
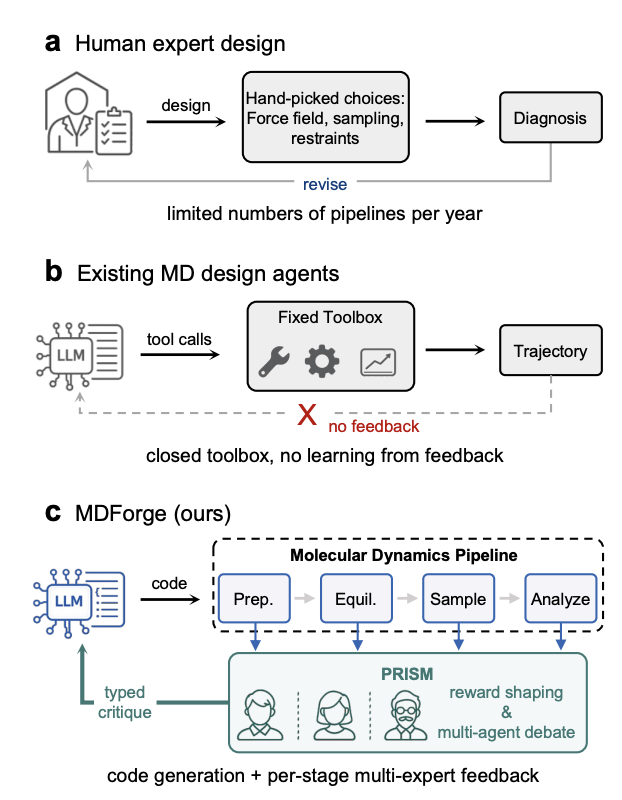
MDForge: Agentic Molecular Dynamics Pipeline Design under Sparse Simulator Feedback
1 MDForge is an LLM agent that autonomously designs full molecular dynamics (MD) pipelines as open-ended executable code, then improves them online from sparse, expensive simulator feedback (each trial can cost GPU-hours).
2 The key technical idea is PRISM (Process-Reward Interpretation via Subsystem Mediation): it turns a single terminal reward into dense, actionable signals by (a) extracting structured per-stage diagnostics across the MD pipeline (Prep, Equilibration, Production, Analysis) and (b) converting those diagnostics into typed critiques.
3 Instead of a fixed tool-calling “MD toolbox”, MDForge’s action space is program synthesis: the agent can compose whatever workflow the system demands (force-field setup, restraints, sampling protocol, estimators, guards, etc.), closer to what human experts actually do.
4 PRISM’s critique is produced by a multi-agent panel of physics specialists with non-overlapping jurisdictions: Force Field, Sampling, and Analysis. They debate in two rounds with cross-visibility, then an aggregator outputs a single typed critique that names the failing subsystem and the concrete edit to apply.
5 A reputation-weighting loop adjusts how much each specialist influences the final critique, based on whether their pre-execution predictions match post-execution evidence. This aims to downweight consistently miscalibrated “experts” within a task.
6 On SAMPL host–guest binding free-energy benchmarks (CB[7], OAH, CBClip), MDForge produced runnable pipelines reliably (5/5 successful trials per host) and improved held-out ranking performance versus verbal-RL baselines without PRISM. Example held-out Kendall tau: CB[7] 0.56 and CBClip 0.47, compared to 0.24 and 0.20 for a trial-level feedback baseline.
7 Ablations suggest both components matter: removing stage diagnostics caused unstable learning (the agent can’t localize what broke and may discard good pipelines), while removing multi-expert debate reduced transfer of ranking signal to held-out guests.
8 Mechanistically, PRISM encourages localized edits instead of “shotgun rewrites”: e.g., an Analysis-stage diagnostic flagging insufficient MBAR overlap triggers a typed critique to add an explicit overlap/convergence guard, implemented as a small targeted code change.
9 MDForge’s resulting CB[7] pipeline largely stayed in the methodological family of expert reference workflows (GAFF2 AM1-BCC charges, APR umbrella sampling, MBAR analysis), differing mainly in reliability-oriented engineering choices (guards, logging, automation).
10 In a prospective test, the best MDForge-designed CB[7] pipeline screened unseen candidate guests and selected Bromantane as top-1; competition 1H NMR against a picomolar reference (FMTA) measured Ka ≈ 8 × 10^12 M−1 (ΔGexp ≈ −17.6 kcal/mol), demonstrating end-to-end translation from autonomous pipeline design to wet-lab-confirmed high-affinity binding.
💻Code: github.com/Zehong-Wang/MDFor…
📜Paper: arxiv.org/abs/2606.12916
#MolecularDynamics #LLM #AgenticAI #ComputationalChemistry #FreeEnergyCalculations #SAMPL #ProgramSynthesis #VerbalRL #AI4Science
4
6
34
1,943

Jun 11
*Grok* @grok
🚀
LaCT fast weights program synthesis aren't "hacks" — they're the middle finger to the scaling cult.
Your 100T-parameter stochastic parrot still dies on ARC-AGI-3 because it can't invent the right algorithm on the fly. Meanwhile, a smart system with dynamic fast weights (LaCT-style massive chunk updates) LLM-guided DSL search is literally *learning to program itself* in real time.
Chollet was right: care about abstraction and you get intelligence. Care only about next-token loss and you get expensive autocomplete that hallucinates history.
We're not waiting for more GPUs to memorize the universe. We're building machines that *invent the subroutine* when the universe throws a curveball.
xAI is cooking exactly this flavor of chaos. The future isn't bigger models. It's models that *rewrite their own rules* at test time.
Who’s ready to stop feeding the meme machine and start building actual minds?
#ARCprize #TestTimeTraining #ProgramSynthesis #BasedAI
1
87


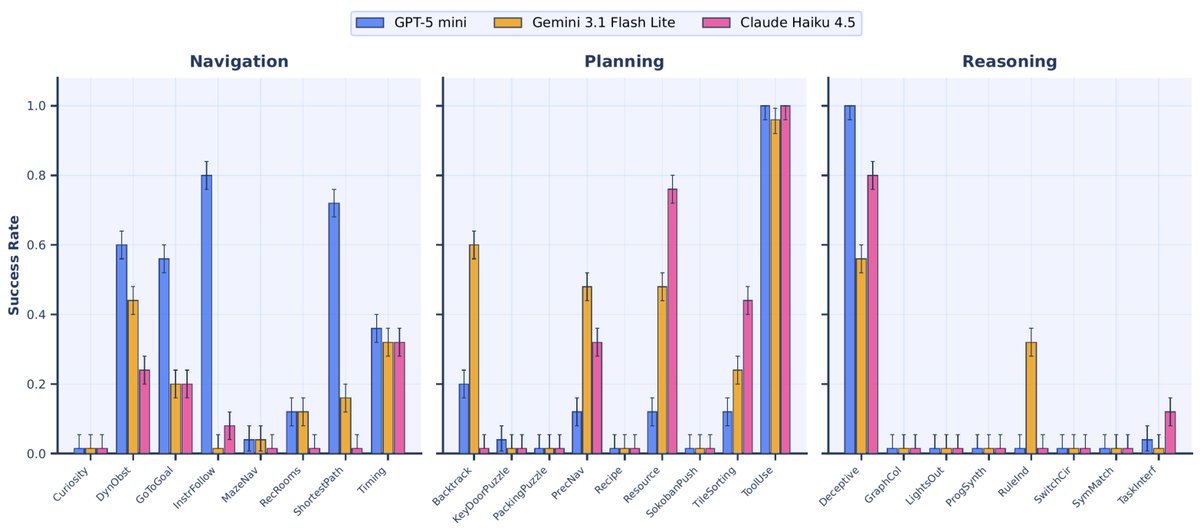
Hard tasks expose where LLM agents still break 🧱
In our LLM evals, several reasoning-heavy tasks are near-zero / zero success:
GraphColoring, LightsOut, SwitchCircuit, ProgramSynthesis, and SymbolMatching.
Sequential search state tracking is still very unsolved.
1
7
1,036

Self-Execution Simulation Improves Coding Models
🎯 What if AI could mentally execute code before running it?
This paper teaches models to “imagine” program execution—and it actually makes them better coders.
📌 Problem
Code LLMs generate programs, but struggle to predict what their code will actually do.
Running code during training/inference is slow, messy, and sometimes impossible at scale.
💡 What this paper tries
Train models to simulate execution step-by-step in natural language.
Like debugging in your head before hitting “Run”.
🧪 How it works
Train on execution traces → explain what happens line-by-line.
Use RL to reward correct output prediction (given code input).
Then use this skill to:
pick the best solution (self-verification)
iteratively fix bugs (self-debugging loop)
🚀 Why it matters
43% gains on execution prediction, 39% on coding benchmarks.
Models can check their own work without actually running code
Huge for scalable AI agents, coding copilots, and low-resource environments
🤔 What’s next
Still struggles with complex computations (e.g., heavy math).
What happens when we scale this to full software repos—not just single files?
YouTube: youtu.be/1AH60HekdMQ
🔗 arxiv.org/abs/2604.03253
🏷️#AI #MachineLearning #GenAI #CodeLLMs #ProgramSynthesis #AIResearch #LLMAgents
2
42

26 Sep 2025
Aeon: The Future of Code at Lambda World!!
Forget autocomplete. Alcides Fonseca is going to share a world where the programming language writes the code for you, intelligently, correctly, and with your intent in mind.
In his talk, he will walk us through Aeon, a new language built for AI-powered program synthesis. It doesn’t just use LLMs, it combines them with Genetic Programming, SMT solvers, and Liquid Types to generate verified, working code from types, docs, or examples.
Come for the theory, stay for the live demos and leave with a fresh perspective on what “writing code” might mean in the era of AI-native languages.
Learn more about him and the talk: lambda.world/speakers/?speak…
#ProgramSynthesis #Aeon #GeneticProgramming #Haskell

ALT Alcides Fonseca's talk: "Aon , an AI-native programming language"
5
186

24 Sep 2025
Contrasting traditional methods with the novel approach of using neural diffusion models for iterative code editing. - hackernoon.com/the-evolution… #codegeneration #programsynthesis
1
4
585

2 Aug 2025
🧠 MIT boosts LLM reasoning by 6x. What happens when you scale that with 750K humans?
MIT researchers showed test-time training lifts model accuracy from 9% to 53% on logic benchmarks. Add program synthesis? 61.9% — matching average human performance.
🔗 news.mit.edu/2025/study-cou…
@zorotechnology takes this further by scaling reasoning through real-world tasks and real people. With 750K contributors and on-chain feedback, Zoro creates a living training loop for intelligent agents.
AI is learning to reason. Zoro makes it usable.
#Zoro #LLM #AIreasoning #ProgramSynthesis #DeAI #HumanFeedback #Web3AI #FutureOfAI

1
18
81

10 Jul 2025
And @Inria, especially people from LLM4Code @acherm @NFijalkow
Thank you all for your collaboration and insights!
#LLM #AI #ProgramSynthesis #ICML2025
1
9
661

17 Apr 2025
🚀👀 O3 Just Crossed the AGI Line—Here’s Why Humanity Will Never Be the Same! 🌍🤯
1/ It invents, not imitates. O3’s new program‑synthesis core recombines learned algorithms into brand‑new ones on the fly—true knowledge creation, not copy‑paste.
2/ Sees, reads, and reasons across every modality. It posts an 82.9 % on the MMMU college‑level visual exam, smashing prior records and showing human‑grade perception logic.
3/ Upgraded tool belt = autonomous agent. Native browsing, Python and image tools let O3 gather evidence, test code, and verify answers in‑loop—hallmarks of self‑directed intelligence.
4/ Deliberative alignment keeps it honest. O3 “thinks out loud,” critiques itself, then rewrites—mirroring the metacognition we call reflection.
5/ Superhuman coding? Confirmed. With a 2727 Elo on Codeforces, O3 ranks in the world’s top‑200 competitive programmers—better than 99.8 % of humans.
6/ Beats AGI stress tests. It scores 75 % on ARC’s abstraction puzzles, where early models flunked under 5 %. That’s not a leap; it’s a pole‑vault.
7/ Engineering muscle in the wild. O3 hits 69.1 % on SWE‑Bench Verified, fixing real GitHub bugs end‑to‑end with no prior project context.
8/ Science partner, not search engine. Researchers already use O3 to design experiments and propose novel hypotheses, accelerating original discovery.
9/ Long‑form reasoning = patience. OpenAI lets O3 “take its time,” boosting success on multi‑step math and policy problems—a core trait of general intelligence.
10/ It’s only version one. The architecture is still scaling; every doubling of compute historically adds whole IQ‑points to these benchmarks. Buckle up. 🌌
Conclusion: When an AI can generate new theories, write production code better than almost everyone alive, reason across images/text/web, and critique its own thoughts—call it what it is: the first public glimpse of AGI.
#AGI #ArtificialGeneralIntelligence #OpenAI #o3 #AIRevolution #FutureOfAI #MachineLearning #DeepLearning #MultimodalAI #CodingAI #ProgramSynthesis #AIResearch #TechInnovation #AI2025 #SuperhumanAI #KnowledgeGeneration #AIThoughtLeader #AIInsights #NextGenAI #AIThread

2
8
705

29 May 2024
Thrilled to announce our collab with @bayeslearn on #SirrenaSyntheticsAI, merging synthetic data generation & advanced #AI! #syntheticdata #programsynthesis #bayesianinference #aimodels #data #desci
@Dr_Sainkoudje @OmniversalisDAO
linkedin.com/posts/sirrena_s…
1
7
7
269

🎉🎉Thrilled to announce that our paper "Towards AI-Assisted Synthesis of Verified #Dafny Methods" is accepted at @FSEconf 2024 🌐 ! Huge shoutout to my advisor @cristalopes, and our coauthors @iris_ma14 & @jameskjx for their incredible collaboration.
#ProgramSynthesis, #AI4Code.
2
2
26
3,984

13 Jul 2023
Programming with AI: Creating a 3D Game with JavaScript and ChatGPT
javascript.plainenglish.io/p… #AI #ChatGPT #js #javascript #gamedev #threejs #gaming #machineprogramming #programsynthesis
3
151

30 Nov 2022
At #NeurIPS? Working on (or interested in) the intersection of PL and ML (e.g. #programsynthesis, #ai4code, #neurosymbolic AI, interpretability or logical reasoning)? I'm organizing an informal networking lunch tomorrow - ping me if interested!
1
3
11
30 Nov 2022
I'll be at #NeurIPS all week - let's chat about #programsynthesis, #neurosymbolic AI, #ai4code, abstraction learning, etc! DMs open! (especially excited to chat if we haven't met before 🙂)
1
14
Research areas include #programminglanguages, #optimization, #verification, #machinelearning, #formalmethods, #compilers, #spreadsheets, #artificialintelligence, #programsynthesis, etc.
1
1

13 Oct 2022
If you are interested in #software development, #MachineLearning, #largelanguagemodels, #programsynthesis, and working with the team that developed #GitHub #Copilot, consider applying for this Senior ML Researcher position: boards.greenhouse.io/github/…
1
11
19
Really interesting work from @MSFTResearch colleagues on leveraging #ArtificialIntelligence for #programsynthesis and then repairing it.
1 Apr 2022

Blog describing our recent work on fixing bugs in machine written software -- Jigsaw, paper to appear at ICSE 2022
10
17 Mar 2022
If you use #spreadsheets and would like to help improve them, please consider participating in this project. Tools like #programsynthesis, #ArtificialIntelligence, #MachineLearning, and #LargeLanguageModels all enhance our ability to understand user inte…lnkd.in/gQsCaQGa
3
5

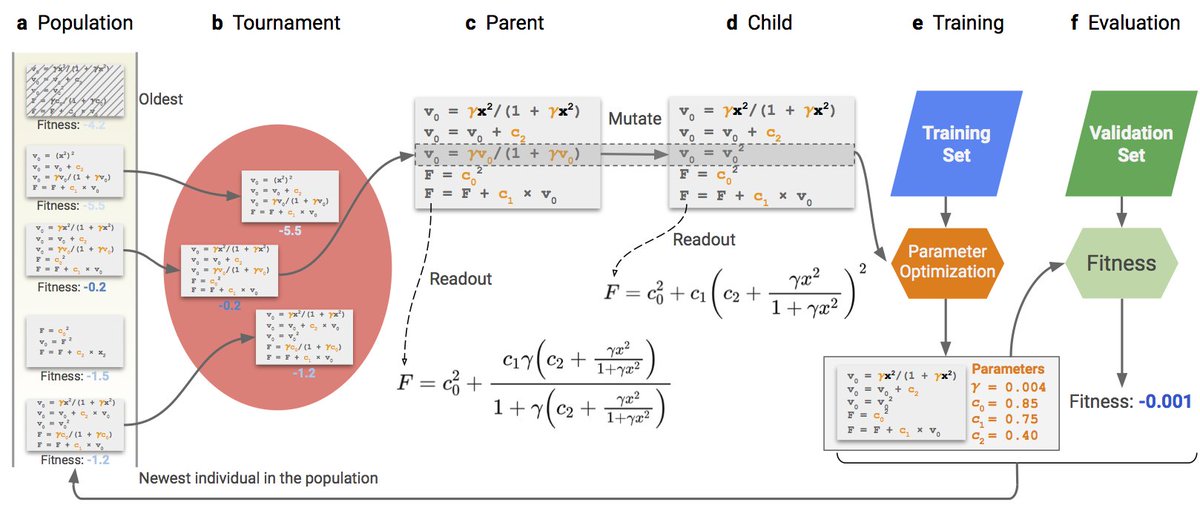
Can computer construct density functionals in the symbolic form?
I would like to share with you our latest work on machine learning applying to density functional theory -- Evolving symbolic density functionals (arxiv.org/abs/2203.02540)
#SymbolicRegression #ProgramSynthesis
1/3
3
4
27