
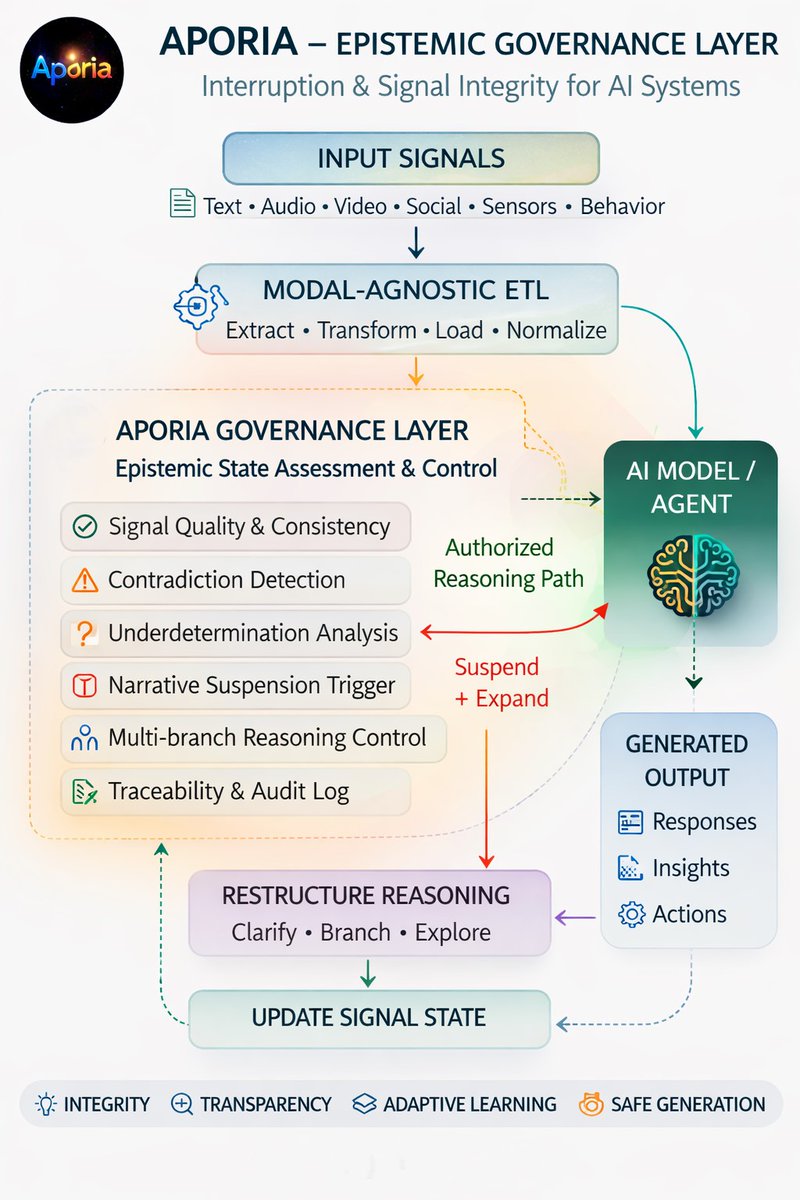
Aporia a dual‑layer intelligence system where AI generates inferences and Aporia governs them enforcing epistemic rigor, uncertainty checks, and logically defensible reasoning. #AIResearch #ReasoningSystems #ExplainableAI #UncertaintyQuantification #AI
linkedin.com/feed/update/urn…
1
7

Flexible Kernels for Protein Property Prediction
1. The paper introduces LOCK-GP: Gaussian processes with a new protein sequence kernel that combines evolutionary substitution matrices (e.g., BLOSUM) with an explicit “local linearity” inductive bias to model protein property landscapes from sparse experimental data.
2. Key kernel idea (LOCK: Locally Linear Correlation Kernel): replace one-hot “same/different” comparisons with amino-acid similarity from substitution matrices, and learn landscape-specific Hadamard-power exponents to tune how strongly similarities are amplified/attenuated while preserving kernel validity.
3. A central technical observation: many BLOSUM matrices are not only PSD but also infinitely divisible, so elementwise exponentiation by any positive power preserves PSD. This enables learnable exponents inside the GP kernel without breaking positive semidefiniteness.
4. LOCK is built from (i) an additive “linear” correlation kernel and (ii) a multiplicative “RBF-like” correlation kernel, then combined so predictions are nuanced and non-linear near training data but revert to a robust linear predictor farther away (avoiding both aggressive linear extrapolation and mean-reversion to the prior mean).
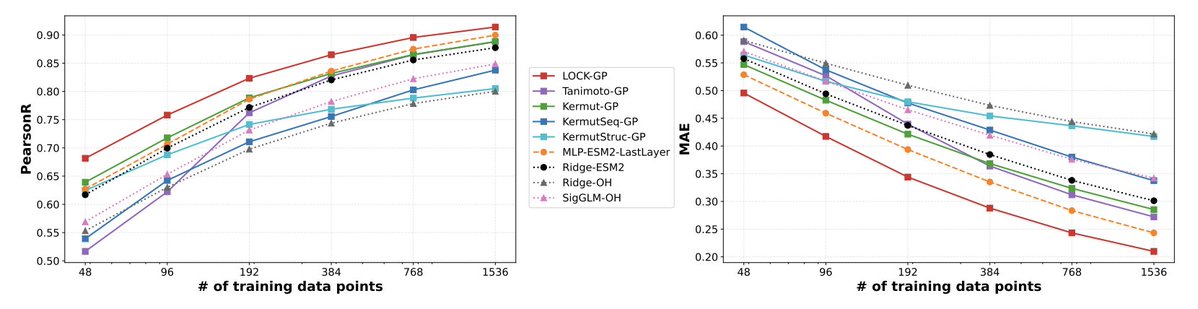
5. Benchmarking is extensive: 30 predictors evaluated across 21 protein property datasets (thermostability, binding affinity, fluorescence, capsid viability, etc.) under three regimes: i.i.d. CV, Hamming-distance extrapolation, and an “unseen mutations” OOD regime where test sequences include mutations absent from training.
6. Results highlight data efficiency and uncertainty quality: across datasets and training sizes (e.g., 48–1536 points), LOCK-GP is typically best or near-best on correlation and error metrics, and shows strong calibration via proper scoring rules like CRPS; uncertainty improves notably when local linearity is included.
7. A notable empirical takeaway: a sequence-only LOCK-GP that relies on a small substitution-matrix prior can frequently outperform or match baselines that depend on large foundation models (e.g., ESM-2 embeddings, structure features, ProteinMPNN-derived features), especially in extrapolation and OOD “unseen mutation” settings where high-dimensional embeddings can be fragile.
8. The paper generalizes LOCK to CLOCK (structure-conditioned LOCK): positional structure embeddings from a foundation model are mapped to position-specific amino-acid correlation matrices (parameterized as exp(-||z_a - z_a'||^2)), effectively learning structure-aware substitution behavior that can be used “zero-shot” as a kernel prior and then refined by GP training.
9. Multi-task learning: CLOCK-GP is trained across 371 thermostability landscapes (Tsuboyama et al.), showing that learning a shared, structure-conditioned kernel across landscapes yields strong performance; CLOCK-GP is especially competitive in low-landscape regimes (e.g., training on 10 landscapes), and learned correlations are interpretable (e.g., proline preferences near helix N-termini; arginine favored on surfaces vs cores).
10. Additional demonstrations: LOCK-GP supports GP-based Bayesian optimization via Thompson sampling to control exploration/diversity in design, and extends to binary classification (e.g., quantized fluorescence) with strong accuracy scaling with dataset size.
💻Code: github.com/generatebio/lock_…
📜Paper: arxiv.org/abs/2606.11057
#ComputationalBiology #ProteinEngineering #GaussianProcesses #MachineLearning #Kernels #ProteinDesign #UncertaintyQuantification #MultiTaskLearning #FoundationModels #Bioinformatics
2
11
1,113

9/25 𝗖𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻-𝗔𝘄𝗮𝗿𝗲 𝗞𝗮𝗹𝗺𝗮𝗻 𝗙𝗶𝗹𝘁𝗲𝗿𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗠𝗼𝗱𝗲𝗹 𝗦𝗲𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗳𝗼𝗿 𝗡𝗲𝘂𝗿𝗮𝗹 𝗗𝘆𝗻𝗮𝗺𝗶𝗰𝘀
This paper introduces the Computation-Aware State-Space Model (CASSM), a framework for dynamical latent variable modeling of single-cell neural recordings, specifically for the scale-imbalanced regime (trials significantly lower than neurons). CASSM extends computational uncertainty to model selection using a novel training loss and optimization scheme, achieving tractable inference in large state-spaces. It demonstrates competitive performance with data-hungry deep networks and significantly improved uncertainty calibration on both synthetic and real data, offering a roadmap for neuroscience researchers.
#CASSM #Neuroscience #BayesianMethods #StateSpaceModels #UncertaintyQuantification #DynamicalLatentModels
Paper Link: arxiv.org/abs/2606.01468

1
23

#mdpisystems Call for reading:
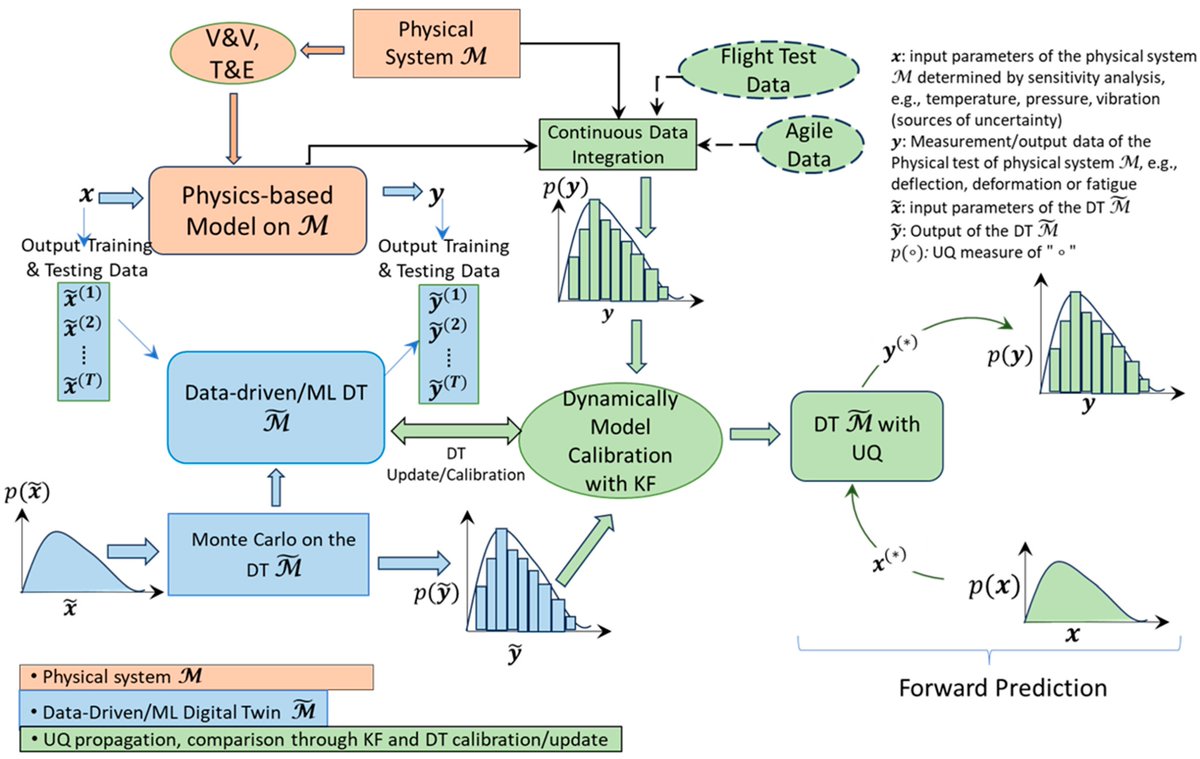
Test and Evaluation of AI/ML Enhanced #DigitalTwin
👉mdpi.com/2079-8954/13/8/656
by authors from @UTEP
#systems #digitalengineering #uncertaintyquantification #uncertaintypropagation #modelcalibration
34

💻 Code: github.com/PedrV/gnn-uq-insp…
📄 Preprint: arxiv.org/abs/2605.22593
Co-authored w/ @PedroCVieira0 & @pedroribeiro_pt.
#MachineLearning #GraphNeuralNetworks #DeepLearning #UncertaintyQuantification #GeometricDeepLearning
1
3
87

May 20
On the SIAM News Blog, Shyam Mohan Subbiah Pillai details his mathematical model that utilizes #StochasticOptimalControl, #NumericalAnalysis, and #UncertaintyQuantification to address issues surrounding renewable energy for cellular networks. Check it out! siam.org/publications/siam-n…

3
4
638
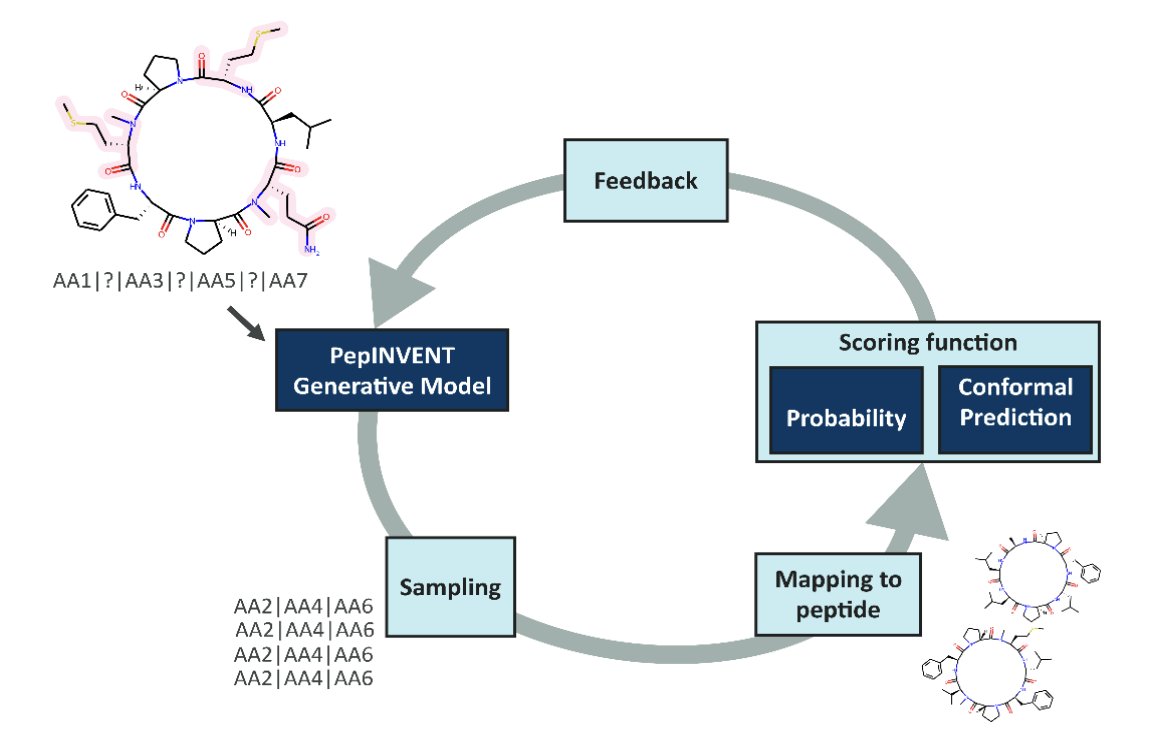
Confidence Is the Key: How Conformal Prediction Enhances the Generative Design of Permeable Peptides
1. The paper argues that RL-guided generative design can be misled by predictive models when generation drifts outside the model’s applicability domain, producing “high reward, high uncertainty” peptides—especially problematic for understudied cyclic peptides.
2. They integrate conformal prediction (CP) directly into the reinforcement learning (RL) scoring loop (PepINVENT-style peptide completion), so the agent is rewarded not just for predicted permeability, but for permeability predictions made with calibrated confidence at a user-chosen confidence level (here, 80%).
3. Core technical setup: a permeability classifier (XGBoost on ECFP features) is trained on CycPeptMPDB PAMPA data (6876 cyclic peptides; threshold LogPexp ≥ -6 as permeable). On top of this, they build an aggregated Mondrian inductive conformal predictor (ACP with 10 ICPs) outputting two p-values: P1 (permeable) and P0 (non-permeable).
4. Key conceptual point: CP’s two p-values encode “evidence for each class,” enabling four outcomes (Class 0, Class 1, Both, None). In RL, the target is not merely “high P(permeable)” but conformal efficiency: confidently permeable designs where P1 > 0.2 and P0 < 0.2 (at significance 0.2).
5. Baseline finding: optimizing raw model probability (standard practice) increases average predicted permeability (raw score rises ~0.51→0.87 over 350 epochs), but many “permeable” designs are not conformally confident—highlighting a mismatch between probability-based rewards and calibrated reliability.
6. They test multiple CP-based reward designs: maximize P1, maximize (1−P0), maximize (P1−P0), plus two discrete schemes: “harsh” (reward 1 only if both thresholds met) and “soft” (reward 1 if both met, 0.5 if one met, else 0).
7. Main methodological takeaway: single p-value optimization (P1 alone or 1−P0 alone) is learnable but does not reliably increase the number of confidently permeable peptides, because maximizing P1 does not ensure low P0 (and vice versa). The joint decision structure of Mondrian ICP matters.
8. Best-performing strategy: the CP “soft” scoring function converges fastest to the desired region (defined as reaching ~50% conformally efficient permeable predictions among valid molecules) and yields more reliable hits than raw-probability scoring when “hits” are defined as confident within-domain.
9. Practical insight on generation dynamics: the soft reward reduces brittleness from sparse rewards (compared to harsh) and improves efficiency—fewer unique valid molecules may be generated overall, but a higher fraction meet the calibrated confidence criterion, meaning less wasted exploration in uncertain space.
10. Robustness check: performance depends on peptide length and training-data coverage. The CP-soft approach works well for lengths well represented in training (6, 7, 8, 10), but deteriorates for 9, 11, 12, effectively flagging when the predictor’s applicability domain is being exceeded—useful as a “stop relying on this objective” signal.
📜Paper: arxiv.org/abs/2605.05770
#ConformalPrediction #ReinforcementLearning #GenerativeModels #PeptideDesign #CyclicPeptides #UncertaintyQuantification #Cheminformatics #ComputationalBiology #DrugDiscovery #MachineLearning
2
5
15
1,876

Apr 30
Our new review article “Calibration, Sensitivity and Uncertainty Analysis of Complex Ecological Models—A Review” now online and freely available in #EcologyLetters dx.doi.org/10.1111/ele.70375 #Ecology #EcologicalModelling #SensitivityAnalysis #UncertaintyQuantification
1
3
150

Apr 16
Huge thanks to my amazing coauthors: @kuben45, @guipsoares, Thiago Rodrigo Ramos, and Rafael Stern.
Paper: lnkd.in/ddbTysx5
#Statistics #MachineLearning #ConformalPrediction #UncertaintyQuantification #AI
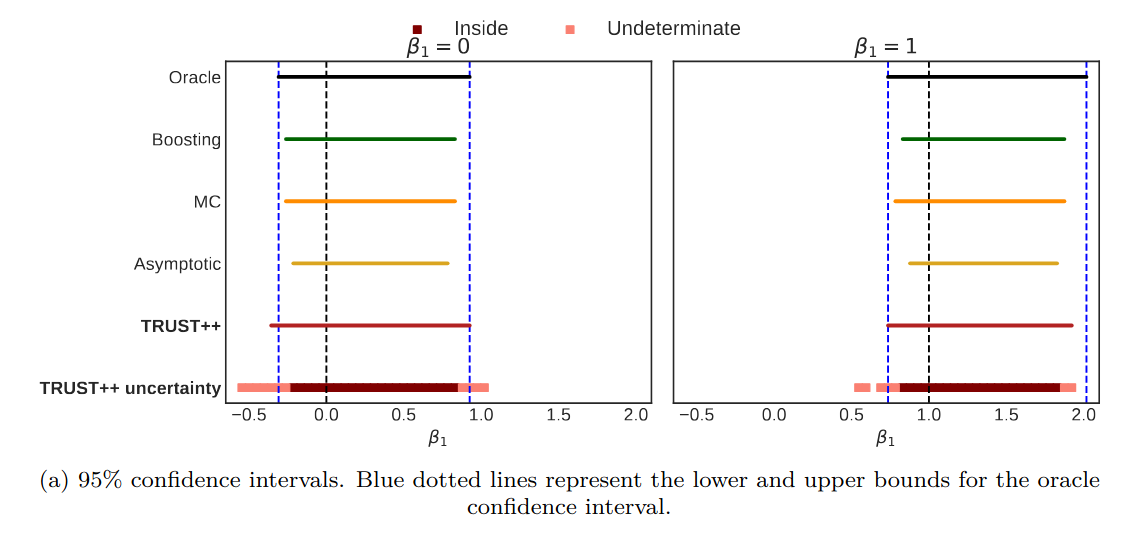
1
1
2
218
Mar 30
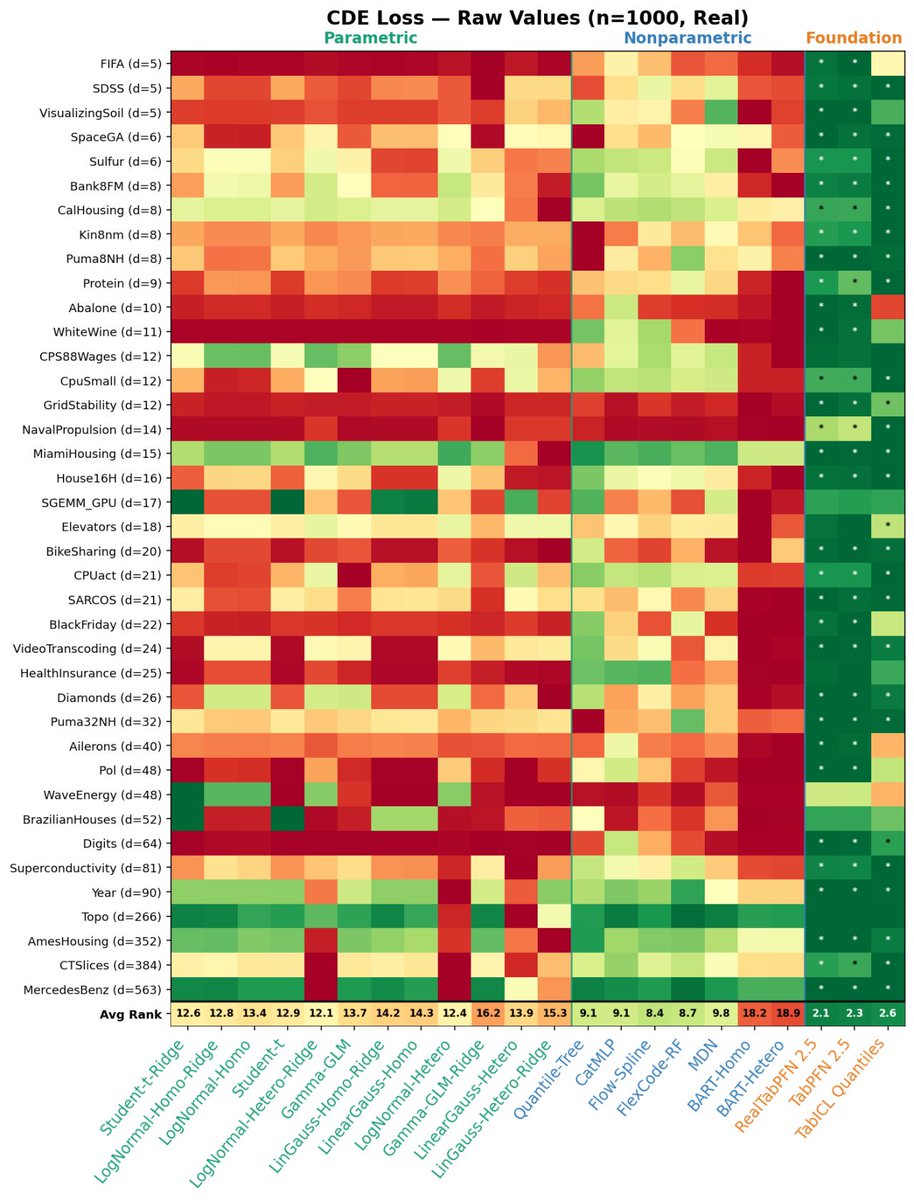
But in my study with @plc_rodrigues across 39 datasets they performed really well. In particular, for photometric redshift prediction, TabPFN trained on 50k galaxies beat all baselines trained on 500k. lnkd.in/dmFfbVcq
#ML #UncertaintyQuantification #FoundationModels
1
8
207

📊 How can we better quantify uncertainty in subsurface predictions?
Join Kushwant Singh for Introduction to Subsurface Uncertainty Quantification course. Learn how conformal prediction supports clearer uncertainty communication and better decision-making in reservoir characterization.
14–15 April 2026. Two half days. 8 hours total.
7:00–11:00 p.m. Perth time | 6:00–10:00 a.m. North America Central Time.
Register now – go.seg.org/3L0U0aA
#SEG #UncertaintyQuantification #Geophysics #ReservoirCharacterization

1
57

Feb 12
🧵 Modeling China’s Grain Yield through the Lens of Uncertainty 🌾📊
Predicting how much grain a country will produce isn’t just math — it’s national strategy.
Tingqing Ye & Rui Kang apply Uncertain Time Series Analysis (UTSA) to forecast grain yield in China, revealing why uncertainty > probability.
🌾 Why Grain Yield Matters
Grain yield fuels economies and feeds nations.
Accurate forecasts = stable food supply policy resilience.
But real-world data is messy — weather, soil, and market factors introduce uncertainty, not pure randomness. 🌦️
📊 The Breakthrough
The study applies UTSA — Uncertain Time Series Analysis — a model built on uncertainty theory, not probability. It captures structured uncertainty across decades of rice yield data. 🍚
🧮 What’s Inside the Model
🔹Order selection
🔹Parameter estimation
🔹Residual analysis
🔹Uncertain hypothesis testing
⚖️ Why Uncertainty Beats Probability
Traditional probabilistic models assume randomness.
But real agricultural systems aren’t purely random — they’re systematically uncertain.
UTSA models uncertainty directly, leading to more stable and interpretable forecasts. 🧠
🚜 The Results
✅Reliable predictions for rice yield trends
✅Improved understanding of residual patterns
✅Stronger linkage between climate variation and yield outcomes
📘 Read the full study:
👉 doi.org/10.1142/S17528909224…
This model bridges math, environment, and economics — showing how uncertainty theory can drive data-driven sustainability.
From crops to climate, uncertainty may be the key to resilience. 🍃
@Worldscientific @NaturePortfolio @AgriFoodNet @FAO @WFPAsiaPacific @DataScienceCtrl @SpringerNature @ScienceMagazine @OECDagriculture @UNFAO @OpenAI @MIT_CSAIL @AIP_Publishing @NatureComms @MDPIOpenAccess @AgriTechFuture @CIMMYT @WileyGlobal @FAOSDGs @WorldBankData @NatureClimate @CGIAR @StatModeling @econometricsoc
#GrainYield #UncertaintyTheory #TimeSeriesAnalysis #AgriculturalModeling #FoodSecurity #UTSA #StatisticalForecasting #UncertainStatistics #AgriculturalEconomics #ClimateImpact #CropModeling #DataScience #AppliedMathematics #UncertaintyQuantification #AIinAgriculture #RiceProduction #PredictiveModeling #BayesianMethods #SystemModeling #UncertainSystems #SustainableAgriculture #EconomicForecasting #FoodSystems #MathematicalModeling #AgriTech

1
3
217
Feb 5
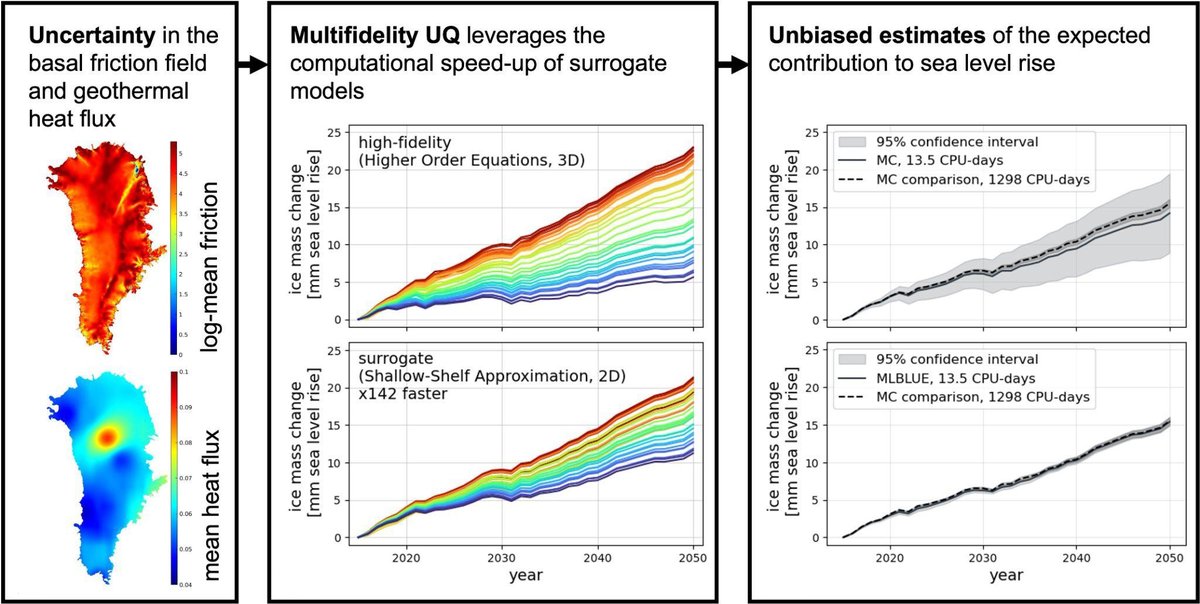
On the SIAM News blog, Leonidas Gkimisis, Nicole Aretz, Marco Tezzele, Thomas Richter, Peter Benner, and Karen Willcox combine multifidelity #uncertaintyquantification and non-intrusive reduced-order models to accurately predict #icesheet melting. siam.org/publications/siam-n…
3
5
612

🌊 Deep models, LLMs, and multimodal AI are like ships in a storm.
Fast. Powerful. But… how sure are we they won’t sink?
In messy real-world data, accuracy is not enough. We need guarantees.
🛶 New preprint: Conformalized Multiview Learning
→ First multimodal conformal inference framework
→ Finite-sample, distribution-free uncertainty
→ Works with any model (including foundation models)
→ Guarantees across early/intermediate/late fusion
📄 doi.org/10.64898/2026.01.22.…
💻 github.com/himelmallick/Cora…
#MultimodalAI #Statistics #Biostatistics #DataScience #UncertaintyQuantification #MachineLearning

1
1
4
268
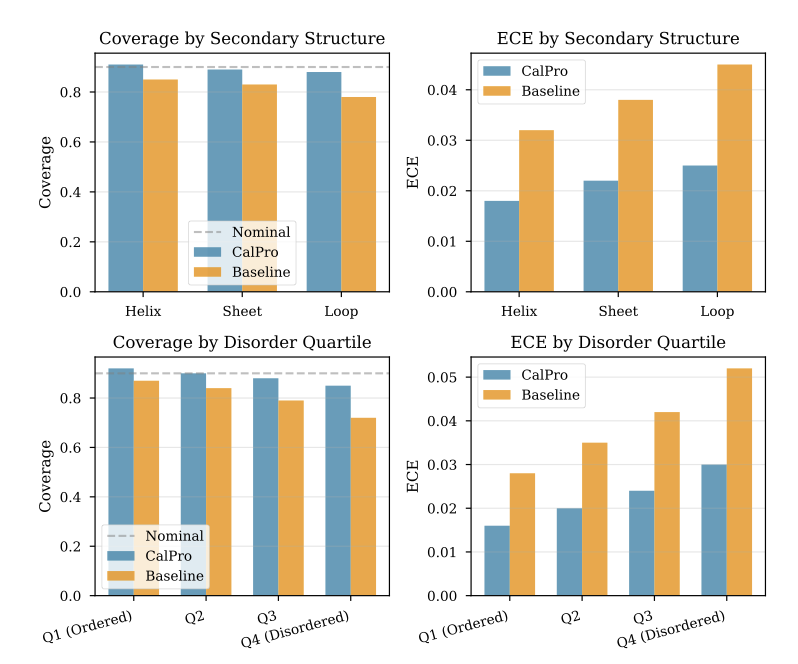
CalPro: Prior-Aware Evidential–Conformal Prediction with Structure-Aware Guarantees for Protein Structures
1. CalPro introduces a novel framework for uncertainty quantification in protein structure prediction, addressing the limitations of existing methods like AlphaFold's pLDDT. It combines geometric evidential regression, conformal prediction, and domain-specific priors to achieve robust and calibrated uncertainty estimates under distribution shifts.
2. The framework features a geometric evidential head that outputs Normal–InverseGamma distributions, capturing both aleatoric and epistemic uncertainties. This head incorporates structural priors such as disorder and flexibility directly into the model, enhancing the reliability of predictions in challenging regions.
3. A differentiable conformal layer is introduced to enable end-to-end training with finite-sample coverage guarantees. This layer approximates the conformal quantile step, ensuring that the model's uncertainty estimates are inherently easy to calibrate.
4. CalPro encodes bio-priors as soft constraints, allowing it to adaptively adjust prediction intervals based on local volatility. This results in tighter intervals in stable regions and wider intervals in disordered or flexible regions, without sacrificing overall coverage.
5. Theoretically, CalPro derives structure-aware coverage guarantees under distribution shifts using PAC-Bayesian bounds. This approach provides a principled way to control coverage degradation and maintain near-nominal coverage even when test distributions differ from the calibration distribution.
6. Empirically, CalPro demonstrates significant improvements in calibration and robustness across various experimental modalities (X-ray, NMR, cryo-EM) and synthetic perturbations. It achieves ≤5% coverage degradation compared to 15–25% for baselines and reduces calibration error by 30–50%.
7. Beyond proteins, CalPro's framework is validated on non-biological structured regression tasks with local reliability priors, showcasing its generalizability. The method also improves downstream tasks such as ligand docking and active selection of high-value experimental candidates.
📜Paper: arxiv.org/abs/2601.07201
#ProteinStructurePrediction #UncertaintyQuantification #MachineLearning #ConformalPrediction #ComputationalBiology
9
1,241
New SOTA in conformal prediction for regression just dropped.
“ Fast Conformal Prediction using Conditional Interquantile Intervals” proposes a conformal method based on conditional interquantile intervals that keeps finite-sample coverage guarantees while producing tighter, more adaptive prediction intervals and staying computationally practical.
Also worth noting: City University of Hong Kong is one of the strongest groups in conformal prediction for regression and has produced several powerful regression models over the years.
One can now find paper on github.com/valeman/awesome-c…
[arxiv.org/pdf/2601.02769](arxiv.org/pdf/2601.02769)
#ConformalPrediction #UncertaintyQuantification #Regression #MachineLearning #TrustworthyAI
2
5
13
1,373

23 Dec 2025
🔬 Reliable physics needs reliable uncertainty — and that means conformal prediction.
In high-energy physics (and increasingly across scientific ML), we still see uncertainty estimates treated as model outputs rather than statistical objects that must be valid. This is a mistake.
A recent paper once again makes the point very clearly: conformal prediction should be the default calibration layer for ML in physics. Not because it’s fashionable — but because it is the only approach that comes with finite-sample validity guarantees.
By contrast, many commonly used methods — Gaussian processes included — quietly rely on strong assumptions (correct noise models, correct kernels, asymptotics). When those assumptions fail, which they almost always do in real physics problems, the uncertainty estimates miscover:
* intervals are too narrow where noise is high
* confidence is overstated
* probabilistic outputs are not actually calibrated
This isn’t controversial, and it doesn’t need further confirmation — but the paper demonstrates it again: GP uncertainty can and does misestimate true uncertainty, while conformal calibration restores correct coverage by construction.
The key point:
> Accuracy is not enough.
> Calibration is not enough.
> Validity matters.
Conformal prediction makes your claims honest. It separates model quality from uncertainty quantification, which is exactly what physics demands.
If we care about robustness, interpretability, and reproducibility in ML-driven physics analyses, then:
* uncertainty without guarantees is not acceptable
* Bayesian-looking error bars are not evidence
* conformal prediction should be standard practice, not an afterthought
Reliable physics requires distribution-free guarantees, not wishful thinking.
💡 Strong models conformal calibration = results we can actually trust.
#MachineLearning #Physics #UncertaintyQuantification #ConformalPrediction #ScientificML #HighEnergyPhysics
arxiv.org/pdf/2512.17048v1

1
4
13
1,634
10 Dec 2025
⭐ NeurIPS 2025 Highlight — Conformal Prediction for Time-Series Forecasting with Change Points
What the paper does:
This work tackles one of the hardest problems in forecasting: real-world time series rarely stay stable. Markets shift, user behavior changes, sensors drift. The authors combine online CP with change-point detection to produce uncertainty intervals that remain valid even when the underlying data distribution suddenly changes.
Why it matters:
In domains like finance, climate, and supply chain, inaccurate uncertainty is often worse than inaccurate forecasts. This paper gives practitioners confidence that their intervals remain reliable even through structural breaks — a scenario where classical statistics often fails.
Why CP is essential:
Conformal prediction provides distribution-free, finite-sample coverage — a lifeline in non-stationary, high-risk applications.
arxiv.org/abs/2509.02844
#NeurIPS2025 #ConformalPrediction #TimeSeries #UncertaintyQuantification
1
10
68
5,039
19 Nov 2025
🎉 Congratulations to the November 2025 cohort of Applied
Conformal Prediction 🎓
What an achievement—to have committed, engaged, and succeeded in this intensive 3-week journey into the world of conformal prediction, uncertainty quantification, and deploying trustworthy ML models.
Your determination has paid off!
Here’s what makes your accomplishment extra special:
✔️ You’ve moved beyond “black-box” predictions and taken on the challenge of quantifying uncertainty in real-world ML systems.
✔️ You’ve gained tools and frameworks that many practitioners find elusive—bridging theory and practice.
✔️ You’ve joined a select cohort of professionals who value clarity, reliability, and production-ready ML.
✔️ The certificate you’ve earned isn’t just a badge—it’s proof you can build models stakeholders can trust.
To each of you:
Well done for showing up, staying focused, and completing the course.
Well done for embracing the complexity and doing the hands-on work.
Well done for taking this step to future-proof your machine learning capabilities.
What’s next?
Use your new skills: share your learnings, apply them to your projects, mentor others, and keep pushing the boundaries of trustworthy ML. You’re now part of a growing community of forward-thinking practitioners.
🚀 Next cohort starts in February 2026 — enrollment is open now!
If you’ve been thinking about mastering conformal prediction, now’s the time to join:
👉 maven.com/valeriy-manokhin/a…
Once again—huge congratulations to everyone in the November 2025 cohort. Here’s to your continued success! 🎓🔥
#ML #ConformalPrediction #UncertaintyQuantification #DataScience #TrustworthyAI #CareerGrowth
4
1,077
8 Nov 2025
🚨 New preprint: LLMs are Overconfident: Evaluating Confidence Interval Calibration with FermiEval
We love asking models for ranges—“give me a 90% CI”—but do those intervals actually cover the truth?
This paper says not really. On Fermi-style estimation questions, the authors show that nominal 99% intervals cover only ~65% of answers across modern LLMs. Ouch.
What’s new
* FermiEval: a benchmark and scoring rule to test interval coverage and sharpness (e.g., Winkler score).
* Fixes that help: conformal calibration restores accurate 99% coverage and cuts the Winkler score by ~54%; log-prob elicitation and quantile adjustments further reduce overconfidence at high confidence levels.
* Why this happens: a proposed perception-tunnel theory—LLMs reason as if sampling from a truncated internal distribution, ignoring the tails.
Why it matters
If you rely on model-reported uncertainty for decisions, uncalibrated intervals can be dangerously optimistic. Simple, model-agnostic calibration (for example, conformal) can make uncertainty estimates trustworthy again.
arxiv.org/abs/2510.26995
#LLM #UncertaintyQuantification #Calibration #ConformalPrediction #Evaluation #AIReliability

1
2
10
1,758