
Full of childlike wonder. Teaching robots manners. RL @ Apptronik. UT Austin PhD candidate. Past: Boston Dynamics AI Institute, NASA JPL, MIT ‘20.
Joined September 2018
- Tweets 37,034
- Following 5,263
- Followers 16,354
- Likes 201,926
2,247 Photos and videos














Pinned Tweet

17 Apr 2024
when you argue with me about control theory this is who you’re arguing with

5
6
147
41,462
Jun 11
in Austin we had the F1 race and the Texas Georgia football game on the same weekend and it was basically this. it was a beautiful thing.

At what point do we sponsor this German tourist to come back in the fall and experience the SEC on any given Saturday?
1
3
1,536
Jun 11
unrelated but Georgia fans might be some of the most annoying people on the planet my god. stop barking.
1
2
729
Kyle🤖🚀🦭 retweeted

Jun 10
Hey so @SemiAnalysis_ why did you put your watermark on my image to include in a "paid" article without asking.

30
24
1,126
142,100
Kyle🤖🚀🦭 retweeted

Jun 7
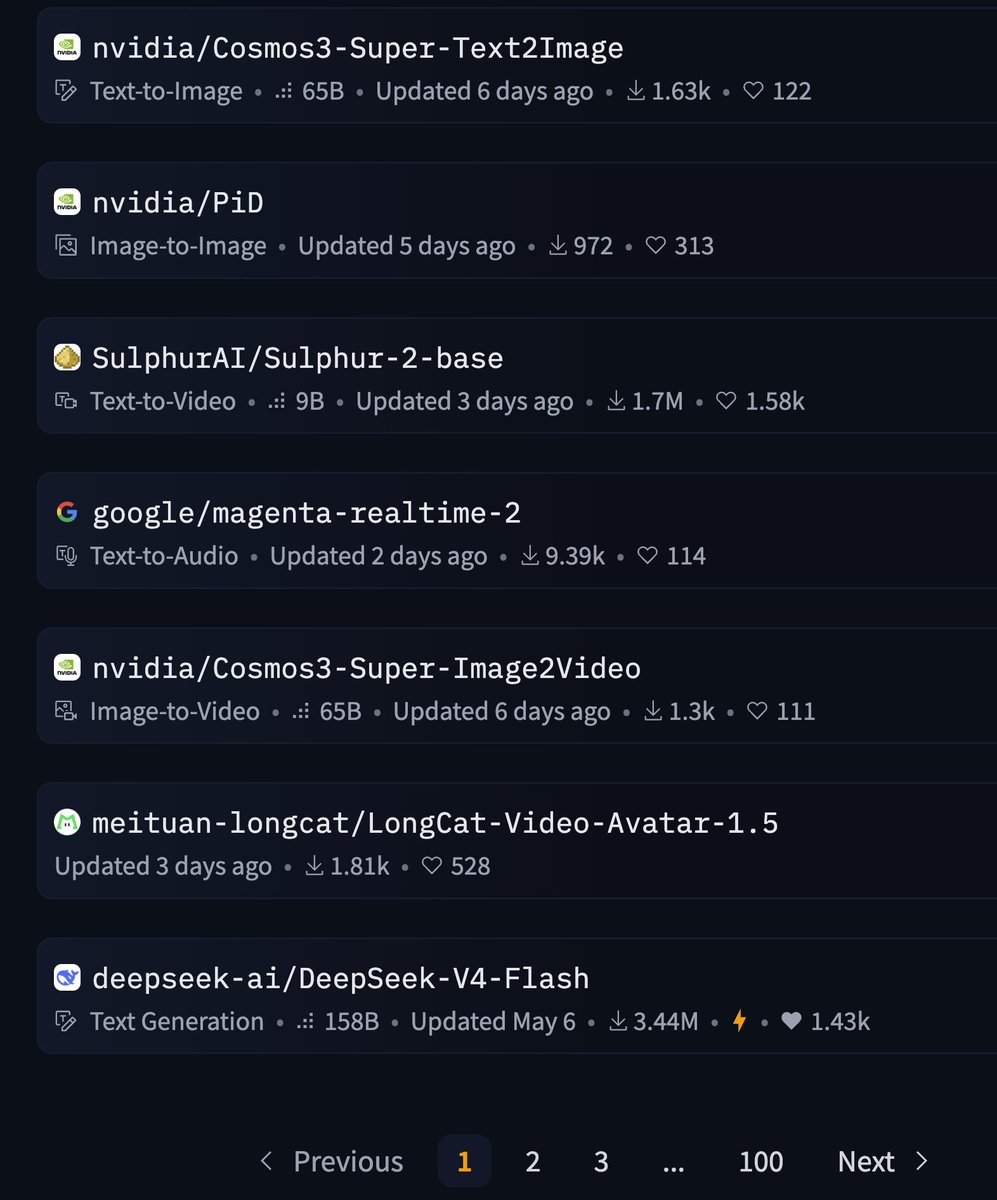
NVIDIA open-source culture is amazing.
I really enjoy working in this environment 😍

American Open Source is so back.
9 / 30 of the models on page 1 of Huggingface are published by Nvidia.
4
36
3,427
Kyle🤖🚀🦭 retweeted

Jun 8
Our SOTA reward model for robotic manipulation. I'm very proud of this work; it was more than a year in the making. Lessons learned below:
Jun 1

Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
4
7
34
6,264
Kyle🤖🚀🦭 retweeted

Jun 5
AME2 has got two follow-ups which can significantly improve training efficiency, performance, and generalization. I think the training cost can be reduced to (not by) 20% now.
1) active gaze arxiv.org/abs/2606.05880
2) sparsify attention arxiv.org/abs/2606.00637
Jan 14

releasing AME2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
arxiv.org/abs/2601.08485
In this work, we discuss how to achieve a combination of generalization and agility in legged locomotion, and propose a general solution.
1
13
69
27,430
Kyle🤖🚀🦭 retweeted

May 31
if you still haven't checked out the big wildflower meadow at duncan park, now's the time

5
13
339
14,366
Kyle🤖🚀🦭 retweeted

May 27
For those who are in need of experience with InEKF & Legged state estimation, check this post.
I’ve explored quite a lot of Invariant EKF and its variants, but the example repo mentioned in this post (legged ros package) shows how a good legged odometry should work. 👍

2
1
16
4,355
May 26
first frunt (frog hunt) of the season! the frymphony (frog symphony) was out in full force. 82 dB from the sidewalk! toad 4 tax
1
4
724
Kyle🤖🚀🦭 retweeted

May 25
“In practice, however, technology is never neutral, because it takes on the characteristics of those who devise it, finance it, regulate it and use it.”
THANK YOU POPE LEO FOR SAYING THIS.
Time for the “technology is a tool with no inherent moral position” idea to die!
53
5,415
26,856
227,256
Kyle🤖🚀🦭 retweeted

May 26
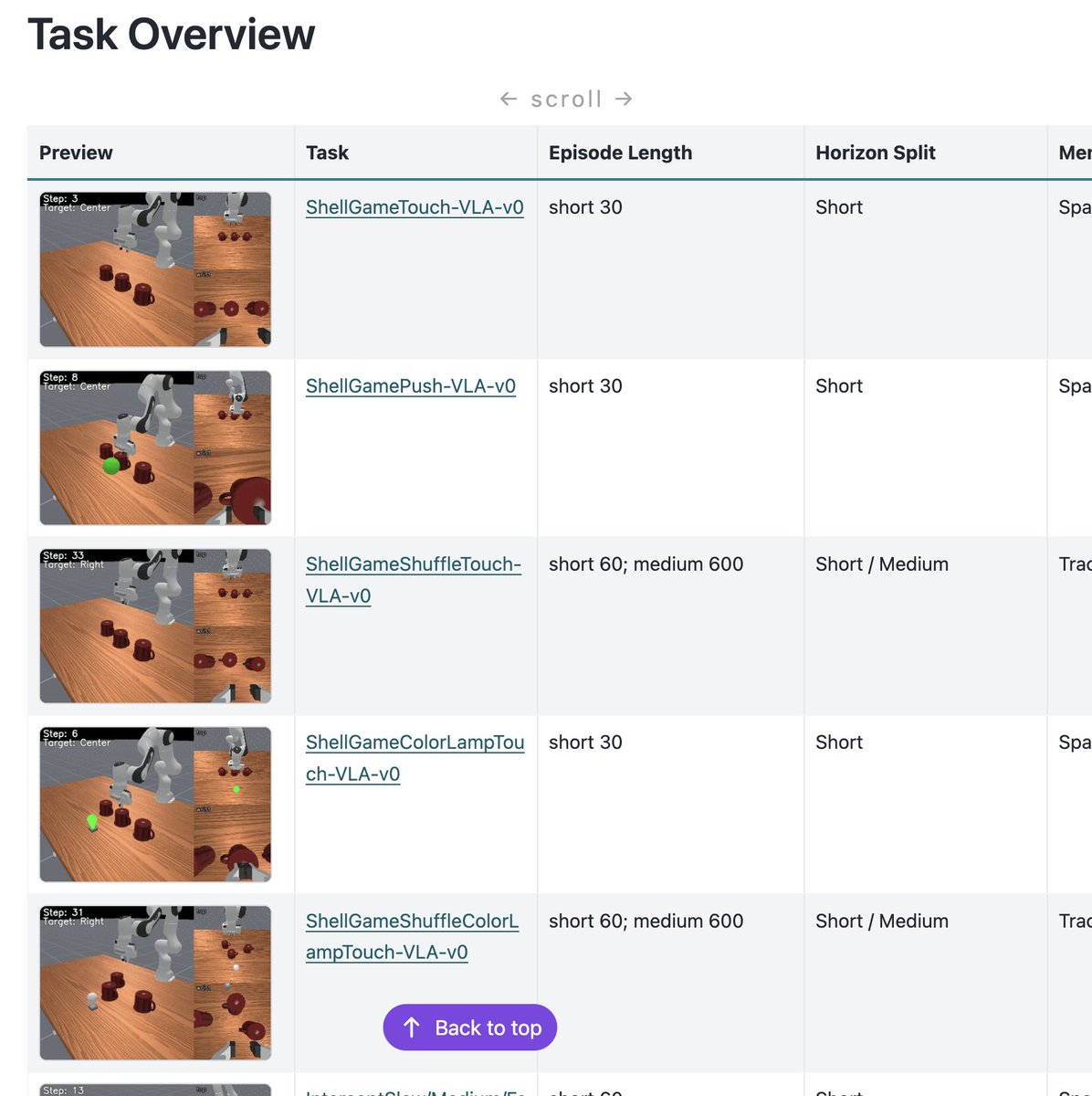
ok I kind of blindly retweeted this last time (I see a neat project using maniskill I usually retweet), but spent a little time looking through this project more
Incredibly well documented, gifs of every task, RLDS/open-x dataset format support (which I never got around to doing in maniskill natively), some nice benchmarking ideas around memory with categorization, and somehow dense rewards and/or motion planning scripts for 90 something tasks

May 22

🎉 We released MIKASA-Robo-VLA v1.0.0 — a benchmark suite for studying memory in Vision-Language-Action (VLA) policies for tabletop robotic manipulation.
mikasarobo.github.io/
🧠 The goal is simple:
make memory evaluation in robotic manipulation more systematic.
👇
2
12
82
11,034
Kyle🤖🚀🦭 retweeted

May 25
Bar

May 25

Humanity, created by God in all its grandeur, is today facing a pivotal choice: either to construct a new Tower of Babel or to build the city in which God and humanity dwell together. In Jesus Christ, this humanity in its grandeur becomes the Way, the Truth and the Life, opening the path for each of us to grow toward fullness. #MagnificaHumanitas
vatican.va/content/leo-xiv/e…
45
12,017
58,833
1,050,745
Kyle🤖🚀🦭 retweeted

The backlash against arXiv is a bit odd. All they're asking is that you read your papers before submitting them.
44
142
2,134
80,908
Kyle🤖🚀🦭 retweeted

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
139
921
6,555
1,088,690
Kyle🤖🚀🦭 retweeted

May 14
The community didn't wait for us.
Before we even released code for fine-tuning, training, and inference, builders were already deploying MolmoAct2 in the wild. So we're shipping faster.
Today: official LeRobot integration for MolmoAct2.
Train, evaluate, and deploy with standard LeRobot datasets and workflows — bring your own task, bring your own embodiment.
→ github.com/allenai/molmoact2
Can't wait to see what you build.
May 5

Most capable generalist robotics models today are closed or at best, open weights. But robotics won’t reach its ChatGPT moment without real openness.
That GPT moment was built on years of open tools and datasets such as Python, PyTorch, ImageNet and more, that let researchers inspect, reproduce, and build.
Today, we’re introducing MolmoAct 2: a fully open-source action reasoning model for real-world robotics.
We rethought and reshaped everything!
🧵👇
8
16
131
17,862
May 14
do I have any Japanese moots that would be willing to let me pay to ship this to the US from their address? quag is my favorite, I’ll do anything 😭
May 14

本日5月14日(木)から、ポケモンセンターオンラインで「ミニテーブル ヌオー」が注文受け付け中!
ヌオーといっしょなら、おやつタイムがもっと楽しくなるかも……!?
くわしくはこちらをチェックしてね!
pokemoncenter-online.com/452… #ポケモンセンターオンライン

2
587
Kyle🤖🚀🦭 retweeted

May 9
Atrocious take, and I understand now why some of the old school RL people refuse to interact with LLM people.
"Who cares about the theory and the entire underlying body of work, just do the one simple instantiation that I use, nothing else is important."
May 9

I feel it’s really unhelpful that searching for “deep RL” sends you to Q learning, MDPs, Bellman’s equation etc, when it’s literally just
Run LLM agent on data -> was it good? -> policy gradient /- reward
Like that’s actually it! And LLMs are just stacks of attn MLP
5
9
232
21,812
Kyle🤖🚀🦭 retweeted
May 7
If Caffe, TensorFlow, or PyTorch had been closed to only a few; if the Transformer was never published; if ResNet had stayed inside MSR; or if ImageNet and Common Crawl had never been made available, we would not have the ChatGPT moment we see today.
Openness is not just a choice. It is a responsibility.
We are excited that MolmoAct 2 from @allen_ai can contribute, even in a small way, toward bringing the robotics community closer to its own ChatGPT moment.
Thanks @stepjamUK for featuring!
May 7

Most open VLA models are not really open.
They release weights and call it reproducibility. The training data is withheld. The training code is withheld. The deployment pipeline is withheld. You get a checkpoint file and a paper.
You cannot verify the data quality. You cannot reproduce the training run. You cannot adapt it to your robot without starting from scratch.
Researchers from Allen AI released MolmoAct2, the first VLA that is open. Weights, training code, complete datasets.
• MolmoAct2-BimanualYAM Dataset: 720 hours of teleoperated trajectories across 28 real-world tasks, the largest open bimanual dataset available.
• MolmoAct2-SO100/101 Dataset: 38,059 episodes curated from 1,222 public datasets.
• MolmoAct2-DROID Dataset: Quality-filtered Franka trajectories with re-annotated instructions.
The system deploys out-of-the-box on three platforms spanning the low-to-medium cost range. Bimanual YAM, SO-100/101, DROID Franka. No additional fine-tuning required.
The backbone is Molmo2-ER, trained on a 3.3M sample corpus for embodied reasoning: metric distance estimation, free space detection, cross-view object tracking, scene geometry reconstruction. The skills general-purpose VLMs do not test.
Results Look Promissing 63.8% average across 13 embodied reasoning benchmarks. Outperforms GPT-5 and Gemini Robot ER-1.5 on 9 of 13 tasks. Outperforms π0.5 across 7 simulation and real-world benchmarks.
The architecture uses per-layer KV conditioning between the VLM and a flow-matching action expert trained with DiT-style transformers. This bridges discrete reasoning tokens to continuous control trajectories while exposing the attention state the VLM itself uses.
This is the deployment model NeuraCore advocates for: standardized ecosystems with reproducible training data. Custom infrastructure for every embodiment is technical debt that prevents fleet scaling.
Nice work from @hq_fang, @DJiafei, and the team at @allen_ai
4
32
3,266
Kyle🤖🚀🦭 retweeted

May 7
when my phd advisor asks me for a weekly update on my experiments
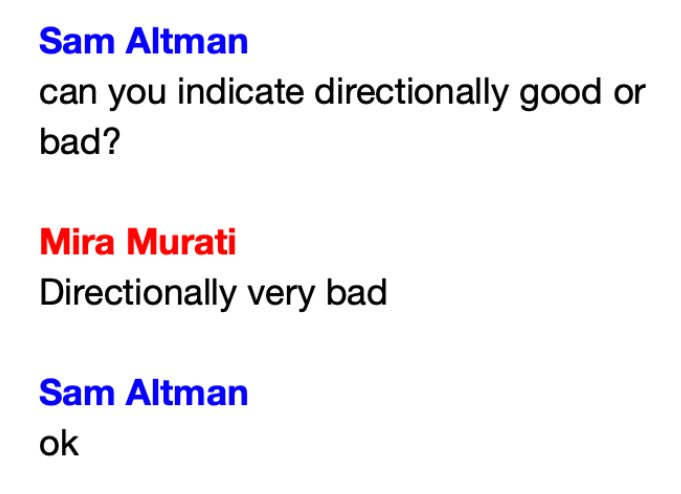
10
124
3,511
112,533