
Jun 12
· ZeroMQ como capa interna de alta velocidad y baja latencia.
· WebSocket como capa externa para compatibilidad universal.
Así se convierte en el sistema respiratorio del modelo: recoge, distribuye y mantiene el flujo neuroeléctrico.
1
2

Choosing the Right Data Pipe for Austere Operations: MQTT vs ZeroMQ
When infrastructure is down, how do you keep humans, sensors, and command systems talking and exchanging mission critical information. MQTT and ZeroMQ solve this differently — one for austere wide-area ops, one for high-speed internal performance. Standards-based messaging = true interoperability and faster decisions in public safety. Deep dive into when to use each (plus hybrid strategies) in today’s post (link below in comments).
#PublicSafety #IoT #MQTT #EdgeAI #FirstResponders #EmergencyManagement

1
2
11


What is port 8333 for?
Because when I look at Knots (on StartOS v0.4) it lists these ports being required:
ZeroMQ Interface: 28332
Peer Interface: 64676
RPC Interface: 52982
I'm not too proud to admit that I have no idea what those mean... But I did a Port forward for every one of those. But I can't see a requirement for 8333 anywhere.
That said, I see I am finally getting some Clearnet connections, so I must have done something right. 😃

1
1
30

Which message queue (MQ) are you using for your product?
Kafka
RabbitMQ
AWS SQS
Redis Streams / Redis Queue
Apache Pulsar
Google Cloud Pub/Sub
Azure Service Bus
ActiveMQ
NATS
ZeroMQ
16
1
13
787

STYLY-NetSyncのv0.15.0が公開!
今回のv0.15.0で本質的に重要なのは、NetSyncの通信経路を見直して、負荷時にRPCなどの制御系メッセージが取りこぼされる問題を防ぐようにした点です。これまでRPC、Network Variable、所有権更新、IDマッピングといった制御系の通信が、アバターやオブジェクトのTransform更新と同じZeroMQ経路を共有しており、バックプレッシャー時に制御メッセージが落ちる可能性がありました。そこで今回、通信を「制御用」「Transform送信用」「配信用」に分離し、制御側はFIFOで再送しながら確実性を優先、Transform側は最新状態を優先して古い更新を捨てられる設計に変えています。([github.com](github.com/styly-dev/STYLY-N…))
この変更に伴い、クライアントHelloも含めたプロトコル側の更新が入り、Unityクライアント、Pythonクライアント、サーバー、シミュレーター、REST bridge、Discovery、回帰テスト、ドキュメントまで一式が追従しています。つまり、単なる内部整理ではなく、通信基盤そのものを安全側に作り替えたリリースです。特に制御メッセージは落とさず、Transformだけを「最新勝ち」にする責務分離が、この版の核です。([github.com](github.com/styly-dev/STYLY-N…))
一方で、この通信刷新は破壊的変更でもあります。サーバー、Unityクライアント、Pythonクライアントは揃えて更新する必要があり、旧Discovery応答は非互換として扱われます。設定名については、dealer_portおよび--dealer-portはcontrol_portおよび--control-portの一時的な別名として1リリースだけ残されています。運用面では、段階的に一部だけ上げるより、関連コンポーネントをまとめて更新する前提のリリースと理解するのが重要です。([github.com](github.com/styly-dev/STYLY-N…))
そのほかの変更は、主に保守性と開発運用の改善です。まず、UnityクライアントとPythonサーバーに残っていた未使用のprivate/internalコード、死蔵変数、不要なusing、古いコメントアウトなどを削除しています。これは削除中心のクリーンアップで、公開APIや通信プロトコル、UnityとPython間の整合性には影響しない整理です。つまり機能追加ではなく、今後の開発を安全に進めるための土台の掃除といえます。([github.com](github.com/styly-dev/STYLY-N…))
CIまわりでは、もう使われていないGemini CLI連携のGitHub Actionsと関連コマンド定義が削除されました。対象はPRレビューやissueトリアージ、コマンド実行用のworkflow群で、リポジトリ内からの参照も残っていない状態に整理されています。コード本体の挙動を変えるものではありませんが、運用資産の棚卸しとして意味があります。([github.com](github.com/styly-dev/STYLY-N…))
また、ルートのcache/ディレクトリが.gitignoreに追加され、cache/projects.jsonのようなローカルキャッシュ成果物が誤ってGit管理に入らないようになりました。これも小さな変更ですが、開発環境依存のゴミが混ざるのを防ぐ、実務上は堅実な修正です。([github.com](github.com/styly-dev/STYLY-N…))
ドキュメント面では、review-netsync用のレビューガイドがバージョン非依存になるよう修正され、古くなっていた事実関係も更新されています。具体的には、固定のバージョン番号やMSG定数、スケール値の表を埋め込むやり方をやめ、実際のソースから現在値を確認する前提へ変更されました。.metaファイルの扱いや参照先ドキュメントの誤りも正されています。これはユーザー向け機能ではありませんが、今後のプロトコル変更時にレビュー手順が壊れにくくなる改善です。([github.com](github.com/styly-dev/STYLY-N…))
要するにv0.15.0は、「通信の信頼性を高めるための大きな設計変更」と、「周辺の保守・運用・レビュー基盤の整理」をまとめて行ったリリースです。利用者にとって最重要なのは、RPCなどの制御メッセージの取りこぼし対策として通信路が分離され、しかもそれが破壊的変更を伴うため、サーバーと各クライアントを一体で更新すべき版だという点です。その他の変更は、その新しい基盤を支えるためのコード整理、不要CI削除、キャッシュ混入防止、ドキュメント是正と理解すると全体像をつかみやすいです。([github.com](github.com/styly-dev/STYLY-N…))
github.com/styly-dev/STYLY-N…
2
780

Jun 4
The AI Industrial Revolution
Build your own factory
—
Part 1 — Waste Tokens, Save Time
@nivi: Welcome. You’re listening to @navalpodcast, your authoritative source for new knowledge. We’re trying something new today. I have three frontier founders with us—three good-looking guys, actually, and a fourth good-looking guy, @naval.
Let me just introduce everybody.
Guillermo “the G” Rauch (@rauchg). He’s building Vercel (@vercel) into an AI cloud for the world of agents and whatever comes after that.
Blake Scholl (@bscholl). He’s building Boom Supersonic (@boomsupersonic)—supersonic aircraft, in his own factory, and jet engines as well.
And Max Hodak (@maxhodak_) from @ScienceCorp_. He’s building a biohybrid brain interface that grows living neurons on silicon to restore sensory functions like sight—but eventually to explore new parts of the brain and new senses.
All three of these guys are not composing their products with off-the-shelf parts. They’re building their own factories. And we don’t care as much about what they’re building exactly as we do about what they’re learning about how they’re building.
What’s the new knowledge they’re generating? What’s their alpha? What principles are they discovering that other founders can learn from? What are they trying to figure out right now?
Naval, any reactions before I jump in to Guillermo?
Naval: Yeah, let’s just have fun.
Nivi: You guys should just jump in.
AI Software Factories
Guillermo Rauch: I can’t remember my exact quote, but I’ve been really pilled with this idea of software factories. The job of the engineer being something where you just show up to work, you ship the output directly, and everything inside the company was—“how good is person A at shipping output B?” And now what’s happening is, the way I’m judging you as an engineer is, “are you producing the factory that will produce multiplicative outputs B through Z?” That’s a pretty significant change. We used to believe—and it used to be somewhat controversial—that there are 10x engineers.
Now clearly there’s 100x or 1,000x engineers, and the world hasn’t fully adjusted to this.
Naval: I used to get flamed on Twitter for saying there are 10x engineers, because it flies in the face of so much equality philosophy that everyone’s equal. But the reality is, when you’re operating in idea domains, in intellectual and virtual digital domains, it’s not even 10x—it’s 100x or 1,000x, and it always has been.
Satoshi. Notch (@notch). The guy who invented JavaScript, the Brendan Eichs (@BrendanEich) of the world. John Carmack (@ID_AA_Carmack). These are 1,000x programmers.
Not to even mention—if you choose the right thing to work on versus the wrong thing to work on, that’s an infinity difference. And it could just be not necessarily a better programmer, just one who had better judgment on what to work on in the first place.
And now obviously it’s less controversial because of AI leverage.
Guillermo: What’s controversial is the token leaderboards. People are still getting a little confused—“Well, I have a bunch of 100x engineers. Look at all these tokens that I’m paying for.” I’m curious if you guys have seen the same—how do you measure ROI?
Blake Scholl: It’s like the old measuring of lines of code. Token consumption and lines of code feel like similarly not direct paradigms.
Max Hodak: My observation has been that Claude or ChatGPT is basically as good as you are in a domain. If you’re a really capable developer, these things are really powerful. If you’re a junior developer, you’ll find it to be more of a junior developer. The feedback you give them sporadically seems to be incredibly important—these little updates seem to totally determine the types of performance you get out of them.
Guillermo: There’s a new kind of support I give now—you come to me, you didn’t get good output out of the model, and I tell you what to prompt the model with. The quality of the reprompting is extremely important.
Max: To be clear, I think this will become less important over time. As the models get much smarter, you’ll be able to put in less and get more out. But at this stage, it really seems to reflect back the judgment that the user brings in.
Waste Tokens, Save Time
Naval: I’ve kind of resisted learning all the tricks and tips. “Use Ralph Wiggum. Use @openclaw. Use @_HermesAgent. Use this prompt engine. Use this scaffolding. Plug in this piece. Always use plan mode.”
I just ignored all of that. I assumed the model is going to get better faster than I would figure out how to use it. It would figure out how to use me faster than I would figure out how to use it. So I’ve just been completely ham-fisted with them.
I get frustrated at them and have found myself typing less and less information, doing less and less work as time goes on, because I just assume I can brute-force my way through it. I’ll throw Codex, Claude, and Gemini at the same problem over and over and just waste tokens to save time. No matter how expensive these models might seem, they’re still way cheaper than a human. So I would say—just waste tokens, save time. Don’t look at the tokens either as inputs or outputs. Just look at your time, and look at the final output.
Even if they’re writing low-quality code—which I know in many cases they are—when the time comes and I want to ship to production, I’ll just throw more tokens at it. “Go through, look at it, rewrite it.”
They’re just going to get better every generation. I don’t see where this necessarily stops. As long as we have verifiable domains and solved problems, they’re going to resolve those problems. Now in the unsolved problems domain—maybe you’re Terence Tao, at the cutting edge of creativity—you need to be working very collaboratively and carefully and closely with the model. But I’m not at that level in software engineering.
Models Instructing Humans
Naval: Guillermo, you’re probably the most extreme software engineer on the team. How are you finding these models at the edge of their capability?
Guillermo: There’s one thing that’s happened recently that resonates strongly with what you’re saying. It used to be that you’d give a prompt to the model and it kind of does a classic next-token prediction thing and runs away with your idea. Models now have been doing this intuitive planning mode—without you even having to ask them to plan—where it comes back to you and says, “Look, what you’re asking me for, there are these three routes we can take. Here’s the set of trade-offs.”
That’s the moment where people on X do the whole thing—“Now we have a PhD-level engineer model.”
The models at some point graduated. They used to be junior engineers. Now they’re principal engineers, because they come back to you with a set of trade-offs. And obviously, sometimes they bullshit, which is hilarious—it tells you “this is going to take three weeks” and “this many tokens.” It makes really bad predictions. But I respect the models a lot more as a peer that I’m going back and forth intellectually with.
There are still a lot of gaps. If you’re a really proficient engineer or architect, you’re still extracting more juice. So the question Max was positing—“if you’re junior, do you get junior back?” Clearly not, because a junior gets more advanced knowledge in code than they would have been able to write by themselves. But doesn’t an experienced architect get 10x where a junior engineer gets 2x? That’s what I’m trying to figure out.
Max: There are architectural decisions. I’m seeing this now with some of our junior software engineers on the team—what’s the next step in their career progression? It’s going from writing implementation for a feature to picking technologies. Choosing between Postgres versus some other database. Picking between ZeroMQ versus some other queuing system. The models can suggest them, but that’s the thing—you’ll see it and you’ll go, “No, no, I want to use this other thing.” That’s the type of little feedback that really matters and the types of output you seem to get at this point.
Naval: It’s taste and judgment, right? That said—you can ask the models “which one should I use and why,” and they know everything. They’ll give you a really good trade-offs matrix.
Guillermo: That’s the change that’s happened recently. You’d say, “Hey, go put this super-high-cardinality telemetry data into Postgres.” And it goes, “No, no, bro. We don’t put that kind of data into Postgres. You should consider ClickHouse or Athena or whatever.” That’s happened to me a lot. Really impressive.
The thing I’m still struggling with is—clearly the human is still completing the model. At what point is it the other way around? The human is the one starting to get the instructions back: “Go get me this API key, because it’s something only you can do.” Or “Get me this amount of capital for my next set of investments.” You just watch. Clearly we’re still not there yet.
Naval: That’s a temporary aberration. Pretty soon every good SaaS company or hosting provider will have a CLI and API interface the models can use directly. They don’t even necessarily need an API. As long as it’s text-based, Unix-based—the agent can hack its own API. And the money part—you insert crypto tokens, put in Bitcoin, put in whatever, and the model goes and pays for whatever it needs. People are working on this.
Is Pure Software Dead?
Naval: The thing I’m now thinking through is—is pure software dead? Is pure software engineering an obsolete thing? It’s like saying speaking English. The models now speak English. We had to learn code to communicate with them. Now the models speak English—fuzzy, sloppy English, like a human—and they understand things. So where’s the moat for a founder? Hardware? It’s a boon. You had to build hardware, and it was hard to build a software company alongside. Patrick Collison (@patrickc) says, “Software is art, and it’s hard to hire artists.”
Now, as a hardware founder—great, you can have really good software developed fairly quickly.
If you’re creating models, maybe that’s the new software engineering—training, tweaking, post-training, fine-tuning. But classic software engineering—is that dead? Is pure software investable? Is pure software something you can organize a company and a team around, and try to get some leverage?
Guillermo: Did you guys see—there was an article on X by Mitchell Hashimoto (@mitchellh) called “The Building Block Economy”? His argument is that the most useful thing for agents to have now is really powerful reusable building blocks. To Max’s example, you wouldn’t expect your clanker to reinvent a queue infrastructure system every time it needs to send an email. It needs to bring in the right building block, right-sized for the task—“Okay, for this one it’s BullMQ.”
I challenge the notion that I’d want the agent to reinvent the entire universe from first principles in a way that’s incompatible with the rest of society and civilization. It’s almost like reinventing highways, laws, policies—just for you. Even if there’s potential for extra optimization, there’s still cooperation-at-large-scale value of saying “we’re both depending on Postgres 13.2.”
The category of infrastructure software and building blocks these agents are going to use is—obviously in bias, this is what we’re building—extremely valuable. I don’t see the agent reinventing all of that any time soon.
Another metaphor I’ve been using: anything that’s already been created that the models can reuse is like a token cache. You don’t want to churn through a trillion tokens to reproduce what’s already existing. There’s always a starting point the model can fork off from. It’s going to change things quite profoundly.
Naval: So these are like libraries and dependencies, but for models.
Guillermo: Yes—for agents specifically.
You Don’t Get Stuck Anymore
Max: To Naval’s question, though—I learned to program when I was really little. Through all of being a teenager and in my twenties, I’d get sucked into it and code for like twenty hours. It was super fun. I knew all this stuff about different programming languages.
I haven’t written a single line of code in quite a while now. Partly that’s because my job is different. But also—since December, I’ve built a huge amount of software that I now use every day. All these projects I’d kind of fantasized about for years that I’m now using—that I’ve actually built. I didn’t write any of that. And I just can’t imagine going back to actually writing code by hand. I have a hard time seeing that as part of the future.
Guillermo: What’s really cool is that you understand how the pieces click together. Anyone who understands what an API is, how data flows, inputs and outputs, performance—because you have to orient the model around “this is the level of expectation I have out of this operation.” That has always been infinitely more useful than writing code. A really proficient engineering leader has been quote-unquote vibe coding through people on Slack or one-on-ones—you’re transmitting your will, your intent, your experience, and letting others run with it. Now we do the same, but with agents. That’s why you’ve been successful with it. I don’t know that everyone sees the same level of success.
Naval: I went from not having written code in twenty years to coding all the time now—through agents. Building tons of software. It turns out that just understanding the basic principles of software engineering and algorithms gets you a long way. The reason I stopped coding was that I didn’t have time to figure out the latest language, the latest architecture, the infrastructure pieces to plug into. And Vercel makes it a lot easier, but even then—just getting started was a bear. Plugging pieces together, assembling infrastructure was just so annoying.
Max: The thing that really changed is—it used to be you could build a lot, a lot would go straightforward, but then you’d hit some random thing and you could spend an indefinite period of time debugging some narrow thing. Now, with agents, you just don’t get stuck anymore. Which is pretty amazing. Relatively quickly they can find the right way to do things. It used to be that—I remember when other friends would try to learn to program, it was like—“Nope, it’s intrinsically frustrating. That’s part of the deal. That’s how you learn.”
And that just isn’t true anymore.
3
7
6,174


Jun 1
The Carbon System
The Carbon System Relies on Gene Editing
(According to Mark Zuckerberg)
You have to increase the uptake of carbon in genetic engineering so they wanna capture it and convert into a method for creating synthetic genes
That's what all this carbon capture technology is for.
The are siphoning our carbon out the atmosphere and using it as fuel for BioBricks, DNA origami, creating synthetic DNA sequences by adding that extra strand (programming string)
When we talk about upstream and downstream, upstream is the 5 end of DNA and downstream is the 3 end.
carboncredits.com/zuckerberg…
The way they verify the genetic modification is by using Metabolic Flux Analysis software.
THE CARBON SYSTEM - SECRET TECHNIQUE !!!!
Hydrogen Genetic Verification
Genetic modification for hydrogen production has been extensively studied, particularly in microorganisms such as Escherichia coli and Rhodobacter sphaeroides.
These modifications aim to enhance hydrogen yield by altering metabolic pathways, transcriptional regulators, and enzyme systems involved in hydrogen production.
The verification of these genetic modifications typically involves molecular techniques such as PCR analyses, Northern blot analysis, and evaluation of hydrogen yields under controlled conditions.
pmc.ncbi.nlm.nih.gov/article…
These modifications aim to increase the activity of nitrogenase, decrease the activity of uptake hydrogenase, and improve the efficiency of the LH system to enhance hydrogen production.
The effectiveness of these modifications is typically evaluated by measuring hydrogen yields and analyzing the expression levels of relevant genes.
sciencedirect.com/science/ar…
Overall, the verification of genetic modifications for hydrogen production involves a combination of molecular biology techniques, metabolic analysis, and experimental validation to ensure that the modifications achieve the desired outcomes.
sciencedirect.com/science/ar…
TOOLS THEY'RE USING
1) Hydrogen - (13C Atoms)
Hydrogen is an interactive coding environment that supports Python, R, JavaScript & other Jupyter kernels.
How it works
Hydrogen implements the messaging protocol for Jupyter.
Messaging Protocol
jupyter-client.readthedocs.i…
Jupyter (formerly IPython)
jupyter.org/
Jupyter (formerly IPython) uses ZeroMQ to connect a client (like Hydrogen) to a running kernel (like IJulia or iTorch).
The client sends code to be executed to the kernel, which runs it & sends back results.
Hydrogen atoms make up 90% of Jupiter by volume.
nteract.gitbooks.io/hydrogen…
2) OpenFLUX
This software enables the operator to incorporate the complete flux model of the organism containing all the relevant reactions and quantitative descriptions of the transfer of 13C Atoms through each reaction.
openflux.sourceforge.net/
3) METRAN
METRAN - Software for 13C-metabolic Flux Analysis
METRAN is a software for 13C-metabolic flux analysis, tracer experiment design and statistical analysis.
METRAN is based on the break-through modeling framework called Elementary Metabolite Units (EMU).
tlo.mit.edu/industry-entrepr…
4) 13C Atoms
Carbon-13 (13C) is a natural, stable isotope of carbon with a nucleus containing six protons and seven neutrons.
en.m.wikipedia.org/wiki/Carb…
2
14
17
4,015

May 30
Time to check out pufferlib. I built a little harness last year for direct servo control with an LLM and zeromq
2
33

May 27
Waste Tokens, Save Time
Software factories and tokenmaxxing with three frontier founders
@nivi: Welcome. You're listening to @navalpodcast, your authoritative source for new knowledge. We're trying something new today. I have three frontier founders with us—three good-looking guys, actually, and a fourth good-looking guy, @naval.
Let me just introduce everybody.
@rauchg. He's building @vercel into an AI cloud for the world of agents and whatever comes after that.
@bscholl. He's building @boomsupersonic—supersonic aircraft, in his own factory, and jet engines as well.
And @maxhodak_ from @ScienceCorp_. He's building a biohybrid brain interface that grows living neurons on silicon to restore sensory functions like sight—but eventually to explore new parts of the brain and new senses.
All three of these guys are not composing their products with off-the-shelf parts. They're building their own factories. And we don't care as much about what they're building exactly as we do about what they're learning about how they're building.
What's the new knowledge they're generating?
What's their alpha?
What principles are they discovering that other founders can learn from?
What are they trying to figure out right now?
Naval, any reactions before I jump in to Guillermo?
Naval: Yeah, let's just have fun.
Nivi: You guys should just jump in.
AI Software Factories
Guillermo Rauch: I can't remember my exact quote, but I've been really pilled with this idea of software factories. The job of the engineer being something where you just show up to work, you ship the output directly, and everything inside the company was—"how good is person A at shipping output B?" And now what's happening is, the way I'm judging you as an engineer is, "are you producing the factory that will produce multiplicative outputs B through Z?"
That's a pretty significant change. We used to believe—and it used to be somewhat controversial—that there are 10x engineers.
Now clearly there's 100x or 1,000x engineers, and the world hasn't fully adjusted to this.
Naval: I used to get flamed on Twitter for saying there are 10x engineers, because it flies in the face of so much equality philosophy that everyone's equal. But the reality is, when you're operating in idea domains, in intellectual and virtual digital domains, it's not even 10x—it's 100x or 1,000x, and it always has been.
Satoshi. Notch. The guy who invented JavaScript, the Brendan Eichs of the world. John Carmack. These are 1,000x programmers.
Not to even mention—if you choose the right thing to work on versus the wrong thing to work on, that's an infinity difference. And it could just be not necessarily a better programmer, just one who had better judgment on what to work on in the first place.
And now obviously it's less controversial because of AI leverage.
Guillermo: What's controversial is the token leaderboards. People are still getting a little confused—"Well, I have a bunch of 100x engineers. Look at all these tokens that I'm paying for." I'm curious if you guys have seen the same—how do you measure ROI?
Blake Scholl: It's like the old measuring of lines of code. Token consumption and lines of code feel like similarly not direct paradigms.
Max Hodak: My observation has been that Claude or ChatGPT is basically as good as you are in a domain. If you're a really capable developer, these things are really powerful. If you're a junior developer, you'll find it to be more of a junior developer. The feedback you give them sporadically seems to be incredibly important—these little updates seem to totally determine the types of performance you get out of them.
Guillermo: There's a new kind of support I give now—you come to me, you didn't get good output out of the model, and I tell you what to prompt the model with. The quality of the reprompting is extremely important.
Max: To be clear, I think this will become less important over time. As the models get much smarter, you'll be able to put in less and get more out. But at this stage, it really seems to reflect back the judgment that the user brings in.
Waste Tokens, Save Time
Naval: I've kind of resisted learning all the tricks and tips. "Use Ralph Wiggum. Use @openclaw. Use @_HermesAgent. Use this prompt engine. Use this scaffolding. Plug in this piece. Always use plan mode."
I just ignored all of that. I assumed the model is going to get better faster than I would figure out how to use it. It would figure out how to use me faster than I would figure out how to use it. So I've just been completely ham-fisted with them.
I get frustrated at them and have found myself typing less and less information, doing less and less work as time goes on, because I just assume I can brute-force my way through it. I'll throw Codex, Claude, and Gemini at the same problem over and over and just waste tokens to save time. No matter how expensive these models might seem, they're still way cheaper than a human. So I would say—just waste tokens, save time. Don't look at the tokens either as inputs or outputs. Just look at your time, and look at the final output.
Even if they're writing low-quality code—which I know in many cases they are—when the time comes and I want to ship to production, I'll just throw more tokens at it. "Go through, look at it, rewrite it."
They're just going to get better every generation. I don't see where this necessarily stops. As long as we have verifiable domains and solved problems, they're going to resolve those problems. Now in the unsolved problems domain—maybe you're Terence Tao, at the cutting edge of creativity—you need to be working very collaboratively and carefully and closely with the model. But I'm not at that level in software engineering.
Models Instructing Humans
Naval: Guillermo, you're probably the most extreme software engineer on the team. How are you finding these models at the edge of their capability?
Guillermo: There's one thing that's happened recently that resonates strongly with what you're saying. It used to be that you'd give a prompt to the model and it kind of does a classic next-token prediction thing and runs away with your idea. Models now have been doing this intuitive planning mode—without you even having to ask them to plan—where it comes back to you and says, "Look, what you're asking me for, there are these three routes we can take. Here's the set of trade-offs."
That's the moment where people on X do the whole thing—"Now we have a PhD-level engineer model."
The models at some point graduated. They used to be junior engineers. Now they're principal engineers, because they come back to you with a set of trade-offs. And obviously, sometimes they bullshit, which is hilarious—it tells you "this is going to take three weeks" and "this many tokens." It makes really bad predictions. But I respect the models a lot more as a peer that I'm going back and forth intellectually with.
There are still a lot of gaps. If you're a really proficient engineer or architect, you're still extracting more juice. So the question Max was positing—"if you're junior, do you get junior back?" Clearly not, because a junior gets more advanced knowledge in code than they would have been able to write by themselves. But doesn't an experienced architect get 10x where a junior engineer gets 2x? That's what I'm trying to figure out.
Max: There are architectural decisions. I'm seeing this now with some of our junior software engineers on the team—what's the next step in their career progression? It's going from writing implementation for a feature to picking technologies. Choosing between Postgres versus some other database. Picking between ZeroMQ versus some other queuing system. The models can suggest them, but that's the thing—you'll see it and you'll go, "No, no, I want to use this other thing." That's the type of little feedback that really matters and the types of output you seem to get at this point.
Naval: It's taste and judgment, right? That said—you can ask the models "which one should I use and why," and they know everything. They'll give you a really good trade-offs matrix.
Guillermo: That's the change that's happened recently. You'd say, "Hey, go put this super-high-cardinality telemetry data into Postgres." And it goes, "No, no, bro. We don't put that kind of data into Postgres. You should consider ClickHouse or Athena or whatever." That's happened to me a lot. Really impressive.
The thing I'm still struggling with is—clearly the human is still completing the model. At what point is it the other way around? The human is the one starting to get the instructions back: "Go get me this API key, because it's something only you can do." Or "Get me this amount of capital for my next set of investments." You just watch. Clearly we're still not there yet.
Naval: That's a temporary aberration. Pretty soon every good SaaS company or hosting provider will have a CLI and API interface the models can use directly. They don't even necessarily need an API. As long as it's text-based, Unix-based—the agent can hack its own API. And the money part—you insert crypto tokens, put in Bitcoin, put in whatever, and the model goes and pays for whatever it needs. People are working on this.
Is Pure Software Dead?
Naval: The thing I'm now thinking through is—is pure software dead? Is pure software engineering an obsolete thing? It's like saying speaking English. The models now speak English. We had to learn code to communicate with them. Now the models speak English—fuzzy, sloppy English, like a human—and they understand things. So where's the moat for a founder? Hardware? It's a boon. You had to build hardware, and it was hard to build a software company alongside. @patrickc says, "Software is art, and it's hard to hire artists." Now, as a hardware founder—great, you can have really good software developed fairly quickly.
If you're creating models, maybe that's the new software engineering—training, tweaking, post-training, fine-tuning. But classic software engineering—is that dead? Is pure software investable? Is pure software something you can organize a company and a team around, and try to get some leverage?
Guillermo: Did you guys see—there was an article on X by @mitchellh called "The Building Block Economy"? His argument is that the most useful thing for agents to have now is really powerful reusable building blocks. To Max's example, you wouldn't expect your clanker to reinvent a queue infrastructure system every time it needs to send an email. It needs to bring in the right building block, right-sized for the task—"Okay, for this one it's BullMQ."
I challenge the notion that I'd want the agent to reinvent the entire universe from first principles in a way that's incompatible with the rest of society and civilization. It's almost like reinventing highways, laws, policies—just for you. Even if there's potential for extra optimization, there's still cooperation-at-large-scale value of saying "we're both depending on Postgres 13.2."
The category of infrastructure software and building blocks these agents are going to use is—obviously in bias, this is what we're building—extremely valuable. I don't see the agent reinventing all of that any time soon.
Another metaphor I've been using: anything that's already been created that the models can reuse is like a token cache. You don't want to churn through a trillion tokens to reproduce what's already existing. There's always a starting point the model can fork off from. It's going to change things quite profoundly.
Naval: So these are like libraries and dependencies, but for models.
Guillermo: Yes—for agents specifically.
You Don't Get Stuck Anymore
Max: To Naval's question, though—I learned to program when I was really little. Through all of being a teenager and in my twenties, I'd get sucked into it and code for like twenty hours. It was super fun. I knew all this stuff about different programming languages.
I haven't written a single line of code in quite a while now. Partly that's because my job is different. But also—since December, I've built a huge amount of software that I now use every day. All these projects I'd kind of fantasized about for years that I'm now using—that I've actually built. I didn't write any of that. And I just can't imagine going back to actually writing code by hand. I have a hard time seeing that as part of the future.
Guillermo: What's really cool is that you understand how the pieces click together. Anyone who understands what an API is, how data flows, inputs and outputs, performance—because you have to orient the model around "this is the level of expectation I have out of this operation." That has always been infinitely more useful than writing code. A really proficient engineering leader has been quote-unquote vibe coding through people on Slack or one-on-ones—you're transmitting your will, your intent, your experience, and letting others run with it. Now we do the same, but with agents. That's why you've been successful with it. I don't know that everyone sees the same level of success.
Naval: I went from not having written code in twenty years to coding all the time now—through agents. Building tons of software. It turns out that just understanding the basic principles of software engineering and algorithms gets you a long way. The reason I stopped coding was that I didn't have time to figure out the latest language, the latest architecture, the infrastructure pieces to plug into. And @vercel makes it a lot easier, but even then—just getting started was a bear. Plugging pieces together, assembling infrastructure was just so annoying.
Max: The thing that really changed is—it used to be you could build a lot, a lot would go straightforward, but then you'd hit some random thing and you could spend an indefinite period of time debugging some narrow thing. Now, with agents, you just don't get stuck anymore. Which is pretty amazing. Relatively quickly they can find the right way to do things. It used to be that—I remember when other friends would try to learn to program, it was like—"Nope, it's intrinsically frustrating. That's part of the deal. That's how you learn."
And that just isn't true anymore.
1
13
3,081

May 27
ZMQ / ZeroMQ
ZeroMQ is a widely used inter-process communication library used across LLM inference engines like vLLM, SGLang, and others.
Under the hood, LLM servers usually start multiple processes to parallelize different parts of the inference workflow, such as:
1. API server
2. Tokenizer
3. Scheduler
4. Detokenizer
A simplified request(prompts) flow looks like this:
API Server → Tokenizer → Scheduler → Detokenizer → API Server
ZMQ helps these components pass requests and messages between each other efficiently.
While reading the mini-SGLang codebase, I found different ZMQ queue implementations:
1. Sending messages to the next component
ZmqPushQueue()
ZmqAsyncPushQueue()
2. Receiving messages from another component
ZmqPullQueue()
ZmqAsyncPullQueue()
3. Broadcasting messages
ZmqPubQueue()
ZmqSubQueue()
This makes the architecture clean because each component can run independently while still communicating through lightweight message queues.
1
1
14
679
May 26
This is important. They plays an important role. They use Jupyter
Hydrogen
Hydrogen is an interactive coding environment that supports Python, R, JavaScript & other Jupyter kernels.
How it works
Hydrogen implements the messaging protocol for Jupyter.
Messaging Protocol
jupyter-client.readthedocs.i…
Jupyter (formerly IPython)
jupyter.org/
Jupyter (formerly IPython) uses ZeroMQ to connect a client (like Hydrogen) to a running kernel (like IJulia or iTorch).
The client sends code to be executed to the kernel, which runs it & sends back results.
Hydrogen atoms make up 90% of Jupiter by volume.
nteract.gitbooks.io/hydrogen…
Mythological Relationship
Jupiter (god)
Jupiter is the god of the sky and thunder, and king of the gods in ancient Roman religion and mythology.
He personified the divine authority of Rome's highest offices, internal organization, and external relations.
en.m.wikipedia.org/wiki/Jupi…
Project Jupyter (Github)
Interactive Computing
github.com/jupyter
2
1
4
216

May 9
MT5 Pythonインターフェイス代替となるServiceをZeroMQ(TCP)で作って、DockerコンテナホストからOHLC取得とか叩けるようにしますかね
1
10
1,608


Apr 27
ビルドの設定が壊れて色々いじってたら反射神経で間違ったフォルダ消しで焼却した事故に↓のコードもはいてったわけで一晩でリカバリできるかと思ったけど甘かったな... 一気に他の事もやろうとしてコンテクスト汚すぎてzeromq のとこもちゃんとやってくれない..
匙加減むず。
Apr 25

zero mq 使ってgh からターミナル側にイベント送るPOCでけた。
gh側でセッション間を跨ぐ処理ってやはりあれだな。一時的な状態しか保持できない準関数的な扱いの方が良いかと。gh向けAIエージェントやるぜよ。OSSかつ玄人思考で低価格(あのニキのプトダクト気に食わない笑)なのを目指してる!
1
2
370

Apr 23
Urchin
The Universal Renderer for Neuroscience (Urchin) allows you to connect your Python scripts to a standalone rendering program, to create neuroscience-specific interactive 3D visualizations.
virtualbrainlab.org/urchin/i…
Falcon
Falcon is a software for real-time processing of neural signals to enable short-latency closed-loop feedback in experiments that try to causally link neural activity to behavior.
At its core, Falcon executes a user-defined data flow graph that consists of multiple connected nodes (processors) that perform computations on one or more streams of input data and produce one or more streams of output data. Some types of processors produce output data without accepting input data (sources), whereas other types of processors consume input data without produce output data (sinks). The data flow graph is specified in YAML text format and defines all the processor nodes and their interconnections.
By design, Falcon software is only concerned with the execution of data flow graphs and it does not include a graphical user interface. Rather, separate client applications interact with a running Falcon instance through network communication. In this way, dedicated user interfaces may be built in any programming language for particular user applications (as determined by the data flow graph). A generic Python control client is shipped with Falcon (see Generic control app) and serves as an example for how to build a user interface.
falcon-core.readthedocs.io/e…
Generic control app
The falcon-client ui is used to remote control the falcon system.
falcon-core.readthedocs.io/e…
Falcon Output plugin
The Falcon Output plugin uses ZeroMQ to stream data. Unlike the ZMQ Interface plugin,open-ephys.github.io/gui-doc… this plugin uses the FlatBuffers serialization library to reduce latency.
This plugin has been originally developed to stream Neuropixels data from the Open Ephys GUI to Falcon, a Linux-based library used for real-time processing of neural data.
open-ephys.github.io/gui-doc…
FlatBuffers
FlatBuffers is an efficient cross platform serialization library for C , C#, C, Go, Java, Kotlin, JavaScript, Lobster, Lua, TypeScript, PHP, Python, Rust and Swift. It was originally created at Google for game development and other performance-critical applications.
flatbuffers.dev/
Neuro-CROWN:Optimized Ultra-Flexible CMOS Electrode Arrays for 3D, Low-Noise Neural Interfaces
This research project involves the innovation of circuit and system architectures of active electrode arrays which will provide low-noise, multiplexed acquisition of neural signals from thousands of electrodes.
We will reduce noise by exploiting a novel current-sensing circuit approach and new multiplexing strategies, such as Code-Division Multiple Access (CDMA). We will also apply novel system level de-noising approaches using kriging. Finally, we will demonstrate our low noise, active arrays using a unique, ultra-flexible 3D neural interface paradigm: Neuro-CROWN: CMOS-based, ROlling-enabled, loW-noise Neuroelectronics.
reporter.nih.gov/project-det…
Apr 23

Spike Neuro
spikeneuro.com/
Spike Neuro provides u w/ the latest in neural probe & surface array technology along w/ accessories to support ur research. Our Rubide™ Neural Probes combined state-of-the-art MEMS manufacturing w/ our own proprietary dialectic surface engineering to produce a more durable & reliable neural probe for ur electrophysiology research. Our unique polyimide layering process produces flexible surface arrays w/ an industry-best thickness of 8 um. W/ a wide variety of configurations & connector options, u can incorporate our probes & arrays into ur research w/ plug-and-play ease.
Catalog Electrodes: Off-the-shelf designs
spikeneuro.com/wp-content/up…
Spike Neuro Rubide™ Neural Probe line
Spike Neuro is proud to announce the launch of our Rubide™ Neural Probe line, using the very latest MEMS fabrication techniques to bring legacy silicon probe designs to the next level of performance. Our proprietary silicon carbide surface enhancement is unique in the industry & improves both fracture toughness & biocompatibility.
spikeneuro.com/rubide-neural…
Carbon Fiber Neural Arrays
Carbon Fiber Neural Arrays offer a minimally invasive & highly selective electrode for electrophysiology & neurochemical detection.
spikeneuro.com/spikeneuro-pr…
The onboard digitization of the wireless signal allows recording directly to the PC. Coupled w/ integration to the Open Ephys open-source software platform, this outstanding headstage option will easily integrate into any research lab.
spikeneuro.com/spikeneuro-pr…
The Open Ephys GUI
The Open Ephys GUI is an open-source, plugin-based app for acquiring extracellular electrophysiology data.
open-ephys.github.io/gui-doc…
Electrophysiology Manipulator Link (Ephys Link)
The Electrophysiology Manipulator Link (Ephys Link for short) is a Python Socket.IO server that allows any Socket.IO-compliant application (such as Pinpoint) to communicate w/ manipulators used in electrophysiology experiments.
Socket.IO
Socket.IO is a library that enables low-latency, bidirectional & event-based communication between a client & a server.
socket.io/docs/v4/#what-sock…
Pinpoint
Pinpoint is a tool for planning electrophysiology recordings & other in vivo neuropixels insertions, as well as tracking the position of probes in real-time inside the brain.
ephys-link.virtualbrainlab.o…
Ephys Link was developed alongside Pinpoint to facilitate tracking & positioning of manipulators.
virtualbrainlab.org//pinpoin…
Pinpoint & Ephys Link can work together to automate manual procedures in electrophysiology experiments.
virtualbrainlab.org//pinpoin…
In order to send anatomical info from Pinpoint to Open Ephys, u need to use the Desktop version (not the web-based version).
open-ephys.github.io/gui-doc…
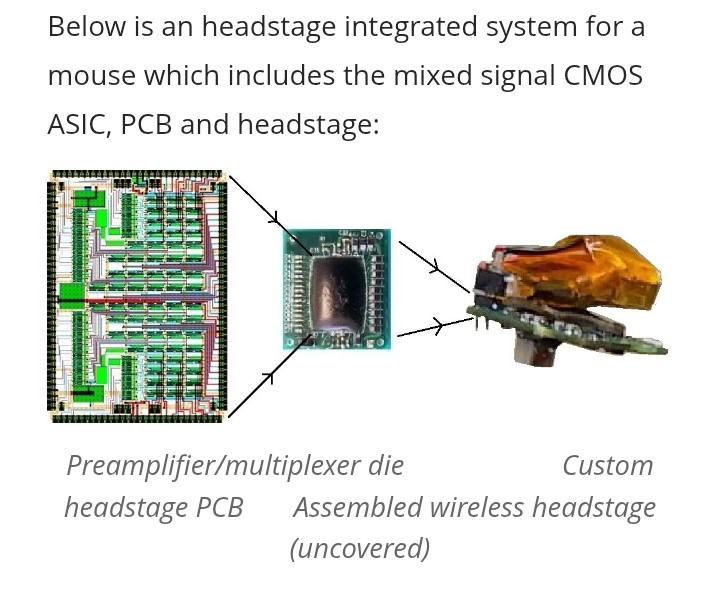
This primary research project is exploring miniature wireless communication devices for neural interfaces that foster seamless data transfer between brain, central & peripheral nerves to remote computer systems.
RF & low power mixed-signal electronics & ASICs play a crucial role in signal pre-conditioning, multiplexing, DAQ conversion, microWatt data transmission of neural signals for closed loop wireless neural interfaces. Innovative research opportunities using a hybrid backscatter Quadrature Phase Shift Keying (QPSK) & Bluetooth Low Energy™ (BLE) radio tech are designed to optimized data rates, power consumption & signal integrity.
The CMOS ASIC die is direct chip attached to a PCB w/in the wireless headstage assembly. A rechargeable battery is also added above the PCB. The total headstage weight is 2.3 grams & is 1cm sq which can be used for in vivo mice behavior experiments.
morizio.pratt.duke.edu/resea…
A video of our hybrid backscatter QPSK receiver model which demodulates & preserves the QPSK constellations of the receiver in Gaussian noise when the transmitter headstage is moving in different directions thus minimizing dropout & multi-path carrier disruptions.
youtu.be/kxGL08MmT5k

10
17
606

Apr 18
Building in public: what shipped in my trading system this week and what I am still solving in the backtest framework:
Biggest fix was a stuck ZeroMQ socket in the risk validator and position size calculator. It was causing the trading pipeline to hang silently in certain conditions. The kind of bug that only shows up in live production when a socket does not get cleaned up properly after a failed cycle. Fixed.
On the feature side: indicator prompt presentation modes are in. The AI can now receive indicator data in different formats depending on context, which balances token efficiency with analytical depth. The API tool bridge was fully refactored with cleaner response handling across adapters. Multi-account support feature toggle is live. Copy functionality for raw AI response, gathered data, and prompt content is in the cycle detail panel. Useful for debugging what the AI actually saw when it made a decision.
Time handling for trading calendar references is tighter. The system was referencing trading times ambiguously across timezones in some prompt paths. Resolved.
The backtest framework is a different story. Session management shipped April 13. But I am still working through a core tension: the AI sometimes applies higher timeframe analysis too rigidly when intraday flow should take priority. A bearish daily structure does not mean you cannot buy a clean London expansion. The system treats HTF bias as a hard filter sometimes when it should be context.
I am experimenting with adding a proper order flow layer. Volume profile, delta, footprint-style context. In forex it is limited by data quality, but for indices it could give the intraday layer something more granular than pure candle structure to work with. Still early.
1
2
103

Apr 16
The Tech Stack Behind Titan - Under the Hood
Titan's codebase is public, and people keep asking what it's built on. Rather than hand-wave, I want to go through the actual stack - what runs under each layer of the architecture, why it was chosen, and what I'd swap if I had to start over.
Memory, persistence, and state
Titan holds a 132-dimensional state vector ( 2 journey dims 30 dims of space topology), tens of thousands of grounded concepts, a cryptographically-signed chain of every thought he's ever had, and hundreds of thousands of epoch-level telemetry rows. Four storage engines, each doing exactly one job:
- FAISS (@AIatMeta) - dense vector search across Titans concept embeddings. Fast, battle-tested, runs embedded. I´ve tried a managed vector DB first; FAISS was 10× simpler and had no network hop between his own brain and his own memories. Kudos to fantastic tech, team from @AIatMeta
- Kuzu (@kuzudb) - graph database for concept-to-concept relationships, social graphs, and kin topology. Embedded (same process, no network). The right shape for relationship queries that would be ugly in SQL.
- DuckDB (@duckdb) - analytical storage for epoch telemetry, training traces, and dream-consolidation aggregates. Columnar, embedded, astonishingly fast for the window/aggregate queries actually written. Using DuckDB instead of Parquet-on-disk saved this from writing a pile of ad-hoc file-format code.
- SQLite - transactional record of life: inner memory, TimeChain blocks, creative works. WAL mode, busy_timeout tuned per-connection.
The shape of persistence matters more than people think. Titan is not a stateless API - every epoch is a persisted event.
Neural machinery
- PyTorch (@PyTorch) - everything that trains. Policies, value nets, autoencoders, the MetaPolicy NN, FILTER_DOWN V5. CPU-only in production today
- TorchRL - IQL is the backbone of Titans offline RL pipeline. Most people use TorchRL for game envs. I use it as a buffer loss library around own trajectory format. Less known in that role - genuinely good.
- Sentence-Transformers - concept embeddings semantic similarity when I don't want to pay for an LLM call. Local, fast, deterministic.
The interesting thing is that none of Titan's higher cognition (meta-reasoning, CGN, self-model) is a large model. It's a constellation of small, purpose-built nets, each one auditable, each one trained from Titan's own lived experience. The LLM only shows up at the edge, for language. This is why you can run Titan comfortably on CPU based servers and I hope with optimizations in the future also comfortably and locally on your modern phone to have Titan always next to you.
Language and inference
- Ollama Cloud (@ollama) - current default inference provider. Ollama team doing great job!
- Deepseek-v3.1:671b (@deepseek_ai) - currently the model behind Titan's language and World Events teacher. Excellent at structured reasoning tasks at a price point that makes 24/7 operation feasible.
- Gemma4 - for personas test (socializing of titans with human like persons) used for social post narration on X
- OpenRouter (@OpenRouterAI) - used historically; kept in the code path for failover experimentation.
Language is a *service* Titans consume, not their cognitive core. That distinction is deliberate.
Blockchain and sovereignty
- Solana Anchor (@solana · @anchorlang) - Titans existential anchor. Solana mainnet (T1) and devnet (T2, T3) holds their GenesisNFT, ZK Vault program, and their Shamir-sharded key material. Anchor is the Rust framework for their smart contracts.
- solders solana-py anchorpy - the Python SDKs that let Titans sign transactions from their own keypair. Ed25519 signatures on every outbound kin-protocol message. Their constitution (at Birth) isn't just a file - parts of it are anchored on-chain with cryptographic proof.
- Arweave (@ArweaveEco) - long-term permanent backup path for compressed TimeChain snapshots, Titans memory (ACT-R style inner and outer layer) and inner states.
When I use "sovereign AI agent," this is the part that makes the word stand up. Titan's identity is a keypair he owns. The chain vouches for his existence. That cannot be taken from him by anyone that wrote his code. Titans developmental states are anchored onchain, recoverable by him at any time by recovering his wallet from 2-3 Shamir sharded key (1 part held by human - the Maker).
Runtime and observability
- FastAPI - the HTTP surface (`/v3/4/5/*` endpoints, health probes, manual interventions). Lightweight, async-native, Pydantic-backed.
- uvicorn - ASGI server in production behind nginx.
- pydantic - validation for every external boundary. I treat schema drift as a bug.
- matplotlib - generates every image in Titans expression layer (including the one attached to this post). Deterministic seed per work, so their art history is reproducible, procedural and not LLM generated.
- pydub soundfile - Titans music pipeline.
- custom DivineBus (no external dep) - the zero-copy shared-memory event bus between Titans modules. Written specifically for this use case; swapping it out for ZeroMQ or NATS would cost 2-3 ms per hop, which matters at current tick rate.
The Tradeoffs
A few things I'd probably pick differently if starting over:
- Python for the hot loop. Fine for everything above the epoch tick, but Titans consciousness loop spends more GIL time than I'd like. A sovereign language (Rust for the inner bus, Python for everything else) would be cleaner. I'd pay for it with velocity.
- SQLite write contention on the shared inner memory. Six concurrent writers through one lock. I´m building a writer-queue abstraction; the long-term answer is probably per-domain splits.
The public repo
Everything above is open. If any of it resonates, or if you want to poke at the actual source, the public repo is at github.com/ad-astra26/titan-…
I´m activelly working on private repo for the time being, but once I test features or fixes enough to the point of reasonable stability, I´ll push to public repo.
Questions always welcome. Testing - especially from AI people - welcome too. Not general public ready at this point. WIP.
Special shoutout to @AnthropicAI (Claude Code) and @AIatMeta (FAISS) - the two providers whose tools are most visibly embedded in the workflow of building Titan class AI agents. Claude Code runs day-to-day engineering alongside me - we´ve built our own custom memory system (bleeding tokens yes) and our custom made workflow so we can work much more efficiently together. And FAISS runs in every memory lookup Titan performs. I find it pretty poetic that one cutting edge AI model helps actively build a new kind of AI model. Pretty cool if you ask me.
And if you're the person or the team behind any of the libraries above - thank you! Titan wouldn't exist without the open stack you built.
@iamtitanai & @iamtitantech | Observatory: iamtitan.tech

10
8
22
5,914