
Ceinsys Tech has secured international purchase orders worth $3.16 million (~₹30.06 crore) from T Second Inc, USA, marking a significant step in its global AI and technology expansion. The orders cover NVME drive supply, AI-powered building/road extraction and asset monitoring on the BRYCK AI platform, and Enterprise Geospatial Imagery Repository & AI Feature Extraction solutions.
📌 Timeline:
• Order received: 13 June 2026
• Execution period: Within 2 weeks
• Delivery completion target: 30 June 2026
The win strengthens Ceinsys’ overseas presence and validates its AI-led enterprise solutions strategy.
#CeinsysTech #AI #ArtificialIntelligence #GeospatialAI #EnterpriseAI #DigitalTransformation #TechStocks #SmartInfrastructure #Innovation #IndiaTech #StockMarketIndia
45

Jun 13
🌍 Traditional GIS analysis has limits. AI doesn't.
🎓 AI & GIS: from classical ML to advanced AI methods for geospatial data
👇 udemy.com/course/ai-for-geos…
#GeospatialAI #MachineLearning #RemoteSensing
9

GeoAI is transforming utilities in 2026.
Using GIS, satellites, drones, and AI, companies can predict issues, detect leaks, reduce outages, and respond faster to disasters.Smarter. Faster. More efficient
#GeoAI #GIS #RemoteSensing #AI #UtilityManagement #SmartGrid #GeospatialAI

27

Honored to have our CEO, Asim Javaid, represent AI Geo Navigators as an Observer in the UNFCCC process. This was a valuable opportunity to learn from global climate leaders, engage in meaningful discussions on climate action, and gain insights into emerging challenges and solutions shaping a more resilient and sustainable future.
@UNFCCC
@UNFCCCObservers
@CANIntl
@AIforGood
@CopernicusEU
#UNFCCC #ClimateAction #AIGeoNavigators #GeospatialAI #ClimateResilience #Sustainability




1
21


Jun 8
Remote sensing models have long faced a challenge: balancing detailed image analysis with the broader geographic context needed for accurate land-cover mapping. SFR-Net addresses this by combining local, nearby, and wide-area views of the same location, helping improve classification accuracy, especially in complex environments where context matters as much as texture.
This research highlights how multi-scale understanding can significantly enhance geospatial AI and move remote sensing beyond traditional tile-based approaches.
Thanks for sharing this insightful research, @yohaniddawela.
#GeospatialAI #RemoteSensing #EarthObservation #MachineLearning
Jun 7

Geospatial models has a strange problem. It can recognise a house in one crop, then forget the road network around it a few kilometres later.
That’s because most remote sensing models are still built around small image tiles. They label patches of land, one crop at a time. A building is a building. A road is a road. A field is a field.
But satellite imagery doesn’t work like a folder of neatly cropped photos. It comes as huge scenes covering hundreds of square kilometres, where the meaning of a pixel often depends on what surrounds it.
A narrow strip of water could be a river, canal, drainage channel, or pond edge. A pale rectangle could be a roof, greenhouse, road surface, or bare ground. The local texture gives clues, but the wider geography often gives the answer.
This creates a bit of a trade-off.
Use small crops and the model keeps sharp detail, but loses context. It can see the road surface, but loses the road network. It can label water pixels, but loses the shape that tells you whether it’s a pond, river, lake, or canal.
Use the full image and the model gets the broader scene, but fine detail gets compressed. Narrow roads blur. Small buildings disappear. Boundaries get messy.
A new paper from Beihang University and NTU tries to solve this with SFR-Net, a model for ultra-wide area remote sensing segmentation.
The core idea is pretty simple: make the model look at the same place from multiple “altitudes” at once.
For each target area, SFR-Net creates three aligned views. A local view for fine detail. A short-range view for nearby context. A long-range view for the wider landscape.
All three are centred on the same location. The model isn’t stitching together random tiles. It’s building a stack of views around one place, closer to how a person might move between a drone image, a city map, and a regional map.
The authors call this a scale-frustum representation.
Then the model fuses the views in stages. First, the local view absorbs nearby context. Then that richer view absorbs the broader scene. Instead of choosing between detail and context, it builds from one into the other.
The results are meaningful.
On GID, SFR-Net reaches 74.67% mIoU and 86.94% overall accuracy, beating the previous best by 1.72 percentage points in mIoU.
On FBPS, the harder dataset with 24 fine-grained land-cover classes, it reaches 77.24% mIoU and 92.91% overall accuracy. That’s a 4.29 point mIoU gain over the previous best.
That second result is the more interesting one. Fine-grained land-cover mapping is where the confusion gets worse: river versus pond, road versus bare ground, small building versus surrounding urban fabric.
The model improves most where geography starts doing the work that texture can’t.
Remote sensing models have borrowed heavily from normal computer vision. That helped the field move fast, but aerial imagery has a different structure. Roads, rivers, forests, cities, and fields are spatial systems. Their meaning depends on scale, shape, continuity, and surroundings.

2
18
1,198

A porch today.
A city block captured by drone tomorrow.
The future of AI isn't just understanding documents.
It's understanding the physical world.
#WorldModel #SpatialAI #GaussianSplatting #DigitalTwin #GeospatialAI #MetisOS
15

Bharat Innovates presents Cyran AI Solutions, an IIT Delhi spin off at the forefront of deep tech innovation, building enterprise grade hardware and software AI solutions for geospatial intelligence, Industry 4.0, and EdTech applications. Leveraging advanced artificial intelligence, multi sensor data fusion, computer vision, edge AI, and cyber physical security technologies, Cyran is enabling smarter decision making, real time situational awareness, and intelligent automation across critical sectors. Their mission is to empower industries through research driven innovation and indigenous technology development.
Bharat Innovates is taking Cyran AI Solutions to Nice, France | 14–16 June 2026, showcasing India's growing leadership in artificial intelligence, advanced hardware, and next generation digital technologies on the global stage.
From AI powered geospatial analytics and industrial automation to innovative educational AI platforms, Cyran is translating cutting edge research into impactful real world solutions. As industries worldwide embrace intelligent systems and automation, Cyran represents the future of Indian deep tech innovation with global relevance.
@narendramodi @PMOIndia @eduminofindia @dpradhanbjp @PrinSciAdvGoI @Vineet_K26 @sanjayjavin @IndiaDST @AICTE_INDIA @ugcindia @pibindia @DDNewslive @airnewsalerts @sjaishankaroffc @MEABharat @IndiainPortugal @IndiaembFrance @CGIMarseille @eoiberlin @IndiainIreland @HCI_London @iitbombay @SINEIITB @paniitindia @cyran_tech
#BharatInnovates #ArtificialIntelligence #DeepTech #Industry40 #GeospatialAI
12
14
2,422
💬"We're building a model of the world, rather than a world model — a layer on top of reality, not a substitute for it."
At #SXSWLondon, Niantic Spatial’s Chief Scientist, Victor Prisacariu, joined leaders from Google DeepMind and Runway to discuss the future of world models, Physical AI, and the race to transform pixels into spatially intelligent representations of reality.
#NianticSpatial #PhysicalAI #SpatialAI #WorldModels #Robotics #ComputerVision #GeospatialAI #AI

2
2
21
7,260
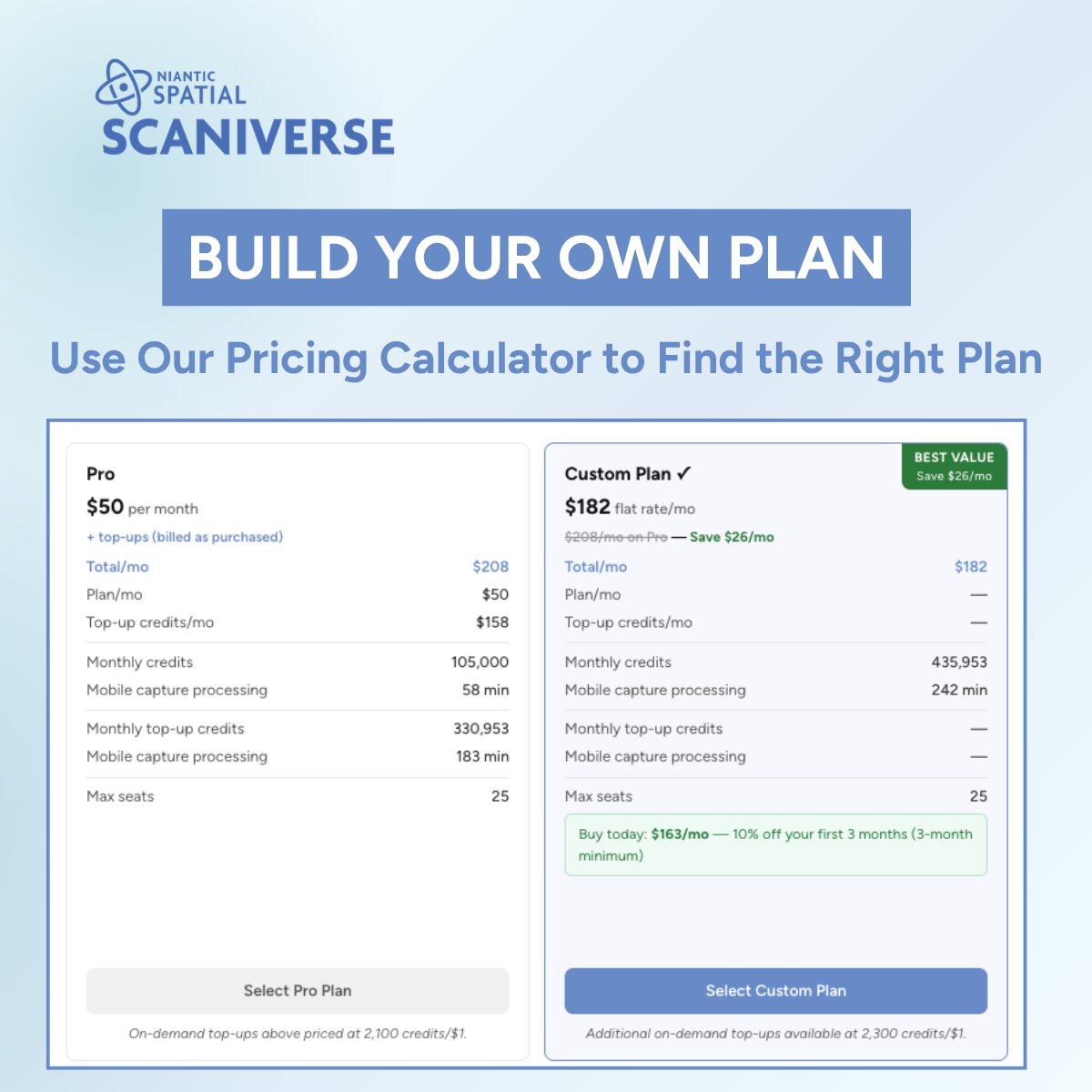
Need more flexibility for your 3D capture workflow?
Top-Up credits and annual plans are now available in Scaniverse, making it easier to scale from one-off splats to production workflows.
Not sure which plan is right for you? Build your own with our pricing calculator:
hubs.ly/Q04k8r6_0
Learn more: hubs.ly/Q04k8r_80
#NianticSpatial #Scaniverse #Reconstruction #3DScanning #GaussianSplat #360Capture #AI #GeospatialAI #PhysicalAI #VPS #SplatYourWorld
2
11
6,782
法人向けScaniverseでは、ご要望が多かった追加クレジットのご購入、「トップアップ」機能をリリースいたしました。
合わせてお得な年間プランも登場し、6月30日までにご登録頂く方へはトップアップクレジットを1ヶ月分プレゼント🎁
詳細はブログをご覧ください:nianticspatial.com/blog/scan…
#NianticSpatial #Scaniverse #Reconstruction #3DScanning #GaussianSplat #360Capture #AI #GeospatialAI #PhysicalAI #VPS #DigitalTwins

1
14
4,759
Need more Scaniverse credits? We've got good news.
✅ Top-Ups are now available for all paid accounts.
✅ Go annual with Plus & Pro. Get 2 months free.
✅ Buy an annual plan before June 30 → get a full month of bonus credits.
No plan changes. No promo codes. Just more processing power to #SplatYourWorld 🌐
Learn more: hubs.ly/Q04j_z8D0
#NianticSpatial #Scaniverse #Reconstruction #3DScanning #GaussianSplat #360Capture #AI #GeospatialAI #PhysicalAI #VPS #DigitalTwins

1
7
9,952

May 29
$PL ✨
Planet Labs : "A Long-Term Buy At The Right Price"
A recent analysis highlights Planet as one of the most compelling long-term geospatial AI and Earth observation platforms — but argues valuation discipline remains critical.
Key positives:
• Daily global Earth imaging
• AI-enabled geospatial intelligence
• $900M backlog providing multi-year visibility
• 41% Q4 revenue growth
• Four consecutive quarters of positive Adjusted EBITDA
• FY2026 free cash flow of $52.9M
The broader thesis:
Planet is increasingly being viewed not as a satellite imagery company, but as a real-world AI and data infrastructure platform.
Key growth drivers:
• Planetary Intelligence
• Defense & sovereign demand
• Climate monitoring
• AI-powered geospatial analytics
• Large Earth Models
However, the report notes that after a ~300% share price increase, valuation has become a major consideration.
Main risks:
• Continued GAAP losses
• Margin pressure
• Defense budget uncertainty
• Competition
• Elevated valuation multiples
Bottom line:
The long-term story remains attractive, but the report argues future returns may depend heavily on entry price and valuation discipline.
$PL #PlanetLabs #AI #PlanetaryIntelligence #GeospatialAI #EarthObservation #SpaceTech
1
2
937

May 28
Most AI-generated worlds are optimized to look realistic. But physical AI systems operating in the real world need something much harder: geometry that is physically consistent, spatially accurate, and grounded to real-world coordinates.
Our latest Ground Truth blog breaks down how Niantic Spatial reconstructs georeferenced 3D environments from off-the-shelf drones, phones, and 360° imagery — solving depth, alignment, and surface consistency at scale.
🔗Read more: hubs.ly/Q04jdfsS0
#NianticSpatial #Spexi #PhysicalAI #Reconstruction #GaussianSplat #DigitalTwins #Robotics #GeospatialAI #AI #GeospatialIntelligence #GEOINT #SpatialIntelligence
4
56
292
22,507

🚀 Applications are now open for the IGARSS 2026 Summer School! 🌍📡
Join us at the Fairfax Campus of George Mason University, Virginia, for an exciting three-day immersive learning experience focused on: 🛰️ AI Applications for Satellite Data Analysis: Theory, Methods, and Applications
Organized as part of IGARSS 2026, this Summer School will bring together students and early-career researchers from around the world to explore cutting-edge advancements in remote sensing, artificial intelligence, and Earth observation science.
📅 6–8 August 2026
📍 Fairfax Campus, George Mason University, 4400 University Drive, Fairfax, VA 22030, USA (gmu.edu/campus-maps)
👥 Limited to 35 students
🏠 Accommodation available (Not available after 30 June 2026)
💡 Registration Details:
🗓️ Registration Period: May 20 – June 30, 2026
💲 Registration Fee: $100 ($150 after June 30)
Participants will gain hands-on exposure to modern AI-driven satellite data analysis techniques while connecting with experts and peers across the global geoscience community.
🔗 Learn more and apply here:
IGARSS 2026 || Washington, D.C. || 9 - 14 August 2026
We look forward to welcoming the next generation of remote sensing innovators to Washington, D.C.! 🌎✨
#IEEEGRSS #IGARSS2026 #SummerSchool #RemoteSensing #ArtificialIntelligence #EarthObservation #SatelliteData #GeospatialAI #Geoscience #MachineLearning #WashingtonDC #NASA #FutureInnovation #GIS #AIForEarthObservation

2
5
19
1,015

May 28
フィジカルAIに不可欠なジオメトリ精度の高い3D 再構築🤔- Niantic Spatial でどのように生成しているのかをブログでご案内しています。
ぜひご一読ください。
nianticspatial.com/blog/geom…
#GaussianSplatting #NianticSpatial #PhysicalAI #GeoSpatialAI
1
6
23
4,680
May 27
$PL ✨
“Planetary Intelligence” is becoming one of the biggest long-term narratives around Planet Labs
The core idea:
AI is evolving beyond internet text models toward “real-world AI” trained on continuous Earth data from space.
Planet’s advantage:
• Daily imaging of Earth’s landmass
• Massive historical geospatial dataset
• AI-enhanced satellite intelligence
• Near real-time planetary monitoring
The broader thesis:
Satellite imagery is no longer just about taking pictures.
It’s becoming:
• Predictive intelligence
• Infrastructure monitoring
• Climate analysis
• Agricultural optimization
• Defense & security awareness
• Real-world AI training data
Planet has described this shift as moving toward:
“Planetary Intelligence” and “Large Earth Models.”
Some analysts increasingly view Planet not simply as a satellite company —
but as a potential Earth-scale data & AI infrastructure platform.
As AI moves beyond the internet and into the physical world, continuous real-world data may become one of the most valuable layers of future AI systems.
$PL #PlanetLabs #AI #PlanetaryIntelligence #Satellite #GeospatialAI #EarthObservation #SpaceTech
will4planet.substack.com/p/p…
1
2
367
May 27
Physical AI needs more than maps, GPS, or pixels alone. It needs a living, geometrically accurate understanding of the real world.
Niantic Spatial and @SpexiGeospatial are partnering to transform drone imagery into large-scale 3D intelligence for physical AI.
🔗Learn more: hubs.ly/Q04hYS1R0
#NianticSpatial #Spexi #PhysicalAI #Reconstruction #GaussianSplat #DigitalTwins #Robotics #GeospatialAI #AI #GeospatialIntelligence #GEOINT #SpatialIntelligence
1
9
37
27,077
May 26
$PL ✨
Revere Asset Management disclosed a new position in Planet Labs , purchasing approximately 389,452 shares according to a recent filing.
Why some investors may view this as notable:
• Institutional interest in geospatial AI continues growing
• Planet sits at the intersection of AI satellite data defense intelligence
• Increasing focus on “real-world AI” and Earth observation infrastructure
Planet’s broader thesis continues expanding beyond satellite imagery toward:
• AI-powered geospatial intelligence
• Real-time Earth monitoring
• Defense & security analytics
• Supply chain & infrastructure tracking
The company has also been emphasizing:
• Planetary Intelligence
• AI-enabled change detection
• On-orbit AI processing
• NVIDIA-related AI initiatives
Important context:
Institutional purchases alone do not guarantee future performance, and PL remains a volatile growth-oriented space infrastructure stock.
But filings like this often attract attention because they may reflect growing institutional exposure to AI-driven geospatial data platforms.
$PL #PlanetLabs #AI #Satellite #GeospatialAI #Defense #SpaceTech #EarthObservation
marketbeat.com/instant-alert…
1
4
363
May 23
$PL ✨
Planet Labs is pushing beyond satellite imagery into “Agentic AI” for Earth intelligence.
The company’s new vision:
Ask a question in natural language →
AI analyzes satellite imagery, detects changes, combines public data, and delivers actionable geospatial intelligence almost instantly.
No GIS expertise.
No manual image scanning.
Just AI-powered Earth understanding.
Planet says the system combines:
• Satellite data
• AI-enabled change detection
• Public information
• Map-based conversational AI
Potential use cases:
• Defense & security
• Infrastructure monitoring
• Insurance assessment
• Supply chain intelligence
• Disaster response
• Energy & maritime tracking
The bigger shift:
Earth observation is moving from static imagery toward autonomous AI-driven decision systems.
Planet calls this the evolution from “Earth observation” to “actionable intelligence.”
Combined with onboard AI processing on Pelican satellites, Planet is building what increasingly looks like a real-time planetary intelligence layer.
$PL #PlanetLabs #AI #AgenticAI #Satellite #GeospatialAI #EarthObservation #Defense #SpaceTech
planet.com/pulse/how-agentic…
1
403