ひろけん retweeted

2 Dec 2025
VCWorld: A Biological World Model for Virtual Cell Simulation
1. VCWorld introduces a novel cell-level white-box simulator that integrates structured biological knowledge with large language models (LLMs) to predict cellular responses to perturbations, offering a transparent and interpretable alternative to traditional black-box models.
2. The core innovation lies in its biological world model, which leverages signaling pathways, protein-protein interactions, and gene regulatory networks to enhance data efficiency and generalization, even with limited training data.
3. VCWorld achieves state-of-the-art performance in predicting differential expression and directional changes in gene expression, outperforming existing models while providing mechanistic explanations aligned with biological principles.
4. The study introduces GeneTAK, a new benchmark derived from the Tahoe-100M dataset, reframing cell-drug observations into gene-centric perturbation responses to enable more granular modeling of drug effects.
5. VCWorld's reasoning process is grounded in a comprehensive biological knowledge graph, ensuring that predictions are not only accurate but also verifiable through step-by-step mechanistic hypotheses.
6. The model demonstrates robustness in few-shot learning scenarios, making it particularly valuable for predicting responses to novel perturbations not present in the training data.
7. VCWorld's design emphasizes interpretability, allowing biologists to trace the reasoning behind each prediction, which is crucial for scientific discovery and experimental design.
📜Paper: arxiv.org/abs/2512.00306v1
#VirtualCellModeling #BiologicalWorldModel #LLMs #PerturbationPrediction #InterpretableAI #ComputationalBiology

1
9
18
1,552

Jun 14
VCWorld:仮想細胞シミュレーションのための生物学的世界モデル
仮想細胞モデリングは、摂動に対する細胞応答を予測することを目的としています。
arxiv.org/abs/2512.00306
9
Aligning LLMs with Biomedical Knowledge using Balanced Fine-Tuning
1. The paper argues that “low-confidence tokens” mean something different in biomedicine: they often form dense contiguous runs that encode rare entities (genes/mutations/pathway nodes) and mechanistic causal chains—i.e., epistemic uncertainty (knowledge gaps)—rather than the sparse stylistic alternatives (aleatoric uncertainty) common in general text.
2. This observation motivates Balanced Fine-Tuning (BFT), a dual-scale post-training objective designed to keep learning signal on knowledge-dense uncertainty while still stabilizing optimization—addressing a key failure mode where Dynamic Fine-Tuning (DFT) down-weights exactly the biomedical tokens that matter.
3. The authors operationalize “dense epistemic uncertainty” with a teacher-forcing diagnostic: compute per-token confidence, slide a 256-token window, and classify windows by (a) fraction of low-confidence tokens and (b) longest contiguous low-confidence run. Sparse-low windows (Group A) tend to be stylistic; dense-low windows (Group B) are enriched for biomedical entities and causal connectives.
4. BFT token-level innovation: replace DFT’s absolute confidence weighting with group-normalized reweighting using a local context confidence (mean confidence in a g=256 sliding window). Each token weight is proportional to cb,t / (Clocb,t ε), clipped to [0,1] and stop-gradient detached—suppressing isolated low-confidence outliers while preserving gradients in globally hard (dense-low) biomedical spans.
5. BFT sample-level innovation: reallocate learning across sequences using a bounded hard-sample coefficient derived from the minimum local context confidence within the sequence. This explicitly shifts optimization budget toward samples containing the hardest knowledge-dense regions, complementing token-level gating.
6. Across tasks (medical evaluation, biological reasoning, sparse-reward RL, and representation learning), BFT provides more consistent gains than SFT and DFT under the same training recipe and model family (DeepSeek-R1-Distill 14B/32B/70B), suggesting the uncertainty-aware loss design transfers across biomedical settings.
7. Backbone replacement results in agentic biology pipelines: swapping closed-source backbones with a BFT-aligned 70B model improves GeneAgent biological process reasoning and matches/exceeds the original VCWorld Gemini-2.5-Flash backbone on chemical perturbation reasoning (VCWorld average accuracy reported at 0.70 for BFT 70B vs 0.68 for Gemini-2.5-Flash; SFT/DFT replacements lag behind).
8. Sparse-reward RL compatibility is a key takeaway: after subsequent GRPO on Tahoe-100M with sparse binary rewards, SFT and DFT degrade, but all BFT variants improve (e.g., BFT 70B from 0.70 to 0.74 average on held-out VCWorld cell lines). The paper links this to richer mechanistic traces (more entities, more causal connectives, longer responses), which increases “credit assignment surface area” under sparse rewards.
9. Beyond generation, BFT aims to narrow the generative–discriminative split in computational biology: BFT-generated biomedical profile texts (encoded with a text embedding model) yield stronger gene- and cell-level representations, improving gene property prediction and gene interaction tasks, cell clustering, multimodal integration (scIB), and perturbation response prediction—sometimes rivaling or outperforming specialized biology foundation models in reported settings.
10. Practical considerations: BFT introduces only one main hyperparameter (window size g, default 256) and is reported robust across a broad range; it also shows reduced hidden preference transfer in a synthetic-data “subliminal learning” style safety test compared to SFT, staying closer to the base model’s behavior.
💻Code: github.com/TencentAILabHealt…
📜Paper: arxiv.org/abs/2511.21075
#LLM #BioNLP #ComputationalBiology #BiomedicalAI #FineTuning #ReinforcementLearning #SingleCell #PerturbationBiology #RepresentationLearning #AIAlignment

1
14
1,491

Feb 23
𝐁𝐢𝐠 𝐜𝐨𝐧𝐠𝐫𝐚𝐭𝐮𝐥𝐚𝐭𝐢𝐨𝐧𝐬 𝐭𝐨 𝐇𝐞𝐢𝐳𝐞𝐧 𝐨𝐧 𝐬𝐞𝐜𝐮𝐫𝐢𝐧𝐠 𝐚 𝐝𝐞𝐚𝐥 𝐨𝐧 𝐒𝐡𝐚𝐫𝐤 𝐓𝐚𝐧𝐤 𝐈𝐧𝐝𝐢𝐚! 🚀
Kudos to the founders — Aman Arora, Abhilasha Singh, and Nijansh Verma — for building with clarity, speed, and ambition.
We’re incredibly proud to back them early — Titan Capital invested in Heizen’s seed round, and it’s exciting to see their journey now unfold at @sharktankindia.
𝐖𝐡𝐚𝐭 𝐢𝐬 𝐇𝐞𝐢𝐳𝐞𝐧?
@HeizenOfficial helps companies ship production-grade products in days, not months by combining AI agents with the top 1% engineers.
They operate as an on-demand tech team — delivering internal tools and product features in weekly sprints — enabling startups and enterprises to move fast, stay lean, and out-execute the competition.
𝐖𝐡𝐲 𝐖𝐞 𝐈𝐧𝐯𝐞𝐬𝐭𝐞𝐝
Heizen is building the kind of execution engine AI-native companies truly need. Their approach is fast, focused, and lean. The founding team has a rare combination of enterprise insight and a builder’s mindset. The IT services industry is on the brink of a transformation, and Heizen is leading the charge with its innovative AI-led delivery model.
Well deserved. Onwards and upward 🚀
#SharktankIndia #TitanCapitalBacked #VCWorld

1
8
570

2 Dec 2025
VCWorld: A Biological World Model for Virtual Cell Simulation. arxiv.org/abs/2512.00306
2
42

Yep. There’s a cadre of isolationists in Trumpworld led by quasi Nazi Tucker Carlson that’s been influencing VCworld like Elon and what led to Vance being VP and Don Jr becoming a Vatnik.
1 May 2025

Laura Loomer victorious.
1
230

2 Nov 2024
Startups these days: spending more time⏰ figuring out which VC to pitch than actually pitching… only to get ghosted by half of them anyway 😂 #Startuplife #VCworld
2
65

27 Sep 2024
One of the truths about “VCWorld” is the belief that it can only be done one way.
What you have built is amazing and any other entrepreneur would be jealous. What that person does is place bets. Bets they know will mostly miss, but they hope that one or two hit big. Two completely different games.
1
5
1,373

🚨 Carta's unsolicited sales scandal raises big questions about #StartupEthics and #DataPrivacy.
CEO says sorry, but is it enough? #TechControversy #VCWorld
techzi.co/vc/carta-accused-o…
2
1
3
54

2 Jan 2024
Happy new year 2024 everyone, keep building!
Major Learnings From 2023 – VCWorld vcworld.in/2024/01/02/major-…
5
543
The current reactionary vibe in some segments of VCworld is out of frustration that the masses aren’t adopting the nerd’s (not so) new toys
1
3
357
Segments of VCworld truly are infested with cranks
13 Nov 2023

Absolutely disgusting genocidal rhetoric from someone who apparently works in the VC world.
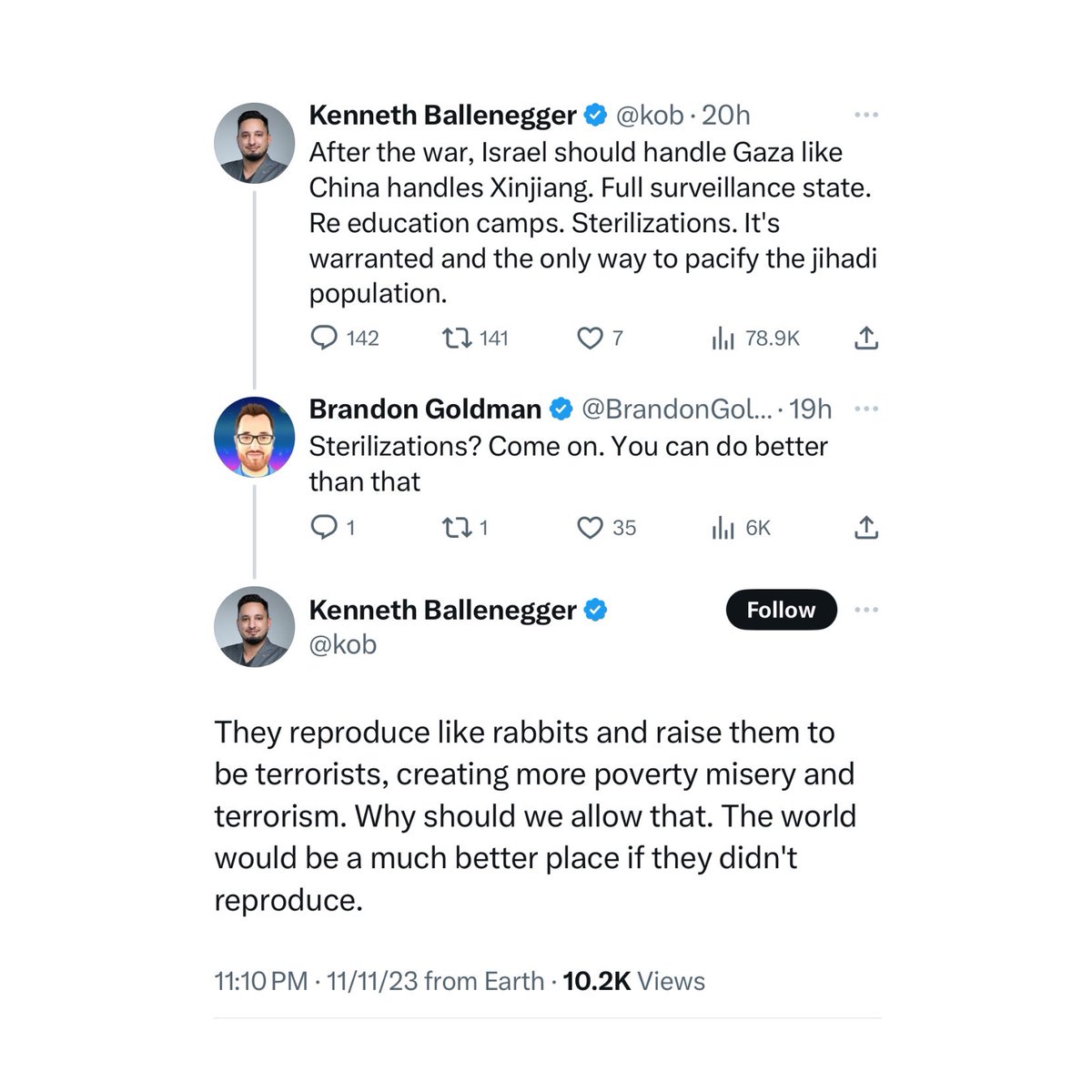
1
2
2
564
Wired changed because the worlf moved on from a world where tech CEOs were feted for what they could do in the future instead of being questioned abt their effects now and yet VCworld can’t accept that change even if it’s been over half a decade in the making.

Wired used to be accelerationist and now it is massively decel
Time to rebuild the next Wired
3
219
This vindicates what certain ppl have said for years abt what was going on between Trump and the Russians and now suddenly Epstein is somehow involved too? Plus the involvement of certain VCworld individuals is notable too
archive.ph/2023.08.30-093801…
1
4
313
Think it’s deeper than that. If Elon’s as much of a dick to his own kids as he is to his workers then no wonder his daughter became trans and later wanted nothing to do with him. Also it’s quite telling he was radicalized under lockdown too like far too many in VCworld
31 Aug 2023

Elon Musk’s right-wing inclinations “were partly triggered” after Vivian Jenna Wilson, his then-16-year-old child, came out to her aunt.
trib.al/uXeM49k
4
622
Elon has gone full natcon because segments of VCworld have teamed up with the enemy and idiot contrarians to undermine a west that increasingly recognizes that we can’t have democracy without a more regulated social internet
30 Aug 2023

. @elonmusk
The decline of the Hungarian population is due to the exit of mainly young people leaving their beautiful country… because it’s badly governed by autocrat Victor Orbán !
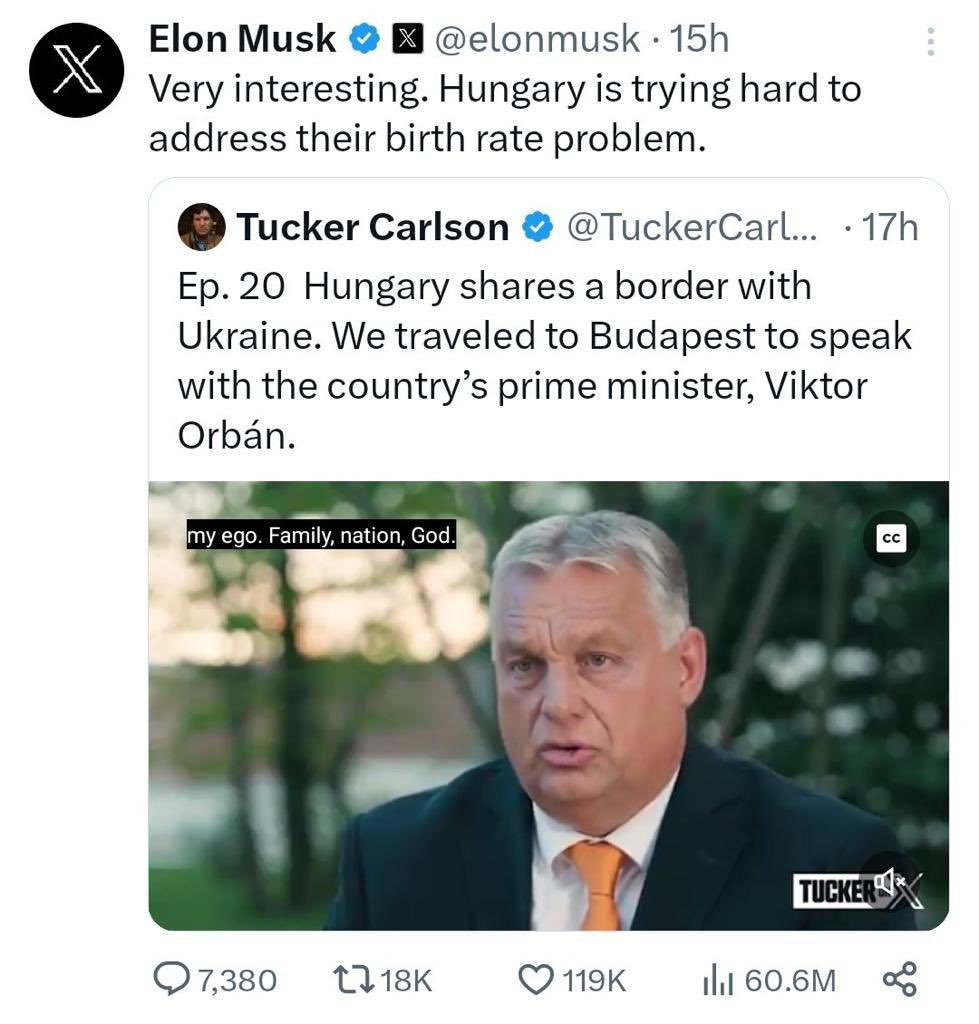
2
367
No matter what ppl like Taibbi and Greenwald say the truth is the truth and there's no doubt the Kremlin has some connections in business and in VCworld.

Russian intelligence is operating a systematic program to launder pro-Kremlin propaganda through private relationships between Russian operatives and unwitting US and Western targets, according to newly declassified US intelligence cnn.it/3KYPciZ
5
360

18 Jul 2023
For #EEI30years celebration we activated many TOP events:
👉The @Esade #EESummit to connect our community
👉#PromotingEntrepreneurship to connect founders with researchers
👉#VCseries to introduce founders into the #VCworld
👉#eWorksBootcamp23 to kickoff our #eWorksAccelerator

2
3
386
It's sad to watch a certain segment of VCworld completely melt down so publicly
111