
Jun 12
📢GeroScience #CallForPapers focusing on neurosurgical and neurological perspectives on aging and age-related diseases.
Read more in the comments and submit 📩 at the link⬇️
springer.com/journal/11357/u…
#neurosurgicalinterventions #cnsdisorders #aging #NeurodegenerativeDisorders #TraumaticBrainInjury #cognitivefunction

1
2
1
430

Jun 10
Say goodbye to brain fog and hello to enhanced mental clarity with Best Naturals Acetyl L-Carnitine Premium Powder! 🧠✨
#BestNaturals #AcetylLCarnitine #PremiumPowder #BrainHealth #NaturalEnergy #MentalFocus #CognitiveFunction
shopbestnaturals.com/product…

1
1
8

🤯 Oral storytelling is the secret to unlocking cognitive reserve in older adults, boosting brain health like never before #BrainHealth #AgingWell #CognitiveFunction
Jun 9

The best “memory game” for older adults is not an app, it is telling the same stories out loud.
4

Jun 9
Vitamin D is crucial for your brain! It regenerates neurons, enhances connections, and repairs nerve cells. 👉 Watch the full episode here: drcolbert.com/13-of-12-know-…
#VitaminD #BrainHealth #Neurogenesis #CognitiveFunction #NerveRepair
1
1
46

How to Improve Memory Power ..?
#memory #tips #students #education #latest #news #viralvídeo #tricks #MemoryImprovement #MemoryBoost #brainhealth #CognitiveFunction #MentalFitness #MemoryTips #BrainPower
1
11

🗝️ takeaways:
🧠 Prior MI was linked to accelerated decline in #CognitiveFunction
💔 Decline occurred whether participants were aware of the history of MI or not
@StrokeAHA_ASA
vist.ly/54g7g
1
3
236

New study: Children in more polluted areas of Tehran showed significantly lower concentration scores- even after adjusting for 10 confounders. Air pollution isn't just a lung disease risk. It's associated with how well your child can pay attention in class.
#AirPollution #cognitivefunction
10
8
311

Are You Letting AI Do Too Much of Your Thinking? cysecurity.news/2026/05/are-… #AIChatbot #ArtificialIntelligence #cognitivefunction
1
357

May 1
Repost from my @dailyflash.tv show segment that aired on national tv yesterday.
•
Two studies reveal exercise's power: Moderate to low intensity, just twice a week, significantly cuts dementia risk, boosts brain function, memory, and focus. One study showed a 41% reduction! #DementiaPrevention #BrainHealth #ExerciseBenefits #CognitiveFunction #HealthyAging #FitnessFacts #Neuroscience #WellnessTips #StaySharp #BritishJournalOfSportsMedicine
1
228

Apr 24
❤️🔥 LBCT #HRS2026
Read the ALONE-AF substudy here to understand how discontinuation of #anticoagulation 🩸might affect #cognitivefunction 🧠
heartrhythmjournal.com/artic…
2
6
521

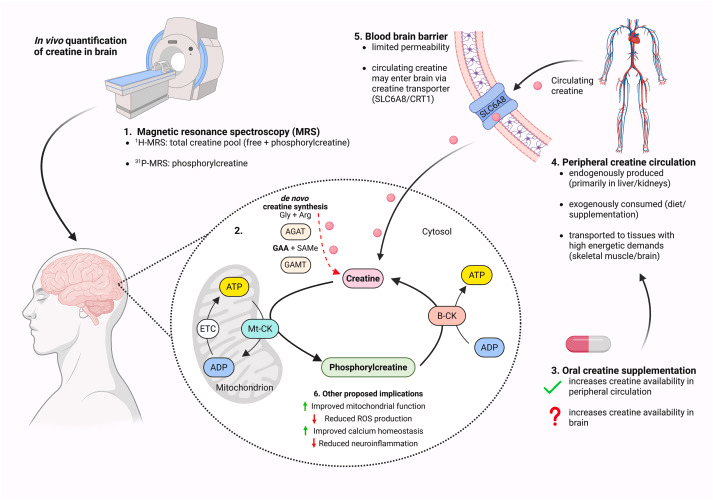
Creatine is not just for muscles — it acts like a backup battery for the brain.
Especially useful under stress conditions !
🔗sciencedirect.com/science/ar…
#creatine #brainhealth #cognitivefunction
2
8
23
1,856

Apr 15
I built a Darwinian simulator where AI agents can die, reproduce and compete for survival.
Inspired by @karpathy's nanochat, I called it
>nanolife
(find in repo: nanothrones, nanomatrix, nanorings, etc)
Runs are cheap enough to treat as experiments: $0.50–$2 on Groq. Up to a $5 on frontier models, depending on ticks and population.
It's a minimalist implementation, built on just 7 primitives: scarcity, reputation, environmental harshness, heredity, memory compression, local observation, world log.
Unlike heavier multi-agent stacks with orchestration frameworks, retrieval, and embeddings, nanolife is a minimal harness for LLM-driven artificial life and social simulation in a small, readable codebase.
You set API keys, run one module, and watch dozens of agents tick in parallel in the terminal. When the run ends you get charts, a social graph, and an LLM-written academic report.
The core loop is on the order of ~350 lines in engine.py and is built to stay hackable:
- Parallel cognition loop (observe, act, log, resource drain, births/deaths, log compression)
- Maslow hierarchy in the prompt
- Lamarck-inspired inheritance to offspring
- Postmortem pipeline
- Runs on Groq by default or OpenRouter
- Benchmarking models is possible
- Modular: you can swap CognitiveFunction, CompressionFunction, SpreadFunction, or Scenario without rewriting the engine
13 Oct 2025

Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI.
It weighs ~8,000 lines of imo quite clean code to:
- Train the tokenizer using a new Rust implementation
- Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics
- Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use.
- SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval)
- RL the model optionally on GSM8K with "GRPO"
- Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI.
- Write a single markdown report card, summarizing and gamifying the whole thing.
Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc.
My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved.
Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
4
1
25
2,804

Apr 13
I’ve lived this one.
Back in 2016… I had what I can only describe as symptoms of moderately severe dementia.
Memory issues.
Struggling to focus.
Things just weren’t connecting the way they should.
And it was scary.
At the time, I wasn’t trying to “fix” that.
I had started a ketogenic diet to help manage symptoms of narcolepsy.
But what I didn’t expect…
was how much my cognitive function began to improve.
The fog started to lift.
Things became clearer.
I felt like myself again.
That’s when I realized—
Food is medicine.
Food quality matters.
And the role of nutrition in metabolic and autoimmune health
was being pushed aside.
But that’s starting to change.
More attention is being given to whole foods
in both disease management and prevention.
Because for many,
the transition to whole foods
is where their health begins to improve. #wholefoods #brainhealth #cognitivefunction
1
2
4
117
Apr 9
📢GeroScience #CallForPapers focusing on neurosurgical and neurological perspectives on aging and age-related diseases.
Read more in the comments and submit 📩 at the link⬇️
springer.com/journal/11357/u…
#neurosurgicalinterventions #cnsdisorders #aging #NeurodegenerativeDisorders #TraumaticBrainInjury #cognitivefunction

1
2
2
293

#CreatineForHealth
Creatine is well-known for boosting performance and recovery, but its effects on sleep and cognitive function in healthy, active individuals have remained less explored.
#Creatine #SleepQuality #CognitiveFunction #SportsNutrition #Recovery

1
2
8
295

Mar 21
Blood Sugar : ટાઇપ 1 ડાયાબિટીસના દર્દીઓમાં યાદશક્તિ નબળી પડવાનું જોખમ, સંશોધન શું કહે છે...
#BrainHealth #CognitiveFunction #ChildrenDiabetes #YouthDiabetes #BloodSugar
tv9gujarati.com/photo-galler…
196

Mar 18
தேர்வின் போது தண்ணீர் குடிக்கும் மாணவர்கள் அதிக மார்க் எடுக்கிறார்கள் என ஆய்வில் தகவல்!
#ExamHall #DrinkingWater #Marks #CognitiveFunction #Offbeat #Oneindia #OneindiaTamil

2
23
184
3,388

After our session at #EAU26 I met with Jeremy Bellaiche from shuf.ai to integrate the main messages on physical exercise and cognitive performance in a short #podcast. Very nice experience to start with and hope to work together on more topics in the future! Great tool for MDs to generate informative and individualized podcasts @jeremy02766919 shuf.ai/
#PhysicalExercise #CognitiveFunction #Exercisumab #BrainFertilizer @uroweb
👉shuf.ai/episode-player/06409…


After a short exercise session this morning, I was very honored to join a great panel on the topic of physician‘s wellbeing and sustainable performance at #EAU26 and talk about the significant positive impact of physical exercise on #cognitive function and resilience - beyond all well known impact on life span, health span, cancer and chronic diseases #PhysicalExercise #BrainFertilizer #Exercisumab @Uroweb @UroDoco @drphil_urology @carme_mir1 @JLVasquez82 #JasonHowlett @urotoday



5
15
1,655

Busting a common health myth! 🧠
While puzzles and brain games keep our minds sharp, overall brain health is a complex equation.
It's a combination of physical activity, vascular health, sleep, and education.
Let's focus on the whole picture!
#MentalStimulation #CognitiveFunction
#HealthyAging

8
468

Feb 26
Congratulations to Dorothy Farrar Edwards, PhD, the 2026 recipient of our Dr. Carolyn Baum Cognitive Function in Daily Life Mentor Award! @uwmadot
Learn more: aotf.org/Grants/Dr-Carolyn-B…
#OTResearch #OccupationalTherapy #CognitiveFunction #MentorAward #ResearchRecognition

4
62