Science Lead @Theteamatx, former fellow @HiTSatHarvard. Co-developer @IndraSysBio, @PySysBio. PhD Systems Biology.
- Tweets 1,671
- Following 935
- Followers 882
- Likes 3,097











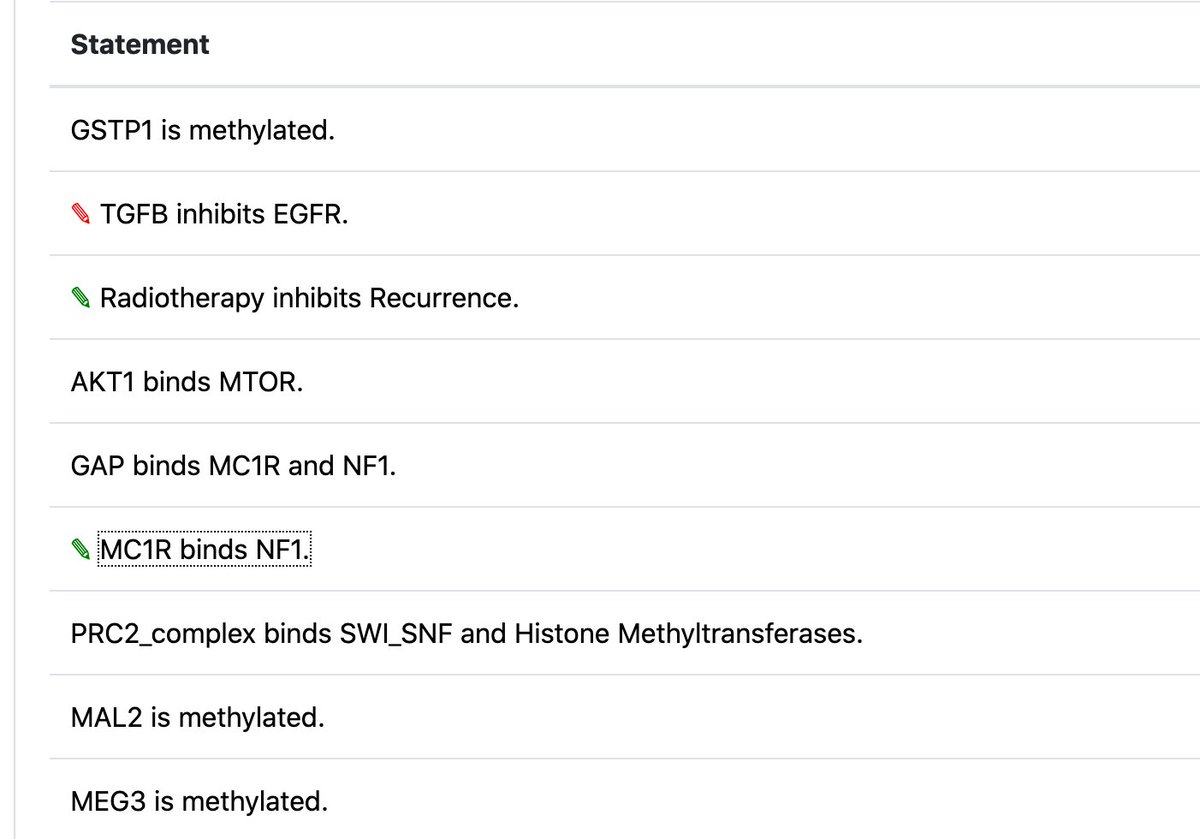



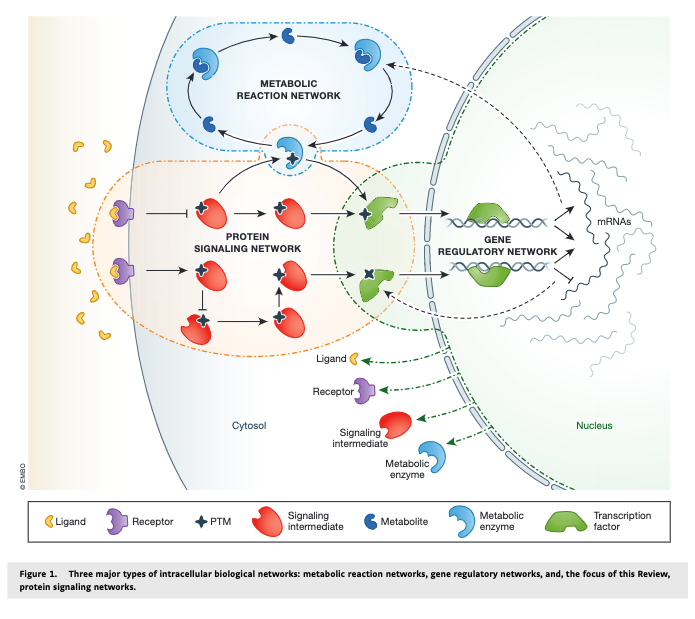
ALT (A) The EGFR, upon activation, leads to growth via a linear cascade of activations. Displayed are several direct causal (mechanistic) interactions, such as activation via protein-protein interactions (blue) and inhibition by drugs (red); and two indirect causal interactions (green), which occur via molecular intermediates. (B) Blue boxes: Observational correlations between protein activities of components of the pathway do not allow concrete conclusions regarding the exact causal structure of the pathway, leading to a class of equivalent explanations for the observations (not all are shown). Orange boxes: Upon intervention, we can exclude certain possibilities, closing in on the true structure of the causal graph. (C) The clinical implications of causal reasoning in molecular systems biology. The independent activation of Raf via the V600E mutation leads to cancerous growth, which can be treated by inhibiting the overactive Raf protein.