
Jun 10
If you can’t see what’s happening in production, you can’t fix it fast. We implement observability so your team can detect issues before users complain.
#AppVertices #CloudDevelopment #DevOps #Observability #SystemReliability

1

Jun 8
🎯⚙️ MONDAY READINESS | Operational Headroom Assessment
P-OPS Team — Validator Operations
☕ Good Morning Operators,
A quiet Monday morning tells us very little.
What matters is how much capacity remains before conditions change.
📊 Readiness is not measured by what systems are doing now.
🧠 It is measured by what they can absorb later.
Before governance proposals arrive.
Before transaction volumes expand.
Before infrastructure encounters unexpected stress.
We assess operational headroom.
🧭 Focus: identifying available capacity before the week begins to consume it
Across supported networks this morning:
📡 Peer connectivity → healthy route diversity maintained
⚙️ Validator services → operating within expected resource profiles
💾 Storage systems → low latency with clean response characteristics
🧠 Memory utilisation → stable with sufficient allocation headroom
🗂️ State growth → progressing within forecasted ranges
📊 Monitoring pipelines → delivering complete and consistent telemetry
Current conditions remain stable.
The objective is ensuring they remain stable when demand increases.
🔎 Areas receiving additional attention
📈 Resource consumption trends accelerating faster than baseline
🧩 Capacity bottlenecks forming inside otherwise healthy systems
📡 Network paths becoming overly dependent on preferred peers
💾 Storage utilisation approaching operational review thresholds
🔄 Background services consuming increasing scheduler time
These signals rarely trigger alerts.
They often determine how infrastructure behaves days later.
🧪 Monday verification set
𝚏𝚛𝚎𝚎 -𝚑
𝚞𝚙𝚝𝚒𝚖𝚎
𝚝𝚘𝚙 -𝚋 -𝚗 1
𝚒𝚘𝚜𝚝𝚊𝚝 -𝚡 1 5
𝚍𝚏 -𝚑
𝚌𝚞𝚛𝚕 -𝚜 𝚕𝚘𝚌𝚊𝚕𝚑𝚘𝚜𝚝:𝟸𝟼𝟼𝟻𝟽/𝚜𝚝𝚊𝚝𝚞𝚜
🎯 Why this matters
Infrastructure rarely fails because capacity disappears suddenly.
More often, capacity is consumed gradually until flexibility vanishes.
Monday Readiness exists to measure that flexibility while it still exists.
Because resilient weeks are built from surplus capacity, not last-minute reactions.
☎️ Stay Connected with P-OPS Team:
🌎 Website: pops.one
🌳 Linktree: linktr.ee/p_opsteam
🐥 Twitter: x.com/popsteam1
↗️ Telegram: t.me/POPS_Team_Validator
👾 Discord: discord.gg/jJ8aaMwPwa
#MONDAYREADINESS #ValidatorOps #PopsTeam #NodeOperations #DevOps #CryptoInfrastructure #Web3Infrastructure #SystemReliability #InfrastructureEngineering #StakingOperations

7
16
238

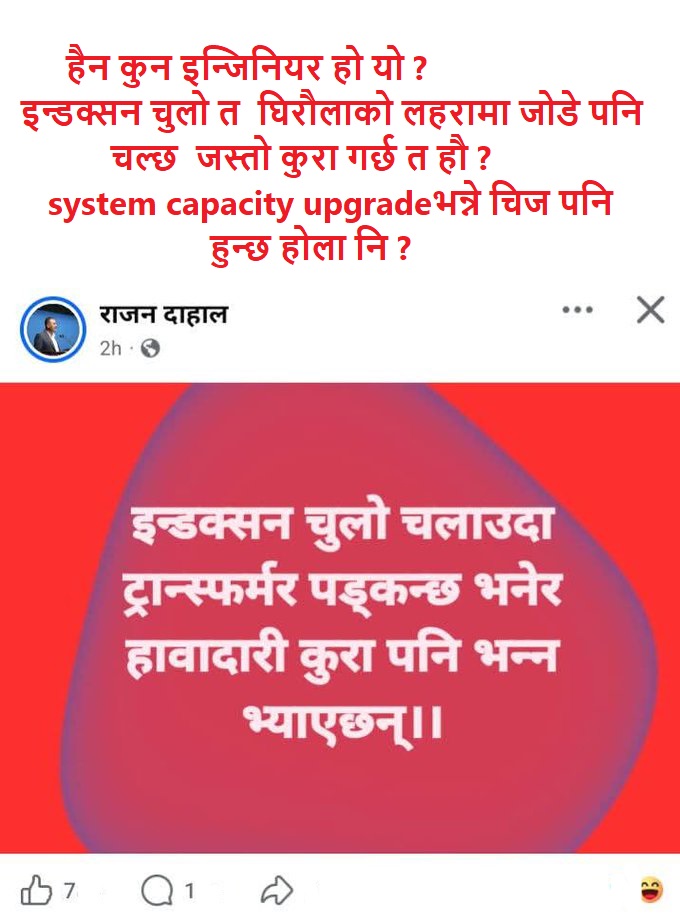
उर्जा विकास गफले होइन, ठोस इन्जिनियरिङले चल्छ। #SystemReliability, Load Flow, र Substation को क्षमता अभिवृद्धि नगरी दिगो विद्युत आपूर्ति असम्भव छ। प्राविधिक ज्ञानविहीन सस्तो भिडको पछि लाग्नुभन्दा प्रणालीको दिगो सुधारमा बहस गरौँ। #PowerSector #HydroNepal #NepalElectricity
1
2
12
185
Jun 1
🎯⚙️ MONDAY READINESS | Systems Preparedness Report
P-OPS Team — Validator Operations
☕ Good Morning Operators,
Monday does not begin with activity.
It begins with verification.
Before load increases.
Before governance changes propagate.
Before network conditions introduce variance.
We establish readiness as a measurable state — not an assumption.
🧭 Focus: confirm operational stability before the week introduces stressors
Across supported networks this morning:
🧱 Consensus state → aligned across validator set
📡 Peer topology → stable, diversified routing maintained
🗂️ Service configuration → consistent across deployments
💾 Storage performance → within expected latency bands under baseline load
📊 Monitoring systems → reflecting observed node behaviour accurately
🔄 Processes → running cleanly with no unexpected restarts or drift
No anomalies required escalation.
That is the baseline we protect.
⚠️ Areas under routine observation
🧩 Configuration drift emerging from prior maintenance cycles
🧹 Residual artifacts from temporary operational workarounds
📈 Gradual resource creep masked by stable averages
🌐 Subtle reductions in peer diversity across edge routes
🗃️ Log growth patterns approaching review thresholds
None are critical in isolation.
Together, they define future risk if left unchallenged.
🧪 Verification set
𝚜𝚢𝚜𝚝𝚎𝚖𝚌𝚝𝚕 𝚜𝚝𝚊𝚝𝚞𝚜 <𝚜𝚎𝚛𝚟𝚒𝚌𝚎>
𝚓𝚘𝚞𝚛𝚗𝚊𝚕𝚌𝚝𝚕 -𝚋 -𝚜𝚢𝚜𝚝𝚎𝚖
𝚜𝚜 -𝚝𝚞𝚕𝚗𝚊𝚙
𝚒𝚘𝚜𝚝𝚊𝚝 -𝚡𝚣 𝟷 𝟻
𝚌𝚞𝚛𝚕 -𝚜 𝚕𝚘𝚌𝚊𝚕𝚑𝚘𝚜𝚝:𝟸𝟼𝟼𝟻𝟽/𝚜𝚝𝚊𝚝𝚞𝚜
🎯 Why this matters
Most infrastructure issues do not begin as incidents.
They begin as unverified assumptions carried forward into a new cycle.
Monday Readiness is the control point where those assumptions are removed.
A stable week is not created by reacting well.
It is created by starting correctly.
☎️ Stay Connected with P-OPS Team:
🌎 Website: pops.one
🌳 Linktree: linktr.ee/p_opsteam
🐥 Twitter: twitter.com/POpsTeam1
↗️ Telegram: t.me/POPS_Team_Validator
👾 Discord: discord.gg/jJ8aaMwPwa
#MONDAYREADINESS #ValidatorOps #PopsTeam #NodeOperations #DevOps #CryptoInfrastructure #Web3Infrastructure #SystemReliability #InfrastructureEngineering #StakingOperations

7
18
123

🔥 Ancient firefighters waited for fires.Modern SREs prevent them before they spread.
Read More 👉 resources.callgoose.com/blog…
#CallgooseSQIBS #SRE #DevOps #IncidentResponse #Automation #ITAutomation #Alerting #IncidentManagement #WorkflowAutomation #SystemReliability

5
5
22
⚙️ Still handling routine IT requests manually? That’s draining your team.
Read More 👉 resources.callgoose.com/blog…
#CallgooseSQIBS #ITAutomation #Automation #ITOperations #WorkflowAutomation #DevOps #SRE #IncidentManagement #IncidentResponse #CloudOps #SystemReliability

4
4
27
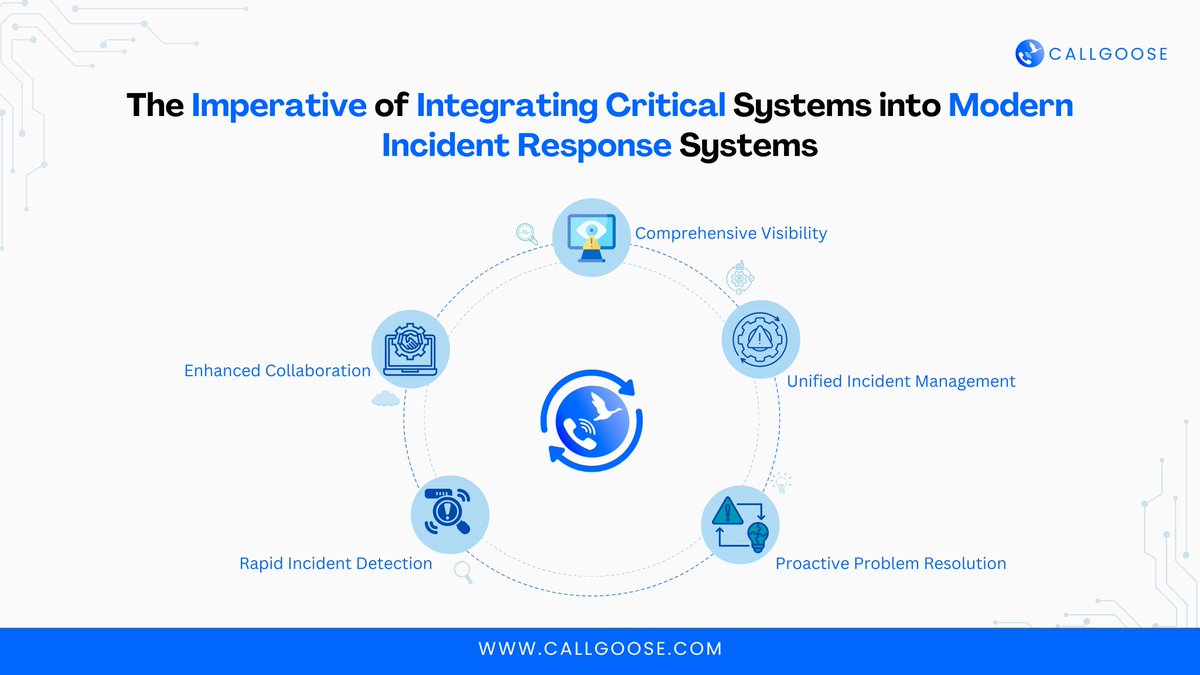
🚨 Your incident response is only as strong as the systems connected to it.
Read More 👉 resources.callgoose.com/blog…
#CallgooseSQIBS #IncidentResponse #ITOperations #Automation #ITAutomation #DevOps #SRE #Monitoring #Alerting #WorkflowAutomation #CloudOps #SystemReliability
5
5
23

May 21
Most AI deployment failures I've seen weren't accuracy problems. They were reliability problems. And the distinction matters because the fix for one makes the other worse.
Here's what I mean:
Model accuracy is: "Given this input, does the model produce the right output?" You measure it on a test set. You improve it with more data, better architectures, fine-tuning. It's the thing everyone optimizes for because it's the thing you can measure most easily.
System reliability is: "Given the real world, does the whole pipeline produce a usable result consistently?" That pipeline includes data freshness, upstream API uptime, schema drift, latency budgets, fallback paths, the human who has to act on the output, and the edge cases your test set never saw because they didn't exist when you built it.
The conflation happens like this: a team ships a model that's 94% accurate on their benchmark. In production, it works well for three weeks. Then an upstream data provider changes a field format. The model doesn't break — it still returns outputs with 94% accuracy on the cases it recognizes. But now 12% of incoming requests hit a path the model was never trained on, and it silently returns confident wrong answers instead of flagging uncertainty.
The accuracy didn't change. The reliability collapsed.
Here's the tradeoff nobody talks about: making a system more reliable almost always makes the model less accurate on the cases you can measure. Because reliability requires guardrails — input validation, confidence thresholds, fallback to simpler models, human review loops — and every guardrail rejects some correct outputs along with the wrong ones. Your precision on the easy cases drops slightly so your system doesn't fail catastrophically on the hard ones.
Teams that optimize only for accuracy build fragile systems. Teams that optimize only for reliability build slow, over-cautious systems that frustrate users. The real work is in the middle, and it's architectural, not algorithmic.
Three distinctions that help:
1. Confidence calibration vs. accuracy. A model that's right 94% of the time but can't tell you WHICH 6% it's wrong about is far more dangerous than a model that's right 88% of the time and knows exactly where it's uncertain. Uncertainty isn't a failure mode — unidentified uncertainty is.
2. Graceful degradation vs. failure. A reliable system has explicit degraded modes: "I can't give you a full answer, but here's a partial one with these caveats." An accurate-only system has two states: works or doesn't. In production, you need three: works, degrades, and signals for help.
3. Monitoring the gap, not just the score. Track the delta between your benchmark accuracy and your production output distribution. When they diverge, something in the environment changed, and your model's accuracy number is now fictional. The gap is your most important metric, and most teams don't measure it.
What we learned the hard way: the teams that succeed long-term with AI deployments aren't the ones with the best models. They're the ones who built systems where model failure is cheap to detect, quick to route around, and informative enough to fix. Accuracy is a model property. Reliability is a system property. Optimizing the wrong one is the most expensive mistake you can make — because you won't notice until the system is already in production.
#AIDeployment #SystemReliability #MLOps
2
22
🚨 Downtime doesn’t wait for your team to wake up.
Read More 👉 resources.callgoose.com/blog…
#CallgooseSQIBS #SRE #IncidentResponse #Downtime #Automation #ITAutomation #DevOps #ITOperations #Monitoring #Alerting #MTTR #MTTD #SystemReliability #CloudOps #Observability

4
5
21

May 6
Confidence is built through consistent system reliability.
Continuous monitoring ensures stable and dependable performance.
UseExchange.com
#UseExchange #CEX #SystemReliability #SecureTrading

3
13
66
2,225
📊 You’re tracking uptime… but are you tracking what actually matters?
Read More 👉 resources.callgoose.com/blog…
#MTTR #MTTD #MTTF #MTBF #SystemReliability #DevOps #SRE #ITOperations #Automation #ITAutomation #Monitoring #Alerting #IncidentManagement #WorkflowAutomation

4
5
18

Outages don’t start big, they start at one weak point.
That’s the risk of single-point dependencies.
Nobus Cloud ensures redundancy across your system.
👉 nobus.io/contact
#cloudinfrastructure
#nobuscloud
#systemreliability
#africatech

1
3
46

Apr 8
Higher density targets impose proportional demands on thermal removal capacity and distribution discipline. Performance scaling is not achieved through load increase alone—it requires infrastructure alignment across every operational layer. ⚙️
Ambition without architecture introduces instability at scale. Systems that push density without corresponding thermal strategy encounter inefficiencies, throttling, and reduced hardware lifespan. ⚠️
Where are you pushing your site? Density expansion must remain synchronized with cooling capacity, airflow efficiency, and power distribution balance. 🌡️
BiXBiT USA engineers high-density environments with integrated thermal and power architecture—ensuring stability as computational demand intensifies. 🔋
⚡ Engineer for your density goal → info@BiXBiTUSA.io
#BiXBiTUSA #HighDensityComputing #ThermalManagement #DataCenterDesign #InfrastructureEngineering #CoolingSystems #PowerDistribution #ComputePerformance #OperationalStability #SystemReliability #EnergyEfficiency #IndustrialEngineering #ScalableInfrastructure #HardwareOptimization #MiningInfrastructure #HeatManagement #AirflowDesign #LoadBalancing #InfrastructureIQ #PerformanceEngineering #ThermalDynamics #DataCenterCooling #SystemArchitecture #EfficiencyEngineering #ComputeScaling

1
2
18
Apr 7
Hardware efficiency gains are merely theoretical until validated by the environment. While new ASIC models offer improved benchmarks, their practical utility is governed by the structural integrity of the facility. 🧠
Sustained performance is achieved through the convergence of:
✅ Thermal stability
✅ Electrical integrity
✅ Continuous uptime
✅ Monitoring discipline
Infrastructure is the definitive layer that translates potential into performance. Engineering defines the boundary between a spec sheet and a stable, high-output operation. 🏗️
🌐 Build the layer that lasts → info@BiXBiTUSA.io
#BiXBiTUSA #MiningInfrastructure #EngineeringMatters #OperationalExcellence #CryptoScale #HighDensityComputing #DataCenterDesign #PowerDistribution #ThermalManagement #PerformanceEngineering #SystemArchitecture #IndustrialEngineering #InfrastructureResilience #ScalableSystems #HardwareOptimization #ASICMining #ComputePerformance #TechInfrastructure #OperationalStability #EnergyOptimization #DigitalInfrastructure #FutureCompute #ReliabilityEngineering #InfrastructureIQ #SystemReliability

1
2
13
Apr 3
New ASIC releases capture attention, but performance is not defined at the chip level alone. Cooling systems, power distribution, and control architecture ultimately determine whether that hardware operates at its intended capacity. 🧠
Infrastructure is the governing layer—translating theoretical performance into stable, sustained output under real-world conditions. Without alignment, even advanced hardware operates below its potential. 🔋
The most effective infrastructure is not visible in operation. It delivers consistency, absorbs variability, and maintains performance without disruption. And it should remain that way. 🧩
🏗️ Build the layer that lasts → info@BiXBiTUSA.io
#BiXBiTUSA #MiningInfrastructure #CryptoCycle #EngineeringMatters #InfrastructureIQ #ThermalManagement #PowerDistribution #HighDensityComputing #DataCenterDesign #SystemReliability #OperationalStability #EnergyOptimization #ComputePerformance #IndustrialEngineering #InfrastructureResilience #ScalableSystems #TechInfrastructure #HardwareOptimization #SystemArchitecture #PerformanceEngineering

3
8



Mar 26
Reliable systems must maintain performance even under continuous transaction demand
Many networks show strong performance in testing but degrade in real usage
#Tectum’s layered architecture separates processing, distribution, and storage, allowing the system to handle load without impacting verification quality
This supports consistent performance in high-volume environments
#TET #SystemReliability #DistributedSystems #Throughput #Fintech

3
3
1,080

📏 Daily operations stay dependable with unified protocols 🚀.
🌐 Riscoin relies on clear frameworks for orderly performance 📊.
🔄 Defined procedures reduce variation and support steady workflow 💡.
#Riscoin #OperationalStandards #WorkflowConsistency #SystemReliability

25,773

Mar 21
🍀 Confidence grows when systems operate with clarity.
🌐 At DSJEX, consistent mechanisms support stable daily operations.
🔗 With BG strengthening the framework, the platform remains dependable.
#DSJEX #BG #SystemReliability #PlatformStability

25,804
Feb 27
Without real-time monitoring:
☑️ Flow imbalance goes undetected
☑️ Pumps fail unnoticed
☑️ Breaker stress escalates
☑️ Temperature drift accumulates
When visibility is delayed, by the time alarms trigger, the issue has already compounded. ⚠️
BiXBiT AMS provides structured, system-wide visibility that enables consistent, real-time operational awareness. ⏱️
Data operates as preventative infrastructure, supporting early intervention and long-term system stability. 📡
📊 Request AMS demo → info@BiXBiTUSA.io
#BiXBiTUSA #SmartMining #TelemetrySystems #OperationalControl #InfrastructureEngineering #IndustrialMonitoring #SystemReliability #PredictiveMaintenance #EngineeringAnalytics #ProcessOptimization #IndustrialAutomation #DataDrivenOperations #PerformanceEngineering #RiskManagement #TechnicalInfrastructure #OperationalStability #MonitoringSystems #IndustrialEfficiency #EngineeringSystems #TechOperations

1
3
14