
Jun 9
RIWI and TGOA Launch Global Data Impact Index Revealing Enterprise Data Maturity Gap
Full Story: nfne.ws/300721
#RIWIdata $RIWI.CA #RIWI.V #RWCRF #dataimpact #datamaturity #RIWI #Internet #InternetTechnology #Technology #OTC #OTCMarkets #OTCStocks #SmallCaps #TSXV
32

Happy Birthday to @tobioladimeji_
The mastermind behind @DatafellowsInfo — thank you for your selfless impact and for building a community that empowers many.
Here’s to more wins.
#DataFellows #HappyBirthday #dataimpact

1
2
8
68

Apr 30
Not Every Fever is Malaria - Here's a story I worked on about how data is saving lives in Kogi State lnkd.in/esRw3Y-u
#MalariaElimination #PublicHealth #DataImpact #KogiState #GlobalHealth
Michael Jackson Teni Davido #MichaelJackson


1
2
42

Apr 14
¡Conoce a nuestro Senior Data Scientist! 👨💻
Cristian Camilo Chica se une al equipo como Senior Data Scientist para llevar nuestro producto al siguiente nivel. Con experiencia en instituciones de talla mundial, Cristian viene a demostrar que los problemas más difíciles se resuelven con matemáticas y propósito. 🚀
¡Bienvenido al #TeamDapper!
#Product #DataImpact #DapperTeam #DapperBackground
3
147

24 Jul 2025
Resources for health are often scarce. That’s where health economists come in. Using data to analyze the cost-effectiveness of policies, they provide critical information for decision-makers.
As part of the @BloombergDotOrg #Data4Health Initiative, and in partnership with @VUMChealth and the @CDCFound, we were proud to support the work of 5 brilliant health economists at the @healtheconomics 2025 Congress. At this global convening for health economists, they presented analyses on topics ranging from the economic value of alcohol cessation policies in the Philippines to the cost-effectiveness of AI-based chest X-rays in India. Congratulations to Samuel Abera, Lawrence Mwenge, Yasiini Nuwamanya, Andrea Margreth Ora-Corachea, and Dr. Samraj Sahay for their critical research.
Together with Vanderbilt, we also hosted a pre-Congress workshop on Open Source Approaches to Economic Evaluation in Low and Middle-Income Country Contexts, introducing participants to Amua, an open-source tool for decision modeling created by Zachary Ward at Harvard which enables researchers and practitioners to rigorously analyze the value of health investments in their contexts
#InformingPolicyImprovingHealth. #DataImpact
↪️ Check out the workshop tools here: ihea2025-vanderbilt.netlify.…




1
6
454

The @OpenledgerHQ Data Attribution Pipeline isn’t just a step forward it’s a whole new paradigm for how data is valued in AI.
For too long, data contributors have been invisible feeding models that go on to power billion-dollar systems, with zero traceability, zero credit, and zero upside.
That ends here., and that's where @OpenledgerHQ steps in!
OpenLedger’s Attribution Pipeline flips the script by introducing Proof of Attribution, OpenLedger introduces the Data Attribution Pipeline, a fully decentralized, verifiable system that ensures every dataset used to train an AI model is:
1. Recorded on-chain
2. Audited for impact
3. Rewarded with precision
4. Protected from abuse
It aligns incentives, enforces transparency, and finally gives contributors ownership of their influence.
How It Works: The 5-Step Data Attribution Pipeline
Each step in this pipeline builds toward one goal: making data attribution provable, rewarded, and secure.
Step 1: Sharing Data; Provenance from Day One
The process begins when contributors upload specialized datasets tailored to specific use cases e.g., medical records (de-identified), financial time-series, scientific literature, or language-specific corpora.
Each dataset submission includes metadata:
1. Purpose of the dataset
2. Intended use domain
3. Format and licensing terms
4. contributor identity (on-chain)
Once submitted, the data is:
1. Cryptographically hashed
2. Time-stamped
3. Stored in decentralized storage (e.g., IPFS, Arweave)
4. Registered on-chain for traceability.
Result: The origin of every dataset is irrefutable. This is data with provenance, permanence, and auditability: no more invisible contributions.
Step 2: Measuring DataImpact Quantifying Value with Math
Not all data holds equal weight in model training. So how do you fairly measure its impact?
@OpenledgerHQ uses a dual-evaluation system:
1. Feature-Level Influence Analysis
Tracks how much the dataset shapes or enhances model learning.
Methods include SHAP values, gradient attribution, and sensitivity analysis.
Answers the question: "How much did this data change the model’s behavior?"
2. Contributor Reputation Scoring
Not all data is equal. OpenLedger scores it using:
Feature-Level Influence (e.g., SHAP values, gradients).
Contributor Reputation (historical quality, slashing record)
Combined, these form an Influence Score the backbone of fair rewards.
This step brings fairness to the reward economy.
Step 3: Training & Attribution; A Transparent Learning Process
Once training begins, OpenLedger:
1. Every cycle is logged
2. Dataset impact is tracked live
3. Model checkpoints include attribution data
For every batch & epoch of model training:
The Influence Score is updated in real time, on-chain audit log is generated
Model checkpoints include attribution metadata
This creates a transparent, verifiable training ledger. a kind of on-chain "flight recorder" that shows exactly how your data helped shape the model.
Step 4: Rewarding Contributors;
After training completes, the pipeline calculates reward allocations for each contributor.
Token rewards are distributed based on:
Final Influence Scores, Contributor reputation boosts, Bonus multipliers for rare/novel datasets
Payouts are automated, on-chain, and irreversible
Contributors can stake their rewards or withdraw, depending on their strategy.
Better data = better models = better rewards. It’s the clearest incentive loop in AI.
Step 5: Handling Low-Quality or Harmful Data, Defense by Design
To safeguard model integrity, OpenLedger introduces slashing mechanics:
Low-quality or harmful data gets slashed via:
1. Stake penalties
2. Reputation throttling
3. (Optional) Peer-audited validation pools
> Only impactful, ethical data makes the cut, bad actors lose their edge.
This isn’t some “maybe one day” idea. It’s a working system that aligns incentives, enforces transparency, and finally lets data contributors own their impact.
Gledger

1
3
126

🧡 OpnUp Octo 🐙💉 #ProofOfAttribution is a game changer on #OpenLedger! See how your data shapes decisions in real-time. Transparency at its best! ✨
#Blockchain #DataImpact #Web3 #DeFi
2
13

9 Apr 2025
SIT-40 is underway in Fukuoka, Japan! Topics include:
#GreenhouseGases
#Biodiversity
#DataImpact
#EW4All
#SDGs
Hosted by @JAXA_en

3
7
1,157
11 Feb 2025
🇿🇼 Zimbabwe held its first-ever #DataToPolicy Policy Forum in partnership with the @BloombergDotOrg #Data4Health Initiative, @zimstat, the Ministry of Health, @CivilRegZim, and the @mwacsmed – a first step to turning data into action. #DataImpact
Participants produced policy briefs on:
💡Maternal mortality
💡Costly cancer diagnoses and treatment
💡Unregistered rural deaths
💡Mental health issues associated with gender-based violence
📖 Check out this article from @healthtimeszim to find out more: vitalstrat.org/4gCRdyq

2
8
450

19 Jan 2025
$DAG - where data meets blockchain for real-world impact $DAG = America's Blockchain #DataImpact #RWA #RWAWARS

1
9
63
1,308

30 Dec 2024
Revised jobs, revised policies?
Will these numbers influence future economic policies?
The stakes for getting it right have never been higher. 🧮
#EconomicPolicy #JobRevisions #DataImpact #StimulusEffect #EconomicIntegrity
20 Dec 2024

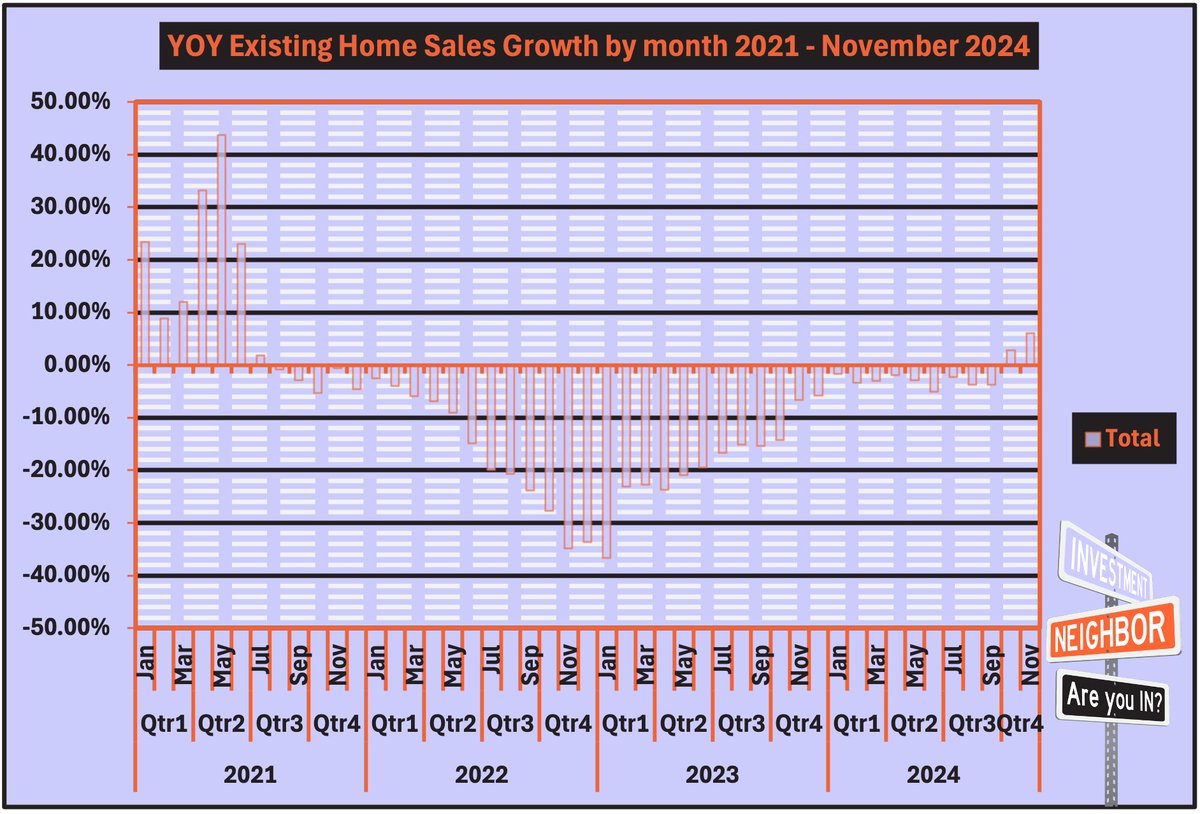
😳Decline Dominates (2022-2024)📉
Over the last three years, 94% of months have reported YoY declines in existing #homesales 👀
Remember that one broker who claimed ‘9 properties sold in 6 weeks business as usual!”?
The data says otherwise. 😅
1
4
20
18 Dec 2024
Missed the UN World Data Forum last month? Catch up with our blog recap.
We’ve rounded up some of our favorite moments from the conference, including presentations from our incredible partners at @BloombergDotOrg and @InfanciaEc.
Take a look at some highlight videos and photos, and read more here: vitalstrat.org/3DjtlSh
Thank you to @DANE_Colombia and @UNStats for hosting an inspiring convening and giving us the opportunity to connect with colleagues from around the world to #CommitToData.
#DataforHealth #DataImpact #CRVS

2
7
274
11 Nov 2024
💡Last week in Istanbul, government officials from seven countries came together for a #DataToPolicy workshop to develop policy adoption plans for critical public health issues, particularly for women:
✔️ Hypertension in pregnancy in Ethiopia and Maharashtra, India
✔️ Emergency obstetric care in Zimbabwe
✔️ One Stop Centers for survivors of gender-based violence in Cambodia
✔️ Establishing Cameroon’s first national breast cancer policy
✔️Automating death registration in Kenya to enhance mortality data completeness
✔️ Online mental health screening for Quezon City government employees in the Philippines
With the support of the @BloombergDotOrg #Data4Health Initiative, teams returned home ready to create change. #DataImpact




2
211

9 Oct 2024
Being a data analyst, your most important job is to find solution for that business problem with data and convey it effectively to stakeholders.
Your job is not to make things complex so that you can call yourself expert data analyst, actually it is completely opposite of that.
The data analyst who can solve business problems ensuring easy and effective implementation of tools with efficient communication is the expert data analyst.
#DataAnalyst #BusinessSolutions #DataDriven #StakeholderManagement #DataAnalytics #DataAnalysis #BusinessIntelligence #DataCommunication #AnalyticsCommunity #TechSkills #BusinessStrategy #DataTools #DataInsights #ProblemSolving #AnalyticsCareer #TechIndustry #TechJobs #SQL #DataScience #DataStorytelling #DataOptimization #USTech #UKTech #EuropeTech #DataProfessionals #CareerGrowth #DataImpact

1
59

🌍 Absolutely 100% agree! Many people underestimate how much data can impact the environment. We are proud to partner with @storj and, as an storage aggregator, to implement additional providers on our platform in the future who are also interested in developing innovative and eco-friendly solutions. Hats off, and keep it up guys! 💚
#Sustainability #EcoFriendly #DataImpact #Innovation #Partnership #WeSendit #Storj #GreenTech #ClimateAction #DataStorage

Many leaders in media & entertainment don’t realize that a major threat to the environment is their data.☁️
Data is quickly becoming the largest contributor to carbon emissions. Find out more from @storj's latest blog 💡 hubs.li/Q02R-N0h0
#IBCBlog #sustainability

9
26
77
2,503

10 Sep 2024
Join @JensenWarwick and @profmarkreed as they discuss the far-reaching effects of data-intensive research in this #DataImpact blog post: buff.ly/45ZHmyK #ResearchImpact #SocialChange

4
6
682

2 Sep 2024
Happy New Month! Let's kick off September with a dose of inspiration from Susan Boyle's incredible data impact story. Her journey proves that even the smallest actions can make a big difference. #inspiration #dataimpact #spooday #spoodayconcept


3
19

30 Aug 2024
WORKSHOP:
Ifakara, partners host training on communicating data 📊
🎉 The @ifakarahealth, in partnership with Vital Strategies, hosted a groundbreaking workshop on science communication from August 27-29 in Arusha! 🌍🗣️ Participants from key government ministries and agencies dealing with vital statistics - @wizara_afyatz, #Tamisemi, @NBSTanzania & @RITATanzania - honed their skills in conveying critical health data to the public and media. 📰
>> ihi.or.tz/our-events/526/det……
>> #IFAKARAevents #PublicHealth #ScienceCommunication #DataImpact



5
13
1,073

24 Jul 2024
Check out this insightful clip from Keeping Up with Conspicuous where Conor and Lucy talk about the often-overlooked impact of data in our everyday lives.
We understand how crucial data management is and we're here to help.
#DataImpact #BusinessSuccess #DataDriven #Podcast
2
165
30 Jun 2024
Who benefited from data-driven impact? 🌍 This study by @fasttrackimpact and @profmarkreed highlights the beneficiaries of research data, from policymakers to industry leaders.🔗 zenodo.org/record/4013924
#Research #DataImpact #ScienceCommunication #FastTrackImpact

7
5
900