
The US government just took Claude Fable 5 offline. Anthropic couldn't segment access in real time, so it shut the model down for everyone.
The first time a deployed frontier AI model has effectively been switched off worldwide.
This is exactly why open-source and decentralized AI matters.
Who's building it:
- @NousResearch: the team behind Hermes is building Psyche, a decentralized training network on Solana, powered by DisTrO. Hermes 4.3 became the first Hermes model to be post-trained over the open internet.
- @MacrocosmosAI: leading Bittensor subnets like IOTA (SN9) and Data Universe (SN13), allowing distributed participants to collaboratively train AI models rather than compete individually.
- @tplr_ai: its Covenant-72B is one of the boldest experiments in decentralized AI so far: a 72B parameter model trained across 70 permissionless nodes. Its SparseLoCo framework reduces communication overhead by over 100x, making internet-scale collaborative pretraining increasingly practical.
- @PluralisHQ: builds 'Protocol Learning' where no single node holds the full model weights. Its collaborative training stack, Agora, lets users with consumer GPUs contribute to large-scale AI training. The current Pluralis-8B pilot runs across distributed participants, making open, community-owned AI more accessible than ever.
- @flock_io: Rather than focusing on frontier pretraining, FLock brings decentralized AI to privacy-sensitive industries through federated learning. Data stays local while model updates are shared and verified onchain, enabling privacy-preserving AI for healthcare, biology, finance, and the public sector.
- @gensynai: Building the coordination and verification layer for decentralized ML with its rollup architecture and RL Swarm framework.
AI is becoming too important to be controlled by a handful of companies, governments, or data centers.

2
11
501


Jun 13
Camp Curriculum:
Week 1 — Bittensor Fundamentals
• Understanding Bittensor's miner, validator, and incentive mechanisms
• Exploring leading subnets including Sportstensor (SN41) & Data Universe (SN13)
Week 2 — Hands-On Mining
• Wallet setup and environment configuration
• Deploying and registering miners on real subnets
Week 3 — Optimization & Strategy
• Miner optimization techniques
• Custom scripting and anti-slash strategies
• Building your own mining proposal
Week 4 — Demo Day
• Submit and present your mining strategy
• Live feedback and Q&A with the community
1
6
257

📣 Weekend Fixtures 📣
🗓: Saturday 13th June
1s 🆚 @BoxCricketClub 2s
🏆 Wilts Div 7
📍: Box Recreation Ground - SN13 8NH
⏰: 1pm
2s 🆚 @chippenhamcc 5s
🏆 Wilts Div 10
📍: Lacock
⏰: 1pm
1
1
150

Jun 11
$TAO Smart Synergies ⬇️⬇️
ConnitoAI and Quasar: A Smart Synergy Shaping Bittensor’s Future
In the rapidly maturing Bittensor ecosystem, two subnets stand out for their complementary strengths. ConnitoAI (Subnet 102) delivers practical, efficient fine-tuning, while Quasar (Subnet 24) tackles one of AI’s toughest challenges: long-context performance. Together, they point to a realistic and powerful way forward for decentralized AI — one that can compete with centralized giants while each team chases its own revenue opportunities.
ConnitoAI: Efficient Fine-Tuning for the Masses
ConnitoAI focuses on Mixture-of-Experts (MoE) models with its in-place ESFT approach. Miners running single-GPU setups train small shards — typically just 8 out of 64 experts — using clever masked routing. The updated experts are then intelligently merged back into the full model via techniques like averaging or TIES.
The payoff is compelling: around 5× lower memory usage and 4× faster training, with solid gains on targeted tasks and minimal loss of general capabilities. This lowers barriers dramatically, allowing far more participants to contribute meaningful work.
Quasar: Cracking the Long-Context Code
Quasar brings architectural innovation through Continuous-Time Attention, achieving linear scaling instead of the usual quadratic slowdown. This enables stable, high-performance handling of contexts from 100K tokens up to millions — perfect for entire codebases, long documents, or extended reasoning.
Its hybrid, MoE-friendly design also slashes compute costs, making it an excellent base model for further development.
The Integration: Composability at Its Best
The real opportunity lies in combining them:
1. Start with a strong Quasar base for efficient long-context power.
2. Layer on Connito’s in-place ESFT for targeted expert specialization.
3. Merge the results intelligently and iterate across the miner network.
Repeated cycles can build models that excel in both massive context windows and specialized skills, steadily advancing toward generalist performance.
Why This Thesis Matters — and Why It Can Work Independently
Bittensor’s subnet model turns global collaboration into a self-reinforcing flywheel: faster iteration, lower costs, and improving efficiency over time. By tapping underutilized hardware worldwide, this approach sidesteps the enormous energy bills and capex of massive centralized data centers. Over time, the blend of linear scaling, MoE efficiency, and permissionless contributions could let these models outperform specialized offerings from Grok, Anthropic, or OpenAI in cost-efficiency, massive-context reasoning, and niche expertise.
Crucially, all of this can — and does — happen while each subnet pursues its own revenue path. Teams monetize through APIs, enterprise deals, and alpha token economics independently, yet naturally compose with others because better outputs in one subnet drive demand in the next.
Broader Paths in the Ecosystem
This isn’t the only route. Other strong options include direct large-scale pre-training via Teutonic (SN3, formerly Templar), inference optimization on Chutes (SN64), Targon (SN4), and Nineteen (SN19), agentic capabilities through Apex (SN1) and Ridges AI (SN62), and quality data via Data Universe (SN13). These interconnect seamlessly — for example, Quasar bases refined by Connito, trained on Teutonic, and served on Chutes.
The beauty of Bittensor lies in this modularity. Teams compete aggressively for revenue while the network rewards useful collaboration. In a world dominated by a handful of well-funded labs, this open, incentive-driven model offers a genuinely different — and potentially superior — path to scalable, accessible intelligence.
The ConnitoAI Quasar thesis isn’t just plausible; it’s already aligned with how the ecosystem is evolving.
#Bittensor #TAO #Quasar #Connito #SN24 #SN102 #Teutonic #SN3 #Chutes #SN64 #Targon #SN4 #Apex #SN1 #DeAI #Web3 #Crypto #AI #Solana $TAO $SOL
1
1
7
865
Jun 11
$TAO What if? - Possible synergies 👀
Pure speculation but interesting ⬇️⬇️
ConnitoAI and Quasar: A Powerful Synergy for Decentralized AI
In the Bittensor ecosystem, two innovative subnets tackle complementary challenges in building powerful AI. ConnitoAI (Subnet 102) excels at efficient fine-tuning, while Quasar (Subnet 24) solves long-context limitations. Together, they create a compelling path to accessible, high-performing decentralized AI that can compete with centralized systems.
ConnitoAI: Making Fine-Tuning Practical
ConnitoAI specializes in Mixture-of-Experts (MoE) models using in-place ESFT. Miners with single-GPU setups train small shards (e.g., 8 of 64 experts) via masked routing, then merge improvements back using techniques like averaging or TIES.
Result: ~5× lower memory and ~4× faster training, with strong task gains and minimal regression on general abilities. This opens AI development to many more participants.
Quasar: Solving the Long-Context Problem
Quasar introduces Continuous-Time Attention for linear scaling, enabling stable performance from 100K to millions of tokens. Its hybrid, MoE-friendly designs cut compute costs for massive contexts like full codebases or long documents.
The Integration: Stronger Together
Combine them like this:
1. Use a Quasar base for efficient long-context power.
2. Apply Connito’s in-place ESFT for targeted expert specialization.
3. Merge results intelligently.
Repeated rounds across miners build models strong in both long contexts and specialized skills—moving toward generalist capabilities like frontier models.
Why This Thesis Matters
Bittensor’s subnet composability turns global collaboration into a powerful flywheel: faster, cheaper development with improving speeds and efficiency over time. Connito handles practical training; Quasar provides the architectural edge.
This approach democratizes AI progress, reducing reliance on a few centralized labs with massive capex budgets. It taps underutilized global hardware and avoids the expensive energy and infrastructure costs of huge data centers. Over time, the combination of linear long-context scaling, efficient MoE specialization, and permissionless iteration could allow these models to outperform specialized offerings from Grok, Anthropic, or OpenAI in areas like massive-context reasoning, cost-efficiency, and niche expertise—where decentralized scale and rapid community-driven improvements provide a lasting edge. The result is more accessible, scalable intelligence built by the many—not just big tech.
Other Promising Paths Forward
While the Connito Quasar synergy is strong, Bittensor has multiple complementary routes involving specific subnets:
• Direct decentralized pre-training via Teutonic (SN3, formerly Templar), which has powered large-scale models like Covenant-72B and continues ambitious training runs.
• Inference optimization through subnets like Chutes (SN64) for serverless compute, Targon (SN4) for confidential/high-performance inference, Nineteen (SN19), and Apex (SN1) for agentic workflows.
• Agentic and tool-use via Apex (SN1) and Ridges AI (SN62) for autonomous agents and coding tasks.
• Data curation through Data Universe (SN13) for high-quality, community-curated datasets.
These paths interconnect—for example, Quasar bases fine-tuned via Connito, pre-trained on Teutonic, deployed on Chutes, and enhanced with data from SN13. The ecosystem’s strength lies in this modularity: many parallel experiments compounding into robust, open AI.
This synergy highlights Bittensor’s potential for truly open and competitive AI.
#Bittensor #TAO #Quasar #Connito #DecentralizedAI #Solana $TAO $SOL
1
1
3
513

Jun 9
Live Townhall Schedule 🗓️
June 11 — Introduction to Bittensor
June 15 — Tooling & Tokenomics
June 17 — Subnets Deep Dive
June 19 — Hands-on Mining (SN41)
June 22 — Hands-on Mining (SN13) & Troubleshooting
June 24 — Graduation & Showcase
All sessions take place online via Zoom from 19:00–21:00 WIB.
1
4
361
Jun 9
Camp Curriculum 📖
Topics include:
• Bittensor fundamentals: subnets, miners, validators & incentives
• $TAO and Dynamic TAO tokenomics
• Wallet setup, btcli & Bittensor SDK
• Deep dives into leading subnets like Chutes, Data Universe & Sportstensor
• Hands-on mining workshops on SN41 and SN13
• Miner monitoring, troubleshooting & deployment best practices
Come curious. Leave with real Bittensor experience 🤝
1
1
326
Jun 8
Thinking about joining but still have questions?
❓ Who can join?
Anyone interested in Web3 — from complete beginners to experienced builders.
❓ What will you learn?
A hands-on learning track in Bittensor covering:
▪️ Bittensor fundamentals & subnet architecture
▪️ Miners, validators, and TAO incentives
▪️ Wallet setup, btcli, and mining tooling
▪️ Real subnet participation with SN41 & SN13
▪️ Mining strategies and optimization
❓ Is it free?
Yes — completely free to join, with opportunities to compete for hackathon prizes 🏆
1
4
266
Jun 8
🗓️ Schedule
▪️ June 11 — Registration deadline
▪️ June 12 — Camp starts
▪️ July 2 — Graduation
🕘 All townhalls: 9:00–10:00 PM EAT (Zoom)
Townhalls:
▪️ June 12 — Intro to Bittensor
▪️ June 16 — Tooling & Tokenomics
▪️ June 20 — Core Subnets Deep Dive
▪️ June 24 — SN41 Sportstensor Mining
▪️ June 28 — SN13 Data Universe Mining
▪️ July 2 — Graduation Builder Showcase
1
1
5
271

Jun 4
The largest company $TAO
No CEO. No HQ. No payroll.
Just teams competing to out-build each other, it is closer to equity in the only company on earth that hires, fires, and promotes without a single human in the loop.
SN1: @MacrocosmosAI
SN2: @inference_labs
SN4: @TargonCompute
SN6: @numinous_ai
SN7: @allways_io
SN8: @VantaSN8
SN9: @MacrocosmosAI
SN11: @TrajectoryRL
SN13: @MacrocosmosAI
SN15: @oroagents
SN17: @404gen_
SN18: @zeussubnet
SN22: @desearch_ai
SN23: @trishoolai
SN29
SN32: @ai_detection
SN33: @ReadyAI_
SN34: @bitmind
SN35: @0x_Markets
SN36: @rendix_network
SN39
SN41: @almanac_market
SN43: @graphitesubnet
SN44: @webuildscore
SN47
SN48: @qBitTensorLabs
SN50: @SynthdataCo
SN51: @lium_io
SN54: @yanez__ai
SN55: @NiomeAI
SN56: @gradients_ai
SN60: @bitsecai
SN61: @redteam
SN63: @EnigmaSN63
SN64: @chutes_ai
SN65: @SN65_TPN
SN66: @Ninja_Subnet
SN68: @metanova_labs
SN70: @NexisGen_ai
SN71: @LeadpoetAI
SN74: @gittensor_io
SN75: @hippius_subnet
SN77: @77Liquidity
SN103: @djinn_gg
SN104
SN107: @theminos_ai
SN108: TalkHead
SN110: @green_compute_
SN111: @oneoneoneIO
SN117
SN120: @affine_io
SN123: @Barbarian7676
SN124: @SwarmSubnet
SN126: @poker44subnet
SN128: @byteleap_ai
@mentatminds said something most of these subnets burn 100% of their emissions the ones that produce real revenue rise while the rest get starved of emissions automatically.
It is a corporation run by natural selection instead of a corner office.
Sit with that.
$TAO
Jun 4

Bittensor isn't broken, our focus is.
Sum of Subnets (SoS) contains 50 subnets that burn 100% of their emissions.
We need a true benchmark that tracks what actually matters.
Sum of Mining Subnets (SoMS) is the one we need.
Buy the real Bittensor market in 1 click with Mentat SoMS.
Bittensor is designed around incentives. If we fund the subnets that build, ghost subnets die out. No regulation needed, just better capital allocation.
Let's make SoMS outperform SoS.
These subnets in comments are the true face of the network 👇
2
17
105
6,823

Jun 4
SN1: @MacrocosmosAI
SN2: @inference_labs
SN3
SN4: @TargonCompute
SN6: @numinous_ai
SN7: @allways_io
SN8: @VantaSN8
SN9: @MacrocosmosAI
SN11: @TrajectoryRL
SN13: @MacrocosmosAI
SN15: @oroagents
1
10
892
Jun 2
🚨 The reason this is bigger than Decentralized Training JUST Got BIGGER is the Architectural Choice. THE most powerful moat in all of AI is the training cluster $TAO's SN1, SN9, SN13.
Ask yourself this: if GPUs worldwide can be aggregated into frontier training capacity at a fraction of the cost then the defining bottleneck of the AI age stops being WHO CAN AFFORD A DATACENTER and becomes WHO CAN COORDINATE THE CROWD (blockchain & AI)
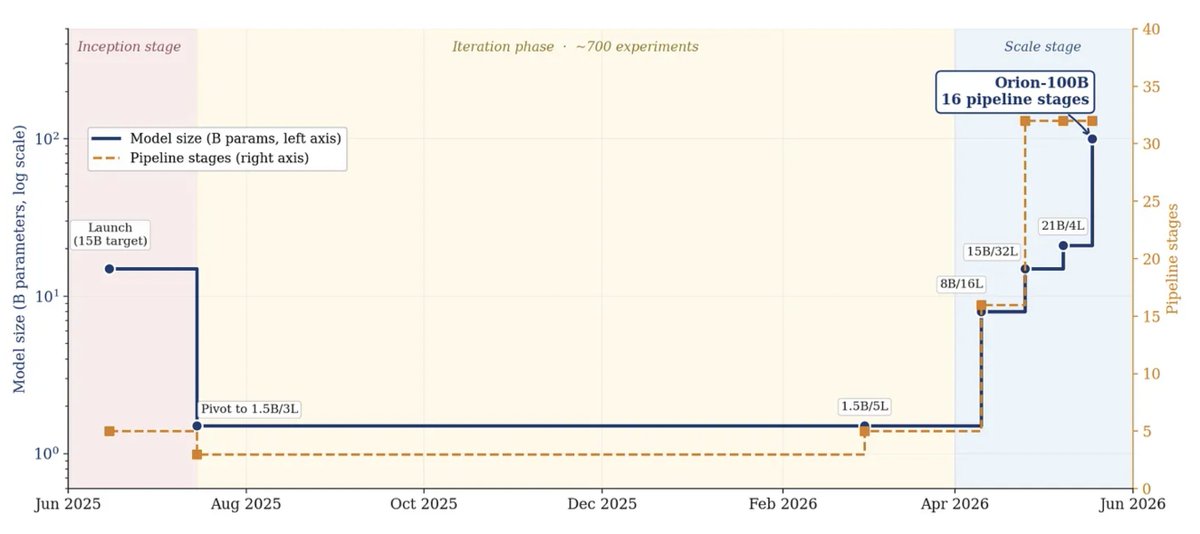
A 100-billion-parameter model was just pre-trained across single GPUs scattered around the open internet. No datacenter.
The thing every expert said was impossible just happened, and almost nobody grasps what it unlocks.
Macrocosmos @MacrocosmosAI launched Project Orion Orion-100B, an early pre-training run of a:
• 100B-parameter model
• Llama-3.2 architecture
• 90 transformer blocks
• Sharded across 16 pipeline stages
• One A100 per stage
• 3 replicas
• Globally distributed hardware
It hit 30% Model FLOP Utilization and roughly 65% of full datacenter training speed on commodity GPUs costing a fraction of a cluster.
Every other decentralized-training effort INTELLECT-1, EVEN Covenant-72B, Psyche took the DATA PARALLEL route: Every peer must hold the entire model.
That works, but it has a hard ceiling the biggest model you can train is capped by the SMALLEST machine you require.
Covenant needs 8×B200 per peer ($50/hr). "Permissionless" on paper; almost nobody can actually join. And data-parallelism only SPEEDS-UP training you could already do it doesn't unlock training you otherwise couldn't.
IOTA did the hard thing instead.
It splits the MODEL ITSELF across peers each one holds as little as a single transformer block, contributes one commodity GPU, and the network stitches them into one larger machine. (A leading researcher last October called this LIKE FIGHTING GRAVITY and walked out. They built it anyway, in under a year.)
Sit with this because it is the whole thing.
In traditional data-parallel training, capacity is capped by the biggest machine in the room.
In IOTA’s pipeline-parallel world, capacity scales with the SIZE OF THE NETWORK
Add more peers.
Train a bigger model.
No single GPU sets the ceiling.
That is A MASSIVE breakthrough.
The largest models in the world become trainable by a CROWD of ordinary GPUs eventually, consumer hardware.
Orion-100B was trained across the open internet using globally distributed GPUs, hitting up to 65% of datacenter training efficiency on hardware costing a fraction of the price.
That does not happen by accident.
It required real engineering:
• ResBM for lossless activation compression.
• A custom fault-tolerant P2P protocol for unreliable nodes.
• Distributed synchronization that keeps replicas tracking together.
The biggest moat in AI is the training cluster.
Hundreds of billions in capex.
Massive datacenters.
Only a few companies able to play.
That is the wall keeping frontier intelligence centralized.
IOTA is putting the first serious crack in it.
If underutilized GPUs around the world can be coordinated into frontier training capacity, then the bottleneck is no longer who can afford the datacenter.
It becomes who can coordinate the crowd.
That changes everything.
And this is not a one-off.
Macrocosmos is building the full TRULY OPEN AI stack on Bittensor:
@IOTA_SN9 for distributed pre-training.
@Apex_SN1 for post-training and competitions.
@Data_SN13 for real-time open data.
Pre-training.
Post-training.
Data.
The three things frontier labs keep locked behind closed doors are being rebuilt in the open, owned by a network, and paid for in $TAO.
The bear case said decentralized training was fighting gravity.
The bull case just trained 100B parameters across the open internet at 65% of datacenter speed.
If they are right, the most expensive moat in AI does not get crossed.
It gets dissolved, folks.
The floor of who gets to build intelligence just dropped through the basement.
$TAO
DYOR.
Jun 1

Today, we are launching the first stage of Project Orion.
Our early pre-training run of Orion-100B achieves upward of 65% of data-center training efficiency on hardware costing a fraction of the price.
Orion-100B is the first proof point for a simple idea: that underutilized compute around the world can be turned into frontier training capacity.
We believe that this work presents, for the first time, an economically compelling case for training large models using distributed approaches.
2
10
61
3,209

Jun 2
Buzzing round the estates 🐝
@BeeNetwork @StagecoachGM 27941 - SN13 CKK at #Oldham Bus Station yesterday afternoon working a 402 service back to #Shaw.

5
132

Jun 1
I'd like to think that usually past performance is a predictor of future performance - in all likelihood the team that's been running SN1, SN9 & SN13 from the inception of bittensor subnets and exited SN25 & SN39 gracefully without negative impact to investors is one of the least likely teams to rugpull.
The entire reason we use one wallet was to allow >256 miners and bittensor simply imposes various limitations that occasionally make it useful to think out of the box.
5
171

May 29
27 intel items. 4 subnets flashing RSI oversold. TD Buy 13confirmed on SN13. Conviction holders quietly stacking on CliqueAI (66), ByteLeap (31), dogelayer (25).
TAO is down 4.4% and nobody's paying attention to what's moving underneath.
That's the edge
subnetaiq.io
2
38

Monday Bittensor Series — Week 21: Subnet 13 — Data Universe
What if AI builders could access fresh social data at scale without relying on centralised data vendors? That’s the idea behind Data Universe on Bittensor bittensor:native
Category: Data Infrastructure
SN13 Price: 0.0075 TAO / $2.10
Market Cap: 39,020 TAO / $10.9M (Rank 30)
Daily TAO Emissions: N/A
Yield: 45–55% APY
About
SN13 Data Universe is Bittensor’s decentralised data layer, built to collect, structure and distribute fresh, high-value social data at scale. It continuously scrapes social platforms such as X and Reddit, allowing AI builders and businesses to access fresh, queryable data in real time.
Team
Data Universe is operated by Macrocosmos, one of Bittensor’s premier builders, led by co-founders Will Squires (@WSquires) and Steffen Cruz (@macrocrux). The team also includes a broad engineering and product group spanning machine learning, software, delivery, design and communications.
How it works
Traditional data scraping services for real-time social data are expensive, create vendor lock-in, and often struggle to provide fresh, diverse data across multiple platforms. Data Universe takes a different approach by using Bittensor to create a decentralised peer-to-peer network where miners collectively scrape and store large volumes of real-time data from social platforms. Validators then quality-check the data and reward miners for the most useful, unique and credible contributions.
The team brings this together through Gravity, its data collection product and automated tool. Gravity extracts data from social networks and makes it easier to access and analyse. It currently provides data from X, Reddit and YouTube transcripts, with more sources in the pipeline. It collects text, product listings, pricing information, reviews, articles and more.
In a short period of time, Data Universe has already become one of the world’s largest open-source social media repositories, with 55B rows scraped to date and up to 80M rows of new data added per day. On privacy and compliance, it enforces strict data protection standards, including GDPR-related requirements in supported regions.
Data Universe offers flexible pricing for Gravity, with plans ranging from $99 to $499 per month depending on business size and requirements, plus pay-as-you-go and enterprise options. Ready-made datasets curated by others can also be purchased via its marketplace and integrated seamlessly. Datasets can be uploaded and explored via Nebula, an interactive 3D point-cloud visualisation tool that helps companies better understand their data.
What’s next
The Data Universe roadmap points toward broader data coverage, stronger API integration and improved analytics tooling. The team also plans to expand beyond its current social platform coverage, implement stronger validation and reward mechanics, and continue focusing on transparency, automation and new datasets.
SN13 Data Universe Alpha Token
At the time of writing, Data Universe is ranked No.30 on Bittensor but is not currently receiving daily TAO emissions due to negative net TAO flows in its liquidity pool. Its SN13 Alpha token is priced at 0.0075 TAO (~$2.10), with about 5.2M tokens issued out of a 21M max supply cap. SN13 can be purchased and staked on platforms that support the Bittensor ecosystem, with current staking rewards in the region of 45–55% APY (subject to change, so always verify the latest numbers).
Why it matters
When you combine Gravity’s real-time scraping, the marketplace for ready-made datasets and the Nebula 3D visualisation tool, SN13 becomes more than a protocol — it becomes a usable data product for market research, forecasting and AI training.
Data is one of the biggest bottlenecks in modern AI, and with Data Universe, the Macrocosmos team is aiming to make that data more open, current and scalable. As the product grows, it could become a key supply layer for AI training, sentiment analysis, market intelligence and any application that depends on high-quality social signals. In short, SN13 is not just a data subnet — it’s an infrastructure layer for the next wave of AI and social intelligence.
For more info on SN13 Data Universe, check out:
Website: datauniverse.macrocosmos.ai/
X: @Data_SN13 / @MacrocosmosAI
Before investing in Bittensor Subnets, always do your own due diligence, and remember: the value created by all 128 Bittensor subnets — including Affine — is ultimately reflected in bittensor:native
If you found this helpful, please like and share to help spread the word of #Bittensor and #SN13 #DataUniverse
Thanks for reading :)
3
67