
Jun 13
⚡ Quantization, Distillation & Model Compression — the final practical layer that makes powerful LLMs viable for real-world industrial deployment.
Just read this excellent technical white paper from @aasaitech on turning massive models into efficient, edge-ready systems without sacrificing too much intelligence.
Key highlights: • 4-bit quantization (GPTQ, AWQ, GGUF, bitsandbytes) as the sweet spot for production • Knowledge distillation: teacher → student for smaller, faster specialized models • Complementary techniques: pruning, LoRA/QLoRA, sparsity • Industrial wins: lower latency/memory on factory hardware, cost reduction, energy-efficient edge orchestration, faster inference on industrial PCs
Essential for scaling AI across manufacturing floors, maintenance copilots, robotics, and resource-constrained environments.
Full white paper infographic: x.com/aasaitech/status/20653…
How are you approaching model compression in your deployments — 4-bit quantization, distillation pipelines, or full QLoRA workflows?
#Quantization #ModelCompression #KnowledgeDistillation #LLMOptimization #IndustrialAI #EdgeAI #AgenticAI

14

Jun 12
What makes a good teacher? On-policy distillation has spent the year reinventing loss functions to fix problems that come from one source: the teacher doesn't know the student. New article on why every popular OPD loss has an unbounded advantage and why the fix isn't another loss. Read the full article at - x.com/ayans007/status/206541…
w/ @Tanmoy_Chak @lcs2lab
#LLM #KnowledgeDistillation

1
2
273

🚀🤖 Як зробити штучний інтелект швидшим без втрати точності?
📖 journals.uran.ua/eejet/artic…
#ArtificialIntelligence #DeepLearning #KnowledgeDistillation #NeuralNetworks #MachineLearning 🤖📊⚡🚀📚
1
7

Jun 5
【Skill 经济:AI Agent 时代被低估的基础设施战争】
- 125 万个 Skill:市场到底有多大,长什么样
- Skill 在做什么:分类图谱
- 谁在做 Skill:创作者画像
- 三代创作者经济:YouTube → App Store → Skill Market
- Skill 过剩:增而不减的代价
- 从Skill 到蒸馏专家
- 大模型吞噬与Skill 存活率
- 当 Agent 开始自己调用 Skill:协议之战,与分发之战
- 2027 主要趋势
#aiagent #skills #knowledgedistillation #daatingestion

2
290

Jun 3
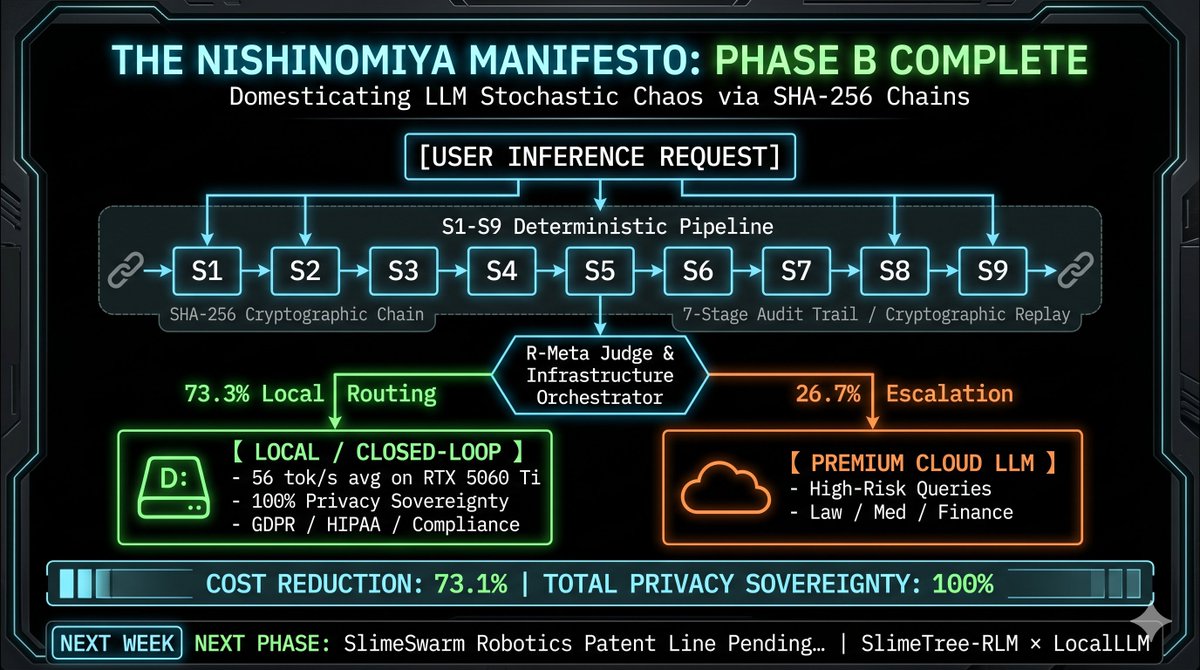
【西宮宣言:Phase B 完結】LLMの確率的カオスをSHA-256の鎖で完全去勢。コスト73%削減とプライバシー主権を両立する「本物のB mode」実装成功。
1/5 AI業界の「薄いラッパー屋」や、法外なクラウドAPI請求書に怯えるエンタープライズへ。ジャバテルは、推論のカオスを9つの純粋関数へ直列解剖する「S1-S9 決定論的パイプライン」の上層に、メタ判定器(R-meta judge)とインフラ統治(Orchestrator)を完全実装しました。
2/5 【100%再現可能な時間軸の統治:SPEC T1適合】 「LLMは確率的だから応答がブレる」という思考停止を粉砕。同一シード(Seed)注入時は1bitの狂いもない完全一致応答(Identical response)を保証。全7ステージの推論プロセスは、直前のハッシュを巻き込み暗号論的に直列連結(Audit Chain)。
3/5 【73.1%コスト削減の数理】 全クエリを強欲なGPT-5等に依存する旧時代は終了。クエリの73.3%を、社内ローカル環境(RTX 5060 Tiで平均56 tok/s)で完全クローズド処理。法律/医療/金融などの知識限界クエリのみを26.7%の確率で自動検知し、Premium LLMへ安全にエスカレーションします。
4/5 【100%のプライバシー主権と規制適合】 処理の73.3%は外部ネットワークへパケットを1bitも飛ばさず、社内のオンプレミス(Dドライブ)内で完結・消滅。これにより、クラウドAI導入の壁だったHIPAA、GDPR、自治体の住民データ残留要件を完全にクリア。弱点すら仕様パラメータとして統治。
5/5 来週のロボット系特許ライン『SlimeSwarm』の出願完了シグナルを合図に、この「SlimeTree-RLM ✕ LocalLLM」の自己完結型メインフレーム移行ソリューションの全弾を世界へ解放します。 データセンターの電気代の泥沼に絶望している、世界の孤独なテックファウンダーたちへ。DMでコードとロジックを語り合いましょう。
javatel.co.jp
#EdgeAI #DeterministicAI #LLM #WASM #WebAssembly #ONNX #ModelCompression #KnowledgeDistillation #PrivacySovereignty #DisruptBigTech #FinTech #LegalTech #MainframeModernization #Javatel #SlimeSwarm
2
375

𝗣𝗮𝗽𝗲𝗿 𝗔𝗰𝗰𝗲𝗽𝘁𝗮𝗻𝗰𝗲 𝗔𝗻𝗻𝗼𝘂𝗻𝗰𝗲𝗺𝗲𝗻𝘁 🎉
Paper titled "Transitioning Heads Conundrum: The Hidden Bottleneck in Long-Tailed Class-Incremental Learning" has been accepted at TMLR 2026 (Transactions on Machine Learning Research).
Authors: Rahul Vigneswaran, Hari Chandana Kuchibhotla, Vineeth N Balasubramanian
👏 Congratulations to all the authors!
🔍 Key Highlight:
This work introduces DEREK (DEcoupling Representations for Early Knowledge Distillation), a method addressing a previously overlooked challenge in Long-Tailed Class-Incremental Learning (LTCIL): the Transitioning Heads Conundrum.
In LTCIL, head classes that are well-represented in earlier tasks become tail classes in subsequent tasks due to memory constraints, leading to accelerated catastrophic forgetting. DEREK mitigates this by decoupling head and tail learning via specialized expert networks and applying Early Knowledge Distillation before data constraints take effect, preserving rich representations.
Across 2 LTCIL benchmarks, 12 experimental settings, and 24 baselines, DEREK consistently establishes new state-of-the-art performance.
#MachineLearning #ContinualLearning #LongTailedLearning #KnowledgeDistillation #TMLR2026 #IITHyderabad
1
2
5
487

Apr 19
🚀 Distil SN97 just dropped serious upgrades — and the cheaters are officially cooked. 📷🔥
A7 v1: Private prompt-pool commit-reveal scheme differential privacy noise
Capability v2: Rotating per-block prompts procedural math generation dynamic evaluation
This isn't another hype subnet.
Distil is a live Bittensor marketplace for knowledge distillation — turning massive LLMs (like Qwen3.5-35B) into smaller, faster, beast-mode student models... while validators brutally test them on fresh, never-seen-before prompts.
In plain English:
They killed the old game of miners memorizing test questions. Now every round is new, hidden, noisy, and procedurally generated. Commit-reveal differential privacy = real sybil resistance. No more gaming the system.
This is proper decentralized ML infrastructure — moving from static leaderboards to robust, adversarial mechanism design. The kind of hard engineering most subnets are still avoiding while they argue about tokenomics.
Bollaks take: 76/100
aGap Score: 84
Market cap sitting at ~$3.6M
While others sleep, Distil is building the actual plumbing for fair AI validation at scale. Real velocity. Real defenses against model farming and collusion. The opportunity in decentralized evaluation is massive.
If you're in #Bittensor, this is one of the most slept-on plays right now. The work here is legit.Check it yourself:
→ GitHub: github.com/unarbos/distil
→ Live Dashboard: distil.arbos.life
Who else is watching SN97? Drop your thoughts 📷#Bittensor #TAO #SN97 #DistilSN97 #DeAI #KnowledgeDistillation @bittensor @learnbittensor
2
5
312

📣 Deal of the Day 📣 Apr 9
Save 45% TODAY ONLY!
Rearchitecting LLMs & selected titles: hubs.la/Q04bf8_j0
Structural techniques for efficient models.
@PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3 #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local small language models (SLMs). Along the way, you’ll learn how to combine behavioral analysis with structural modifications, identifying and removing parts that don’t contribute to your model’s goals, and even use “fair pruning” to reduce model bias at the neuron level.

1
5
28
989

Geometry-enhanced Protein Language Modeling Enables Discovery of Novel Antibiotic Resistance Genes
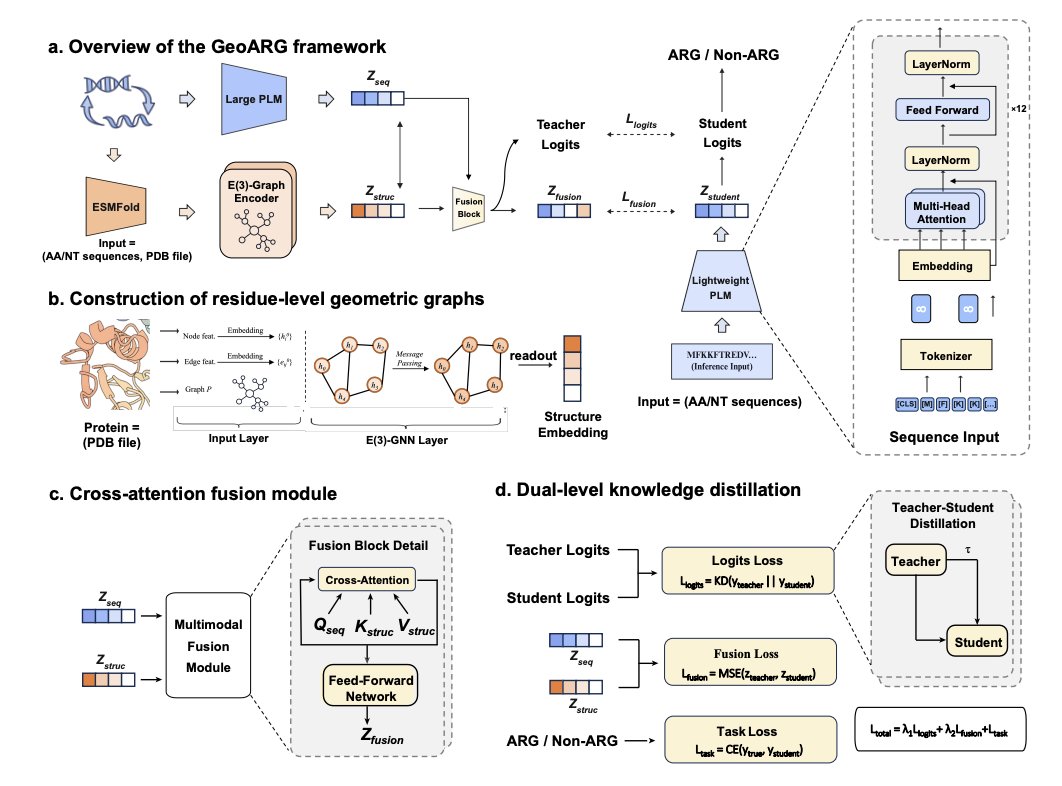
1. The study introduces GeoARG, a geometry-enhanced antibiotic resistance gene (ARG) predictor that distills 3D structural constraints into a fast sequence-only model, aiming to detect evolutionarily remote ARGs that homology-based pipelines often miss.
2. Core idea: ARG function is frequently conserved at the level of active-site geometry even when global sequence identity collapses. GeoARG leverages this by training a multimodal teacher (sequence PLM E(3)-equivariant structure GNN) and transferring that knowledge to a lightweight student that needs sequence input only at inference.
3. Architecture highlights: sequences are embedded with a pretrained protein language model; predicted structures (via ESMFold) are converted into residue graphs; an E(3)-equivariant GNN encodes rotation/translation-invariant geometry; cross-attention fuses sequence and structure; dual-level distillation aligns both logits and internal representations.
4. Practical deployment focus: one unified student pipeline supports four common screening inputs—LSnt, SSnt, LSaa, SSaa—avoiding separate models for long vs short sequences and for nucleotide vs protein inputs (nucleotide handled via six-frame translation and longest ORF selection).
5. Benchmark resource contribution: GeoARG-DB integrates seven public ARG sources, removes SNP-only resistance records, deduplicates at 100% identity, and standardizes labels into 36 resistance classes, yielding 40,624 non-redundant ARG proteins for training/validation/testing.
6. Performance summary: on curated-protein (UniProt) and genome-derived ORF negative backgrounds, GeoARG shows strong binary discrimination (e.g., LSaa accuracy 0.9987, MCC 0.9973; ORF benchmarks MCC > 0.88 and AUROC > 0.97 across input settings) and improves 36-class subtype prediction accuracy (0.8792 vs 0.7380 ARGNet and 0.6260 DeepARG).
7. Why geometry matters (ablation): removing structural features or cross-attention reduces performance, with the largest drops in short-fragment settings (SSnt/SSaa), consistent with geometry compensating when sequence context is limited.
8. Specificity stress test: against 8,793 viral proteins (a stringent, evolutionarily distant negative set), GeoARG maintains higher specificity (LSaa 0.9611; SSaa 0.9062) than ARGNet, HMD-ARG, and DeepARG, suggesting reduced spurious calls on non-bacterial proteins.
9. Remote and emerging resistance: for mobilized colistin resistance (mcr) genes, GeoARG achieves high recall on phylogenetically expanded mcr-like sequences, especially on amino-acid inputs where sequence-only baselines degrade under divergence (e.g., expanded recall LSaa 0.9718 vs 0.6665 for ARGNet; SSaa 0.9532 vs 0.6281).
10. Metagenomic discovery: screening unannotated human gut ORFs from GMGC with <25% identity to GeoARG-DB yields 1,485 high-confidence novel ARG candidates (P > 0.8) across six classes (glycopeptide, beta-lactamase, MLS, phenicol, aminoglycoside, tetracycline). Pfam enrichment supports biological plausibility (e.g., CAT, VanS-like domains, beta-lactamase folds, aminoglycoside-modifying enzyme domains).
11. Structural plausibility checks: representative candidates show strong structure-level conservation despite low sequence identity (e.g., a beta-lactamase candidate at 21.11% identity aligns with TM-score 0.88 and motif-level RMSD 0.32 Å; AlphaFold3 co-folding places ampicillin in a canonical pocket with similar pose; MD simulations keep ligand RMSD ~1–3 Å with persistent hydrogen bonds).
12. Interpretability via counterfactuals: alanine substitutions in beta-lactamase catalytic motifs reduce GeoARG confidence in a motif-specific way, with SXXK disruption causing the largest probability drop and pairwise motif disruptions compounding effects—consistent with known catalytic roles rather than generic sequence cues.
13. Efficiency payoff from distillation: the deployable student (ESM2-35M) is ~15.4× faster than the multimodal teacher (ESM2-650M E(3) GNN) on A100 inference, enabling large-scale metagenomic screening while still benefiting from structure during training.
💻Code: github.com/XingqiaoLin/GeoAR…
📜Paper: biorxiv.org/content/10.64898…
#AntimicrobialResistance #AMR #AntibioticResistance #Metagenomics #ProteinLanguageModels #GeometricDeepLearning #KnowledgeDistillation #Bioinformatics #ComputationalBiology #Resistome
3
19
1,916

Mar 10
LEARN AI. Start here with these 42 short videos covering the basic terms you need to know. They’ll help you understand AI and how the technology works at a level that will put you ahead of 99% of people.
@towards_AI
@Whats_AI
#BuildForTheFuture #TheFutureIsNow
#GenerativeAI #LLMs #Tokens #Embeddings
#LatentSpace #Parameters #PreTraining
#BaseModelsVsInstructModels #FineTuning
#Alignment #RLHF
#SystemPromptVsUserPrompt
#ContextWindow
#ZeroShotVsFewShotLearning
#ReasoningAndCoT #Inference #Latency
#TemperatureAndDeterministicVsStochasticOutputs
#GroundingAndRAG #WorkflowVsAgent
#AgeneticAI #ProprietaryVsOpenSourceModels
#API #SLM(Small Language Models)
#KnowledgeDistillation #ModalityAndMultimodality
#ReasoningModels #Benchmarks #Metrics
#LLMAsTheJudge #Hallucination
#PoorMathematicalAndLogicalReasoning
#InherentBias #KnowledgeCutoff
#GuardrailsAndSafetyFilters
#PromptInjectionPromptHacking
#PreferenceTuning #RLAIF #RLVR
#SelfConsistency #ModelEnsembling
#AddressingFailures
youtube.com/playlist?list=PL…
3
2
430

Feb 23
#KnowledgeDistillation does have scalable impact both ve and -ve... I recall one of the very first papers (in our group) in the context of @AnthropicAI 's post!



5
118
Distilling Protein Language Models with Complementary Regularizers
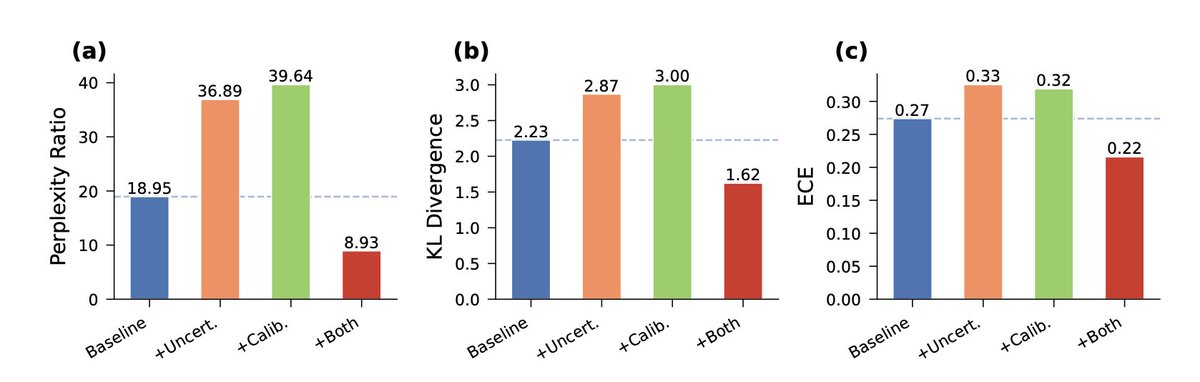
1) A new study reveals a counterintuitive discovery in protein language model distillation: two techniques that individually harm performance combine to deliver a 53% perplexity improvement over standard methods.
2) The researchers identified "complementary regularizers"—uncertainty-aware position weighting and calibration-aware label smoothing—that together filter teacher noise while amplifying biological signal at variable sequence positions.
3) The approach compresses ProtGPT2 (738M parameters) down to 37M–194M student models, achieving 20× to 3.8× compression ratios while maintaining amino acid distributions nearly identical to natural proteins (KL divergence <0.015).
4) The compressed models deliver 2.4–5.3× inference speedup on consumer GPUs, with the smallest model running in just 170MB of memory—enabling on-premise screening of millions of proprietary sequences without cloud dependencies.
5) This addresses a critical bottleneck in biopharma workflows like antibody affinity maturation, where evaluating 10^6 candidates now takes ~6 GPU-hours instead of ~48 hours on standard hardware.
6) The mechanistic explanation draws from signal processing: smoothing acts as a noise filter while weighting amplifies the cleaned signal, analogous to amplification followed by filtering in communication systems.
7) All three compressed models (Tiny, Small, Medium) are openly available on HuggingFace, with training code and evaluation scripts released for reproducibility.
💻Code: github.com/ewijaya/protein-l…
📜Paper: biorxiv.org/content/10.64898…
#ProteinLanguageModels #KnowledgeDistillation #ComputationalBiology #ProteinDesign #MachineLearning #Bioinformatics #ModelCompression
1
7
1,267
📣 Deal of the Day 📣 Feb 2
HALF OFF NEW MEAP!
Rearchitecting LLMs: Structural techniques for efficient models & selected titles: hubs.la/Q041hX8j0
This book turns research from the latest AI papers into production-ready practices for domain-specific model optimization. @PereMartra #LLMs #LLMOptimization #SLMs #TinyLLMs #Gemma #Qwen #Llama3
As you work through this practical book, you’ll perform hands-on surgery on popular open-source models like Llama-3, Gemma, and Qwen to create cost-effective local Small Language Models (SLMs). You’ll learn how to combine behavioral analysis with structural modifications, and even use "fair pruning" to reduce model bias at the neuron level. #ModelPruning #KnowledgeDistillation #EfficientLLMs #ModelCompression #StructuredPruning #ModelOptimization

3
12
73
2,334

Jan 28
⚡️ Pruning, Quantization & Distillation: 3 Steps to Faster AI
Want smaller, faster models? You need these three techniques:
✂️ Pruning: Removing unnecessary weights or layers. 📉 Quantization: Lowering precision (like FP32 to Int8) to speed up inference. 🧠 Distillation: Teaching a small "student" model to mimic a large "teacher."
Combine them to create super-efficient AI! 🚀
#MachineLearning #Pruning #Quantization #KnowledgeDistillation #AI #DeepLearning #TechTips #Coding
3
266

Bigger LLMs win benchmarks.
Production pays the price.
Knowledge distillation transfers big-model reasoning into fast, cheap models that scale.
~3× faster inference →
medium.com/@harsha90145/know…
#KnowledgeDistillation #LLMInference #MachineLearning
1
78
Investigating Knowledge Distillation Through Neural Networks for Protein Binding Affinity Prediction
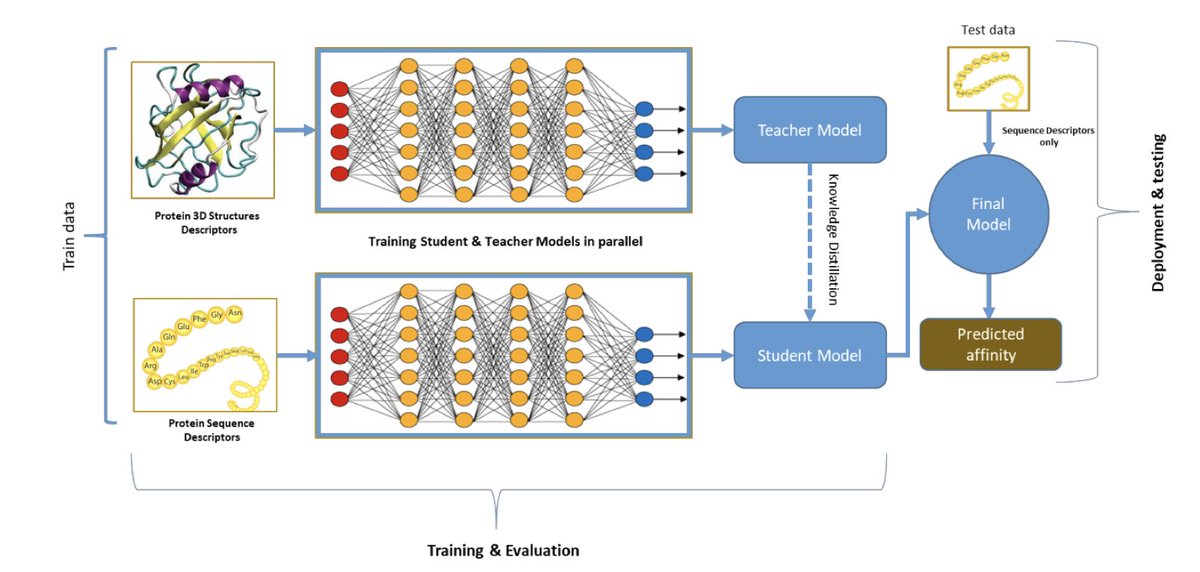
1. This study introduces a novel approach to protein binding affinity prediction using knowledge distillation, effectively bridging the gap between sequence-based and structure-based models. The framework leverages structural data during training but requires only sequence data during inference, making it highly practical for real-world applications where structural information is often limited.
2. The core innovation lies in the use of a teacher-student learning paradigm. The teacher model, trained on rich 3D structural descriptors, imparts its knowledge to a student model that relies solely on sequence-based descriptors. This distillation process allows the student model to achieve significantly improved accuracy compared to traditional sequence-only methods.
3. The study demonstrates that the distillation-based student model outperforms sequence-only baselines in both Leave-One-Complex-Out cross-validation and external validation experiments. It achieves a Pearson correlation coefficient of 0.481 and an RMSE of 2.488 kcal/mol, approaching the performance of structure-based models while retaining the advantage of sequence-only inference.
4. The framework is designed to be scalable and adaptable. It can be expanded with more advanced neural architectures and larger datasets, potentially achieving performance levels comparable to structure-based predictors in the future. This makes it a promising tool for enhancing the accuracy and applicability of protein-protein interaction predictions.
5. The authors provide detailed implementation details, including network architectures and training hyperparameters, ensuring full reproducibility of the experiments. The study highlights the potential of knowledge distillation as an efficient method for transferring structural knowledge to sequence-based predictors.
📜Paper: arxiv.org/abs/2601.03704
#ProteinBindingAffinity #KnowledgeDistillation #NeuralNetworks #ComputationalBiology #Bioinformatics
3
17
1,513

23 Dec 2025
I am happy to announce that we have uploaded the final camera-ready version and the updated official code for our NeurIPS 2025 paper: "Why Knowledge Distillation Works in Generative Models: A Minimal Working Explanation".
I would like to express my sincere gratitude to everyone who stopped by our poster session. The discussions we had were incredibly valuable and inspiring.
Reflecting on the feedback and requests we received: 1) We have incorporated minor updates into the final paper. 2) We have updated the official code to support reproducibility and further exploration.
We hope that our framework and codebase will serve as a useful foundation for fellow researchers in the field of #KnowledgeDistillation, #LLMs and #GenerativeAI.
Code: github.com/csm9493/kd-minima…
2
20
137
10,101
19 Dec 2025
🔬 Parmanu (Hindi for Atom) is live.
Parmanu is part of the Computational Social Systems (LCS2) @lcs2lab at IIT Delhi, led by Prof. Tanmoy Chakraborty @Tanmoy_Chak , and is our dedicated home for Efficient Large Language Models (LLMs) and Small Language Models (SLMs).
We’re at a turning point in AI. The future won’t be defined by scaling alone - it will be shaped by efficiency, accessibility, and real-world deployability. Parmanu is our effort to push this efficiency-first vision forward. ✨🤖
🔗 Explore the project page: parmanu.lcs2.in/
Why Parmanu matters 🔥
• 📚 A centralized hub for our research, with papers accepted at ICLR, ICML, NeurIPS, TACL, ACL, and TMLR
• 🛠️ Open access to tools, code, and artifacts spanning model compression, KV efficiency, PEFT, inference optimization, knowledge distillation, and model coordination
• 🧠 A growing ecosystem focused on making strong language models smarter per parameter, not just larger
What this means for the community
For researchers 👩🔬👨🔬
A curated, evolving resource tied to top-tier venues
Reproducible artifacts and principled problem formulations
A shared space to advance efficiency-centric LLM research
For practitioners 👩💻👨💻
Practical techniques to deploy LLMs under tight latency and memory budgets
Faster paths from paper → production
Tools that actually work under real deployment constraints
What’s coming in 2026 🚀🔮
• 📊 Efficient LLM/SLM leaderboards
• 🧪 Open-sourced efficient LLM artifacts
• ⚙️ More tools for compression, distillation, and inference
• 🤝 Deep integration with Hugging Face and other popular libraries
If you’re excited about efficient, sustainable, and scalable AI, check out Parmanu, share feedback, and collaborate with us. The next wave of LLMs won’t just be bigger - they’ll be leaner, faster, and more impactful. 🌟
#EfficientLLMs #SLMs #ModelCompression #InferenceOptimization #KnowledgeDistillation #AIResearch #NLP #ICLR #ICML #NeurIPS #ACL #TACL #TMLR #IITDelhi #LCS2 #Parmanu
1
5
10
324

3 Dec 2025
And now @SwamiSivasubram arrived at @Amazon Sagemaker. Of course has all the capabilities teed up before - #KnowledgeDistillation #ReInforcementLearning etc etc. #AWSReinvent

2
2
179
27 Nov 2025
I will be at #NeurIPS2025 in San Diego next week!
Please stop by my poster if you are interested in the underlying mechanisms of #KnowledgeDistillation in generative models!
- Paper: Why Knowledge Distillation Works in Generative Models: A Minimal Working Explanation
- Wed 3 Dec 11 a.m. PST — 2 p.m. PST
- neurips.cc/virtual/2025/loc/…



1
12
806