
1 Photos and videos
Valentin Thomas retweeted

May 1
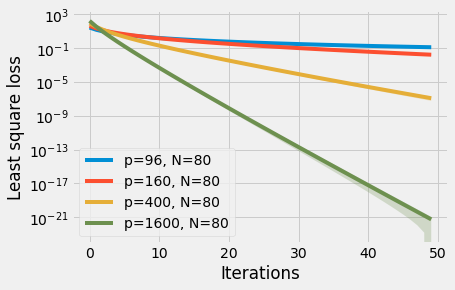
Keller's approach (ultra-fast iteration) is promising because it lead to the first major innovation since Adam (Muon). CIFAR was only 2 seconds to train end-to-end which meant he could try many ideas fast. His first unoptimized Muon run was something like 30 seconds but it was clear it was onto something due to large drop in steps
Apr 28

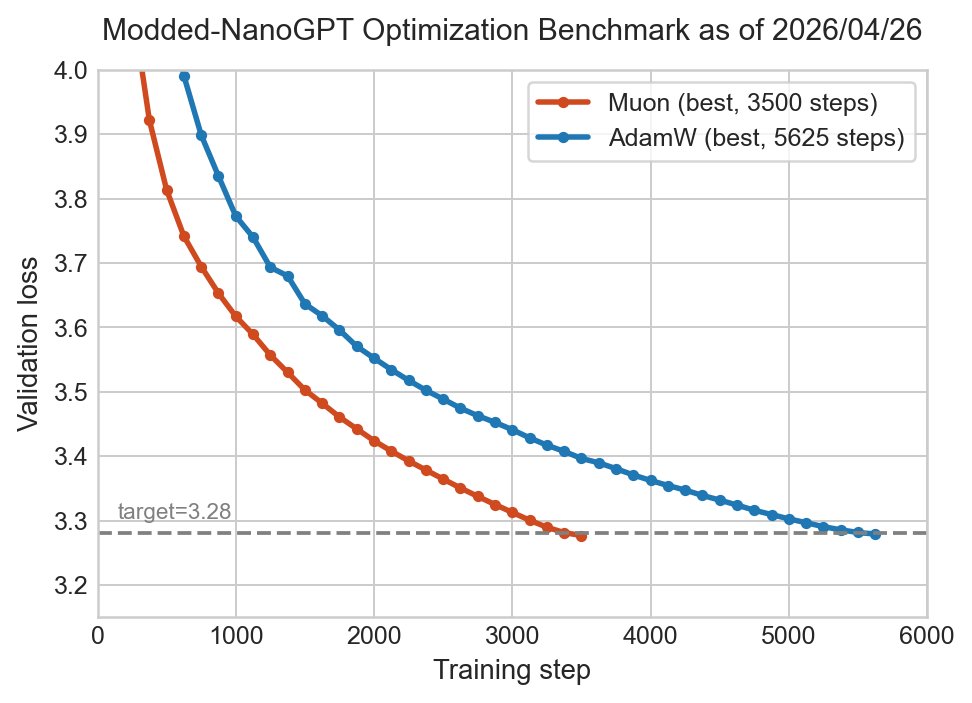
Modded-NanoGPT Optimization Benchmark
Hundreds of neural network optimizers have been proposed in the literature, recently including dozens citing Muon: MARS, SWAN, REG, ADANA, Newton-Muon, TrasMuon, AdaMuon, HTMuon, COSMOS, Conda, ASGO, SAGE, and Magma, to name a few.
The majority of this innovation is happening in the public research community. But the community currently lacks a widely accepted, easily accessible way to compare and make sense of the deluge of methods. As a result, promising new ideas get buried, and spurious results go unchallenged.
To help address these issues, I'm releasing a new optimization benchmark. It's designed for maximum simplicity and speed: Just a single file containing ~350 lines of plain PyTorch, which can complete a baseline LM training within 20 minutes of booting up a fresh 8xH100 machine. It also works with {1,2,4}xH100 or A100. These attributes make the new benchmark more accessible than any prior work.
The rules are simple: The optimization algorithm can be changed arbitrarily, with the goal being to minimize the number of training steps needed to reach 3.28 val loss on FineWeb (this is the same target loss as in the main speedrun). Modifying the architecture or dataloader, on the other hand, is not allowed. Wallclock time is unlimited, in order to give a fair chance to optimizers which would need kernel work or larger scale to become wallclock-efficient.
Like the main NanoGPT speedrun, submissions are open, and new results will be publicly broadcast. Beyond just improving the step count record, another goal of the benchmark is to collaboratively produce well-tuned baselines for as many optimizers as possible. For example, any improvement to the benchmark's best hyperparameters for AdamW would be considered a worthwhile new result.
This benchmark is not intended to be the final measure of optimizer quality across all domains. Convenient shared experimental infrastructure which covers the full space of possibilities -- across varying batch size, tokens per parameter, model scale, epoch count, and architecture -- is desirable, but far beyond the current status quo. This benchmark is only meant to be one step towards that goal.
To start the benchmark off, I've spent ~20 runs tuning baselines for Muon and AdamW. From time to time over the next few weeks, I'll add another optimizer from the literature, with my best effort at finding good hyperparameters. Researchers interested in neural network optimization are invited to join in by picking an optimizer and giving it a try on the benchmark. All optimizers are welcome, and even runs that don't necessarily have the best hyperparameters are desirable additions to the repo, because each new run adds to the collective knowledge.
1
17
206
33,030
Valentin Thomas retweeted

Jan 20
Me defending my O(n^3) solution to the coding interviewer.
413
4,947
48,972
3,976,468
Valentin Thomas retweeted

Like @davidbessis and others, I think that Hinton is wrong. To explain why, let me tell you a brief story.
About a decade ago, in 2017, I developed an automated theorem-proving framework that was ultimately integrated into Mathematica (see: youtube.com/watch?v=mMaid2jY…) (1/15)

Geoffrey Hinton says mathematics is a closed system, so AIs can play it like a game.
They can pose problems to themselves, test proofs, and learn from what works, without relying on human examples.
“I think AI will get much better at mathematics than people, maybe in the next 10 years or so.”
128
490
2,809
848,306
Valentin Thomas retweeted

12 Jun 2025
Maybe to one's surprise, taking KL estimates as `kl_loss` to minimize does *not* enforce the KL.
This implementation, however, is quite common in open source RL repos and recent research papers.
In short: grad of an unbiased KL estimate is not an unbiased estimate of KL grad.
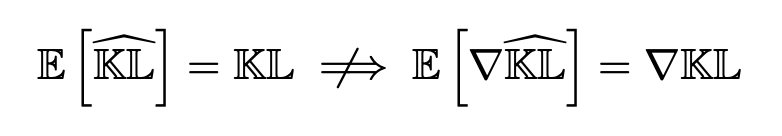
15
54
657
71,257
Valentin Thomas retweeted

10 Jun 2025
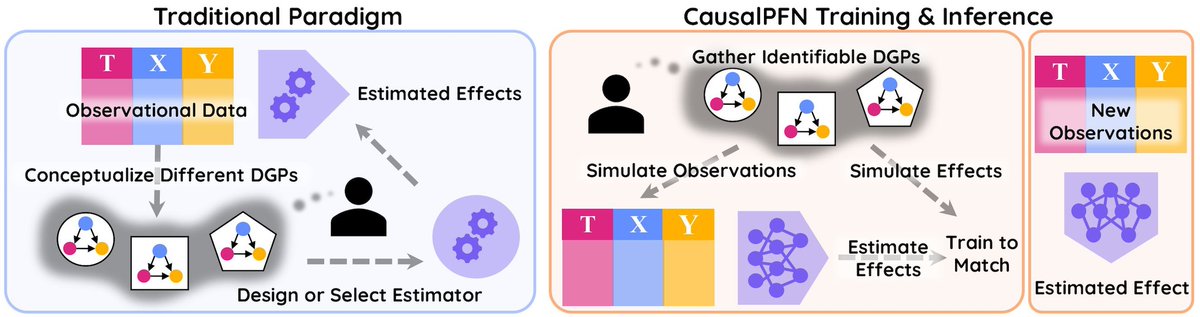
Can neural networks learn to map from observational datasets directly onto causal effects?
YES! Introducing CausalPFN, a foundation model trained on simulated data that learns to do in-context heterogeneous causal effect estimation, based on prior-fitted networks (PFNs). Joint work with @Layer6AI & @hamid_R_kamkar
w/ @_valthomas, Jeremy Ma, Benson Li, Jesse C. Cresswell, & @rahulgk
📝ArXiv: arxiv.org/abs/2506.07918
🔗Code: github.com/vdblm/CausalPFN/
🗣️Oral paper @ ICML SIM workshop
🧵[1/7]
3
11
35
3,713
Valentin Thomas retweeted

18 Feb 2025
Optimization hyperparameters (LR, schedule, weight decay) do not affect loss-to-loss scaling of LLMs (which could be seen as a proxy for generalization). ☄️
Unclear: how about different optimizers (Shampoo, ScheduleFree...)?
Plots from this paper: arxiv.org/pdf/2502.12120
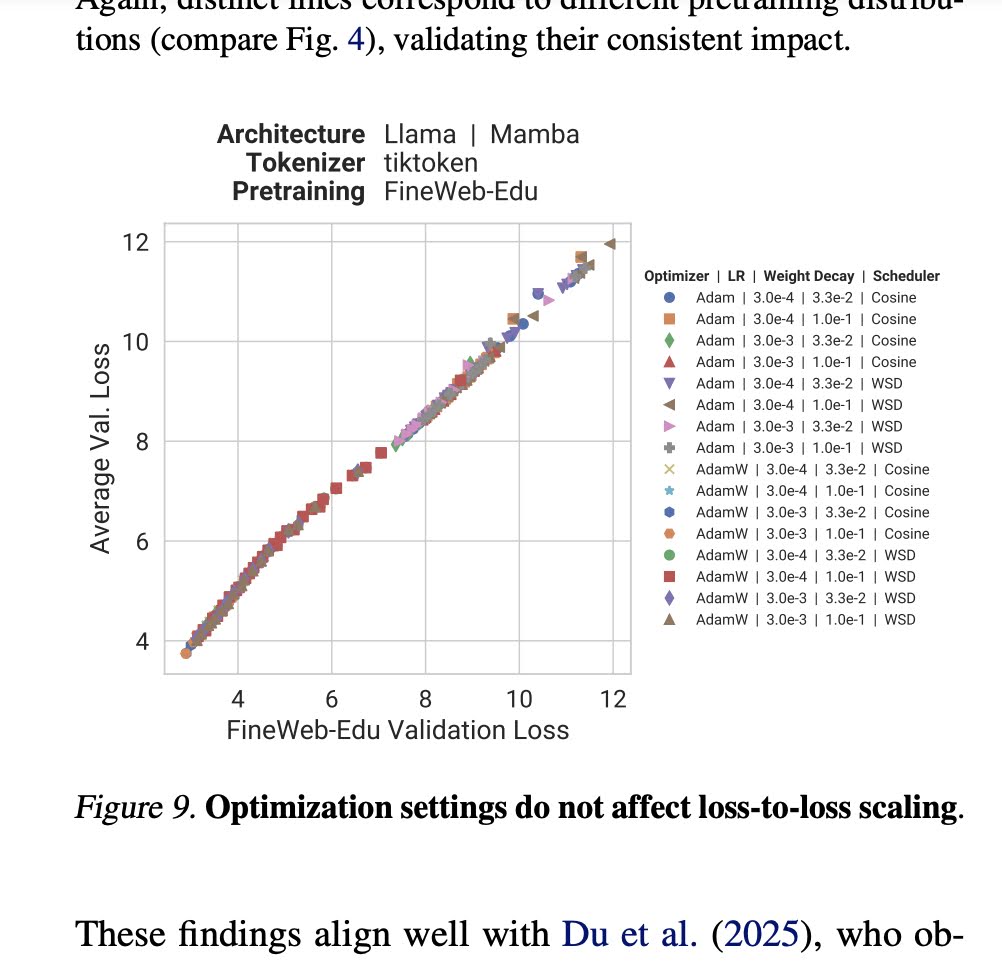
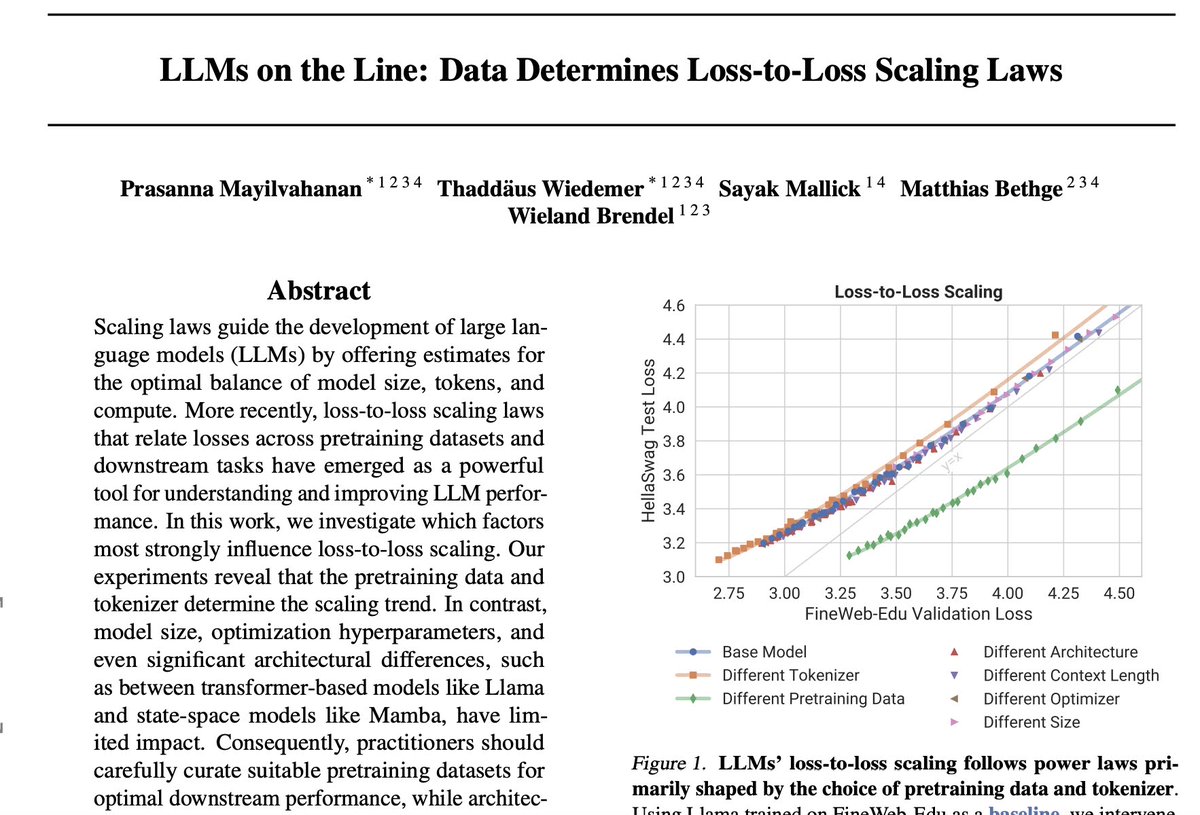
4
9
89
6,289
Valentin Thomas retweeted

10 Feb 2025
*Every single* cure for a disease ultimately flowed from basic exploratory research. Stopping basic research is like stopping the mountain rains and expecting rivers of cures to still flow. Examples:
1) studying saliva of Gila monster -> GLP1's
2) studying funghi -> first statins
3) mRNA biology -> gene therapy for spinal atrophy
4) studying bacterial genetics -> CRISPR gene therapies
5) studies of nuclear magnetic resonance -> MRI scans
this list can go on and on. Not only in biology but all aspects of technology.... e.g.
6) curvature of spacetime -> GPS
7) quantum mechanics -> semiconductors
8) electromagnetism -> fiber optics -> internet
...
9 Feb 2025

As a taxpayer (irrespective of whether you’re a scientist) would you would be in favor of more of the @NIH budget going to fund efforts to solve specific diseases at the expense of basic exploratory research? Which diseases?
171
1,420
9,950
743,223
Valentin Thomas retweeted

10 Feb 2025
see this decoder only autoregressive transformer? that's right. it goes in the neurosymbolic AI hole

20
29
802
25,195



Valentin Thomas retweeted

31 Jan 2025
Today we’re thrilled to announce that real-time and historical AI-based weather forecasts from @Google’s WeatherNext suite of models are now available on Earth Engine and BigQuery. Anyone can access and use these data for research, analysis and operational decision making, which we hope will help accelerate research and development in the weather and climate community.
You can check out the AI-powered forecasts here: deepmind.google/technologies…
7
48
268
31,236
Valentin Thomas retweeted

26 Jan 2025
With R1, a lot of people have been asking “how come we didn't discover this 2 years ago?”
Well... 2 years ago, I spent 6 months working exactly on this (PG / PPO for math gsm8k), but my results were nowhere as good.
Here’s my take on what blocked me and what’s changed: 🧵
13
131
1,599
356,714
Valentin Thomas retweeted

21 Nov 2024
Bonjour-Hi!
1) We moved to Montreál! It is good to be back and lovely so far.
2) I joined the Department of Computer and Software Engineering of the Polytechnique Montréal @polymtl as an associate professor and Mila @Mila_Quebec as the core academic member. 🇨🇦
More news to come!
22
7
240
13,806
Valentin Thomas retweeted

1 Nov 2024
🚀Our tabular foundation model (TabDPT) is out and performs out-of-the-box classification/regression tasks with a single forward pass!
📊Test out the code: github.com/layer6ai-labs/tab…
📜Paper: arxiv.org/pdf/2410.18164v1
To learn more, follow the thread! 🧵(1/5)
1
3
9
592
Valentin Thomas retweeted

3 Jul 2024
Introducing ReSearch: An iterative self-reflection algorithm that enhances LLM's self-restraint abilities:
• Encouraging abstention when uncertain
• Producing accurate, informative content when confident
Result: Significant accuracy boost for Llama2 7B Chat and Mistral 7B! 🚀
1
43
99
18,356
Valentin Thomas retweeted

18 Jun 2024
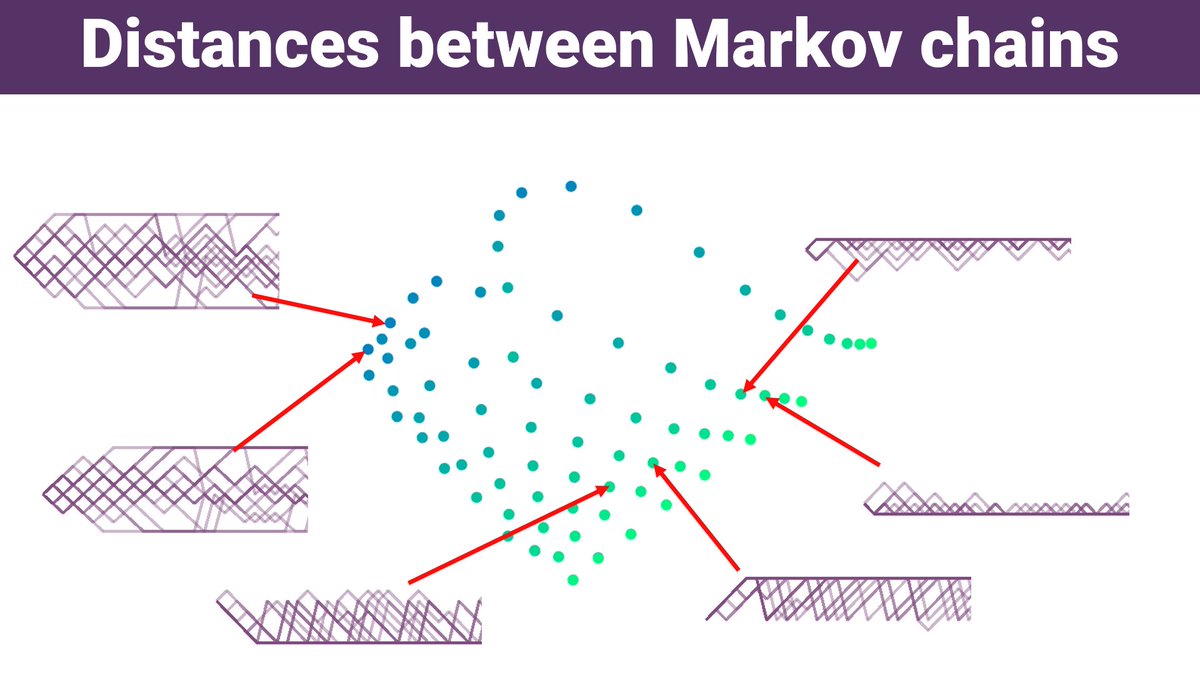
OK, time for some tweets about distances between Markov chains! Actually this is about a preprint we've just posted on arxiv with Sergio Calo, Anders Jonsson, Ludovic Schwartz & Javier Segovia-Aguas. FFO optimal transport & bisimulation. Let's dig in!
arxiv.org/abs/2406.04056
1/n
8
77
400
59,027

23 May 2022
100%! Investigative papers are my favorite to write yet they are so hard to publish if you don't have SotA or an all-explaining theoretical result. However the issues they raise are sometimes what makes science progress further later on.
1
4
Valentin Thomas retweeted

2 May 2022
@le_roux_nicolas, @BachFrancis: today it is the 10-year anniversary of the stochastic average gradient (SAG) paper getting rejected from ICML.
4
26
288
Valentin Thomas retweeted

21 Apr 2022
Aaand it's a 100 ⭐️ I've been working on #PaperMemory with 1 goal: automate the recording of papers I read on @arxiv_org or @openreviewnet and the discovery code w/ @paperswithcode. It's a simple browser extension that changed my #research workflow github.com/vict0rsch/PaperMe…
5
29
189
Valentin Thomas retweeted

28 Jul 2021
My PhD thesis is now online (thesis.library.caltech.edu/1…).
7
29
201