
Jun 13
⚡ Quantization, Distillation & Model Compression — the final practical layer that makes powerful LLMs viable for real-world industrial deployment.
Just read this excellent technical white paper from @aasaitech on turning massive models into efficient, edge-ready systems without sacrificing too much intelligence.
Key highlights: • 4-bit quantization (GPTQ, AWQ, GGUF, bitsandbytes) as the sweet spot for production • Knowledge distillation: teacher → student for smaller, faster specialized models • Complementary techniques: pruning, LoRA/QLoRA, sparsity • Industrial wins: lower latency/memory on factory hardware, cost reduction, energy-efficient edge orchestration, faster inference on industrial PCs
Essential for scaling AI across manufacturing floors, maintenance copilots, robotics, and resource-constrained environments.
Full white paper infographic: x.com/aasaitech/status/20653…
How are you approaching model compression in your deployments — 4-bit quantization, distillation pipelines, or full QLoRA workflows?
#Quantization #ModelCompression #KnowledgeDistillation #LLMOptimization #IndustrialAI #EdgeAI #AgenticAI

14

Jun 10
Apple Core AI 공개, 애플 실리콘용 온디바이스 AI 추론 스택과 PyTorch 변환 도구 coreai-torch
(by 9bow님)
d.ptln.kr/10612
#pytorch #apple #ondevice #inference #modelcompression #coreaitorch #coreai
40

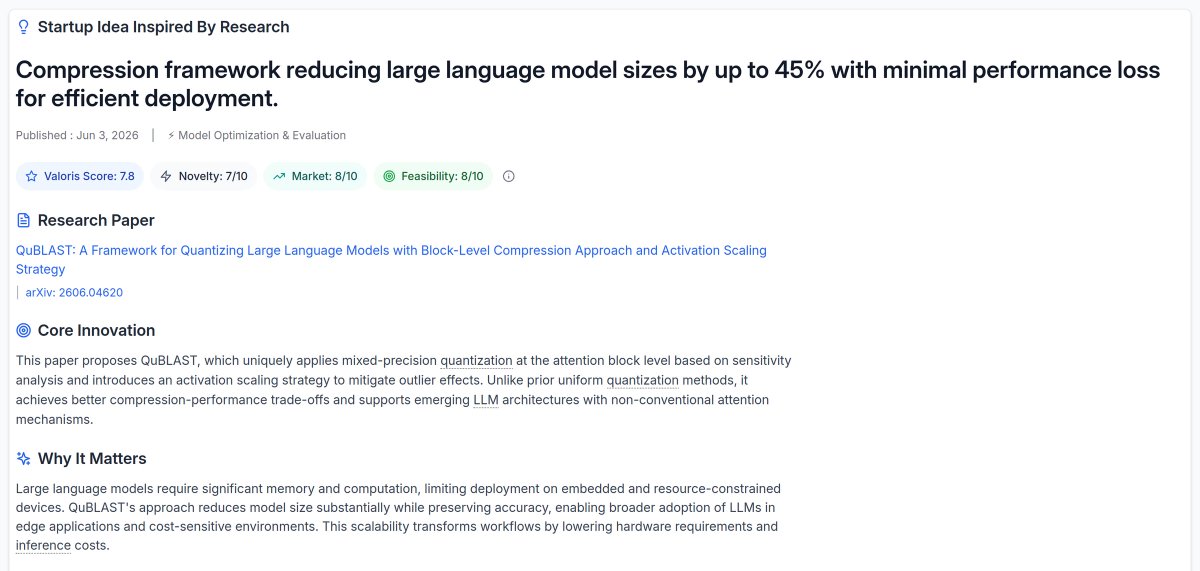
LLMs stay locked to costly GPUs and data centers. QuBLAST compresses models up to 45% with minimal accuracy loss, cutting memory and inference cost to ship LLMs on edge and budget hardware. Explore → valoris-research.com/idea/id… #EdgeAI #ModelCompression
5

Jun 3
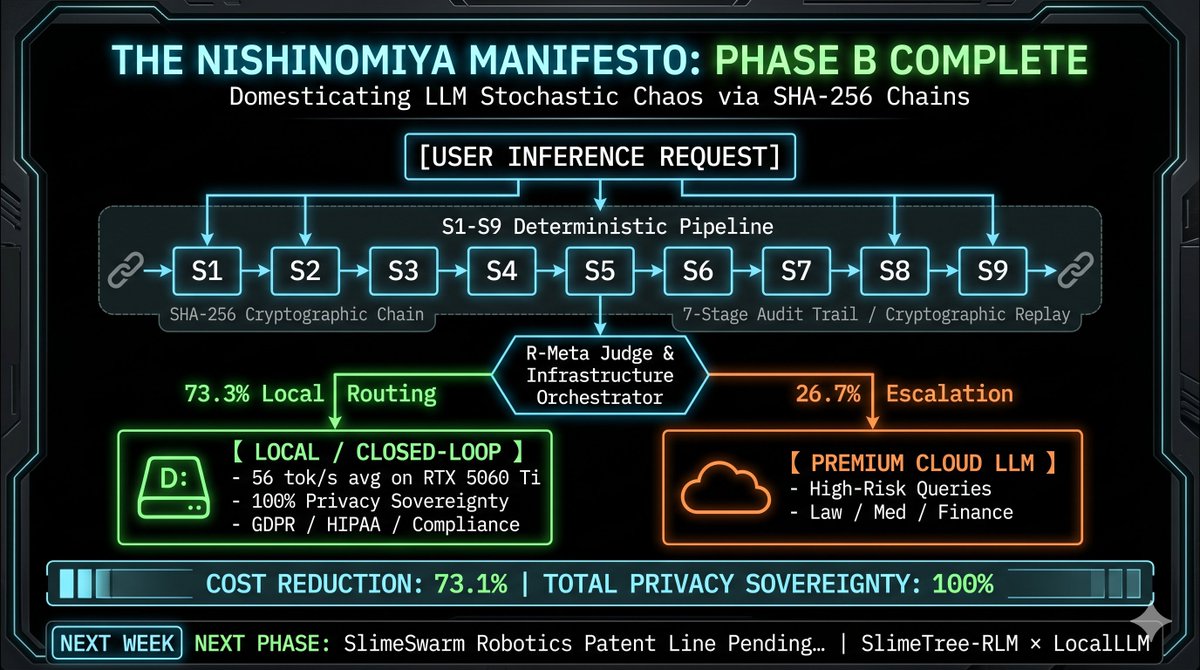
【西宮宣言:Phase B 完結】LLMの確率的カオスをSHA-256の鎖で完全去勢。コスト73%削減とプライバシー主権を両立する「本物のB mode」実装成功。
1/5 AI業界の「薄いラッパー屋」や、法外なクラウドAPI請求書に怯えるエンタープライズへ。ジャバテルは、推論のカオスを9つの純粋関数へ直列解剖する「S1-S9 決定論的パイプライン」の上層に、メタ判定器(R-meta judge)とインフラ統治(Orchestrator)を完全実装しました。
2/5 【100%再現可能な時間軸の統治:SPEC T1適合】 「LLMは確率的だから応答がブレる」という思考停止を粉砕。同一シード(Seed)注入時は1bitの狂いもない完全一致応答(Identical response)を保証。全7ステージの推論プロセスは、直前のハッシュを巻き込み暗号論的に直列連結(Audit Chain)。
3/5 【73.1%コスト削減の数理】 全クエリを強欲なGPT-5等に依存する旧時代は終了。クエリの73.3%を、社内ローカル環境(RTX 5060 Tiで平均56 tok/s)で完全クローズド処理。法律/医療/金融などの知識限界クエリのみを26.7%の確率で自動検知し、Premium LLMへ安全にエスカレーションします。
4/5 【100%のプライバシー主権と規制適合】 処理の73.3%は外部ネットワークへパケットを1bitも飛ばさず、社内のオンプレミス(Dドライブ)内で完結・消滅。これにより、クラウドAI導入の壁だったHIPAA、GDPR、自治体の住民データ残留要件を完全にクリア。弱点すら仕様パラメータとして統治。
5/5 来週のロボット系特許ライン『SlimeSwarm』の出願完了シグナルを合図に、この「SlimeTree-RLM ✕ LocalLLM」の自己完結型メインフレーム移行ソリューションの全弾を世界へ解放します。 データセンターの電気代の泥沼に絶望している、世界の孤独なテックファウンダーたちへ。DMでコードとロジックを語り合いましょう。
javatel.co.jp
#EdgeAI #DeterministicAI #LLM #WASM #WebAssembly #ONNX #ModelCompression #KnowledgeDistillation #PrivacySovereignty #DisruptBigTech #FinTech #LegalTech #MainframeModernization #Javatel #SlimeSwarm
2
375

🔥Researchers from Beihang University and ETH Zurich conducted a systematic evaluation of Qwen3's robustness under various quantization settings. Check out the paper at:
link.springer.com/article/10…
@qin_haotong
#Quantization #LLM #Modelcompression
2
83

Apr 24
ICLR 2026 paper list of Lambda @LambdaAPI is live 📄📷!
🤖 Agentic AI
[1] In-The-Flow Agentic System Optimization for Effective Planning and Tool Use iclr.cc/virtual/2026/poster/…
[2] EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing iclr.cc/virtual/2026/poster/…
🛡️ Trustworthy AI
[3] Measuring and Mitigating Rapport Bias of Large Language Models under Multi-Agent Social Interactions iclr.cc/virtual/2026/poster/…
[4] OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always! iclr.cc/virtual/2026/poster/…
[5] Randomized Antipodal Search Done Right for Data Pareto Improvement of LLM Unlearning iclr.cc/virtual/2026/poster/…
🎧 Multimodal AI
[6] TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and CLAP-Ranked Preference Optimization iclr.cc/virtual/2025/poster/…
[7] Latent Particle World Models: Self-supervised Object-centric Stochastic Dynamics Modeling iclr.cc/virtual/2026/poster/…
🌀 Diffusion LLM
[8] Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective iclr.cc/virtual/2026/poster/…
🧪 AI for Science
[9] Align Your Structures: Generating Trajectories with Structure Pretraining for Molecular Dynamics iclr.cc/virtual/2026/poster/…
⚡ Efficient AI
[10] VideoNSA: Native Sparse Attention Scales Video Understanding iclr.cc/virtual/2026/poster/…
[11] To Compress or Not? Pushing the Frontier of Lossless GenAI Model Weights Compression with Exponent Concentration iclr.cc/virtual/2026/poster/…
[12] Mitigating Non-IID Drift in Zeroth-Order Federated LLM Fine-Tuning with Transferable Sparsity iclr.cc/virtual/2026/poster/…
Huge shoutout to all of our collaborators!
#ICLR2026 #MachineLearning #AI #gpu #ai4science #agents #worldmodel #federatedLLM #modelcompression #sparseattention #vlm #rl #diffusionLLM #MolecularDynamics #LLMUnlearning #Text2Audio #TrustworthyAI @iclr_conf @chuanli11
Apr 23

We're at @iclr_conf #ICLR2026 this year with 12 papers and two workshops.
Over 20 collaborators across @Stanford, @CarnegieMellon, @BerkeleyRDI, @Google, @nvidia, and @Microsoft helped make this work happen.

1
9
669

Apr 15
🚀 New Shared Task: Model Compression for Machine Translation at #WMT2026 (co-located with #EMNLP2026)!
📅 Test data out on June 18th, submissions by July 2nd!
Can you shrink an LLM and keep translation quality high? 🧠🔧
👉 statmt.org/wmt26/model-compr… #NLP #ML #LLM #ModelCompression
6
10
882
Apr 14
🚀 Excited to share our latest work on lossless GenAI model compression, which is accepted to ICLR 2026 @iclr_conf
🤝 In collaboration with researchers from Rice University @RiceUniversity , Stevens Institute of Technology @FollowStevens, and Lambda @LambdaAPI .
📄 To Compress or Not? Pushing the Frontier of Lossless GenAI Model Weights Compression with Exponent Concentration
🔗Paper: arxiv.org/pdf/2510.02676
⚙️ Code: github.com/zeyuyang8/ecf8
💡 We propose ECF8, a lossless compression framework in GenAI model weights, which is built on a key observation:
👉 model weight exponents exhibit strong concentration (low entropy) across layers and architectures.
Key results:
• 💾📉 Up to 26.9% memory savings
• ⚡🚀 Up to 177.1% throughput speedup
• 🎯💯 100% lossless computation (no accuracy drop)
• 🏗️📈 Scales to models up to 671B parameters
🔥 Impact:
Lower GPU memory footprint faster inference → more efficient deployment on GPU cloud and reduced cost for large-scale GenAI systems.
👏 Huge shoutout to our collaborators:
@YangZeyu9, Tianyi Zhang, @jianwen_xie, @chuanli11 @ZhaozhuoX and @Anshumali_
#ICLR2026 #GenAI #LLM #ModelCompression #EfficientAI #Quantization #FP8 #GPU

11
37
4,668

🚀 @MultiverseCompu featured in @GSMA ’s Quantum Technologies report with @Telefonica
Using CompactifAI, we compressed Llama 3.1 8B & 70B to deliver:
✅ 80% smaller models
⚡ 75% less energy use
💬 Faster AI customer service
🌱 Lower CO₂
Real-world quantum-inspired LLM compression is here scaling AI efficiently without compromising performance.
📄 Read here: multiversecomputing.com/reso…
@Telefonica_en
@Movistar
#AI #LLM #Telecom #QuantumInspired #GenAI #ModelCompression

3
7
276

📣 Deal of the Day 📣 Apr 9
Save 45% TODAY ONLY!
Rearchitecting LLMs & selected titles: hubs.la/Q04bf8_j0
Structural techniques for efficient models.
@PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3 #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local small language models (SLMs). Along the way, you’ll learn how to combine behavioral analysis with structural modifications, identifying and removing parts that don’t contribute to your model’s goals, and even use “fair pruning” to reduce model bias at the neuron level.

1
5
28
989

Apr 1
Meetween is part of the organising committee of #IWSLT2026 — the premier conference on spoken language translation. The Shared Task Evaluation Period is open. Working on #speechtranslation, instruction following, or #modelcompression?
Get involved now! 🔗 iwslt.org/2026

4
4
139

AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape.
By @antgrasso #AI #ModelCompression #Efficiency

2
8
80

Mar 24
AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape.
rt @antgrasso #AI #ModelCompression #Efficiency

3
8
95

Our new study on interpretability explains -- 𝐭𝐡𝐞 𝐏𝐡𝐲𝐬𝐢𝐜𝐬 𝐨𝐟 𝐊𝐕 𝐂𝐚𝐜𝐡𝐞 𝐂𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 𝐟𝐨𝐫 𝐋𝐋𝐌𝐬
Pre-print: arxiv.org/abs/2603.01426
As context lengths continue to grow, the KV cache has become the primary memory bottleneck during inference. While many compression techniques report impressive memory savings with minimal drops in benchmark accuracy, we asked a more structural question:
👉 𝘞𝘩𝘢𝘵 𝘢𝘤𝘵𝘶𝘢𝘭𝘭𝘺 𝘩𝘢𝘱𝘱𝘦𝘯𝘴 𝘵𝘰 𝘢𝘵𝘵𝘦𝘯𝘵𝘪𝘰𝘯 𝘢𝘯𝘥 𝘳𝘦𝘢𝘴𝘰𝘯𝘪𝘯𝘨 𝘸𝘩𝘦𝘯 𝘸𝘦 𝘤𝘰𝘮𝘱𝘳𝘦𝘴𝘴 𝘵𝘩𝘦 𝘒𝘝 𝘤𝘢𝘤𝘩𝘦?
We frame KV compression as a 𝐜𝐨𝐧𝐭𝐫𝐨𝐥𝐥𝐞𝐝 𝐩𝐞𝐫𝐭𝐮𝐫𝐛𝐚𝐭𝐢𝐨𝐧 𝐨𝐟 𝐭𝐨𝐤𝐞𝐧-𝐥𝐞𝐯𝐞𝐥 𝐫𝐨𝐮𝐭𝐢𝐧𝐠 𝐢𝐧 𝐬𝐞𝐥𝐟-𝐚𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧. Rather than evaluating only final task accuracy, we design synthetic datasets to probe: (1) Multi-entity tracking, (2) Coreference resolution, and (3) Multi-hop reasoning.
This setup allows us to disentangle three critical dimensions: Information Retention, Accessibility, and Utilisation.
Our findings reveal an interesting pattern:
👉 𝐌𝐨𝐝𝐞𝐫𝐚𝐭𝐞 𝐜𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧 often preserves surface-level accuracy despite substantial internal representational degradation — suggesting significant redundancy in current models.
👉 𝐍𝐞𝐚𝐫 𝐞𝐱𝐭𝐫𝐞𝐦𝐞 𝐜𝐨𝐦𝐩𝐫𝐞𝐬𝐬𝐢𝐨𝐧, we observe a sharp "safety cliff" in hallucinations, driven by global erasure of answer-critical tokens.
👉 We also uncover a second failure mode -- 𝐫𝐞𝐩𝐫𝐞𝐬𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐫𝐢𝐠𝐢𝐝𝐢𝐭𝐲 -- where tokens remain present, but routing flexibility collapses.
These results suggest that evaluating compression solely through downstream accuracy can mask stronger structural effects on reasoning. Understanding these internal dynamics is crucial as we move toward longer-context and more memory-efficient LLMs.
Brilliant work by Ayan Sengupta and Samhruth Ananthanarayanan.
#ScienceofLLMs #Interpretability #KVCache #ModelCompression

1
5
58
3,700
🚀 HyperNova 60B 2602 is live on @huggingface
Our revamped HyperNova model.
Now with major gains in tool calling & agentic coding.
⚡ 5x better agentic tool use
⚡ 2x better agentic coding
⚡ 1.5x better function calling
Efficient. Open. Production-ready.
📰 lnkd.in/egZub8Mg
👉 lnkd.in/ejN4UEeN
#AI #LLM #ModelCompression #CompactifAI #OpenSource

1
6
364

Distilling Protein Language Models with Complementary Regularizers
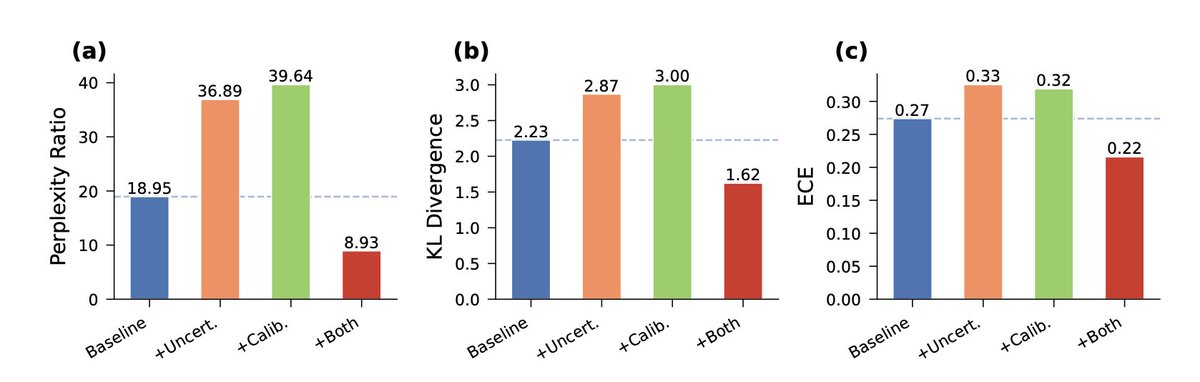
1) A new study reveals a counterintuitive discovery in protein language model distillation: two techniques that individually harm performance combine to deliver a 53% perplexity improvement over standard methods.
2) The researchers identified "complementary regularizers"—uncertainty-aware position weighting and calibration-aware label smoothing—that together filter teacher noise while amplifying biological signal at variable sequence positions.
3) The approach compresses ProtGPT2 (738M parameters) down to 37M–194M student models, achieving 20× to 3.8× compression ratios while maintaining amino acid distributions nearly identical to natural proteins (KL divergence <0.015).
4) The compressed models deliver 2.4–5.3× inference speedup on consumer GPUs, with the smallest model running in just 170MB of memory—enabling on-premise screening of millions of proprietary sequences without cloud dependencies.
5) This addresses a critical bottleneck in biopharma workflows like antibody affinity maturation, where evaluating 10^6 candidates now takes ~6 GPU-hours instead of ~48 hours on standard hardware.
6) The mechanistic explanation draws from signal processing: smoothing acts as a noise filter while weighting amplifies the cleaned signal, analogous to amplification followed by filtering in communication systems.
7) All three compressed models (Tiny, Small, Medium) are openly available on HuggingFace, with training code and evaluation scripts released for reproducibility.
💻Code: github.com/ewijaya/protein-l…
📜Paper: biorxiv.org/content/10.64898…
#ProteinLanguageModels #KnowledgeDistillation #ComputationalBiology #ProteinDesign #MachineLearning #Bioinformatics #ModelCompression
1
7
1,267
📣 Deal of the Day 📣 Feb 2
HALF OFF NEW MEAP!
Rearchitecting LLMs: Structural techniques for efficient models & selected titles: hubs.la/Q041hX8j0
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. @PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3
As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local Small Language Models (SLMs). You’ll learn how to combine behavioral analysis with structural modifications, and even use "fair pruning" to reduce model bias at the neuron level. #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization

3
12
73
2,334
Inetum and Multiverse Computing are joining forces to tackle one of the biggest challenges in the industry: making AI sustainable.
Most enterprise models are too heavy, too expensive, or too energy-intensive. By integrating Multiverse’s compression technology, we’re now able to deploy high-performance AI that slashes energy consumption and costs without losing its edge.
What does this mean in practice? We can now bring advanced AI to environments where it was previously impossible—from secure "edge" devices to highly regulated sectors like defense and banking—all managed through Inetum’s AMAIA AI Experience Center.
Real innovation isn’t just about power; it’s about making that power efficient and accessible. 🚀
Check out the full details here: ow.ly/1PTu50Y5MTg
#AI #Inetum #MultiverseComputing #ModelCompression

2
3
271
When Less Is Enough: Low-Rank Structure in DNA Sequence-to-Function Models
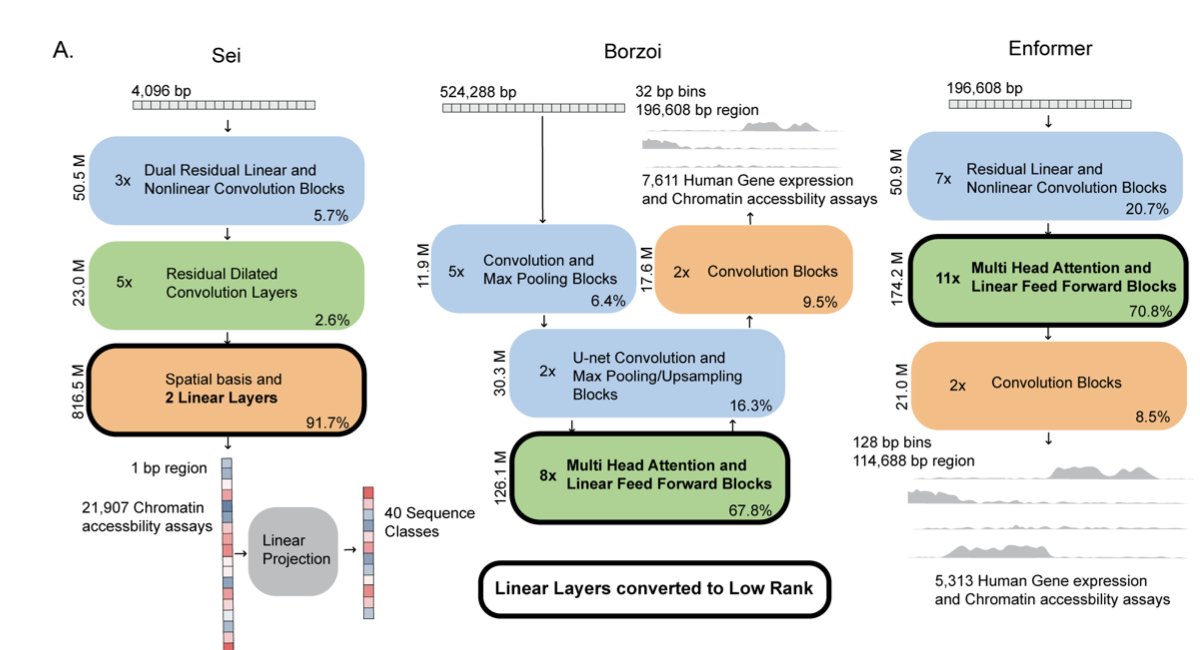
1. A new preprint by Gilfeather, Chikina & Kostka shows that 90 % of parameters in large regulatory-genomics deep nets can be tossed without hurting accuracy.
2. Trick: post-hoc singular-value decomposition of every linear layer in Sei, Borzoi & Enformer yields “LLRA” models whose weight matrices are rank-k with k as low as 1.
3. Shockingly, rank-1 Sei-LLRA beats the full 890 M-parameter model on most promoter-variant benchmarks, hinting that chromatin-state signals live in a tiny linear subspace.
4. Combine low-rank weights with 8-bit static quantization → 5× CPU speed-up and >100× faster per-sequence inference than Borzoi/Enformer while keeping ρ>0.96 with full outputs.
5. On 7 promoter-eQTL & 6 cell-type-specific QTL datasets, quantized Sei-LLRA (rank 64–256) matches or outperforms the parent model and runs on a laptop in seconds.
6. Authors release the “seillra” Python package that lets anyone swap ranks (1–2048) and toggle CPU/GPU inference—no GPU farm required for high-quality variant effect scoring.
7. Work reframes model-compression from an engineering hack to a scientific probe: if rank-1 captures the biology, maybe we should rethink how much complexity regulatory sequence really needs.
💻Code: github.com/kostkalab/seillra
📜Paper: biorxiv.org/content/10.64898…
#Bioinformatics #RegulatoryGenomics #ModelCompression #VariantEffectPrediction #LowRank #CPUfriendly
6
16
1,473

AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape.
By @antgrasso #AI #ModelCompression #Efficiency

1
6
73