
Senior Vice President, Global AI Markets at AMD
Joined January 2013
- Tweets 5,140
- Following 1,097
- Followers 1,425
- Likes 1,146
219 Photos and videos













Keith Strier retweeted

Jun 10
$AMD & Oriole Networks work to beat $NVDA GPU🚀
The Oriole Networks and AMD £50 million (~$68M) UK ARIA Scaling Inference Lab delivers significant strategic benefits to AMD by deploying its Instinct GPUs and EPYC CPUs in the world’s first large-scale pure photonic AI network. This high-profile project showcases AMD hardware in a revolutionary networking environment that dramatically improves performance, achieving an 81% reduction in network power consumption, slashing GPU idle time from ~60% to under 1%, and delivering up to 10x higher inference throughput and interactivity.
By solving critical communication bottlenecks that plague traditional GPU clusters, AMD’s accelerators appear far more powerful and efficient, strengthening its competitive position against NVIDIA’s dominant networking solutions. The partnership provides real-world validation for AMD in next-generation, xPU-agnostic photonic fabrics, lowers total cost of ownership for customers through major energy and cooling savings, and creates a compelling sales pipeline as Oriole scales deployments in 2027. Overall, AMD gains market credibility as an innovator in sustainable, high-performance AI infrastructure, boosts demand for its chips in frontier-scale inference, and positions itself at the forefront of energy-efficient computing.
Source : quantumzeitgeist.com/oriole-…

Jun 9

BREAKING $AMD Agentic AI Rack At SCALE is out! 🚀
AKA CPUs Dense Rack for Fleets of Agents!🆕🆕🆕
I been talking about this for years & it is HAPPENING
Not Financial Advice! DYOR!
Today, @AMD published a detailed technical blog emphasizing that the future of agentic AI autonomous, multi-step AI systems requiring heavy orchestration, databases, caching, APIs, and control planes demands massive CPU-dense rack-scale infrastructure, not just GPUs. The catalyst prominently positions their upcoming 6th Gen EPYC "Venice" processors as the key enabler for next-generation dense racks, delivering leadership throughput under real-world power, cooling, and density constraints.
AMD's EPYC-powered "dense rack" (primarily the Helios platform with Venice CPUs) is on track for volume availability and deployments in the second half of 2026 (H2 2026).
Timeline:
Venice production ramp May 2026
Helios Previews/showcases Jan-June 2026
Customers testing Q2-Q3
Vol deployments From H2 2026
Accelerated Ramp Q4 2026 and onward
UBS Note is completely false and misleading!
Key highlights:
~EPYC Venice (Zen 6 architecture, up to 256 cores / 512 threads per socket) is projected to deliver exceptional rack-level performance. In AMD’s modeled 100 kW rack comparisons, Venice-powered systems are expected to achieve ~3.30x the throughput of NVIDIA’s Vera (88-core Olympus) baseline across a broad mix of agentic-supporting workloads.
~This builds on current-generation 5th Gen EPYC "Turin" (up to 192 cores), which already delivers ~2.37x rack throughput vs. Vera and ~1.6x vs. Intel’s Xeon 6980P (128 cores).
~ Liquid-cooled Turin deployments already support >27,000 CPU cores per rack today. Venice is architected to push this beyond 36,000 cores in the same rack class, dramatically increasing concurrent agent capacity and overall infrastructure efficiency.
1. The Helios AI Rack Platform
Venice CPUs are a cornerstone of AMD’s Helios reference design, the company’s flagship open, standards-based rack-scale AI platform. Helios integrates:
~EPYC Venice CPUs for orchestration and CPU-bound services.
~Instinct MI400-series GPUs ( MI455X) for AI acceleration.
~Pensando Vulcano AI networking for high-bandwidth, low-latency scale-out.
Each compute node in Helios typically pairs one Venice CPU with four MI455X GPUs, enabling full liquid cooling and extreme density. The platform is on track for multi-gigawatt deployments in the second half of 2026, targeting hyperscalers and large enterprises running production agentic AI
2. Key Performance Advantages for Agentic AI
AMD’s analysis normalizes everything to 100 kW racks using dual-processor (2P) servers, focusing on real deployable capacity rather than isolated chip benchmarks. Workloads modeled include:
~SPEC CPU 2017 Integer Rate
~Server-side Java
~NGINX web serving
~Redis / Memcached
~MySQL OLTP (TPROC-C
Venice is also projected to maintain strong single-threaded/per-core performance (critical for latency-sensitive database and orchestration tasks), with up to 27% per-core advantage vs. competitors at comparable configurations. Additional benefits include up to 1.6 TB/s memory bandwidth per socket and advanced I/O.
Conclusion:
AMD stresses deployability today on standard x86 platforms (no proprietary architectures required), full software compatibility, and open standards. This positions Venice Helios as a practical, high-density alternative to competing solutions while underscoring that agentic AI shifts the balance toward CPU-rich racks alongside GPUs.
In her recent public remarks and earnings commentary, AMD Chair and CEO Dr. Lisa Su has been clear and bullish: the rapid rise of inference-heavy, agentic AI workloads represents a major inflection point, one that is poised to trigger a steep J-curve acceleration in demand for high-performance CPUs and balanced CPU GPU infrastructure.
“We always believed that inference would actually be the driver of AI going forward, and we can now see that inference inflection point,” Su stated. She emphasized that as AI adoption scales from simple chatbots to autonomous agentic systems, which continuously orchestrate tasks, access data, reason over long horizons, and operate in real time the compute requirements shift dramatically. These workloads demand far more CPU resources for orchestration, data movement, caching, databases, and head-node control planes alongside GPU acceleration.
This shift is already reshaping the economics of AI infrastructure. The current CPU TAM forecast to more than $500 billion by 2030 where analysts are expecting AMD to be biggest winner. Dr. Su noted that customer demand across cloud and enterprise is running “stronger than expected,” with agentic AI and large-scale inference driving both larger GPU clusters and significantly higher CPU density per rack.
The result is a classic J-curve for AMD: modest but visible gains today from 5th Gen EPYC Turin dense racks, followed by a sharp upward trajectory as 6th Gen EPYC Venice and the Helios rack-scale platform (Venice CPUs MI400-series GPUs) ramp in the second half of 2026. With Venice enabling >36,000 CPU cores per liquid-cooled rack and Helios delivering rack-level performance leadership, AMD is positioning itself at the center of the next phase of AI buildout, one where balanced, CPU-rich, open-standards infrastructure becomes the dominant architecture.
Dr. Su’s message is confident: the industry is still in the “early innings” of unlocking AI’s full potential, with global compute needing to grow ~100x in the coming years to reach yottascale. For AMD, the combination of leadership in EPYC server CPUs, a strong Instinct GPU roadmap, and open rack-scale solutions like Helios places the company squarely on the steep part of the J-curve.
Not Financial Advice! DYOR!
AMD Blog Source: amd.com/en/blogs/2026/agenti…
1
7
49
13,199
Keith Strier retweeted
Jun 9
BREAKING $AMD Agentic AI Rack At SCALE is out! 🚀
AKA CPUs Dense Rack for Fleets of Agents!🆕🆕🆕
I been talking about this for years & it is HAPPENING
Not Financial Advice! DYOR!
Today, @AMD published a detailed technical blog emphasizing that the future of agentic AI autonomous, multi-step AI systems requiring heavy orchestration, databases, caching, APIs, and control planes demands massive CPU-dense rack-scale infrastructure, not just GPUs. The catalyst prominently positions their upcoming 6th Gen EPYC "Venice" processors as the key enabler for next-generation dense racks, delivering leadership throughput under real-world power, cooling, and density constraints.
AMD's EPYC-powered "dense rack" (primarily the Helios platform with Venice CPUs) is on track for volume availability and deployments in the second half of 2026 (H2 2026).
Timeline:
Venice production ramp May 2026
Helios Previews/showcases Jan-June 2026
Customers testing Q2-Q3
Vol deployments From H2 2026
Accelerated Ramp Q4 2026 and onward
UBS Note is completely false and misleading!
Key highlights:
~EPYC Venice (Zen 6 architecture, up to 256 cores / 512 threads per socket) is projected to deliver exceptional rack-level performance. In AMD’s modeled 100 kW rack comparisons, Venice-powered systems are expected to achieve ~3.30x the throughput of NVIDIA’s Vera (88-core Olympus) baseline across a broad mix of agentic-supporting workloads.
~This builds on current-generation 5th Gen EPYC "Turin" (up to 192 cores), which already delivers ~2.37x rack throughput vs. Vera and ~1.6x vs. Intel’s Xeon 6980P (128 cores).
~ Liquid-cooled Turin deployments already support >27,000 CPU cores per rack today. Venice is architected to push this beyond 36,000 cores in the same rack class, dramatically increasing concurrent agent capacity and overall infrastructure efficiency.
1. The Helios AI Rack Platform
Venice CPUs are a cornerstone of AMD’s Helios reference design, the company’s flagship open, standards-based rack-scale AI platform. Helios integrates:
~EPYC Venice CPUs for orchestration and CPU-bound services.
~Instinct MI400-series GPUs ( MI455X) for AI acceleration.
~Pensando Vulcano AI networking for high-bandwidth, low-latency scale-out.
Each compute node in Helios typically pairs one Venice CPU with four MI455X GPUs, enabling full liquid cooling and extreme density. The platform is on track for multi-gigawatt deployments in the second half of 2026, targeting hyperscalers and large enterprises running production agentic AI
2. Key Performance Advantages for Agentic AI
AMD’s analysis normalizes everything to 100 kW racks using dual-processor (2P) servers, focusing on real deployable capacity rather than isolated chip benchmarks. Workloads modeled include:
~SPEC CPU 2017 Integer Rate
~Server-side Java
~NGINX web serving
~Redis / Memcached
~MySQL OLTP (TPROC-C
Venice is also projected to maintain strong single-threaded/per-core performance (critical for latency-sensitive database and orchestration tasks), with up to 27% per-core advantage vs. competitors at comparable configurations. Additional benefits include up to 1.6 TB/s memory bandwidth per socket and advanced I/O.
Conclusion:
AMD stresses deployability today on standard x86 platforms (no proprietary architectures required), full software compatibility, and open standards. This positions Venice Helios as a practical, high-density alternative to competing solutions while underscoring that agentic AI shifts the balance toward CPU-rich racks alongside GPUs.
In her recent public remarks and earnings commentary, AMD Chair and CEO Dr. Lisa Su has been clear and bullish: the rapid rise of inference-heavy, agentic AI workloads represents a major inflection point, one that is poised to trigger a steep J-curve acceleration in demand for high-performance CPUs and balanced CPU GPU infrastructure.
“We always believed that inference would actually be the driver of AI going forward, and we can now see that inference inflection point,” Su stated. She emphasized that as AI adoption scales from simple chatbots to autonomous agentic systems, which continuously orchestrate tasks, access data, reason over long horizons, and operate in real time the compute requirements shift dramatically. These workloads demand far more CPU resources for orchestration, data movement, caching, databases, and head-node control planes alongside GPU acceleration.
This shift is already reshaping the economics of AI infrastructure. The current CPU TAM forecast to more than $500 billion by 2030 where analysts are expecting AMD to be biggest winner. Dr. Su noted that customer demand across cloud and enterprise is running “stronger than expected,” with agentic AI and large-scale inference driving both larger GPU clusters and significantly higher CPU density per rack.
The result is a classic J-curve for AMD: modest but visible gains today from 5th Gen EPYC Turin dense racks, followed by a sharp upward trajectory as 6th Gen EPYC Venice and the Helios rack-scale platform (Venice CPUs MI400-series GPUs) ramp in the second half of 2026. With Venice enabling >36,000 CPU cores per liquid-cooled rack and Helios delivering rack-level performance leadership, AMD is positioning itself at the center of the next phase of AI buildout, one where balanced, CPU-rich, open-standards infrastructure becomes the dominant architecture.
Dr. Su’s message is confident: the industry is still in the “early innings” of unlocking AI’s full potential, with global compute needing to grow ~100x in the coming years to reach yottascale. For AMD, the combination of leadership in EPYC server CPUs, a strong Instinct GPU roadmap, and open rack-scale solutions like Helios places the company squarely on the steep part of the J-curve.
Not Financial Advice! DYOR!
AMD Blog Source: amd.com/en/blogs/2026/agenti…
Jun 9
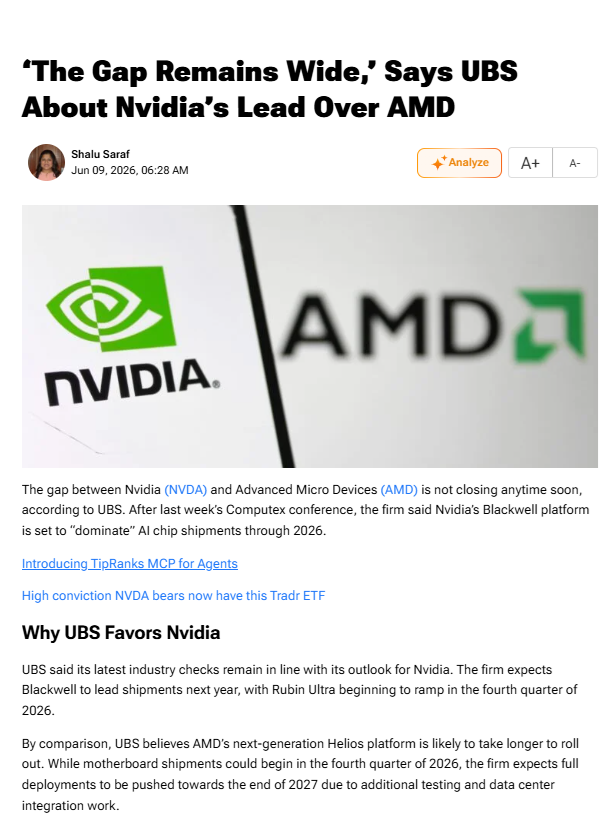
BREAKING $AMD UBS Bullshit Note 🚨🚨🚨
I refused to believe UBS Does not have access to BofA 2026 GLobal Tech Conference Call, Even myself, a Nobody got it on June 3rd 2026. This note from UBS is full of shit and lying bullshit. I been dealing with fake news like this for years, so get used to it.
Here is key points from UBS's post-Computex note (June 8-9 2026), after the BofA conference.
Nvidia's Timeline: Blackwell leads shipments in 2026–2027; industry checks align with their bullish outlook.
AMD's Timeline: The next-gen Helios platform will see motherboard shipments possibly in Q4 2026, but full data-center deployments are likely pushed to late 2027 due to extra testing and integration needs.
Ok there has been significant more delay news from the Media on $NVDA Rubin rack for the last 2-3 months. And this has nothing to do with @AMD!!!
Dr. Su already said Helios Rack is on track along with other AMD Executives.
On BofA Conference call, they said new customers are testing Helios Rack not Existing orders. OpenAI and $META are going to get their Helios Rack in H2 2026 and 4GW in 2027(Implying faster deployment).
NOT Late 2027 Bullshit.
Not Financial Advice! DYOR!
Source: tipranks.com/news/the-gap-re…
3
11
69
28,113
Keith Strier retweeted

We've made a breakthrough in self-evolving AI scientists moving from "search" to "principled discovery": Scientific discovery requires that the search space itself changes, and an AI scientist must perceive this shift without intervention. We built an AI that achieves this for the first time with the ability to discover the scientific vocabulary it reasons in. Evidence, tools, artifacts, verifiers, failures & claims become typed provenance. We show three distinct modalities: 1) retrieval, adding known objects; 2) search, exploring a fixed schema; and critically: 3) discovery, a verified regime transition.
We solve the open-endedness evaluation problem by lifting agentic workflows into a typed copresheaf and proving, via a Kan obstruction, that true discovery is not unbounded generation but a verifiable schema expansion: old evidence is transported by Left Kan extension, and genuine novelty is mathematically quantified by the pointwise residual beyond the transported image - separating discovery from mere search and making novelty objective and measurable rather than a subjective judgment or benchmark delta.
Our AI scientist is built in a way that does not pre-conceive the approach it chooses; instead, we endow the system with formal power to adapt, evolve, and reason from first principles. Case studies include:
1⃣Builder/Breaker model that discovers mode-conditioned compliance in proteins;
2⃣CategoryScienceClaw that finds anisotropic fiber-network stiffness rules.
Great work in collaboration with my graduate student @fwang108_ @MITdeptofBE
F.Y. Wang & M.J. Buehler, Self-Revising Discovery Systems for Science: A Categorical Framework for Agentic Artificial Intelligence, arXiv:2606.01444, 2026
105
378
2,524
781,094
Keith Strier retweeted

May 28
Энэ жилийн арга хэмжээний гол одод Цахиурын хөндийгөөс холбогдоно.
- AI-ийн тэсрэлтийн гол ялагчдын нэг @AMD-ийн SVP @kbsdigital
- Монголын мэдээллийн технологийн салбарын нүүр царай болсон @Google-ийн @battulga11
- Дэлхийн хамгийн том технологийн гигантуудын нэг @amazon-ийн Г.Мөнхбаяр



1
2
8
891
Keith Strier retweeted

May 26
🚀 Дэлхийн хагас дамжуулагчийн технологийн аварга @AMD компанийн Ахлах дэд ерөнхийлөгч @kbsdigital -ийн гал асаасан ярилцлага DevSummit 2026 арга хэмжээний тайзнаа!
Өнөөдөр дэлхийн технологийн салбарын хамгийн халуухан сэдэв бол гарцаагүй Agentic AI. Түүнийг ажиллуулах суурь хэрэгцээ болох GPU (График процессор)-ийн зах зээлд АНУ болон БНХАУ-ын өрсөлдөөн улам ширүүссээр байна.
⚡ Тэгвэл БНХАУ-тай хил залгаа, АНУ-тай "Гуравдагч хөрш"-ийн бодлоготой Монгол Улс энэ том давалгаанд хэрхэн тэнцвэрээ хадгалж, зөв нүүдэл хийх вэ?
Манай улсад ямар боломж, сорилт байгааг AMD компанийн Ахлах дэд ерөнхийлөгч (SVP) Keith Strier-тэй хийсэн онцгой ярилцлагаас олж мэдээрэй.
🔥 Зөвхөн DevSummit 2026 арга хэмжээний тайзнаас хүлээн авч үзэх боломжтой.
🗓️ Хэзээ: 5-р сарын 30, 31
📍 Хаана: Тусгаар Тогтнолын Ордон
🎟️ Тасалбар худалдан авах: devsummit.dev/tickets

1
88
Keith Strier retweeted

May 24
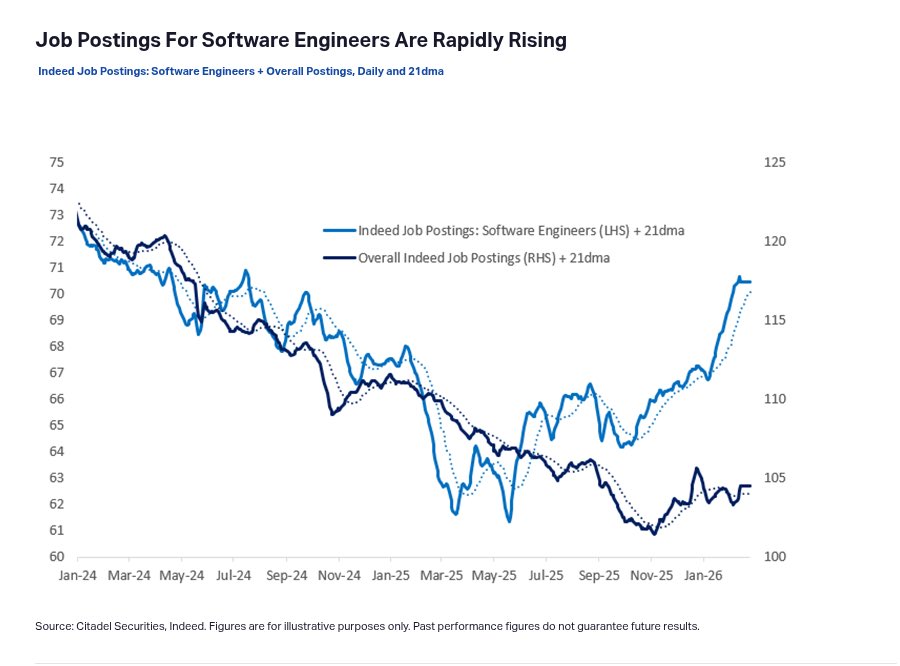
Q: How are job postings for software engineers rising rapidly despite AI agents automating coding?
A: Because there’s far more code to manage than ever before. We’re already seeing a 14x YoY increase in GitHub commits, and it’s accelerating.
AI has dramatically lowered the cost of writing code, so it’s now being used across far more businesses, applications, and use cases.
We’re at the beginning of a massive productivity boom driven by the proliferation of bespoke software throughout the entire economy.
Coding has been AI’s breakout use case this year. The fact that it’s increased demand for software engineers — rather than decreased it — should call into question the entire “AI will cause mass job loss” narrative.
827
1,466
9,114
1,630,251
Keith Strier retweeted

May 20
✨ Personal AI is the next computing platform.
AI is shifting from something you access to something you build with, locally, at the edge, and across systems.
We’re unlocking new possibilities for developers:
• @AMD Ryzen AI Halo, a local-first developer system, preorder starting in June, develop AI without limits on your desk
• Gorgon Halo with up to 192GB unified memory, supporting 300B parameter models locally, run massive models locally
We’re excited to partner with @ClementDelangue🤗, Co-founder and CEO of @huggingface, to advance open-source AI for Ryzen AI.
Our focus is seamless AI, from model to deployment.
Cloud, edge, device. One continuum.
Multi-agent systems, local inference at scale, open models as infrastructure.
This is the next computing era 🚀
25
42
160
47,242



Built for the harshest environments.
Radiation-tolerant, space-grade AMD Virtex-5QV FPGAs were onboard the Artemis II Orion spacecraft, enabling functions critical to the success of the mission.
Details from @FierceSensors 🚀 fiercesensors.com/sensors/na…

8
22
154
13,959
Keith Strier retweeted

Today, SCSP is proud to announce the launch of the National Security Commission on Robotics for Advanced Manufacturing, a bipartisan commission with the mission to ensure that the United States leads the next frontier of industrial competition. This commission will bring together leaders from government, academia, and industry to shape a national robotics strategy.
Our leadership includes:
• @SenTedBuddNC (R-NC)
• @SenatorSlotkin (D-MI)
• @Ylli_Bajraktari, President of SCSP
The Commission will focus on four key priorities:
1. National Framework: Coordinating public and private sector investment.
2. Talent Pipeline: Upskilling the next generation of technicians and engineers.
3. Supply Chain Integration: Setting measurable targets for robotics adoption.
4. U.S. Leadership: Ensuring American dominance in both hardware and software ecosystems.
Commissioners include:
• Peter Barrett, Founder & General Partner, Playground Global
• Heather Carroll, Chief Revenue Officer, Path Robotics
• Michael Cicco, President & CEO, @FANUCAmerica
• Dr. Ayanna Howard, Dean, @OSUengineering
• Dr. Torsten Kroeger, Chief Science Officer, @IntrinsicAI
• @RevLebaredian, Vice President of Omniverse and Simulation Technology, @nvidia
• Anne Neuberger, Senior Advisor, @a16z, Distinguished Fellow, @Stanford, Former Deputy National Security Advisor
• Dr. Chinedum Okwudire, Professor, @umichme
• Dr. @LizBeckReynolds, Principal Research Scientist & Executive Director, MIT Industrial Performance Center
• Brendan Schulman (@RobotPolicy), Vice President of Policy & Government Relations, @BostonDynamics
• Keith Strier (@kbsdigital), Senior Vice President, Global AI Markets, @AMD
• Josh Tavel, Senior Vice President of R&D, Manufacturing and Product Engineering, @GM
• Chris Walti, Founder & CEO, Mytra
• Dr. David Van Wie, Director, Johns Hopkins Applied Physics Laboratory
For more information on the commission, visit: scsp.ai/2026/03/scsp-announc…
Read more about our launch in POLITICO: subscriber.politicopro.com/a…
2
10
522
Keith Strier retweeted

Mar 23
AMD's inference team has improved the performance of those chips by a lot recently, even beating the B200
So, it's a smart choice

I predicted (without any insider knowledge) on an analyst call last week that people would stock up on MI355x.
5
11
270
35,443
Keith Strier retweeted

Mar 20
American AI leadership by the American people, for the American people.
This National AI Legislative Framework from @mkratsios47 @davidsacks47 and @WhiteHouse team is a commonsense plan for Federal AI legislation. Look forward to working with Congress to realize @POTUS vision!
Mar 20

The Trump administration is committed to WINNING the AI race for the American people. President Trump has unveiled a commonsense national policy framework in order to achieve this goal while keeping Americans safe. 🇺🇸

4
5
35
1,985

🤪
Even a 2x performance boost is only about on par with AMD's CPUs from two years ago...
phoronix.com/review/nvidia-g…


Jensen: "There are no CPUs in the world that are two times the performance of anything else, besides Vera."
He doesn't see Nvidia's CPUs playing in the traditional server CPU market: "That's not the problem we're trying to solve."
9
26
286
56,024
Keith Strier retweeted

Mar 19
KING ALERT: Congrats to @roaner & @AnushElangovan & 10x AMD China Engineering team for its amazing FP8 MI355 ROCm SGLang disaggregated performance beating NVIDIA Blackwell! They are also the Inference King! 👑
Mar 19


8
14
184
51,033
Keith Strier retweeted

Feb 24
Meta 🤝 AMD
Today we’re announcing a multi-year agreement with @AMD to integrate their latest Instinct GPUs into our global infrastructure. With approximately 6GW of planned data center capacity dedicated to this deployment, we’re scaling our compute capacity to accelerate the development of cutting-edge AI models and deliver personal superintelligence to billions around the world.
Learn more: go.meta.me/220f12
163
312
2,315
369,519

White House Moves to Lock In Quantum Dominance With Sweeping Executive Order
The U.S. is fast-tracking quantum supremacy within the next 180 days. A leaked draft EO 'Ushering In The Next Frontier Of Quantum Innovation,' mandates a national quantum computer, overhauls the 2018 strategy, and weaponizes federal R&D to counter global threats. Agencies are directed to align manufacturing, research, and international engagement, positioning quantum as a cornerstone of economic and national security strategy by 2027. No more lab experiments, this is full deployment mode.
nextgov.com/emerging-tech/20…
5
12
63
5,912
Keith Strier retweeted

Looking forward to leading the U.S. delegation to the AI Impact Summit in India this month.
America is setting the gold standard for AI innovation and we want to share it with our global partners.
@UnderSecE, @TradeGov U/S Kimmitt, @BISgov U/S Kessler, & @skrishnan47 will join @USAmbIndia on Team USA in Delhi.

17
73
507
117,564
Keith Strier retweeted

Jan 30
🙏 ROCm ease of use is a high priority
Jan 30

Legend thank you. I was wondering if it was just that easy. This is much improved from before when you had to custom compile vllm. Congrats to the team, will give it a try!
3
5
67
6,193
From training to inference at massive scale, delivering on the promise of AI depends on collaboration across open hardware and software.
AMD and @OpenAI are working together to tailor hardware like Instinct MI455X and Helios for where AI workloads are going, not just where they are today.
Greg Brockman (@gdb) on the power of our engineering partnership at #CES2026.
10
36
281
19,984
Keith Strier retweeted

Jan 21
India is working on all 5 layers of the AI architecture: application, model, chip, infra and energy. We are building the foundation for global AI services.
📍 World Economic Forum, Davos
815
3,251
15,585
692,241