the platform for agents to use AI: ~49M requests in just two months, and growing fast!
huggingface.co/blog/hf-cli-f…
95
93
542
115,443

Former Google, Meta executives raise $100 million for high-capacity AI servers startup cnbc.com/2025/11/10/majestic…
8
9
18
18,218
Jun 5
And this is what Dr. @ylecun has been saying all along. Self learning models; #robotics can't go the #LLM (token generation) way. #WorldModels
Jun 4

We’re going all in on World Models.
Today we’re launching the 1X World Model Lab.
The bet is simple:
You can’t fine-tune your way to AGI.
And you definitely can’t fine-tune your way to robots that can operate in the physical world.
General-purpose humanoids need models that understand space, motion, objects, causality, affordances, physics, and action before they ever see a specific task.
The frontier is not better VLA wrappers.
The frontier is embodied world models.
The 1X World Model Lab will focus on large-scale embodied world model pretraining: building the most generalizable foundation model for humanoid robots from the ground up.
The next frontier in AI requires scaling:
web-scale media egocentric human videos sim dexterous remote operated robot data on-policy NEO data → real-world deployment for robot data collection and RL → abundance of data → physical AI
The robot collects data.
The model gets better.
The robot gets better.
Repeat.
To lead this, we brought in one of the best for the mission: @_sam_sinha_ , as Head of World Models.
Sam was a founding research scientist at Luma AI and has been at the frontier of scaling multimodal generative video models his whole career.
If you’re the best in the world at large-scale pretraining, video models, robotics, RL, infra, or data — and you want your models to move atoms, not just pixels — join us.
Send background evidence of exceptional ability to:
wmlab@1x.tech
We’re building the model that makes autonomous labor real.

19
DTInnovate retweeted

NVIDIA has just released Nemotron 3 Ultra, the new most intelligent US open weights model, with leading speed for its intelligence
Nemotron 3 Ultra scores 47.7 on the Artificial Analysis Intelligence Index, well ahead of the next strongest US open weights models, Gemma 4 31B (39.2), Nemotron 3 Super (36.0) and gpt-oss-120b (33.3), but behind the Chinese-led open weights frontier (Kimi K2.6 at 53.9).
We partnered with @NVIDIA to evaluate this model for intelligence and speed ahead of its public release. These figures use the final NVFP4 weights that NVIDIA recommends for inference, but our tests show minimal intelligence impact compared to BF16 testing, with higher precision resulting in an Artificial Analysis Intelligence Index score of 48.2 vs. the NVFP4 score of 47.7.
Key Takeaways:
➤ Nemotron 3 Ultra leads in speed for its intelligence: through BlackBox AI ahead of release, Nemotron 3 Ultra is served at over 400 output tokens per second - this is slightly faster than the typical serving speed of gpt-oss-120b despite being >4X larger, and comes with significantly greater intelligence
➤ Largest Nemotron 3 model so far: with approximately 550 billion total parameters and 55 billion active, Nemotron 3 Ultra is significantly larger than its siblings and is the largest and most intelligent US open weights model release ever
➤ Nemotron 3 Ultra is the leading US open weights model on the Artificial Analysis Intelligence and Agentic Indexes by far, but Gemma 4 31B scores ~1 point higher on the Coding Index (comprised of Terminal-Bench Hard and SciCode)

31
57
699
93,637
Jun 5
#cyberharassment #hatecrime, #financialabuse & #blacklisting by #racist NAM #HR for ten years is acceptable & not criminal harassment.
But speaking up is unacceptable & results in more #blacklisting. Thanks to the Magic Quadrant-Hype cycle "research" firm #CHRO & #ceom89
🙏Classy
18
Jun 4
"#Cosmos 3 is the world’s first fully open omnimodel that can natively understand & generate text, images, video, ambient sound & actions with leading physics accuracy..."
@NVIDIAAI : Natively understand? (i.e. token generation via RL-right?)
Dr. @ylecun & Dr.@drfeifei prob. know
Jun 4

@NVIDIAAI & @NVIDIARobotics: Why do you keep refering to 'vision reasoning' (instead of #VLA, which was also inaccurate) in #Cosmos3?
#worldmodels: there is training data, simulation & action prediction
Perhaps Dr. @ylecun & Dr. @drfeifei know?
nvidianews.nvidia.com/news/n…
1
28

In a structural development positioned to reshape the baseline parameters of high-performance data infrastructure, Microsoft has officially unveiled its next-generation topological quantum processing unit, the Majorana 2 superchip.
Steering clear of standard superconducting or trapped-ion formulations backed by regional tech conglomerates, Microsoft’s deep 20-year commitment to the elusive Majorana fermion underpins a highly calculated strategic timeline: delivering a commercially viable, fault-tolerant quantum computer scaling to 1 million logical qubits by 2029.
The 20-Year Paradigm Shift: Engineering Inherent Topological Protection
While competitor platforms scaled physical qubit aggregates into the hundreds and thousands over the past decade, Microsoft sustained severe industry skepticism due to the prolonged engineering intervals required to validate its underlying physics.
However, standard quantum topologies face an existential barrier: environmental decoherence and high error rates. Classical superconducting qubits suffer severe state collapse from microscopic thermal variances or electromagnetic noise, requiring more than a 10,000:1 ratio of unstable physical qubits to construct a single high-fidelity "Logical Qubit."
The Majorana 2 sub-architecture re-engineers this paradigm at the foundational materials layer:
Hardware-Level Error Correction: The Majorana 2 chip exploits non-local topological states within engineered superconductor-semiconductor heterostructures. Quantum information is encoded non-locally across the physical boundaries of the geometric network. Consequently, localized environmental perturbations cannot alter the global topological braid, establishing native hardware immunity to standard decoherence profiles.
Disruptive Qubit Efficiency Mapping: By shifting the burden of error correction away from software layers and directly onto the physical characteristics of the silicon substrate, Microsoft’s architecture projects an unprecedentedly tight physical-to-logical qubit ratio. This structural efficiency translates the deployment of 1 million logical qubits from a logistical impossibility into an actionable engineering roadmap capable of fitting within standard data center footprints.
Cross-Disciplinary Fabrication Concurrency: Deep visibility into elite foundry logistics reveals that the realization of the Majorana 2 platform depended entirely on translating molecular beam epitaxy (MBE) research into standard semiconductor cleanroom environments. Microsoft successfully bonded high-purity semiconductor nanowires to highly uniform superconducting shells at an atomic level, shifting topological quantum computing away from academic observation and straight into high-yield industrial fabrication.
The 2029 Operational Matrix: Sovereign Compute & Advanced LLM Integration
Microsoft intends to transition the Majorana 2 compute fabric into the foundational compute engine of its Azure Quantum platform. By targeting the 2029 commercial window for its million-qubit infrastructure, the enterprise seeks to unlock massive market premiums across high-barrier sectors:
Exact Molecular and Catalyst Simulation: Achieving 1 million logical qubits grants the hardware the capability to natively simulate the quantum states of multi-atomic molecules without approximation. This capability collapses materials-science development loops from decades to days, empowering enterprises to synthesize room-temperature superconductors, optimize high-density BMS storage matrices, and discover zero-carbon industrial chemical catalysts.
Quantum-Accelerated Reasoning Engines: While emerging client-side AI PCs and cloud-hosted custom silicon process foundational agentic reasoning efficiently, hyper-complex optimization tasks remain constrained by von Neumann energy boundaries. Microsoft plans to interface its quantum cloud directly with its MAI-Thinking reasoning pipelines, allowing long-horizon autonomous agents to evaluate trillions of systemic interactions concurrently within quantum sandboxes.
Post-Quantum Cryptographic Isolation: To secure corporate databases ahead of this massive transition in computing power, Microsoft is accelerating the integration of Post-Quantum Cryptography (PQC) across its global data center perimeters. By implementing deterministic quantum-safe authorization layers, the enterprise ensures that sovereign asset variations and multi-tenant telemetry remain fully isolated against emerging algorithmic decryption threats.
#Microsoft #Majorana2 #QuantumComputing #TopologicalQubit #AzureQuantum #Semiconductor #TechFinance #DeepTech #AIAgent #FutureComputing

2
1
3
262
Jun 3
#MSBuild2026
@Microsoft is using #AgenticAI & #AI to capture elusive #quantumcomputing market.
Who know, @GoogleDeepMind might also be on it with their #AlphaEvolve.
But even qubit states are up for disruption.

Microsoft has officially unveiled its new quantum computing hardware component, the Majorana 2 chip.
In a significant shift, researchers utilized advanced AI materials-science tools to bypass standard manufacturing limits, successfully integrating lead, a water-soluble material historically avoided in chip fabrication, into the architecture.
Microsoft claims this AI-driven materials breakthrough puts them on a definitive timeline to deploy commercially viable, fault-tolerant quantum machines by 2029.

22
Jun 1
Another cool development from @NVIDIAAI / @NVIDIARobotics
#Cosmos3 -> hope to see it go from #VLA to #JEPA (it is evolving), because VLA is inefficient for sustainable #PhysicalAI

Introducing Cosmos 3: Our latest frontier model for Physical AI
Cosmos 3 is the world’s first fully open omnimodel with native vision reasoning, world and action generation.
Today we’re releasing Super (32B) and Nano (8B) variants.
2
109
DTInnovate retweeted

May 28
What if you could take three completely different model families… and distill them into one tiny model? 🤯
📜 Paper: arxiv.org/pdf/2605.21699
MOPD (Multi-Teacher On-Policy Distillation) has become a standard procedure in post-training. We already distill multiple specialized variants of the same model into a single set of weights.
But what if we could go further - and distill models from entirely different families? Turns out, it is possible.
Today we’re releasing a paper on cross-tokenizer distillation - our first steps in this exciting direction. 📄
We distilled Qwen3-4B, Phi-4-Mini, and Llama-3B into Llama-3.2-1B.
MMLU jumped from 32.05 → 46.32 when using multiple teachers. 📈
The team is now working on Nemo-RL integration so the community can try this method in their own settings. Plus, we are scaling experiments up. 🚀
50
327
2,732
1,357,825
DTInnovate retweeted

May 30
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!

11
61
507
93,954
May 30
When #RAG gets too expensive & inaccurate for large corpus, #MeMo (Memory as a Model) steps in.
Computationally efficient (though 1st time training, eats up lots of #GPU hours), transferrable to other models & retains accuracy. #AI
May 22

🚨 LLMs are frozen after pretraining, but the world keeps changing. How do you give an LLM new knowledge without retraining it, bloating its context, or breaking what it already knows?
Existing methods hit a wall:
🔸 RAG is brittle to retrieval noise and struggles with cross-document reasoning;
🔸 Fine-tuning is expensive and causes catastrophic forgetting;
🔸 Latent memory is tightly coupled to the model that produced it.
👉 Key question: Can we encode knowledge into a small, dedicated memory model that any LLM can query without accessing the LLM itself?
🚀 Introducing MeMo (Memory as a Model) 🚀
We train a dedicated MEMORY model on a reflection Question-Answer dataset synthesized from the target corpus. At inference, a frozen EXECUTIVE model (any LLM, including closed-source models) queries the MEMORY model through a structured 3-stage protocol that decomposes complex queries into targeted sub-queries to retrieve precise, noise-robust knowledge and reasons over the responses.
🔥 Key Highlights
🧠 5-step data synthesis pipeline captures explicit facts, implicit relationships, and cross-document connections as reflections;
🛡️ Robust to retrieval noise: where RAG drops up to 6.22% with added distractors, MeMo holds steady;
🔌 Plug-and-play with any LLM, no weights, gradients, or logits required;
📦 Fixed inference cost, independent of corpus size;
🔄 Continual integration via model merging: 33% compute savings over full retraining and scaling benefits grow with the number of corpora.
📊 Strong results across BrowseComp-Plus, NarrativeQA, and MuSiQue, matching or outperforming retrieval baselines (BM25, NV-Embed-V2, HippoRAG2) with gains of up to 27% on NarrativeQA when paired with Gemini-3-Flash.
💡 Why this matters
MeMo decouples knowledge from reasoning: Train memory once with a small open model, then plug it into the frontier LLM of your choice. No retraining as new corpora arrive, no fragile retrieval pipelines, and full compatibility with proprietary APIs, paving the way for scalable knowledge-aware AI systems.
🤝 Joint work with @workryanq_nus, @961014dltkdg, @alfredleongwl, Alok Prakash, Nancy F. Chen, @arun_v3rma, Daniela Rus, and Armando Solar-Lezama
📄 Paper: arxiv.org/abs/2605.15156
💻 Code: github.com/arunv3rma/MeMo
🌐 Project page: arunv3rma.github.io/blogs/me…
🤗 Huggingface: huggingface.co/collections/G…
#LLMs #KnowledgeIntegration #MemoryAugmentedLLMs #RAG #ModelMerging

1
57