
Feb 20
Spring Boot Vue3 前后端分离 实战wiki知识库系统
pan.quark.cn/s/08169cb353a9
尚硅谷大数据技术之FlinkSQL - 带源码课件
pan.quark.cn/s/35a87899c480
红逗号小学1-6年级数学思维闯关,分层递进式思维训练系统
pan.quark.cn/s/e0151e77a907
极客时间-分布式系统案例课
pan.quark.cn/s/f81ce1ca5460
4
518


5 Dec 2025
Grab enhances its data platform with real-time quality monitoring for Apache Kafka. The new system leverages FlinkSQL and an LLM to identify data errors, ensuring cleaner data streams. This proactive approach improves data reliability for downstream users. #Strategy
2
24

30 Nov 2025
Every arc represents a real order, drawing an as-the-crow-flies path from shop to buyer. Under the hood, Apache FlinkSQL pipelines process a firehose of events to define arcs and compute sales and buyer metrics, and Grafana powers our infrastructure stats.
3
150

11 Aug 2025
Flink SQL looks simple, but there’s a full optimizer behind it.
At Flink Forward Barcelona 2025, Muhammet Orazov explains how query plans are built and optimized, from rules to cost models.
👉 Register: hubs.li/Q03C4psp0
#FlinkForward #ApacheFlink #FlinkSQL

2
9
402

22 Jun 2025
Dockerized runner, utilities, and functions for FlinkSQL applications
#apacheflink
github.com/DataSQRL/flink-sq…
1
7
395

20 Jun 2025
Stateless vs. Stateful #StreamProcessing with #KafkaStreams #ApacheFlink
Learn when to use filters vs. windows, how to embed #AI/#MachineLearning, and why stream processing powers modern #DataStreaming.
🔗 kai-waehner.de/blog/2024/12/…
#RealTimeData #FlinkSQL #EventDriven
5
212



5 Mar 2025
Summary of my recent #FlinkForward talk "Building #Copilots with #FlinkSQL, LLMs & Vector DBs":
🤖 AI Assistants & self-serve AI/BI for streaming & batch data
🧠 AI-powered schema intelligence
🔄 Natural Language to generate Flink SQL jobs
⚙️ Continuous monitoring for agentic AI
2
5
235

12 Feb 2025
🎉 Let’s unleash the track Mind the Geek at Voxxed Days Amsterdam!
This is where the most creative, nerdy, and out-of-the-box talks happen! A mix of fascinating tech, unconventional thinking, and hands-on home projects 😆🚀
Meet @TheDanicaFine as she brings open-source magic to life with an exciting tech stack:
📡 Tech stack: #Kafka, #Flink, #Apache Iceberg and a Raspberry Pi
Tired of interruptions during calls? Learn how to capture live events from Zoom, process data streams with FlinkSQL, and store insights with Iceberg, all while building a custom on-air sign using open-source technologies!
🎟 Redeem your early bird spot (last week) via amsterdam.voxxeddays.com
Tracklead: @KayaWeers
CFP board: @Sander_Mak, @iamsoham, Simone de Gijt, , @MichelSchudel, @wilcoburggraaf, @MaritvanDijk77, @jlengrand, @KoTurk77
#VoxxedAmsterdam
@voxxed @Devoxx

2
7
600

9 Nov 2024
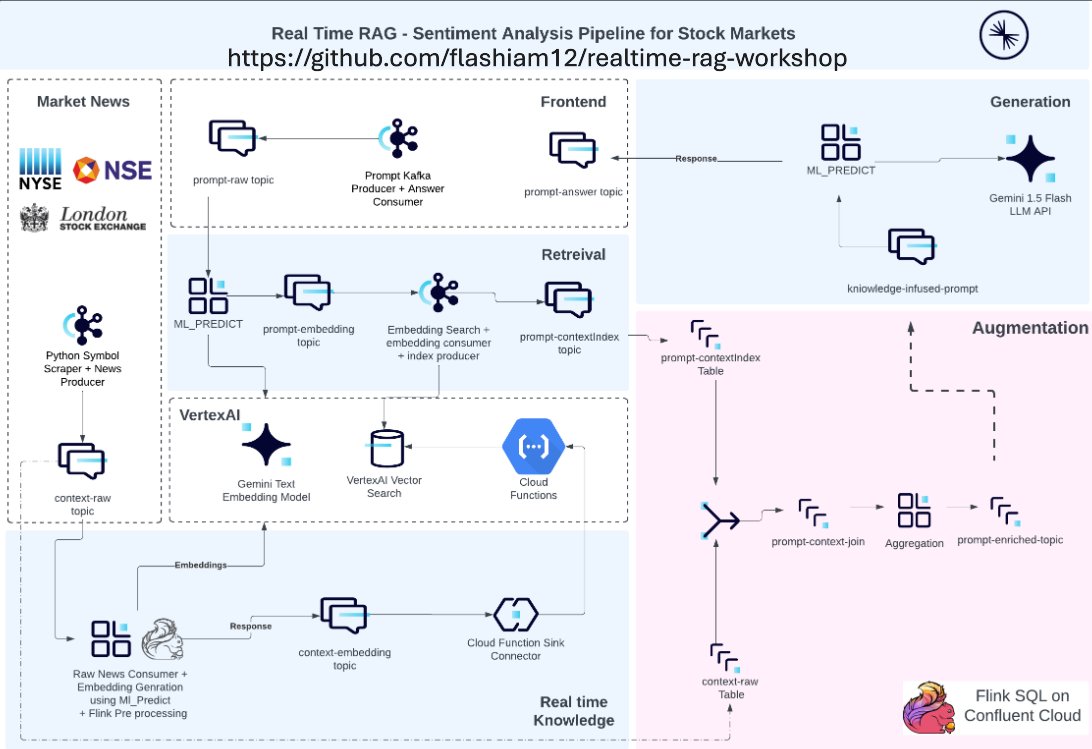
Great workshop from @confluentinc: Real-time sentiment analysis pipeline leveraging the power of @ApacheFlink , vector databases, and Large Language Models (LLMs) from @Google
"With Confluent Cloud Kafka as the central nervous system, the idea to operationalize and adopt GenAI managed services from various hyperscalers looks a very feasible reality.
This hands-on workshop dives deep into building a real-time sentiment analysis pipeline leveraging the power of FlinkSQL, vector databases, and Large Language Models (LLMs). We'll explore how to:
Harness FlinkSQL for data enrichment: Aggregate real-time financial data and market news analysis, enriching prompts with context retrieved from a vector database using FlinkSQL's powerful JOIN capabilities.
Connect to the AI ecosystem: Seamlessly integrate embedding models, LLMs, and external APIs through Kafka Connectors, simplifying communication and data flow.
Build scalable pipelines with Confluent Cloud: Leverage the robustness of Confluent Cloud Kafka clusters and Flink compute pools for real-time processing and analysis."
2
210

Uber has built a robust real-time data infrastructure to process Petabyte-scale data per day, using open-source technologies like Apache Kafka, Flink and Apache Pinot - these support production machine learning applications that require processing massive data volumes with low latency.
Uber enables scalable stream processing and low-latency analytics critical for ML workflows like real-time prediction monitoring by enhancing these tools through leveraging frameworks such as FlinkSQL for easier streaming job creation with SQL and adding upsert capabilities to Pinot for real-time data updates.
This is quite an interesting deep dive from Uber into their challenges and lessons learned throughout their large-scale data journey.
Paper: buff.ly/3UcHt5B
--
If you liked this article you can join 60,000 practitioners for weekly tutorials, resources, OSS frameworks, and MLOps events across the machine learning ecosystem: buff.ly/4813RDa
#ML #MachineLearning #ArtificialIntelligence #AI #MLOps #AIOps #DataOps #augmentedintelligence #deeplearning #privacy #kubernetes #datascience #python #bigdata
4
216

7 Oct 2024
#communityOverCode schedule change this morning! Catch @bbejeck in Mt. Columbia NOW for windowing in #flinkSQL and #kafkaStreams!
1
1
4
483

3 Oct 2024
Watermarks are at the heart of what makes stream processing with #FlinkSQL possible. Join @alpinegizmo as he explains the ins and outs of watermarking in in the latest video from his new course on #ApacheFlink SQL.
Check it out on Confluent Developer ➡️ cnfl.io/3XSiR2Z

1
3
1,057
26 Sep 2024
🚨 New Course Alert: Apache Flink® SQL
Curious about #ApacheFlink? Learn how #FlinkSQL works and what you can do with it in this introductory course from David Anderson.
Get started here ➡️ cnfl.io/4eg5D7l

1
10
1,558
16 Sep 2024
🚀 Excited to speak at #Current24 in Austin on building AI Assistants / Copilots with #FlinkSQL!
📍Wed Sep 18, 11 AM CDT, Room F
💡 Self-serve AI/BI 🔗 LLMs structured data 📝 Annotate schemas for data intelligence 📊 Unstructured data & RAG 🛠️ Demo
events.bizzabo.com/599116/ag…

8
158

21 Aug 2024
that escalated quickly…
#current24 #flinkSQL
20 Aug 2024

Starting to organise my thoughts for writing my #Current24 talk, which is going to be all about fun and frolics with #FlinkSQL 😁
1
2
993
20 Aug 2024
Starting to organise my thoughts for writing my #Current24 talk, which is going to be all about fun and frolics with #FlinkSQL 😁
2
13
2,796
15 Aug 2024
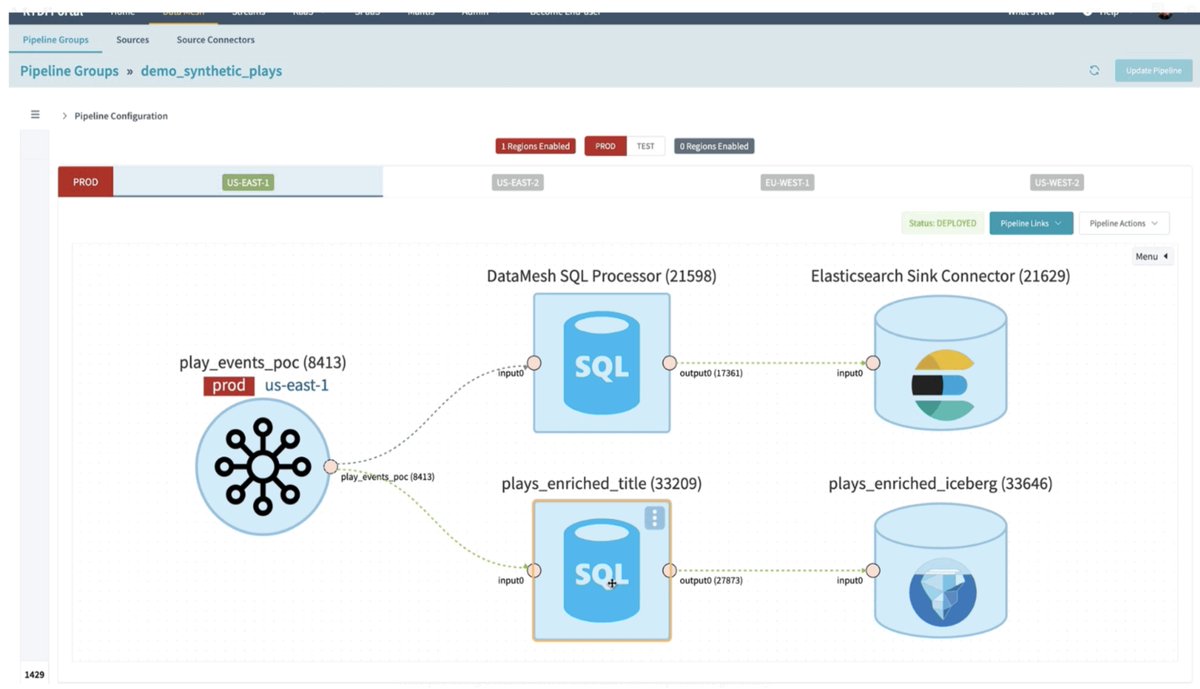
"Streaming SQL in #DataMesh with #ApacheFlink at #netflix"
=> A new abstraction layer with #flinksql to enable simple but scalable and flexible stream processing.
The apps are decoupled by #apachekafka and stored with open table format #apacheiceberg.
netflixtechblog.medium.com/s…
3
9
536
4 Aug 2024
Exploring #ApacheFlink 1.20 is #GA: Features, Improvements, and More...
And the community is doing its final preparations to prepare for Flink 2.0!
Improvements to #FlinkSQL and #DataStream API. Plus improvements to disaster recovery capabilities.
#streamprocessing #opensource

1
12
352