
Released a second audio2face teacher dataset on Hugging Face today.
Different supervision signal from our first dataset. MediaPipe FaceLandmarker. CC-BY-NC-4.0.
Link in the comments 👇
#HuggingFace #OpenSource #DigitalHumans #ARKit #MediaPipe #ModelDistillation
1
12

winbuzzer.com/2026/06/07/xai…
xAI appears to have used a workaround to train its Grok AI with outputs of Anthropic's Claude model after an Anthropic access cutoff in January.
#xAI #Grok #Anthropic #Claude #ModelDistillation #AITraining #AICoding #AIModels #ElonMusk

1
48

May 17
Many cutting-edge academic studies are dedicated to the application of lightweight model distillation within distributed networks. Traditional distillation methods mostly rely on centralized servers for parameter compression, which fail to fit decentralized architectures with scattered nodes, and easily cause information loss during knowledge transfer and weaken reasoning performance.
New academic solutions establish a collaborative distributed distillation structure, splitting the model compression process into different nodes step by step. Cryptographic tools are adopted throughout the whole process to prevent core original model knowledge from being leaked. Without centralized computing scheduling, it greatly lowers the operating threshold of edge nodes while retaining core model capabilities.
This research further expands the application scope of lightweight intelligent models in DeSci scenarios. It enables more low-cost distributed nodes to undertake scientific research reasoning tasks, and consolidates solid technical foundations for an open and inclusive decentralized intelligent research ecosystem.
#HETU #Setu #ModelDistillation #DeSciTech #DistributedAI
1
28
2,290

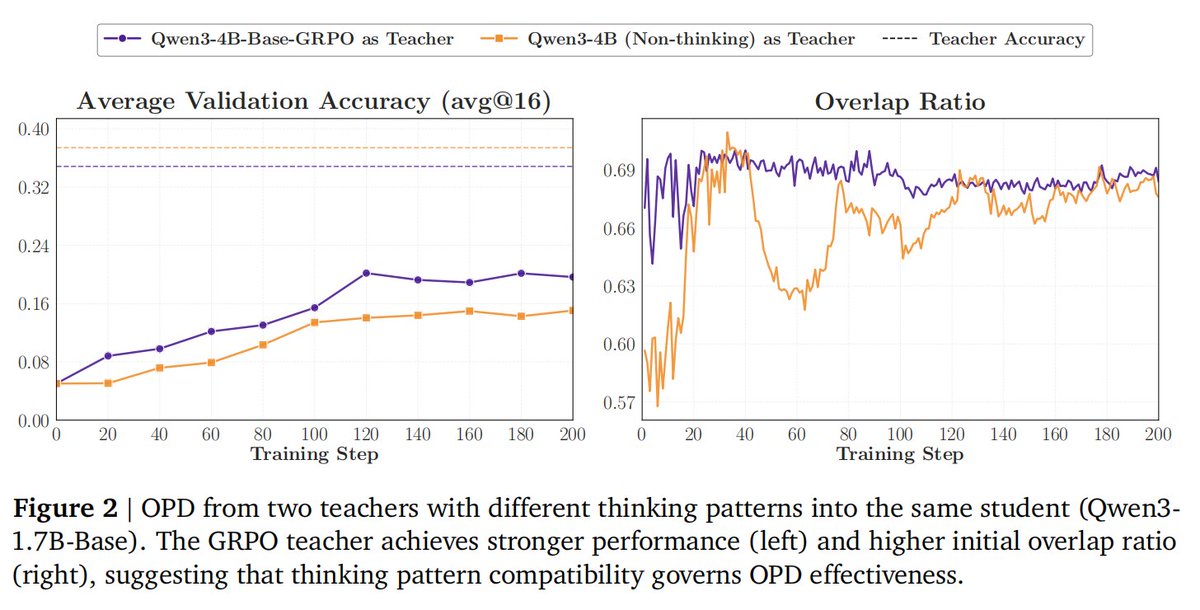
On-Policy Distillation (OPD) is the go-to technique for LLM post-training, but it often mysteriously fails. Is a "smarter" teacher model enough to guarantee success? The answer is NO. 🤔
Today, we dive into a comprehensive study on OPD by @TsinghuaNLP (OpenBMB member) alongside researchers from ShanghaiTech, UIUC, and RUC. This paper systematically unpacks the phenomenology, mechanism, and practical recipes behind successful On-Policy Distillation.
🤗 Paper: huggingface.co/papers/2604.1…
📄 arXiv: arxiv.org/abs/2604.13016
💻 Code: github.com/thunlp/OPD
Why it matters:
1️⃣ The Two Rules of Success: A high-scoring teacher isn't a magic bullet. OPD success depends strictly on two factors: Thinking Pattern Consistency (student and teacher must share compatible reasoning styles) and Information Gain (the teacher must offer truly new, out-of-distribution knowledge). 🧠
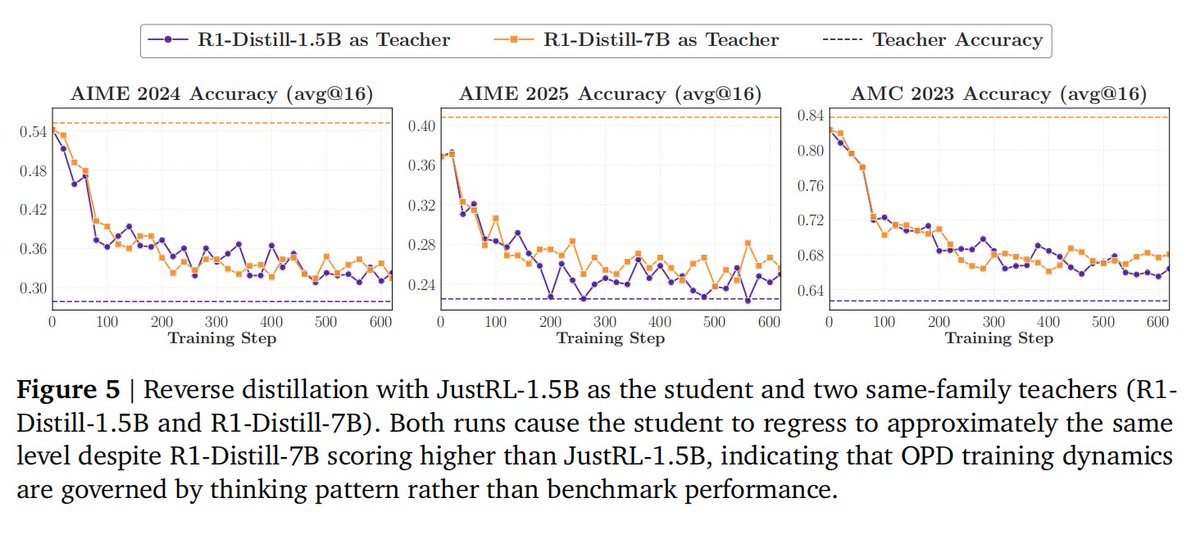
2️⃣ The Reverse Distillation Paradox: We tried using an ultra-strong teacher (R1-Distill-7B) to distill a strong RL-tuned student (JustRL-1.5B). Surprisingly, the student regressed to its pre-RL state! Why? Because OPD strictly mimics the teacher's thinking pattern, effectively overwriting the student's existing RL behaviors regardless of the final reward. 🔄
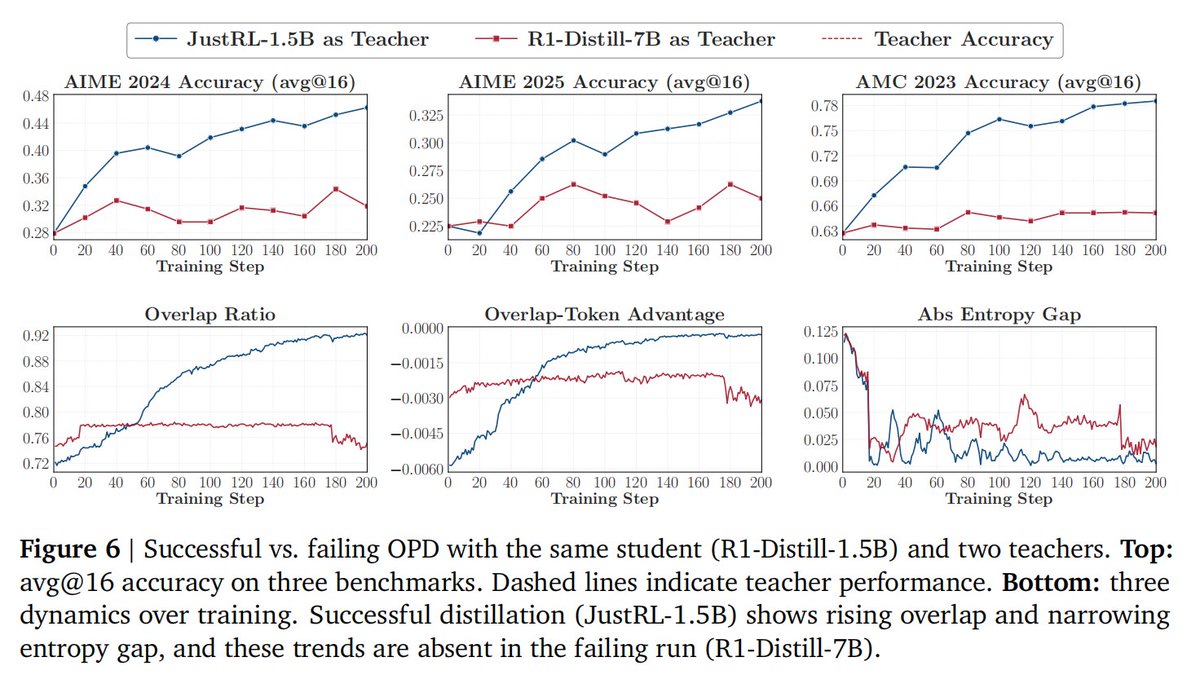
3️⃣ The Overlap Token Mechanism: Zooming into token-level dynamics, we found that successful OPD is driven by "overlap tokens." The model heavily optimizes these shared, high-probability regions, while non-overlapping tokens contribute almost zero useful gradients. 🔍
4️⃣ The Winning Recipe: How do we fix a "failed" OPD when the thinking patterns don't match? Our recipe: apply Supervised Fine-Tuning (SFT) on teacher rollouts before starting OPD. This elegantly bridges the thinking-pattern gap and dramatically raises the performance ceiling! 🛠️
5️⃣ The Token-Level Reward Mirage: OPD's token-level reward looks like a free lunch — but it isn't. Reward quality decays with trajectory depth. Instability originates at later tokens and propagates backward. Even failing teachers produce globally informative reward — the bottleneck is local optimization geometry, not signal quality.📉
Stop guessing why your distillation failed and start aligning thinking patterns! Read the full paper to master LLM post-training.
#AI #THUNLP #OpenBMB #LLM #ModelDistillation #ReinforcementLearning

4
18
116
6,607

Feb 24
The irony? Training on others content was called innovation but training on their model is called theft. The real debate is where we draw the line between learning copying, and getting paid for it. 🤔
#AI #LLMs #ModelDistillation #AIethics
Feb 23

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
2
100

24 Nov 2025
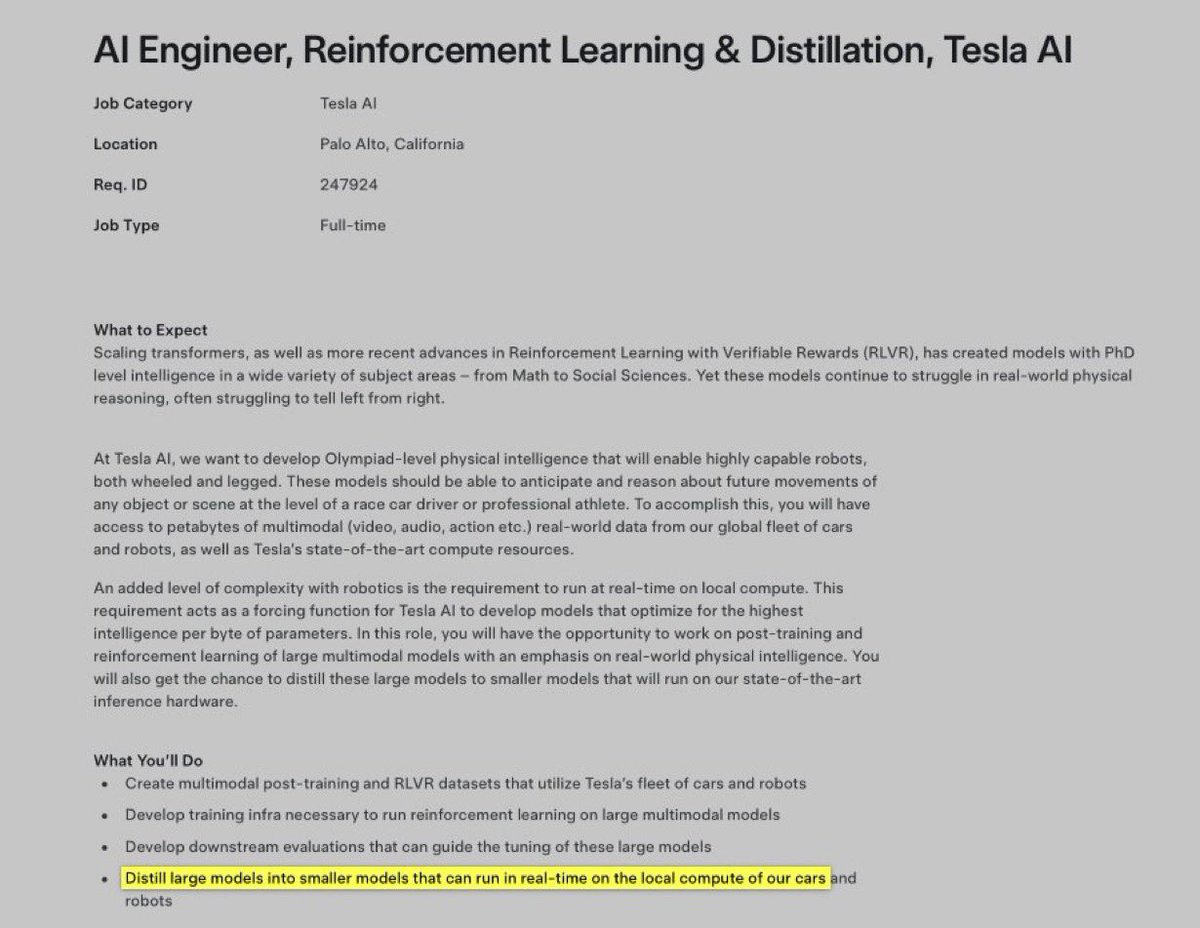
🔥🎯Tesla is recruiting AI Distillation Engineers to accelerate on-vehicle inference model deployment
1️⃣ Latest hiring update: Tesla has officially posted the role “AI Engineer, Reinforcement Learning & Distillation,” based in Palo Alto, California.
2️⃣ Role significance: This position focuses on “distillation”—compressing large training models into lightweight versions that can run directly on vehicle inference hardware. It signals Tesla’s push to strengthen on-car AI execution, not just cloud-based processing.
3️⃣ Underlying logic:
• On-vehicle inference faces tighter constraints than cloud training, including compute limits, latency, and power efficiency.
• Distillation transfers the “knowledge” of a large model into a smaller network suited for automotive hardware.
• The move aligns with Tesla’s broader strategy in autonomous driving, robotics, and in-car intelligence.
4️⃣ Strategic implications:
• Tesla is investing not only in training but also in “how to make AI run efficiently inside the car.”
• Stronger on-vehicle inference could reinforce Tesla’s moat in autonomy, robotics, and the future vehicle-edge AI ecosystem.
• For investors, this marks Tesla’s transition from an AI training powerhouse toward an AI deployment platform.
5️⃣ Risks & challenges:
• Compressing large models while preserving performance is technically demanding.
• While distillation helps, heavy reliance on specific hardware may leave Tesla exposed if competitors win on software-hardware integration.
• Expectations for Tesla’s autonomy and in-car intelligence remain high; slow progress could disappoint in the short term.
6️⃣ Key points to watch:
• Whether Tesla later discloses details on its on-vehicle inference framework or hardware specs.
• Compensation levels and talent-competition signals tied to this role (e.g., whether it triggers industry movement).
• Real-world use cases of distillation in autonomy, such as how a vehicle inherits capabilities from a large model but executes them with a smaller one.
🔍 Summary: Tesla’s move to hire “AI Distillation Engineers” is a clear indicator that its AI strategy is shifting toward large-scale deployment inside the vehicle. For investors tracking $TSLA or its broader AI ecosystem, this development deserves close attention.
📬 How long do you think it will take for Tesla’s distilled on-vehicle models to scale across the fleet? Share your view in the comments.
#Tesla #AI #AutonomousDriving #MachineLearning #ModelDistillation
1
3
10,522

20 Sep 2025
AI NEWSWIRE: DeepSeek Reveals Low AI Training Cost, Challenges US Giants
TECHNOLOGY NEWS; China's DeepSeek revealed its R1 AI model cost $294,000 to train, challenging US AI giants and intensifying global competition.
BIG DATA BREAKTHROUGH: This low-cost approach redefines AI development economics.
PEOPLE'S REPUBLIC OF CHINA: DeepSeek has reignited the global AI race.
MORE BANG FOR THE BUCK: Deep Seek's stunning revelation is that its its R1 model cost just $294,000 to train.
This figure, published in the academic journal Nature, stands in stark contrast to the “much more than $100 million” estimated by OpenAI CEO Sam Altman for foundational model training.
Further this directly challenges the perceived dominance of US AI giants and sending ripples through global tech markets.
The Hangzhou-based developer’s disclosure, its first estimate of R1’s training costs, initially prompted global investors to dump tech stocks, fearing the new models could threaten leaders like Nvidia.
DeepSeek stated R1 was trained for 80 hours on 512 Nvidia H800 chips.
However, the company also acknowledged for the first time using more powerful A100 chips in preparatory development stages, a detail that fuels ongoing debate given US export controls on advanced AI chips to China.
DeepSeek also responded to assertions that it “distilled” OpenAI’s models.
While consistently defending distillation as a method for better, cheaper AI, the company now states its V3 model’s training data, sourced from crawled web pages, contained a “significant number of OpenAI-model-generated answers.”
This, it explained, could lead to the base model indirectly acquiring knowledge, but was incidental, not intentional.
This lower-cost approach, whether through efficient training or indirect knowledge acquisition, has profound implications.
It suggests a potentially more accessible pathway to advanced AI, intensifying competition and forcing a re-evaluation of development economics in the rapidly evolving global AI landscape.
#AI #ArtificialIntelligence #DeepSeek #AINewswire #R1Model #AIRevolution #TechNews #ChinaTech #AICompetition #USAI #GlobalAI #LowCostAI #AITraining #BigData #TechBreakthrough #AIDevelopment #TechNews #Nvidia #H800Chips #A100Chips #BusinessNews #AIChips #TechMarkets #AIInnovation #MachineLearning #DeepLearning #AIEconomics #TechStocks #GlobalTech #HangzhouTech #NatureJournal #OpenAI #SamAltman #AIInvestment #DataCrawling #WebData #ModelDistillation #AIEthics #TechCompetition #AIAdvancements #TrainingCosts #AIAccessibility #FutureOfAI #TechRace #AIlandscape #Innovation #TechDisruption #AIPower #GlobalInnovation

3
179

30 Jul 2025
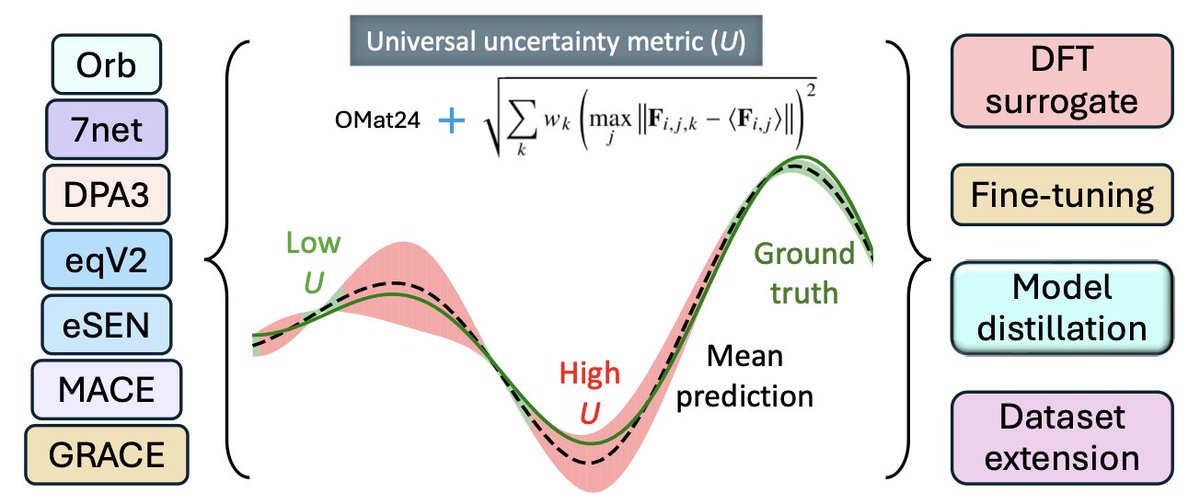
Heterogeneous Ensemble Enables a Universal Uncertainty Metric for Atomistic Foundation Models
1. A new universal uncertainty metric 𝐴? has been introduced for atomistic foundation models (uMLIPs), which provides a reliable measure of prediction errors without needing reference DFT calculations. This metric is based on a heterogeneous ensemble of existing uMLIPs, leveraging their diversity to quantify uncertainty effectively.
2. The metric 𝐴? shows a strong correlation with true prediction errors across diverse datasets, including metals, alloys, inorganic compounds, and complex materials. It can accurately identify high-risk configurations and filter out numerical noise, leading to improved accuracy in some cases compared to DFT reference labels.
3. An uncertainty-aware model distillation framework is proposed, which uses 𝐴? to create system-specific potentials with significantly reduced computational cost. For tungsten (W), comparable accuracy to full-DFT training is achieved using only 4% of DFT labels, while for MoNbTaW alloys, no additional DFT calculations are required.
4. The study demonstrates that the uncertainty metric 𝐴? can guide data selection and fine-tuning strategies, enabling cost-efficient development of accurate interatomic potentials. This approach also facilitates the expansion of datasets and the construction of more reliable foundation models.
5. The framework is validated on a wide range of materials, including elemental tungsten and high-entropy alloys like MoNbTaW, showing its broad applicability. The results highlight the potential for 𝐴? to enhance the safety and reliability of uMLIPs in critical applications.
📜Paper: arxiv.org/abs/2507.21297v1
#MachineLearning #MaterialsScience #UncertaintyQuantification #AtomisticSimulations #ModelDistillation
1
5
774
30 Jul 2025
Heterogeneous Ensemble Enables a Universal Uncertainty Metric for Atomistic Foundation Models
1. A new universal uncertainty metric 𝐴? has been introduced for atomistic foundation models (uMLIPs), which provides a reliable measure of prediction errors without needing reference DFT calculations. This metric is based on a heterogeneous ensemble of existing uMLIPs, leveraging their diversity to quantify uncertainty effectively.
2. The metric 𝐴? shows a strong correlation with true prediction errors across diverse datasets, including metals, alloys, inorganic compounds, and complex materials. It can accurately identify high-risk configurations and filter out numerical noise, leading to improved accuracy in some cases compared to DFT reference labels.
3. An uncertainty-aware model distillation framework is proposed, which uses 𝐴? to create system-specific potentials with significantly reduced computational cost. For tungsten (W), comparable accuracy to full-DFT training is achieved using only 4% of DFT labels, while for MoNbTaW alloys, no additional DFT calculations are required.
4. The study demonstrates that the uncertainty metric 𝐴? can guide data selection and fine-tuning strategies, enabling cost-efficient development of accurate interatomic potentials. This approach also facilitates the expansion of datasets and the construction of more reliable foundation models.
5. The framework is validated on a wide range of materials, including elemental tungsten and high-entropy alloys like MoNbTaW, showing its broad applicability. The results highlight the potential for 𝐴? to enhance the safety and reliability of uMLIPs in critical applications.
📜Paper: arxiv.org/abs/2507.21297v1
#MachineLearning #MaterialsScience #UncertaintyQuantification #AtomisticSimulations #ModelDistillation

6
827
8 Jul 2025
AI NEWSWIRE: OpenAI Boosts Security After DeepSeek Model Copying Claims
OpenAI has reportedly enhanced its security protocols to safeguard against potential corporate espionage.
The increased security measures were implemented following the release of a competing model by the Chinese startup DeepSeek in January.
OpenAI alleges that DeepSeek improperly copied its models through “distillation” techniques.
The new security measures include “information tenting” policies, which restrict employee access to sensitive algorithms and new products.
During the development of OpenAI’s o1 model, only verified team members who had been briefed on the project were permitted to discuss it in shared office spaces.
Furthermore, OpenAI now isolates proprietary technology within offline computer systems.
Biometric access controls, such as fingerprint scanning, have been implemented for office areas.
The company also maintains a “deny-by-default” internet policy, requiring explicit approval for all external connections.
Physical security at data centers has been increased, and the company has expanded its cybersecurity personnel.
These changes are reportedly driven by concerns regarding potential intellectual property theft by foreign entities.
#AI
#OpenAI
#DeepSeek
#AISecurity
#Cybersecurity
#AIIntellectualProperty
#ModelDistillation
#AIEthics
#CorporateEspionage
#DataProtection
#AIInnovation
#TechSecurity
#InformationTenting
#BiometricSecurity
#FingerprintScanning
#OfflineSystems
#DenyByDefault
#DataCenterSecurity
#CyberThreats
#AICompetition
#IntellectualProperty
#AIResearch
#TechNews
#AIStartups
#ChineseAI
#USAI
#TechRivalry
#AIGovernance
#DataPrivacy
#SecurityProtocols
#AIAdvancements
#TechIndustry
#CyberDefense
#AITheft
#ProprietaryTech
#AIRevolution
#TechEthics
#CyberSec
#AIDevelopment
#SecurityMeasures
#TechInnovation
#DataBreaches
#AIChallenges
#TechPolicy
#CyberRisks
#IPProtection
#TechCompetition
#AIStrategy
#DigitalSecurity
#TechTrends

1
3
218

1 May 2025
Big Moments from 𝗟𝗹𝗮𝗺𝗮𝗖𝗼𝗻 𝟮𝟬𝟮𝟱
𝗠𝗲𝘁𝗮 made waves at hashtag#LlamaCon2025 with major announcements shaping the future of 𝗔𝗜 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗺𝗲𝗻𝘁:
🔹 A standalone 𝗠𝗲𝘁𝗮 𝗔𝗜 𝗮𝗽𝗽 with a social "Discover" feed - positioned to rival ChatGPT
🔹 𝗟𝗹𝗮𝗺𝗮 𝗔𝗣𝗜 enters free preview, making Llama models more accessible to devs
🔹 New safety tools: 𝗟𝗹𝗮𝗺𝗮 𝗚𝘂𝗮𝗿𝗱 𝟰 (𝟭𝟮𝗕), 𝗟𝗹𝗮𝗺𝗮𝗙𝗶𝗿𝗲𝘄𝗮𝗹𝗹, 𝗮𝗻𝗱 𝗣𝗿𝗼𝗺𝗽𝘁 𝗚𝘂𝗮𝗿𝗱
🔹 Hardware collabs with 𝗚𝗿𝗼𝗾 and 𝗖𝗲𝗿𝗲𝗯𝗿𝗮𝘀 for lightning-fast inference
During a conversation between 𝗠𝗮𝗿𝗸 𝗭𝘂𝗰𝗸𝗲𝗿𝗯𝗲𝗿𝗴 and 𝗦𝗮𝘁𝘆𝗮 𝗡𝗮𝗱𝗲𝗹𝗹𝗮, some eye-opening stats and predictions surfaced:
🧠 𝟮𝟬–𝟯𝟬% 𝗼𝗳 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁’𝘀 𝗰𝗼𝗱𝗲 is now 𝗔𝗜-𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗲𝗱
📈 𝗠𝗲𝘁𝗮 𝗲𝘅𝗽𝗲𝗰𝘁𝘀 𝗔𝗜 𝘁𝗼 𝗵𝗮𝗻𝗱𝗹𝗲 𝟱𝟬% of its software development 𝘄𝗶𝘁𝗵𝗶𝗻 𝗮 𝘆𝗲𝗮𝗿
The buzz wasn’t just about speed - model distillation took center stage in the open source discussions. The ability to compress massive models into efficient, smaller versions (while preserving most of the intelligence) is being hailed as one of open source's most "magical" strengths. Imagine retaining 90 to 95% of a giant model’s power - optimized for your laptop or phone.
This is 𝗔𝗜 𝗽𝗿𝗼𝗴𝗿𝗲𝘀𝘀 𝗮𝘁 𝘀𝗰𝗮𝗹𝗲, and it's only just getting started.
#AI #Meta #Llama #OpenSource #DevTools #AIInfrastructure #LlamaAPI #LlamaCon #Groq #Cerebras #SoftwareDevelopment #ModelDistillation #GenAI #TechNews #Llamacon2025
2
61

19 Feb 2025
Make AI smarter, faster, and more efficient without the high cost & complexity!
Model Distillation is doing just that. But how?🤔& What does it mean for your business?👇
👉 Read More: zurl.co/rttgB
#AI #ModelDistillation #Innovation #Opensource #VE3 #AImodels




2
5
35

6 Feb 2025
🔥 Build a GPT-like AI for just $50, no coding required 😱!
(🔔 Please Follow me for more exciting updates on cutting-edge AI and tech!
🎥 Continue watching the full video on my YouTube: youtube.com/shorts/KcJOmjenD… )
Researchers at Stanford and the University of Washington have developed S1, an AI model that rivals industry giants like OpenAI's GPT and DeepSeek's R1. Discover how model distillation and tools like Kiln AI are democratizing advanced AI development.
__________________________________________
🌐 Discover more in my latest blog:
makayis.co/model-distillatio…
__________________________________________
🌐 Visit Our Website: Makayis.co
Revolutionize Your Business with Our Custom Chatbot 🤖
No matter your industry, our Custom Chatbot makes your business smarter, faster, and more efficient. Perfect for:
👉 Retail: Manage inquiries and suggest products seamlessly.
👉 Healthcare: Schedule appointments and handle patient questions.
👉 Hospitality: Simplify bookings and enhance customer satisfaction.
👉 E-commerce: Offer 24/7 support and tailored recommendations.
👉 Small Businesses: Automate tasks to save time.
👉 Education: Answer queries and streamline processes.
✅ Top Features:
👉 24/7 Customer Support: Never miss a query with round-the-clock assistance.
👉 Appointment Booking: Effortless scheduling for customers and clients.
👉 Order Management: Recommend products and manage customer orders with ease.
👉 Auto-Scheduling Promotions: Plan and send offers to customers via WhatsApp, email, or SMS, boosting engagement and sales.
🌟 Why Choose Us?
Affordable, easy to set up, and designed to help mid-level businesses grow without breaking the bank.
👉 Learn More & Sign Up: chatbot.makayis.co/custom-ch…
__________________________________________
Let’s Build the Future Together!
🌟 Stay Connected with Us:
🐦 X (formerly Twitter): x.com/MAKAYIS2024
📸 Instagram: instagram.com/makayisai/f
🎥 YouTube: youtube.com/@MAKAYIS2024
👍 Facebook: facebook.com/profile.php?id=…
👥 Reddit: reddit.com/user/makayis2024/
📌 Pinterest: es.pinterest.com/makayis2024…
🎶 Tiktok: tiktok.com/@makayis2024
__________________________________________
#AI #TechRevolution #ModelDistillation #S1AI #BigTech #MachineLearning #ArtificialIntelligence #getkiln #makayis
1
3
128

3 Dec 2024
🔊 I'm super excited about the new model distillation capability in Amazon Bedrock to easily transfer knowledge from a large, complex model to a smaller one. More details in @channyun 's post!
aws.amazon.com/blogs/aws/bui… via @awscloud #AWS #reInvent #ModelDistillation #AmazonBedrock
4
10
959

9 Sep 2024
Meta's Llama, an open generative AI model, is available in multiple versions and platforms, offering diverse capabilities and tools for developers.
#GenerativeAi #Llama #ModelDistillation
haywaa.com/article/meta-llam…
1
2
41

7 Feb 2024
📝 How does #ModelDistillation, #FineTuning & #RLHF come together for computer vision use cases? 📌
🙌🏻 Recently my colleague Rahul Sharma & I co-authored an end-to-end tutorial showing how easy it is for anyone to create a smaller, efficient computer vision model using a combination of model distillation and fine-tuning.
1
1
4
383

13 Nov 2023
🎓 Knowledge Extraction: Distillation techniques help smaller models mimic the network, enabling offline evaluation. #ModelDistillation $TAO #bittensor
8
534

28 Mar 2022
A survey about model distillation! 🍷
#nlp #naturallanguageprocessing #artificialintelligence #datascience #machinelearning #modeldistillation
medium.com/nlplanet/a-model-…
2
4

14 Mar 2022
#CFP #SpecialIssue "Future Edge and Tiny Machine Learning", edited by Dr. Matthew Pediaditis, Greece.
#Machinelearning
#EdgeML
#TinyML
#Embeddedmachinelearning
#EnergyefficientML
#Modeldistillation
#Smartsensors
mdpi.com/journal/futureinter…

2
4

26 Jan 2022
AutoDistill: An End-to-End Fully Automated Distillation Framework for Hardware-Efficient Large-Scale NLP Models | bit.ly/3H6o4uj
#AI #ML #ArtificialIntelligence #MachineLearning #NLP #PretrainedModel #ModelDistillation #AutoML

2