
2 Sep 2025
If Apache Iceberg adoption is fast, the ecosystem around it is growing even faster and that's creating one of the cheapest lakehouse infrastructure options available today.
I'm seeing some pretty exciting stuff happening in the cost-efficiency space.
If you're watching @ApacheIceberg adoption (and you should be), you've probably noticed the ecosystem around it is exploding even faster than the format itself. What's really caught my attention is how this is creating some of the cheapest lakehouse infrastructure options we've seen.
Here's the stack I'm seeing smart teams build:
🔹 @_olake for real-time replication
🔹 Apache Iceberg as the open table format
🔹 @ClickHouseDB for analytics (with some game-changing recent updates)
Let me break down why this combo is working so well...
OLake is doing the heavy lifting where it matters most - streaming data from your operational databases (@PostgreSQL , @MySQL, @MongoDB @) straight into Iceberg.
We're talking 46K records/second throughput here. And here's the kicker: it's open-source and doesn't need the usual suspects like ApacheSpark , Flink, or Debezium. Just clean, direct replication to all major Iceberg catalogs.
Iceberg brings the foundation - that open table format that eliminates vendor lock-in while giving you ACID transactions, schema evolution, and time travel. You know, all the stuff that used to be expensive and proprietary.
But here's where it gets interesting - ClickHouse just dropped some major updates in v25.8 that are making this stack even more compelling:
✅ Native Write Support - Full CRUD operations, not just reads anymore
✅ Production-Ready Catalogs - REST, Glue, Unity all promoted from experimental
✅ Schema Evolution - Add/drop/modify columns without breaking a sweat
✅ Better Deletes - Position deletes merged efficiently
✅ Near Real-time Streaming - Perfect match for ingestion platforms like OLake
Why this matters for your infrastructure costs:
Traditional warehouses are still charging premium prices for what this open stack delivers at a fraction of the cost.
ClickHouse alone is showing 5-15x cost advantages over traditional warehouses, and when you combine it with free, open-source ingestion and storage layers, the economics become pretty compelling.
The pattern I'm seeing:
Real-time ingestion → Open storage → Fast analytics = Maximum performance at minimum cost
Anyone else experimenting with similar stacks? Would love to hear what combinations are working (or not working) for you.
#ApacheIceberg #OpenTableFormats #ClickHouse #DataLakehouse #DataEngineering

1
3
49
1 Sep 2025
One of the cheapest complete lakehouse architectures you can build.
Last night I got @ClickHouseDB's experimental Iceberg write support working end-to-end.
In under 30 minutes I had a complete modern data lakehouse running locally: @MySQL (CDC source), @_olake (data pipeline), ClickHouse (Iceberg writes), @ApacheIceberg (tables), and @Minio (S3 storage).
What usually takes weeks of setup and expensive cloud services ran entirely on my laptop with a single docker-compose file.
Real-time data flowing from MySQL → Iceberg, cross-database queries working, schema auto-discovery through OLake, and MinIO acting as the S3 layer.
This stack shows how the future of data engineering is open source, fast to deploy, and accessible to anyone whether you’re a startup, learning, or experimenting with modern architectures.
Detailed blog on this coming soon!
#dataengineering #opentableformats

7
48
29 Aug 2025
We have launched one of the core features in our OLAKE 8th Meetup Call!
@_olake now supports Helm deployment, thus making it easier to scale and more reliable to work around within our ecosystem.
We have added filtering, so now you don’t have to consider those historical workflows, thus decreasing storage costs.
We have added incremental sync, helping save on storage. If your company doesn’t support CDC, you can now go ahead and experiment with Full Refresh Incremental as well!
All supported by our various databases: @MongoDB , @MySQL , @postgres , and @Oracle (newly added).
The complete call had all the people participating and showing their interest in the product.
We look forward to keeping you updated on our new core features and making our community more thriving. As part of Community Week all around @ApacheIceberg , next up are the Slack discussions!
See you there.
#dataengineering #opentableformats



7
334
28 Aug 2025
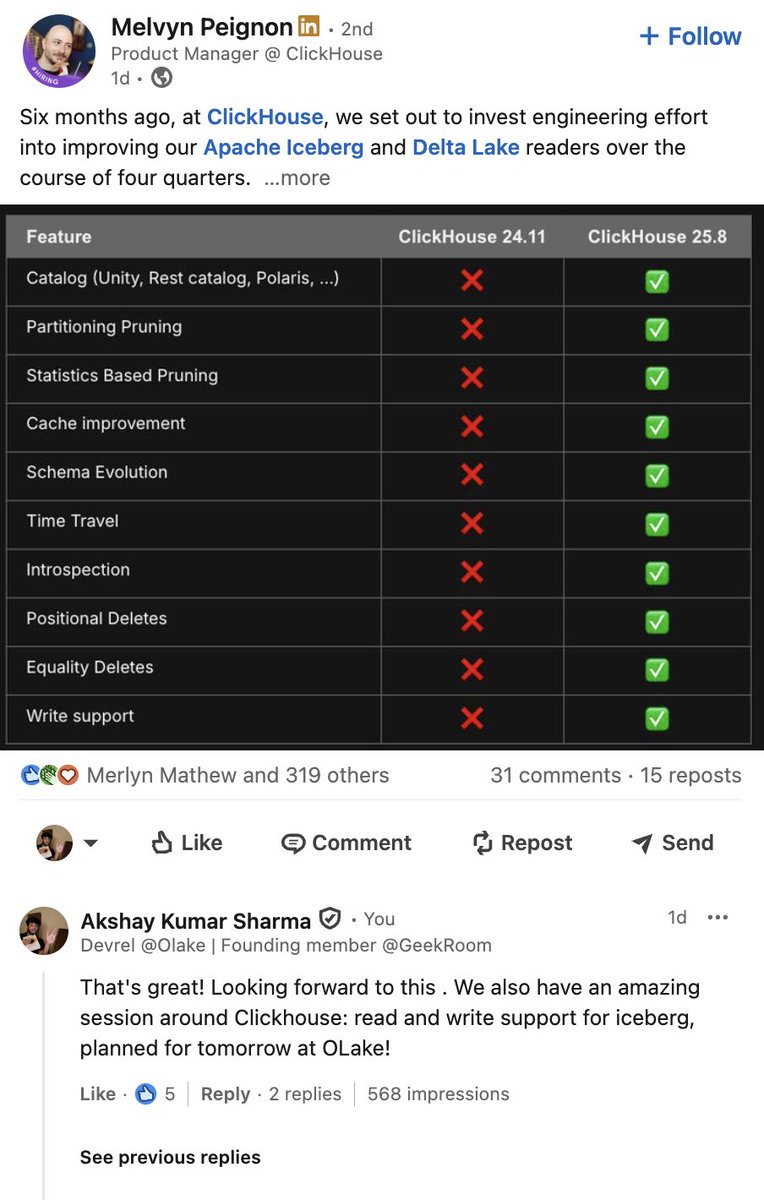
We have @ClickHouseDB that is going to drop a massive update the most comprehensive yet for open table formats
What it would hold ?
-Write support for Delta Lake (exp)
-Expanded Iceberg write support (CREATE, ALTER, etc.)
-Catalogs now in beta (incl. Unity Catalog)
-Position & equality deletes
-Improved Parquet reader
@ApacheIceberg & other open table formats are gaining serious traction, staying updated is key.
On that note, join our @_olake session today with speakers from @nutanix covering ClickHouse Iceberg read/write support, along with a live demo.
Don’t miss it fresh insights straight out of the oven: app.livestorm.co/datazip-inc…
#dataengineering #opentableformats #opensource
1
8
135
24 Aug 2025
Pheww..
I just created an 18-minute video talking about the real challenges with Apache Iceberg and why engines like @_olake are super helpful to actually address these.
I tried to get into the nitty gritty of @ApacheIceberg 6-level data elimination stack, go deep on Z-ordering (trust me, this makes a huge difference for your queries with over 1000x efficiency), and break down how partitioning in Hive can become a real bottleneck.
Along the way, I highlight where other open table formats like @DeltaLakeOSS tend to perform better or stumble and show what OLake does differently especially around issues like small file explosion and handling schema changes.
Honestly, I cover a lot more in the video than I could ever fit into a tweet, so if you’re interested in OpenTable formats or just want to be able to pitch Apache Iceberg at an event as this is what getting the PEOPLE TALKING!… give this a like and I will share the youtube link here once it's up!
See ya.
#ApacheIceberg #OLake #DataEngineering #Hive #OpenTableFormats

1
7
241
18 Aug 2025
Apache Iceberg searches are at an all-time high!
Well, if you’re a data engineer and already part of this wave great.
But if you’re not, it’s high time you adopt and understand how Apache Iceberg and open table formats are being adopted so fast, and why the biggest companies are moving towards them including @Google , @awscloud , and more.
Just check the recent acquisitions by Snowflake and other data engineering giants, and you’ll get to know where the space is heading.
That’s exactly the gap @_olake solves helping your data adoption journey and making this transition easy.
All cheap, fast, and fully open-source.
#dataengineering #bigdata #apacheiceberg #opentableformats #data

4
60
14 Aug 2025
Data engineering is changing and 2025 is being guided by open table formats..
Heard about them?
Open table formats and the “three musketeers” Apache Iceberg, Delta Lake, and Apache Hudi go in "sync" in shaping the future of data management.
To remove the blur around these choices and clear up what open table formats actually are, I’ve created a video where I summarise these concepts.
If you’re not familiar with this emerging paradigm, this video can help you understand it through both simple, layman-friendly explanations and in-depth examples.
𝐈𝐧 𝐭𝐡𝐢𝐬 𝐯𝐢𝐝𝐞𝐨, 𝐈 𝐜𝐨𝐯𝐞𝐫:
What are Open Table Formats?
How they have developed?
What about traditional formats?
How the data timeline has been?
of course, the big three, Apache Iceberg, Delta Lake, and Apache Hudi
and most importantly what's the better choice for an organziation?
Whether you’re already keeping up with these trends or just starting to explore them, this can be a good starting point to get clarity on where things are headed and how to stay aligned with the latest practices.
#dataengineering #deltalake #opentableformats #apacheiceberg #lakehouse
@_olake
1
4
183

18 Jul 2025
Big shoutout to Jordano Mark from @dremio for breaking down how clustering and Z-ordering can supercharge your Iceberg queries. Lakehouse tuning never looked so good.
Thanks to everyone who came out to the NYC Apache Iceberg Meetup!
#ApacheIceberg #Dremio #IcebergClustering #ZOrdering #LakehousePerformance #DataLayoutMatters #BigDataNYC #OpenTableFormats #ModernDataStack

1
4
324

#SnowflakeSummit is LIVE🚨Join #theCUBE’s @dvellante, @ggilbert41 & @knightrm on Day 1 discussing how @Snowflake is maintaining its value advantage with recent #OpenSource strategies.
📺 Tune in NOW!
thecube.net/events/snowflake…
#OpenTableFormats #Iceberg #EnterpriseTech #LiveNews
2
2
6
3,321

30 May 2025
Join us at @Data_AI_Summit for a deep-dive AMA exploring how Rust is transforming open table formats like Delta Lake and @ApacheIceberg! 🎉
Hear from R. Tyler Croy, Robert Pack, and @dennylee on how projects like delta-rs and iceberg-rs leverage Rust’s memory safety, zero-cost abstractions, and fearless concurrency to accelerate development and performance at scale.
Whether you're a data engineer, Rustacean, or Lakehouse contributor, this is your chance to ask how #Rust is shaping the future of data infrastructure.
📅 June 9–12
📍 San Francisco
🔗 REGISTER: databricks.com/dataaisummit
#DeltaLake #RustLang #ApacheIceberg #OpenTableFormats #DataEngineering #DataAISummit

2
6
560

15 May 2025
Cloud data costs are rising, and over 50% of that spend goes into ETL workloads. But how do you 𝘢𝘤𝘤𝘶𝘳𝘢𝘵𝘦𝘭𝘺 measure the price-performance of these critical pipelines across data lakehouses, Spark platforms and cloud warehouses?
At Onehouse, we went deep into this question. The result? A comprehensive new benchmarking study and an open-source tool – “Lake Loader”-- that captures real-world incremental loading patterns across fact, dimension, and event tables and more—that are often overlooked by traditional benchmarks like TPC-DS or even TPC-DI.
💡 In this blog:
• We break down 𝘄𝗵𝘆 𝘀𝘁𝗮𝗻𝗱𝗮𝗿𝗱 𝗘𝗧𝗟 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸𝘀 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 in today’s hybrid, real-time, open data environments
• Examine data from production and OSS communities to unpack what’s missing in current benchmarks.
• Introduce a 𝘀𝗶𝗺𝗽𝗹𝗲 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝗯𝗲𝗻𝗰𝗵𝗺𝗮𝗿𝗸 𝘁𝗼𝗼𝗹 to measure incremental loads at scale
• Finally, share an 𝗶𝗻𝘁𝗲𝗿𝗮𝗰𝘁𝗶𝘃𝗲 𝗰𝗮𝗹𝗰𝘂𝗹𝗮𝘁𝗼𝗿 to estimate TCO across platforms like Snowflake, Databricks, EMR, and others
If you care about 𝗰𝗼𝘀𝘁-𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗱𝗮𝘁𝗮 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 or want to understand how emerging data patterns like event streams, mutable tables, and concurrency impact spend, this is a must-read.
🔍 Explore the blog and try the calculator: onehouse.ai/blog/measuring-e…
#ETL #CloudDataPlatforms #DataEngineering #PricePerformance #DataLakehouse #OpenData #OpenTableFormats #Benchmarking #Onehouse #DataOps #StreamingData #TCO #BigData #OSS #DataWarehouse #AWS #Databricks #Snowflake

1
2
264

2 May 2025
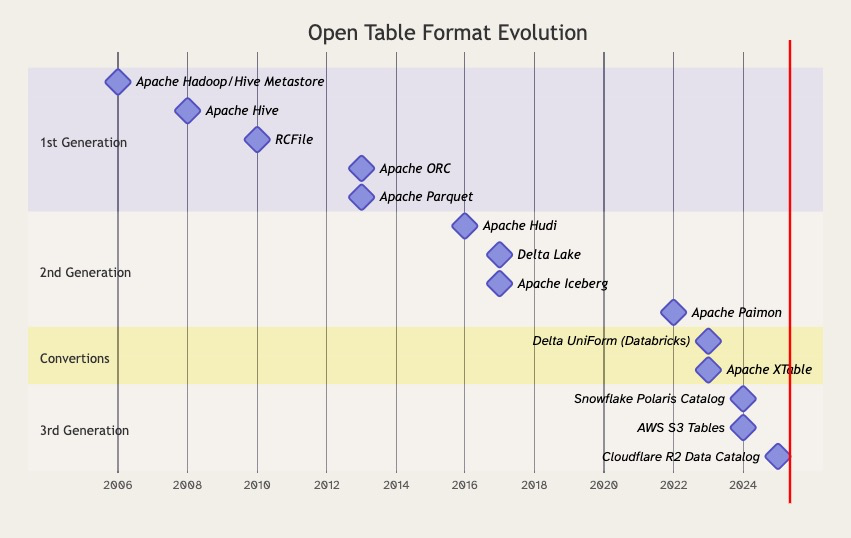
I'm writing about #opentableformats. With the newest entries of AWS S3 tables and Cloudflare R2, it's interesting to reassess the market and see where the future with managed Iceberg Tables leads us.
What's your take? And anything missing on the evolution below? Anything to add to this piece?
1
27
1,274

13 Mar 2025
✨ The RUM Conjecture on Lakehouse Table Formats
Designing storage systems is hard. It involves balancing trade-offs, encapsulated by the RUM Conjecture (Read, Update, Memory/Storage). It states you can optimize two of these aspects, inevitably sacrificing the third:
✅ Read (R): Efficient data retrieval.
✅ Update (U): Fast data updates and ingestion.
✅ Memory/Storage (M/S): Space overhead.
It's an easy choice on the data lakehouse: pick U (write efficiency)/R (query speed), given storage is relatively inexpensive.
Below are the prevalent approaches to balancing these tradeoffs on the lakehouse.
Expanded blog 👉 lnkd.in/gHSWHcPV
File Snapshots 📁 (Optimized for R, M)
- 🔍 Excellent read efficiency due to query optimization.
- 📦 Minimal storage overhead.
- ⚠️ Limited update efficiency.
LSM Trees 🛠️ (Optimized for U, M)
- 🛠️ Great for fast writes and updates.
- 📉 Poor scan performance for analytical queries. Unsuitable.
File Groups Indexes 🚀 (Optimized for R, U)
- ⚡ Balanced read/write performance.
- 📊 Higher storage overhead for maintaining indexes.
Understanding these tradeoffs via the RUM Conjecture helps you choose the ideal table format based on your primary needs—write efficiency/query speed, or storage economy.
#DataEngineering #DataLakehouse #ApacheHudi #ApacheIceberg #DeltaLake #OpenTableFormats #RUMConjecture

1
2
501

28 Jun 2023
Possibly one of the most important announcements in the #OpenSource #DataEngineering space recently:
@DeltaLakeOSS 3.0 brings a universal #Metadata format to all leading #OpenTableFormats - @DeltaLakeOSS, @ApacheIceberg, and @apachehudi!!!
#opensource #BigData #DataAISummit



1
3
10
1,728