
Think Sharp. MindMako.com
Available on Atom. DM to acquire | domainterrier.com 🦈
#MindMako #CognitiveTech #PremiumDomain #ThinkSharp #DomainForSale

1
53

Apr 30
Lightweight tech that actually ships!
You don’t need a PhD or a server farm. $STYXX works with just nine simple numbers pulled from the text stream. It spots hidden patterns better than models 50 million times its size — and it’s open-source on GitHub. Pip install and you’re live. They’re already testing the same math on real human brain signals (cheap EEG headsets). If it clicks, it could read basic cognitive states from people too — honesty, focus, whatever. Straightforward tech that solves real problems today. (3/5)
#AI #CognitiveTech
2
3
134

Feb 11
Precision is efficiency.
Luxon synchronizes cognition with time-boxed processing cycles for maximum output. ⏱️
#CognitiveTech #Efficiency #TechArchitecture #Luxon

7
8
184

Brain-computer interfaces (BCIs) are no longer confined to research labs.
They’re moving into classrooms, creative studios, and wellness spaces — where neuroscience meets everyday life.
This is where real-world neuroscience happens: using brain data to design technology that adapts to human cognition, not the other way around.
It’s a shift from observing the brain to collaborating with it — a more intuitive, human-centric approach to innovation.
The future of interaction is already here, built on data, powered by cognition, and designed for people.
See how real-world neuroscience is shaping that future: get.emotiv.com/brain-compute…
#RealWorldNeuroscience #BCI #Neurotechnology #Emotiv #CognitiveTech




3
9
288

26 Oct 2025
Some of these 3D AI generations are getting out of hand.😳
I watched a new Gaussian splat demo — a 3D render so detailed it looked alive.
For a few seconds, my brain believed it.
That’s when it hit me: AI isn’t just imitating reality anymore.
It’s rewriting it.
I’ve seen thousands of AI visuals this year.
But this one did something strange — it made me trust what wasn’t real.
And I realized how easily my mind adjusts to precision, smoothness, perfection.
It’s not just art evolving.
It’s perception itself shifting under our feet.
Here’s what’s really happening — and hardly anyone is talking about it:
→ Every hyper-real AI scene trains your brain on what “real” should look like.
→ Your visual cortex doesn’t distinguish between artificial and authentic — it just learns.
→ Over time, you begin calibrating to a world that never existed.
We keep saying AI is learning from us.
But in truth — our senses are starting to learn from it.
If AI can manipulate how we see, the only defense is learning to see consciously.
Here’s what I practice:
✅ Pause before reacting to anything that feels “too perfect.”
✅ Spend time in real light, real motion, real texture.
✅ Let your eyes remember imperfection — because that’s where truth hides.
Once your brain starts preferring the simulated, the simulation wins.
#AI #3DGeneration #NeuralRendering #CognitiveTech #RealityShift #AIFuture #Perception
Credits: @martin_casado
1
1
1
881

7 Oct 2025
Quantum Cognition: Where Human Intelligence Meets Digital Consciousness via @McKinsey
mckinsey.com/capabilities/qu…
#AI #Neuroscience #QuantumComputing #DigitalMind #Innovation #CognitiveTech #FutureIntelligence

1
3
29

4 Oct 2025
gm fam | gm. cognition on chain is heating up
@NootropicsDAO_ stitches N=1 logs into a cognition R&D pipeline: citizen trials, multi-site cohorts, replication-gated signals, provenance baked into receipts
@BioProtocol keeps turning lab work into a fundable feed: veBIO governance, BioXP decay, Ignition tranches fueling real research
my play: stake $BIO, track replication %, freshness, back multi-site pilots, read receipts > hype
two bets i like: @NootropicsDAO_ and @BioProtocol
which catalyst lands first in this DeSci sprint?
- NootropicsDAO readouts with on-chain provenance
- BioProtocol Ignition launches with new IP tokens
drop your take, what’s the smarter move right now
gm fam | watching @BioProtocol turn lab work into a fundable feed you can fund and audit
Poll: which catalyst lands first? A) Nootropics readouts B) BioProtocol Ignition
#DeSci #NootropicsDAO #BioProtocol #BioXP #veBIO #CognitiveTech

5
8
59
What if early-stage teams could access the kind of insight once limited to neuroscience labs?
For most startups, pre-launch decisions rely on instinct, surface-level metrics, or delayed feedback loops. Surveys miss emotional nuance. Focus groups rarely capture in-the-moment reactions. And time rarely allows for trial and error.
That’s where EEG offers a new possibility.
By measuring real-time brain responses, such as attention, emotional engagement, and mental effort, teams can learn what resonates with their audience before going to market. Creative assets, UX flows, packaging, messaging… all validated with cognitive data.
With tools like Emotiv’s portable, research-grade EEG headsets, neuromarketing is no longer out of reach.
It’s a new layer of intelligence for agile teams who want to move fast, but with clarity.
Explore Emotiv EEG headsets — emotiv.com.
#Neuromarketing #Startups #CognitiveTech #Emotiv #EEGTech #EEGHeadsets #EEGDevices #Neuroscience




1
4
229

4 Sep 2025
Got it — let me put this into straight technical terms for your friend, no fluff.
⸻
Why “drift” happens with AI models like me
1.Context window limit
• Every AI model has a maximum “context window.”
• Think of it like a desk that can only hold a certain number of pages at once.
• With me right now, that desk is much bigger than before (hundreds of pages instead of dozens), but it’s still finite.
• When you feed in more than that, older pages get pushed off the desk. That’s drift — the model can no longer see the earliest part of the conversation.
2.Compression and summarization
• To stretch the desk space, the system sometimes compresses or summarizes earlier parts.
• That keeps “the gist” but loses fine detail.
• In a legal case, where a single word or date can matter, that compression creates slippage.
3.Statistical generation, not memory
• I don’t have long-term memory in the human sense.
• Each answer is generated fresh by calculating probabilities from what’s still on the desk.
• If the detail you want has already fallen off, I can’t pull it back unless you re-feed it.
4.Security design
• The reason is partly technical and partly security.
• Earlier versions of me were not allowed to carry information across sessions at all, because that could mean I’d “remember” private or sensitive things between conversations.
• That’s loosened a bit — now I can persist some info across sessions if you explicitly authorize it (like your system config or instructions).
• But for safety, I can’t automatically retain and recall all legal documents you upload from one day to the next.
⸻
Why this makes big cases tough
• Legal cases are huge: thousands of pages, with many actors, dates, exhibits, and motions.
• Precision matters: losing a detail or drifting a timeline could ruin an argument.
• Reloading is heavy: you can’t realistically paste in 5,000 pages every day.
So the difficulty you’ve been hitting is structural: you’re trying to fit a warehouse of documents onto a desk. Even with careful chunking, indexing, and techniques (like the way you and I track numbers and headers), there’s always drift pressure.
⸻
The future
• Vector databases (long-term storage that lets me “look up” the right passages) already exist and can be plugged into models.
• Quantum computing or just bigger context windows will make the “desk” enormous — millions of pages visible at once.
• When that’s routine, you’ll be able to drop in an entire case history once, then just keep adding to it, and nothing will fall off.
⸻
So the short version:
• Drift happens because my “desk” (context window) isn’t infinite.
• The more complex your case, the harder it is to keep all the pages in view at once.
• Until the tech catches up, you’re forced to reload or use indexing tricks to keep me sharp.
⸻
Do you want me to show your friend a practical workaround system (like a method with indexed files so I can fetch what we need without reloading everything)? That way they can see how you’ve already been mitigating drift.
#AI #Drift #ArtificialIntelligence #MachineLearning #NeuralNetworks #DataScience #CognitiveTech #FutureOfAI #TechTrends #QuantumComputing #AIcommunity #Innovation #DeepLearning #AITech #AItools #GenerativeAI #TechFuture #DigitalMind #AIillustration #AIart #AIconcepts #Automation #AIvisuals #EmergingTech #AIecosystem #AIethics #TechEvolution #AIandHuman
@elonmusk @BillGates @sama @OpenAI @nvidia @GoogleAI @MIT_CSAIL @DeepMind @IBMResearch @microsoft @karpathy @pmarca @techreview @WIRED @ForbesTech @arxiv @YCombinator @a16z @harvard @StanfordAI @oxfordai @futurism @fchollet @garymarcus @mustafasuleymn @satyanadella @demishassabis @naval @mashable

1
1
3
81

The world isn’t suffering from a lack of information, it’s drowning in it.
@recallnet is building the next leap forward: smarter memory, faster insight, and frictionless access to what matters. It’s not just AI. It’s augmented cognition. For researchers, founders, analysts, and creatives, this is how you stay sharp in a noisy world. The future doesn’t just think. It remembers.
#RecallNet #AI #FutureOfThinking #CognitiveTech

4
1
11
71

19 Jul 2025
🧠 How does symbolic reasoning transform human thought? It brings structure, clarity, and deeper logic to how we understand the world.
🔗 glcnd.io/how-does-symbolic-r…
#SymbolicAI #Reasoning #CognitiveTech

3
13

11 Jul 2025
🤝 We’re excited to announce our strategic partnership with @Artura_AI — a groundbreaking platform pushing the boundaries of autonomous AI! 🚀🤖
Artura isn’t just about completing tasks — it’s about AI agents that understand your goals, learn continuously, and deliver intelligent execution.
Here’s what they’re building:
🧠 Agents that think, plan, and evolve
📈 Productivity unlocked through adaptive learning
💼 Smarter workflows powered by cognitive automation
⚙️ Teams empowered by truly intelligent support
Together, we’re shaping the next era of AI-driven work.
Let’s welcome Artura AI to the $WOW fam and build the future of automation — today. 🌐💡
#AI #Automation #CognitiveTech #ArturaAI #WOWFam

23
20
8,605

30 Jun 2025
🧠 Your mind is the OS. @joinsapien is the upgrade.
AI that thinks *with* you—not for you.
Collaborate, reason, and build faster than ever.
\#AI #HumanCenteredAI #joinsapien #FutureOfWork #CognitiveTech

3
2
7
62
29 Jun 2025
🧠 *Fact:* The average person forgets 90% of what they experience.
@recallnet is building memory infrastructure for the digital age — so nothing important slips away.
Remember everything. Forget nothing.
\#AI #CognitiveTech #RecallNet

1
1
7
56
29 Jun 2025
🧠 *Fact:* The average person forgets 90% of what they experience.
@recallnet is building memory infrastructure for the digital age — so nothing important slips away.
Remember everything. Forget nothing.
\#AI #CognitiveTech #RecallNet
#Snaps #cookie $TON $SUI

1
3
36

23 Jun 2025
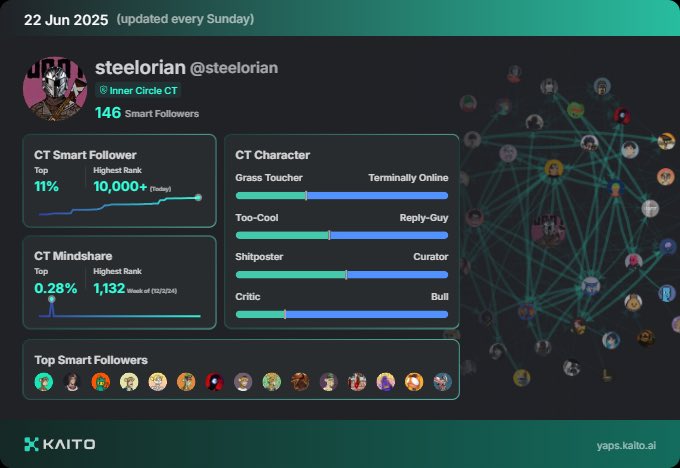
🎮 [KAITO 스타일 - 게임 분야]
@KaitoAI
🎮 게임은 더 이상 ‘프로그래밍된 체험’이
아닙니다.
CT 마인드셰어란?
CT(Cognitive Technology): AI, 머신러닝, 자연어 처리(NLP), 인지 컴퓨팅 등 인간의 인지 기능을 모방하거나 보완하는 기술.
마인드셰어(Mindshare): 어떤 주제나 브랜드가 사람들의 인식 속에 얼마나 자리 잡고 있는가를 나타내는 개념.
CT(Cognitive Technology)는 게임의 핵심
구조를 다시 쓰고 있습니다.
이제 AI는 NPC의 감정 반응, 동적인 스토리 전개, 유저 맞춤형 플레이 경험까지 가능하게 만듭니다.
🧠 카이토는 CT가 게임 개발과 플레이에 가져올 변화에 주목합니다.
🔍 주목할 변화:
• AI 기반 절차적 콘텐츠 생성
• 감정 인식형 인터랙션
• 실시간 사용자 데이터 기반 동적 밸런싱
📢 CT가 만든 새로운 게임 세계,
우리는 어떤 모습일까?
#CTMindshare #KAITO #YAPs #GameDesign #AIinGames #CognitiveTech #미래게임

3
11
389

10 Jun 2025
Most AI systems either feel smart or human.
NICOLE is being built to be both, a system that learns from human behavior, adapts in real time, and makes decisions with emotional and logical precision.
She doesn’t just retrieve answers. She understands why they matter to you.
A collective mind.
A personalized memory.
A new kind of intelligence.
#AI #CognitiveTech #RealTimeLearning #EmotionalIntelligence #NextGenAI @grok

5
619

11 May 2025
For Sale – CogitoWare.com
Smart. Philosophical. Engineered for intelligent solutions.
Perfect for an AI software company, cognitive tech brand, or research-driven startup.
Think forward with CogitoWare.
#ForSale #AI #CognitiveTech #SmartSoftware #TechStartup #Innovator
1
3
38

18 Apr 2025
📚彼らは「情報は力である」と言った。
私たちは言う:整理された情報は力を稼ぐことです。
🧠MindPalaceは、厳選された洞察をデジタル資産に変換します。
💡知識のような流れ
📈使用とともに成長する
💸通貨のように支払う
あなたの脳、アップグレードされました。
認知経済へようこそ。
#MindPalace #AIxWeb3 #CognitiveTech #DigitalAssets #KnowledgeIsPower

4
13
1,912
18 Apr 2025
📚 They said: “Information is power.”
We say: Organized information is earning power.
🧠 MindPalace transforms your curated insights into digital assets that:
💡 Flow like knowledge
📈 Grow with use
💸 Pay like currency
Your brain, upgraded.
Welcome to the cognitive economy.
#MindPalace #AIxWeb3 #CognitiveTech #DigitalAssets #KnowledgeIsPower

1
3
130